Django多表查询
目录
一.多表查询引入
1.数据准备
2.外键的增删改查
(1)一对多外键的增删改查
1.1外键的增加
1.2外键的删除
1.3外键的修改
(2)多对多外键的增删改查
2.1增加
2.2删除
2.3更改
2.4清空
3.正反向概念
二.多表查询
1.子查询(基于对象的跨表查询)
2.联表查询(基于双下划线的跨表查询)
三.聚合查询
四.分组查询
五.F与Q查询
1.F查询
2.Q查询
一.多表查询引入
1.数据准备
class Book(models.Model):title = models.CharField(max_length=32)price = models.DecimalField(max_digits=8, decimal_places=2)publish_date = models.DateField(auto_now_add=True)# 一对多publish = models.ForeignKey(to='Publish')# 多对多authors = models.ManyToManyField(to='Author')class Publish(models.Model):name = models.CharField(max_length=32)addr = models.CharField(max_length=64)# 该字段不是给models看的,而是给校验行组件使用的email = models.EmailField()class Author(models.Model):name = models.CharField(max_length=32)age = models.IntegerField()# 一对一author_detail = models.OneToOneField(to='AuthDetail')class AuthDetail(models.Model):phone = models.BigIntegerField()addr = models.CharField(max_length=40)
重载数据库
python36 manage.py makemigrationspython36 manage.py migrate
2.外键的增删改查
(1)一对多外键的增删改查
1.1外键的增加
# (1)一对多的外键的增删改查
# (1.1)外键的增加 - 直接写实际字段
models.Book.objects.create(title="三国演义",price=1369.25,publish_id=1)# (1.2)外键的增加 - 虚拟字段
publish_obj = models.Publish.object.objects.filter(pk=2).first()
models.Book.objects.create(title="红楼梦",price=1569.25,publish=publish_obj)1.2外键的删除
# (2)一对多的外键删除
models.Publish.objects.filter(pk=1).delete()
1.3外键的修改
# (2)一对多的外键的修改
# - 直接写实际字段
models.Book.object.filter(pk=1).update(publish_id=2)
# - 虚拟字段
publish_obj = models.publish.objects.filter(pk=1).first()models.Book.objects.filter(pk=1).update(publish=publish_obj)(2)多对多外键的增删改查
多对多 增删改查就是在操作第三张表
2.1增加
# 多对多外键的增删改查 - 就是在操作第三张表
# (1)如何给书籍添加作者
book_obj = models.Book.objects.filter(pk=1).first()
# book_obj.authors - 这样我们就已经能操作第三张关系表了
# 书籍ID为1的书籍绑定了一个主键为1的作者
book_obj.authors.add(1)
# 可以传多个参数
book_obj.authors.add(2,3)
# 支持参数传对象 - 且支持多个对象
book_obj.authors.add(author_obj)2.2删除
支持多个参数/支持对象
# (2)删除
book_obj = models.Book.objects.filter(pk=1).first()
# 支持多个参数 - 支持多个对象
book_obj.authors.remove(2)2.3更改
先删除后增加
# (3)修改
book_obj = models.Book.objects.filter(pk=1).first()
# 括号内必须给一个可迭代对象
# 把1删掉,替换成2
book_obj.author.set([1,2])
# 把原来都删掉,替换成3
book_obj.authors.set([3])
# 支持放对象
book_obj.authors.set([author_obj])2.4清空
# (4)清空
# 在第三张表中清除某一本书和作者的绑定关系
book_obj = models.Book.objects.filter(pk=1).first()
# 不要加任何参数
book_obj.authors.clear()3.正反向概念
- 正向
- 外键字段在我手上,那么我查你就是正向
- book>>>外键字段在book这边(正向)>>>出版社
- 反向
- 外键字段不在我手上,那么我查你就是反向
- 出版社>>>外键字段在书这边(反向)>>>book
- 一对一和一对多的判断也是这样
正向查询按字段
反向查询按表名(小写)
二.多表查询
1.子查询(基于对象的跨表查询)
# [1] 基于对象的跨表查询
# (1)查询书籍主键为1的出版社
book_obj = models.Book.objects.filter(pk=1).first()
# 书查出版社 - 正向 - 按字段查
res = book_obj.publish
print(res) # Publish object
print(res.name) # 东方出版社
print(res.addr) # 东方# (2)查询书籍主键为2的作者
book_obj = models.Book.objects.filter(pk=1).first()
# 书查作者 - 正向查询按字段
res = book_obj.authors
print(res) # app01.Author.None
# 列表中存放的是作者对象
print(res.all()) # <QuerySet [<Author: Author object>]># (3)查询作者 的 电话号码
author_obj = models.Author.objects.filter(name="dream").first()
# 作者查询作者详情 - 正向查询按字段
res = author_obj.author_detail
print(res) # AuthDetail object
