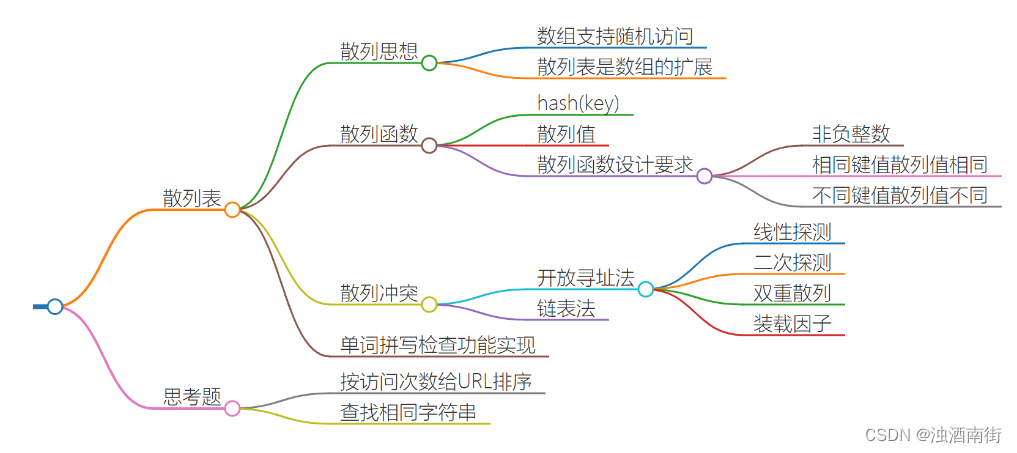
数据结构与算法之美学习笔记:18 | 散列表(上):Word文档中的单词拼写检查功能是如何实现的?
目录
- 前言
- 散列思想
- 散列函数
- 散列冲突
- 解答开篇
前言

