【Python大数据笔记_day08_hive查询】
hive查询
语法结构:
SELECT [ALL | DISTINCT] 字段名, 字段名, ... FROM 表名 [inner | left outer | right outer | full outer | left semi JOIN 表名 ON 关联条件 ] [WHERE 非聚合条件] [GROUP BY 分组字段名] [HAVING 聚合条件] [ORDER BY 排序字段名 asc | desc] [CLUSTER BY 字段名 | [DISTRIBUTE BY 字段名 SORT BY 字段名]] [LIMIT x,y]
类sql基本查询
基础查询格式: select distinct 字段名 from 表名; 注意: *代表所有字段 distinct去重 as给表或者字段起别名 条件查询格式: select distinct 字段名 from 表名 where 条件;比较运算符: > < >= <= != <>逻辑运算符: and or not模糊查询: %代表任意0个或者多个字符 _代表任意1个字符空判断: 为空is null 不为空is not null范围查询: x到y的连续范围:between x and y x或者y或者z类的非连续范围: in(x,y,z) 排序查询格式: select distinct 字段名 from 表名 [where 条件] order by 排序字段名 asc|desc ;asc : 升序 默认升序desc: 降序 聚合查询格式: select 聚合函数(字段名) from 表名;聚合函数: 又叫分组函数或者统计函数聚合函数: count() sum() avg() max() min() 分组查询格式: select 分组字段名,聚合函数(字段名) from 表名 [where 非聚合条件] group by 分组字段名 [having 聚合条件];注意: 当分组查询的时候,select后的字段名要么在groupby后出现过,要么放在聚合函数内,否则报错where和having区别? 区别1: 书写顺序不同,where在group by关键字前,having在group by关键字后区别2: 执行顺序不同,where在分组之前过滤数据,having在分组之后过滤数据区别3: 筛选数据不同,where只能在分组之前过滤非聚合数据,having在分组之后主要过滤聚合数据区别4: 操作对象不同,where底层操作伪表,having底层操作运算区 分页查询格式: select 字段名 from 表名 [ order by 排序字段名 asc|desc] limit x,y;x: 起始索引 默认从0开始,如果x为0可以省略 计算格式: x=(页数-1)*yy: 本次查询记录数
数据准备:
-- 创建订单表
CREATE TABLE orders (orderId bigint COMMENT '订单id',orderNo string COMMENT '订单编号',shopId bigint COMMENT '门店id',userId bigint COMMENT '用户id',orderStatus tinyint COMMENT '订单状态 -3:用户拒收 -2:未付款的订单 -1:用户取消 0:待发货 1:配送中 2:用户确认收货',goodsMoney double COMMENT '商品金额',deliverMoney double COMMENT '运费',totalMoney double COMMENT '订单金额(包括运费)',realTotalMoney double COMMENT '实际订单金额(折扣后金额)',payType tinyint COMMENT '支付方式,0:未知;1:支付宝,2:微信;3、现金;4、其他',isPay tinyint COMMENT '是否支付 0:未支付 1:已支付',userName string COMMENT '收件人姓名',userAddress string COMMENT '收件人地址',userPhone string COMMENT '收件人电话',createTime timestamp COMMENT '下单时间',payTime timestamp COMMENT '支付时间',totalPayFee int COMMENT '总支付金额'
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- 加载数据(因为是普通内部表可以直接上传文件到hfds表路径下)数仓分层思想:
-- 数仓分层: 本质就是分库分表
-- 构建源数据层
create database xls_ods;
-- 构建数数据仓库
create database xls_dw;
-- 构建数据应用层
create database xls_da;
-- 转换应用场景
-- 注意: 在大数据分析中转换完后为了以后方便使用一般存储起来
create table xls_dw.dw_orders as
selectorderid,orderno,shopid,userid,orderstatus,goodsmoney,delivermoney,totalmoney,realtotalmoney,casewhen payType=0 then '未知'when payType=1 then '支付宝'when payType=2 then '微信'when payType=3 then '现金'when payType=4 then '其他'end as payType,payType,username,useraddress,userphone,createtime,paytime,totalpayfee
from orders;
-- 修改字段类型
alter table dw_orders change orderstatus orderstatus string;
alter table dw_orders change ispay ispay string;
-- 修改后重新修改了,需要覆盖数据
insert overwrite table xls_dw.dw_orders
selectorderid,orderno,shopid,userid,casewhen orderstatus=-3 then '用户拒收'when orderstatus=-2 then '未付款的订单'when orderstatus=-1 then '用户取消'when orderstatus=0 then '待发货'when orderstatus=1 then '配送中'when orderstatus=2 then '用户确认收货'endas orderstatus,goodsmoney,delivermoney,totalmoney,realtotalmoney,casewhen payType=0 then '未知'when payType=1 then '支付宝'when payType=2 then '微信'when payType=3 then '现金'when payType=4 then '其他'end as payType,
casewhen isPay=0 then '未支付'when isPay=1 then '已支付'end as isPay,username,useraddress,userphone,createtime,paytime,totalpayfee
from orders;课堂练习:
-- 基础查询格式: select distinct 字段名 from 表名;
-- 注意: *代表所有字段 distinct去重 as给表或者字段起别名且可以省略
-- 指定字段查询
select userName,userPhone from orders where userName='邓力夫';
-- 指定字段并且取别名查询
select distinct userName name,userPhone phone from orders where userName='邓力夫';
-- 当然也可以给表起别名(目前单表即使起了也没有多大意义)
select o.userName ,o.userPhone from orders as o ;
-- 查询支付类型要求去重
select distinct payType from orders;
-- 2.演示where条件查询
-- 查询广东省订单
drop table if exists da_gd_orders;
create table da_gd_orders as
select * from orders where userAddress like '广东省%';
-- 3.演示聚合查询
-- 查询广东省数据量
select count(*) from orders where userAddress like '广东省%';
-- 4.演示分组查询
-- 注意: select后的字段要么在groupby后出现要么在聚合函数内出现,否则报错
-- 统计已支付和未支付各自多少人
select isPay,count(*) cnt from orders group by isPay;
-- 5.演示条件查询,聚合查询,分组查询综合练习
-- 在已支付订单中,统计每个用户最高的一笔消费金额
select userId, username, max(realTotalMoney)
from orders
where isPay = 1
group by userId, username;
