2023年亚太杯APMCM数学建模大赛数据分析题MySQL的使用
2023年亚太杯APMCM数学建模大赛
以2022年C题全球变暖数据为例
数据分析:
以2022年亚太杯数学建模C题为例,首先在navicat建数据库然后右键“表”,单击“导入向导”,选择对应的数据格式及字符集进行数据导入
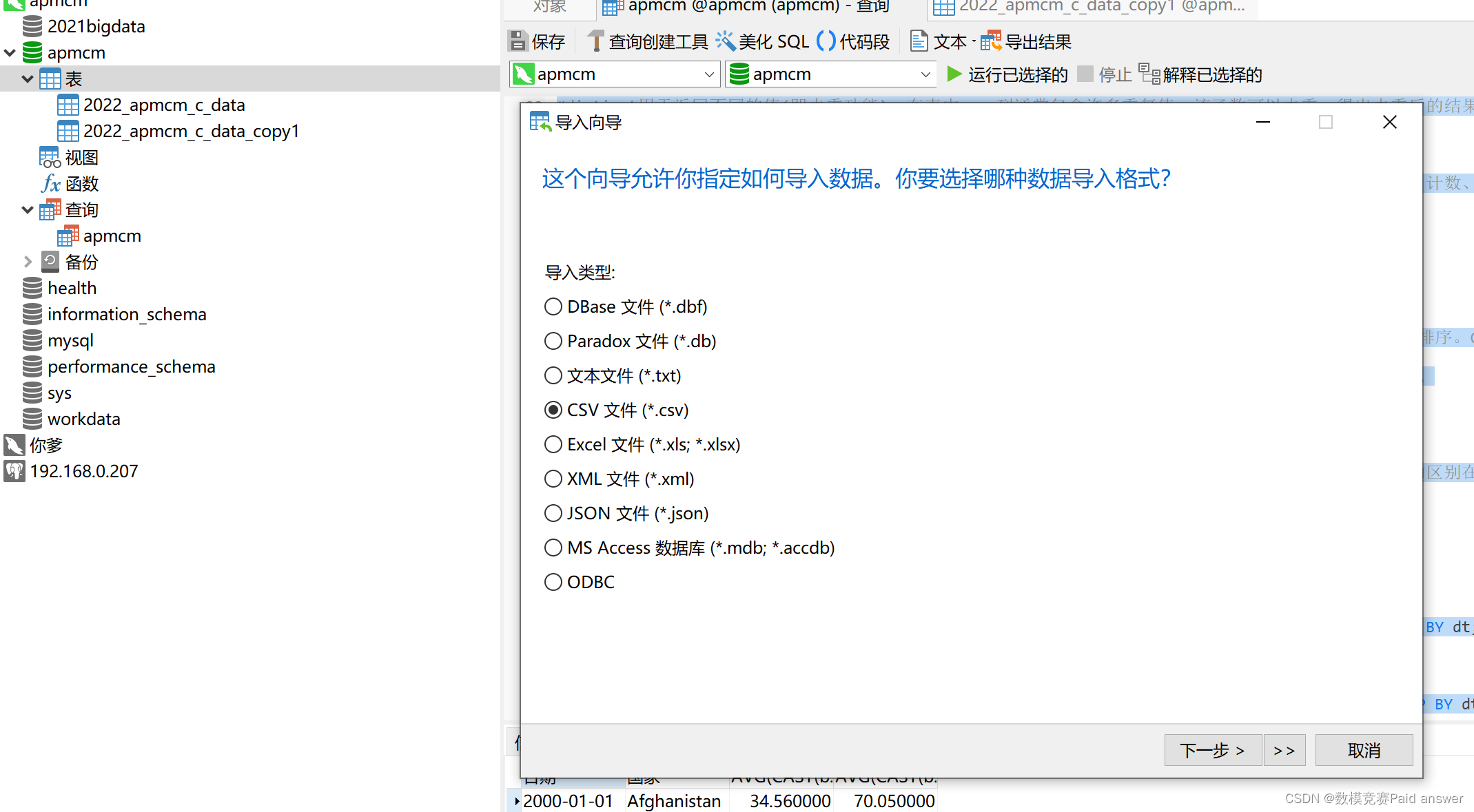
导入之后,我们可以双击刚刚导入的2022_apmcm_c_data表,查看一下数据情况。使用"ctrl"+"q"快捷键来新建SQL查询语言,结构化语言查询页面中会自动生成代码:select * from 2022_apmcm_c_data
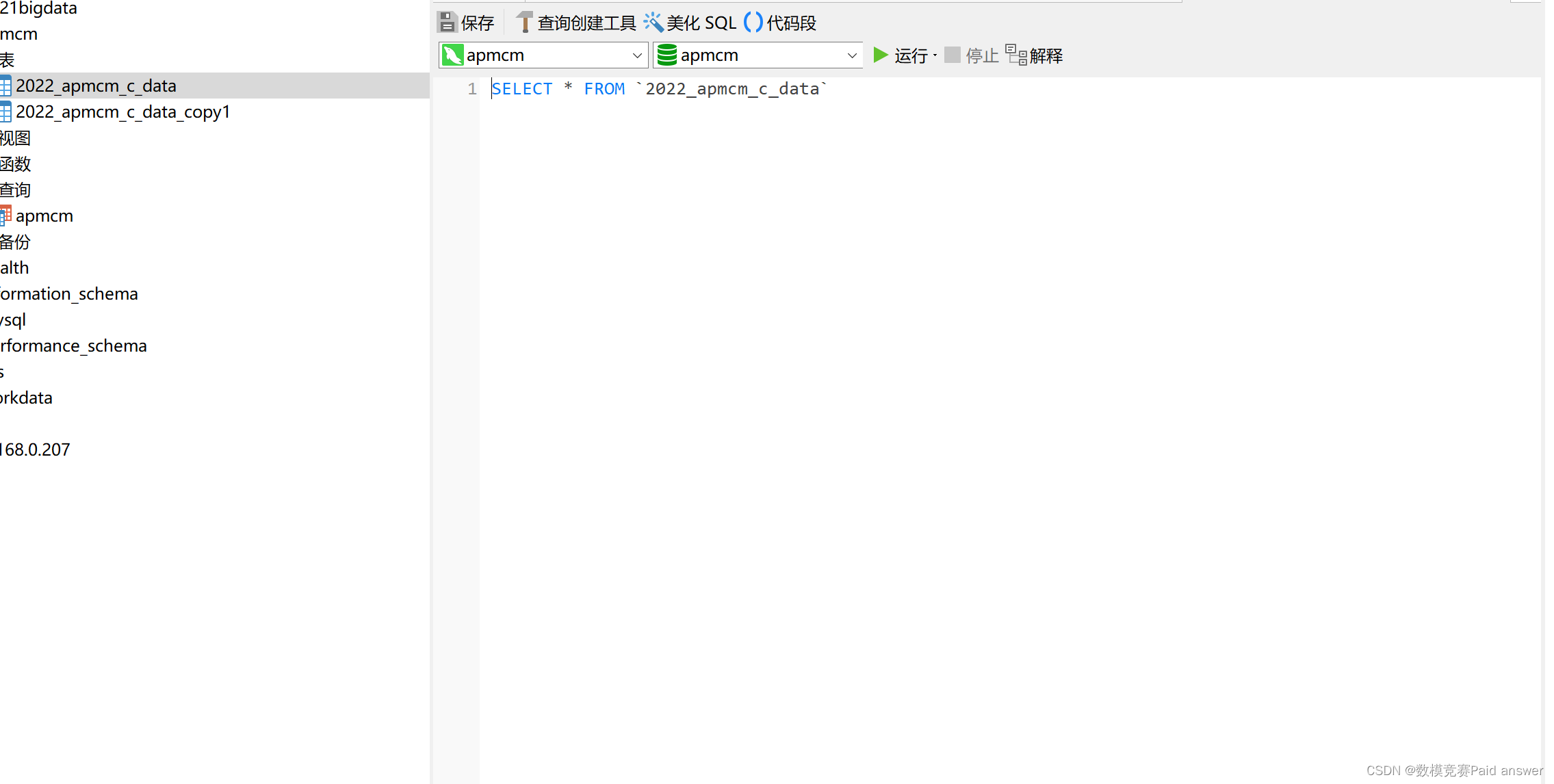
由于原数据条数太多,因此我们可以使用mysql中的limit函数简单查看表重所有字段的前100条数据情况。代码如下:
SELECT * FROM `2022_apmcm_c_data` limit 100;
你如果要是计算机专业,不会mysql,那你赶紧找个厂子上班得了;你如果不是计算机专业,没学过mysql我不说什么,不是说轻视,因为这个东西根本不用想,然后还有星号星号博主把mysql说的多么高大上,我今天毫无保留的把mysql这点破玩意都讲给你们。
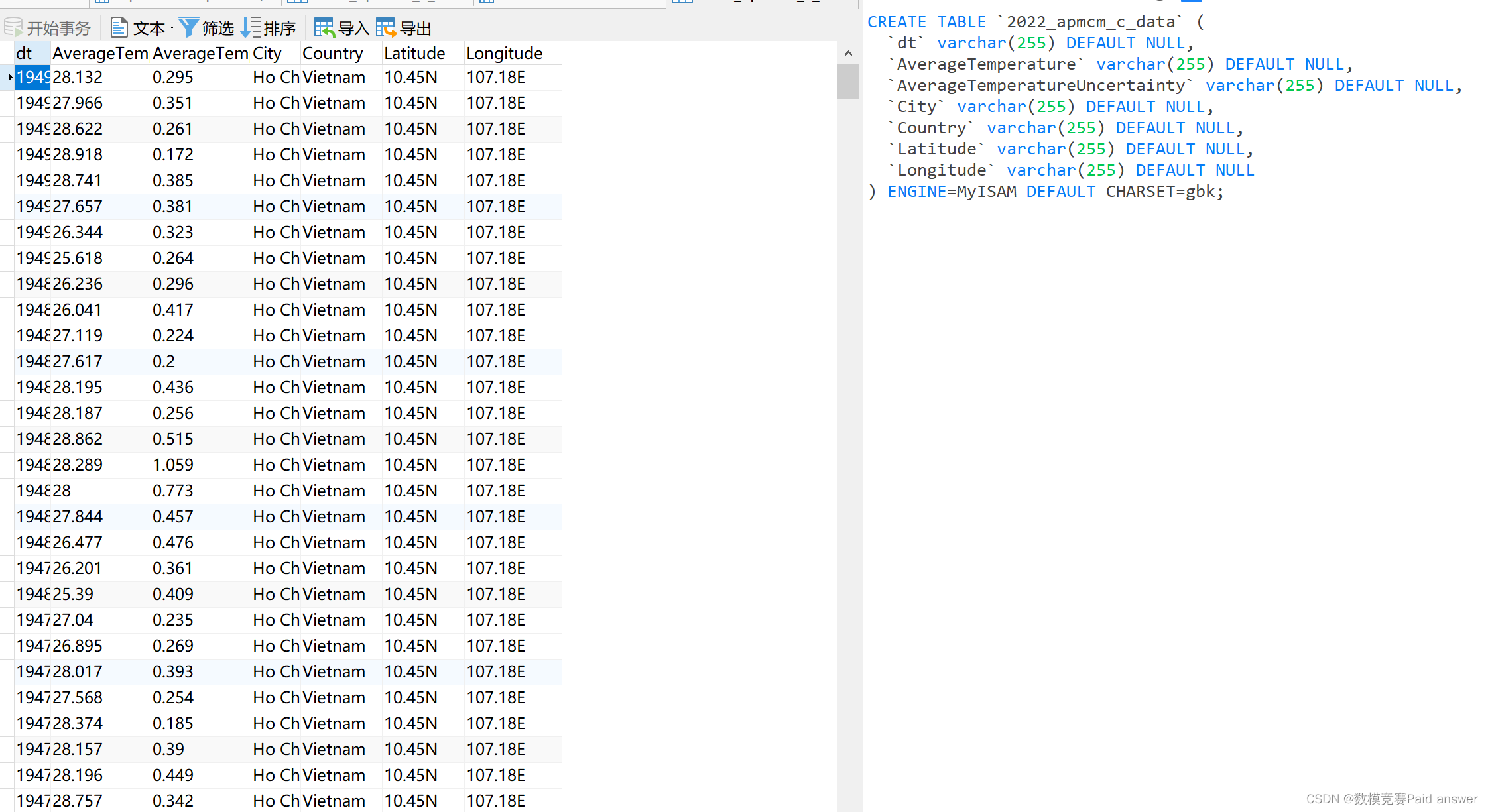
mysql也好还是oracle数据库也好,它本身最常用最实用的功能就是提供数据存储增删改查的,你tm有的星号星号博主说mysql是机器学习软件,你把读者都当作星号星号是么?它就是个结构化查询语言,别误导读者行么?对于在自己电脑安装mysql的学生,完全没有必要使用建表语句去建表,为什么呢?因为你在导入表之后,双击打开表之后,在表的右侧就会自动生成建表语句,而且这个表在你导入之后就自动建好了。
然后我再多说一嘴,你如果搭建数据库这个环境,完全没有必要在官网下载mysql,因为现在已经有了mysql环境集成程序包,就30MB,无须配置环境而且免费的,你如果安装官网mysql,不仅步骤繁琐,而且占空间太大。我就很好奇这事为啥没一个博主说呢?还是你们不会啊??我带**大学的拿研究生数学建模国奖的时候,你还在那“习莱克特”呢,你还支棱上了,还mysql数学建模,mysql根本做不了数学建模,严格意义上讲是pivot分析。
猪鼻子插葱都在这装象是吧,好,上菜
查看某张表的数据结构或所有列和列变量数据类型
DESCRIBE 2022_apmcm_c_data;
desc 2022_apmcm_c_data;
这两个函数用哪个都行 无所谓的 结果都是一样的
查看指定字段的表数据
select dt,AverageTemperature,Country from 2022_apmcm_c_data;
常用聚合计算函数教学
计算某一列(这里选用的是温度)数值变量之和
select sum(AverageTemperature) from 2022_apmcm_c_data;
请得出所给表中数据所有城市名称汇总
