pandas教程:Data Aggregation 数据聚合
文章目录
- 10.2 Data Aggregation(数据聚合)
- 1 Column-Wise and Multiple Function Application(列对列和多函数应用)
- 2 Returning Aggregated Data Without Row Indexes(不使用行索引返回聚合数据)
10.2 Data Aggregation(数据聚合)
聚合(Aggregation)指的是一些数据转化(data transformation),这些数据转化能从数组中产生标量(scalar values)。下面的例子就是一些聚合方法,包括mean, count, min and sum。我们可能会好奇,在一个GroupBy对象上调用mean()的时候,究竟发生了什么。一些常见的聚合,比如下表,实现方法上都已经被优化过了。当然,我们可以使用的聚合方法不止这些:
我们可以使用自己设计的聚合方法,而且可以调用分组后对象上的任意方法。例如,我们可以调用quantile来计算Series或DataFrame中列的样本的百分数。
尽管quantile并不是专门为GroupBy对象设计的方法,这是一个Series方法,但仍可以被GroupBy对象使用。GroupBy会对Series进行切片(slice up),并对于切片后的每一部分调用piece.quantile(0.9),然后把每部分的结果整合到一起:
import numpy as np
import pandas as pd
df = pd.DataFrame({'key1' : ['a', 'a', 'b', 'b', 'a'],'key2' : ['one', 'two', 'one', 'two', 'one'], 'data1' : np.random.randn(5), 'data2' : np.random.randn(5)})
df
| data1 | data2 | key1 | key2 | |
|---|---|---|---|---|
| 0 | 1.707738 | 0.186729 | a | one |
| 1 | 1.069831 | 1.305796 | a | two |
| 2 | -2.291339 | -1.609071 | b | one |
| 3 | 1.348090 | -0.294999 | b | two |
| 4 | 0.341176 | 0.429461 | a | one |
grouped = df.groupby('key1')
for key, group in grouped:print(key)print(group)
adata1 data2 key1 key2
0 1.707738 0.186729 a one
1 1.069831 1.305796 a two
4 0.341176 0.429461 a one
bdata1 data2 key1 key2
2 -2.291339 -1.609071 b one
3 1.348090 -0.294999 b two
grouped['data1'].quantile(0.9)
key1
a 1.580157
b 0.984147
Name: data1, dtype: float64
如果想用自己设计的聚合函数,把用于聚合数组的函数传入到aggregate或agg方法即可:
def peak_to_peak(arr):return arr.max() - arr.min()
grouped.agg(peak_to_peak)
| data1 | data2 | |
|---|---|---|
| key1 | ||
| a | 1.366563 | 1.119067 |
| b | 3.639430 | 1.314072 |
我们发现很多方法,比如describe,也能正常使用,尽管严格的来说,这并不是聚合:
grouped.describe()
| data1 | data2 | ||
|---|---|---|---|
| key1 | |||
| a | count | 3.000000 | 3.000000 |
| mean | 1.039582 | 0.640662 | |
| std | 0.683783 | 0.588670 | |
| min | 0.341176 | 0.186729 | |
| 25% | 0.705503 | 0.308095 | |
| 50% | 1.069831 | 0.429461 | |
| 75% | 1.388785 | 0.867629 | |
| max | 1.707738 | 1.305796 | |
| b | count | 2.000000 | 2.000000 |
| mean | -0.471624 | -0.952035 | |
| std | 2.573465 | 0.929189 | |
| min | -2.291339 | -1.609071 | |
| 25% | -1.381482 | -1.280553 | |
| 50% | -0.471624 | -0.952035 | |
| 75% | 0.438233 | -0.623517 | |
| max | 1.348090 | -0.294999 |
细节的部分在10.3会进行更多解释。
