部署百川大语言模型Baichuan2
Baichuan2是百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练。在多个权威的中文、英文和多语言的通用、领域 benchmark 上取得同尺寸最佳的效果。包含有 7B、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits 量化。
模型下载
基座模型
Baichuan2-7B-Base
https://huggingface.co/baichuan-inc/Baichuan2-7B-Base![]() https://huggingface.co/baichuan-inc/Baichuan2-7B-BaseBaichuan2-13B-Base
https://huggingface.co/baichuan-inc/Baichuan2-7B-BaseBaichuan2-13B-Base
https://huggingface.co/baichuan-inc/Baichuan2-13B-Base![]() https://huggingface.co/baichuan-inc/Baichuan2-13B-Base
https://huggingface.co/baichuan-inc/Baichuan2-13B-Base
对齐模型
Baichuan2-7B-Chat
https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat![]() https://huggingface.co/baichuan-inc/Baichuan2-7B-ChatBaichuan2-13B-Chat
https://huggingface.co/baichuan-inc/Baichuan2-7B-ChatBaichuan2-13B-Chat
https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat![]() https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat
https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat
对齐模型 4bits 量化
Baichuan2-7B-Chat-4bits
https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat-4bits![]() https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat-4bitsBaichuan2-13B-Chat-4bits
https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat-4bitsBaichuan2-13B-Chat-4bits
https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat-4bits![]() https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat-4bits
https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat-4bits
拉取代码
git clone https://github.com/baichuan-inc/Baichuan2安装依赖
pip install -r requirements.txt调用方式
Python代码调用
Chat 模型推理方法示例:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Chat", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Chat", device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan2-13B-Chat")
messages = []
messages.append({"role": "user", "content": "解释一下“温故而知新”"})
response = model.chat(tokenizer, messages)
print(response)Base 模型推理方法示范
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Base", device_map="auto", trust_remote_code=True)
inputs = tokenizer('登鹳雀楼->王之涣\n夜雨寄北->', return_tensors='pt')
inputs = inputs.to('cuda:0')
pred = model.generate(**inputs, max_new_tokens=64, repetition_penalty=1.1)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))模型加载指定 device_map='auto',会使用所有可用显卡。
如需指定使用的设备,可以使用类似 export CUDA_VISIBLE_DEVICES=0,1(使用了0、1号显卡)的方式控制。
命令行方式
python cli_demo.py本命令行工具是为 Chat 场景设计,不支持使用该工具调用 Base 模型。
网页 demo 方式
依靠 streamlit 运行以下命令,会在本地启动一个 web 服务,把控制台给出的地址放入浏览器即可访问。
streamlit run web_demo.py本网页demo工具是为 Chat 场景设计,不支持使用该工具调用 Base 模型。
量化方法
Baichuan2支持在线量化和离线量化两种模式。
在线量化
对于在线量化,baichuan2支持 8bits 和 4bits 量化,使用方式和 Baichuan-13B 项目中的方式类似,只需要先加载模型到 CPU 的内存里,再调用quantize()接口量化,最后调用 cuda()函数,将量化后的权重拷贝到 GPU 显存中。实现整个模型加载的代码非常简单,以 Baichuan2-7B-Chat 为例:
8bits 在线量化:
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
model = model.quantize(8).cuda() 4bits 在线量化:
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
model = model.quantize(4).cuda() 需要注意的是,在用 from_pretrained 接口的时候,用户一般会加上 device_map="auto",在使用在线量化时,需要去掉这个参数,否则会报错。
离线量化
为了方便用户的使用,baichuan2提供了离线量化好的 4bits 的版本 Baichuan2-7B-Chat-4bits,供用户下载。 用户加载 Baichuan2-7B-Chat-4bits 模型很简单,只需要执行:
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat-4bits", device_map="auto", trust_remote_code=True)对于 8bits 离线量化,baichuan2没有提供相应的版本,因为 Hugging Face transformers 库提供了相应的 API 接口,可以很方便的实现 8bits 量化模型的保存和加载。用户可以自行按照如下方式实现 8bits 的模型保存和加载:
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_8bit=True, device_map="auto", trust_remote_code=True)
model.save_pretrained(quant8_saved_dir)
model = AutoModelForCausalLM.from_pretrained(quant8_saved_dir, device_map="auto", trust_remote_code=True)CPU 部署
Baichuan2 模型支持 CPU 推理,但需要强调的是,CPU 的推理速度相对较慢。需按如下方式修改模型加载的方式:
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat", torch_dtype=torch.float32, trust_remote_code=True)模型微调
依赖安装
git clone https://github.com/baichuan-inc/Baichuan2.git
cd Baichuan2/fine-tune
pip install -r requirements.txt如需使用 LoRA 等轻量级微调方法需额外安装 peft
如需使用 xFormers 进行训练加速需额外安装 xFormers
单机训练
hostfile=""
deepspeed --hostfile=$hostfile fine-tune.py \--report_to "none" \--data_path "data/belle_chat_ramdon_10k.json" \--model_name_or_path "baichuan-inc/Baichuan2-7B-Base" \--output_dir "output" \--model_max_length 512 \--num_train_epochs 4 \--per_device_train_batch_size 16 \--gradient_accumulation_steps 1 \--save_strategy epoch \--learning_rate 2e-5 \--lr_scheduler_type constant \--adam_beta1 0.9 \--adam_beta2 0.98 \--adam_epsilon 1e-8 \--max_grad_norm 1.0 \--weight_decay 1e-4 \--warmup_ratio 0.0 \--logging_steps 1 \--gradient_checkpointing True \--deepspeed ds_config.json \--bf16 True \--tf32 True轻量化微调
代码已经支持轻量化微调如 LoRA,如需使用仅需在上面的脚本中加入以下参数:
--use_lora True
LoRA 具体的配置可见 fine-tune.py 脚本。
使用 LoRA 微调后可以使用下面的命令加载模型:
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM.from_pretrained("output", trust_remote_code=True)
相关文章:
部署百川大语言模型Baichuan2
Baichuan2是百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练。在多个权威的中文、英文和多语言的通用、领域 benchmark 上取得同尺寸最佳的效果。包含有 7B、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits 量化。 模…...
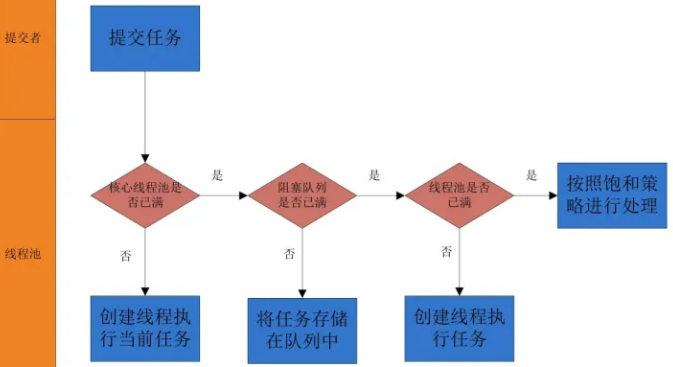
java面试常问
文章目录 java 基础1、JDK 和 JRE的区别2、 和equals的区别3、String、StringBuffer、StringBuilder4、String str “a”、 new String(“a”)一样吗?5、ArrayList 和 LinkedList的区别?6、HashMap的原理与实现6.1、容量与扩容6.2、扩容机制 7、HashMa…...