本节课程思维导图:
Word 的单词拼写检查功能,虽然很小但却非常实用。你有没有想过,这个功能是如何实现的呢?其实啊,一点儿都不难。只要你学完今天的内容,散列表(Hash Table)。你就能像微软 Office 的工程师一样,轻松实现这个功能。
散列思想
散列表的英文叫“Hash Table”,我们平时也叫它“哈希表”或者“Hash 表”。你一定也经常听过它,但是你是不是真的理解这种数据结构呢?
散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表。
我用一个例子来解释一下。假如我们有 89 名选手参加学校运动会。为了方便记录成绩,每个选手胸前都会贴上自己的参赛号码。假设校长说,参赛编号不能设置得这么简单,要加上年级、班级这些更详细的信息,所以我们把编号的规则稍微修改了一下,用 6 位数字来表示。比如 051167,其中,前两位 05 表示年级,中间两位 11 表示班级,最后两位还是原来的编号 1 到 89。这个时候我们该如何存储选手信息,才能够支持通过编号来快速查找选手信息呢?
我们可以把这 89 名选手的信息放在数组里。尽管我们不能直接把编号作为数组下标,但我们可以截取参赛编号的后两位作为数组下标,来存取选手信息数据,编号为01 的选手,我们放到数组中下标为 1 的位置;编号为 02 的选手,我们放到数组中下标为 2 的位置。以此类推,编号为 k 的选手放到数组中下标为 k 的位置。
这就是典型的散列思想。其中,参赛选手的编号我们叫做键(key)或者关键字。我们用它来标识一个选手。我们把参赛编号转化为数组下标的映射方法就叫作散列函数(或“Hash 函数”“哈希函数”),而散列函数计算得到的值就叫作散列值(或“Hash 值”“哈希值”)。
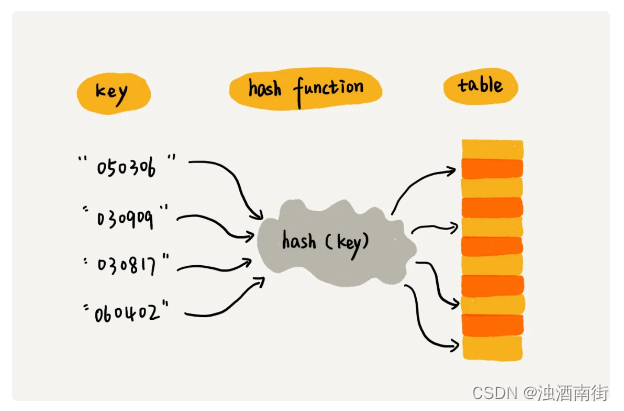
通过这个例子,我们可以总结出这样的规律:散列表用的就是数组支持按照下标随机访问的时候,时间复杂度是 O(1) 的特性。我们通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。当我们按照键值查询元素时,我们用同样的散列函数,将键值转化数组下标,从对应的数组下标的位置取数据。
散列函数
散列函数,顾名思义,它是一个函数。我们可以把它定义成 hash(key),其中 key 表示元素的键值,hash(key) 的值表示经过散列函数计算得到的散列值。
int hash(String key) {// 获取后两位字符string lastTwoChars = key.substr(length-2, length);// 将后两位字符转换为整数int hashValue = convert lastTwoChas to int-type;return hashValue;
}
刚刚的散列函数比较简单,也比较容易想到。但是,如果参赛选手的编号是随机生成的 6 位数字,又或者用的是 a 到 z 之间的字符串,该如何构造散列函数呢?我总结了三点散列函数设计的基本要求:
- 散列函数计算得到的散列值是一个非负整数;
- 如果 key1 = key2,那 hash(key1) == hash(key2);
- 如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)。
第一点和第二点理解起来比较简单,第三点理解起来可能会有问题。这个要求看起来合情合理,但是在真实的情况下,要想找到一个不同的 key 对应的散列值都不一样的散列函数,几乎是不可能的。即便像业界著名的MD5、SHA、CRC等哈希算法,也无法完全避免这种散列冲突。
散列冲突
再好的散列函数也无法避免散列冲突。那究竟该如何解决散列冲突问题呢?我们常用的散列冲突解决方法有两类,开放寻址法(open addressing)和链表法(chaining)。
- 开放寻址法
开放寻址法的核心思想是,如果出现了散列冲突,我们就重新探测一个空闲位置,将其插入。那如何重新探测新的位置呢?我先讲一个比较简单的探测方法,线性探测(Linear Probing)。当我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。
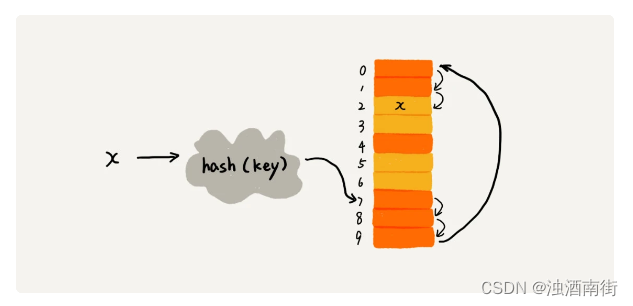
从图中可以看出,散列表的大小为 10,在元素 x 插入散列表之前,已经 6 个元素插入到散列表中。x 经过 Hash 算法之后,被散列到位置下标为 7 的位置,但是这个位置已经有数据了,所以就产生了冲突。于是我们就顺序地往后一个一个找,看有没有空闲的位置,遍历到尾部都没有找到空闲的位置,于是我们再从表头开始找,直到找到空闲位置 2,于是将其插入到这个位置。
我们通过散列函数求出要查找元素的键值对应的散列值,然后比较数组中下标为散列值的元素和要查找的元素。如果相等,则说明就是我们要找的元素;否则就顺序往后依次查找。如果遍历到数组中的空闲位置,还没有找到,就说明要查找的元素并没有在散列表中。
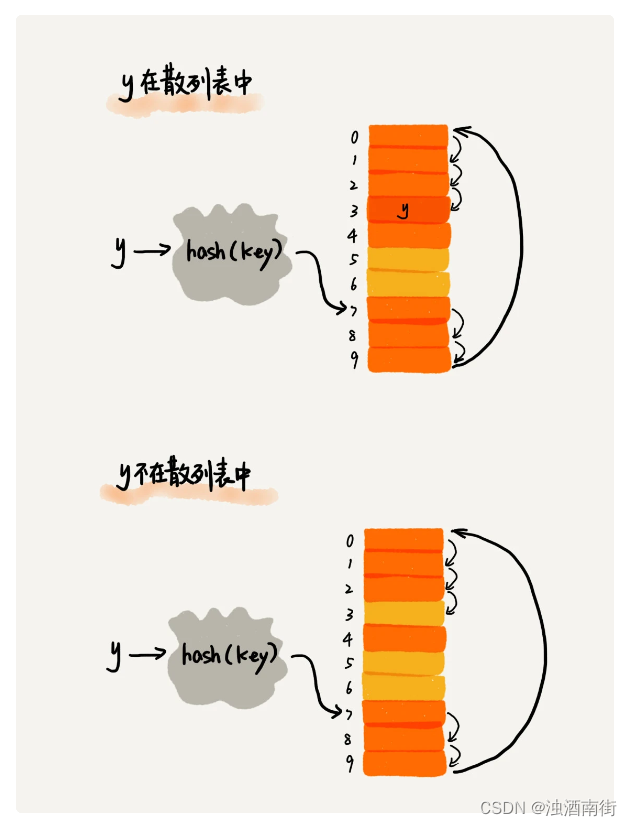
散列表跟数组一样,不仅支持插入、查找操作,还支持删除操作。对于使用线性探测法解决冲突的散列表,删除操作稍微有些特别。我们不能单纯地把要删除的元素设置为空。我们可以将删除的元素,特殊标记为 deleted。当线性探测查找的时候,遇到标记为 deleted 的空间,并不是停下来,而是继续往下探测。
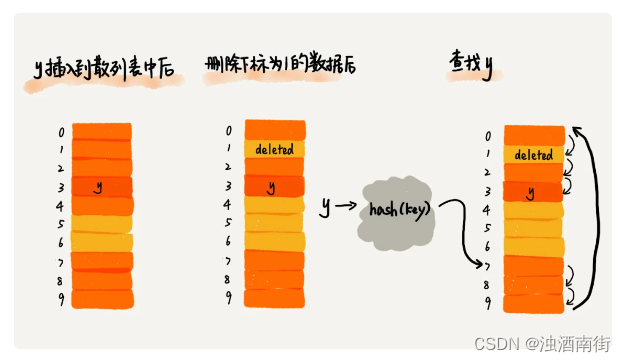
你可能已经发现了,线性探测法其实存在很大问题。当散列表中插入的数据越来越多时,散列冲突发生的可能性就会越来越大,空闲位置会越来越少,线性探测的时间就会越来越久。
对于开放寻址冲突解决方法,除了线性探测方法之外,还有另外两种比较经典的探测方法,二次探测(Quadratic probing)和双重散列(Double hashing)。