distinct用于返回不同的值(即去重功能)。在表中,一列通常包含许多重复值,该函数可以去重,得出去重后的结果。
select distinct City from 2022_apmcm_c_data;
计算不同国家下的数据条数
Group by是SQL语句中的一个重要操作,它可以将数据按照指定的列进行分组,并对每个分组进行聚合操作,如求和、计数、平均值等。
select Country,count(1) from 2022_apmcm_c_data group by Country;
计算不同国家不同时间下的数据条数
select dt,Country,count(1) from 2022_apmcm_c_data group by dt,Country;
计算不同国家不同时间下的温度之和
select dt,Country,sum(AverageTemperature) from 2022_apmcm_c_data
group by dt,Country;
计算不同国家不同时间下的温度之和并按照时间顺序进行排序
在SQL中,ORDER BY是一种用于对结果集进行排序的子句。它通常紧跟在SELECT语句之后,可以根据一个或多个列对结果集进行排序。ORDER BY子句可以使用升序(默认)或降序来排序数据。
select dt,Country,sum(AverageTemperature) from 2022_apmcm_c_data
group by dt,Country ORDER BY dt;
请给出2000年以来不同地区国家的最高气温数据透视表
where和having都可以实现字段条件的限制
在SQL语句中,WHERE子句用于筛选出符合特定条件的数据。
在SQL语句中,HAVING子句通常与GROUP BY子句一起使用来限制对分组后的结果集进行过滤。它和WHERE子句的区别在于:
1. HAVING子句用于过滤分组后的结果集,而WHERE子句用于过滤原始数据集。
2. HAVING子句只能在SELECT语句中使用,而WHERE子句可以在SELECT、UPDATE和DELETE语句中使用。
3. HAVING子句中可以使用聚合函数,而WHERE子句不可以使用聚合函数。
方法一 使用where和日期转化函数中的截取年功能YEAR函数
select dt,max(AverageTemperature) from 2022_apmcm_c_data
where YEAR(dt) >=2000 GROUP BY dt ORDER BY dt;
此方法虽然得到2000年以来不同地区国家的最高气温数据透视表,但是并未按照正确的时间顺序给出结果
因此我们稍作改动 使用日期转化函数from_unixtime
由于数据库中dt字段为char类型,因此需转换成日期类型
select dt,max(AverageTemperature) from 2022_apmcm_c_data
where from_unixtime(dt,'%Y-%m-%d') GROUP BY dt havingYEAR(dt) >=2000 ORDER BY dt;
