Datawhale智能汽车AI挑战赛
1.赛题解析
赛题地址:https://tianchi.aliyun.com/competition/entrance/532155
任务:
- 输入:元宇宙仿真平台生成的前视摄像头虚拟视频数据(8-10秒左右);
- 输出:对视频中的信息进行综合理解,以指定的json文件格式,按照数据说明中的关键词(key)填充描述型的文本信息(value,中文/英文均可以)
评分标准:
系统会针对参赛者提交的json文件,通过描述型的文本信息与真值进行对比,综合得出分数;其中,“距离最近的交通参与者的行为”的题目为2分,其它题目为1分;每个视频的满分为10分。每一个视频结果中的key值,需要参考数据说明的json格式示例,请勿进行修改。
2.Baseline详解
深度学习框架搭建:
可参考
Paddle版:
首先导入库
import paddle
from PIL import Image
from clip import tokenize, load_model
import glob, json, os
import cv2
from PIL import Image
from tqdm import tqdm_notebook
import numpy as np
from sklearn.preprocessing import normalize
import matplotlib.pyplot as plt
paddle:PaddlePaddle深度学习框架。
PIL:Python Imaging Library,用于图像处理。
clip:包含CLIP模型的库。
glob:用于获取文件路径。
json:用于处理JSON数据。
os:用于操作文件和目录。
cv2:OpenCV库,用于读取视频帧。
tqdm_notebook:用于显示进度条。
numpy:用于数值计算。
sklearn.preprocessing.normalize:用于归一化数据。
matplotlib.pyplot:用于绘图。
加载CLIP模型和转换器:
model, transforms = load_model('ViT_B_32', pretrained=True)
定义匹配词典:
en_match_words = {"scerario" : ["suburbs","city street","expressway","tunnel","parking-lot","gas or charging stations","unknown"],"weather" : ["clear","cloudy","raining","foggy","snowy","unknown"],"period" : ["daytime","dawn or dusk","night","unknown"],"road_structure" : ["normal","crossroads","T-junction","ramp","lane merging","parking lot entrance","round about","unknown"],"general_obstacle" : ["nothing","speed bumper","traffic cone","water horse","stone","manhole cover","nothing","unknown"],"abnormal_condition" : ["uneven","oil or water stain","standing water","cracked","nothing","unknown"],"ego_car_behavior" : ["slow down","go straight","turn right","turn left","stop","U-turn","speed up","lane change","others"],"closest_participants_type" : ["passenger car","bus","truck","pedestrain","policeman","nothing","others","unknown"],"closest_participants_behavior" : ["slow down","go straight","turn right","turn left","stop","U-turn","speed up","lane change","others"],
}定义结果JSON对象
submit_json = {"author" : "abc" ,"time" : "231011","model" : "model_name","test_results" : []
}
获取视频文件路径并排序:
paths = glob.glob('./初赛测试视频/*')
paths.sort()
遍历每个视频文件:
for video_path in paths:print(video_path)
读取视频帧并进行预处理
cap = cv2.VideoCapture(video_path)
img = cap.read()[1]
image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
image = Image.fromarray(image)
image = transforms(image).unsqueeze(0)
定义单个视频结果的字典,并设置默认值:
single_video_result = {"clip_id": clip_id,"scerario" : "cityroad","weather":"unknown","period":"night","road_structure":"ramp","general_obstacle":"nothing","abnormal_condition":"nothing","ego_car_behavior":"turning right","closest_participants_type":"passenger car","closest_participants_behavior":"braking"
}
对于每个关键词,使用CLIP模型进行分类:
