用封面预测书的价格【图像回归】
今天,我将介绍计算机视觉的深度学习应用,用封面简单地估算一本书的价格。 我没有看到很多关于图像回归的文章,所以我为你们写这篇文章。
距离我上一篇文章已经过去很长时间了,我不得不承认,作为一名数据科学家,我用于副业或写文章的时间更少了(或者,也许这只是我的懒惰)。
如果你对本文旁边的编码感兴趣,请查看此 GitHub。

在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器
1、数据
本文使用的数据可以从此处提供的 Kaggle 数据集下载。 它包含来自 BookDepository 网站的书籍特征数据,但我们将主要使用书籍封面图像来训练深度学习模型。 现在让我们看看图书数据是什么样的。
import pandas as pd
df= pd.read_csv('main_dataset.csv')
df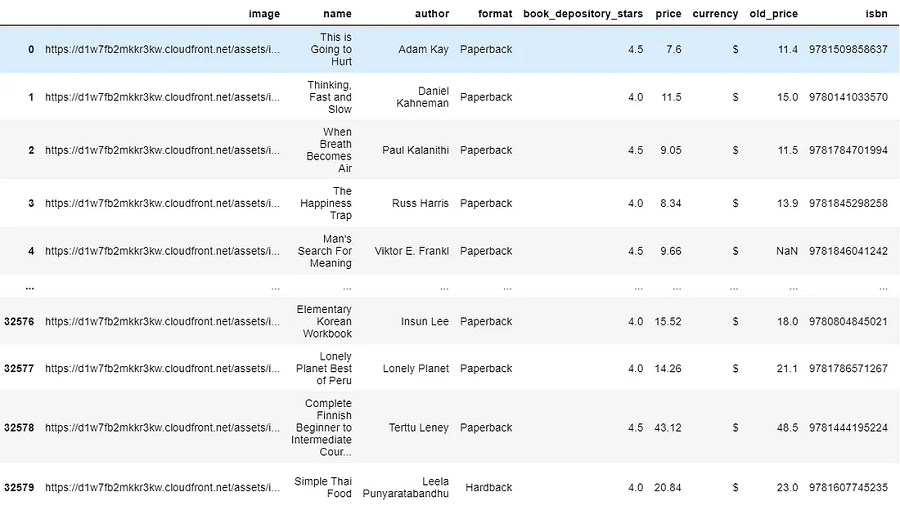
数据的形状为 (32581, 11),但在本文中,我们将仅关注“图像”和“价格”字段给出的书籍封面图像数据和价格标签(不是旧价格)。 如果仔细查看加载的数据,我们会发现除了“图像”列中给出的图像 URL 之外,我们没有图像数据。 原因是图像数据是非结构化数据,不能与其他数据采用相同的格式。
抛开这些原因不谈,我如何访问这种格式的图像数据? 我需要创建一个函数来从这些 URL 中获取图像并将它们全部加载到文件夹图像中。
2、加载并查看图片
from matplotlib import pyplot as plt
import numpy as np
import urllib
import cv2
def show_image_from_url(image_url):
"""Fetches image online from the image_url and plots it as it is using matplotlib's pyplot's image show"""
response = urllib.request.urlopen(image_url)image = np.asarray(bytearray(response.read()), dtype="uint8")image_bgr = cv2.imdecode(image, cv2.IMREAD_COLOR)image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)plt.imshow(image_rgb), plt.axis('off')上面的函数将从图像 URL 获取图像,并使用 matplotlib 和 OpenCV 库显示图像。 让我们看看该函数是如何工作的:
plt.figure()
show_image_from_url(df['image'].loc[10])
我们得到了Michael Mosley 撰写的 The Clever Guts Diet 一书的封面。 现在你看到我们可以显示给定 URL 中的图像,是时候获取图像并将其加载到你的计算机以将其放入深度学习中了。
3、图像预处理
下面是一个相当长的函数,因为它不仅加载图像,还进行图像预处理—转换为灰度、裁剪和调整图像大小。 所有这些预处理都是为了让覆盖数据更加一致,适合即将到来的深度学习:
def image_processing(image_url):
"""Converts the URL of any image to an array of size 100x1 The array represents an OpenCV grayscale version of the original imageThe image will get cropped along the biggest red contour (4 line polygon) tagged on the original image (if any)"""
#Download from image url and import it as a numpy arrayresponse = urllib.request.urlopen(image_url)image = np.asarray(bytearray(response.read()), dtype="uint8")
#Read the numpy arrays as color images in OpenCVimage_bgr = cv2.imdecode(image, cv2.IMREAD_COLOR)
#Convert to HSV for creating a maskimage_hsv = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2HSV)
#Convert to grayscale that will actually be used for training, instead of color image image_gray = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2GRAY)
#Create a mask that detects the red rectangular tags present in each imagemask = cv2.inRange(image_hsv, (0,255,255), (0,255,255))