select dt,max(AverageTemperature) from 2022_apmcm_c_data
where from_unixtime(CONVERT(dt,date),'%Y%m%d') GROUP BY
dt ORDER BY dt;
select dt,max(AverageTemperature) from 2022_apmcm_c_datawhere from_unixtime(cast(dt as date),'%Y%m%d') GROUP BY dt ORDER BY dt;
select dt,max(AverageTemperature) from 2022_apmcm_c_data
where DATE_FORMAT(CONVERT(dt,date),'%Y%m%d') GROUP BY dt ORDER BY dt;
select dt,max(AverageTemperature) from 2022_apmcm_c_data
where DATE_FORMAT(STR_TO_DATE(dt,'%Y-%m-%d'),'%Y%m%d')
GROUP BY dt ORDER BY dt;
数据格式检验
select DATE_FORMAT(STR_TO_DATE(dt,'%Y-%m-%d'),'%Y%m%d') from 2022_apmcm_c_data where dt is not null ORDER BY dt;
我虽然列出了这么多方法 但是结果不正确 为什么?因为导入数据时,数据格式不统一,这就造成了后续数据分析中较大的数据偏差
进行数据处理之后 我们再次导入数据
新导入的数据表为2022_apmcm_c_data_copy1
select dt,max(AverageTemperature) from 2022_apmcm_c_data_copy1
where from_unixtime(CONVERT(dt,date),'%Y%m%d') GROUP BY dt ORDER BY dt;
查完之后还是不正确,为什么呢?因为你导入数据的类型不对 温度这是数值数据
我们使用限定条件检查一下
select max(AverageTemperature) from 2022_apmcm_c_data_copy1
where dt='2013-01-01';
接着我们修改一下数据类型 因为varchar类型无法进行数值比较
这里可直接修改表结构或使用sql语言来改变表结构
注意 不能使用int类型,因为原温度数据带有小数点,应使用double类型
之后下一节我们会专门讲解alter的用法
ALTER TABLE 2022_apmcm_c_data_copy1 MODIFY AverageTemperature double;
接着我们再次检查一下
select max(AverageTemperature) from 2022_apmcm_c_data_copy1where dt='2013-01-01';
数据正常之后我们现在再来实现一下2000年以来不同地区国家的最高气温数据透视表功能