关于nginx一个域名,配置多个端口https的方法
假如我有一个域名 abc.com。在这个域名下,部署了两个应用,分别对应端口:8081,8082 想要给两个应用接口都开启https访问。 nginx配置如下: server { #监听443端口 listen 443 ssl;…...

IntelliJ IDEA插件开发入门实战
介绍 IntelliJ IDEA是备受赞誉的Java开发工具,提供了丰富的功能和工具。通过使用插件,可以扩展和增强这个集成开发环境。IntelliJ IDEA拥有庞大的插件生态系统,涵盖了代码分析、格式化工具和完整的框架等各个领域。开发人员还可以创建自己的…...

站群服务器如何选择
站群服务器如何选择 1.站群服务器线路 双线服务器在访问网站不受线路影响,较稳定。 2.站群服务器的稳定性 选择站群服务器的时候,服务器的稳定性是非常重要的。 3.站群服务器带宽大小 站群服务器网站在日常使用时,主要的目的是为了集中网…...
【vue】AntDV组件库中a-upload实现文件上传:
文章目录 一、文档:二、使用(以Jeecg为例):【1】template:【2】script: 三、效果图: 一、文档: Upload 上传–Ant Design Vue 二、使用(以Jeecg为例): 【1】template: <a-uploa…...
JSP在Scriptlet中编写java代码的形式
我们想在jsp界面中去写java代码,就需要将java代码写在Scriptlet中 虽然说 有这种方式 但是 目前 大部分都会不建议你往jsp中去写java代码 因为 目前都在推广前后端分离 这也是jsp使用面有没有少的原因 jsp也建议解耦 不要让你的程序耦合性太高 还是前端是前端 后端是…...

