ClickHouse 面试题
文章目录
- 什么是 ClickHouse?
- ClickHouse 有哪些应用场景?
- ClickHouse 列式存储的优点有哪些?
- ClickHouse 的缺点是是什么?
- ClickHouse 的架构是怎样的?
- ClickHouse 的逻辑数据模型?
- ClickHouse 的核心特性?
- 使用 ClickHouse 时有哪些注意点?
- ClickHouse 的引擎有哪些?
- 建表引擎参数有哪些?
什么是 ClickHouse?
ClickHouse 是近年来备受关注的开源列式数据库管理系统,主要用于数据分析 (OLAP)领域。通过向量化执行以及对 cpu 底层指令集(SIMD)的使用,它 可以对海量数据进行并行处理,从而加快数据的处理速度。ClickHouse从 OLAP 场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序 存储、主键索引、稀疏索引、数据 Sharding、数据 Partitioning、TTL、主备复 制等丰富功能。
ClickHouse 有哪些应用场景?
- 绝大多数请求都是用于读访问的;
- 数据需要以大批次(大于 1000 行)进行更新,而不是单行更新;
- 数据只是添加到数据库,没有必要修改;
- 读取数据时,会从数据库中提取出大量的行,但只用到一小部分列;
- 表很“宽”,即表中包含大量的列;
- 查询频率相对较低(通常每台服务器每秒查询数百次或更少);
- 对于简单查询,允许大约 50 毫秒的延迟;
- 列的值是比较小的数值和短字符串(例如,每个 URL只有 60 个字节);
- 在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行);
- 不需要事务;
- 数据一致性要求较低;
- 每次查询中只会查询一个大表。除了一个大表,其余都是小表;
- 查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务 器内存。
ClickHouse 列式存储的优点有哪些?
- 当分析场景中往往需要读大量行但是少数几个列时,在行存模式下,数据按行连续存储,所有列的数据都存储在一个 block 中,不参与计算的列在 IO 时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计 算的列即可,极大的减低了 IO cost,加速了查询。
- 同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
- 更高的压缩比意味着更小的 data size,从磁盘中读取相应数据耗时更短。 - 自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
- 高压缩比,意味着同等大小的内存能够存放更多数据,系统 cache 效果更好。
ClickHouse 的缺点是是什么?
- 不支持事务,不支持真正的删除/更新; - 不支持二级索引;
- join 实现与众不同;
- 不支持窗口功能;
- 元数据管理需要人为干预。
ClickHouse 的架构是怎样的?
ClickHouse 采用典型的分组式的分布式架构,其中:
- Shard:集群内划分为多个分片或分组(Shard 0 … Shard N),通过 Shard
的线性扩展能力,支持海量数据的分布式存储计算。- Node:每个 Shard 内包含一定数量的节点(Node,即进程),同一 Shard 内的节点互为副本,保障数据可靠。ClickHouse 中副本数可按需建设,且逻辑上不同 Shard 内的副本数可不同。
- ZooKeeper Service:集群所有节点对等,节点间通过 ZooKeeper 服务进行分布式协调。
ClickHouse 的逻辑数据模型?
从用户使用⻆度看,ClickHouse 的逻辑数据模型与关系型数据库有一定的相似: 一个集群包含多个数据库,一个数据库包含多张表,表用于实际存储数据。
ClickHouse 的核心特性?
- 列存储:列存储是指仅从存储系统中读取必要的列数据,无用列不读取,速度非常快。ClickHouse 采用列存储,这对于分析型请求非常高效。一个典型 且真实的情况是,如果我们需要分析的数据有 50 列,而每次分析仅读取其 中的 5 列,那么通过列存储,我们仅需读取必要的列数据,相比于普通行存,可减少 10 倍左右的读取、解压、处理等开销,对性能会有质的影响。
- 向量化执行:在支持列存的基础上,ClickHouse 实现了一套面向 向量化处理 的计算引擎,大量的处理操作都是向量化执行的。相比于传统火山模型中 的逐行处理模式,向量化执行引擎采用批量处理模式,可以大幅减少函数调 用开销,降低指令、数据的 Cache Miss,提升 CPU 利用效率。并且ClickHouse可利用SIMD指令进一步加速执行效率 。 这部分是 ClickHouse 优于大量同类 OLAP 产品的重要因素。
