【Python】Pandas(学习笔记)
一、Pandas概述
1、Pandas介绍
2008年WesMcKinney开发出的库,专门用于数据挖掘的开源python库
以Numpy为基础,借力Numpy模块在计算方面性能高的优势
基于matplotib,能够简便的画图
独特的数据结构
import pandas as pd
2、Pandas优势
- 便捷的数据处理能力
- 读取文件方便
- 封装了Matplotlib、Numpy的画图和计算
二、数据类型
1、DataFrame
1)结构
既有行索引、又有列索引的二维数组
- 行索引,表明不同行,横向索引,叫
index - 列索引,表明不同列,纵向索引,叫
columns
2)初识
import numpy as np
import pandas as pd
stock = np.random.normal(0, 1, (10,5))
hang = ["股票{}".format(i) for i in range(10)]
lie = pd.date_range(start="20180101", periods=5, freq="B")df = pd.DataFrame(stock, index=hang, columns=lie)
df.head()



3)属性
| 属性 | 属性名 |
|---|---|
| shape | 形状 |
| index | 行索引列表 |
| columns | 列索引列表 |
| values | 直接获取其中 array 的值 |
| T | 行列转置 |
4)方法
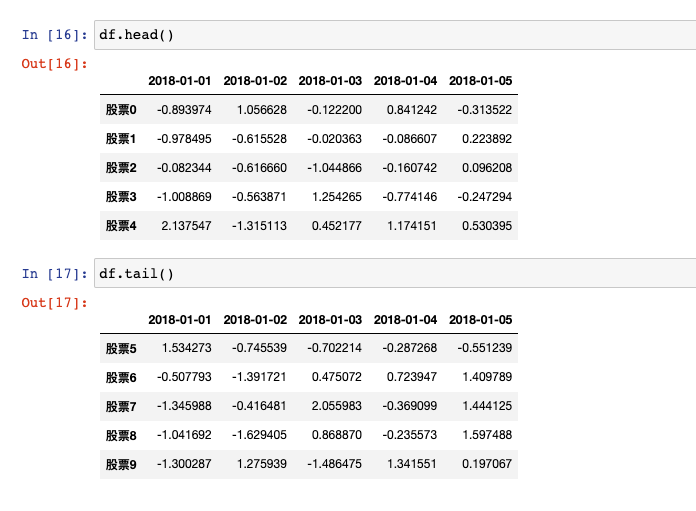
# 开头几行(默认5)
df.head(n)
# 最后几行
df.tail(n)
5)索引的设置
1. 修改行列索引值
不能单独修改索引
stock_ = ["股票_{}".format(i) for i in range(10)]
data.index = stock_

2. 重设索引
把原始索引删除(True)或当成普通列(False),重设索引
data.reset_index()
data.reset_index(drop=True) # drop=True把之前的索引删除

3. 设置新索引
df1 = pd.DataFrame({'month': [1, 4, 7, 10],'year': [2012, 2014, 2013, 2014],'sale':[55, 40, 84, 31]})
# 以月份设置新的索引
df1.set_index("month", drop=True)
# 设置多个索引,以年和月份
df1.set_index(["year", "month"])

2、MultiIndex
多级或分层索引对象
- names:levels 的名称
- levels:每个 level 的元组值
df2.index
df2.index.names
df2.index.levels

3、Panel
存储三维数组的容器
Panel 是 DataFrame 的容器 => 每个维度都是一个DataFrame
注:Pandas 从版本 0.20.0 开始弃用,推荐的用于表示 3D 数据的方法是 DataFrame 上的 MultiIndex 方法
4、Series
带索引的一维数组
DataFrame 是 Series 的容器
sr = data.iloc[1, :]# 索引
sr.index
# 值
sr.values

三、数据操作
1、索引操作
# 直接索引 必须先列后行
data["open"]["2018-02-26"]# 按名字索引
data.loc["2018-02-26"]["open"]
data.loc["2018-02-26", "open"]# 数字索引
data.iloc[1, 0]# 组合索引
data.loc[data.index[0:4], ['open', 'close', 'high', 'low']]

