Django之模型层
【1】常见的13中查询方法
例子语法:models.Userinfo.objects.filter().all()
| 查询方法 | 解释 |
| all() | 查询所有数据 |
| first() | 那queryset中第一条数据 |
| last() | 那最后一条数据 |
| filter() | 带有过滤条件的查询,查询不到结果返回None |
| get() | 带有guolv条件的查询,查询不到结果报错 |
| values() | 指定查询的字段,返回的是列表套字典 |
| value_list() | 指定查询的字段,返回的是列表套元组 |
| distinct() | 去重 |
| order_by() | 排序,默认是升序,降序在条件前面加 "-" |
| count() | 统计有多少条数据 |
| reverse() | 反转,前提是要先排序 |
| exclude() | 排除、 |
| exists() | 判断某个字段存不存在 |
【2】基于下划线的查询
例子语法:models.Userinfo.objects.filter(age__gt=3)
| 方法 | 解释 |
| __gt | 大于 |
| __lt | 小于 |
| __gte | 大于等于 |
| __lte | 小于等于 |
| __in | 是,例如(年龄是11) |
| __range | 范围,例如(年龄在18到40岁之间的 首尾都要) |
| __contains | 模糊查询,例如(查询出名字里面含有s的数据 ),区分大小写 |
| __icontains | 模糊查询,例如(查询出名字里面含有s的数据 ),不区分大小写 |
| __startswith | 判断是否以某个字母开头,例如(用户名以s开头的) |
| __endswith | 判断是否以某个字母结尾,例如(用户名以s结尾的) |
| __year,__month等 | 时间 |
【3】一对多外键的增删改查
以Book表为例
【3.1】增:create()
- models.Book.objects.create(title = ' 西游记 ',price = ' 100 ' publish_id = 1)
- title:书名、price:价格、publish_id:外键字段
【3.2】删:delete()
- models.Book.objects.filter(id=1).delete()
- id:id字段
- 删除id=1的字段
【3.3】修改:update()
- models.Book.objects.filter(id=1).update(public_id=2)
- 将id=1的那条记录的外键id的值改成2
【4】多对多外键的增删改查
以书籍表和作者表为例
【4.1】增:add
第一步:先查
book_obj = models.Book.objects.filter(id=1).first()
print(book_obj.authors) # 到达第三张表
第二步:增加
book_obj.authors.add(1) # 书籍id为1的书籍绑定一个主键为1 的作者
括号内可以传数字也可以是对象,并且都支持多个
【4.2】删:remove
第一步:先查
book_obj = models.Book.objects.filter(id=1).first()
print(book_obj.authors) # 到达第三张表
第二步:删除
book_obj.authors.remove(1) # 删除外键id=1的全部作者
括号内可以传数字也可以是对象,并且都支持多个
【4.3】修改:set
第一步:先查
book_obj = models.Book.objects.filter(id=1).first()
print(book_obj.authors) # 到达第三张表
第二步:增加
book_obj.authors.set([2]) # 书籍id为1的书的原作者改为外键为2的作者
set():括号内必须填一个可迭代对象,该对象既可以是数字也可以是对象,并且都支持多个
【5】正反向的概念(用于多表查询)
正向:拥有外键字段的表去查别的表。---------正向查询按外键字段查询
反向:没有外键字段的表去查有外键字段的表。
反向查询按表名小写查询。如果表名小写查不到就加_set。例如:book_set
【6】多表查询
【6.1】子查询(基于对象的跨表查询)
- 子查询步骤
- 1、先判断数据的表关系
- 2、判断数据的正反向关系
- 3、写方法
正向例题:
查询书籍主键为1的出版社book_obj = models.Book.objects.filter(pk=1).first()# 书查出版社 正向res = book_obj.publishprint(res)print(res.name)print(res.addr)基于对象在正向什么时候加 .all()问题:
当查询的结果有多个的时候需要加 .all()
反向例题:
查询出版社是东方出版社出版的书publish_obj = models.Publish.objects.filter(name='东方出版社').first()# 出版社查书 反向res = publish_obj.book_set # app01.Book.Noneres = publish_obj.book_set.all()print(res)
基于对象在反向什么时候需要加_set.all()
在反向查询的时候,当查询的结果有多个,就需要加_set.all()
【6.2】联表查询(基于双下划线的跨表查询)