方法一
select dt,max(AverageTemperature) from 2022_apmcm_c_data_copy1
where from_unixtime(dt,'%Y-%m-%d') GROUP BY dt having YEAR(dt)>=2000 ORDER BY dt;
方法二
select dt,max(AverageTemperature) from 2022_apmcm_c_data_copy1
where DATE_FORMAT(STR_TO_DATE(dt,'%Y-%m-%d'),'%Y%m%d') >='20000101'GROUP BY dt ORDER BY dt;
这里方法太多了 我上述给出我最常用的两种
上述我们使用了日期函数,现在我这边教学一下字符串函数和聚合函数的简单综合运用
请计算2010年以来不同国家的平均地理位置(平均经纬度)
在mysql中,replace函数与SELECT语句配合使用时,可以用于进行字符串替换操作,同时也支持多个字符串同时被替换,语法为“SELECT REPLACE(数据库表的列名,需要替换的字符串,替换成的字符串)”。
在MySQL中,AVG函数用于计算某个字段的平均值。平均值是通过将数值求和然后除以总数得到的。
我们循序渐进的来教学
这里不使用update的原因就是不要改变原数据,因为改变之后或许还会用到经纬度的字符。
但是如果你有备份不嫌麻烦可以使用update,但更新有风险,检验需谨慎
sql嵌套子查询和函数的综合运用
1.先替换掉字段数据中的N和E字符
select dt as 日期,Country as 国家,replace(Latitude,'N','') as 纬度,
replace(Longitude,'E','') as 经度 from 2022_apmcm_c_data_copy1 where
from_unixtime(dt,'%Y-%m-%d') GROUP BY dt,Country,Latitude,Longitude
having YEAR(dt) >=2000 ORDER BY dt;
2.然后再替换掉数据中的S和W字符
select a.日期,a.国家,replace(a.纬度,'S','') as 纬度,replace(a.经度,'W','') as 经度
from(
select dt as 日期,Country as 国家,replace(Latitude,'N','') as 纬
度,replace(Longitude,'E','') as 经度 from 2022_apmcm_c_data_copy1 where
from_unixtime(dt,'%Y-%m-%d') GROUP BY dt,Country,Latitude,Longitude
having YEAR(dt) >=2000 ORDER BY dt)a;
3.1使用convert函数类型转化及均值函数计算
注意 这里转不了double类型 数据类型不懂的 看一下float double 和decimal的区别