2、赋值操作
data.open = 100
data.iloc[1, 0] = 120

3、排序操作
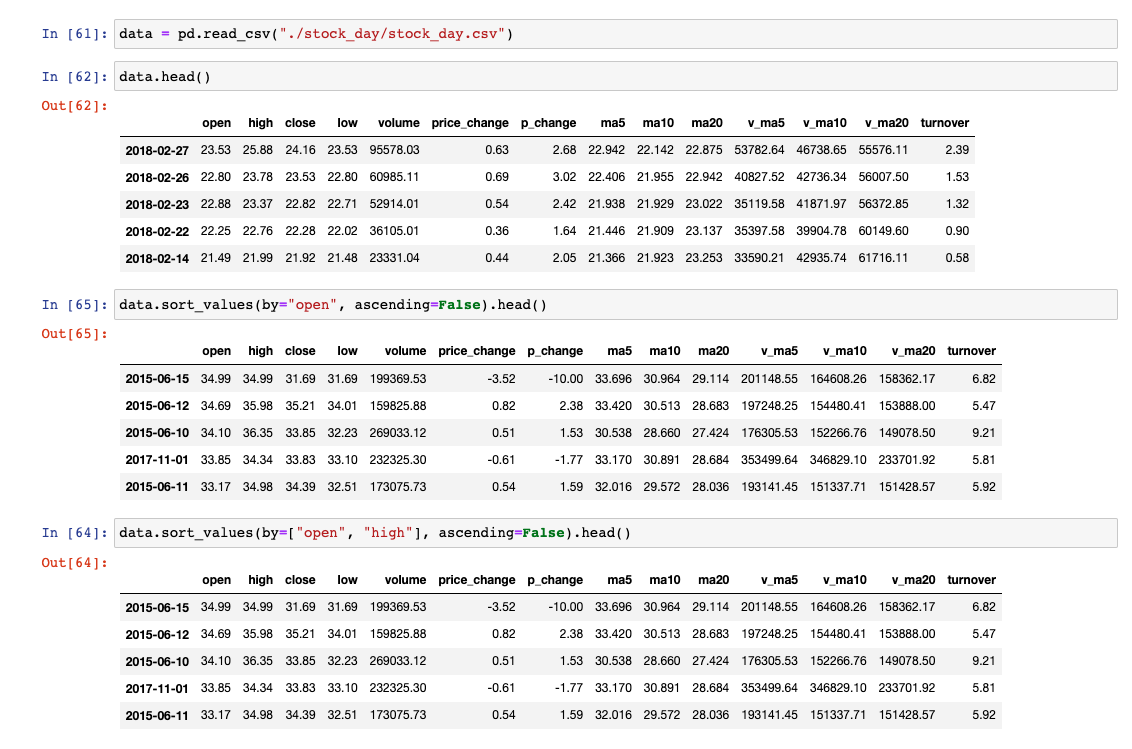
1)内容排序
# 单列内容排序
# ascending=False:降序、True:升序
data.sort_values(by="open", ascending=False)# 多个列内容排序
data.sort_values(by=["open", "high"], ascending=False).head()
2)索引排序
data.sort_index()