- 联表查询步骤
- 1、先判断数据的表关系
- 2、判断数据的正反向关系
- 3、写方法
例题的正向查询和反向查询的方法
1.查询jason的手机号和作者姓名# 正向 res = models.Author.objects.filter(name='jason').values('author_detail__phone','name')print(res)# 反向 res = models.AuthorDetail.objects.filter(author__name='jason').values('phone','author__name')print(res)
【6.3】聚合查询:aggregate
集合查询一般配合分组一起使用
聚合查询需要导入:from.db.models import Max,Min,Avg,Sum,Count
使用方法:
例子# 1 所有书的平均价格res = models.Book.objects.aggregate(Avg('price'))print(res)# 2.上述方法一次性使用res = models.Book.objects.aggregate(Max('price'),Min('price'),Sum('price'),Count('pk'),Avg('price'))print(res)
【6.4】分组查询:annotate
分组查询特点:
分组之后只能获得分组的依据,其它的字段不能获取。
这是因为设置了严格模式:ONLY_FULL_GROUP_BY
只需要将严格模式的指令去除就行了
例题
from django.db.models import Max, Min, Sum, Count, Avg# 1.统计每一本书的作者个数res = models.Book.objects.annotate(author_num=Count('authors')).values('title','author_num')'''
models点后面的表名,是以Book表分组我们还可以给起别名author_num就是给Count('authors')起别名'''分组查询按照指定字段分组:
models.Book.object.values('price').annotate()
如果出现分组查询报错的情况,解决方式:修改严格模式
【7】F和Q查询
【7.1】F查询
F查询作用:能够帮助我们直接获取到表中某个字段对应的数据
F查询需要导入:from django.db.models import F
F查询实例1:
# 1.查询卖出数大于库存数的书籍from django.db.models import Fres = models.Book.objects.filter(maichu__gt=F('kucun'))print(res)F查询实例2:
# 3.将所有书的名称后面加上爆款两个字"""在操作字符类型的数据的时候 F不能够直接做到字符串的拼接""" # 需要借用Concat方法和Value方法才能实现字符串的拼接from django.db.models.functions import Concatfrom django.db.models import Valuemodels.Book.objects.update(title=Concat(F('title'), Value('爆款')))'''如果直接使用F查询,得到的结果是所有的名称都会变成空白'''# models.Book.objects.update(title=F('title') + '爆款') # 所有的名称会全部变成空白
【7.2】Q查询
Q查询将 filter方法括号内默认的and关系查询变换成or关系查询或not关系查询
Q查询默认有3中关系:and、or、not
1、Q包裹用 " ," 分割是 and 关系
例子:
# 1.查询卖出数大于100或者价格小于600的书籍from django.db.models import Qres = models.Book.objects.filter(Q(maichu__gt=100),Q(price__lt=600)) # Q包裹逗号分割 还是and关系2、Q包裹用" | "分割是 or 关系
# 1.查询卖出数大于100或者价格小于600的书籍from django.db.models import Qres = models.Book.objects.filter(Q(maichu__gt=100)|Q(price__lt=600)) # Q包裹"|"分割 还是and关系3、Q查询前面加" ~ "就是 not 关系
# 1.查询卖出数大于100或者价格小于600的书籍from django.db.models import Qres = models.Book.objects.filter(~Q(maichu__gt=100)|Q(price__lt=600))''' ~Q(maichu__gt=100)只是这个条件是 not关系 竖杠后面的条件不是 not关系~(Q(maichu__gt=100)|Q(price__lt=600):这个才全是not关系'''
Q查询的高阶用法:能够将查询条件左边也变成字符串的形式
语法:
q = Q()q.connector = 'or'q.children.append(('maichu__gt',100))q.children.append(('price__lt',600))res = models.Book.objects.filter(q) # 默认还是and关系print(res)
相关文章:

Django之模型层
【1】常见的13中查询方法 例子语法:models.Userinfo.objects.filter().all() 查询方法解释all()查询所有数据first()那queryset中第一条数据last()那最后一条数据filter()带有过滤条件的查询,查询不到结果返回Noneget()带有guolv条件的查询,…...
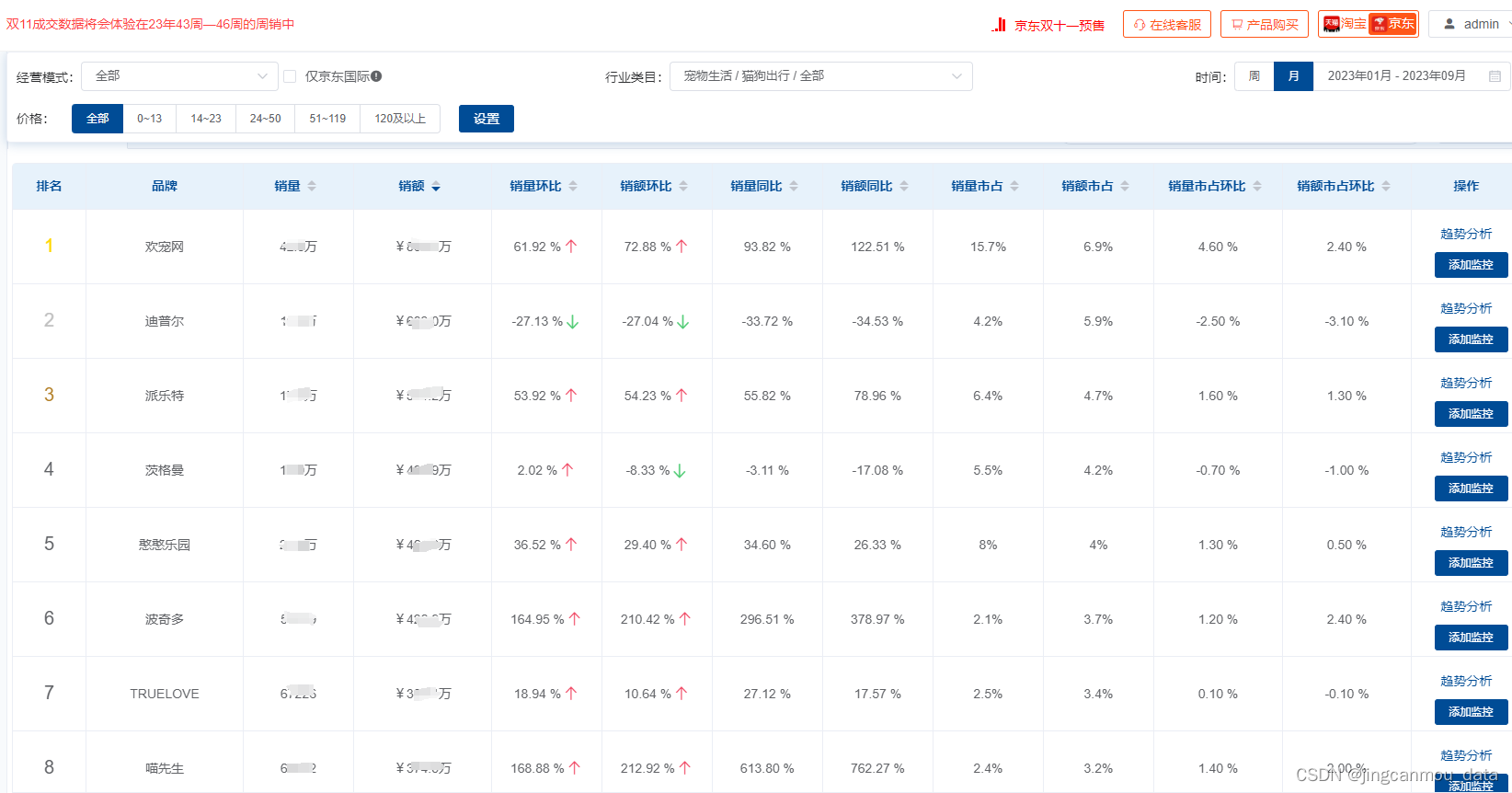
京东数据挖掘(京东运营数据分析):2023年宠物行业数据分析报告
随着社会经济的发展,人均收入水平逐渐提高,使得宠物成为越来越多家庭的成员,宠物数量不断增长。伴随养宠人群的增多,宠物相关产业的发展也不断升温,宠物经济规模持续增长。 根据鲸参谋平台的数据显示,在宠物…...

