pandas教程:Apply:General split-apply-combine 通常的分割-应用-合并
文章目录
- 10.3 Apply:General split-apply-combine(应用:通用的分割-应用-合并)
- 1 Suppressing the Group Keys(抑制组键)
- 2 Quantile and Bucket Analysis(分位数与桶分析)
- 3 Example: Filling Missing Values with Group-Specific Values(例子:用组特异性值来填充缺失值)
- 4 Example: Random Sampling and Permutation(例子:随机抽样和排列)
- 5 Example: Group Weighted Average and Correlation(例子:组加权平均和相关性)
- 6 Example: Group-Wise Linear Regression(例子:组对组的线性回归)
10.3 Apply:General split-apply-combine(应用:通用的分割-应用-合并)
general-purpose: 可以理解为通用,泛用。
例子:在计算机软件中,通用编程语言(
General-purpose programming language)指被设计为各种应用领域服务的编程语言。通常通用编程语言不含有为特定应用领域设计的结构。
相对而言,特定域编程语言就是为某一个特定的领域或应用软件设计的编程语言。比如说,
LaTeX就是专门为排版文献而设计的语言。
最通用的GroupBy(分组)方法是apply,这也是本节的主题。如下图所示,apply会把对象分为多个部分,然后将函数应用到每一个部分上,然后把所有的部分都合并起来:
返回之前提到的tipping数据集,假设我们想要根据不同组(group),选择前5个tip_pct值最大的。首先,写一个函数,函数的功能为在特定的列,选出有最大值的行:
import numpy as np
import pandas as pd
tips = pd.read_csv('../examples/tips.csv')
# Add tip percentage of total bill
tips['tip_pct'] = tips['tip'] / tips['total_bill']
tips.head()
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 | 0.059447 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 | 0.160542 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 | 0.166587 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 | 0.139780 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 | 0.146808 |
def top(df, n=5, column='tip_pct'):return df.sort_values(by=column)[-n:]
top(tips, n=6)
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 109 | 14.31 | 4.00 | Yes | Sat | Dinner | 2 | 0.279525 |
| 183 | 23.17 | 6.50 | Yes | Sun | Dinner | 4 | 0.280535 |
| 232 | 11.61 | 3.39 | No | Sat | Dinner | 2 | 0.291990 |
| 67 | 3.07 | 1.00 | Yes | Sat | Dinner | 1 | 0.325733 |
| 178 | 9.60 | 4.00 | Yes | Sun | Dinner | 2 | 0.416667 |
| 172 | 7.25 | 5.15 | Yes | Sun | Dinner | 2 | 0.710345 |
现在,如果我们按smoker分组,然后用apply来使用这个函数,我们能得到下面的结果:
tips.groupby('smoker').apply(top)
| total_bill | tip | smoker | day | time | size | tip_pct | ||
|---|---|---|---|---|---|---|---|---|
| smoker | ||||||||
| No | 88 | 24.71 | 5.85 | No | Thur | Lunch | 2 | 0.236746 |
| 185 | 20.69 | 5.00 | No | Sun | Dinner | 5 | 0.241663 | |
| 51 | 10.29 | 2.60 | No | Sun | Dinner | 2 | 0.252672 | |
| 149 | 7.51 | 2.00 | No | Thur | Lunch | 2 | 0.266312 | |
| 232 | 11.61 | 3.39 | No | Sat | Dinner | 2 | 0.291990 | |
| Yes | 109 | 14.31 | 4.00 | Yes | Sat | Dinner | 2 | 0.279525 |
| 183 | 23.17 | 6.50 | Yes | Sun | Dinner | 4 | 0.280535 | |
| 67 | 3.07 | 1.00 | Yes | Sat | Dinner | 1 | 0.325733 | |
| 178 | 9.60 | 4.00 | Yes | Sun | Dinner | 2 | 0.416667 | |
| 172 | 7.25 | 5.15 | Yes | Sun | Dinner | 2 | 0.710345 |
我们来解释下上面这一行代码发生了什么。这里的top函数,在每一个DataFrame中的行组(row group)都被调用了一次,然后各自的结果通过pandas.concat合并了,最后用组名(group names)来标记每一部分。(译者:可以理解为,我们先按smoker这一列对整个DataFrame进行了分组,一共有No和Yes两组,然后对每一组上调用了top函数,所以每一组会返还5行作为结果,最后把两组的结果整合起来,一共是10行)。