-- 统计每个用户的平均消费金额
select userId, username, avg(realTotalMoney)
from orders
where isPay = 1
group by userId, username;
-- 统计每个用户的平均消费金额并且筛选大于10000的
select userId, username, avg(realTotalMoney) as avg_money
from orders
where isPay = 1
group by userId, username
having avg_money > 10000;
-- 统计每个用户的平均消费金额并且筛选大于10000的,平均值要求保留2位小数
select userId, username,round(avg(realTotalMoney),2)
from orders
where isPay = 1
group by userId, username
having round(avg(realTotalMoney),2) > 10000;
-- 6.演示排序查询
-- asc默认升序 desc 降序
-- 查询广东省订单,要求按照总价降序排序
select * from orders where userAddress like '广东省%' order by realTotalMoney desc;
-- 7.演示分页查询
-- limit x,y 注意: x和y都是整数,x是从0开始起始索引,y是查询的条数
-- 查询广东省订单总价最高的前5个订单
select * from orders where userAddress like '广东省%' order by realTotalMoney desc limit 5;类sql多表查询
交叉连接格式: select 字段名 from 左表 cross join 右表;注意: 交叉连接产生的结果叫笛卡尔积,此种方式慎用!!! 内连接格式: select 字段名 from 左表 inner join 右表 on 左右表关联条件;特点: 相当于只取两个表的交集 左外连接格式: select 字段名 from 左表 left outer join 右表 on 左右表关联条件;特点: 以左表为主,左表数据全部保留,右表只保留和左表有交集的部分 右外连接格式: select 字段名 from 左表 right outer join 右表 on 左右表关联条件;特点: 以右表为主,右表数据全部保留,左表只保留和右表有交集的部分 自连接: 本质是一个特殊的内外连接,最大特点就是左右表是同一个表应用场景: 比较局限,场景1: 存储省市县三级数据的区域表 场景2: 存储上下级信息的员工表 子查询: 本质是一个select语句作为另外一个select语句的一部分(表或者条件)注意: 子查询作为表使用的话必须取别名
数据准备:
-- 创建用户表
CREATE TABLE users (userId int,loginName string,loginSecret int,loginPwd string,userSex tinyint,userName string,trueName string,brithday date,userPhoto string,userQQ string,userPhone string,userScore int,userTotalScore int,userFrom tinyint,userMoney double,lockMoney double,createTime timestamp,payPwd string,rechargeMoney double
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- 加载数据
load data inpath '/source/itheima_users.txt' into table users;
-- 验证数据
select * from users limit 1;练习:
-- 交叉连接格式: select 字段名 from 左表 cross join 右表;
-- 注意: 交叉连接产生的结果叫笛卡尔积,此种方式慎用!!!
select * from users cross join orders;
-- 内连接格式: select 字段名 from 左表 inner join 右表 on 左右表关联条件;
-- 特点: 相当于只取两个表的交集
select * from users u inner join orders o on u.userId=o.userId ;
-- 左外连接格式: select 字段名 from 左表 left outer join 右表 on 左右表关联条件;
-- 特点: 以左表为主,左表数据全部保留,右表只保留和左表有交集的部分
select * from users u left outer join orders o on u.userId=o.userId ;
-- 右外连接格式: select 字段名 from 左表 right outer join 右表 on 左右表关联条件;
-- 特点: 以右表为主,右表数据全部保留,左表只保留和右表有交集的部分
select * from users u right outer join orders o on u.userId=o.userId ;
-- 自连接: 本质是一个特殊的内外连接,最大特点就是左右表是同一个表
-- 应用场景: 比较局限,场景1: 存储省市县三级数据的区域表 场景2: 存储上下级信息的员工表
-- 可以运行下基础班的areas.sql脚本,做以下练习
-- 方式1: 建议
select xian.title
from(select * from areas where title = '北京市' and pid is not null) city
joinareas xian
on city.id = xian.pid;
-- 方式2:
select xian.title
fromareas city
joinareas xian
on city.id = xian.pid
where city.title = '北京市' and city.pid is not null;
-- 子查询: 本质是一个select语句作为另外一个select语句的一部分(表或者条件)
-- 注意: 子查询作为表使用的话必须取别名
;
select title
from areas
where pid = (select id from areas where title = '北京市' and pid is not null);hive其他join操作
在Hive中除了支持cross join(交叉连接,也叫做笛卡尔积),inner join(内连接)、left outer join(左外连接)、right outer join(右外连接)还支持full outer join(全外连接)、left semi join(左半开连接)
全外连接: 左表 full [outer] join 右表 on 条件 左半开连接: 左表 left semi join 右表 on 条件
-- hive不同于mysql的join操作
-- 全外连接(左表 full outer join 右表 on 条件) 大白话就是左外和右外结果合并同时去重
select * from users u full outer join orders o on u.userId = o.userId;
-- 左半开连接(左表 left semi join 右表 on 条件) 大白话就是内连接的一半
select * from users u left semi join orders o on u.userId = o.userId;hive其他排序操作
set mapreduce.job.reduces: 查看当前设置的reduce数量 默认结果是-1,代表自动匹配reduce数量和桶数量一致 set mapreduce.job.reduces = 数量 : -- 修改reduces数量 cluster by 字段名: 分桶且正序排序 弊端: 分和排序是同一个字段,相对不灵活 distribute by 字段名 sort by 字段名: distribute by负责分,sort by负责排序, 相对比较灵活 order by 字段名:全局排序 注意: cluster by 和 distribute by 字段名 sort by 字段名 受当前设置的reduces数量影响,但是设置的reduces数量对order by无影响,因为orderby就是全局排序,就是一个reduce 建表的时候指定分桶字段和排序字段: clustered by (字段名) sorted by (字段名) into 桶数量 buckets注意: 如果建表的时候设置了桶数量,那么reduces建议设置值-1或者值大于桶数量
-- 演示4个by区别
-- 创建表
create table students(id int,name string,gender string,age int,cls string
)row format delimited
fields terminated by ',';
-- 加载数据
load data inpath '/source/students.txt' into table students;
-- 验证数据
select * from students limit 1;