五分钟k8s实战-Istio 网关
istio-03.png 在上一期 k8s-服务网格实战-配置 Mesh 中讲解了如何配置集群内的 Mesh 请求,Istio 同样也可以处理集群外部流量,也就是我们常见的网关。 其实和之前讲到的k8s入门到实战-使用Ingress Ingress 作用类似,都是将内部服务暴露出去的…...
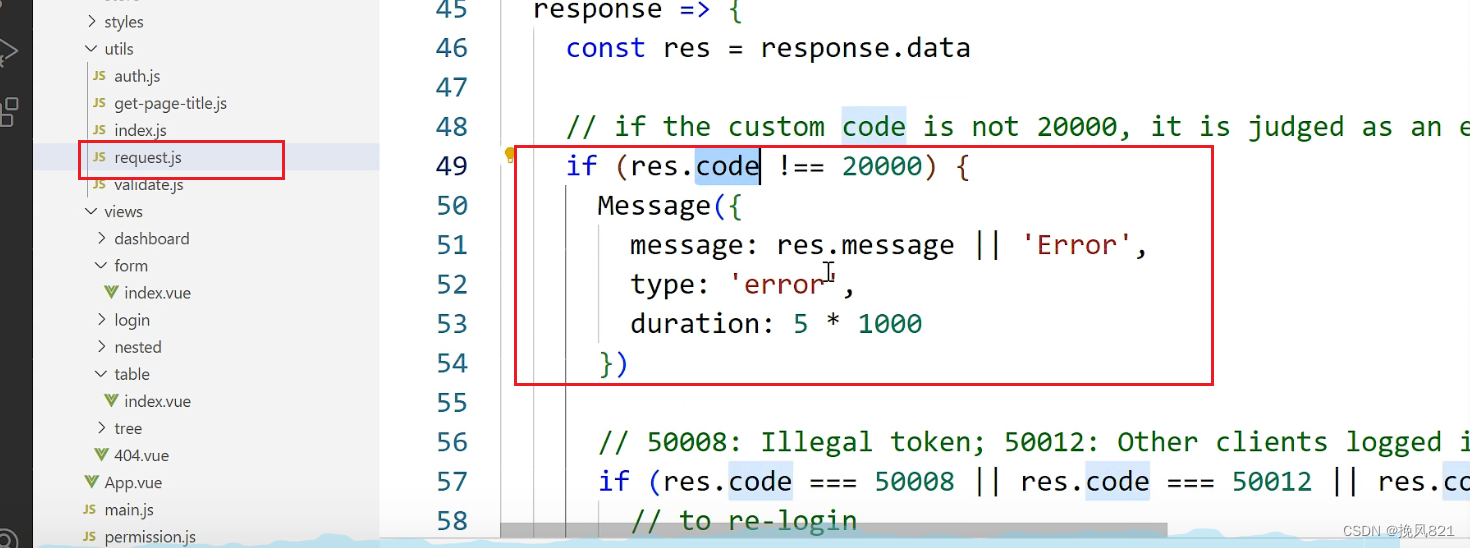
vue-admin-template
修改登录接口 1.f12查看请求接口 模仿返回数据写接口 修改方式1 1.在env.devolopment修改 修改方式2 vue.config.js 改成本地接口地址 配置转发 后端创建相应接口,使用map返回相同的数据 修改前端请求路径 修改前端返回状态码 utils里面的request.js...