所谓二次探测,跟线性探测很像,线性探测每次探测的步长是 1,那它探测的下标序列就是 hash(key)+0,hash(key)+1,hash(key)+2……而二次探测探测的步长就变成了原来的“二次方”,也就是说,它探测的下标序列就是 hash(key)+0,hash(key)+12,hash(key)+22……
所谓双重散列,意思就是不仅要使用一个散列函数。我们使用一组散列函数 hash1(key),hash2(key),hash3(key)……我们先用第一个散列函数,如果计算得到的存储位置已经被占用,再用第二个散列函数,依次类推,直到找到空闲的存储位置。
不管采用哪种探测方法,当散列表中空闲位置不多的时候,散列冲突的概率就会大大提高。为了尽可能保证散列表的操作效率,一般情况下,我们会尽可能保证散列表中有一定比例的空闲槽位。我们用装载因子(load factor)来表示空位的多少。装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降。
2. 链表法
链表法是一种更加常用的散列冲突解决办法,相比开放寻址法,它要简单很多。我们来看这个图,在散列表中,每个“桶(bucket)”或者“槽(slot)”会对应一条链表,所有散列值相同的元素我们都放到相同槽位对应的链表中。
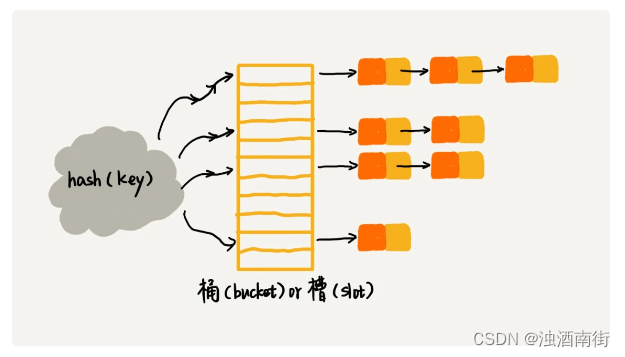
插入的时候,我们只需要通过散列函数计算出对应的散列槽位,将其插入到对应链表中即可,所以插入的时间复杂度是 O(1)。当查找、删除一个元素时,我们同样通过散列函数计算出对应的槽,然后遍历链表查找或者删除。那查找或删除操作的时间复杂度是多少呢?实际上,这两个操作的时间复杂度跟链表的长度 k 成正比,也就是 O(k)。对于散列比较均匀的散列函数来说,理论上讲,k=n/m,其中 n 表示散列中数据的个数,m 表示散列表中“槽”的个数。
解答开篇
Word 文档中单词拼写检查功能是如何实现的?
常用的英文单词有 20 万个左右,假设单词的平均长度是 10 个字母,平均一个单词占用 10 个字节的内存空间,那 20 万英文单词大约占 2MB 的存储空间,就算放大 10 倍也就是 20MB。对于现在的计算机来说,这个大小完全可以放在内存里面。所以我们可以用散列表来存储整个英文单词词典。当用户输入某个英文单词时,我们拿用户输入的单词去散列表中查找。如果查到,则说明拼写正确;如果没有查到,则说明拼写可能有误,给予提示。借助散列表这种数据结构,我们就可以轻松实现快速判断是否存在拼写错误。
相关文章:
数据结构与算法之美学习笔记:18 | 散列表(上):Word文档中的单词拼写检查功能是如何实现的?
目录 前言散列思想散列函数散列冲突解答开篇 前言 本节课程思维导图: Word 的单词拼写检查功能,虽然很小但却非常实用。你有没有想过,这个功能是如何实现的呢?其实啊,一点儿都不难。只要你学完今天的内容,…...