四、DataFrame运算
1、算术运算
data["open"] + 3
data["open"].add(3)data.sub(100)
data - 100data["close"] - data["open"]
data["close"].sub(data["open"])
2、逻辑运算
data[data["p_change"] > 2]
data[(data["p_change"] > 2) & (data["low"] > 15)]# query(expr) expr:查询字符串
data.query("p_change > 2 & low > 15")
# isin(values) 判断是否为 values
data[data["turnover"].isin([4.19, 2.39])]
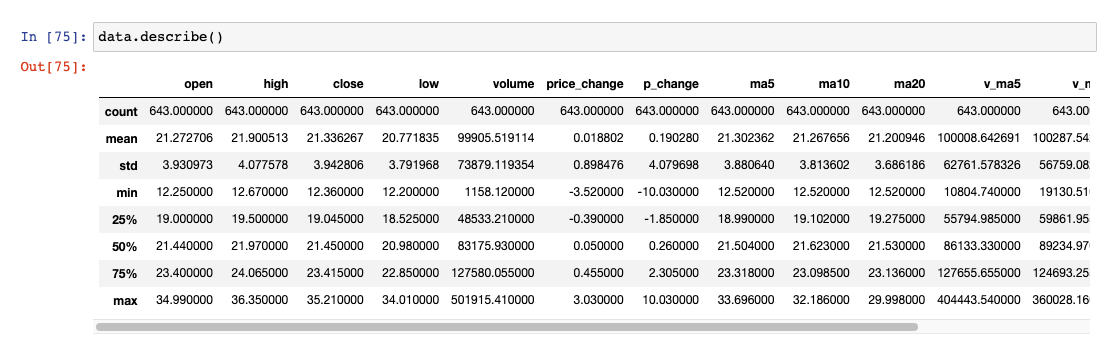
3、统计运算
describe()综合分析:能够直接得出很多统计结果,count,mean,std,min,max 等
data.describe() # 综合分析
data.max() # 最大值
data.idxmax() # 最大值位置
4、累计统计函数
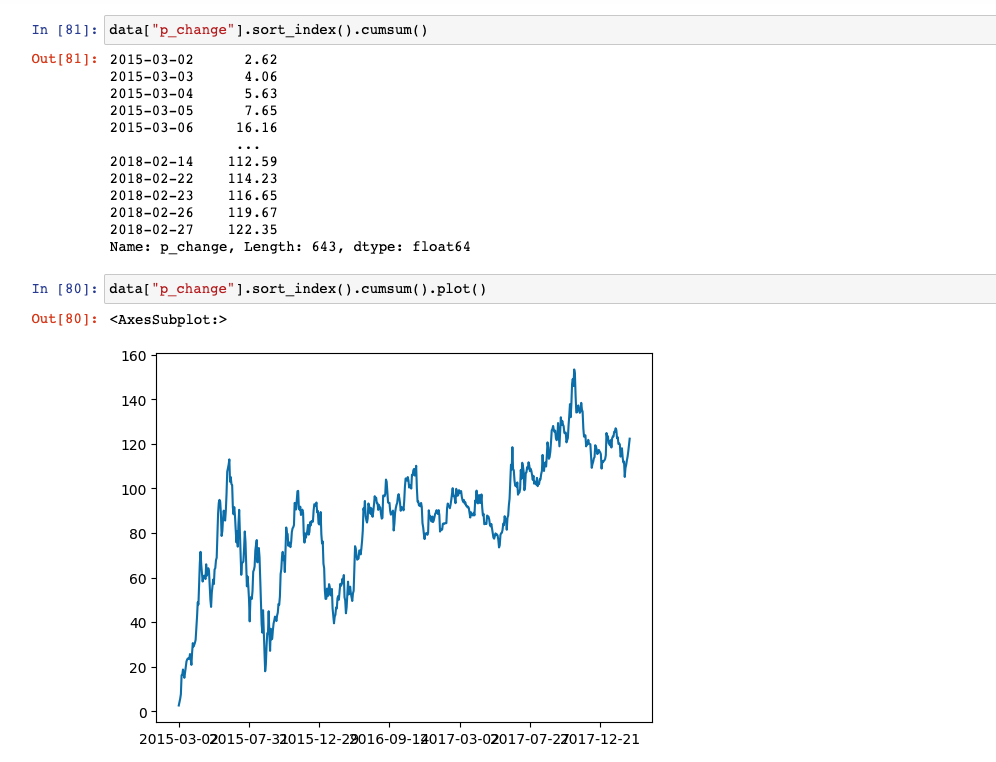
cumsum计算前 1/2/3/…/n 个数的和cummax计算前 1/2/3/…/n 个数的最大值cummin计算前 1/2/3/…/n 个数的最小值cumprod计算前 1/2/3/…/n 个数的积
data["p_change"].sort_index().cumsum()
data["p_change"].sort_index().cumsum().plot()
5、自定义运算
apply(func, axis=0)
func:自定义函数axis=0:默认按列运算,axis=1:按行运算
data.apply(lambda x: x.max() - x.min())

五、Pandas画图
1、DataFrame
DataFrame.plot(x=None, y=None, kind='line')
- x: 标签或位置,默认为“无”
- y: 标签、位置或标签列表、位置。默认无标签
- 允许打印一列与另一列
- kind: str
- ‘line’: 折线图(default)
- ''bar": 条形图
- “barh”: 水平条形图
- “hist”: 直方图
- “pie”: 饼图
- “scatter”: 散点图
data.plot(x="volume", y="turnover", kind="scatter")