Go fsnotify简介
fsnotify是一个用Go编写的文件系统通知库。它提供了一种观察文件系统变化的机制,例如文件的创建、修改、删除、重命名和权限修改。它使用特定平台的事件通知API,例如Linux上的inotify,macOS上的FSEvents,以及Windows上的ReadDirec…...

分类预测 | Matlab实现PSO-BiLSTM-Attention粒子群算法优化双向长短期记忆神经网络融合注意力机制多特征分类预测
分类预测 | Matlab实现PSO-BiLSTM-Attention粒子群算法优化双向长短期记忆神经网络融合注意力机制多特征分类预测 目录 分类预测 | Matlab实现PSO-BiLSTM-Attention粒子群算法优化双向长短期记忆神经网络融合注意力机制多特征分类预测分类效果基本描述程序设计参考资料 分类效果…...
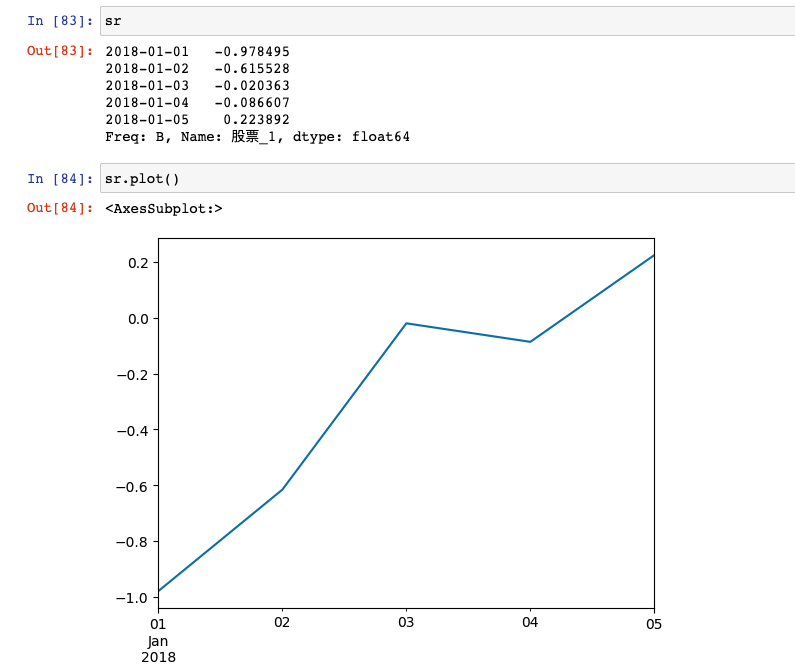
【Python】Pandas(学习笔记)
一、Pandas概述 1、Pandas介绍 2008年WesMcKinney开发出的库,专门用于数据挖掘的开源python库 以Numpy为基础,借力Numpy模块在计算方面性能高的优势 基于matplotib,能够简便的画图 独特的数据结构 import pandas as pd2、Pandas优势 便…...

京联易捷科技与劳埃德私募基金管理有限公司达成合作协议签署
京联易捷科技与劳埃德私募基金管理有限公司今日宣布正式签署合作协议,双方在数字化进程、资产管理与投资以及中英金融合作方面将展开全面合作。 劳埃德(中国)私募基金管理有限公司是英国劳埃德私募基金管理有限公司的全资子公司,拥有丰富的跨境投资经验和卓越的募资能力。该集…...