解决java发邮件错误javax.net.ssl.SSLHandshakeException: No appropriate protocol
java发送邮件时报以下错误信息: javax.net.ssl.SSLHandshakeException: No appropriate protocol (protocol is disabled or cipher [com.bm6api.controller.v1.AppUserController] - sendLoginAuthCodeMail 发送登录验证码邮件 : {"code":200,"inf…...

杭电oj 2035 人见人爱A^B C语言
#include<stdio.h>void main() {int a, b, i,num;while (~scanf_s("%d%d", &a, &b) && (a ! 0 || b ! 0)){num a;for (i 1; i < b; i){num * a;num % 1000;}printf("%d\n", num);} }...

[量化投资-学习笔记017]Python+TDengine从零开始搭建量化分析平台-异常处理
一个完成的程序一定少不了对异常的处理,以及错误日志的输出。 在之前章节的程序中对这两部分没有进行说明,以下用两个单独的章节进行介绍。 [量化投资-学习笔记016]PythonTDengine从零开始搭建量化分析平台-日志输出 异常处理 Python 通常使用 try .. except 和防…...
Mysql中的索引与事务和B树的知识补充
索引与事务和B树的知识补充 一.索引1.概念2.作用3.使用场景4.使用 二.事务1.为什么使用事务2.事务的概念3.使用3.1脏读问题3.2不可重复读3.3 幻读问题3.4解决3.5 使用代码 三.B树的知识补充1.B树2.B树 一.索引 1.概念 索引是一种特殊的文件,包含着对数据表里所有记…...

2024上海国际智能驾驶技术展览会(自动驾驶展)
2024上海国际智能驾驶技术展览会 2024 Shanghai International Autonomous driving Expo 时间:2024年3月26-28日 地点:上海跨国采购会展中心 随着科技的飞速发展,智能驾驶已经成为了汽车行业的重要趋势。在这个时代背景下,汽车不…...

嵌入式Linux开发,NFS文件系统挂载
在嵌入式linix的开发中,经常会需要在pc端和板端互相传输文件,优先可选择ftp传输,但是有些嵌入式板端不支持,只能使用nfs这种方式,即pc端作为服务端,板端作为客户端,将pc端的某个文件夹挂载到板端…...
什么是3D建模中的“高模”和“低模”?
3D建模中什么是高多边形和低多边形? 高多边形建模和低多边形建模之间的主要区别正如其名称所暗示的那样:您是否在模型中使用大量多边形或少量多边形。 然而,在决定每个模型的细节和多边形级别时,还需要考虑其他事项。最值得注意的…...

python数据结构与算法-04_队列
队列和栈 前面讲了线性和链式结构,如果你顺利掌握了,下边的队列和栈就小菜一碟了。因为我们会用前两章讲到的东西来实现队列和栈。 之所以放到一起讲是因为这两个东西很类似,队列是先进先出结构(FIFO, first in first out), 栈是…...
从理论到实践:深度解读BIO、NIO、AIO的优缺点及使用场景
文章目录 BIO优缺点示例代码 NIO优缺点示例代码 AIO优缺点示例代码 总结 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 BIO、NIO和AIO是Java编程语言中用于处理输入输出(IO…...