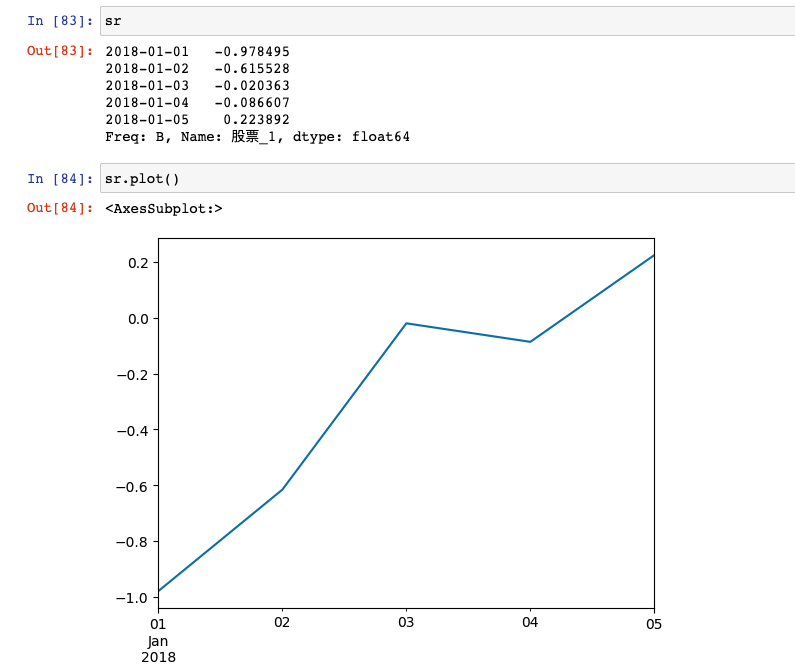
2、Series
sr.plot()
六、文件读取与存储
1、读取CSV
# 读取数据表,并指定读哪些列
data = pd.read_csv("./stock_day/stock_day.csv", usecols=["high", "low", "open", "close"])# 如果数据表的列没有列名,用names传入列名
data = pd.read_csv("stock_day2.csv", names=["open", "high", "close"])
2、保存CSV
# 保存open列的数据
data[:10].to_csv("test.csv", columns=["open"]) # index=False不要行索引
# header=False不要列索引
# mode="a"追加模式|mode="w"重写
data[:10].to_csv("test.csv", columns=["open"], index=False, mode="a", header=False)
相关文章:
【Python】Pandas(学习笔记)
一、Pandas概述 1、Pandas介绍 2008年WesMcKinney开发出的库,专门用于数据挖掘的开源python库 以Numpy为基础,借力Numpy模块在计算方面性能高的优势 基于matplotib,能够简便的画图 独特的数据结构 import pandas as pd2、Pandas优势 便…...

京联易捷科技与劳埃德私募基金管理有限公司达成合作协议签署
京联易捷科技与劳埃德私募基金管理有限公司今日宣布正式签署合作协议,双方在数字化进程、资产管理与投资以及中英金融合作方面将展开全面合作。 劳埃德(中国)私募基金管理有限公司是英国劳埃德私募基金管理有限公司的全资子公司,拥有丰富的跨境投资经验和卓越的募资能力。该集…...