btree,hash,fulltext,Rtree索引类型区别及使用场景
当涉及到数据库索引类型的选择时,理解其特点和适用场景非常重要。下面是对B树、哈希索引、全文索引和R树的详细介绍,以及它们在不同数据场景下的使用示例: B树(B-tree):特点:B树是一种多路搜索…...

掌握这个技巧,你也能成为资产管理高手!
资产管理是企业管理中至关重要的一环,涉及到对公司财务、物资和信息等各个方面的有效监控和管理。 随着企业规模的扩大和业务复杂性的增加,采用先进的资产管理系统成为确保企业高效运营的必要条件之一。 客户案例 医疗机构 温州某医疗机构拥有大量的医…...
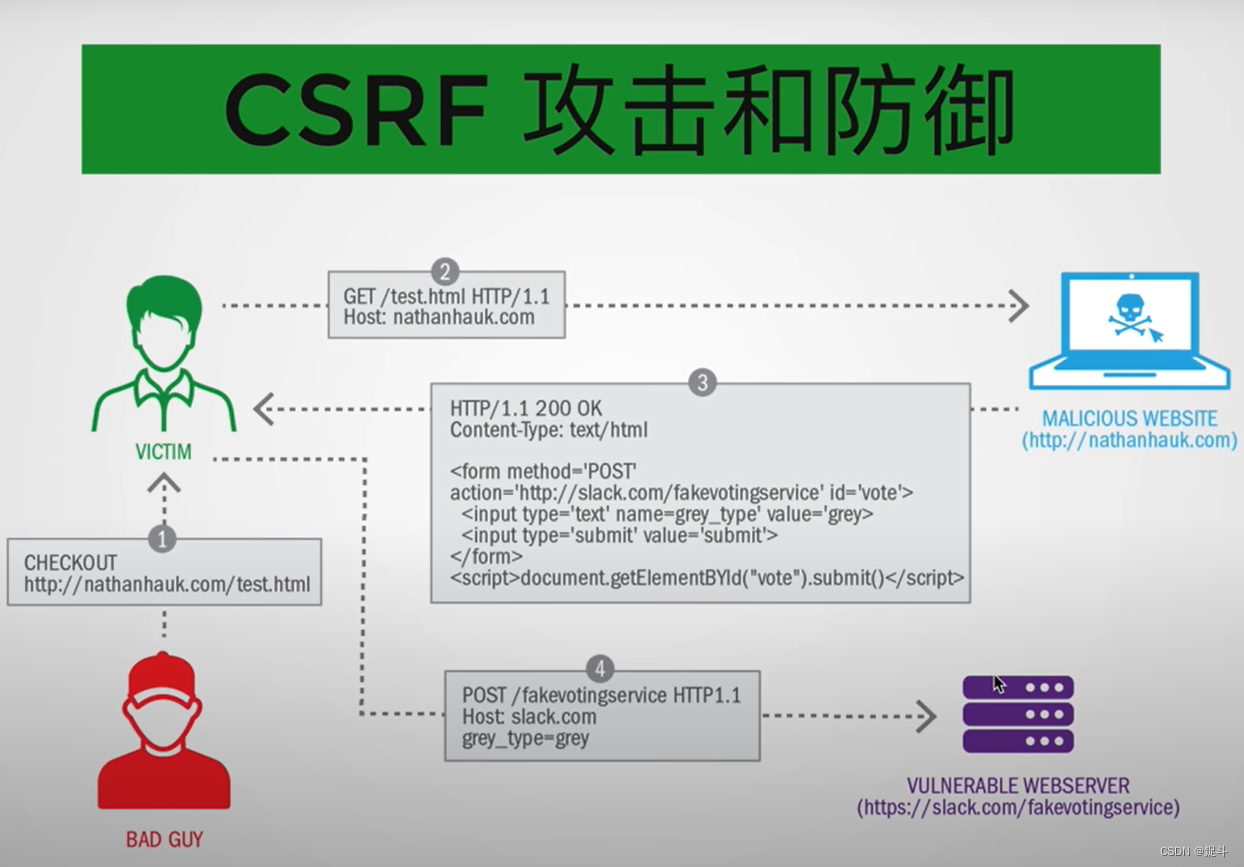
前端安全策略保障