注意:自定义的函数会比上面表中的函数慢一些,上面的函数时优化过的,而自定义的函数会有一些额外的计算,所以慢一些。
1 Column-Wise and Multiple Function Application(列对列和多函数应用)
让我们回到tipping数据集。加载数据及后,我们添加一列用于描述小费的百分比:
tips = pd.read_csv('../examples/tips.csv')
# Add tip percentage of total bill
tips['tip_pct'] = tips['tip'] / tips['total_bill']
tips[:6]
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 | 0.059447 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 | 0.160542 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 | 0.166587 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 | 0.139780 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 | 0.146808 |
| 5 | 25.29 | 4.71 | No | Sun | Dinner | 4 | 0.186240 |
我们可以看到,对series或DataFrame进行聚合,其实就是通过aggregate使用合适的函数,或者调用一些像mean或std这样的方法。然而,我们可能想要在列上使用不同的函数进行聚合,又或者想要一次执行多个函数。幸运的是,这是可能的,下面将通过一些例子来说明。首先,对于tips数据集,先用day和smoker进行分组:
grouped = tips.groupby(['day', 'smoker'])
对于像是上面表格10-1中的一些描述性统计,我们可以直接传入函数的名字,即字符串:
grouped_pct = grouped['tip_pct']
for name, group in grouped_pct:print(name)print(group[:2], '\n')
('Fri', 'No')
91 0.155625
94 0.142857
Name: tip_pct, dtype: float64 ('Fri', 'Yes')
90 0.103555
92 0.173913
Name: tip_pct, dtype: float64 ('Sat', 'No')
19 0.162228
20 0.227679
Name: tip_pct, dtype: float64 ('Sat', 'Yes')
56 0.078927
58 0.156584
Name: tip_pct, dtype: float64 ('Sun', 'No')
0 0.059447
1 0.160542
Name: tip_pct, dtype: float64 ('Sun', 'Yes')
164 0.171331
172 0.710345
Name: tip_pct, dtype: float64 ('Thur', 'No')
77 0.147059
78 0.131810
Name: tip_pct, dtype: float64 ('Thur', 'Yes')
80 0.154321
83 0.152999
Name: tip_pct, dtype: float64
grouped_pct.agg('mean')
day smoker
Fri No 0.151650Yes 0.174783
Sat No 0.158048Yes 0.147906
Sun No 0.160113Yes 0.187250
Thur No 0.160298Yes 0.163863
Name: tip_pct, dtype: float64
如果我们把函数或函数的名字作为一个list传入,我们会得到一个DataFrame,每列的名字就是函数的名字:
# def peak_to_peak(arr):
# return arr.max() - arr.min()
grouped_pct.agg(['mean', 'std', peak_to_peak])
| mean | std | peak_to_peak | ||
|---|---|---|---|---|
| day | smoker | |||
| Fri | No | 0.151650 | 0.028123 | 0.067349 |
| Yes | 0.174783 | 0.051293 | 0.159925 | |
| Sat | No | 0.158048 | 0.039767 | 0.235193 |
| Yes | 0.147906 | 0.061375 | 0.290095 | |
| Sun | No | 0.160113 | 0.042347 | 0.193226 |
| Yes | 0.187250 | 0.154134 | 0.644685 | |
| Thur | No | 0.160298 | 0.038774 | 0.193350 |
| Yes | 0.163863 | 0.039389 | 0.151240 |
上面我们把多个聚合函数作为一个list传入给agg,这些函数会独立对每一个组进行计算。