for keyword in en_match_words.keys():if keyword not in ["weather", "road_structure"]:#只有当关键词为"weather"或"road_structure"时才会执行后续的操作,其他关键词则会跳过continuetexts = np.array(en_match_words[keyword])#先将关键词对应的文本转换为一个NumPy数组
#先使用了一个名为tokenize的函数,它将关键词转换为模型能够理解的标记序列,然后调用CLIP模型的model方法,传入图像和标记化的文本,获取图像和文本的logits(预测得分)。其中,logits_per_image表示图像的logits,logits_per_text表示文本的logitswith paddle.no_grad():logits_per_image, logits_per_text = model(image, tokenize(en_match_words[keyword]))probs = paddle.nn.functional.softmax(logits_per_image, axis=-1)#使用softmax函数对图像的logits进行归一化处理,得到每个类别的概率probs = probs.numpy() single_video_result[keyword] = texts[probs[0].argsort()[::-1][0]]#将概率值转换为NumPy数组,并根据概率值从高到低进行排序。然后将对应的文本赋值给single_video_result字典中的相应关键词将单个视频结果添加到结果JSON对象中:
submit_json["test_results"].append(single_video_result)
将结果JSON对象保存为文件:
with open('clip_result.json', 'w', encoding='utf-8') as up:json.dump(submit_json, up, ensure_ascii=False)
对一系列视频进行分类,并将结果保存在一个JSON文件中。其中使用了PaddlePaddle的深度学习框架和OpenAI的CLIP模型来进行图像和文本的匹配和分类。
CLIP模型原理
可参考另一位助教写的博客点击直达
参考链接1
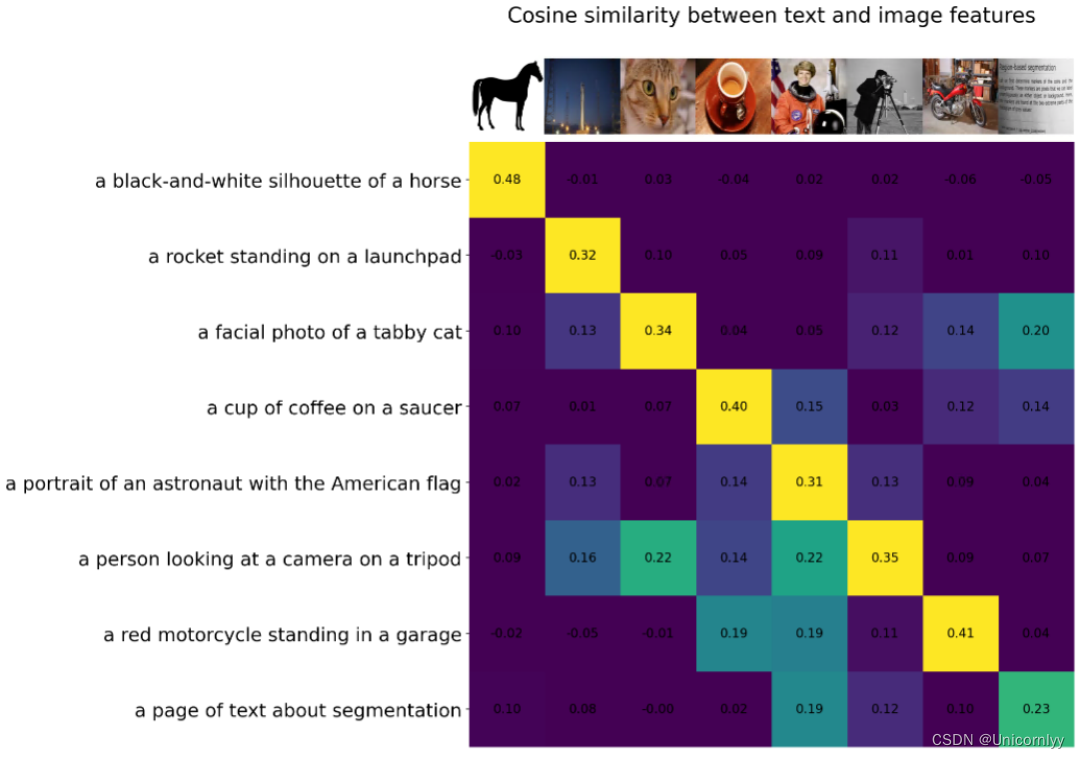
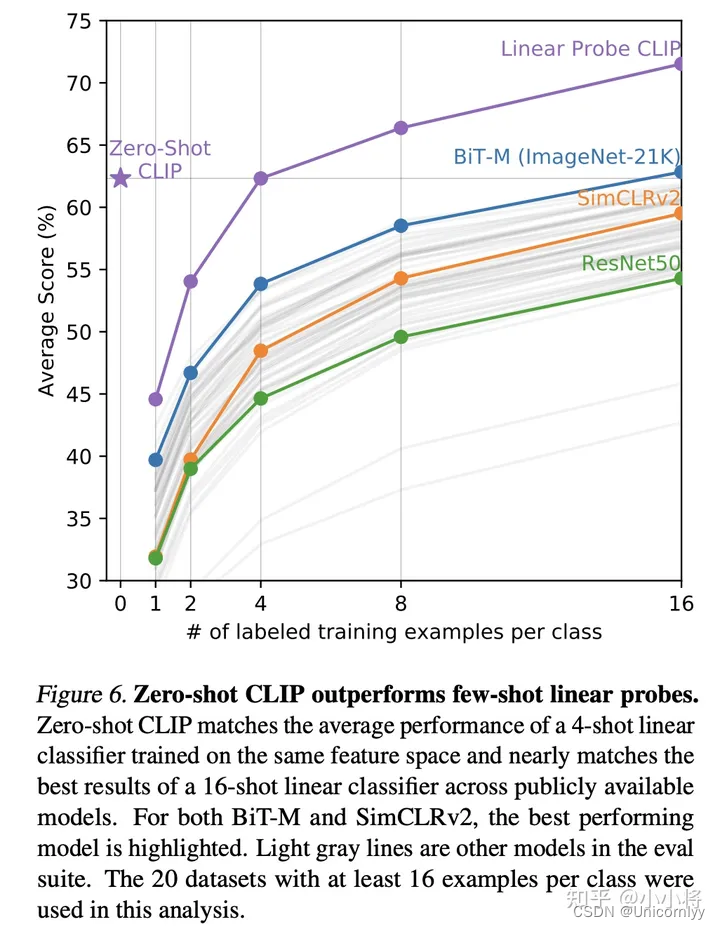
CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。如下图所示,CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。
CLIP的思想非常简单,只需要看懂这幅图就可以了,左边是训练的原理,CLIP一共有两个模态,一个是文本模态,一个是视觉模态,分别对应了Text Encoder和Image Encoder。
- Text Encoder用于对文本进行编码,获得其Embedding;
- Image Encoder用于对图片编码,获得其Embedding。
- 两个Embedding均为一定长度的单一向量。
pytorch版:
全部代码及注释
#导入库
import glob, json, os
import cv2
from PIL import Image
from tqdm import tqdm_notebook
import numpy as np
from sklearn.preprocessing import normalize
import matplotlib.pyplot as pltfrom PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
#加载预训练的CLIP模型:
#通过使用Hugging Face的transformers库,该代码从预训练模型 "openai/clip-vit-large-patch14-336" 中加载了一个CLIP模型,并创建了一个处理器processor
model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14-336")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14-336")
#通过URL下载一张图像,并使用PIL库打开该图像,处理图像数据
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
#准备模型输入并获取输出,使用CLIP处理器processor对图像和文本进行处理,准备成模型需要的张量格式,然后将输入传递给CLIP模型,获取模型的输出
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)outputs = model(**inputs)logits_per_image = outputs.logits_per_image # this is the image-text similarity score# 得到图像-文本相似度得分
logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities# 对结果进行softmax处理,得到标签概率
#我们得到了图像和文本之间的相似度得分logits_per_image,并对其进行了softmax处理,得到了标签的概率分布#分别定义了中文和英文对应的关键词匹配字典。