float类型表示单精度浮点数值,double类型表示双精度浮点数值,float和double都是浮点型,而decimal是定点型;
MySQL 浮点型和定点型可以用类型名称后加(M,D)来表示,M表示该值的总共长度,D表示小数点后面的长度,M和D又称为精度和标度,如float(5,2)的 可显示为999.99,MySQL保存值时会进行四舍五入,如果插入999.009,则结果为999.01。
select b.日期,b.国家,AVG(CONVERT(b.纬度,DECIMAL(10,2))),
AVG(CONVERT(b.经度,DECIMAL(10,2))) from(
select a.日期,a.国家,replace(a.纬度,'S','') as 纬度,
replace(a.经度,'W','') as 经度 from(
select dt as 日期,Country as 国家,replace(Latitude,'N','')
as 纬度,replace(Longitude,'E','') as 经度 from 2022_apmcm_c_data_copy1where from_unixtime(dt,'%Y-%m-%d') GROUP BY dt,Country,Latitude,Longitude having YEAR(dt) >=2000 ORDER BY dt)a)b group by b.日期,b.国家;
3.2也可以使用cast函数类型转化及均值函数计算
cast功能测试
select CAST(AverageTemperature as decimal(8,2)) from 2022_apmcm_c_data_copy1;
select b.日期,b.国家,AVG(CAST(b.纬度 as decimal(9,2)))
,AVG(CAST(b.经度 as decimal(9,2))) from(
select a.日期,a.国家,replace(a.纬度,'S','')
as 纬度,replace(a.经度,'W','') as 经度 from(
select dt as 日期,Country as 国家,replace(Latitude,'N','')as 纬度,replace(Longitude,'E','') as 经度 from 2022_apmcm_c_data_copy1 where from_unixtime(dt,'%Y-%m-%d')GROUP BY dt,Country,Latitude,Longitude having YEAR(dt) >=2000 ORDER BY dt)a)b group by b.日期,b.国家;
下节课我们详细讲,MySQL中的where用法
相关文章:
2023年亚太杯APMCM数学建模大赛数据分析题MySQL的使用
2023年亚太杯APMCM数学建模大赛 以2022年C题全球变暖数据为例 数据分析: 以2022年亚太杯数学建模C题为例,首先在navicat建数据库然后右键“表”,单击“导入向导”,选择对应的数据格式及字符集进行数据导入 导入之后,…...