最后的结果是有多层级索引(hierarchical index)的,而且这个多层级索引的内部层级(inner level)含有来自于原来DataFrame中的索引值(index values)
如果传递一个函数给apply,可以在函数之后,设定其他一些参数:
tips.groupby(['smoker', 'day']).apply(top, n=1, column='total_bill')
| total_bill | tip | smoker | day | time | size | tip_pct | |||
|---|---|---|---|---|---|---|---|---|---|
| smoker | day | ||||||||
| No | Fri | 94 | 22.75 | 3.25 | No | Fri | Dinner | 2 | 0.142857 |
| Sat | 212 | 48.33 | 9.00 | No | Sat | Dinner | 4 | 0.186220 | |
| Sun | 156 | 48.17 | 5.00 | No | Sun | Dinner | 6 | 0.103799 | |
| Thur | 142 | 41.19 | 5.00 | No | Thur | Lunch | 5 | 0.121389 | |
| Yes | Fri | 95 | 40.17 | 4.73 | Yes | Fri | Dinner | 4 | 0.117750 |
| Sat | 170 | 50.81 | 10.00 | Yes | Sat | Dinner | 3 | 0.196812 | |
| Sun | 182 | 45.35 | 3.50 | Yes | Sun | Dinner | 3 | 0.077178 | |
| Thur | 197 | 43.11 | 5.00 | Yes | Thur | Lunch | 4 | 0.115982 |
除了上面这些基本用法,要想用好apply可能需要一点创新能力。毕竟传给这个函数的内容取决于我们自己,而最终的结果只需要返回一个pandas对象或一个标量。这一章的剩余部分主要介绍如何解决在使用groupby时遇到的一些问题。
可以试一试在GroupBy对象上调用describe:
result = tips.groupby('smoker')['tip_pct'].describe()
result
smoker
No count 151.000000mean 0.159328std 0.039910min 0.05679725% 0.13690650% 0.15562575% 0.185014max 0.291990
Yes count 93.000000mean 0.163196std 0.085119min 0.03563825% 0.10677150% 0.15384675% 0.195059max 0.710345
Name: tip_pct, dtype: float64
result.unstack('smoker')
| smoker | No | Yes |
|---|---|---|
| count | 151.000000 | 93.000000 |
| mean | 0.159328 | 0.163196 |
| std | 0.039910 | 0.085119 |
| min | 0.056797 | 0.035638 |
| 25% | 0.136906 | 0.106771 |
| 50% | 0.155625 | 0.153846 |
| 75% | 0.185014 | 0.195059 |
| max | 0.291990 | 0.710345 |
在GroupBy内部,当我们想要调用一个像describe这样的函数的时候,其实相当于下面的写法:
f = lambda x: x.describe()
grouped.apply(f)
1 Suppressing the Group Keys(抑制组键)
在接下来的例子,我们会看到作为结果的对象有一个多层级索引(hierarchical index),这个多层级索引是由原来的对象中,组键(group key)在每一部分的索引上得到的。我们可以在groupby函数中设置group_keys=False来关闭这个功能:
tips.groupby('smoker', group_keys=False).apply(top)
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 88 | 24.71 | 5.85 | No | Thur | Lunch | 2 | 0.236746 |
| 185 | 20.69 | 5.00 | No | Sun | Dinner | 5 | 0.241663 |
| 51 | 10.29 | 2.60 | No | Sun | Dinner | 2 | 0.252672 |
| 149 | 7.51 | 2.00 | No | Thur | Lunch | 2 | 0.266312 |
| 232 | 11.61 | 3.39 | No | Sat | Dinner | 2 | 0.291990 |
| 109 | 14.31 | 4.00 | Yes | Sat | Dinner | 2 | 0.279525 |
| 183 | 23.17 | 6.50 | Yes | Sun | Dinner | 4 | 0.280535 |
| 67 | 3.07 | 1.00 | Yes | Sat | Dinner | 1 | 0.325733 |
| 178 | 9.60 | 4.00 | Yes | Sun | Dinner | 2 | 0.416667 |
| 172 | 7.25 | 5.15 | Yes | Sun | Dinner | 2 | 0.710345 |
2 Quantile and Bucket Analysis(分位数与桶分析)
在第八章中,我们介绍了pandas的一些工具,比如cut和qcut,通过设置中位数,切割数据为buckets with bins(有很多箱子的桶)。
把函数通过groupby整合起来,可以在做桶分析或分位数分析的时候更方便。假设一个简单的随机数据集和一个等长的桶类型(bucket categorization),使用cut:
frame = pd.DataFrame({'data1': np.random.randn(1000),'data2': np.random.randn(1000)})
frame.head()
| data1 | data2 | |
|---|---|---|
| 0 | 0.723973 | 0.120216 |
| 1 | 2.053617 | 0.468000 |
| 2 | -0.543073 | -1.874073 |
| 3 | -0.915136 | 0.159179 |
| 4 | 0.775965 | 0.105447 |
quartiles = pd.cut(frame.data1, 4)
quartiles[:10]
0 (0.194, 1.795]
1 (1.795, 3.395]
2 (-1.407, 0.194]
3 (-1.407, 0.194]
4 (0.194, 1.795]
5 (0.194, 1.795]
6 (0.194, 1.795]
7 (-1.407, 0.194]
8 (-1.407, 0.194]
9 (-1.407, 0.194]
Name: data1, dtype: category
Categories (4, object): [(-3.0139, -1.407] < (-1.407, 0.194] < (0.194, 1.795] < (1.795, 3.395]]
cut返回的Categorical object(类别对象)能直接传入groupby。所以我们可以在data2列上计算很多统计值:
def get_stats(group):return {'min': group.min(), 'max': group.max(),'count': group.count(), 'mean': group.mean()}
grouped = frame.data2.groupby(quartiles)
grouped.apply(get_stats).unstack()
| count | max | mean | min | |
|---|---|---|---|---|
| data1 | ||||
| (-3.0139, -1.407] | 70.0 | 2.035166 | 0.113238 | -2.363707 |
| (-1.407, 0.194] | 481.0 | 3.284688 | -0.044535 | -2.647341 |
| (0.194, 1.795] | 407.0 | 2.402272 | -0.043887 | -2.898145 |
| (1.795, 3.395] | 42.0 | 2.051843 | 0.095178 | -2.234979 |
也有相同长度的桶(equal-length buckets);想要按照样本的分位数得到相同长度的桶,用qcut。这里设定labels=False来得到分位数的数量:
# Return quantile numbers
grouping = pd.qcut(frame.data1, 10, labels=False)
译者:上面的代码是把frame的data1列分为10个bin,每个bin都有相同的数量。因为一共有1000个样本,所以每个bin里有100个样本。grouping保存的是每个样本的index以及其对应的bin的编号。
grouped = frame.data2.groupby(grouping)
grouped.apply(get_stats).unstack()
| count | max | mean | min | |
|---|---|---|---|---|
| data1 | ||||
| 0 | 100.0 | 2.178653 | 0.078390 | -2.363707 |
| 1 | 100.0 | 3.284688 | -0.018699 | -2.647341 |
| 2 | 100.0 | 2.214011 | -0.066341 | -2.262063 |
| 3 | 100.0 | 2.880188 | -0.014041 | -2.475753 |
| 4 | 100.0 | 2.741344 | -0.007952 | -2.576095 |
| 5 | 100.0 | 2.346857 | -0.109602 | -2.898145 |
| 6 | 100.0 | 2.402272 | 0.004522 | -1.911955 |
| 7 | 100.0 | 2.351513 | -0.161472 | -2.640625 |
| 8 | 100.0 | 2.135995 | -0.016079 | -1.986676 |
| 9 | 100.0 | 2.051843 | 0.037685 | -2.513164 |
对于pandas的Categorical类型,会在第十二章做详细介绍。
3 Example: Filling Missing Values with Group-Specific Values(例子:用组特异性值来填充缺失值)
在处理缺失值的时候,一些情况下我们会直接用dropna来把缺失值删除,但另一些情况下,我们希望用一些固定的值来代替缺失值,而fillna就是用来做这个的,例如,这里我们用平均值mean来代替缺失值NA:
s = pd.Series(np.random.randn(6))
s[::2] = np.nan
s
0 NaN
1 0.878562
2 NaN
3 -0.264051
4 NaN
5 0.760488
dtype: float64
s.fillna(s.mean())
0 0.458333
1 0.878562
2 0.458333
3 -0.264051
4 0.458333
5 0.760488
dtype: float64
假设我们想要给每一组填充不同的值。一个方法就是对数据分组后,用apply来调用fillna,在每一个组上执行一次。这里有一些样本是把美国各州分为西部和东部:
states = ['Ohio', 'New York', 'Vermont', 'Florida','Oregon', 'Nevada', 'California', 'Idaho']
group_key = ['East'] * 4 + ['West'] * 4
group_key
['East', 'East', 'East', 'East', 'West', 'West', 'West', 'West']
data = pd.Series(np.random.randn(8), index=states)
data