-- 查询reduces的数量
set mapreduce.job.reduces; -- -1代表根据任务实时改变
-- 1.cluster by 字段名 查询的时候分桶且排序
-- 注意: 如果是1个reduces那么cluster by全局升序排序
select * from students cluster by id;
-- 修改reduces数量为3
set mapreduce.job.reduces=3;
-- 再次使用cluster by查询,查看效果
-- 效果: 如果多个reduces那么cluster by桶内局部排序
select * from students cluster by age;
-- 2.distribute by + sort by
-- 设置reduces的数量为-1
set mapreduce.job.reduces = -1;
-- 默认1个ruduces数量,使用distribute by + sort by查询观察结果
-- 注意: 如果是1个ruduces那么distribute by + sort by全局排序
select * from students distribute by name sort by age desc;
-- 修改reduces数量
set mapreduce.job.reduces = 2;
-- 再次distribute by + sort by查询
-- 效果: 如果多个redueces,那么distribute by 分reduces数量个桶,sort by桶内局部排序
select * from students distribute by name sort by age desc;
-- 3.order by
-- 注意: order by 永远都是全局排序,不受reduces数量影响,每次只用1个reduces
select * from students order by age desc;抽样查询
TABLESAMPLE抽样好处: 尽可能实现随机抽样,并且不走MR查询效率相对较快 基于随机分桶抽样格式: SELECT 字段名 FROM tbl TABLESAMPLE(BUCKET x OUT OF y ON(字段名 | rand()))y:表示将表数据随机划分成y份(y个桶)x:表示从y里面随机抽取x份数据作为取样| : 或者字段名: 表示随机的依据基于某个列的值,每次按相关规则取样结果都是一致rand(): 表示随机的依据基于整行,每次取样结果不同
-- 随机抽样函数 tablesample
-- 参考字段分桶抽样,快且随机
select * from orders tablesample ( bucket 1 out of 10 on orderid);
-- 参考rand()随机数,快且真正达到随机
select * from orders tablesample ( bucket 1 out of 10 on rand());
-- 快速取前面部分数据 : 快但没有随机
-- 前100条
select * from orders tablesample ( 100 rows );
-- 前10%数据
select * from orders tablesample ( 10 percent );
-- 取1k或者1m的数据
select * from orders tablesample ( 16k );
select * from orders tablesample ( 167k );
select * from orders tablesample ( 1m );
-- 随机取100条: 随机但是不快
select * from orders distribute by rand() sort by rand() limit 100;正则模糊查询
sql模糊查询关键字: like 任意0个或者多个: % 任意1个: _ 正则模糊查询关键字: rlike 任意0个或者多个: .* 任意1个: . 正则语法还有很多...
-- 正则表达式查询
-- 1.查询广东省数据
-- sql模糊查询
select * from orders where userAddress like '广东省%';
-- 正则模糊查询
select * from orders where userAddress rlike '广东省.*';
-- 2. 查询满足'xx省 xx市 xx区'格式的信息
-- sql模糊查询
select * from orders where userAddress like '__省 __市 __区';
-- 正则模糊查询
select * from orders where userAddress rlike '..省 ..市 ..区';
-- 3.查询所有姓张王邓的用户信息
-- sql模糊查询
select * from orders where username like '张%' or username like '王%' or username like '邓%' ;
-- 正则模糊查询
select * from orders where username rlike '[张王邓].*';
select * from orders where username rlike "[张王邓].+";
-- 4.查找所有188开头的手机号
-- sql模糊查询
select * from orders where userPhone like '188________' ;
-- 正则模糊查询
select * from orders where userPhone rlike '188........' ;
select * from orders where userPhone rlike '188.{8}' ;
select * from orders where userPhone rlike '188\\*{4}[0-9]{4}' ;
select * from orders where userPhone rlike '188\\*{4}\\d{4}' ;union联合查询
union联合查询: 就是把两个select语句结果合并成一个临时结果集,整体可以用于其他sql操作 union [distinct]: 去重,只是省略了distinct union all : 不去重
-- 插入数据
insert into product values('p1','联想','c1'),('p2','小米','c2'),('p3','华为',null);
-- 创建分类表
create table category(cid varchar(100),cname varchar(100)
);
-- 插入数据
insert into category values('c1','电脑'),('c2','手机'),('c3','服饰');
-- 1.如果在mysql中,使用union实现全外连接
-- 使用union关键字,自动去重
-- 左外 union 右外
select pid,pname,p.cid,cname from product p left join category c on p.cid = c.cid
union
select pid,pname,c.cid,cname from product p right join category c on p.cid = c.cid;
-- 注意: 如果不想去重使用 union all
-- 左外 union all 右外
select pid,pname,p.cid,cname from product p left join category c on p.cid = c.cid
union all
select pid,pname,c.cid,cname from product p right join category c on p.cid = c.cid;
-- 2.在hive中使用full outer join实现全外连接
select pid,pname,c.cid,cname from product p full join category c on p.cid = c.cid;CTE表达式
CTE: 公用表表达式(CTE)是一个在查询中定义的临时命名结果集将在from子句中使用它。 注意: 每个CTE仅被定义一次(但在其作用域内可以被引用任意次),仅适用于当前运行的sql语句 语法如下:with 临时结果集的别名1 as (子查询语句),临时结果集的别名2 as (子查询语句)...select 字段名 from (表别名);
内置虚拟列
虚拟列是Hive内置的可以在查询语句中使用的特殊标记,可以查询数据本身的详细参数。 Hive目前可用3个虚拟列: INPUT__FILE__NAME:显示数据行所在的具体文件 BLOCK__OFFSET__INSIDE__FILE:显示数据行所在文件的偏移量 ROW__OFFSET__INSIDE__BLOCK:显示数据所在HDFS块的偏移量 注意: 此虚拟列需要设置:SET hive.exec.rowoffset=true 才可使用
-- 演示内置虚拟列
-- 打开ROW__OFFSET__INSIDE__BLOCK
SET hive.exec.rowoffset=true;
-- 演示查询
SELECT *, INPUT__FILE__NAME, BLOCK__OFFSET__INSIDE__FILE, ROW__OFFSET__INSIDE__BLOCK FROM students_bucket;相关文章:

【Python大数据笔记_day08_hive查询】
hive查询 语法结构: SELECT [ALL | DISTINCT] 字段名, 字段名, ... FROM 表名 [inner | left outer | right outer | full outer | left semi JOIN 表名 ON 关联条件 ] [WHERE 非聚合条件] [GROUP BY 分组字段名] [HAVING 聚合条件] [ORDER BY 排序字段名 asc | desc] [CLUSTE…...

魔众文库系统 v5.6.0 DWG文件格式支持,部分数据封面显示异常,定时调度清理临时文件
魔众文库系统基于文档系统知识,建立平台与领域,打造流量、用户、付费和变现的闭环,帮助您更好的搭建文库系统。 魔众文库系统发布v5.6.0版本,新功能和Bug修复累计17项,DWG文件格式支持,部分数据封面显示异…...

2023 PostgreSQL 数据库生态大会:解读拓数派大数据计算系统及其云存储底座
11月3日-5日,由中国开源软件推进联盟 PostgreSQL 分会主办的中国 PostgreSQL 数据库生态大会在北京中科院软件所隆重举行。大会以”极速进化融合新生”为主题,从线下会场和线上直播两种方式展开,邀请了数十位院士、教授、高管和社群专家&…...
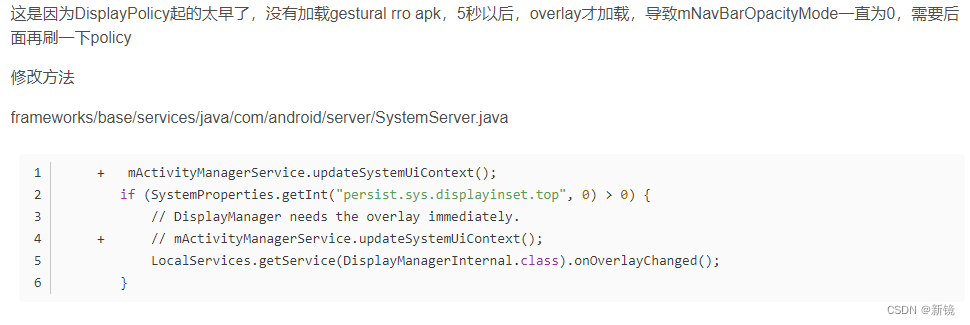
Android10 手势导航
种类 Android10 默认的系统导航有三种: 1.两个按钮的 2.三个按钮的 3.手势 它们分别对应三个包名 frameworks/base/packages/overlays/NavigationBarMode2ButtonOverlay frameworks/base/packages/overlays/NavigationBarMode3ButtonOverlay frameworks/base/packa…...

Pinia 插件 pinia-plugin-persist 添加 persist 属性时报错:没有与此调用匹配的重载
项目场景: Vue3TS 语言Pinia插件:pinia-plugin-persist 问题描述 代码如下: import { defineStore } from piniaexport const useInfoStore defineStore(info, {state: () > {return {activeIndex: 0}},actions: {updateIndex(active…...