cn_match_words = {"工况描述": ["高速/城市快速路", "城区", "郊区", "隧道", "停车场", "加油站/充电站", "未知"],"天气": ["晴天", "雨天", "多云", "雾天", "下雪", "未知"],"时间": ["白天", "夜晚", "拂晓/日暮", "未知"],"道路结构": ["十字路口", "丁字路口", "上下匝道", "车道汇入", "进出停车场", "环岛", "正常车道", "未知"],"一般障碍物": ["雉桶", "水马", "碎石/石块", "井盖", "减速带", "没有"],"道路异常情况": ["油污/水渍", "积水", "龟裂", "起伏不平", "没有", "未知"],"自车行为": ["直行", "左转", "右转", "停止", "掉头", "加速", "减速", "变道", "其它"],"最近的交通参与者": ["行人", "小型汽车", "卡车", "交警", "没有", "未知", "其它"],"最近的交通参与者行为": ["直行", "左转", "右转", "停止", "掉头", "加速", "减速", "变道", "其它"],
}en_match_words = {
"scerario" : ["suburbs","city street","expressway","tunnel","parking-lot","gas or charging stations","unknown"],
"weather" : ["clear","cloudy","raining","foggy","snowy","unknown"],
"period" : ["daytime","dawn or dusk","night","unknown"],
"road_structure" : ["normal","crossroads","T-junction","ramp","lane merging","parking lot entrance","round about","unknown"],
"general_obstacle" : ["nothing","speed bumper","traffic cone","water horse","stone","manhole cover","nothing","unknown"],
"abnormal_condition" : ["uneven","oil or water stain","standing water","cracked","nothing","unknown"],
"ego_car_behavior" : ["slow down","go straight","turn right","turn left","stop","U-turn","speed up","lane change","others"],
"closest_participants_type" : ["passenger car","bus","truck","pedestrain","policeman","nothing","others","unknown"],
"closest_participants_behavior" : ["slow down","go straight","turn right","turn left","stop","U-turn","speed up","lane change","others"],
}
#读取视频文件
cap = cv2.VideoCapture(r'D:/D/Download/360安全浏览器下载/初赛测试视频/初赛测试视频/41.avi')
#读取视频帧图像读取第一帧图片可以考虑一下怎么改进
img = cap.read()[1]
image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)#转换图像颜色格式,将图像从BGR格式转换为RGB格式
#创建PIL图像对象
image = Image.fromarray(image)#使用PIL库的fromarray函数将NumPy数组(即经过颜色格式转换后的图像数据)转换为PIL的Image对象image.resize((600, 300))
#两个Python字典的定义和赋值操作
submit_json = {"作者" : "阿水" ,"时间" : "231011","模型名字" : "model_name","测试结果" : []
}submit_json = {"author" : "abc" ,"time" : "231011","model" : "model_name","test_results" : []
}
#使用了Python中的glob模块来匹配文件路径,获取指定目录下所有文件的路径并将结果进行排序
paths = glob.glob(r'.\chusai\*')
paths.sort()
#对paths列表中的每个视频路径进行处理,并生成相应的结果
for video_path in paths:print(video_path)# clip_id = video_path.split('/')[-1]clip_id = os.path.split(video_path)[-1]print(clip_id)# clip_id = video_path.split('/')[-1][:-4]cap = cv2.VideoCapture(video_path)#打开视频文件img = cap.read()[1]#读取视频帧,将得到的图像赋值给变量imgimage = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# image = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)image = Image.fromarray(image) #将BGR格式的图像转换为RGB格式,并将结果赋值给变量image #定义了一个字典single_video_result,包含了一些视频相关的属性single_video_result = {"clip_id": clip_id,"scerario" : "cityroad","weather":"clear","period":"daytime","road_structure":"namal","general_obstacle":"nothing","abnormal_condition":"nothing","ego_car_behavior":"go straight","closest_participants_type":"passenger car","closest_participants_behavior":"braking"}#历en_match_words字典中的关键字,对除了weather、road_structure、scerario和period以外的关键字进行处理for keyword in en_match_words.keys():if keyword not in ["weather", "road_structure", 'scerario', 'road_structure', 'period']:continue texts = np.array(en_match_words[keyword])#转化为Numpy数组inputs = processor(text=list(texts), images=image, return_tensors="pt", padding=True)#使用模型的处理器(processor)对文本和图像进行处理,生成模型输入所需的格式。