上面结果的列名是自动给出的,当然,我们也可以更改这些列名。这种情况下,传入一个由tuple组成的list,每个tuple的格式是(name, function),每个元组的第一个元素会被用于作为DataFrame的列名(我们可以认为这个二元元组list是一个有序的映射):
grouped_pct.agg([('foo', 'mean'), ('bar', np.std)])
| foo | bar | ||
|---|---|---|---|
| day | smoker | ||
| Fri | No | 0.151650 | 0.028123 |
| Yes | 0.174783 | 0.051293 | |
| Sat | No | 0.158048 | 0.039767 |
| Yes | 0.147906 | 0.061375 | |
| Sun | No | 0.160113 | 0.042347 |
| Yes | 0.187250 | 0.154134 | |
| Thur | No | 0.160298 | 0.038774 |
| Yes | 0.163863 | 0.039389 |
如果是处理一个DataFrame,我们有更多的选择,我们可以用一个含有多个函数的list应用到所有的列上,也可以在不同的列上应用不同的函数。演示一下,假设我们想要在tip_pct和total_bill这两列上,计算三个相同的统计指标:
functions = ['count', 'mean', 'max']
result = grouped['tip_pct', 'total_bill'].agg(functions)
result
| tip_pct | total_bill | ||||||
|---|---|---|---|---|---|---|---|
| count | mean | max | count | mean | max | ||
| day | smoker | ||||||
| Fri | No | 4 | 0.151650 | 0.187735 | 4 | 18.420000 | 22.75 |
| Yes | 15 | 0.174783 | 0.263480 | 15 | 16.813333 | 40.17 | |
| Sat | No | 45 | 0.158048 | 0.291990 | 45 | 19.661778 | 48.33 |
| Yes | 42 | 0.147906 | 0.325733 | 42 | 21.276667 | 50.81 | |
| Sun | No | 57 | 0.160113 | 0.252672 | 57 | 20.506667 | 48.17 |
| Yes | 19 | 0.187250 | 0.710345 | 19 | 24.120000 | 45.35 | |
| Thur | No | 45 | 0.160298 | 0.266312 | 45 | 17.113111 | 41.19 |
| Yes | 17 | 0.163863 | 0.241255 | 17 | 19.190588 | 43.11 | |
我们可以看到,结果中的DataFrame有多层级的列(hierarchical columns)。另外一种做法有相同的效果,即我们对于每一列单独进行聚合(aggregating each column separately),然后使用concat把结果都结合在一起,然后用列名作为keys参数:
result['tip_pct']
| count | mean | max | ||
|---|---|---|---|---|
| day | smoker | |||
| Fri | No | 4 | 0.151650 | 0.187735 |
| Yes | 15 | 0.174783 | 0.263480 | |
| Sat | No | 45 | 0.158048 | 0.291990 |
| Yes | 42 | 0.147906 | 0.325733 | |
| Sun | No | 57 | 0.160113 | 0.252672 |
| Yes | 19 | 0.187250 | 0.710345 | |
| Thur | No | 45 | 0.160298 | 0.266312 |
| Yes | 17 | 0.163863 | 0.241255 |
我们之前提到过,可以用元组组成的list来自己定义列名:
ftuples = [('Durchschnitt', 'mean'), ('Abweichung', np.var)]
grouped['tip_pct', 'total_bill'].agg(ftuples)
| tip_pct | total_bill | ||||
|---|---|---|---|---|---|
| Durchschnitt | Abweichung | Durchschnitt | Abweichung | ||
| day | smoker | ||||
| Fri | No | 0.151650 | 0.000791 | 18.420000 | 25.596333 |
| Yes | 0.174783 | 0.002631 | 16.813333 | 82.562438 | |
| Sat | No | 0.158048 | 0.001581 | 19.661778 | 79.908965 |