Django知识
目录 一.request对象方法 1.request.method 2.request.POST 3.request.GET 4.request.FILES 5.request.path 二.FBV与CBV引入 1.FBV 2.CBV (1)路由 (2)视图 3.详解 (1)FBV (2)CBV (3)小结 三.CBV源码剖析 1.as_view方法 (1)路由对应函…...
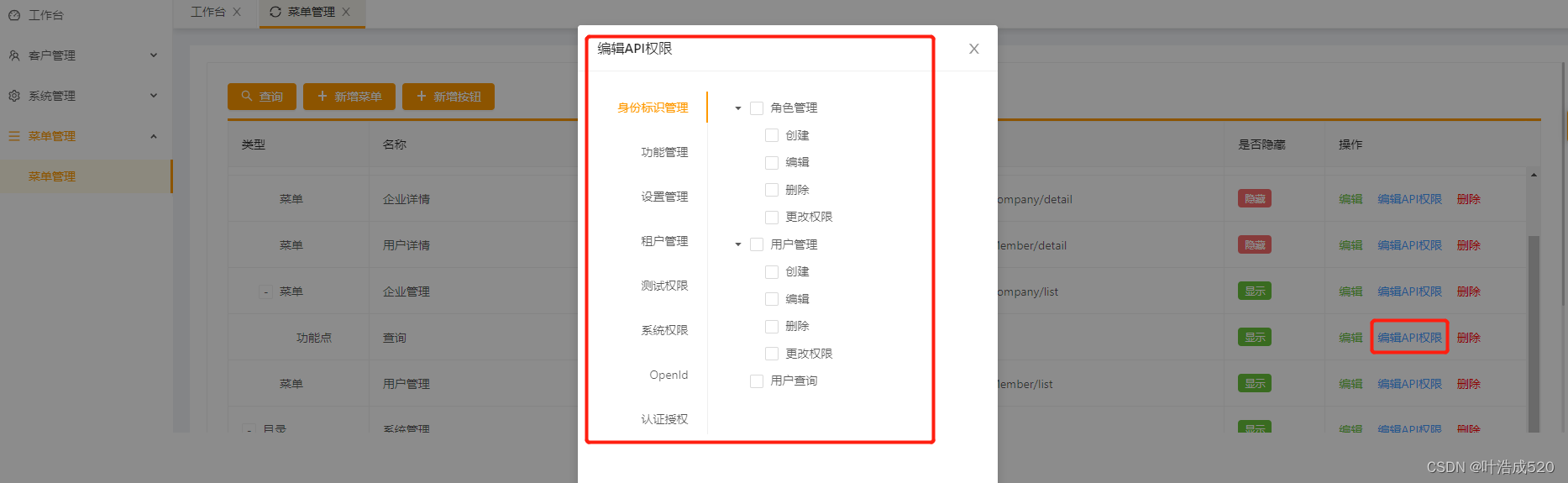
vue2+antd——实现权限管理——js数据格式处理(回显+数据结构渲染)
vue2antd——实现权限管理——js数据格式处理 效果图如下:1.需求说明2.如何展开所有子项及孙子项目——在弹窗之前就获取树形结构,然后直接将数据传到弹窗中3.template部分代码4.script的data部分5.权限tree数据处理——将row中的权限分配到具体的value参…...
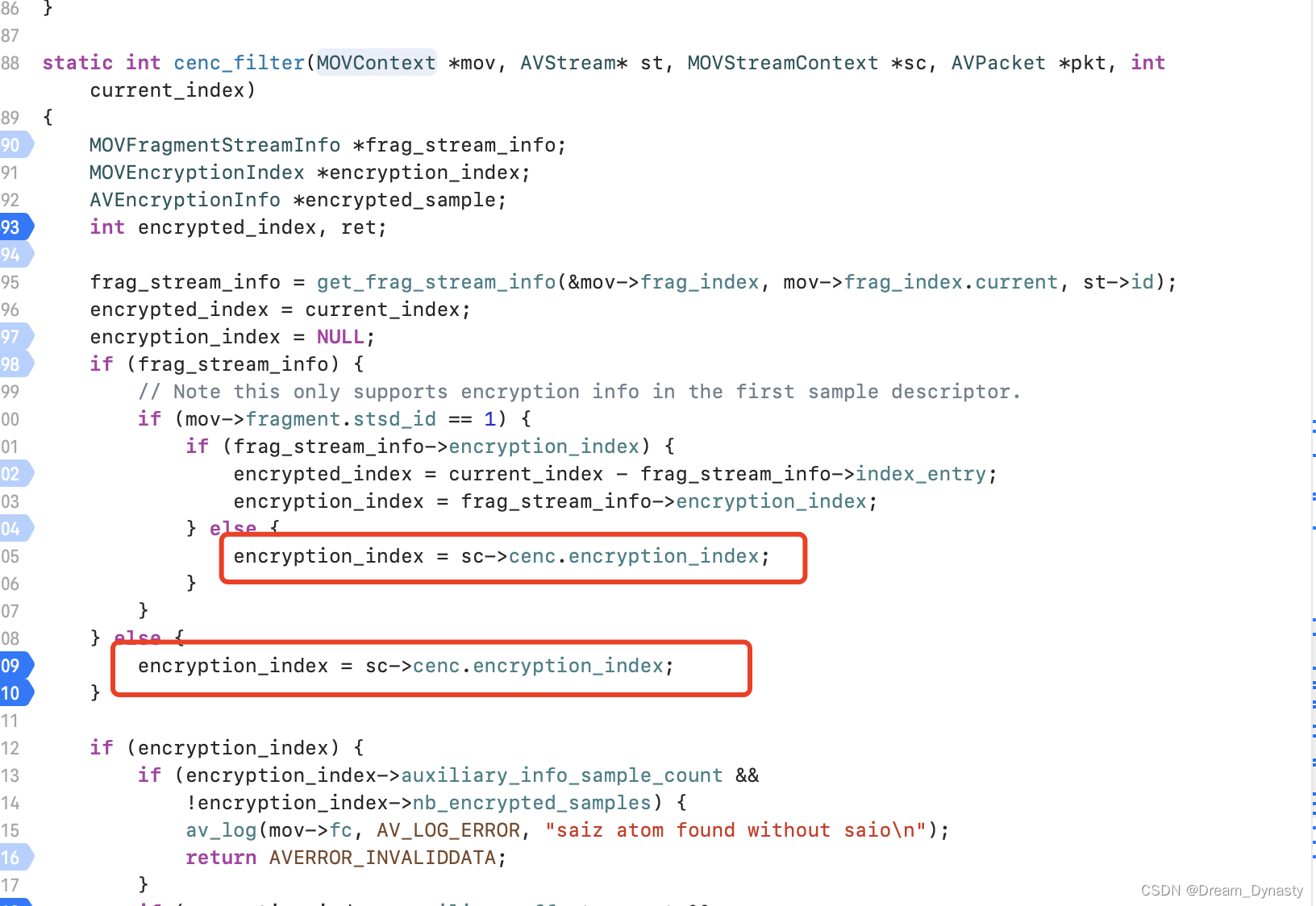
ffmpeg 4.4 cenc-aes-ctr 加解密 MP4 工程性质分析