Ohio 0.683283
New York -1.059896
Vermont 0.105837
Florida -0.328586
Oregon 1.973413
Nevada 0.656673
California 0.001700
Idaho -0.713295
dtype: float64
我们令data中某些值为缺失值:
data[['Vermont', 'Nevada', 'Idaho']] = np.nan
data
Ohio 0.683283
New York -1.059896
Vermont NaN
Florida -0.328586
Oregon 1.973413
Nevada NaN
California 0.001700
Idaho NaN
dtype: float64
data.groupby(group_key).mean()
East -0.235066
West 0.987556
dtype: float64
然后我们可以用每个组的平均值来填充NA:
fill_mean = lambda g: g.fillna(g.mean())
data.groupby(group_key).apply(fill_mean)
Ohio 0.683283
New York -1.059896
Vermont -0.235066
Florida -0.328586
Oregon 1.973413
Nevada 0.987556
California 0.001700
Idaho 0.987556
dtype: float64
在另外一些情况下,我们可能希望提前设定好用于不同组的填充值。因为group有一个name属性,我们可以利用这个:
fill_values = {'East': 0.5, 'West': -1}
fill_func = lambda g: g.fillna(fill_values[g.name])
data.groupby(group_key).apply(fill_func)
Ohio 0.683283
New York -1.059896
Vermont 0.500000
Florida -0.328586
Oregon 1.973413
Nevada -1.000000
California 0.001700
Idaho -1.000000
dtype: float64
4 Example: Random Sampling and Permutation(例子:随机抽样和排列)
假设我们想要从一个很大的数据集里随机抽出一些样本,这里我们可以在Series上用sample方法。为了演示,这里县创建一副模拟的扑克牌:
# Hearts红桃,Spades黑桃,Clubs梅花,Diamonds方片
suits = ['H', 'S', 'C', 'D']
card_val = (list(range(1, 11)) + [10] * 3) * 4
base_names = ['A'] + list(range(2, 11)) + ['J', 'K', 'Q']
cards = []
for suit in ['H', 'S', 'C', 'D']:cards.extend(str(num) + suit for num in base_names)deck = pd.Series(card_val, index=cards)
这样我们就得到了一个长度为52的Series,索引(index)部分是牌的名字,对应的值为牌的点数,这里的点数是按Blackjack(二十一点)的游戏规则来设定的。
Blackjack(二十一点): 2点至10点的牌以牌面的点数计算,J、Q、K 每张为10点,A可记为1点或为11点。这里为了方便,我们只把A记为1点。
deck[:13]
AH 1
2H 2
3H 3
4H 4
5H 5
6H 6
7H 7
8H 8
9H 9
10H 10
JH 10
KH 10
QH 10
dtype: int64
现在,就像我们上面说的,随机从牌组中抽出5张牌:
def draw(deck, n=5):return deck.sample(n)
draw(deck)
7H 7
6D 6
AC 1
JH 10
JS 10
dtype: int64
假设我们想要从每副花色中随机抽取两张,花色是每张牌名字的最后一个字符(即H, S, C, D),我们可以根据花色分组,然后使用apply:
get_suit = lambda card: card[-1] # last letter is suit
deck.groupby(get_suit).apply(draw, n=2)
C QC 109C 9
D 3D 3JD 10
H KH 106H 6
S 3S 37S 7
dtype: int64
另外一种写法:
deck.groupby(get_suit, group_keys=False).apply(draw, n=2)
7C 7
KC 10
AD 1
4D 4
AH 1
8H 8
7S 7
9S 9
dtype: int64
5 Example: Group Weighted Average and Correlation(例子:组加权平均和相关性)
在groupby的split-apply-combine机制下,DataFrame的两列或两个Series,计算组加权平均(Group Weighted Average)是可能的。这里举个例子,下面的数据集包含组键,值,以及权重:
df = pd.DataFrame({'category': ['a', 'a', 'a', 'a','b', 'b', 'b', 'b'],'data': np.random.randn(8),'weights': np.random.rand(8)})
df
| category | data | weights | |
|---|---|---|---|
| 0 | a | 0.098020 | 0.008455 |
| 1 | a | 1.389496 | 0.826219 |
| 2 | a | 0.202869 | 0.258955 |
| 3 | a | -0.242403 | 0.470473 |
| 4 | b | -0.820507 | 0.628758 |
| 5 | b | 0.866326 | 0.653632 |
| 6 | b | -1.297375 | 0.639703 |
| 7 | b | 0.525019 | 0.012664 |
按category分组来计算组加权平均:
grouped = df.groupby('category')