这里的处理器负责将文本和图像转换为模型能够接受的输入格式print(inputs)outputs = model(**inputs)#调用模型,将处理后的输入传入模型中,得到模型的输出。模型的输出包括了图像和文本之间的相似度得分logits_per_image = outputs.logits_per_image # this is the image-text similarity scoreprobs = logits_per_image.softmax(dim=1) # probs: [[1.2686e-03, 5.4499e-02, 6.7968e-04, 9.4355e-01]]将相似度得分进行softmax处理,得到每个类别的概率分布single_video_result[keyword] = texts[probs[0].argsort().numpy()[::-1][0]]#根据概率最大的类别,从文本数组中取出相应的文本,并将其作为该关键字对应的值,赋给single_video_result字典submit_json["test_results"].append(single_video_result)#将处理得到的single_video_result字典添加到submit_json["test_results"]列表中,最终得到一个JSON对象,其中包含了对每个视频的预测结果len(paths)# 遍历每个数据条目,对clip_id进行修改#首先,这个循环遍历了名为submit_json的JSON对象中的'test_results'字段对应的列表。对于列表中的每个条目(在代码中称为entry),它检查是否存在名为'clip_id'的字段。#如果存在'clip_id'字段,代码会执行entry['clip_id'].split("\\")[-1]操作。这行代码的作用是将'clip_id'字段的值按照反斜杠\分割,并取分割后的结果的最后一个部分。这样的操作通常用于获取文件路径中的文件名部分。
for entry in submit_json['test_results']:if 'clip_id' in entry:entry['clip_id'] = entry['clip_id'].split("\\")[-1]
#代码打开了一个名为coggle_result5.json的文件(路径为D:/D/Download/360安全浏览器下载/)以供写入,并使用json.dump将经过处理的submit_json对象写入到这个文件中。参数ensure_ascii=False表示在生成的JSON文件中允许非ASCII字符的存在,通常用于处理非英文文本。
with open(r'D:/D/Download/360安全浏览器下载/coggle_result5.json', 'w', encoding='utf-8') as up:json.dump(submit_json, up, ensure_ascii=False)
# "作者" : "abc" ,
# "时间" : "YYMMDD",
# "模型名字" : "model_name",
# "测试结果" :[
# {
# "视频ID" : "xxxx_1",
# "工况描述" : "城市道路",
# "天气":"未知",
# "时间":"夜晚",
# "道路结构":"匝道",
# "一般障碍物":"无",
# "道路异常情况":"无",
# "自车行为":"右转",
# "最近的交通参与者":"小轿车",
# "最近的交通参与者行为":"制动"
# },submit_json
目前分数132
在pytorch版上做的改进
1.换模型
clip-vit-large-patch14 是两年前的模型
clip-vit-large-patch14-336是一年前的模型
秉着新的肯定会比老的效果好的想法分数从121->126不错!
2.然后还尝试改了一下single_video_result
然后就132了然后就没有了
第一次直播:
第二次直播:
相关文章:
Datawhale智能汽车AI挑战赛
1.赛题解析 赛题地址:https://tianchi.aliyun.com/competition/entrance/532155 任务: 输入:元宇宙仿真平台生成的前视摄像头虚拟视频数据(8-10秒左右);输出:对视频中的信息进行综合理解&…...
pyclipper和ClipperLib操作多边型
目录 1. 等距离缩放多边形 1.1 python 1.2 c 1. 等距离缩放多边形 1.1 python 环境配置pip install opencv-python opencv-contrib-python pip install pyclipper pip install numpy import cv2 import numpy as np import pyclipperdef equidistant_zoom_contour(contour…...
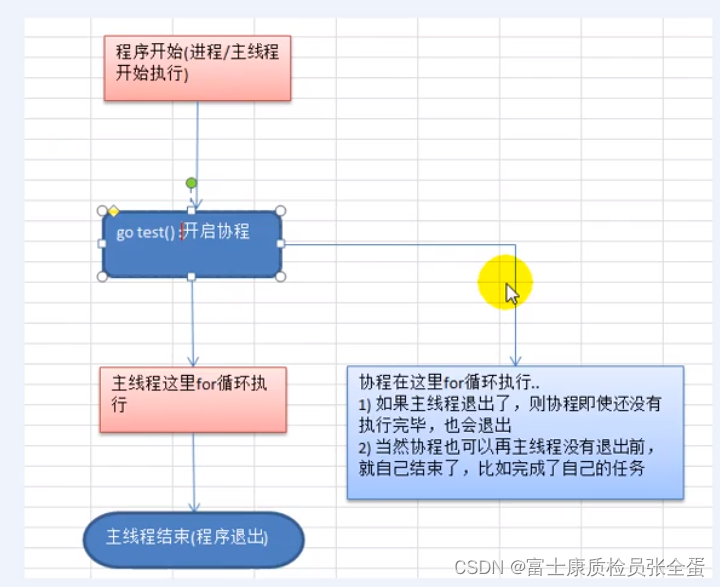
Golang 协程、主线程
Go协程、Go主线程 1)Go主线程(有程序员直接称为线程/也可以理解成进程):一个Go线程上,可以起多个协程,你可以这样理解,协程是轻量级的线程。 2)Go协程的特点 有独立的栈空间 共享程序堆空间 调度由用户控制 协程是轻量级的线程 go线程-…...