自学SLAM(8)《第四讲:相机模型与非线性优化》作业
前言 小编研究生的研究方向是视觉SLAM,目前在自学,本篇文章为初学高翔老师课的第四次作业。 文章目录 前言1.图像去畸变2.双目视差的使用3.矩阵微分4.高斯牛顿法的曲线拟合实验 1.图像去畸变 现实⽣活中的图像总存在畸变。原则上来说,针孔透…...

STL—next_permutation函数
目录 1.next_permutation函数的定义 2.简单使用 2.1普通数组全排列 2.2结构体全排列 2.3string 3.补充 1.next_permutation函数的定义 next_permutation函数会按照字母表顺序生成给定序列的下一个较大的排列,直到整个序列为降序为止。与其相对的还有一个函数—…...

Mysql 三种不使用索引的情况
目录 1. 查询语句中使用LIKE关键字 例 1 2. 查询语句中使用多列索引 例 2 3. 查询语句中使用OR关键字 例 3 总结 索引可以提高查询的速度,但并不是使用带有索引的字段查询时,索引都会起作用。使用索引有几种特殊情况,在这些情况下&…...

Ladybug 全景相机, 360°球形成像,带来全方位的视觉体验
360无死角全景照片总能给人带来强烈的视觉震撼,有着大片的既视感。那怎么才能拍出360球形照片呢?它的拍摄原理是通过图片某个点位为中心将图片其他部位螺旋式、旋转式处理,从而达到沉浸式体验的效果。俗话说“工欲善其事,必先利其…...