Netty Review - 从BIO到NIO的进化推演
文章目录 BIODEMO 1DEMO 2小结论单线程BIO的缺陷BIO如何处理并发多线程BIO服务器的弊端 NIONIO要解决的问题模拟NIO方案一: (等待连接时和等待数据时不阻塞)方案二(缓存Socket,轮询数据是否准备好)方案二存…...
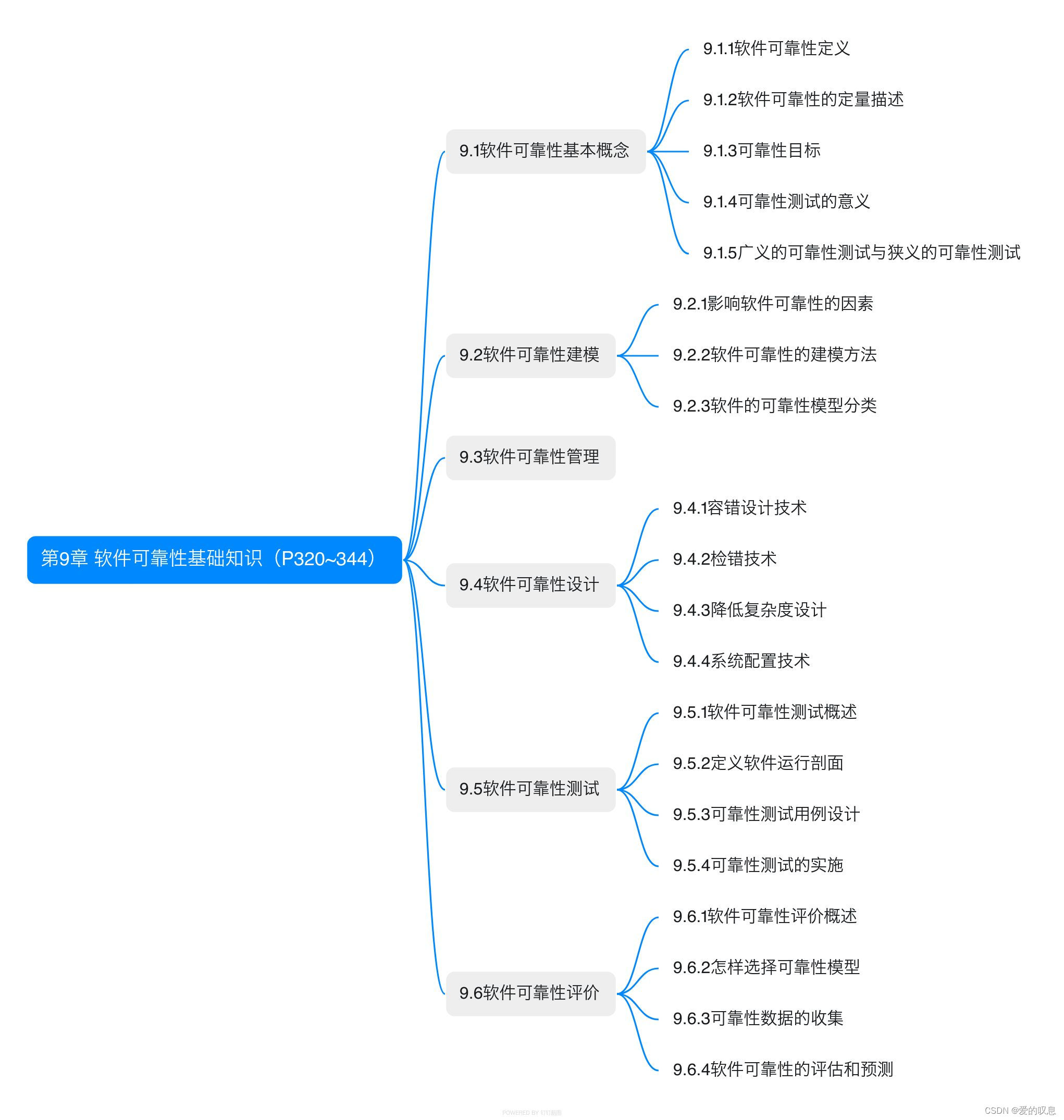
软考-高级-系统架构设计师教程(清华第2版)【第9章 软件可靠性基础知识(P320~344)-思维导图】
软考-高级-系统架构设计师教程(清华第2版)【第9章 软件可靠性基础知识(P320~344)-思维导图】 课本里章节里所有蓝色字体的思维导图...
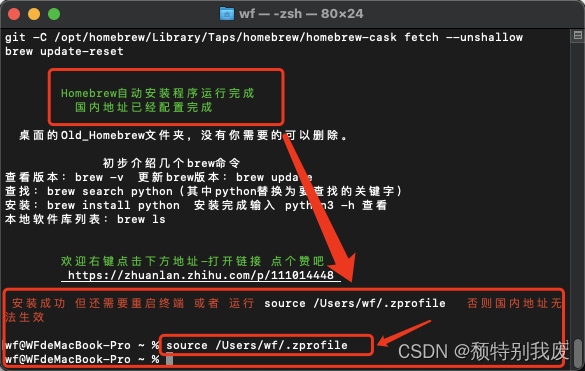
M系列 Mac安装配置Homebrew
目录 首先,验证电脑是否安装了Homebrew 1、打开终端输入以下指令: 2、如图所示,该电脑没有安装Homebrew ,下面我们安装Homebrew 一、官网下载 (不建议) 1、我们打开官网:https://brew.sh/ …...
WebRTC简介及使用
文章目录 前言一、WebRTC 简介1、webrtc 是什么2、webrtc 可以做什么3、数据传输需要些什么4、SDP 协议5、STUN6、TURN7、ICE 二、WebRTC 整体框架三、WebRTC 功能模块1、视频相关①、视频采集---video_capture②、视频编解码---video_coding③、视频加密---video_engine_encry…...