Mysql Innodb Cluster集群搭建 - docker
Mysql Innodb Cluster集群搭建 - docker 背景搭建环境架构图3台机器如下:修改三台机器的ip域名映射如下,并重启网络使其生效部署mysql server实例通过docker启动三台mysql server实例,需要映射数据请自行更改配置加入-v启动第一台mysql-server启动第二台mysql-server启动第三…...
如何在 macOS 中删除 Time Machine 本地快照
看到这个可用82GB(458.3MB可清除) 顿时感觉清爽,之前的还是可用82GB(65GB可清除),安装个xcode都安装不上,费解半天,怎么都解决不了这个问题,就是买磁盘情理软件也解决不了…...

mysql的sql_mode参数
msql修改了这个参数,首先mysql需要重新才能生效,还有就是java连接的springboot项目也需要重新启动。之前是遇到了下面的这个报错。只需要把sql_mode设置为空,重启mysql和服务就行 报错 In aggregated query without GROUP BY, expression #1…...

模拟业务流程+构造各种测试数据,一文带你测试效率提升80%
📢专注于分享软件测试干货内容,欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!📢交流讨论:欢迎加入我们一起学习!📢资源分享:耗时200小时精选的「软件测试」资…...

【linux】 Shell函数返回值
概述 return 返回 shell中通过return返回是有限制的,必须是数字,最大返回255,超过255,则从0开始计算。 通常仅返回0或1;0表示成功,1表示失败。通过echo 直接返回。 在没有return 语句,函数将以…...
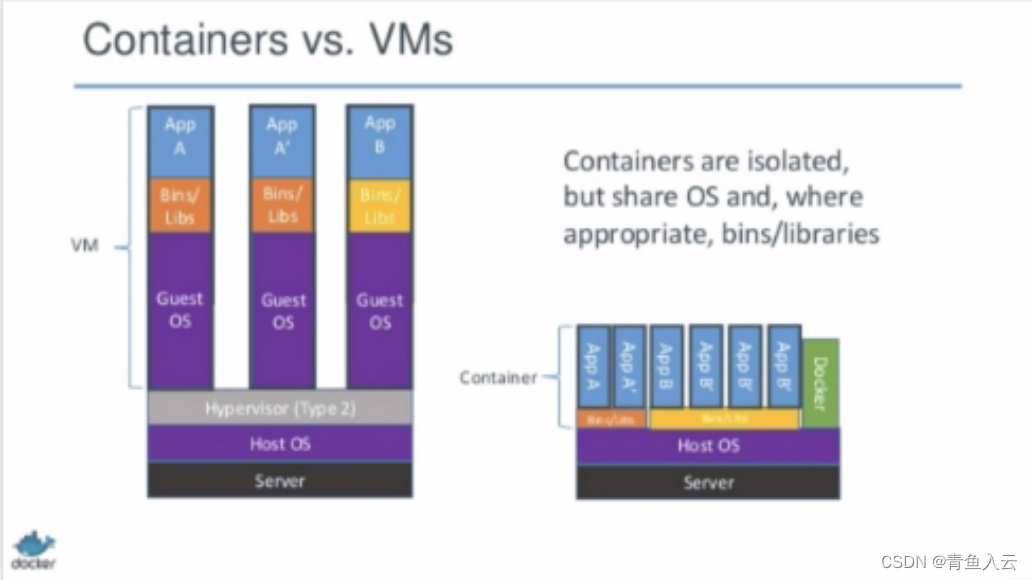
面试:容器技术
目录 为什么需要 DevOpsDocker 是什么?Docker 与虚拟机有何不同?什么是 Docker 镜像?什么是 Docker 容器?Docker 容器有几种状态?解释一下 Dockerfile 的 ONBUILD 指令?什么是 Docker Swarm?如何…...
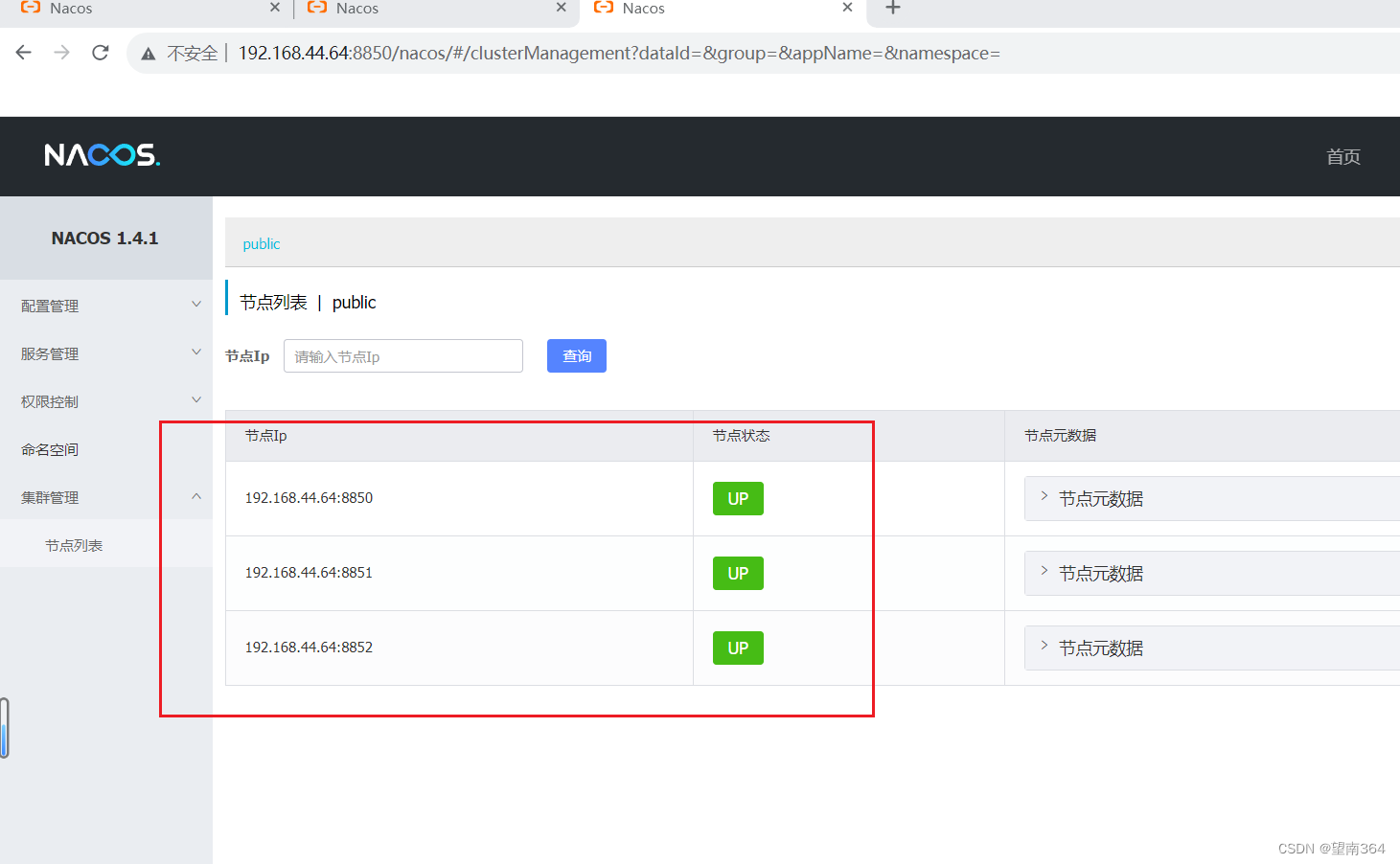
在Linux中nacos集群模式部署
一、安装 配置nacos 在Linux中建立一个nacos文件夹 mkdir nacos 把下载的压缩包拉入刚才创建好的nacos文件中 解压 tar -zxvf nacos-server-1.4.1\.tar.gz 修改配置文件 进入nacos文件中的conf文件的cluster.conf.example 修改cluster.conf.example文件 vim cluster.conf.exa…...