| Yes | 0.147906 | 0.003767 | 21.276667 | 101.387535 | |
| Sun | No | 0.160113 | 0.001793 | 20.506667 | 66.099980 |
| Yes | 0.187250 | 0.023757 | 24.120000 | 109.046044 | |
| Thur | No | 0.160298 | 0.001503 | 17.113111 | 59.625081 |
| Yes | 0.163863 | 0.001551 | 19.190588 | 69.808518 | |
现在,假设我们想要把不同的函数用到一列或多列上。要做到这一点,给agg传递一个dict,这个dict需要包含映射关系,用来表示列名和函数之间的对应关系:
grouped.agg({'tip': np.max, 'size': 'sum'})
| tip | size | ||
|---|---|---|---|
| day | smoker | ||
| Fri | No | 3.50 | 9 |
| Yes | 4.73 | 31 | |
| Sat | No | 9.00 | 115 |
| Yes | 10.00 | 104 | |
| Sun | No | 6.00 | 167 |
| Yes | 6.50 | 49 | |
| Thur | No | 6.70 | 112 |
| Yes | 5.00 | 40 |
grouped.agg({'tip_pct': ['min', 'max', 'mean', 'std'],'size': 'sum'})
| tip_pct | size | |||||
|---|---|---|---|---|---|---|
| min | max | mean | std | sum | ||
| day | smoker | |||||
| Fri | No | 0.120385 | 0.187735 | 0.151650 | 0.028123 | 9 |
| Yes | 0.103555 | 0.263480 | 0.174783 | 0.051293 | 31 | |
| Sat | No | 0.056797 | 0.291990 | 0.158048 | 0.039767 | 115 |
| Yes | 0.035638 | 0.325733 | 0.147906 | 0.061375 | 104 | |
| Sun | No | 0.059447 | 0.252672 | 0.160113 | 0.042347 | 167 |
| Yes | 0.065660 | 0.710345 | 0.187250 | 0.154134 | 49 | |
| Thur | No | 0.072961 | 0.266312 | 0.160298 | 0.038774 | 112 |
| Yes | 0.090014 | 0.241255 | 0.163863 | 0.039389 | 40 | |
只有当多个函数用于至少一列的时候,DataFrame才会有多层级列(hierarchical columns)
2 Returning Aggregated Data Without Row Indexes(不使用行索引返回聚合数据)
目前为止提到的所有例子,最后返回的聚合数据都是有索引的,而且这个索引默认是多层级索引,这个索引是由不同的组键的组合构成的(unique group key combinations)。因为我们并不是总需要返回这种索引,所以我们可以取消这种模式,在调用groupby的时候设定as_index=False即可:
tips.groupby(['day', 'smoker'], as_index=False).mean()
| day | smoker | total_bill | tip | size | tip_pct | |
|---|---|---|---|---|---|---|
| 0 | Fri | No | 18.420000 | 2.812500 | 2.250000 | 0.151650 |
| 1 | Fri | Yes | 16.813333 | 2.714000 | 2.066667 | 0.174783 |
| 2 | Sat | No | 19.661778 | 3.102889 | 2.555556 | 0.158048 |
| 3 | Sat | Yes | 21.276667 | 2.875476 | 2.476190 | 0.147906 |
| 4 | Sun | No | 20.506667 | 3.167895 | 2.929825 | 0.160113 |
| 5 | Sun | Yes | 24.120000 | 3.516842 | 2.578947 | 0.187250 |
| 6 | Thur | No | 17.113111 | 2.673778 | 2.488889 | 0.160298 |
| 7 | Thur | Yes | 19.190588 | 3.030000 | 2.352941 | 0.163863 |
当然,我们也可以在上面的结果上直接调用reset_index,这样的话就能得到之前那种多层级索引的结果。不过使用as_index=False方法可以避免一些不必要的计算。
相关文章:

pandas教程:Data Aggregation 数据聚合
文章目录 10.2 Data Aggregation(数据聚合)1 Column-Wise and Multiple Function Application(列对列和多函数应用)2 Returning Aggregated Data Without Row Indexes(不使用行索引返回聚合数据) 10.2 Data…...

开启创造力之门:掌握Vue中Slot插槽的使用技巧与灵感
🎬 江城开朗的豌豆:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 📝 个人网站 :《 江城开朗的豌豆🫛 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 ⭐ 专栏简介 📘 文章引言 一、s…...

【算法练习Day48】回文子串最长回文子序列
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:练题 🎯长路漫漫浩浩,万事皆有期待 文章目录 回文子串最长回文子序列总结…...
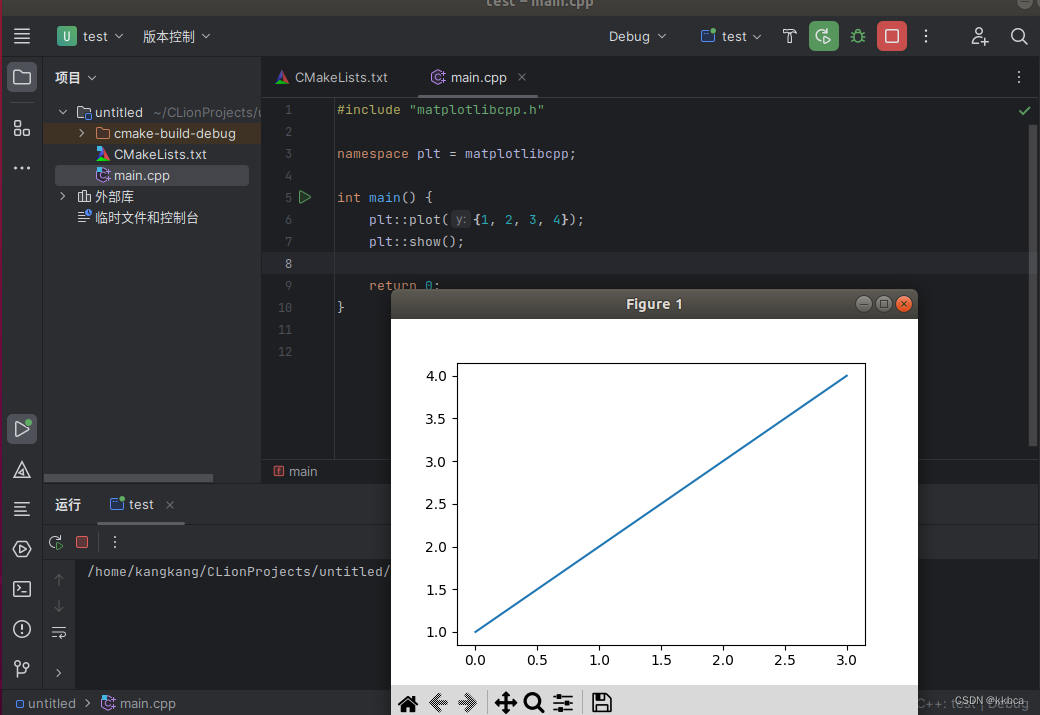
ubuntu下C++调用matplotlibcpp进行画图(超详细)
目录 一、换源 二、安装必要的软件 三、下载matplotlibcpp 四、下载anaconda 1.anaconda下载 2.使用anaconda配置环境 五、下载CLion 1.下载解压CLion 2.替换jbr文件夹 3.安装CLion 4.激活CLion 5.CLion汉化 6.Clion配置 六、使用CLion运行 七、总结 我的环…...