print(res.phone) # 110
print(res.addr) # 山东'''在书写ORM语句的时候跟写SQL语句一样的不要企图一次性将ORM语句写完,如果比较复杂,需要写一些看一些正向 什么时候需要加 .all()当查询返回的结果是多个的时候就需要用 .all()当查询的结果只有一个的时候就不需要加'''# (4)查询出版社是东方出版社出版的书
# 先拿到出版社对象
publish_obj = models.Publish.objects.filter(name="东方出版社").first()
# 出版社查书 - 主键字段在书 - 反向查询
res = publish_obj.book_set.all()
# publish_obj.book_set
# print(res) # app01.Book.None
# publish_obj.book_set.all()
print(res) # <QuerySet [<Book: Book object>, <Book: Book object>, <Book: Book object>]># (5)查询作者是dream写过的书
# 先拿到作者对象
author_obj = models.Author.objects.filter(name="dream").first()
# 作者查书 - 主键在书 - 反向
res = author_obj.book_set.all()
print(res) # <QuerySet [<Book: Book object>]># (5)查询手机号是 110的作者姓名
# 先拿到作者详情的对象
author_detail_obj = models.AuthDetail.objects.filter(phone=110).first()
# 详情查作者 - 主键在作者 - 反向
res = author_detail_obj.author
print(res) # Author object
print(res.name) # dream'''基于对象 - 反向查询什么时候需要加 _set.all()查询结果是多个的时候需要加查询结果是多个的时候需要加'''
补充:_set.all()(反向查询)
- 查询结果是多个的时候需要加
2.联表查询(基于双下划线的跨表查询)
# [2] 基于双下划线的跨表查询
# (1)查询dream的手机号和作者的姓名
# 正向:先查询到作者信息再 .value(需要查询信息的表__需要查询的字段,其他字段)
res = models.Author.objects.filter(name="dream").values('author_detail__phone', 'name')
print(res) # <QuerySet [{'author_detail__phone': 110, 'name': 'dream'}]>
# 反向:先拿到详情,再用作者详情关联作者表,通过 __字段的方法 过滤出我们想要的指定数据
res = models.AuthDetail.objects.filter(author__name="dream").values('phone', 'author__name')
# AuthDetail.objects.filter(author__name="dream")
print(res) # <QuerySet [<AuthDetail: AuthDetail object>]>
# AuthDetail.objects.filter(author__name="dream").values('phone','author__name')
print(res) # <QuerySet [{'phone': 110, 'author__name': 'dream'}]># (2)查询书籍主键ID为1的出版社名字和书的名字
# 正向:先过滤出书籍ID为1的书籍对象,再去关联出版者表,利用__字段取值
res = models.Book.objects.filter(pk=1).values('title', 'publish__name')
print(res) # <QuerySet [{'title': '三国演义', 'publish__name': '东方出版社'}]>
# 反向:先查询到指定出版社,再从出版社反向找到书籍名字
res = models.Publish.objects.filter(book__id=1).values('name', 'book__title')
print(res) # <QuerySet [{'name': '东方出版社', 'book__title': '三国演义'}]># (3)查询书籍主键ID为1的作者姓名
# 先拿到 书籍主键ID为1的对象,再关联作者信息表,通过__字段取值
res = models.Book.objects.filter(pk=1).values('authors__name')
print(res) # <QuerySet [{'authors__name': 'dream'}]>
# 反向 : 先拿到 书籍ID为1的作者数据再去取作者的名字
res = models.Author.objects.filter(book__id=1).values('name')
print(res) # <QuerySet [{'name': 'dream'}]># 查询书籍主键是1的作者的手机号
# book author authordetail
res = models.Book.objects.filter(pk=1).values('authors__author_detail__phone')
print(res) # <QuerySet [{'authors__author_detail__phone': 110}]>'''只要掌握了正反向的概念以及双下划线查询就可以无限跨表'''
三.聚合查询
# 聚合查询# 聚合查询通常情况下都是配合分组一起使用的'''只要是和数据库相关的模块基本上都在 django.db.models 里面如果这里面没有 那大概率可能在 django.db 里面'''from django.db.models import Max, Min, Sum, Count, Avg# (1)所有书的平均价格# 正常情况下,我们是需要 先进行分组再进行 聚合函数运算的# 但是Django给我们提供了一种方法 : aggregate 可以不分组进行某个字段的聚合函数res = models.Book.objects.aggregate(Avg('price'))print(res) # {'price__avg': 1890.083333}# (2)一次性使用res = models.Book.objects.aggregate(Avg('price'), Max('price'), Min('price'), Sum('price'), Count('pk'))print(res) # {'price__avg': 1890.083333, 'price__max': Decimal('5959.25'), 'price__min': Decimal('555.25'), 'price__sum': Decimal('11340.50'), 'pk__count': 6}
四.分组查询