Netty Review - 从BIO到NIO的进化推演
文章目录 BIODEMO 1DEMO 2小结论单线程BIO的缺陷BIO如何处理并发多线程BIO服务器的弊端 NIONIO要解决的问题模拟NIO方案一: (等待连接时和等待数据时不阻塞)方案二(缓存Socket,轮询数据是否准备好)方案二存…...
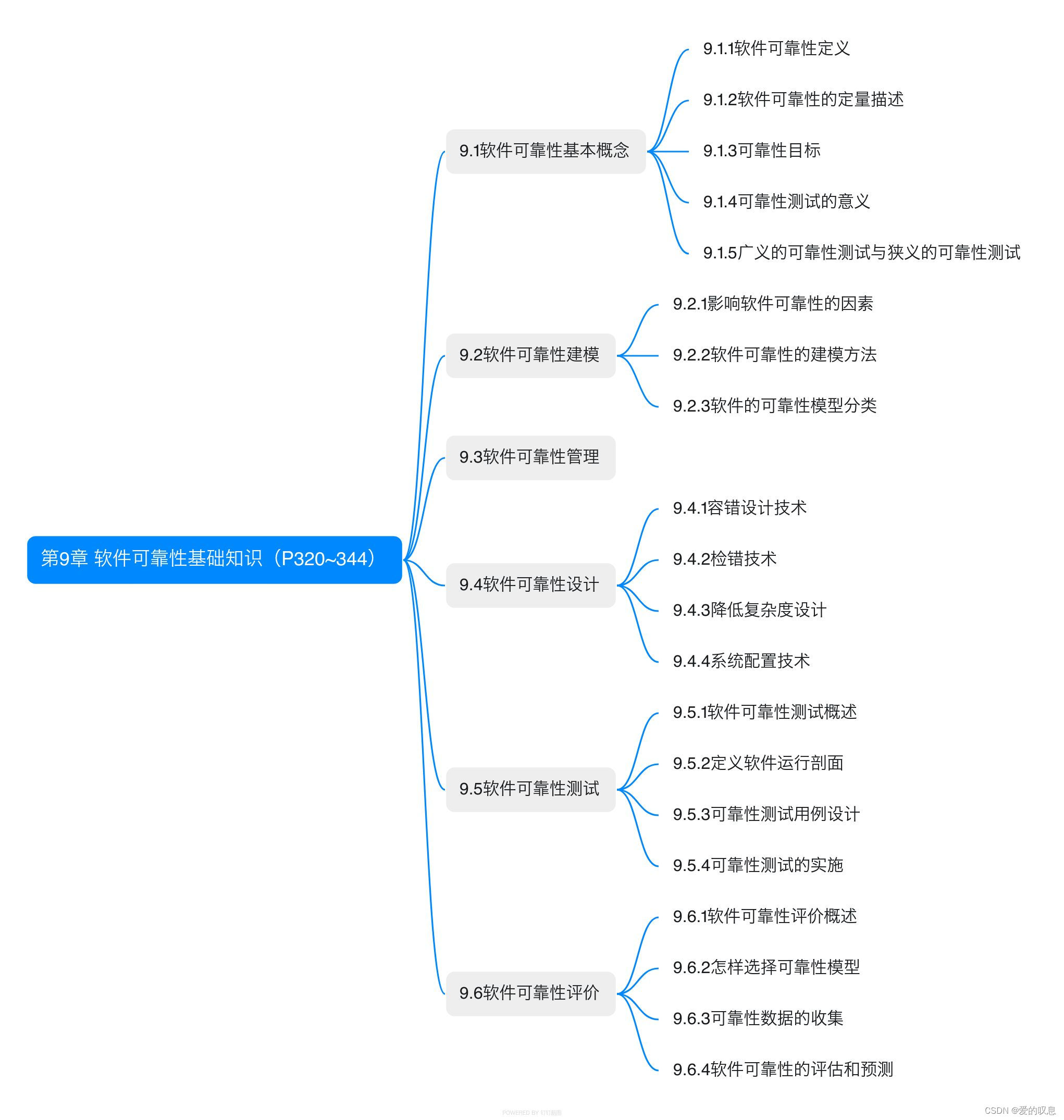
软考-高级-系统架构设计师教程(清华第2版)【第9章 软件可靠性基础知识(P320~344)-思维导图】
软考-高级-系统架构设计师教程(清华第2版)【第9章 软件可靠性基础知识(P320~344)-思维导图】 课本里章节里所有蓝色字体的思维导图...
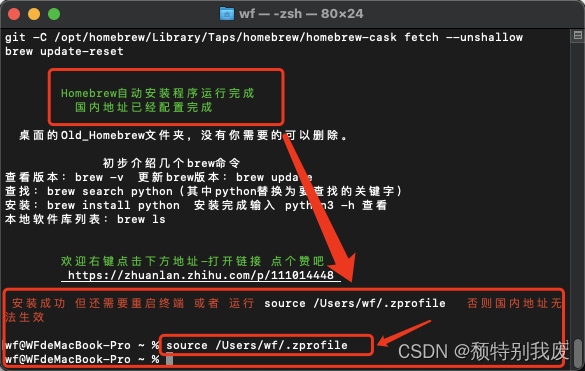
M系列 Mac安装配置Homebrew
目录 首先,验证电脑是否安装了Homebrew 1、打开终端输入以下指令: 2、如图所示,该电脑没有安装Homebrew ,下面我们安装Homebrew 一、官网下载 (不建议) 1、我们打开官网:https://brew.sh/ …...
WebRTC简介及使用
文章目录 前言一、WebRTC 简介1、webrtc 是什么2、webrtc 可以做什么3、数据传输需要些什么4、SDP 协议5、STUN6、TURN7、ICE 二、WebRTC 整体框架三、WebRTC 功能模块1、视频相关①、视频采集---video_capture②、视频编解码---video_coding③、视频加密---video_engine_encry…...