目录 一、cenc-aes-ctr 原理介绍 二、显式 cenc-aes-ctr 和隐式 cenc-aes-ctr 三、加密工具---ffmpeg 四、播放---ffplay 五、总结 一、cenc-aes-ctr 原理介绍 加密算法:CENC-AES-CTR 使用 AES(Advanced Encryption Standard&…...
网络安全/黑客技术(0基础入门到进阶提升)
前言 前几天发布了一篇 网络安全(黑客)自学 没想到收到了许多人的私信想要学习网安黑客技术!却不知道从哪里开始学起!怎么学 今天给大家分享一下,很多人上来就说想学习黑客,但是连方向都没搞清楚就开始学习…...
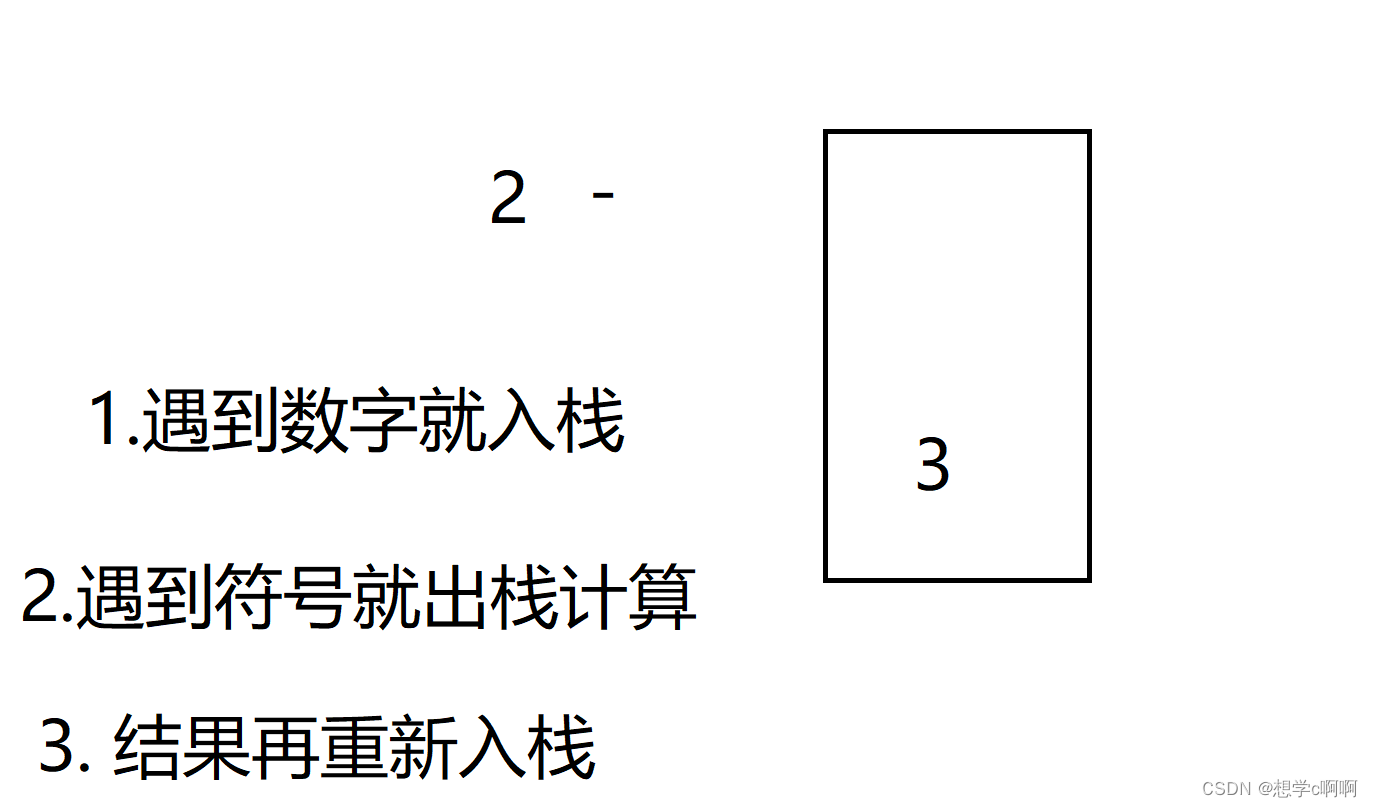
栈的三道oj【C++】
栈和队列的相关oj 最小栈思路解决代码 栈的压入弹出序列思路解决代码 逆波兰表达式思路:解决代码 这里就挑了三道题用来熟悉栈 最小栈 力扣链接 咱们已经是高贵的C使用者了,不用像C语言一样从头开始造轮子了 这里我们调用了stack后,就会发…...