# 分组查询
'''MySQL中的分组查询分组之后只能获取到分组的依据,组内其他字段都无法获取严格模式中可以修改'''# (1)统计每一本书的作者个数
# models 后面跟的是什么,就是按什么分组
# res = models.Book.objects.annotate()
#
# '''
# author_number 是我们自己定义的字段,用来存储统计出来的每本书的作者个数
# '''
# res = models.Book.objects.annotate(author_number=Count('authors')).values('title','author_number')
# # 等价于
# # res = models.Book.objects.annotate(author_number=Count('authors__pk')).values('title','author_number')
# print(res) # <QuerySet [{'title': '三国演义', 'author_number': 1}, {'title': '红楼梦', 'author_number': 0}, {'title': '水浒传', 'author_number': 0}, {'title': '论语', 'author_number': 0}, {'title': '孙子兵法', 'author_number': 0}, {'title': '镇魂街', 'author_number': 0}]># (2)统计每个出版社最便宜的书的价格
# res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name', 'min_price')
# print(res) # <QuerySet [{'name': '东方出版社', 'min_price': Decimal('555.25')}, {'name': '北方出版社', 'min_price': Decimal('888.25')}]># (3)统计不止一个作者的图书
# (3.1)先按照图书分组
# (3.2)过滤出不止一个作者的图书
# 我的数据有限,我统计的是大于 0 的作者的图书
# res = models.Book.objects.annotate(author_num=Count('authors')).filter(author_num__gt=0).values('title',
# '''
# 只要ORM语句得到的是 一个 queryset 对象
# 那么就可以继续无限制的调用封装 的方法
# ''' 'author_num')
# print(res) # <QuerySet [{'title': '三国演义', 'author_num': 1}]># (4)查询每个作者出的书的总价格
res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name', 'sum_price')
print(res) # <QuerySet [{'name': 'dream', 'sum_price': Decimal('1369.25')}, {'name': 'hope', 'sum_price': None}, {'name': 'sad', 'sum_price': None}]>'''如果想按照指定的字段分组该如何处理# 如果 annotate 前面没东西 则会按照 Book 分组 ,如果前面有参数 就会按照前面的参数进行分组 pricemodels.Book.objects.values('price').annotate()'''
五.F与Q查询
1.F查询
# F与Q查询from django.db.models import F, Q# (1)查出卖出数大于库存数的书籍
# F 查询 : 帮助我们直接获取到表中的某个字段对应的数据
res = models.Book.objects.filter(sales__gt=F('stock'))
print(res) # <QuerySet [<Book: 水浒传>]># (2) 将所有书籍的价格提升 50
res = models.Book.objects.update(price=F('price') + 500)
print(res) # 6 - 影响到了 6 条数据# (3)将所有书的名称后边加上 爆款两个字
# 在操作字符串的时候,F查询不能够直接坐到字符串的拼接
from django.db.models.functions import Concat
from django.db.models import Valueres = models.Book.objects.update(title=Concat(F('title'), Value('爆款')))
print(res) # 6 - 影响到了 6 条数据
2.Q查询
# F与Q查询from django.db.models import F, Q# (1)查询卖出数大于100或者价格小于500的书籍# (1.1)直接使用 filter 查询数据,逗号隔开,里面放的参数是 and 关系
res = models.Book.objects.filter(sales__gt=100, price__lt=500)
print(res) # <QuerySet []># (1.2)直接使用 Q 查询数据,逗号隔开,里面放的参数还是 and 关系
res = models.Book.objects.filter(Q(sales__gt=100), Q(price__lt=500))
print(res) # <QuerySet []># (1.3)直接使用 Q 查询数据,逗号可以换成其他连接符达到效果
res = models.Book.objects.filter(Q(sales__gt=100) or Q(price__lt=500))
# 二者等价 (| :或关系) (~ : 取反 not 关系)
res = models.Book.objects.filter(Q(sales__gt=100) | Q(price__lt=500))
print(res) # <QuerySet [<Book: 三国演义爆款>, <Book: 水浒传爆款>, <Book: 论语爆款>, <Book: 孙子兵法爆款>]># (2) Q的高阶用法 能够将查询条件的左边也变成 字符串形式
# 产生 Q 对象
q = Q()
# 修改Q查询的默认连接条件
q.connector = 'or'
q.children.append('sales', 100)
q.children.append('stock', 600)
# filter 参数支持Q对象,默认还是 and 关系
res = models.Book.objects.filter(q)
相关文章:

Django多表查询
目录 一.多表查询引入 1.数据准备 2.外键的增删改查 (1)一对多外键的增删改查 1.1外键的增加 1.2外键的删除 1.3外键的修改 (2)多对多外键的增删改查 2.1增加 2.2删除 2.3更改 2.4清空 3.正反向概念 二.多表查询 1.子查询(基于…...
基于Springboot的非物质文化网站(有报告)。Javaee项目,springboot项目。
演示视频: 基于Springboot的非物质文化网站(有报告)。Javaee项目,springboot项目。 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 项目介…...

1亿美元投资!加拿大量子公司Photonic告别隐身状态
(图片来源:网络) 至今加拿大量子公司Photonic总融资额已达1.4亿美元,将推动可扩展、容错的量子计算和网络平台的快速开发。 官宣完成1亿美元新一轮融资 Photonic总部位于加拿大不列颠哥伦比亚省温哥华市,是一家基…...

Allegro的引流方式有哪些?Allegro买家号测评提高店铺的权重和排名
为了让更多的人发现你的平台并提高转化率,正确的引流是至关重要的。那么Allegro的引流方式有哪些? 首先,对于Allegro平台来说,一个有效且常用的引流方式就是通过搜索引擎优化(SEO)。通过合理地选择关键词、…...
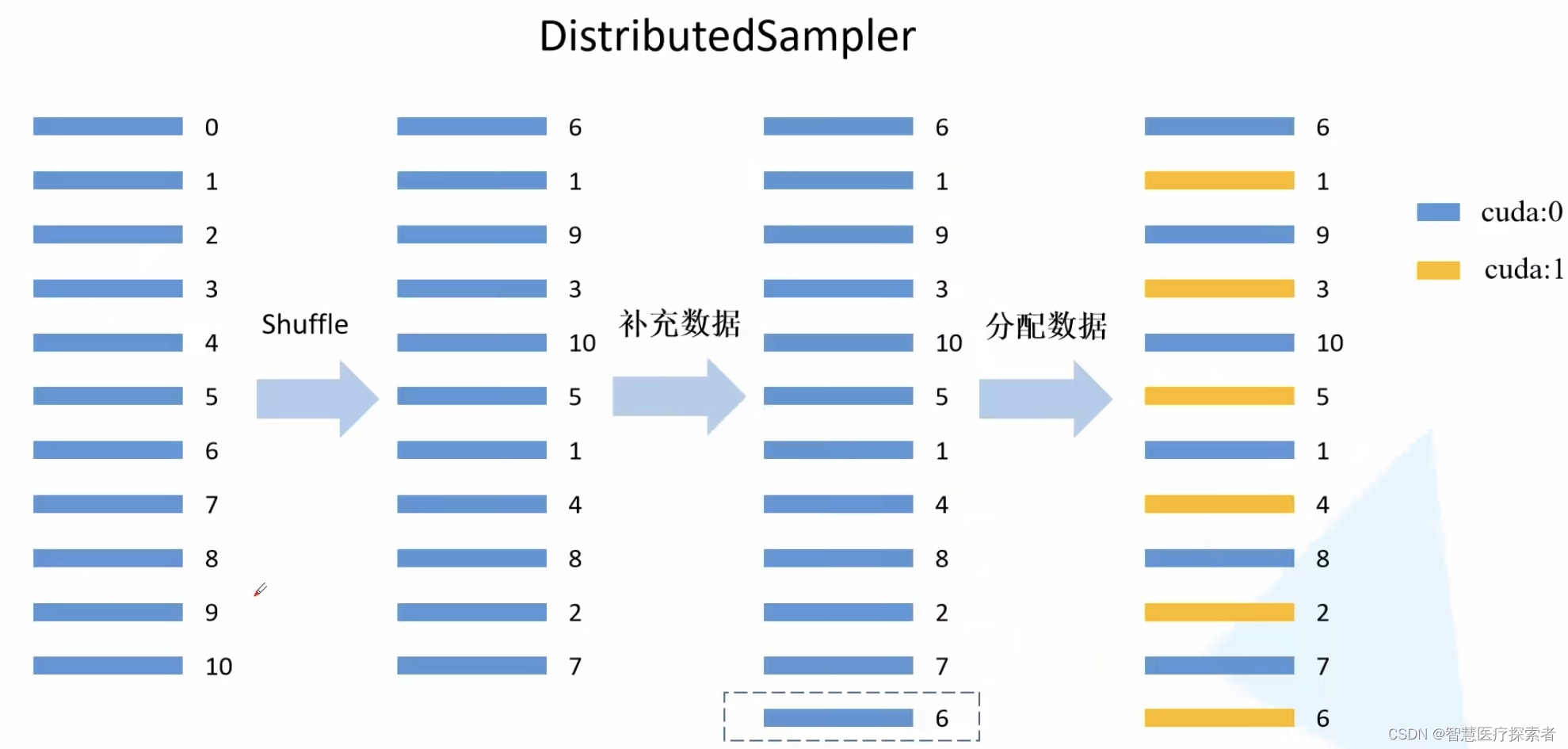
Pytorch多GPU并行训练: DistributedDataParallel
1 模型并行化训练 1.1 为什么要并行训练 在训练大型数据集或者很大的模型时一块GPU很难放下,例如最初的AlexNet就是在两块GPU上计算的。并行计算一般采取两个策略:一个是模型并行,一个是数据并行。左图中是将模型的不同部分放在不同GPU上进…...
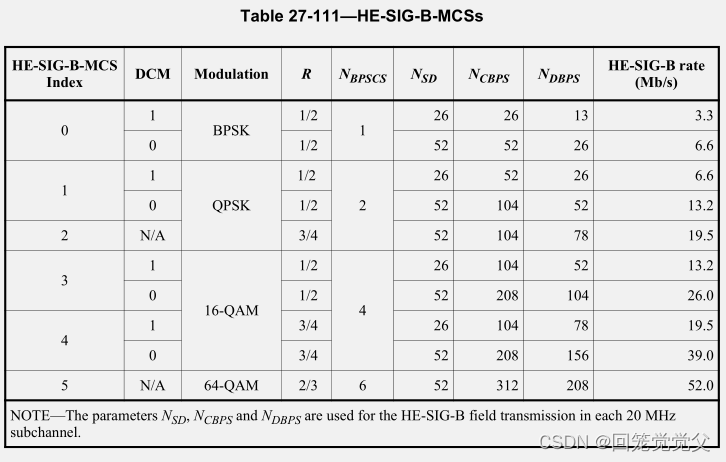
802.11ax-2021协议学习__$27-HE-PHY__$27.5-Parameters-for-HE-MCSs
802.11ax-2021协议学习__$27-HE-PHY__$27.5-Parameters-for-HE-MCSs 27.3.7 Modulation and coding scheme (HE-MCSs)27.3.8 HE-SIG-B modulation and coding schemes (HE-SIG-B-MCSs)27.5 Parameters for HE-MCSs27.5.1 General27.5.2 HE-MCSs for 26-tone RU27.5.3 HE-MCSs f…...