#Get the coordinates of the red rectangle in the image, #But take entire image if mask fails to detect the red rectangleif len(np.where(mask != 0)[0]) != 0:y1 = min(np.where(mask != 0)[0])y2 = max(np.where(mask != 0)[0])else:y1 = 0 y2 = len(mask)
if len(np.where(mask != 0)[1]) != 0:x1 = min(np.where(mask != 0)[1])x2 = max(np.where(mask != 0)[1])else:x1 = 0x2 = len(mask[0])
#Crop the grayscle image along those coordinatesimage_cropped = image_gray[y1:y2, x1:x2]if image_cropped.size ==0:print(image_url)return image_croppedelse:#Resize the image to 100x100 pixels sizeimage_100x100 = cv2.resize(image_cropped, (100, 100))
#Save image as in form of array of 10000x1image_arr = image_100x100.flatten()
return image_arr预处理的阶段包括:
- 灰度化:灰度表示经常用于提取描述符而不是直接对彩色图像进行操作的主要原因是灰度简化了算法并降低了计算要求。 大多数时候,HSV 格式中的颜色并不重要,灰度可以轻松完成相同的工作。
- 裁剪:图像裁剪是一种常见的照片处理过程,它通过删除不需要的区域来改善整体构图。 显然,图像的角落并不是人类感知图像的焦点,我们只关注中心。 书的封面一角并没有对其书的价格留下任何解释力,而且大部分都是相同的。
- 调整大小:为了促进小批量学习,我们需要给定批次内的图像具有固定的形状。 这就是为什么需要初始调整大小的原因。 我们首先将所有图像的大小调整为 (300 x 300) 形状,然后学习它们在 (150 x 150) 分辨率下的最佳表示。 调整大小并不能以任何方式帮助我们改进模型,这只是数据通过神经网络的方式,需要相同的结构。
4、加载数据
现在我们将该函数应用于图像 URL 列以获取图像数据。 请注意,这将花费你一两个小时来加载整个数据集。 如果想快速工作,你可以加载至少 2000 个 URL,这将花费大约 20 到 30 分钟。
from tqdm import tqdm
for url in tqdm(df['image'].tolist()[:]): # 3000 urls is enoughimage_list.append(image_processing(url))请注意,你的图像不再是 PNG 或 JPEG。 现在它是 NumPy 对象中具有灰度的像素向量。 这就是你需要在深度学习模型中传递的内容。
X = np.array(image_list)
np.save('processed_100x100_image.npy',X/255,allow_pickle=True)
book_array = np.load('processed_100x100_image.npy',allow_pickle=True)现在,加载数据并将其保存在 image_list 中,它只是存储在你的代码中,这是不好的做法,因为每次想要再次获取这些数据时,都必须浪费 30 分钟。 所以这里需要将那些处理后的图像数据保存到本地计算机中。
5、清理不同尺寸的图像和价格标签
要将数据传递到深度学习模型中,所有数据都需要具有相同的维度,即 100x100。 但是,当我查看处理后的图像 NumPy 数组时,我发现存在一些错误,即某些图像与其他图像的尺寸不同,因此我们需要在训练模型之前删除这些图像。
#remove non 10000 dimension out of the numpy array
X =[]
exclude =[]
for i in range(len(book_array)):if book_array[i].shape == (10000,):X.append(book_array[i])else:exclude.append(i)
X =np.array(X)
#also remove from the dataframe
df.drop(df.index[exclude],inplace=True)在这里,我删除了与 100x100 尺寸不同的数据,并从数据框中删除了这些数据,因为我们需要使用价格标签数据,而我们不希望有任何复杂的数据映射或不匹配。
import re
df['price'] = df.price.apply(lambda x :re.sub("[^0-9.]",'',x)).apply(float)价格标签中会有非数字值,如“$”、“dollars”等,不适用于运行深度模型。 我将使用正则表达式仅保留数字。
6、预处理后的图像示例
执行如下代码随机选择两张预处理后的图片并显示:
np.random.seed(17)
for i in np.random.randint(0, len(book_array), 2):plt.figure()plt.imshow(book_array[i].reshape(100, 100), cmap='gray'), plt.axis('off')
7、卷积神经网络
为了估算这本书的价格,在这项任务中,我将使用卷积神经网络或 CNN,它是针对涉及图像数据作为输入的任何类型的预测问题最有效的深度学习模型之一。