- 编码压缩:由于 ClickHouse 采用列存储,相同列的数据连续存储,且底层数据在存储时是经过排序的,这样数据的局部规律性非常强,有利于获得更 高的数据压缩比。此外,ClickHouse除了支持 LZ### ZSTD 等通用压缩算 法外,还支持 Delta、DoubleDelta、Gorilla 等专用编码算法,用于进一步 提高数据压缩比。
- 多索引:列存用于裁剪不必要的字段读取,而索引则用于裁剪不必要的记录读取。ClickHouse 支持丰富的索引,从而在查询时尽可能的裁剪不必要的 记录读取,提高查询性能。
使用 ClickHouse 时有哪些注意点?
分区和索引
分区粒度根据业务特点决定,不宜过粗或过细。一般选择按天分区,也可指定为tuple();以单表 1 亿数据为例,分区大小控制在 10-30 个为最佳。
必须指定索引列,clickhouse 中的索引列即排序列,通过 order by 指定,一般 在查询条件中经常被用来充当筛选条件的属性被纳入进来;可以是单一维度,也 可以是组合维度的索引;通常需要满足高级列在前、查询频率大的在前原则;还 有基数特别大的不适合做索引列,如用户表的 userid 字段;通常筛选后的数据 满足在百万以内为最佳。
数据采样策略
通过采用运算可极大提升数据分析的性能。
数据量太大时应避免使用 select * 操作,查询的性能会与查询的字段大小和数 量成线性变换;字段越少,消耗的IO 资源就越少,性能就会越高。 千万以上数据集用 order by 查询时需要搭配 where 条件和 limit 语句一起使用。
如非必须不要在结果集上构建虚拟列,虚拟列非常消耗资源浪费性能,可以考虑 在前端进行处理,或者在表中构造实际字段进行额外存储。 不建议在高基列上执行 distinct 去重查询,改为近似去重 uniqCombined。 多表 Join 时要满足小表在右的原则,右表关联时被加载到内存中与左表进行比较。
存储
ClickHouse 不支持设置多数据目录,为了提升数据 一个券组绑定多块物理磁盘提升读写性能;多数查询场景 硬盘快 2-3 倍。
io 性能,可以挂载虚拟券组,
SSD 盘会比普通机械快
ClickHouse 的引擎有哪些?
ClickHouse 提供了大量的数据引擎,分为数据库引擎、表引擎,根据数据特点 及使用场景选择合适的引擎至关重要。
ClickHouse 引擎分类
在以下几种情况下,ClickHouse 使用自己的数据库引擎:
- 决定表存储在哪里以及以何种方式存储; - 支持哪些查询以及如何支持;
- 并发数据访问;
- 索引的使用;
- 是否可以执行多线程请求;
- 数据复制参数。
在所有的表引擎中,最为核心的当属 MergeTree 系列表引擎,这些表引擎拥有 最为强大的性能和最广泛的使用场合。对于非 MergeTree 系列的其他引擎而言, 主要用于特殊用途,场景相对有限。而 MergeTree 系列表引擎是官方主推的存储引擎,支持几乎所有 ClickHouse 核心功能。
MergeTree 作为家族系列最基础的表引擎,主要有以下特点:
- 存储的数据按照主键排序:允许创建稀疏索引,从而加快数据查询速度; - 支持分区,可以通过 PRIMARY KEY语句指定分区字段;
- 支持数据副本;
- 支持数据采样。
建表引擎参数有哪些?
ENGINE:ENGINE = MergeTree(),MergeTree 引擎没有参数。
ORDER BY:order by 设定了分区内的数据按照哪些字段顺序进行有序保存。
order by 是 MergeTree 中唯一一个必填项,甚至比 primary key 还重要,因 为当用户不设置主键的情况,很多处理会依照 order by 的字段进行处理。 要求:主键必须是 order by 字段的前缀字段。
如果 ORDER BY与 PRIMARY KEY不同,PRIMARY KEY必须是 ORDER BY的 前缀(为了保证分区内数据和主键的有序性)。
ORDER BY 决定了每个分区中数据的排序规则;
PRIMARY KEY 决定了一级索引(primary.idx);
ORDER BY 可以指代 PRIMARY KEY, 通常只用声明 ORDER BY 即可。
PARTITION BY:分区字段,可选。如果不填:只会使用一个分区。 分区目录:MergeTree 是以列文件+索引文件+表定义文件组成的,但是如果设 定了分区那么这些文件就会保存到不同的分区目录中。
PRIMARY KEY:指定主键,如果排序字段与主键不一致,可以单独指定主 键字段。否则默认主键是排序字段。可选。
SAMPLE BY:采样字段,如果指定了该字段,那么主键中也必须包含该字 段。比如 SAMPLE BY
intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID))。可选。
TTL:数据的存活时间。在 MergeTree 中,可以为某个列字段或整张表设置 TTL。当时间到达时,如果是列字段级别的 TTL,则会删除这一列的数据;如果 是表级别的 TTL,则会删除整张表的数据。可选。
SETTINGS:额外的参数配置。可选。
相关文章:

ClickHouse 面试题
文章目录 什么是 ClickHouse?ClickHouse 有哪些应用场景?ClickHouse 列式存储的优点有哪些?ClickHouse 的缺点是是什么?ClickHouse 的架构是怎样的?ClickHouse 的逻辑数据模型?ClickHouse 的核心特性&#…...

Python代码运行速度提升技巧!Python远比你想象中的快~
文章目录 前言一、使用内置函数二、字符串连接 VS join()三、创建列表和字典的方式四、使用 f-Strings五、使用Comprehensions六、附录- Python中的内置函数总结关于Python技术储备一、Python所有方向的学习路线二、Python基础学习视频三、精品Python学习书籍四、Python工具包项…...
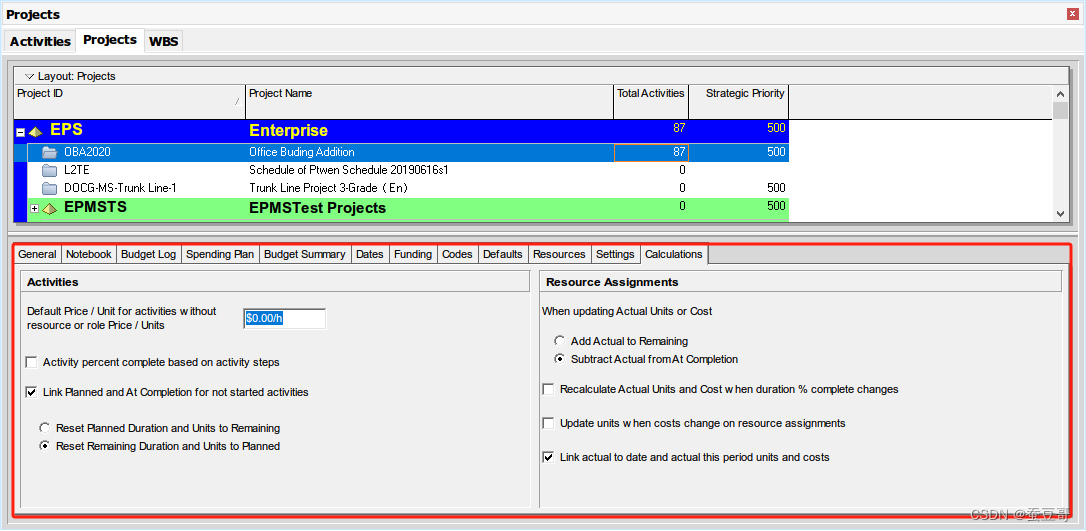
P6入门:项目初始化11-项目详情之计算Calculations
前言 使用项目详细信息查看和编辑有关所选项目的详细信息,在项目创建完成后,初始化项目是一项非常重要的工作,涉及需要设置的内容包括项目名,ID,责任人,日历,预算,资金,分类码等等&…...
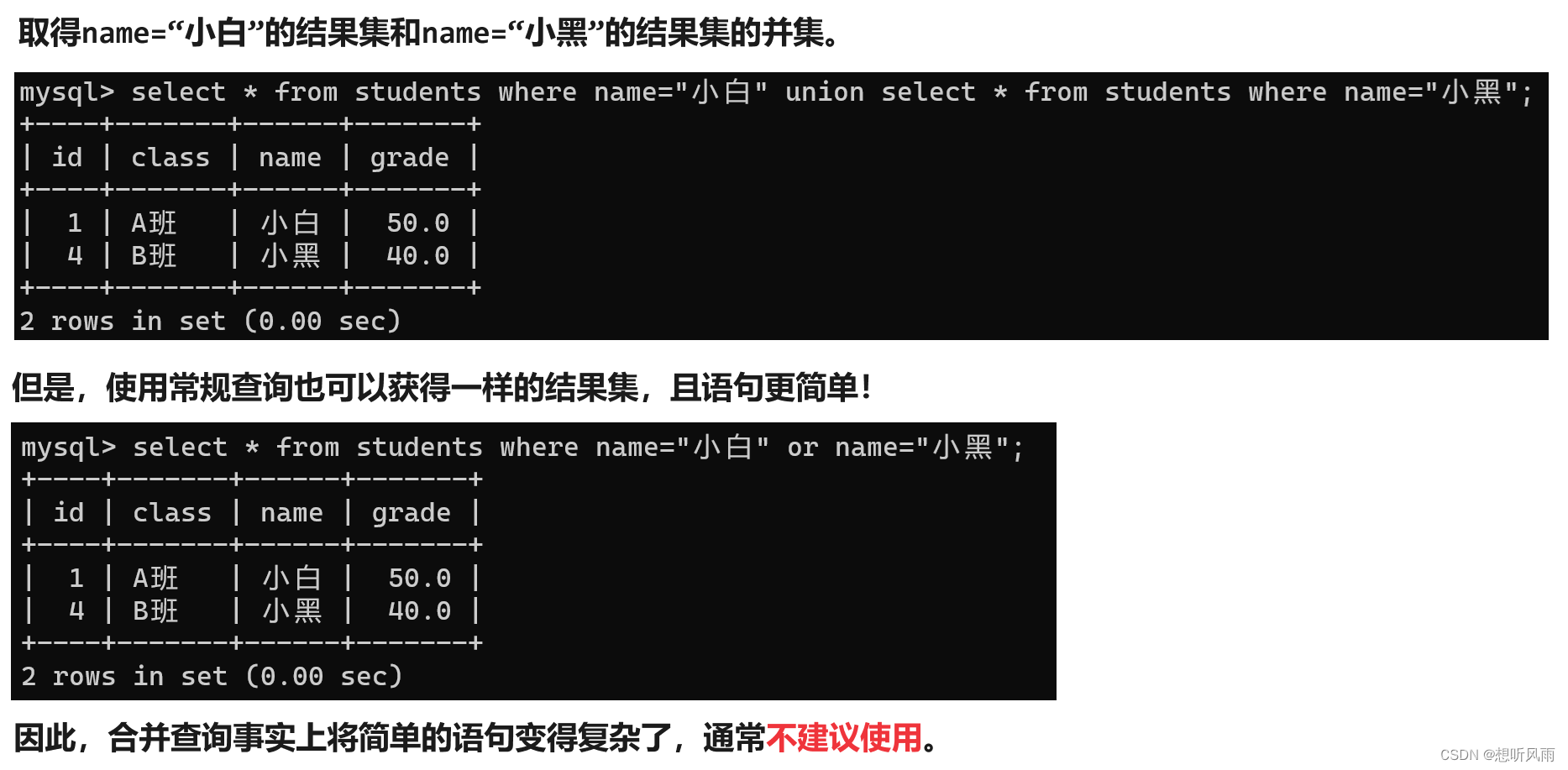
<MySQL> 查询数据进阶操作 -- 联合查询
目录 一、什么是笛卡尔积? 二、什么是联合查询? 三、内连接 3.1 简介 3.2 语法 3.3 更多的表 3.4 操作演示 四、外连接 4.1 简介 4.2 语法 4.3 操作演示 五、自连接 5.1 简介 5.2 自连接非必要不使用 六、子查询(嵌套查询) 6.1 简介 6.…...