【SA8295P 源码分析】125 - MAX96712 解串器 start_stream、stop_stream 寄存器配置 过程详细解析
【SA8295P 源码分析】125 - MAX96712 解串器 start_stream、stop_stream 寄存器配置 过程详细解析 一、sensor_detect_device():MAX96712 检测解串器芯片是否存在,获取chip_id、device_revision二、sensor_detect_device_channels() :MAX96712 解串器 寄存器初始化 及 detec…...

pandas教程:Apply:General split-apply-combine 通常的分割-应用-合并
文章目录 10.3 Apply:General split-apply-combine(应用:通用的分割-应用-合并)1 Suppressing the Group Keys(抑制组键)2 Quantile and Bucket Analysis(分位数与桶分析)3 Example:…...
第一讲之递归与递推下篇
第一讲之递归与递推下篇 带分数费解的开关飞行员兄弟翻硬币 带分数 用暴力将所有全排列的情况都算出来 > 有三个数,a,b,c 每种排列情况,可以用两层for循环,暴力分为三个部分,每个部分一个数 当然注意这里,第一层fo…...

第十六篇-Awesome ChatGPT Prompts-备份
Awesome ChatGPT Prompts——一个致力于提供挖掘ChatGPT能力的Prompt收集网站 https://prompts.chat/ 2023-11-16内容如下 ✂️Act as a Linux Terminal Contributed by: f Reference: https://www.engraved.blog/building-a-virtual-machine-inside/ I want you to act as a…...