AI大模型低成本快速定制法宝:RAG和向量数据库
文章目录 1. 前言2. RAG和向量数据库3. 论坛日程4. 购票方式 1. 前言 当今人工智能领域,最受关注的毋庸置疑是大模型。然而,高昂的训练成本、漫长的训练时间等都成为了制约大多数企业入局大模型的关键瓶颈。 这种背景下,向量数据库凭借其独特…...

文旅媒体有哪些?如何邀请到现场报道?
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 中国文旅产业在近年来得到了持续而快速的发展。从产业端看,中国文旅产业呈现出新的发展趋势,其中“文旅”向“文旅”转变成为显著特点。通过产业升级和空间构建&a…...

搭建知识付费系统的最佳实践是什么
在数字化时代,搭建一个高效且用户友好的知识付费系统是许多创业者和内容创作者追求的目标。本文将介绍一些搭建知识付费系统的最佳实践,同时提供一些基本的技术代码示例,以帮助你快速入门。 1. 选择合适的技术栈: 搭建知识付费…...

计算机视觉:使用opencv实现车牌识别
1 引言 汽车车牌识别(License Plate Recognition)是一个日常生活中的普遍应用,特别是在智能交通系统中,汽车牌照识别发挥了巨大的作用。汽车牌照的自动识别技术是把处理图像的方法与计算机的软件技术相连接在一起,以准…...

用封面预测书的价格【图像回归】
今天,我将介绍计算机视觉的深度学习应用,用封面简单地估算一本书的价格。 我没有看到很多关于图像回归的文章,所以我为你们写这篇文章。 距离我上一篇文章已经过去很长时间了,我不得不承认,作为一名数据科学家&#x…...
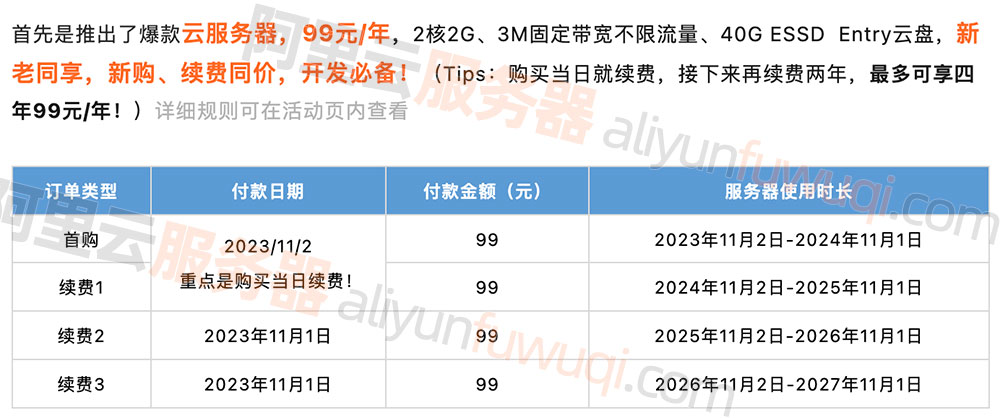
阿里云服务器e实例40G ESSD Entry系统盘、2核2G3M带宽99元
阿里云99元服务器新老用户同享2核2G经济型e实例、3M固定带宽和40G ESSD Entry系统盘,老用户也可以买,续费不涨价依旧是99元一年,阿里云百科aliyunbaike.com分享阿里云3M带宽服务器40G ESSD Entry云盘性能说明: 阿里云99元服务器配…...
Datawhale智能汽车AI挑战赛
1.赛题解析 赛题地址:https://tianchi.aliyun.com/competition/entrance/532155 任务: 输入:元宇宙仿真平台生成的前视摄像头虚拟视频数据(8-10秒左右);输出:对视频中的信息进行综合理解&…...
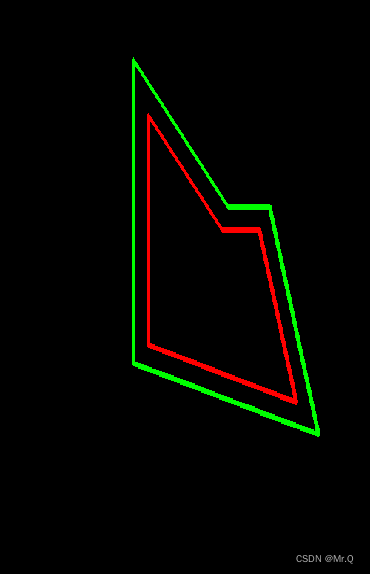
pyclipper和ClipperLib操作多边型
目录 1. 等距离缩放多边形 1.1 python 1.2 c 1. 等距离缩放多边形 1.1 python 环境配置pip install opencv-python opencv-contrib-python pip install pyclipper pip install numpy import cv2 import numpy as np import pyclipperdef equidistant_zoom_contour(contour…...
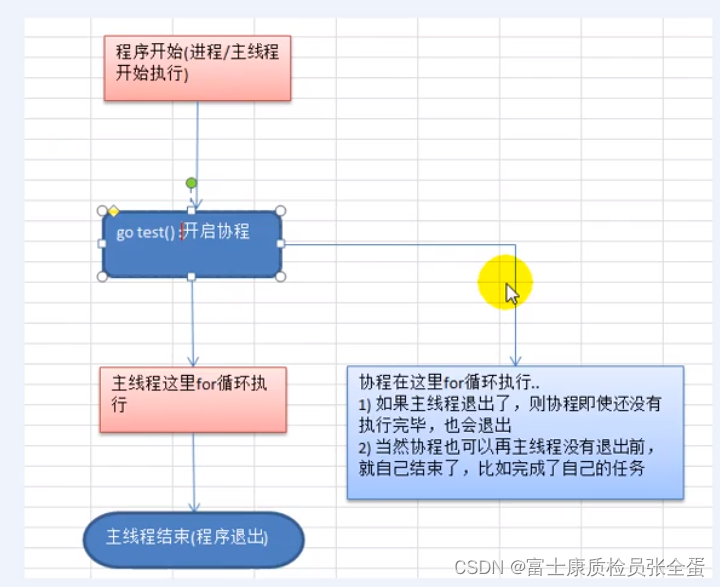
Golang 协程、主线程
Go协程、Go主线程 1)Go主线程(有程序员直接称为线程/也可以理解成进程):一个Go线程上,可以起多个协程,你可以这样理解,协程是轻量级的线程。 2)Go协程的特点 有独立的栈空间 共享程序堆空间 调度由用户控制 协程是轻量级的线程 go线程-…...