假如我是AI Agent专家,你会问什么来测试我的水平
1. 假如我是AI Agent专家,你会问什么来测试我的水平 作为AI Agent专家,您可能需要回答一系列关于AI代理的设计、实现和优化方面的问题。以下是一些可能的问题: AI代理的基本原理:AI代理的基本工作原理是什么?它们如何…...
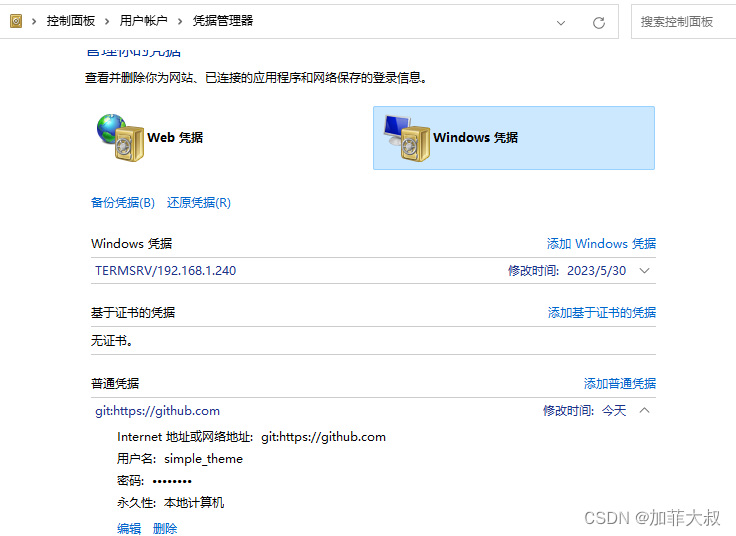
github 私人仓库clone的问题
github 私人仓库clone的问题 公共仓库直接克隆就可以,私人仓库需要权限验证,要先申请token 1、登录到github,点击setting 打开的页面最底下,有一个developer setting 这里申请到token之后,注意要保存起来ÿ…...