网工内推 | 国企、上市公司售前,CISP/CISSP认证,最高18K*14薪
01 中电福富信息科技有限公司 招聘岗位:售前工程师(安全) 职责描述: 1、对行业、用户需求、竞争对手等方面提出分析报告,为公司市场方向、产品研发和软件开发提供建议; 2、负责项目售前跟踪、技术支持、需…...
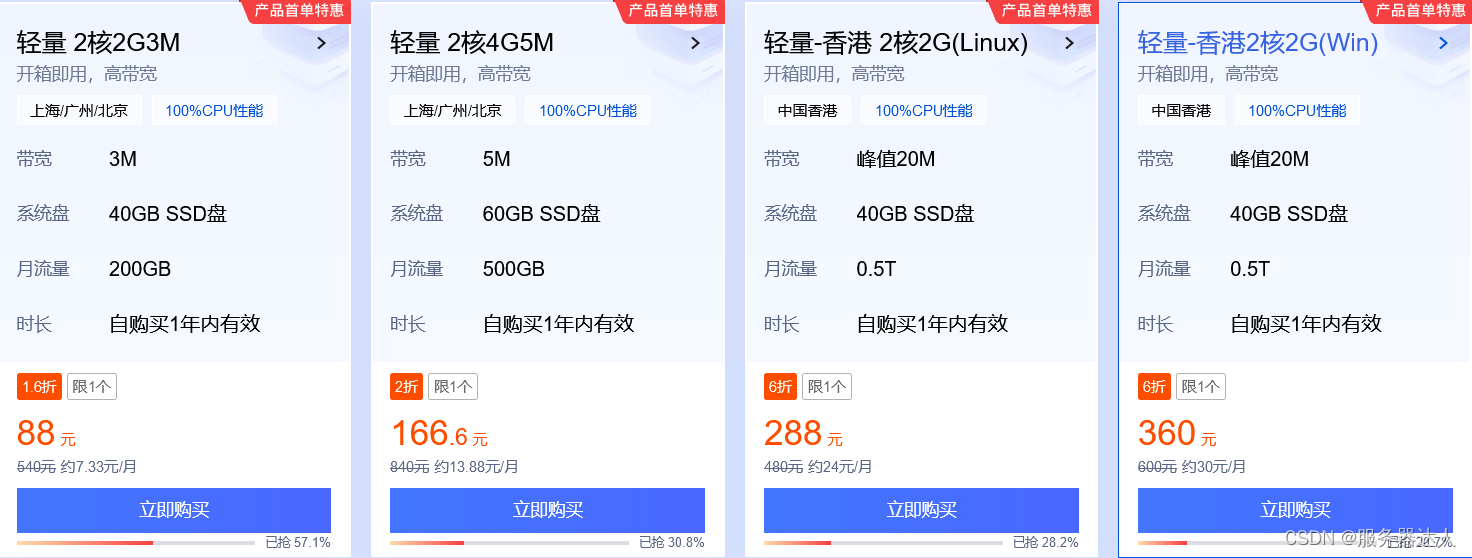
阿里云99元VS腾讯云88元,双11云服务器价格战,谁胜谁负?
在2023年的双十一优惠活动中,阿里云推出了一系列令人惊喜的优惠活动,其中包括99元一年的超值云服务器。本文将带您了解这些优惠活动的具体内容,以及与竞争对手腾讯云的价格对比,助您轻松选择最适合的云服务器。 99元一年服务器优…...

1.jvm基本知识
目录 概述jvm虚拟机三问jvm是什么?java 和 jvm 的关系 为什么学jvm怎么学习为什么jvm调优?什么时候jvm调优调优调什么 结束 概述 相关文章在此总结如下: 文章地址jvm类加载系统地址双亲委派模型与打破双亲委派地址运行时数据区地址运行时数据区-字符串…...

前端---掌握WebAPI:DOM
文章目录 什么是DOM?使用DOM获取元素事件操作元素获取、修改元素内容获取、修改元素属性获取、修改表单元素属性:input获取、修改样式属性直接修改样式:行内样式通过修改class属性来修改样式 新增节点删除节点 什么是DOM? DOM&am…...
)
最优化基础(一)
最优化基础(一)1 最优化问题的数学模型 通俗地说,所谓最优化问题,就是求一个多元函数在某个给定集合上的极值. 几乎所有类型的最优化问题都可以用下面的数学模型来描述: m i n f ( x ) s . t . x ∈ Ω min\ f({x})\\ s.t. \ {…...