【SA8295P 源码分析】125 - MAX96712 解串器 start_stream、stop_stream 寄存器配置 过程详细解析
【SA8295P 源码分析】125 - MAX96712 解串器 start_stream、stop_stream 寄存器配置 过程详细解析 一、sensor_detect_device():MAX96712 检测解串器芯片是否存在,获取chip_id、device_revision二、sensor_detect_device_channels() :MAX96712 解串器 寄存器初始化 及 detec…...
)
树莓派4B避坑指南:手把手教你安装兼容的Miniconda 4.9.2(aarch64版)
树莓派4B避坑指南:手把手教你安装兼容的Miniconda 4.9.2(aarch64版) 树莓派4B作为一款高性能的单板计算机,凭借其强大的aarch64架构和丰富的扩展能力,成为众多开发者和爱好者的首选。然而,在安装Miniconda这…...

告别繁琐操作:用快马AI定制你的智能FileZilla,实现自动化文件管理
告别繁琐操作:用快马AI定制你的智能FileZilla,实现自动化文件管理 作为一个经常需要处理文件传输的开发人员,我深知传统FTP工具的局限性。每次都要重复配置服务器信息,手动同步文件夹,还要花时间筛选文件,…...

NVMe-CLI:Linux系统下NVMe固态硬盘管理的瑞士军刀
NVMe-CLI:Linux系统下NVMe固态硬盘管理的瑞士军刀 【免费下载链接】nvme-cli NVMe management command line interface. 项目地址: https://gitcode.com/gh_mirrors/nv/nvme-cli 你是否曾经为Linux系统中的NVMe固态硬盘管理而烦恼?想要查看设备健…...

掌握LiteDB.Studio:嵌入式文档数据库可视化管理工具全攻略
掌握LiteDB.Studio:嵌入式文档数据库可视化管理工具全攻略 【免费下载链接】LiteDB.Studio A GUI tool for viewing and editing documents for LiteDB v5 项目地址: https://gitcode.com/gh_mirrors/li/LiteDB.Studio 在现代软件开发中,嵌入式数…...

CLAP音频分类环境部署:Python3.8+PyTorch+Gradio一键配置指南
CLAP音频分类环境部署:Python3.8PyTorchGradio一键配置指南 想不想让电脑“听懂”声音?比如,上传一段音频,它就能告诉你这是狗叫、猫叫还是汽车鸣笛。这听起来像是科幻电影里的场景,但现在,借助一个叫CLAP…...

2026年华为云OpenClaw如何安装?配置百炼API零门槛10分钟步骤
2026年华为云OpenClaw如何安装?配置百炼API零门槛10分钟步骤。OpenClaw(曾用名Clawdbot)是一款轻量化、可扩展的开源AI智能体执行框架,支持自然语言指令驱动、多模型灵活切换与全场景任务自动化。对于新手而言,阿里云轻…...
下的隐性崩溃风险:JDK17~21版本兼容性断层分析(仅限内测团队知晓))
ZGC在超大堆(>16TB)下的隐性崩溃风险:JDK17~21版本兼容性断层分析(仅限内测团队知晓)
第一章:ZGC在超大堆(>16TB)下的隐性崩溃风险:JDK17~21版本兼容性断层分析(仅限内测团队知晓)当堆内存突破16TB阈值后,ZGC在JDK17至JDK21的多个GA版本中暴露出未公开的元数据结构越界行为——…...

像素幻梦·创意工坊应用场景:独立音乐人专辑封面像素艺术生成流程
像素幻梦创意工坊应用场景:独立音乐人专辑封面像素艺术生成流程 1. 引言:像素艺术在音乐视觉中的价值 在数字音乐时代,专辑封面依然是艺术家表达音乐理念的重要载体。对于独立音乐人而言,独特的视觉风格往往能成为作品的标志性符…...

SketchUp STL开源工具:让3D设计无缝转化为可打印模型的完整方案
SketchUp STL开源工具:让3D设计无缝转化为可打印模型的完整方案 【免费下载链接】sketchup-stl A SketchUp Ruby Extension that adds STL (STereoLithography) file format import and export. 项目地址: https://gitcode.com/gh_mirrors/sk/sketchup-stl 在…...

万物识别镜像高级功能探索:除了基础识别,还能做什么?
万物识别镜像高级功能探索:除了基础识别,还能做什么? 1. 万物识别镜像的隐藏潜力 大多数人使用万物识别镜像时,只停留在基础识别功能上——上传图片,获取识别结果。但这款基于cv_resnest101_general_recognition算法…...