文章目录 前言后台管理系统网络安全XSSCSRFSQL注入 后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:前端系列文章 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不断努力填补技术短板。(如果出…...
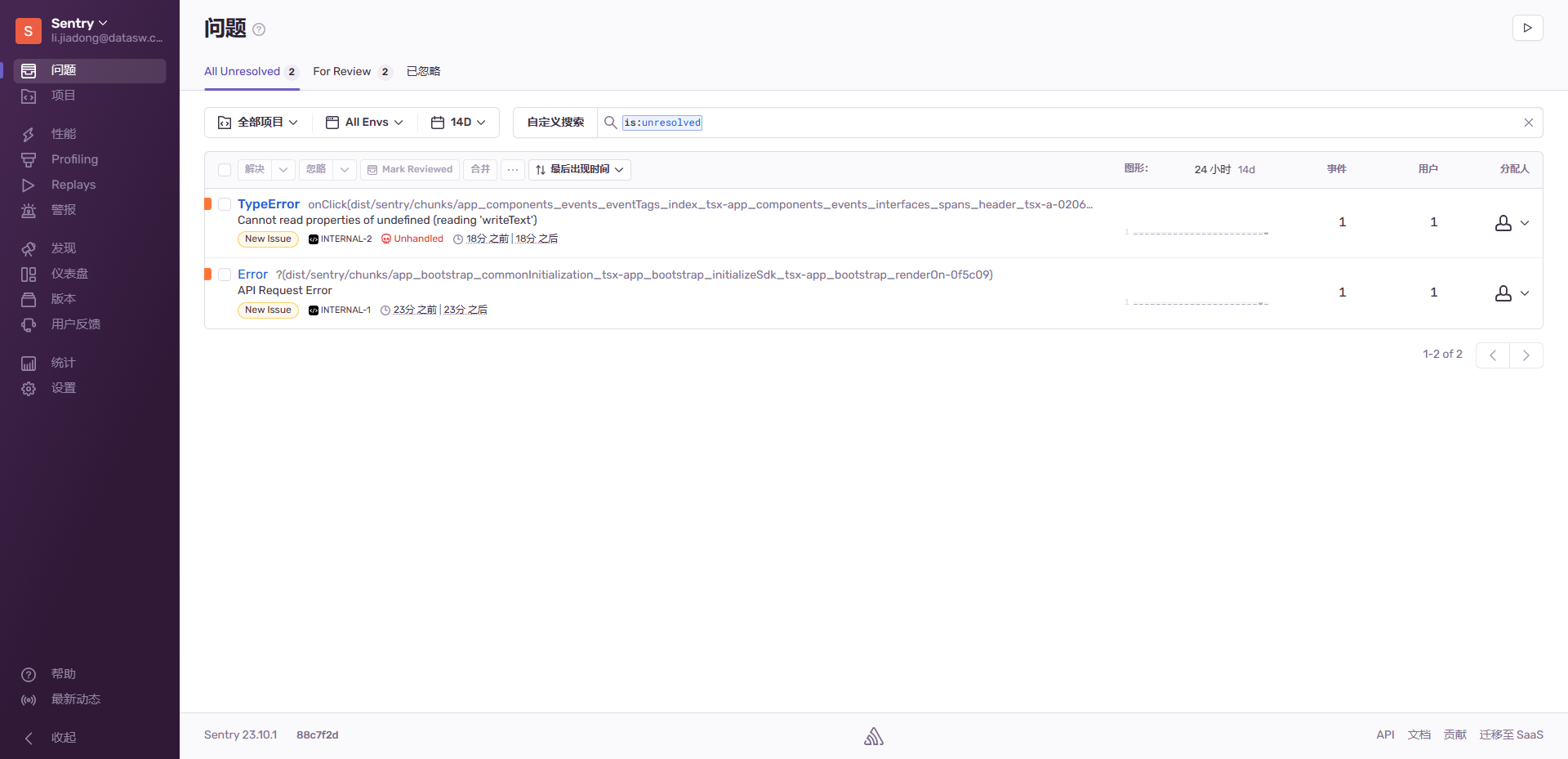
【实施】Sentry-self-hosted部署
Sentry-self-hosted部署 介绍 Sentry 是一个开源的错误追踪(error tracking)平台。它主要用于监控和追踪应用程序中的错误、异常和崩溃。Sentry允许开发人员实时地收集和分析错误,并提供了强大的工具来排查和修复问题,研发最近是…...