7天入门python系列之爬取热门小说项目实战,互联网的东西怎么算白嫖呢
第七天 Python项目实操 编者打算开一个python 初学主题的系列文章,用于指导想要学习python的同学。关于文章有任何疑问都可以私信作者。对于初学者想在7天内入门Python,这是一个紧凑的学习计划。但并不是不可完成的。 学到第7天说明你已经对python有了一…...
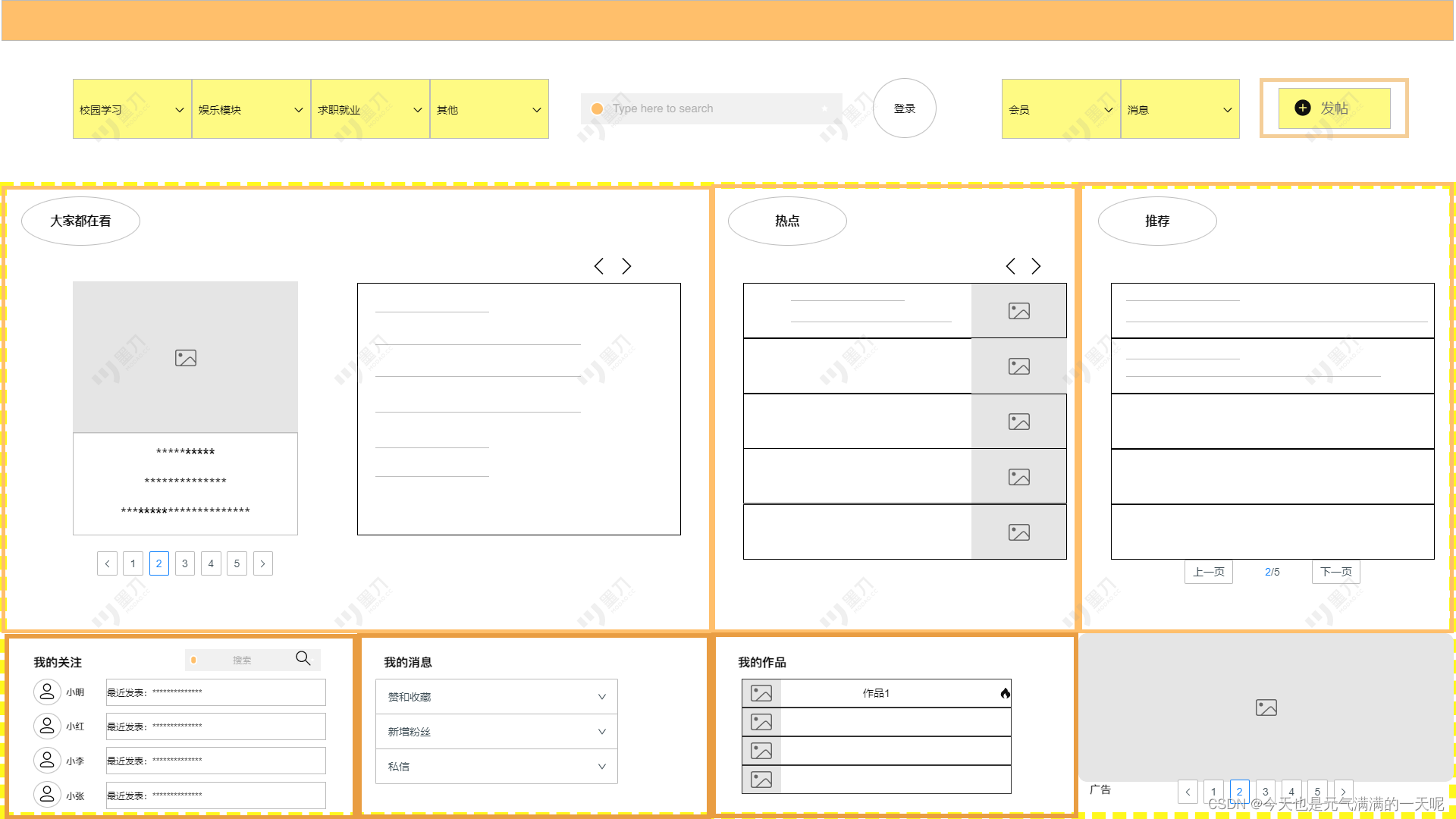
产品经理墨刀学习----注册页面
我们做的产品是一个校园论坛学习开发系统,目前才开始学习。 (一)流程图 (二)简单墨刀设计--注册页面 (1)有账号 (a)直接登录: (b)忘…...
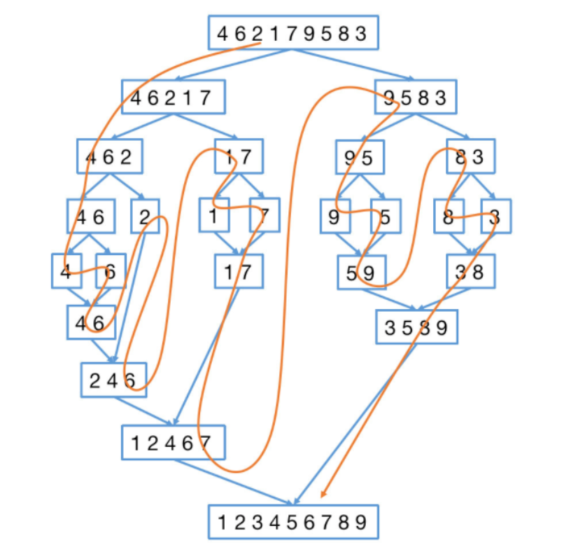
算法通关村——归并排序
归并排序 1、归并排序原理 归并排序是一种很经典的分治策略。 归并排序(MERGE-SORT)简单来说就是将大的序列先视为若干小的数组,分成几个比较小的结构,然后是利用归并的思想实现的排序方法。将一个大的问题分解成一些小的问题分别求解ÿ…...