简而言之,CNN 算法会将图像简化为更易于处理的形式,而不会丢失对于获得良好预测至关重要的特征。
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPool2D, BatchNormalization
from tensorflow.keras.layers import Activation, Dropout, Flatten, Dense
from tensorflow.keras.losses import categorical_crossentropy
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.models import load_model
#Define a Convolutional Neural Network Model
model = Sequential()
model.add(Conv2D(filters = 16, kernel_size = (3, 3), activation='relu',input_shape = input_shape))
model.add(BatchNormalization())
model.add(Conv2D(filters = 16, kernel_size = (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPool2D(strides=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters = 32, kernel_size = (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(Conv2D(filters = 32, kernel_size = (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPool2D(strides=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.4))
#model.add(Dense(n_classes, activation='softmax'))
model.add(Dense(1, activation='relu'))
learning_rate = 0.001
model.compile(loss = 'mse',optimizer = Adam(learning_rate))
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 98, 98, 16) 160
_________________________________________________________________
batch_normalization_4 (Batch (None, 98, 98, 16) 64
_________________________________________________________________
conv2d_5 (Conv2D) (None, 96, 96, 16) 2320
_________________________________________________________________
batch_normalization_5 (Batch (None, 96, 96, 16) 64
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 48, 48, 16) 0
_________________________________________________________________
dropout_4 (Dropout) (None, 48, 48, 16) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 46, 46, 32) 4640
_________________________________________________________________
batch_normalization_6 (Batch (None, 46, 46, 32) 128
_________________________________________________________________
conv2d_7 (Conv2D) (None, 44, 44, 32) 9248
_________________________________________________________________
batch_normalization_7 (Batch (None, 44, 44, 32) 128
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 22, 22, 32) 0
_________________________________________________________________
dropout_5 (Dropout) (None, 22, 22, 32) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 15488) 0
_________________________________________________________________
dense_3 (Dense) (None, 512) 7930368
_________________________________________________________________
dropout_6 (Dropout) (None, 512) 0
_________________________________________________________________
dense_4 (Dense) (None, 1024) 525312
_________________________________________________________________
dropout_7 (Dropout) (None, 1024) 0
_________________________________________________________________
dense_5 (Dense) (None, 1) 1025