Python Web框架Django
Python Web框架Django Django简介第一个Django应用Django核心概念Django django-adminDjango项目结构Django配置文件settingsDjango创建和配置应用Django数据库配置Django后台管理Django模型Django模型字段Django模型关联关系Django模型Meta 选项Django模型属性ManagerDjango模…...

1.Spring的简单使用
简介 本文是介绍spring源码的开始,先了解最基础的使用,最深入源码。 spring源码下载地址 https://github.com/spring-projects/spring-framework.git 依赖 依赖 spring-context dependencies {implementation(project(":spring-context")…...
02.智慧商城——vant组件库使用和vw适配
01. vant组件库及Vue周边的其他组件库 组件库:第三方封装好了很多很多的组件,整合到一起就是一个组件库。 https://vant-contrib.gitee.io/vant/v2/#/zh-CN/ 比如日历组件、键盘组件、打分组件、下拉筛选组件等 组件库并不是唯一的,常用的组…...

Android笔记(十三):结合JetPack Compose和CameraX实现视频的录制和存储
在“Android笔记(八):基于CameraX库结合Compose和传统视图组件PreviewView实现照相机画面预览和照相功能”,文中介绍了拍照功能的实现,在本文中将介绍结合JetPack Compose和CameraX实现视频的录制。 新建一个项目 在项…...

【开题报告】基于SpringBoot的音乐鉴赏平台的设计与实现
1.研究背景与意义 音乐是人类文化的重要组成部分,具有广泛的影响力和吸引力。然而,随着数字化时代的到来,传统的音乐鉴赏方式面临一些挑战。因此,设计和开发一个基于Spring Boot的音乐鉴赏平台,能够满足用户对音乐欣赏…...
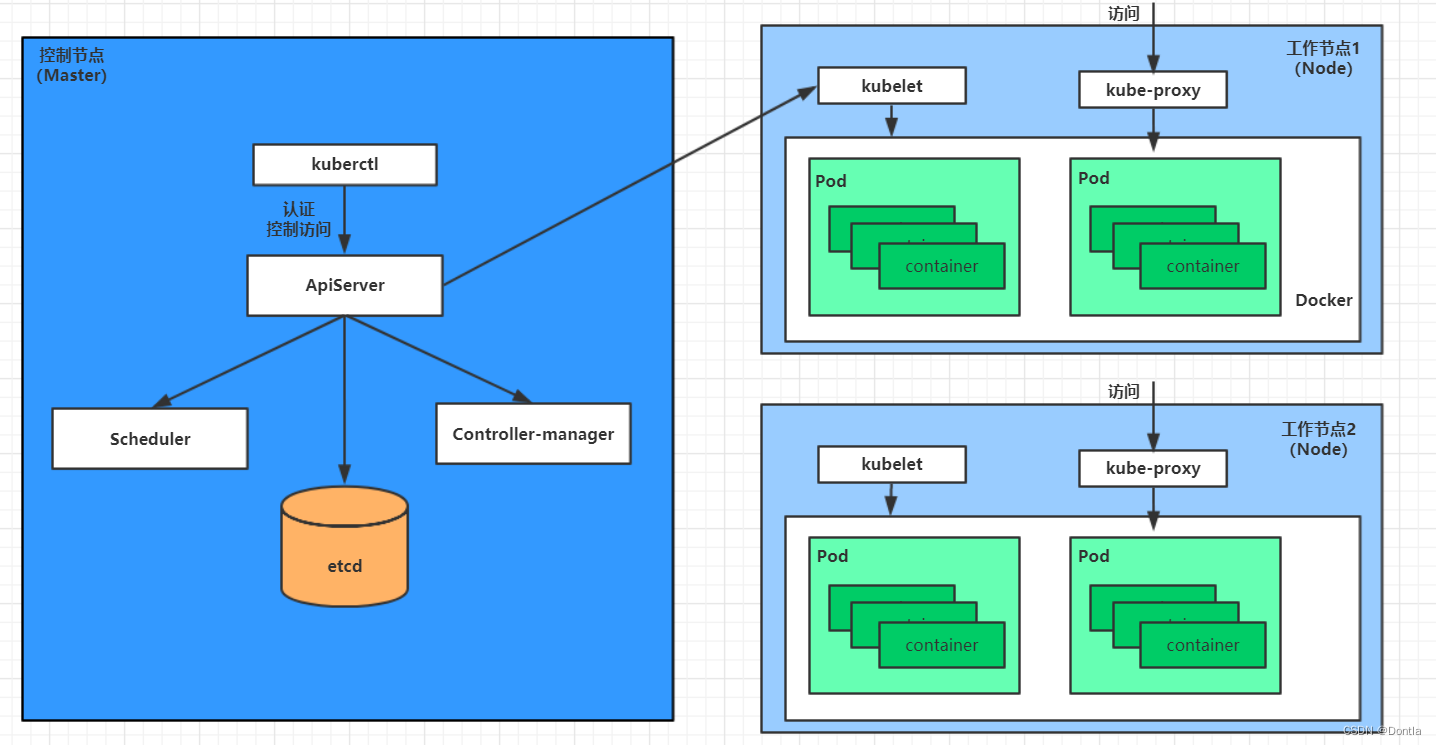
云原生 黑马Kubernetes教程(K8S教程)笔记——第一章 kubernetes介绍——Master集群控制节点、Node工作负载节点、Pod控制单元
参考文章:kubernetes介绍 文章目录 第一章 kubernetes介绍1.1 应用部署方式演变传统部署:互联网早期,会直接将应用程序部署在物理机上虚拟化部署:可以在一台物理机上运行多个虚拟机,每个虚拟机都是独立的一个环境&…...