Django多表查询
目录 一.多表查询引入 1.数据准备 2.外键的增删改查 (1)一对多外键的增删改查 1.1外键的增加 1.2外键的删除 1.3外键的修改 (2)多对多外键的增删改查 2.1增加 2.2删除 2.3更改 2.4清空 3.正反向概念 二.多表查询 1.子查询(基于…...
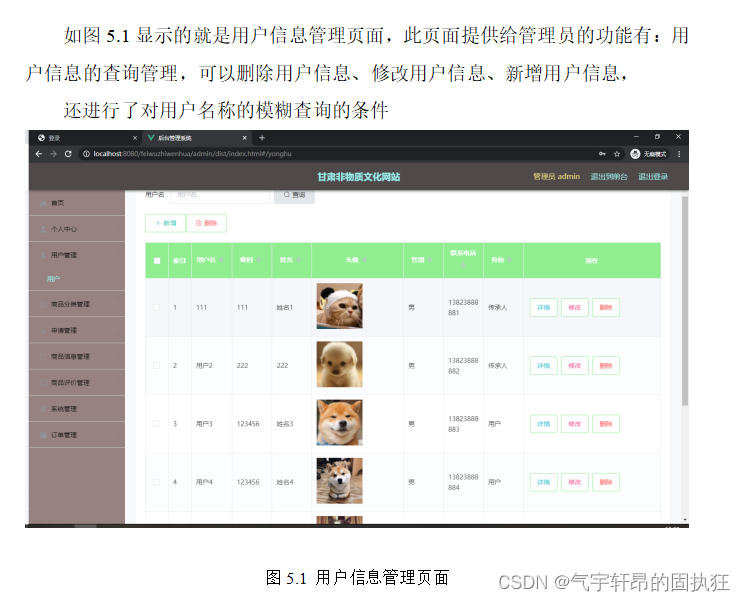
基于Springboot的非物质文化网站(有报告)。Javaee项目,springboot项目。
演示视频: 基于Springboot的非物质文化网站(有报告)。Javaee项目,springboot项目。 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 项目介…...

1亿美元投资!加拿大量子公司Photonic告别隐身状态
(图片来源:网络) 至今加拿大量子公司Photonic总融资额已达1.4亿美元,将推动可扩展、容错的量子计算和网络平台的快速开发。 官宣完成1亿美元新一轮融资 Photonic总部位于加拿大不列颠哥伦比亚省温哥华市,是一家基…...