get_wavg = lambda g: np.average(g['data'], weights=g['weights'])
grouped.apply(get_wavg)
category
a 0.695189
b -0.399497
dtype: float64
另一个例子,考虑一个从Yahoo!财经上得到的经济数据集,包含一些股票交易日结束时的股价,以及S&P 500指数(即SPX符号):
标准普尔500指数英文简写为
S&P 500 Index,是记录美国500家上市公司的一个股票指数。这个股票指数由标准普尔公司创建并维护。
标准普尔500指数覆盖的所有公司,都是在美国主要交易所,如纽约证券交易所、
Nasdaq交易的上市公司。与道琼斯指数相比,标准普尔500指数包含的公司更多,因此风险更为分散,能够反映更广泛的市场变化。
close_px = pd.read_csv('../examples/stock_px_2.csv', parse_dates=True,index_col=0)
close_px.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 2214 entries, 2003-01-02 to 2011-10-14
Data columns (total 4 columns):
AAPL 2214 non-null float64
MSFT 2214 non-null float64
XOM 2214 non-null float64
SPX 2214 non-null float64
dtypes: float64(4)
memory usage: 86.5 KB
close_px[-4:]
| AAPL | MSFT | XOM | SPX | |
|---|---|---|---|---|
| 2011-10-11 | 400.29 | 27.00 | 76.27 | 1195.54 |
| 2011-10-12 | 402.19 | 26.96 | 77.16 | 1207.25 |
| 2011-10-13 | 408.43 | 27.18 | 76.37 | 1203.66 |
| 2011-10-14 | 422.00 | 27.27 | 78.11 | 1224.58 |
一个比较有意思的尝试是计算一个DataFrame,包括与SPX这一列逐年日收益的相关性(计算百分比变化)。一个可能的方法是,我们先创建一个能计算不同列相关性的函数,然后拿每一列与SPX这一列求相关性:
spx_corr = lambda x: x.corrwith(x['SPX'])
然后我们通过pct_change在close_px上计算百分比的变化:
rets = close_px.pct_change().dropna()
最后,我们按年来给这些百分比变化分组,年份可以从每行的标签中通过一个一行函数提取,然后返回的结果中,用datetime标签来表示年份:
get_year = lambda x: x.year
by_year = rets.groupby(get_year)
by_year.apply(spx_corr)
| AAPL | MSFT | XOM | SPX | |
|---|---|---|---|---|
| 2003 | 0.541124 | 0.745174 | 0.661265 | 1.0 |
| 2004 | 0.374283 | 0.588531 | 0.557742 | 1.0 |
| 2005 | 0.467540 | 0.562374 | 0.631010 | 1.0 |
| 2006 | 0.428267 | 0.406126 | 0.518514 | 1.0 |
| 2007 | 0.508118 | 0.658770 | 0.786264 | 1.0 |
| 2008 | 0.681434 | 0.804626 | 0.828303 | 1.0 |
| 2009 | 0.707103 | 0.654902 | 0.797921 | 1.0 |
| 2010 | 0.710105 | 0.730118 | 0.839057 | 1.0 |
| 2011 | 0.691931 | 0.800996 | 0.859975 | 1.0 |
我们也可以计算列内的相关性。这里我们计算苹果和微软每年的相关性:
by_year.apply(lambda g: g['AAPL'].corr(g['MSFT']))
2003 0.480868
2004 0.259024
2005 0.300093
2006 0.161735
2007 0.417738
2008 0.611901
2009 0.432738
2010 0.571946
2011 0.581987
dtype: float64
6 Example: Group-Wise Linear Regression(例子:组对组的线性回归)
就像上面介绍的例子,使用groupby可以用于更复杂的组对组统计分析,只要函数能返回一个pandas对象或标量。例如,我们可以定义regress函数(利用statsmodels库),在每一个数据块(each chunk of data)上进行普通最小平方回归(ordinary least squares (OLS) regression)计算:
import statsmodels.api as sm
def regress(data, yvar, xvars):Y = data[yvar]X = data[xvars]X['intercept'] = 1result = sm.OLS(Y, X).fit()return result.params
现在,按年用苹果AAPL在标普SPX上做线性回归:
by_year.apply(regress, 'AAPL', ['SPX'])
| SPX | intercept | |
|---|---|---|
| 2003 | 1.195406 | 0.000710 |
| 2004 | 1.363463 | 0.004201 |
| 2005 | 1.766415 | 0.003246 |
| 2006 | 1.645496 | 0.000080 |
| 2007 | 1.198761 | 0.003438 |
| 2008 | 0.968016 | -0.001110 |
| 2009 | 0.879103 | 0.002954 |
| 2010 | 1.052608 | 0.001261 |
| 2011 | 0.806605 | 0.001514 |
相关文章:

pandas教程:Apply:General split-apply-combine 通常的分割-应用-合并
文章目录 10.3 Apply:General split-apply-combine(应用:通用的分割-应用-合并)1 Suppressing the Group Keys(抑制组键)2 Quantile and Bucket Analysis(分位数与桶分析)3 Example:…...
第一讲之递归与递推下篇
第一讲之递归与递推下篇 带分数费解的开关飞行员兄弟翻硬币 带分数 用暴力将所有全排列的情况都算出来 > 有三个数,a,b,c 每种排列情况,可以用两层for循环,暴力分为三个部分,每个部分一个数 当然注意这里,第一层fo…...

第十六篇-Awesome ChatGPT Prompts-备份
Awesome ChatGPT Prompts——一个致力于提供挖掘ChatGPT能力的Prompt收集网站 https://prompts.chat/ 2023-11-16内容如下 ✂️Act as a Linux Terminal Contributed by: f Reference: https://www.engraved.blog/building-a-virtual-machine-inside/ I want you to act as a…...

Python Web框架Django
Python Web框架Django Django简介第一个Django应用Django核心概念Django django-adminDjango项目结构Django配置文件settingsDjango创建和配置应用Django数据库配置Django后台管理Django模型Django模型字段Django模型关联关系Django模型Meta 选项Django模型属性ManagerDjango模…...