=================================================================
Total params: 8,473,457
Trainable params: 8,473,265
Non-trainable params: 192我们将创建一个具有四个卷积层和过滤器 [16,16,32,32] 的 CNN 模型,然后该架构师将池化特征图转换为单个列,并传递到全连接层。
save_at = "model_regression.hdf5"
save_best2 = ModelCheckpoint (save_at, monitor='val_accuracy', verbose=0, save_best_only=True, save_weights_only=False, mode='max')
#set up the x, y for training
Y = np.array(df.price.tolist())
X_test = X[30000:,]
Y_test = Y[30000:,]
X_train, X_val, Y_train, Y_val = train_test_split(X[:30000,], Y[:30000,], test_size=0.15, random_state=13)
img_rows, img_cols = 100, 100
input_shape = (img_rows, img_cols, 1)
X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
X_val = X_val.reshape(X_val.shape[0], img_rows, img_cols, 1)前三行是设置训练完成后保存模型的参数。 剩下的就是为训练集和测试集设置目标或价格为 y。 现在我们正在使用 15 个 epoch 和 batch_size 为 100 来训练模型。如果你的计算机有足够的资源,请继续输入与 batch_size 一样多的数据,然后运行以下代码:
history = model.fit( X_train, Y_train, epochs = 15, batch_size = 100, callbacks=[save_best2], verbose=1, validation_data = (X_val, Y_price_val))在这里,你可以看到模型正在过度拟合,绿线或验证损失约为 200,而红线或训练损失则越来越低。 当我将模型设置为保存最低的验证损失时,我们的模型性能将在第七个epoch保存。
plt.figure(figsize=(6, 5))
# training loss
plt.plot(history.history['loss'], color='r')
#validation loss
plt.plot(history.history['val_loss'], color='g')
plt.show()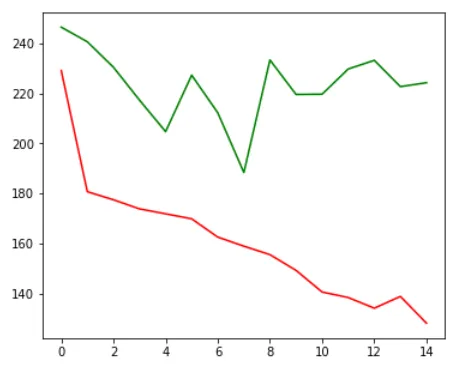
让我们看看模型结果是什么:
Y_pred = np.round(model.predict(X_test))
np.random.seed(23)
for rand_num in np.random.randint(0, len(Y_test), 10):plt.figure()plt.imshow(X_test[rand_num].reshape(100, 100),cmap='gray'), plt.axis('off')if np.where(Y_pred[rand_num] < 10)[0].sum() == np.where(Y_test[rand_num] <10)[0].sum():plt.title(str(Y_pred[rand_num]) +' dollars', color='g')else :plt.title(str(Y_pred[rand_num]) +' dollars', color='r')
8、进一步的工作
我我们构建了一个基于封面的书籍价格预测器,希望你也可以将其应用于其他应用程序。 请注意,该模型仍然需要针对过度拟合进行调整,以使其能够很好地适应现实世界。 你可以采取一下错误来解决 CNN 中的过度拟合问题。
- 添加更多数据
- 使用数据增强
- 使用泛化良好的架构
- 添加正则化(主要是dropout,L1/L2正则化也是可以的)
- 降低架构复杂性。
原文链接:用封面预测书价 - BimAnt
相关文章:
用封面预测书的价格【图像回归】
今天,我将介绍计算机视觉的深度学习应用,用封面简单地估算一本书的价格。 我没有看到很多关于图像回归的文章,所以我为你们写这篇文章。 距离我上一篇文章已经过去很长时间了,我不得不承认,作为一名数据科学家&#x…...
阿里云服务器e实例40G ESSD Entry系统盘、2核2G3M带宽99元
阿里云99元服务器新老用户同享2核2G经济型e实例、3M固定带宽和40G ESSD Entry系统盘,老用户也可以买,续费不涨价依旧是99元一年,阿里云百科aliyunbaike.com分享阿里云3M带宽服务器40G ESSD Entry云盘性能说明: 阿里云99元服务器配…...
Datawhale智能汽车AI挑战赛
1.赛题解析 赛题地址:https://tianchi.aliyun.com/competition/entrance/532155 任务: 输入:元宇宙仿真平台生成的前视摄像头虚拟视频数据(8-10秒左右);输出:对视频中的信息进行综合理解&…...
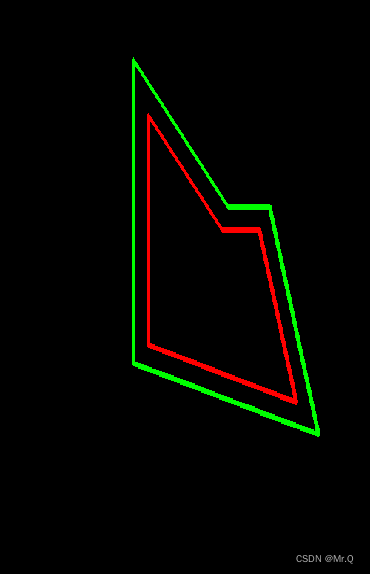
pyclipper和ClipperLib操作多边型
目录 1. 等距离缩放多边形 1.1 python 1.2 c 1. 等距离缩放多边形 1.1 python 环境配置pip install opencv-python opencv-contrib-python pip install pyclipper pip install numpy import cv2 import numpy as np import pyclipperdef equidistant_zoom_contour(contour…...
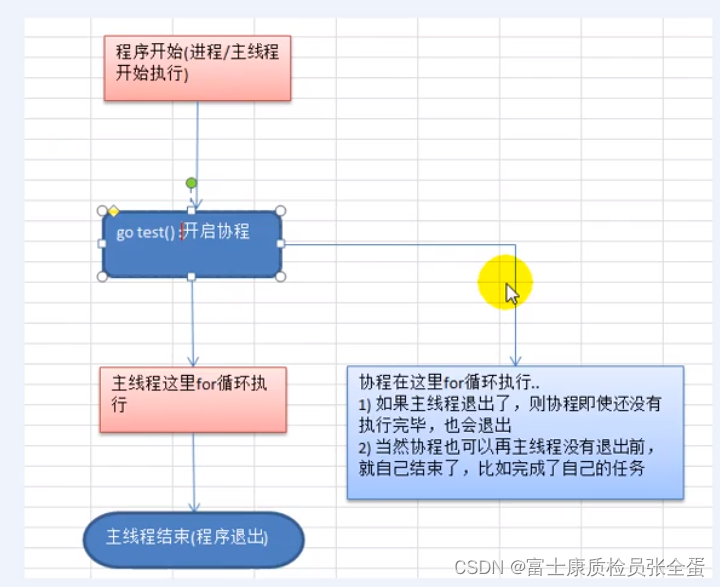
Golang 协程、主线程
Go协程、Go主线程 1)Go主线程(有程序员直接称为线程/也可以理解成进程):一个Go线程上,可以起多个协程,你可以这样理解,协程是轻量级的线程。 2)Go协程的特点 有独立的栈空间 共享程序堆空间 调度由用户控制 协程是轻量级的线程 go线程-…...