网工内推 | 国企、上市公司售前,CISP/CISSP认证,最高18K*14薪
01 中电福富信息科技有限公司 招聘岗位:售前工程师(安全) 职责描述: 1、对行业、用户需求、竞争对手等方面提出分析报告,为公司市场方向、产品研发和软件开发提供建议; 2、负责项目售前跟踪、技术支持、需…...
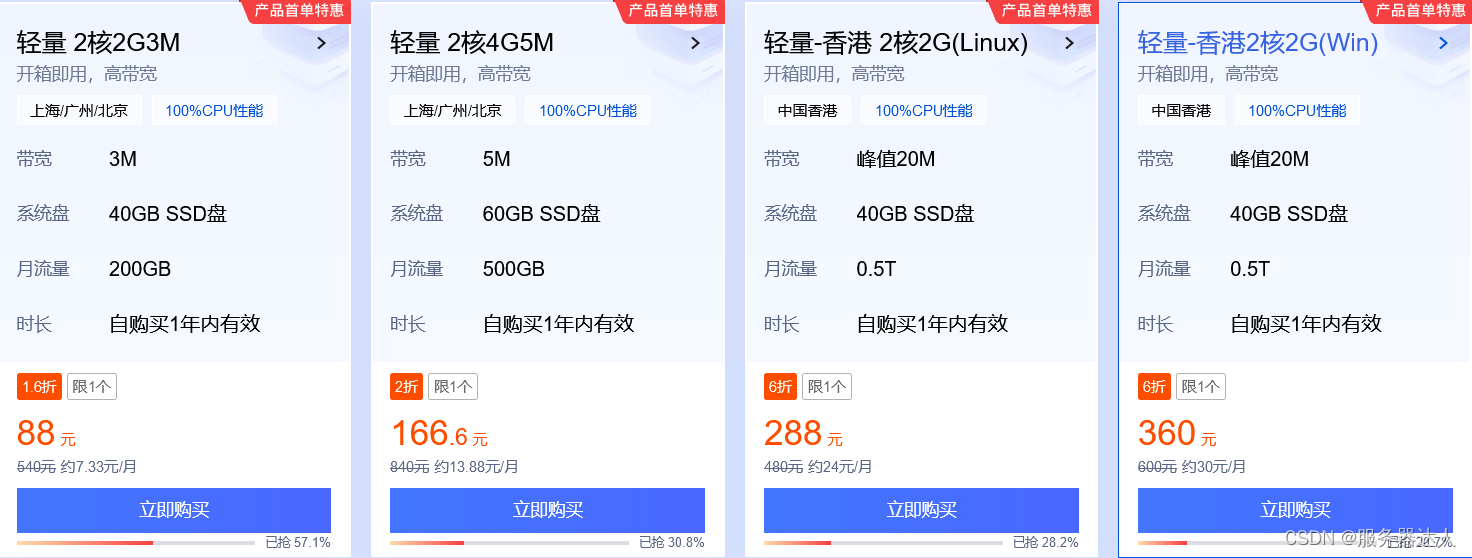
阿里云99元VS腾讯云88元,双11云服务器价格战,谁胜谁负?
在2023年的双十一优惠活动中,阿里云推出了一系列令人惊喜的优惠活动,其中包括99元一年的超值云服务器。本文将带您了解这些优惠活动的具体内容,以及与竞争对手腾讯云的价格对比,助您轻松选择最适合的云服务器。 99元一年服务器优…...

1.jvm基本知识
目录 概述jvm虚拟机三问jvm是什么?java 和 jvm 的关系 为什么学jvm怎么学习为什么jvm调优?什么时候jvm调优调优调什么 结束 概述 相关文章在此总结如下: 文章地址jvm类加载系统地址双亲委派模型与打破双亲委派地址运行时数据区地址运行时数据区-字符串…...

前端---掌握WebAPI:DOM
文章目录 什么是DOM?使用DOM获取元素事件操作元素获取、修改元素内容获取、修改元素属性获取、修改表单元素属性:input获取、修改样式属性直接修改样式:行内样式通过修改class属性来修改样式 新增节点删除节点 什么是DOM? DOM&am…...
)
最优化基础(一)
最优化基础(一)1 最优化问题的数学模型 通俗地说,所谓最优化问题,就是求一个多元函数在某个给定集合上的极值. 几乎所有类型的最优化问题都可以用下面的数学模型来描述: m i n f ( x ) s . t . x ∈ Ω min\ f({x})\\ s.t. \ {…...

基于JavaWeb+SpringBoot+Vue医疗器械商城微信小程序系统的设计和实现
基于JavaWebSpringBootVue医疗器械商城微信小程序系统的设计和实现 源码获取入口前言主要技术系统设计功能截图Lun文目录订阅经典源码专栏Java项目精品实战案例《500套》 源码获取 源码获取入口 前言 摘 要 目前医疗器械行业作为医药行业的一个分支,发展十分迅速。…...

java程序中为什么经常使用tomcat
该疑问的产生场景: 原来接触的ssm项目需要在项目配置中设置tomcat,至于为什么要设置tomcat不清楚,只了解需要配置tomcat后项目才能启动。接触的springboot在项目配置中不需要配置tomcat,原因是springboot框架内置了tomcat…...

大带宽服务器需要选择哪些节点
选择大带宽服务器节点需要考虑以下几个因素: 地理位置:选择距离用户较近的节点,可以降低延迟,提高响应速度。 网络质量:大带宽服务器节点应该有良好的网络质量,稳定可靠,能够提供高速的网络传输…...
)
CSS 属性学习笔记(入门)
1. 选择器 CSS选择器用于选择要样式化的HTML元素。以下是一些常见的选择器: 元素选择器 p {color: blue; }描述: 选择所有 <p> 元素,并将文本颜色设置为蓝色。 类选择器 .highlight {background-color: yellow; }描述:…...