基于 React 的 HT for Web ,由厦门图扑团队开发和维护 - 用于 2D/3D 图形渲染和交互
本心、输入输出、结果 文章目录 基于 React 的 HT for Web ,由厦门图扑团队开发和维护 - 用于 2D/3D 图形渲染和交互前言什么是 HT for WebHT for Web 的特点如何使用 HT for Web相关链接弘扬爱国精神 基于 React 的 HT for Web ,由厦门图扑团队开发和维…...
我把微信群聊机器人项目开源
▍PART 序 开源项目地址》InsCode - 让你的灵感立刻落地 目前支持的回复 ["抽签", "天气", "讲笑话", "讲情话", "梦到", "解第", "动漫图", "去水印-", "历史今天", "星座-…...

数据可视化在监控易中的艺术与实践
在数字化运维管理中,数据可视化成为一种日益重要的工具,它将复杂的数据通过图形化的方式呈现,帮助运维团队更加直观和快速地理解系统的运行状况。监控易(MeiXin Era)将数据可视化引入到运维监控中,通过科学…...
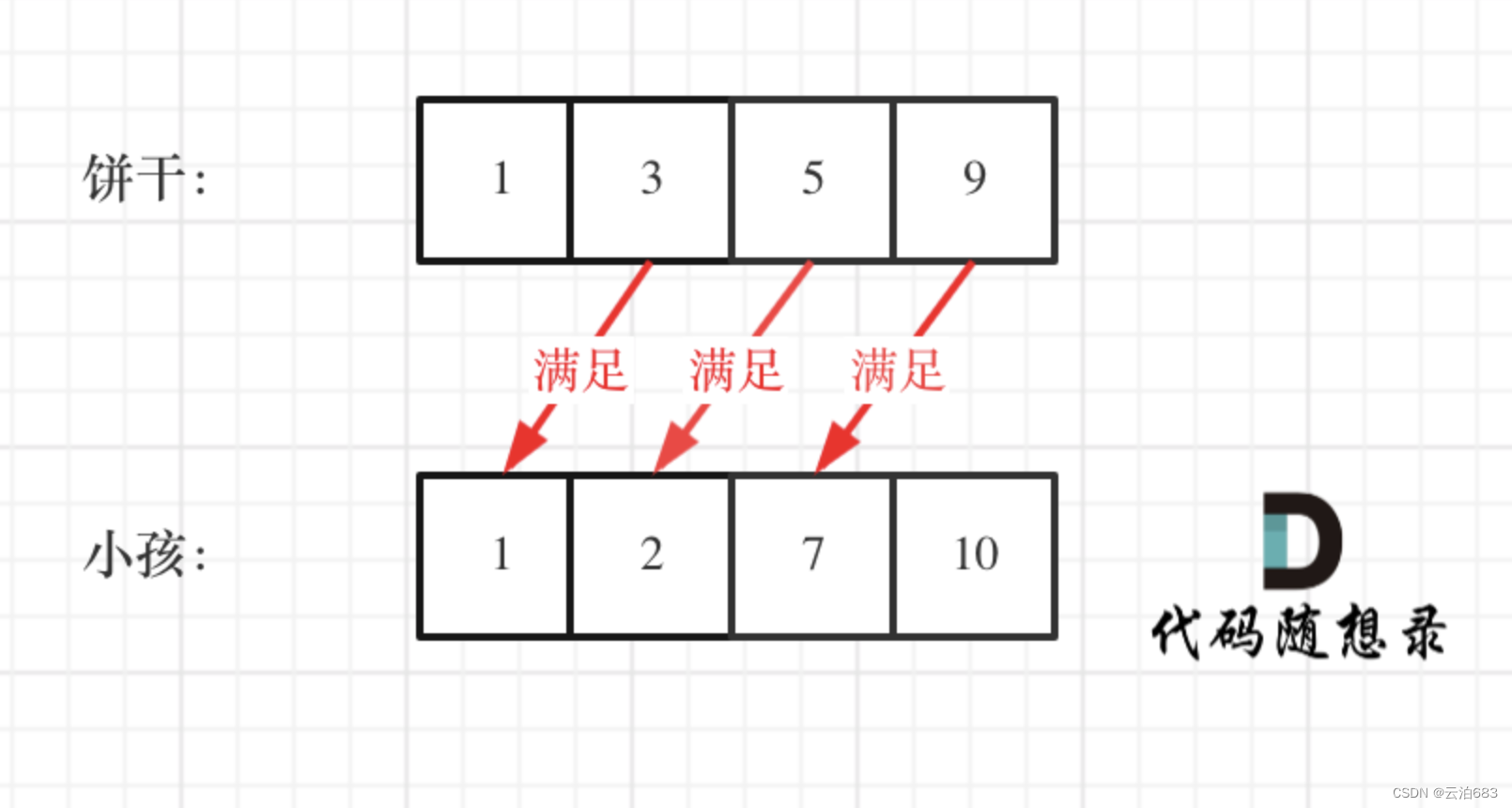
贪心 455.分发饼干
455.分发饼干 题目: 小朋友胃口值数组g[i],饼干尺寸数组 s[j],当饼干尺寸s[j]大于等于g[i]的时候,对应小朋友被满足,小朋友每一个最多一块饼干 ,求给定条件下最多被满足的小朋友数量。 思路:…...