1.Spring的简单使用
简介 本文是介绍spring源码的开始,先了解最基础的使用,最深入源码。 spring源码下载地址 https://github.com/spring-projects/spring-framework.git 依赖 依赖 spring-context dependencies {implementation(project(":spring-context")…...
02.智慧商城——vant组件库使用和vw适配
01. vant组件库及Vue周边的其他组件库 组件库:第三方封装好了很多很多的组件,整合到一起就是一个组件库。 https://vant-contrib.gitee.io/vant/v2/#/zh-CN/ 比如日历组件、键盘组件、打分组件、下拉筛选组件等 组件库并不是唯一的,常用的组…...

Android笔记(十三):结合JetPack Compose和CameraX实现视频的录制和存储
在“Android笔记(八):基于CameraX库结合Compose和传统视图组件PreviewView实现照相机画面预览和照相功能”,文中介绍了拍照功能的实现,在本文中将介绍结合JetPack Compose和CameraX实现视频的录制。 新建一个项目 在项…...

【开题报告】基于SpringBoot的音乐鉴赏平台的设计与实现
1.研究背景与意义 音乐是人类文化的重要组成部分,具有广泛的影响力和吸引力。然而,随着数字化时代的到来,传统的音乐鉴赏方式面临一些挑战。因此,设计和开发一个基于Spring Boot的音乐鉴赏平台,能够满足用户对音乐欣赏…...
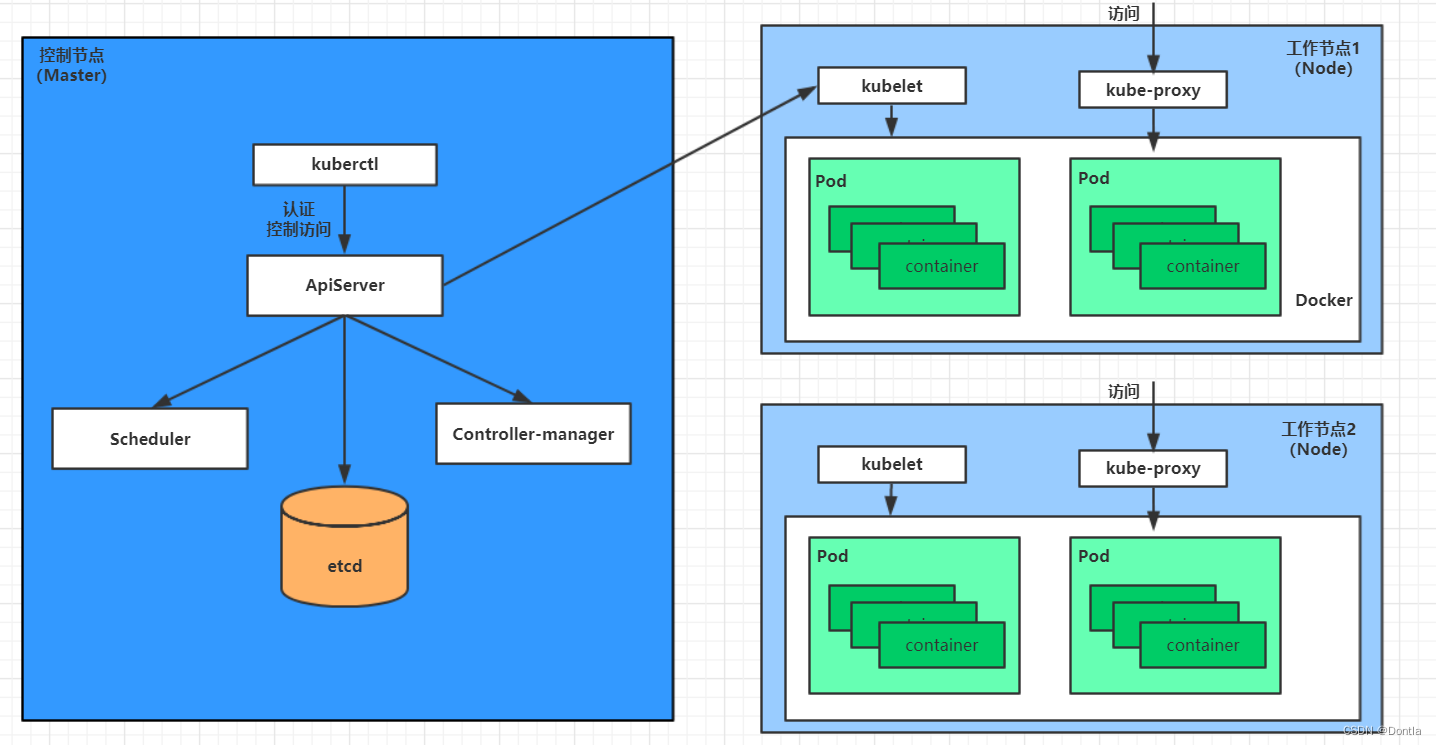
云原生 黑马Kubernetes教程(K8S教程)笔记——第一章 kubernetes介绍——Master集群控制节点、Node工作负载节点、Pod控制单元
参考文章:kubernetes介绍 文章目录 第一章 kubernetes介绍1.1 应用部署方式演变传统部署:互联网早期,会直接将应用程序部署在物理机上虚拟化部署:可以在一台物理机上运行多个虚拟机,每个虚拟机都是独立的一个环境&…...

ElasticSearch 安装(单机版本)
文章目录 ElasticSearch 安装(单机版本)环境配置下载安装包调整系统参数安装启动并验证 ElasticSearch 安装(单机版本) 此文档演示 ElasticSearch 的单机版本在 CentOS 7 环境下的安装方式以及相关的配置。 环境配置 Linux 主机一…...

读书笔记:《BackTrader 量化交易案例图解》
BackTrader 量化软件:https://github.com/mementum/backtrader -> bt 量化框架(前身):https://github.com/pmorissette/bt-> ffn 量化框架(前前身):https://github.com/pmorissette/ffn T…...

CentOS 7 免密密钥登陆sftp服务 —— 筑梦之路
为什么用sftp而不是ftp? sftp是使用ssh协议安全加密的文件传输协议,ftp在很多时候都是使用的明文传输,相对来说容易被抓包,存在安全隐患。 需求说明 1. 使用sftp代替ftp来做文件存储,锁定目录,不允许用户切…...

记一次 .NET 某券商论坛系统 卡死分析
一:背景 1. 讲故事 前几个月有位朋友找到我,说他们的的web程序没有响应了,而且监控发现线程数特别高,内存也特别大,让我帮忙看一下怎么回事,现在回过头来几经波折,回味价值太浓了。 二&#…...
DevExpress WinForms HeatMap组件,一个高度可自定义热图控件!
通过DevExpress WinForms可以为Windows Forms桌面平台提供的高度可定制的热图UI组件,体验DevExpress的不同之处。 DevExpress WinForms有180组件和UI库,能为Windows Forms平台创建具有影响力的业务解决方案。同时能完美构建流畅、美观且易于使用的应用程…...