如何高效批量下载音乐歌词:智能歌词管理完整指南
如何高效批量下载音乐歌词:智能歌词管理完整指南 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX ZonyLrcToolsX 是一款专业的跨平台歌词下载工具,…...

上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷?
更多请点击: https://intelliparadigm.com 第一章:上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷? 在软件交付生命周期末期,传统人工代码审计与通用SAST工具常因误报率高、上下文理解弱而漏检高危漏…...

科华UPS电源全品类汇总:选型与场景适配指南
科华UPS电源作为国内智慧电能领域的主流产品,覆盖家用、办公、机房、工业等全场景,产品系列丰富、规格齐全,但多数用户在选型时,常因分不清系列差异、功率适配、架构类型而踩坑。本文系统汇总科华UPS电源的核心分类、主流系列、核…...

Web渗透测试能力成长地图:从工具使用到漏洞认知跃迁
1. 这不是工具清单,而是一张Web渗透测试的“能力成长地图”你刚点开这篇文章,大概率正站在两个路口之间:一边是网上铺天盖地的“十大免费扫描器推荐”,点进去全是截图下载链接一句“一键扫漏洞”,结果装完跑两下&#…...
原理与ScalableHD架构优化实践)
超维计算(HDC)原理与ScalableHD架构优化实践
1. 超维计算(HDC)基础解析超维计算(Hyperdimensional Computing, HDC)是一种受大脑信息处理机制启发的计算范式,其核心思想是用高维随机向量(通常称为超向量或HV)来表示和处理信息。与传统神经网…...

在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型 开发代码辅助工具时,选择合适的模型是平衡效果与成本的关…...

用图神经网络做缺陷定位,准确率比传统方法高出30%
在现代软件工程的复杂迷宫中,缺陷定位始终是测试团队面临的核心挑战。想象这样一个场景:一个电商系统在特定压力条件下偶发订单丢失,日志中只留下泛泛的超时错误,问题可能深藏在上百个微服务的调用链、分布式事务的竞态条件或某个…...
)
别再纠结了!给激光焊接新手讲透单模和多模激光到底怎么选(附M²因子解读)
激光焊接设备选型指南:单模与多模激光的实战抉择 当你第一次站在激光焊接设备采购的十字路口,面对"单模"和"多模"这两个专业术语时,那种迷茫感我深有体会。五年前,我作为产线技术负责人,需要为汽车…...
到底怎么设?附场景实测)
Unity新手避坑指南:NavMesh烘焙参数(Agent Radius/Height)到底怎么设?附场景实测
Unity导航系统深度解析:Agent参数设置与场景适配实战在Unity游戏开发中,导航系统(Navigation System)是实现角色智能移动的核心模块。对于刚接触Unity导航系统的开发者来说,Agent Radius(代理半径)和Agent Height(代理身高)这两个参数的设置往…...

3步开启Windows 11安卓应用新体验:WSA完整使用指南
3步开启Windows 11安卓应用新体验:WSA完整使用指南 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA Windows Subsystem for Android(简…...