ElasticSearch 安装(单机版本)
文章目录 ElasticSearch 安装(单机版本)环境配置下载安装包调整系统参数安装启动并验证 ElasticSearch 安装(单机版本) 此文档演示 ElasticSearch 的单机版本在 CentOS 7 环境下的安装方式以及相关的配置。 环境配置 Linux 主机一…...

读书笔记:《BackTrader 量化交易案例图解》
BackTrader 量化软件:https://github.com/mementum/backtrader -> bt 量化框架(前身):https://github.com/pmorissette/bt-> ffn 量化框架(前前身):https://github.com/pmorissette/ffn T…...

CentOS 7 免密密钥登陆sftp服务 —— 筑梦之路
为什么用sftp而不是ftp? sftp是使用ssh协议安全加密的文件传输协议,ftp在很多时候都是使用的明文传输,相对来说容易被抓包,存在安全隐患。 需求说明 1. 使用sftp代替ftp来做文件存储,锁定目录,不允许用户切…...

记一次 .NET 某券商论坛系统 卡死分析
一:背景 1. 讲故事 前几个月有位朋友找到我,说他们的的web程序没有响应了,而且监控发现线程数特别高,内存也特别大,让我帮忙看一下怎么回事,现在回过头来几经波折,回味价值太浓了。 二&#…...
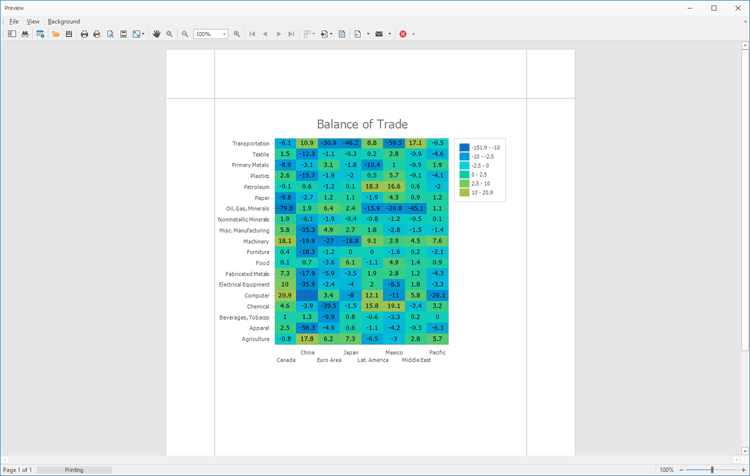
DevExpress WinForms HeatMap组件,一个高度可自定义热图控件!
通过DevExpress WinForms可以为Windows Forms桌面平台提供的高度可定制的热图UI组件,体验DevExpress的不同之处。 DevExpress WinForms有180组件和UI库,能为Windows Forms平台创建具有影响力的业务解决方案。同时能完美构建流畅、美观且易于使用的应用程…...