芯科科技推出新的8位MCU系列产品,扩展其强大的MCU平台
新的BB5系列为简单应用提供更多开发选择 中国,北京 - 2023年11月14日 – 致力于以安全、智能无线连接技术,建立更互联世界的全球领导厂商Silicon Labs(亦称“芯科科技”,NASDAQ:SLAB),今日宣布…...

Flink CDC
1、Flink CDC的介绍: 是一种技术,可以帮助我们实时的捕获数据库中数据的变化,并将这些变化的数据以流的形式传输到其他的系统中进行处理和存储。 2、Flink CDC的搭建: 1、开启mysql的binlog功能: # 1、修改mysql配置…...

数据结构-链表的简单操作代码实现3-LinkedList【Java版】
写在前: 本篇博客主要介绍关于双向链表的一些简答操作实现,其中有有部分代码的实现和前两篇博客中的单向链表是相类似的。例如:查找链表中是否包含关键字key、求链表的长度等。 其余的涉及到prev指向的需要特别注意,区分和单向链表之间的差异…...

JTS: 24 MinimumDiameter 最小矩形
文章目录 版本代码 版本 org.locationtech.jts:jts-core:1.19.0 链接: github 代码 package pers.stu.algorithm;import org.locationtech.jts.algorithm.MinimumDiameter; import org.locationtech.jts.geom.Coordinate; import org.locationtech.jts.geom.Geometry; import…...
MacOS Ventura 13 优化配置(ARM架构新手向导)
一、系统配置 1、About My MacBook Pro 2、在当前标签打开新窗口 桌面上创建目录的文件夹,每次新打开一个目录,就会创建一个窗口,这就造成窗口太多,不太好查看和管理,我们可以改成在新标签处打开新目录。需要在&…...
多区域OSPF配置
配置命令步骤: 1.使用router ospf 进程ID编号 启用OSPF路由 2.使用network 直连网络地址 反掩码 area 区域号 将其归于对应区域 注意: 1.进程ID编号可任意(1-65535) 2.反掩码用4个255相减得到 3.area 0 为主干区域 4.连接不…...

【强化学习】day1 强化学习基础、马尔可夫决策过程、表格型方法
写在最前:参加DataWhale十一月组队学习记录 【教程地址】 https://github.com/datawhalechina/joyrl-book https://datawhalechina.github.io/easy-rl/ https://linklearner.com/learn/detail/91 强化学习 强化学习是一种重要的机器学习方法,它使得智能…...

openwrt Docker不能联网
文章参考:docker上网(docker安装openwrt无法上网) - 老白网络 外网不能访问内网是应为防火墙。内网访问外网如下: 清理容器垃圾 docker volume prune -f 创建一个网络 docker network create --subnet172.18.0.0/16 mynet 通过该网络创建gerrit docker run -tid --name ge…...
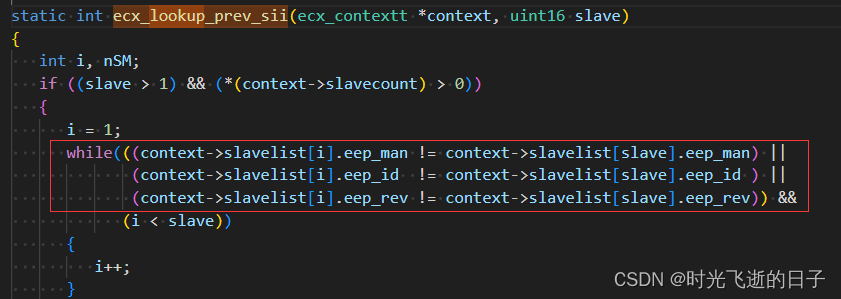
EtherCAT从站EEPROM组成信息详解(2):字8-15产品标识区
0 工具准备 1.EtherCAT从站EEPROM数据(本文使用DE3E-556步进电机驱动器)1 字8-字15产品标识区 1.1 产品标识区组成规范 对于不同厂家和型号的从站,主站是如何区分它们的呢?这就要提起SII的字8-字15区域存储的产品标识ÿ…...
SpringBoot--中间件技术-4:整合Shiro,Shiro基于会话SessionManager实现分布式认证,附案例含源代码!
SpringBoot整合安全中间件Shiro 技术栈:SpringBootShiro 代码实现 pom文件加坐标 Springboot版本选择2.7.14 ;java版本1.8 ; shiro做了版本锁定 1.3.2 <properties><java.version>1.8</java.version><!--shiro版本锁定…...