centos 6.10 安装 svn1.14.2
安装 apr 和 apr-util 下载地址 我下载的分别是 apr-1.7.4 和 apr-unit-1.6.3 常规的安装步骤 ./configure --prefix/usr/local/xxx make && make install注意要先安装 apr 再安装 apr-unit-1.6.3 安装 lz4 下载地址 要配置好环境变量,不然可能还是找…...
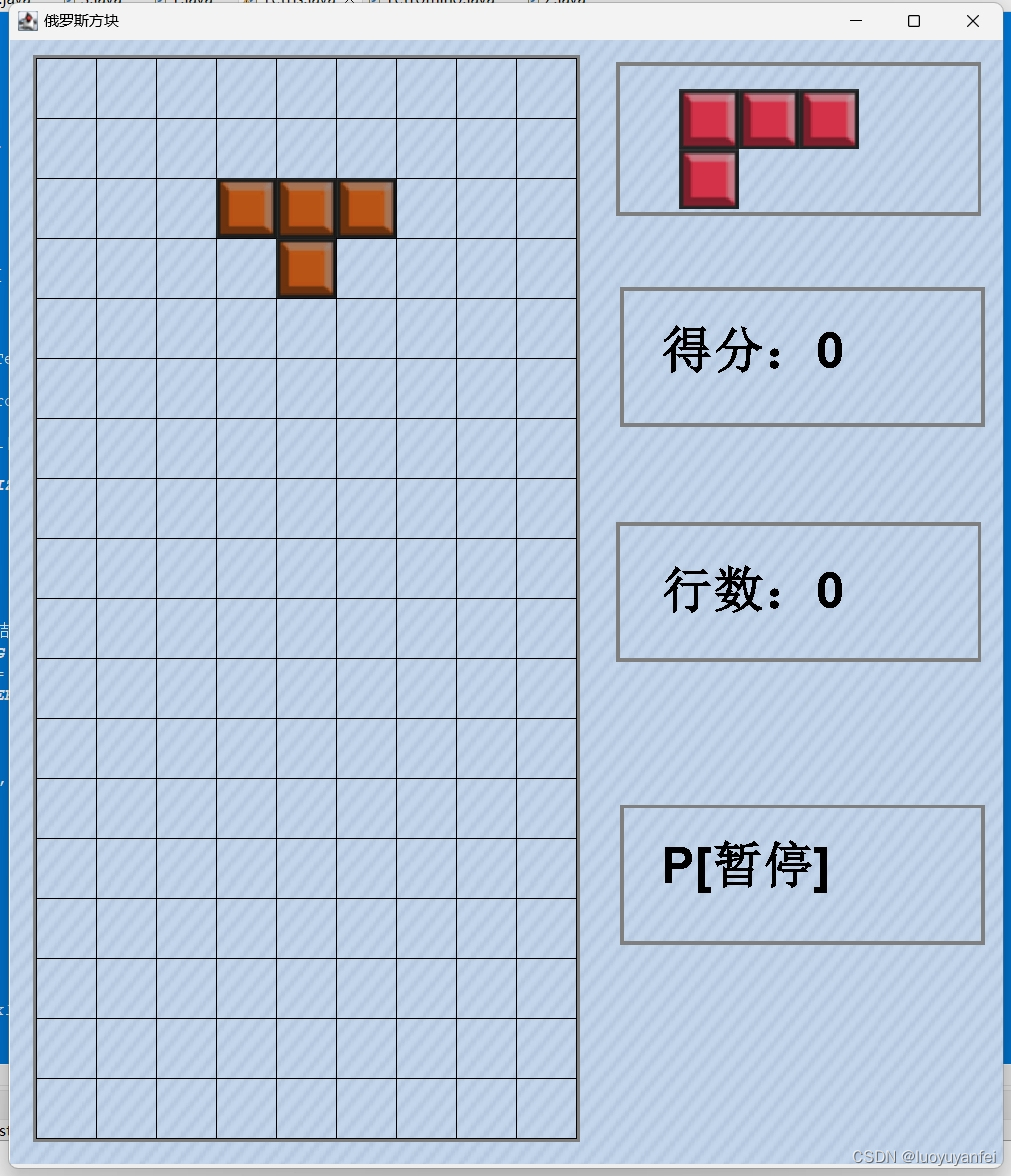
Java实现俄罗斯方块
规则 1.方块会从上方缓慢下落,玩家可以通过键盘上的上下左右键来控制方块。 2.方块移到区域最下方或是着地到其他方块上无法移动时,就会固定在该处,而新的方块出现在区域上方开始落下。 3.当区域中某一列横向格子全部由方块填满,…...