振弦传感器表面应变计与振弦采集仪形成岩土工程监测的解决方案
振弦传感器表面应变计与振弦采集仪形成岩土工程监测的解决方案 振弦传感器表面应变计与振弦采集仪可以结合使用,形成岩土工程监测的解决方案。具体的方案包括以下几个步骤: 1. 安装振弦传感器表面应变计:首先需要在需要监测的岩土结构表面安…...
笔记本电脑没有声音?几招恢复声音流畅!
笔记本电脑已经成为我们日常生活和工作的重要工具,而其中的声音是其功能之一。然而,有时您可能会遇到笔记本电脑没有声音的问题,这可能是由多种原因引起的。在本文中,我们将深入探讨笔记本电脑没有声音的常见原因,并提…...
来帮忙)
Linux内存不够用吧 Linux 交换内存(Swap)来帮忙
Linux内存不够用吧 Linux 交换内存(Swap)来帮忙 Linux 交换内存(Swap)完全指南:概念、配置与性能优化 我开发了一款内存管理工具,内存管理工具下载地址 1. 什么是交换内存(Swap)&a…...

数据库课程设计融合AI:使用PyTorch构建智能图书馆推荐系统
数据库课程设计融合AI:使用PyTorch构建智能图书馆推荐系统 1. 项目背景与价值 高校图书馆管理系统是数据库课程的经典设计选题,但传统方案往往只关注基本的增删改查功能。将AI推荐系统融入课程设计,不仅能让学生掌握数据库设计核心技能&…...

告别重复劳动:用快马AI智能生成OpenCode风格的高效工具函数
最近在开发一个需要大量表单验证的项目时,我发现每次都要重复写类似的验证逻辑,既浪费时间又容易出错。于是我开始寻找更高效的解决方案,最终在InsCode(快马)平台上找到了理想的工具。 需求分析 表单验证是每个Web项目都绕不开的基础功能。常…...

用Matlab模拟大气湍流和相机抖动:从模糊照片到清晰图像的完整复原实战
用Matlab模拟大气湍流和相机抖动:从模糊照片到清晰图像的完整复原实战 当你在高空航拍或长焦拍摄时,是否遇到过图像模糊不清的问题?这种模糊往往源于大气湍流或相机抖动。本文将带你深入理解这些退化现象的数学模型,并手把手教你用…...

3分钟净化微信社交圈:WechatRealFriends让200+好友检测效率提升99%的秘密
3分钟净化微信社交圈:WechatRealFriends让200好友检测效率提升99%的秘密 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/Wech…...

NCNN+OpenCV+Vulkan三件套:Windows环境下的深度学习加速实战教程
NCNNOpenCVVulkan三件套:Windows环境下的深度学习加速实战教程 在深度学习模型部署的战场上,Windows平台往往被开发者视为"次优选择"——直到NCNN、OpenCV和Vulkan这个黄金组合的出现。这个三件套解决方案正在改变游戏规则:NCNN提供…...

从零开始:roLabelImg安装与OBB旋转框标注实战指南
1. 为什么需要roLabelImg和旋转框标注 在计算机视觉项目中,我们经常需要标注图像中的目标物体。对于常规的矩形框标注,LabelImg这类工具已经足够好用。但遇到倾斜物体时,比如遥感图像中的飞机、自然场景中的交通标志、医学图像中的器官&#…...

PIPAL数据集实战:如何用Elo评分系统提升图像质量评估的准确性
PIPAL数据集实战:如何用Elo评分系统提升图像质量评估的准确性 在计算机视觉领域,图像质量评估(IQA)一直是算法研发的关键环节。随着生成对抗网络(GAN)等技术的突破,传统IQA方法逐渐暴露出局限性…...
Pixel Couplet Gen效果展示:抽象门神像素方块+动态卷轴交互演示
Pixel Couplet Gen效果展示:抽象门神像素方块动态卷轴交互演示 1. 项目概览 Pixel Couplet Gen是一款融合传统春节文化与现代像素艺术风格的AI春联生成器。通过ModelScope大模型驱动,将传统春联创作转化为充满游戏感的数字体验。 核心特点:…...

解锁知识:9种突破信息壁垒的创新方案
解锁知识:9种突破信息壁垒的创新方案 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在信息爆炸的数字时代,高效的"信息获取"与"资源解锁"…...