【SA8295P 源码分析】125 - MAX96712 解串器 start_stream、stop_stream 寄存器配置 过程详细解析
【SA8295P 源码分析】125 - MAX96712 解串器 start_stream、stop_stream 寄存器配置 过程详细解析 一、sensor_detect_device():MAX96712 检测解串器芯片是否存在,获取chip_id、device_revision二、sensor_detect_device_channels() :MAX96712 解串器 寄存器初始化 及 detec…...

pandas教程:Apply:General split-apply-combine 通常的分割-应用-合并
文章目录 10.3 Apply:General split-apply-combine(应用:通用的分割-应用-合并)1 Suppressing the Group Keys(抑制组键)2 Quantile and Bucket Analysis(分位数与桶分析)3 Example:…...
第一讲之递归与递推下篇
第一讲之递归与递推下篇 带分数费解的开关飞行员兄弟翻硬币 带分数 用暴力将所有全排列的情况都算出来 > 有三个数,a,b,c 每种排列情况,可以用两层for循环,暴力分为三个部分,每个部分一个数 当然注意这里,第一层fo…...

第十六篇-Awesome ChatGPT Prompts-备份
Awesome ChatGPT Prompts——一个致力于提供挖掘ChatGPT能力的Prompt收集网站 https://prompts.chat/ 2023-11-16内容如下 ✂️Act as a Linux Terminal Contributed by: f Reference: https://www.engraved.blog/building-a-virtual-machine-inside/ I want you to act as a…...

Python Web框架Django
Python Web框架Django Django简介第一个Django应用Django核心概念Django django-adminDjango项目结构Django配置文件settingsDjango创建和配置应用Django数据库配置Django后台管理Django模型Django模型字段Django模型关联关系Django模型Meta 选项Django模型属性ManagerDjango模…...

1.Spring的简单使用
简介 本文是介绍spring源码的开始,先了解最基础的使用,最深入源码。 spring源码下载地址 https://github.com/spring-projects/spring-framework.git 依赖 依赖 spring-context dependencies {implementation(project(":spring-context")…...
02.智慧商城——vant组件库使用和vw适配
01. vant组件库及Vue周边的其他组件库 组件库:第三方封装好了很多很多的组件,整合到一起就是一个组件库。 https://vant-contrib.gitee.io/vant/v2/#/zh-CN/ 比如日历组件、键盘组件、打分组件、下拉筛选组件等 组件库并不是唯一的,常用的组…...

Android笔记(十三):结合JetPack Compose和CameraX实现视频的录制和存储
在“Android笔记(八):基于CameraX库结合Compose和传统视图组件PreviewView实现照相机画面预览和照相功能”,文中介绍了拍照功能的实现,在本文中将介绍结合JetPack Compose和CameraX实现视频的录制。 新建一个项目 在项…...