[Android]使用View Binding 替代findViewById
1.配置 build.gradle文件中添加配置,然后同步。 android {...buildFeatures {viewBinding true} } 2.用 View Binding 类来访问布局中的视图 在Activity代码的顶部导入生成的 View Binding 类: import com.example.yourapp.databinding.ActivityMai…...

Pytest UI自动化测试实战实例
环境准备 序号库/插件/工具安装命令1确保您已经安装了python3.x2配置python3pycharmselenium2开发环境3安装pytest库 pip install pytest 4安装pytest -html 报告插件pip install pytest-html5安装pypiwin32库(用来模拟按键)pip install pypiwin32 6安装openpyxl解析excel文…...

软件测试/测试开发丨接口自动化测试学习笔记,多环境自动切换
点此获取更多相关资料 本文为霍格沃兹测试开发学社学员学习笔记分享 原文链接:https://ceshiren.com/t/topic/28026 多环境介绍 环境使用场景备注dev开发环境开发自测QA测试环境QA日常测试preprod预发布环境回归测试、产品验测试prod线上环境用户使用的环境 通过环…...

Spring-IoC与DI入门案例
IoC入门案例 IoC入门案例思路分析 管理什么?(Service与Dao)如何将被管理的对象告知IoC容器?(配置)被管理的对象交给IoC容器,如何获取到IoC容器?(接口)IoC容…...
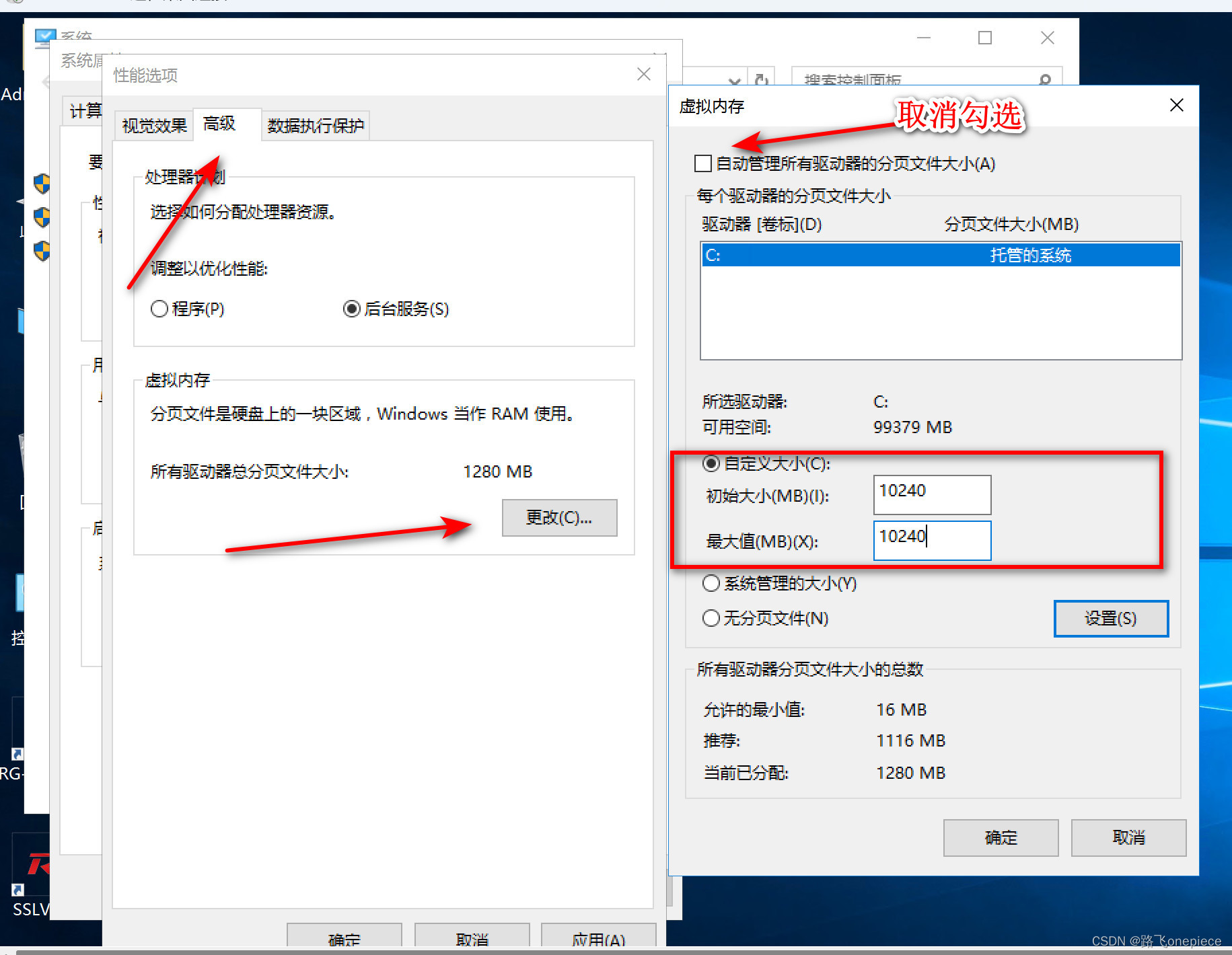
windows虚拟内存自定义分配以及mysql错误:Row size too large (> 8126)
文章目录 虚拟内存概要windows-server配置虚拟内存技术名词解释关于mysql错误Row size too large (> 8126)问题分析解决办法 虚拟内存概要 虚拟内存别称虚拟存储器(Virtual Memory)。电脑中所运行的程序均需经由内存执行,若执行的程序占用…...