【QT基础入门】QT中的容器类
QT中有多种容器类,它们可以用来存储和操作不同类型的数据。根据容器的特性和用途,可以分为以下几类: 序列容器 这些容器按照一定的顺序存储数据,可以通过下标或迭代器访问。QT中的序列容器有: QList: 这是最通用的序列容器,它在内部实现为一个数组列表,可以快速地在头…...
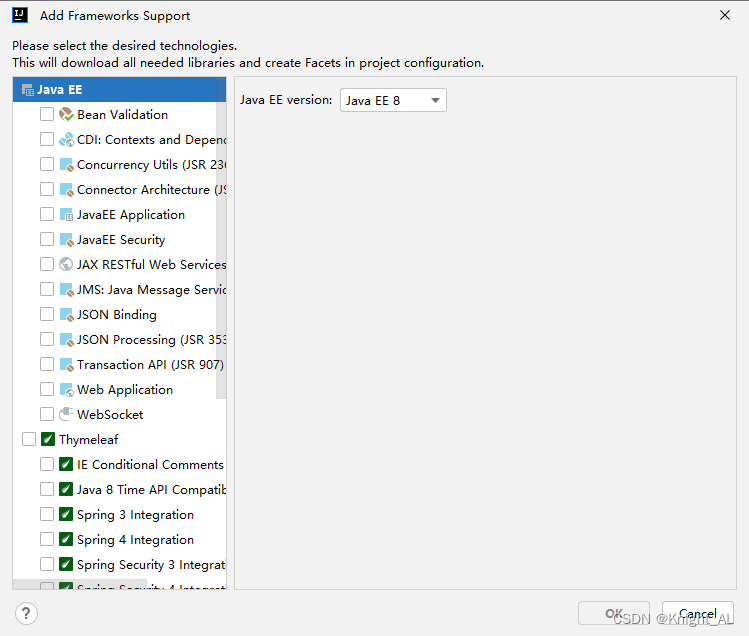
IDEA没有Add Framework Support解决办法
点击File—>Settings 点击第一个设置快捷键 点击apply和ok即可 我们要点击一下项目,再按快捷键ctrlk 即可...
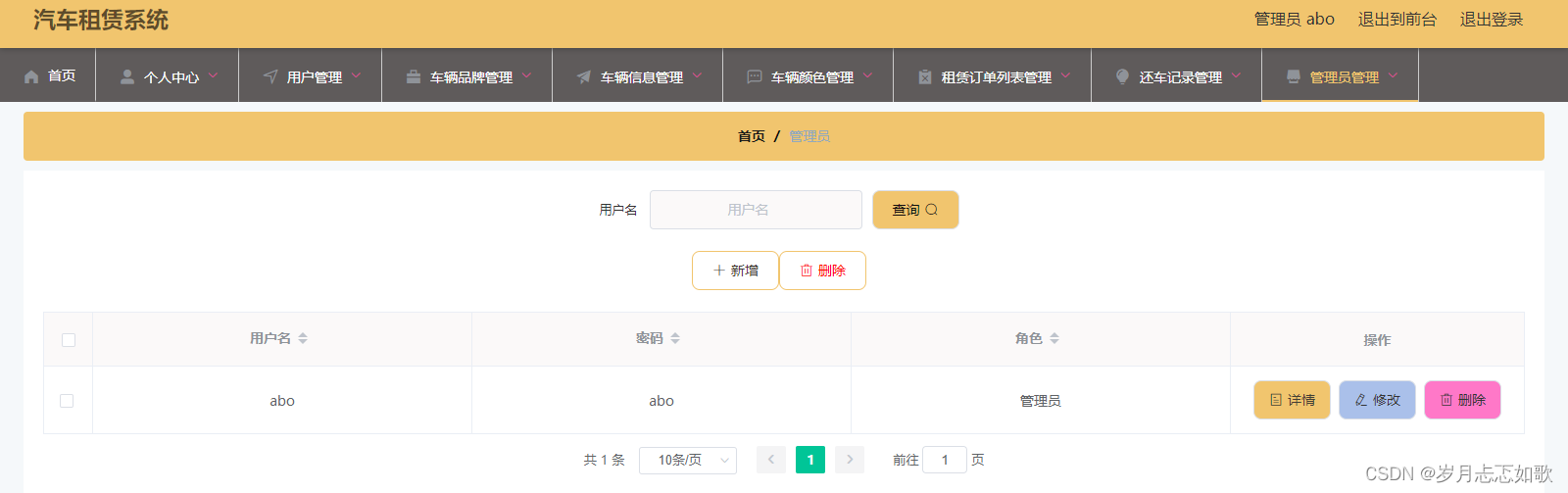
《009.SpringBoot之汽车租赁系统》
《009.SpringBoot之汽车租赁系统》 项目简介 [1]本系统涉及到的技术主要如下: 推荐环境配置:DEA jdk1.8 Maven MySQL 前后端分离; 后台:SpringBootMybatisPlus; 前台:Layuivue; [2]功能模块展示: 前端门户 1.登录&a…...
第四代智能井盖传感器,万宾科技助力城市安全
在迈向更为智能化、相互联系更为紧密的城市发展过程中,智能创新产品无疑扮演了一种重要的角色。智能井盖传感器作为新型科学技术产物,不仅解决传统井盖管理难的问题,也让城市变得更加安全美好,是城市生命线的一层重要保障。这些平…...