【计算思维】少儿编程蓝桥杯青少组计算思维题考试真题及解析B
STEMA考试-计算思维-U8级(样题) 1.浩浩的左⼿边是( )。 A.兰兰 B.⻉⻉ C.⻘⻘ D.浩浩 2.2时30分,钟⾯上时针和分针形成的⻆是什么⻆?( ) A.钝⻆ B.锐⻆ C.直⻆ D.平⻆ 3.下⾯是⼀年级同学最喜欢的《⻄游记》…...

第三章 栈和队列【24王道数据结构笔记】
1.栈 1.1 栈的基本概念 只允许在一端(栈顶top)进行插入或删除操作的受限的线性表。后进先出(Last In First Out)LIFO。或者说先进后出FILO。 进栈顺序:a1 > a2 > a3 > a4 > a5出栈顺序:a5 > a4 > a3 > a2 …...

保姆级教程之SABO-VMD-CNN-SVM的分类诊断,特征可视化
今天出一期基于SABO-VMD-CNN-SVM的分类诊断。 依旧是采用经典的西储大学轴承数据。基本流程如下: 首先是以最小包络熵为适应度函数,采用SABO优化VMD的两个参数。其次对每种状态的数据进行特征向量的求取,并为每组数据打上标签。然后将数据送入…...
)
跳跃游戏(贪心思想)
题解 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。 输入样例 示例 1…...

【JavaSE语法】类和对象(二)
六、 封装 6.1 封装的概念 面向对象程序三大特性:封装、继承、多态。而类和对象阶段,主要研究的就是封装特性。 封装:将数据和操作数据的方法进行有机结合,隐藏对象的属性和实现细节,仅对外公开接口来和对象进行交互…...
】121 - MAX9295A 加串器芯片手册分析 及初始化参数分析)
【SA8295P 源码分析 (三)】121 - MAX9295A 加串器芯片手册分析 及初始化参数分析
【SA8295P 源码分析】121 - MAX9295A 加串器芯片手册分析 及初始化参数分析 一、MAX9295A 芯片特性1.1 GPIO 引脚说明1.2 功能模块框图1.3 时序分析1.3.1 GMSL2 Lock Time:25 ms1.3.2 视频初始化延时:1.1ms + 17000 x t(PCLK)1.3.3 High-Speed Data Transmission in Bursts1.…...
Maya 2024 for Mac(3D建模软件)
Maya 2024是一款三维计算机图形软件,具有强大的建模、动画、渲染、特效等功能,广泛应用于影视、游戏、广告等行业。以下是Maya 2024软件的主要功能介绍: 建模:Maya 2024具有强大的建模工具,包括多边形建模、曲面建模、…...

9. 深度学习——GAN
机器学习面试题汇总与解析——GAN 本章讲解知识点 从 GAN 讲起本专栏适合于Python已经入门的学生或人士,有一定的编程基础。本专栏适合于算法工程师、机器学习、图像处理求职的学生或人士。本专栏针对面试题答案进行了优化,尽量做到好记、言简意赅。这才是一份面试题总结的正…...

BeanUtils中的copyProperties方法使用
一、Beanutils中的copyProperties是我们在日常开发中常用的一个方法。 作用: 将a实体类中的属性赋值到b实体类中相对于的字段上 1.我们前端传参的时候我们后端通常会用vo实体类来接收,但是更新数据库的时候需要用do去操作 2.我们将vo的属性copy到do中可…...

hivesql连续日期统计最大逾期/未逾期案例
1、虚表(测试表和数据) create test_table as select a.cust_no, a.r_date, a.yqts from ( select 123 as cust_no, 20231101 as r_date, 0 as yqts union all select 123 as cust_no, 20231102 as r_date, 1 as yqts union all select 123 as cust_no, 20231103 as r_d…...