centos 6.10 安装swig 4.0.2
下载地址 解压文件。 执行下面命令 cd swig-4.0.2 ./configure --prefix/usr/local/swig-4.0.2 make && make install...

mask: rle, polygon
RLE 编码 RLE(Run-Length Encoding)是一种简单而有效的无损数据压缩和编码方法。它的基本思想是将连续相同的数据值序列用一个值和其连续出现的次数来表示,从而减少数据的存储或传输量。 在图像分割领域(如 COCO 数据集中&#…...

【JMeter】JMeter压测过程中遇到Non HTTP response code错误解决方案
压测过程中并发逐步加大后遇到60%的错误率,查看错误是JMeter网页版聚合报告中显示 Non HTTP response code: java.net.NoRouteToHostException/Non HTTP response message: Cannot assign requested address (Address not available) 这是第二次遇到,故…...

【Kingbase FlySync】评估工具安装及使用
【Kingbase FlySync】评估工具使用 概述准备环境目标资源1.测试虚拟机下载地址包含node1,node22.评估工具下载地址3.exam.sql下载地址 评估工具安装1.上传并解压评估工具安装包2.安装数据库驱动包3.设置环境变量4.node1载入样例信息 收集并阅读node1信息1.收集报告2.阅读报告 收…...

pandas教程:Data Aggregation 数据聚合
文章目录 10.2 Data Aggregation(数据聚合)1 Column-Wise and Multiple Function Application(列对列和多函数应用)2 Returning Aggregated Data Without Row Indexes(不使用行索引返回聚合数据) 10.2 Data…...

开启创造力之门:掌握Vue中Slot插槽的使用技巧与灵感
🎬 江城开朗的豌豆:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 📝 个人网站 :《 江城开朗的豌豆🫛 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 ⭐ 专栏简介 📘 文章引言 一、s…...

【算法练习Day48】回文子串最长回文子序列
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:练题 🎯长路漫漫浩浩,万事皆有期待 文章目录 回文子串最长回文子序列总结…...
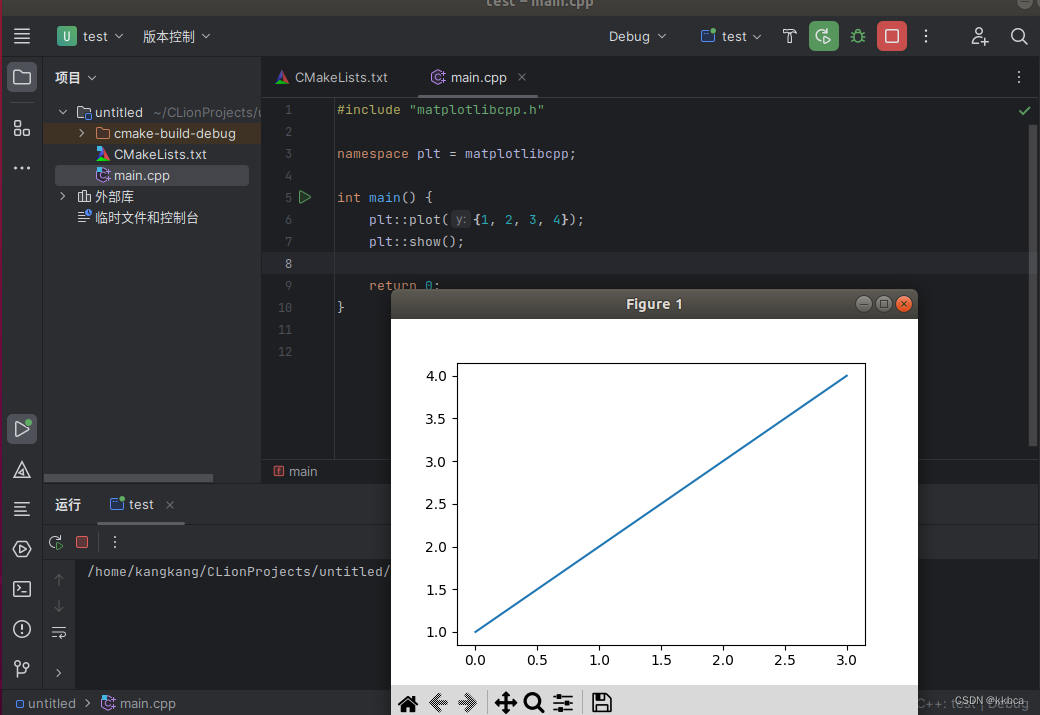
ubuntu下C++调用matplotlibcpp进行画图(超详细)
目录 一、换源 二、安装必要的软件 三、下载matplotlibcpp 四、下载anaconda 1.anaconda下载 2.使用anaconda配置环境 五、下载CLion 1.下载解压CLion 2.替换jbr文件夹 3.安装CLion 4.激活CLion 5.CLion汉化 6.Clion配置 六、使用CLion运行 七、总结 我的环…...

芯科科技推出新的8位MCU系列产品,扩展其强大的MCU平台
新的BB5系列为简单应用提供更多开发选择 中国,北京 - 2023年11月14日 – 致力于以安全、智能无线连接技术,建立更互联世界的全球领导厂商Silicon Labs(亦称“芯科科技”,NASDAQ:SLAB),今日宣布…...