前后端分离项目在Linux的部署方法、一台Nginx如何部署多个Web应用
需求场景:目前有三个前后端分离项目(vue+springboot),Linux服务器一台,nginx一个,比如服务器地址为www.xxxxxxx.com 我想通过80端口访问服务①(即访问www.xxxxxxx.com);通过81端口访问服务②(即www.xxxxxxx.com:81);通过82端口访问服务③(即www.xxxxxxx.com:82) ①部…...
python之 flask 框架(2)项目拆分的 执行逻辑
项目的结构图 app.py # 导入__init__.py 比较特殊 from APP import create_appapp create_app() if __name__ __main__:app.run(debugTrue)init.py # __inti__.py # 初始化文件,创建Flask应用 from flask import Flask from .views import bluedef create_ap…...
)
Angular 模块介绍及使用(二)
Angular 模块概念 Angular 模块是一个重要的概念。模块提供了一种组织和封装组件、指令、管道和服务的方式,以及在应用程序中定义和配置这些功能。 下面是一些常见的 Angular 模块概念的介绍: 根模块:根模块是 Angular 应用程序的入口模块…...

Google云的平台工程
GCP(Google Cloud Platform)是Google云,为其内部(Google search、Gmail、YouTube等)和外部客户提供IaaS、PaaS以及Serverless computing等云服务的平台。 本文将带领你走进GCP,并深入体验其产品功能&#x…...

【Android】画面卡顿优化列表流畅度五之下拉刷新上拉加载更多组件RefreshLayout修改
之前也写过类似组件的介绍: 地址:下拉刷新&上拉加载更多组件SmartRefreshLayout 本来打算用这个替换的,但在进行仔细研究发现不太合适。功能都很好,但嵌入不了当前的工程体系里。原因就是那啥体制懂的都懂。这样的组件需要改…...

【Android】导入三方jar包/系统的framework.jar
1.Android.mk导包 1).jar包位置 与res和src同一级的libs中(没有就新建) 2).Android.mk文件 LOCAL_STATIC_ANDROID_LIBRARIES:android静态库,经常用于一些support的导包 LOCAL_JAVA_LIBRARIES:依赖的java库,一般为系统的jar…...