基于STM32的无线通信系统设计与实现
【引言】 随着物联网的迅速发展,无线通信技术逐渐成为现代通信领域的关键技术之一。STM32作为一款广受欢迎的微控制器,具有丰富的外设资源和强大的计算能力,在无线通信系统设计中具有广泛的应用。本文将介绍如何基于STM32实现一个简单的无线通…...
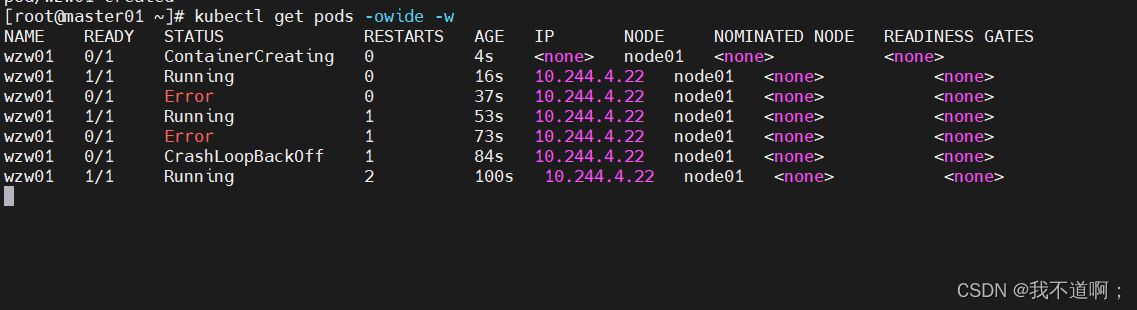
kubernetes--pod详解
目录 一、pod简介: 1. Pod基础概念: 2. Kubrenetes集群中Pod的两种使用方式: 3. pod资源中包含的容器: 4. pause容器的两个核心功能: 5. Kubernetes中使用pause容器概念的用意: 二、pod的分类࿱…...

WPF提供了哪些不同类型的画刷
在WPF中,画刷(Brush)用于填充图形对象(如形状、控件的背景和前景)的颜色和样式。WPF提供了几种不同类型的画刷: SolidColorBrush:这是最简单的画刷,它提供了一个单一的、固定的颜色。…...
STM32与ZigBee技术在智能家居无线通信中的应用研究
一、引言 智能家居系统是利用物联网技术将家庭各种设备进行互联互通,实现智能化控制和管理的系统。在智能家居系统中,无线通信技术起着至关重要的作用,而STM32微控制器和ZigBee技术则是实现智能家居无线通信的关键技术。本文将对STM32与ZigB…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

基于XGBoost与SHAP的分子气味预测:从特征工程到可解释性分析
1. 项目概述与核心价值在香水设计、食品风味工业乃至环境监测领域,一个核心且持久的挑战是:如何从分子的化学结构出发,准确预测其气味?这不仅仅是化学家或调香师的直觉游戏,更是一个复杂的、高维度的模式识别问题。传统…...
叶绿素(CHL)数据,版本 2022.0)
Sentinel-3B OLCI 3 级全球分箱地球观测降分辨率(ERR)叶绿素(CHL)数据,版本 2022.0
Sentinel-3B OLCI Level-3 Global Binned Earth-observation Reduced Resolution (ERR) Chlorophyll (CHL) Data, version 2022.0 简介 叶绿素 a 数据集提供全球网格化的表层叶绿素 a 浓度(浮游植物生物量的替代指标)合成数据。CHL 支持时间序列和气候…...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...

echarts中heatmap鼠标滚动禁用缩放,向下滚动
配置如下效果如下...

如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南
如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software developme…...

MongoDB Limit 与 Skip 方法详解
MongoDB Limit 与 Skip 方法详解 引言 MongoDB 是一个高性能、可伸缩的文档存储系统,它提供了强大的数据存储和查询功能。在处理大量数据时,Limit 与 Skip 方法是 MongoDB 中常用的查询优化工具。本文将详细介绍 MongoDB 中的 Limit 与 Skip 方法,包括其基本用法、性能影响…...

如何快速掌握Avidemux:新手完整入门指南与5个核心技巧
如何快速掌握Avidemux:新手完整入门指南与5个核心技巧 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款功能强大且完全开源的专业视频编辑工具,专为快速剪辑、…...

【DeepSeek漏洞扫描辅助实战指南】:20年安全专家亲授3大避坑法则与5步提效流程
更多请点击: https://intelliparadigm.com 第一章:DeepSeek漏洞扫描辅助的核心价值与适用边界 DeepSeek漏洞扫描辅助并非通用型渗透测试引擎,而是一个聚焦于大语言模型(LLM)应用层安全的轻量级分析工具。其核心价值在…...

从无线破解到PDF解密:盘点那些容易被忽略的‘非主流’密码审计场景与工具
密码安全审计的隐秘战场:从无线网络到加密文档的实战指南 当大多数人谈论密码安全时,脑海中浮现的往往是服务器登录、数据库访问这些企业级场景。然而在数字生活的每个角落,从家庭Wi-Fi到工作文档,密码保护的脆弱性同样可能成为安…...