Allegro的引流方式有哪些?Allegro买家号测评提高店铺的权重和排名
为了让更多的人发现你的平台并提高转化率,正确的引流是至关重要的。那么Allegro的引流方式有哪些? 首先,对于Allegro平台来说,一个有效且常用的引流方式就是通过搜索引擎优化(SEO)。通过合理地选择关键词、…...
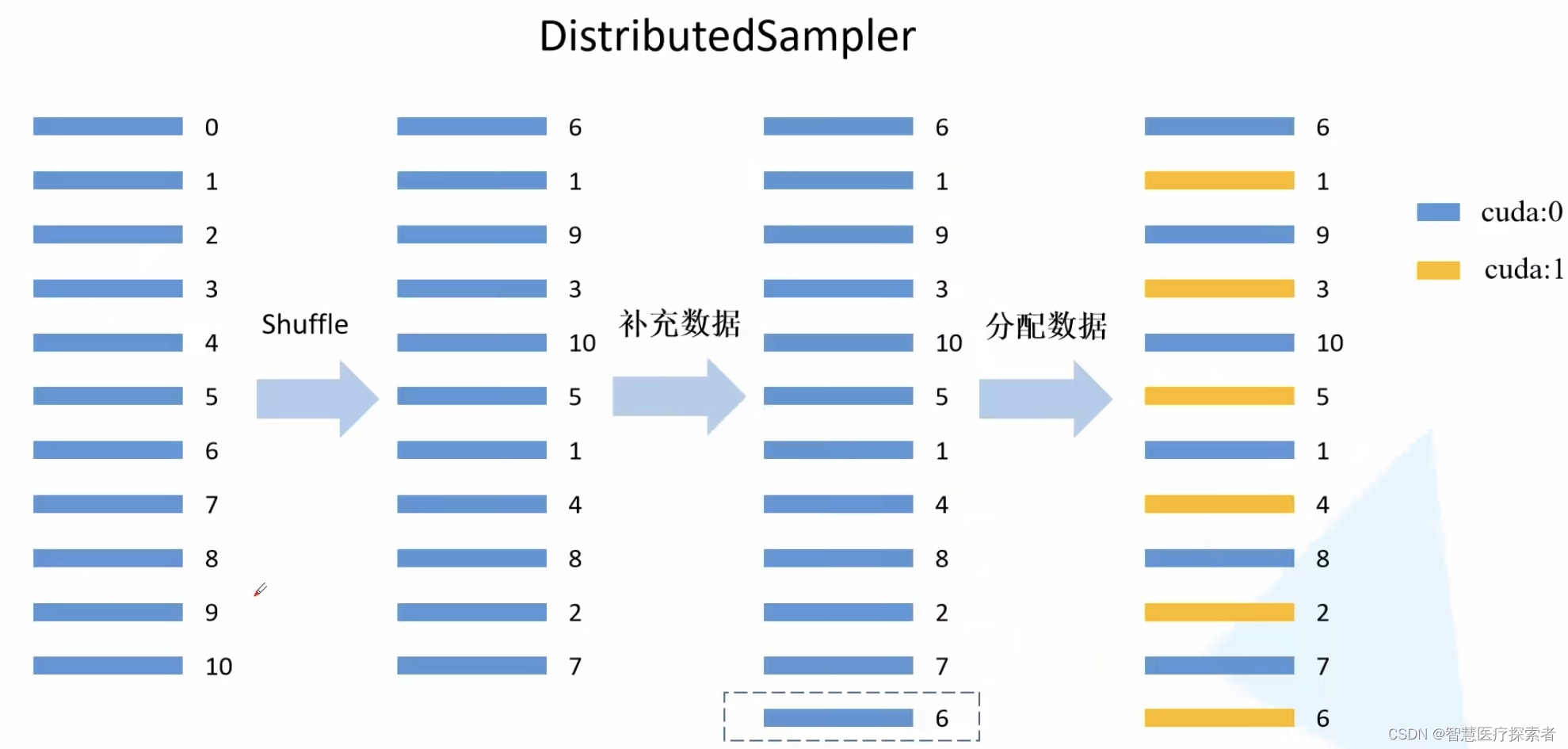
Pytorch多GPU并行训练: DistributedDataParallel
1 模型并行化训练 1.1 为什么要并行训练 在训练大型数据集或者很大的模型时一块GPU很难放下,例如最初的AlexNet就是在两块GPU上计算的。并行计算一般采取两个策略:一个是模型并行,一个是数据并行。左图中是将模型的不同部分放在不同GPU上进…...
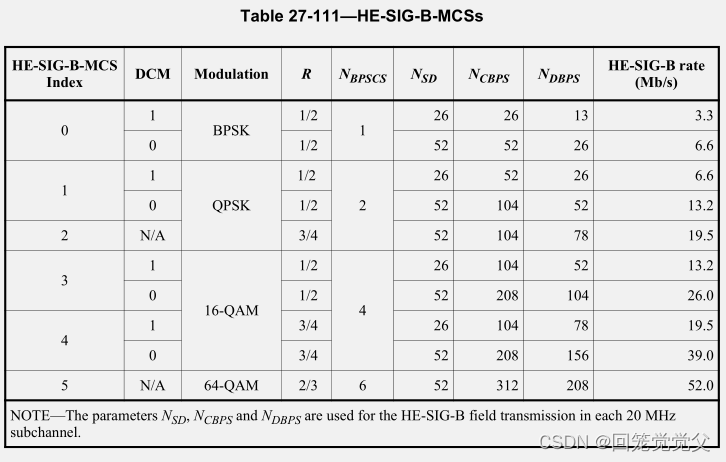
802.11ax-2021协议学习__$27-HE-PHY__$27.5-Parameters-for-HE-MCSs
802.11ax-2021协议学习__$27-HE-PHY__$27.5-Parameters-for-HE-MCSs 27.3.7 Modulation and coding scheme (HE-MCSs)27.3.8 HE-SIG-B modulation and coding schemes (HE-SIG-B-MCSs)27.5 Parameters for HE-MCSs27.5.1 General27.5.2 HE-MCSs for 26-tone RU27.5.3 HE-MCSs f…...