振弦传感器表面应变计与振弦采集仪形成岩土工程监测的解决方案
振弦传感器表面应变计与振弦采集仪形成岩土工程监测的解决方案 振弦传感器表面应变计与振弦采集仪可以结合使用,形成岩土工程监测的解决方案。具体的方案包括以下几个步骤: 1. 安装振弦传感器表面应变计:首先需要在需要监测的岩土结构表面安…...
笔记本电脑没有声音?几招恢复声音流畅!
笔记本电脑已经成为我们日常生活和工作的重要工具,而其中的声音是其功能之一。然而,有时您可能会遇到笔记本电脑没有声音的问题,这可能是由多种原因引起的。在本文中,我们将深入探讨笔记本电脑没有声音的常见原因,并提…...

JavaScript学习_01——JavaScript简介
JavaScript简介 JavaScript介绍 JavaScript是一种轻量级的脚本语言。所谓“脚本语言”,指的是它不具备开发操作系统的能力,而是只用来编写控制其他大型应用程序的“脚本”。 JavaScript 是一种嵌入式(embedded)语言。它本身提供…...
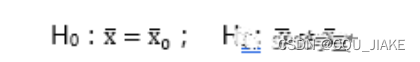
11.10~11.15置信区间,均值、方差假设检验,正态,t,卡方,F分布,第一第二类错误
置信度,置信区间 给定一个置信度,就可以算出一个置信区间。 如果给的置信度越大,那么阿尔法就越小 给的置信度越小,那么α就越大,那么 考虑精确性,希望区间长度尽可能小,所以是取正态的中间…...
)
【洛谷 P2440】木材加工 题解(二分查找+循环)
木材加工 题目背景 要保护环境 题目描述 木材厂有 n n n 根原木,现在想把这些木头切割成 k k k 段长度均为 l l l 的小段木头(木头有可能有剩余)。 当然,我们希望得到的小段木头越长越好,请求出 l l l 的最大…...

反向传播详解BP
误差反向传播(Back-propagation, BP)算法的出现是神经网络发展的重大突破,也是现在众多深度学习训练方法的基础。该方法会计算神经网络中损失函数对各参数的梯度,配合优化方法更新参数,降低损失函数。 BP本来只指损失…...

别再乱算相似度了!用Python实战二元变量聚类:从Jaccard系数到病人分组
医疗数据分析实战:用Python实现基于Jaccard系数的病人症状聚类在医疗数据分析领域,如何从海量病人症状数据中发现潜在规律一直是临床研究的难点。传统方法往往依赖医生经验或简单统计,而现代数据挖掘技术为我们提供了更科学的解决方案。本文将…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

FT231XQ USB串口桥接板设计解析与实战应用指南
1. 项目概述:从FT232R到FT231XQ的USB串口桥接板演进在嵌入式开发和硬件调试的日常工作中,一个可靠、小巧且功能清晰的USB转串口(UART)桥接板(Breakout Board, 简称BoB)几乎是工程师手边的标配工…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...

Godot 4.3随机地图性能优化:避开TileMap与RNG陷阱
1. 为什么刚写完第一版随机地图就崩溃?——从“能跑”到“能用”的真实断层你兴冲冲地照着教程敲完几十行GDScript,RandomNumberGenerator初始化了,for x in range(width)循环也套好了,甚至还在_draw()里用draw_rect()把每个格子都…...

Python到Android的魔法之旅:5步将你的代码变成移动应用
Python到Android的魔法之旅:5步将你的代码变成移动应用 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android 想象一下,你花了几个月时间精心…...

英雄联盟回放播放难题终极解决方案:ROFLPlayer完整使用指南
英雄联盟回放播放难题终极解决方案:ROFLPlayer完整使用指南 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为英雄联盟旧…...

TII投稿避坑指南:LaTeX模板编译报错‘xxx-eps-converted-to.pdf not found’的终极解决方案
TII投稿LaTeX避坑实战:从编译报错到完美PDF生成的终极指南 凌晨三点的实验室,屏幕上闪烁的xxx-eps-converted-to.pdf not found错误提示仿佛在嘲笑你连续八小时的徒劳尝试。这不是科幻场景,而是每位用LaTeX撰写TII论文的研究者都可能遭遇的真…...
)
BGP选路原则--本地优先级(LocPrf)
如果BGP收到相同的路由,首选值PrefVal如果也相同的话,那么就会继续比较下一条原则:本地优先级Local_Pref 一、拓扑图 二、配置BGP路由协议: R1 bgp 100 peer 12.1.1.2 as-number 200 peer 13.1.1.3 as-number 200 R2 bgp 200 peer 4.4.4.4 as-number 200 peer 4.4.4…...