ClickHouse 面试题
文章目录 什么是 ClickHouse?ClickHouse 有哪些应用场景?ClickHouse 列式存储的优点有哪些?ClickHouse 的缺点是是什么?ClickHouse 的架构是怎样的?ClickHouse 的逻辑数据模型?ClickHouse 的核心特性&#…...

Python代码运行速度提升技巧!Python远比你想象中的快~
文章目录 前言一、使用内置函数二、字符串连接 VS join()三、创建列表和字典的方式四、使用 f-Strings五、使用Comprehensions六、附录- Python中的内置函数总结关于Python技术储备一、Python所有方向的学习路线二、Python基础学习视频三、精品Python学习书籍四、Python工具包项…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件
告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件当面对数百GB的设计素材、日志文件或数据库备份需要迁移时,传统的FTP传输往往会成为效率瓶颈。我曾在一个视频处理项目中,需要将230GB的4K原始素材从移动硬盘导入服务器ÿ…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...

组态王通用扫码枪配置
使用组态王扫码枪驱动,是绑定变量,扫码后直接就可以显示扫码内容。解决每次扫码输入数据时必须先用鼠标点进输入框内的问题。驱动安装先添加驱动,亚控网站的文件为 barcodescanner,这个文件是组态王通用扫码枪的驱动,但…...

PentestGPT实战部署指南:AI驱动的渗透测试工作流落地
1. 这不是另一个“AI安全”的概念玩具,而是一套能真正跑起来的渗透测试辅助工作流“PentestGPT”这个名字刚在GitHub上出现时,我第一反应是点开又关掉——过去三年里,我见过太多打着“AI渗透”旗号的项目:有的只是把ChatGPT API封…...
)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)当你在Windows和Ubuntu双系统环境下工作时,是否遇到过这样的窘境:当初安装时给Ubuntu分配的空间捉襟见肘,而Windows…...

配置OpenClaw Agent使用Taotoken作为后端模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置OpenClaw Agent使用Taotoken作为后端模型提供商 基础教程类,指导希望使用OpenClaw等Agent工具的开发者,…...

MobX社区资源大全:10个必备工具、插件和扩展库推荐 [特殊字符]
MobX社区资源大全:10个必备工具、插件和扩展库推荐 🚀 【免费下载链接】MobX-Docs-CN MobX 中文文档 项目地址: https://gitcode.com/gh_mirrors/mo/MobX-Docs-CN MobX作为一个简单、可扩展的状态管理库,已经成为React开发者不可或缺的…...

Hindsight API参考:REST接口完整文档
Hindsight API参考:REST接口完整文档 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight是一个强大的Agent Memory系统,提供了全面的REST API接口&…...
--脚本介绍)
二十六.签名与脚本(1)--脚本介绍
1.区块链脚本介绍在之前的章节中,我们了解了签名与验证相关,但是btc的交易数据,签名和验证,不是单纯的,还有脚本深度参与其中。我们从开始来:bool SendMoney(CScript scriptPubKey, int64 nValue, CWalletT…...