假如我是AI Agent专家,你会问什么来测试我的水平
1. 假如我是AI Agent专家,你会问什么来测试我的水平 作为AI Agent专家,您可能需要回答一系列关于AI代理的设计、实现和优化方面的问题。以下是一些可能的问题: AI代理的基本原理:AI代理的基本工作原理是什么?它们如何…...
github 私人仓库clone的问题
github 私人仓库clone的问题 公共仓库直接克隆就可以,私人仓库需要权限验证,要先申请token 1、登录到github,点击setting 打开的页面最底下,有一个developer setting 这里申请到token之后,注意要保存起来ÿ…...

基于 React 的 HT for Web ,由厦门图扑团队开发和维护 - 用于 2D/3D 图形渲染和交互
本心、输入输出、结果 文章目录 基于 React 的 HT for Web ,由厦门图扑团队开发和维护 - 用于 2D/3D 图形渲染和交互前言什么是 HT for WebHT for Web 的特点如何使用 HT for Web相关链接弘扬爱国精神 基于 React 的 HT for Web ,由厦门图扑团队开发和维…...

如何高效实现Windows自动化鼠标点击:AutoClicker完整实战指南
如何高效实现Windows自动化鼠标点击:AutoClicker完整实战指南 【免费下载链接】AutoClicker AutoClicker is a useful simple tool for automating mouse clicks. 项目地址: https://gitcode.com/gh_mirrors/au/AutoClicker AutoClicker是一款专业的Windows桌…...

PrediPrune:机器学习驱动的编译器超级优化候选剪枝策略
1. 项目概述与核心挑战在编译器优化的世界里,我们总在追求极致的性能。传统的编译器优化器,比如LLVM的Pass,依赖于一系列预定义的、经过验证的转换规则。它们很高效,但想象力也受限于这些规则。超级优化器(Superoptimi…...

终极指南:5步掌握Cursor AI Pro完整功能免费解锁技巧
终极指南:5步掌握Cursor AI Pro完整功能免费解锁技巧 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tria…...

“--glow”并不存在?!深度逆向Midjourney 6.1源码级辉光模拟协议,曝光官方刻意隐藏的4个隐式辉光增强开关
更多请点击: https://kaifayun.com 第一章:辉光效果的视觉本质与Midjourney 6.1协议悖论 辉光(Glow)并非物理光源的直接投射,而是人眼视网膜对高对比度边缘与饱和色域交界处产生的神经光学响应——一种由局部亮度梯度…...

sd卡分区了数据还能恢复吗,只需3种方法和视频教学,数据就能神奇地回来!
断开读写通信!锁死底层端口!你的sd卡在经历重新分区的一瞬间,其物理层面的扇区正在承受最严酷的逻辑改写。这并非介质烧毁,而是系统内核强行切断了旧有簇链的映射关系,将其标定为休克态。此时若任由操作系统自动加载缩…...

Windows 11终极优化指南:Win11Debloat一键清理系统提升51%性能
Windows 11终极优化指南:Win11Debloat一键清理系统提升51%性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutte…...

条件Shapley值:用shapr包实现更公平的模型可解释性
1. 项目概述与核心价值 如果你在数据科学或机器学习领域工作过一段时间,尤其是在需要向业务方或非技术团队解释模型决策的场景里,你肯定遇到过这样的困境:模型预测准确率很高,但当别人问“为什么这个客户的贷款申请被拒绝了&#…...
)
【限时开源】DeepSeek-VL多模态代码重构检查清单:含19个AST级检测规则+CI/CD嵌入脚本(仅剩47份可下载)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-VL多模态代码重构的背景与价值 随着视觉语言模型(VLM)在真实工业场景中加速落地,传统单模态代码架构在处理图像-文本联合推理任务时暴露出显著瓶颈…...

避坑指南:Pillow中getbbox替换getsize时,别再踩‘ValueError: too many values to unpack‘这个坑了
深度解析Pillow中getbbox替换getsize的正确姿势:从报错到精准计算 当你在YOLOv5或其他计算机视觉项目中遇到FreeTypeFont object has no attribute getsize的报错时,说明你正在使用的Pillow库版本已经移除了这个过时的方法。很多开发者会按照文档建议改用…...

Hotkey Detective:3步快速定位Windows快捷键冲突的终极指南
Hotkey Detective:3步快速定位Windows快捷键冲突的终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是…...