【开题报告】基于SpringBoot的音乐鉴赏平台的设计与实现
1.研究背景与意义 音乐是人类文化的重要组成部分,具有广泛的影响力和吸引力。然而,随着数字化时代的到来,传统的音乐鉴赏方式面临一些挑战。因此,设计和开发一个基于Spring Boot的音乐鉴赏平台,能够满足用户对音乐欣赏…...
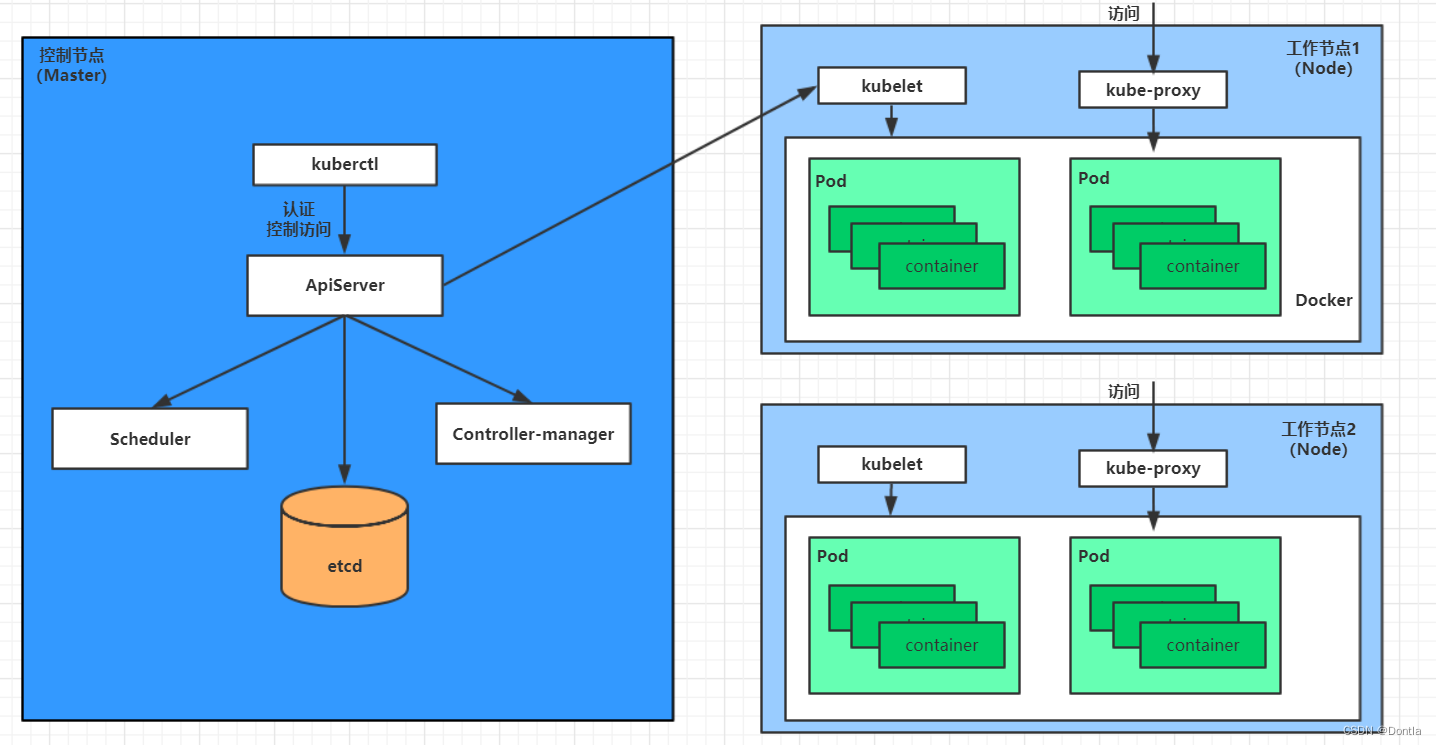
云原生 黑马Kubernetes教程(K8S教程)笔记——第一章 kubernetes介绍——Master集群控制节点、Node工作负载节点、Pod控制单元
参考文章:kubernetes介绍 文章目录 第一章 kubernetes介绍1.1 应用部署方式演变传统部署:互联网早期,会直接将应用程序部署在物理机上虚拟化部署:可以在一台物理机上运行多个虚拟机,每个虚拟机都是独立的一个环境&…...

ElasticSearch 安装(单机版本)
文章目录 ElasticSearch 安装(单机版本)环境配置下载安装包调整系统参数安装启动并验证 ElasticSearch 安装(单机版本) 此文档演示 ElasticSearch 的单机版本在 CentOS 7 环境下的安装方式以及相关的配置。 环境配置 Linux 主机一…...

读书笔记:《BackTrader 量化交易案例图解》
BackTrader 量化软件:https://github.com/mementum/backtrader -> bt 量化框架(前身):https://github.com/pmorissette/bt-> ffn 量化框架(前前身):https://github.com/pmorissette/ffn T…...

CentOS 7 免密密钥登陆sftp服务 —— 筑梦之路
为什么用sftp而不是ftp? sftp是使用ssh协议安全加密的文件传输协议,ftp在很多时候都是使用的明文传输,相对来说容易被抓包,存在安全隐患。 需求说明 1. 使用sftp代替ftp来做文件存储,锁定目录,不允许用户切…...

记一次 .NET 某券商论坛系统 卡死分析
一:背景 1. 讲故事 前几个月有位朋友找到我,说他们的的web程序没有响应了,而且监控发现线程数特别高,内存也特别大,让我帮忙看一下怎么回事,现在回过头来几经波折,回味价值太浓了。 二&#…...
DevExpress WinForms HeatMap组件,一个高度可自定义热图控件!
通过DevExpress WinForms可以为Windows Forms桌面平台提供的高度可定制的热图UI组件,体验DevExpress的不同之处。 DevExpress WinForms有180组件和UI库,能为Windows Forms平台创建具有影响力的业务解决方案。同时能完美构建流畅、美观且易于使用的应用程…...