终极解决方案:如何用qmc-decoder快速解锁QQ音乐加密格式
终极解决方案:如何用qmc-decoder快速解锁QQ音乐加密格式 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾经下载了QQ音乐,却发现那些.qmc3、…...

Zotero中文文献管理神器:茉莉花插件3分钟快速上手指南
Zotero中文文献管理神器:茉莉花插件3分钟快速上手指南 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为Zotero无…...

小红书下载神器XHS-Downloader:3分钟解锁隐藏的高级玩法
小红书下载神器XHS-Downloader:3分钟解锁隐藏的高级玩法 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&a…...

机器学习加速电子-声子耦合计算:对称性描述符与蒙特卡洛采样实践
1. 项目概述:当机器学习遇见电子-声子耦合在计算材料科学领域,有一个长期存在的“效率瓶颈”:如何精确且高效地计算材料性质随温度的变化。比如,为什么半导体的带隙会随着温度升高而变窄?这背后是电子与晶格振动&#…...
)
别再被离群点坑了!用Python+OpenCV手把手教你RANSAC直线拟合(附完整代码)
实战指南:用PythonOpenCV实现RANSAC直线拟合的完整流程在计算机视觉项目中,我们经常遇到需要从嘈杂数据中提取几何特征的情况。想象一下这样的场景:你从一张建筑图纸扫描件中提取了数百个边缘点,但扫描时的折痕、污渍导致30%的点位…...

Sunshine虚拟手柄终极指南:解决游戏串流控制难题
Sunshine虚拟手柄终极指南:解决游戏串流控制难题 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 在游戏串流体验中,最令人沮丧的莫过于手柄连接失败、按键映…...

BabelDOC:智能PDF翻译神器,完美保留原版格式与布局的终极方案
BabelDOC:智能PDF翻译神器,完美保留原版格式与布局的终极方案 【免费下载链接】BabelDOC Yet Another Document Translator 项目地址: https://gitcode.com/GitHub_Trending/ba/BabelDOC 还在为PDF文档翻译后格式错乱而烦恼吗?BabelDO…...

JMeter并发与持续性压测:从按钮操作到系统心跳诊断
1. 这不是“点几下就出报告”的玩具,而是压测工程师的听诊器很多人第一次打开 JMeter,以为它就是个高级版的 Postman:填个 URL、点个“启动”,等几秒弹出个 Summary Report,看到平均响应时间 86ms 就松一口气ÿ…...
)
SAM一键分割后,如何把每个对象单独存成PNG?一个for循环搞定(含透明背景处理技巧)
SAM分割结果高效保存指南:透明背景PNG与批量处理实战当你用Segment Anything Model(SAM)完成图像分割后,面对屏幕上密密麻麻的mask轮廓,最迫切的需求可能就是把这些分割对象一个个保存为独立文件。本文将从实际工程角度…...

石墨烯六边形Hubbard模型的量子模拟研究
1. 石墨烯六边形Hubbard模型的量子模拟背景在凝聚态物理研究中,理解强关联电子系统的行为一直是核心挑战。这类系统展现出超导、量子自旋液体等丰富物理现象,而Hubbard模型作为描述电子在晶格中相互作用的最简模型,已成为理论研究的重要工具。…...