Flink CDC
1、Flink CDC的介绍: 是一种技术,可以帮助我们实时的捕获数据库中数据的变化,并将这些变化的数据以流的形式传输到其他的系统中进行处理和存储。 2、Flink CDC的搭建: 1、开启mysql的binlog功能: # 1、修改mysql配置…...

数据结构-链表的简单操作代码实现3-LinkedList【Java版】
写在前: 本篇博客主要介绍关于双向链表的一些简答操作实现,其中有有部分代码的实现和前两篇博客中的单向链表是相类似的。例如:查找链表中是否包含关键字key、求链表的长度等。 其余的涉及到prev指向的需要特别注意,区分和单向链表之间的差异…...

JTS: 24 MinimumDiameter 最小矩形
文章目录 版本代码 版本 org.locationtech.jts:jts-core:1.19.0 链接: github 代码 package pers.stu.algorithm;import org.locationtech.jts.algorithm.MinimumDiameter; import org.locationtech.jts.geom.Coordinate; import org.locationtech.jts.geom.Geometry; import…...
MacOS Ventura 13 优化配置(ARM架构新手向导)
一、系统配置 1、About My MacBook Pro 2、在当前标签打开新窗口 桌面上创建目录的文件夹,每次新打开一个目录,就会创建一个窗口,这就造成窗口太多,不太好查看和管理,我们可以改成在新标签处打开新目录。需要在&…...
多区域OSPF配置
配置命令步骤: 1.使用router ospf 进程ID编号 启用OSPF路由 2.使用network 直连网络地址 反掩码 area 区域号 将其归于对应区域 注意: 1.进程ID编号可任意(1-65535) 2.反掩码用4个255相减得到 3.area 0 为主干区域 4.连接不…...

【强化学习】day1 强化学习基础、马尔可夫决策过程、表格型方法
写在最前:参加DataWhale十一月组队学习记录 【教程地址】 https://github.com/datawhalechina/joyrl-book https://datawhalechina.github.io/easy-rl/ https://linklearner.com/learn/detail/91 强化学习 强化学习是一种重要的机器学习方法,它使得智能…...

AI智能体架构设计:从成本黑洞到价值引擎的解耦之道
1. 从成本黑洞到价值引擎:为什么你的AI智能体架构正在吞噬预算又到了季度技术复盘会,财务那边递过来的云账单和工程人力成本,是不是又让你倒吸一口凉气?你看着报表上那个名为“AI智能体平台”的项目,它的资源消耗曲线几…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...

雪球网md5__1038参数逆向解析与Node.js复现
1. 这不是“破解”,而是对前端加密逻辑的常规逆向还原你打开雪球网任意一只股票详情页,F12 打开开发者工具,切到 Network 面板,刷新页面——很快就能在 XHR 请求里捕获到类似这样的接口:https://xueqiu.com/stock/cube…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...

LizzieYzy:你的智能围棋教练,让AI分析变得简单有趣 [特殊字符]
LizzieYzy:你的智能围棋教练,让AI分析变得简单有趣 🎯 【免费下载链接】lizzieyzy LizzieYzy - GUI for Game of Go 项目地址: https://gitcode.com/gh_mirrors/li/lizzieyzy 还在为复盘找不到关键点而烦恼吗?想提升棋力却…...

淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理
淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taoji…...

告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南
告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南第一次点击"打包项目"按钮时,进度条仿佛被冻结的场景,每个UE5开发者都经历过。尤其当项目规模达到数十GB时,等待时间可能超过一小时——这背后隐藏着引擎底…...

AhMyth位置跟踪:GPS定位与地理围栏技术深度解析
AhMyth位置跟踪:GPS定位与地理围栏技术深度解析 【免费下载链接】AhMyth Cross-Platform Android Remote Administration Tool | The only maintained version of AhMyth on github | A revival of the original repository at https://GitHub.com/AhMyth/AhMyth-An…...

8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由
8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移…...

Linux 负载均衡的 cache_nice_tries:缓存友好的迁移尝试
简介现如今服务器、嵌入式设备、工控主板普遍采用多核、NUMA 架构 CPU,多进程多线程并发运行模式成为常态。Linux 内核依靠调度域分层负载均衡机制,分散 CPU 运行压力,避免单核心负载过高、其余核心空闲浪费硬件算力。但任务跨核心迁移是一把…...