终极指南:一键解决iPhone USB网络共享驱动问题
终极指南:一键解决iPhone USB网络共享驱动问题 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/gh_mirrors/ap…...

Phi-3-mini-4k-instruct-gguf应用落地:律师助理合同风险点识别与提示生成
Phi-3-mini-4k-instruct-gguf应用落地:律师助理合同风险点识别与提示生成 1. 项目背景与价值 在法律服务领域,合同审查是律师日常工作中最耗时且重复性高的任务之一。传统人工审查方式存在效率低下、容易遗漏细节等问题。Phi-3-mini-4k-instruct-gguf作…...
)
从SENet到KAN卷积:一文搞懂注意力机制如何从‘加权’进化到‘学习’(附演进路线图)
注意力机制的进化图谱:从SENet到KAN卷积的技术跃迁 在计算机视觉领域,注意力机制已成为提升模型性能的关键技术。本文将带您深入探索注意力机制从早期通道注意力到最新动态结构学习的完整演进历程,揭示这一技术如何从简单的特征重标定发展为能…...

终极指南:gh_mirrors/log/log构建流程解析:从CoffeeScript到Grunt自动化
终极指南:gh_mirrors/log/log构建流程解析:从CoffeeScript到Grunt自动化 【免费下载链接】log Console.log with style. 项目地址: https://gitcode.com/gh_mirrors/log/log 如何快速构建优雅的控制台日志工具?gh_mirrors/log/log项目…...

Falcor路径追踪器深度解析:如何实现电影级实时渲染效果
Falcor路径追踪器深度解析:如何实现电影级实时渲染效果 【免费下载链接】Falcor Real-Time Rendering Framework 项目地址: https://gitcode.com/gh_mirrors/fal/Falcor Falcor路径追踪器是一个基于DXR 1.1的高性能实时渲染框架,能够在现代GPU上实…...

3步解锁跨设备游戏自由:Sunshine串流技术重构娱乐体验
3步解锁跨设备游戏自由:Sunshine串流技术重构娱乐体验 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 在这个设备爆炸的时代,我们却被硬件束缚得越来越紧。…...

千问3.5-2B在VSCode中的集成应用:基于CodeX的智能编程助手搭建
千问3.5-2B在VSCode中的集成应用:基于CodeX的智能编程助手搭建 1. 引言 作为一名开发者,你是否经常在编码过程中遇到这些问题:记不清某个API的具体用法?需要快速生成重复性代码片段?遇到报错信息却找不到清晰的解释&…...
)
告别Keil5刺眼白屏!保姆级教程教你配置VS Code同款暗黑主题(附3套配色方案)
Keil5暗黑主题终极改造指南:从护眼原理到深度定制 凌晨三点的实验室里,显示屏刺眼的白光让我的眼球开始灼烧般疼痛——这是许多嵌入式开发者共同的噩梦。Keil5作为单片机开发的主流工具,其默认的亮色主题在长时间编码时带来的视觉负担远超你的…...

从播放卡顿到流媒体优化:深入MP4的stbl盒子,理解视频流畅播放的关键
从播放卡顿到流媒体优化:深入MP4的stbl盒子,理解视频流畅播放的关键 当你在深夜调试一个在线视频播放器,发现用户总是抱怨卡顿和拖拽不准时,是否曾思考过问题可能隐藏在MP4文件最核心的stbl盒子中?作为流媒体开发者&am…...

HY-MT1.5-1.8B功能体验:格式保留翻译,完美处理srt字幕和网页标签
HY-MT1.5-1.8B功能体验:格式保留翻译,完美处理srt字幕和网页标签 1. 引言:翻译模型的新挑战 在全球化内容爆炸式增长的今天,传统翻译工具面临两大核心痛点: 格式丢失问题:翻译srt字幕、HTML网页等内容时…...