在线升级 redis 到7.2.2
1. 操作环境与升级思路 先安装新的版本新版本设置主从备份,将老版本与新版本的数据进行同步新启动一个服务,连接新版本redis,切换到新服务,关闭主从备份kill 老服务, 卸载老版本redis 因为我需要 RedisSearch 所以直接安装 Redi…...

社区新零售:改变生活方式的创新商业模式
社区新零售:改变生活方式的创新商业模式 社区新零售,顾名思义,以社区为核心,利用互联网、大数据、人工智能等先进技术,将线上购物和线下体验有机结合,形成一种全新的零售模式。它特别强调地理位置的便利性&…...

鸿蒙HarmonyOS 5与Unity跨运行时通信实战指南
1. 这不是“调个API”那么简单:为什么鸿蒙Unity通信总在临门一脚卡住我第一次把Unity打包的AR模块塞进HarmonyOS 5 App里时,信心满满——毕竟文档里写着“支持JS/ArkTS调用Native能力”,Unity也标榜“跨平台通用”。结果呢?App一启…...

修复 PowerShell 7 下 conda activate 报错的指南
修复 PowerShell 7 下 conda activate 报错的指南 适用场景:升级到 PowerShell 7.x 后,conda activate 突然报错,但 Windows PowerShell 5.1 正常。 发布日期:2026-05-24 适用版本:conda 23.x PowerShell 7.x 一、问题…...
(Google drive存储解密密钥,加密聊天记录还是存储在Meta服务器上)聊天加密)
Messenger端到端加密机制(end-to-end encryption)(Google drive存储解密密钥,加密聊天记录还是存储在Meta服务器上)聊天加密
Messenger有个save key in google drive选项,这是什么,是指把聊天记录存于google drive吗?还是只存一个key?只存一个key有啥用啊? 文章目录解释为什么只存 key 就够了?如果没有这个 key 会怎样?…...

3步快速上手:AMD Ryzen性能调试工具SMUDebugTool完全指南
3步快速上手:AMD Ryzen性能调试工具SMUDebugTool完全指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:/…...
)
Construct3新手避坑指南:用《幽灵射手》教程搞定你的第一个射击游戏(附B站效果演示)
Construct3新手避坑指南:用《幽灵射手》教程搞定你的第一个射击游戏第一次打开Construct3的《幽灵射手》教程时,我盯着满屏的绿色幽灵和事件表发呆了半小时。为什么子弹穿过了幽灵却没造成伤害?为什么游戏运行三秒后就卡成幻灯片?…...

终极指南:5分钟解决BepInEx插件框架的90%常见问题 [特殊字符]
终极指南:5分钟解决BepInEx插件框架的90%常见问题 🚀 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx是Unity游戏社区中最受欢迎的插件框架之一&…...

医学影像AI迁移学习:如何科学选择预训练数据集?
1. 项目概述在医学影像分析这个对精度和可靠性要求极高的领域,迁移学习已经成为解决数据稀缺问题的关键技术路径。其核心逻辑很直观:与其在有限的目标数据上从头训练一个复杂的深度学习模型,不如先在一个庞大的、通用的源数据集上“预训练”模…...

Godot 4.2小课堂:用TileMap图层和AStarGrid2D,5分钟搞定一个可交互的2D导航Demo
Godot 4.2极简导航实战:5分钟构建TileMap智能寻路系统在游戏开发中,2D导航系统是构建沉浸式体验的核心组件之一。Godot 4.2引擎提供的TileMap与AStarGrid2D组合,为开发者提供了一套轻量级却功能强大的解决方案。本文将带你快速实现一个可交互…...

AI Agent Harness Engineering 生态系统:基础设施、工具与应用层
AI Agent Harness Engineering 生态系统全解:基础设施、工具链与生产级应用落地 一、引言 钩子 你有没有过这样的经历:花了3天时间调好了一个支持多工具调用的AI Agent Demo,演示的时候能自动查订单、退运费、生成工单,效果惊艳到老板当场拍板要上线。结果真到生产环境跑…...

不止是搜索!Listary隐藏玩法大揭秘:网页传文件、快速启动器、资源管理器增强
Listary进阶指南:解锁Windows效率中枢的隐藏玩法双击Ctrl键调出搜索框——这可能是大多数Listary用户对这个工具的全部认知。但如果你只把它当作一个文件搜索工具,那就像用瑞士军刀只开瓶盖一样暴殄天物。经过三年深度使用和上百次工作流优化,…...