基于JavaWeb+SpringBoot+Vue医疗器械商城微信小程序系统的设计和实现
基于JavaWebSpringBootVue医疗器械商城微信小程序系统的设计和实现 源码获取入口前言主要技术系统设计功能截图Lun文目录订阅经典源码专栏Java项目精品实战案例《500套》 源码获取 源码获取入口 前言 摘 要 目前医疗器械行业作为医药行业的一个分支,发展十分迅速。…...

java程序中为什么经常使用tomcat
该疑问的产生场景: 原来接触的ssm项目需要在项目配置中设置tomcat,至于为什么要设置tomcat不清楚,只了解需要配置tomcat后项目才能启动。接触的springboot在项目配置中不需要配置tomcat,原因是springboot框架内置了tomcat…...

大带宽服务器需要选择哪些节点
选择大带宽服务器节点需要考虑以下几个因素: 地理位置:选择距离用户较近的节点,可以降低延迟,提高响应速度。 网络质量:大带宽服务器节点应该有良好的网络质量,稳定可靠,能够提供高速的网络传输…...
)
告别窗口混乱!用RDCMan 2.93一站式管理你的所有Windows服务器(附保姆级配置流程)
告别窗口混乱!用RDCMan 2.93一站式管理你的所有Windows服务器(附保姆级配置流程)当你的工作环境中需要同时管理十几台甚至几十台Windows服务器时,传统的远程桌面连接方式很快就会变成一场噩梦。每个连接都占用一个独立窗口&#x…...

3步实现Windows任务栏透明化:从新手到专家的桌面美化全攻略
3步实现Windows任务栏透明化:从新手到专家的桌面美化全攻略 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB Windows任务栏透明…...

百度网盘直链解析技术实现与高速下载架构设计
百度网盘直链解析技术实现与高速下载架构设计 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在云存储服务日益普及的今天,百度网盘作为国内用户量最大的云存储平台…...

从文本到流程:NLP与LLM驱动的业务流程模型自动提取技术
1. 项目概述与核心价值在业务流程管理(BPM)的日常工作中,我们经常遇到一个经典难题:业务部门或客户给出一大段文字描述,比如一份操作手册、一封需求邮件或一次会议纪要,我们需要从中梳理出清晰、可执行的业…...

[智能体-28]:Python HTTP 请求库:requests 背景、原理、作用 完整版详解
一、全称与字面含义Requests:英文本意「请求、申请」Python 中:HTTP 请求库二、诞生背景Python 原生自带 urllib、urllib2语法冗长、写法繁琐、兼容性差、使用门槛高。2011 年 Kenneth Reitz 开发 requests口号:HTTP for Humans(给…...

软体机器人跳跃:离散弹性杆仿真与动态分岔原理详解
1. 软体机器人跳跃:从生物灵感走向工程现实如果你观察过一只蚂蚱的起跳,或者一只青蛙的弹射,那种瞬间爆发、姿态优雅的运动,背后是自然界亿万年来优化的高效能量转换机制。传统的刚性机器人,靠着电机、齿轮和连杆&…...

建筑项目进度延误率下降37%的秘密:一个轻量化AI Agent工作流,已在12个EPC项目中闭环验证
更多请点击: https://codechina.net 第一章:建筑项目进度延误率下降37%的秘密:一个轻量化AI Agent工作流,已在12个EPC项目中闭环验证 在某头部工程总承包(EPC)企业落地的轻量化AI Agent工作流,…...

量子态估计新突破:超越置乱时间,QELM稳健实现高效信息提取
1. 项目概述 量子态估计,简单来说,就是“看清”一个未知量子系统内部状态的过程。这好比在完全黑暗的房间里,你需要通过有限的光线(测量)来推断房间内物体的精确形状和位置。在量子计算、量子通信和量子传感等领域&…...

AI医疗转化瓶颈诊断:网络分析与LLM分类的工程实践
1. 项目概述:当AI医疗研究撞上转化“玻璃墙”在医疗健康领域,人工智能(AI)的研究论文和专利数量正以前所未有的速度增长。作为一名长期关注医疗科技转化的从业者,我亲眼见证了从早期影像识别到如今大语言模型ÿ…...

GParted实战:从虚拟机沙盒到实体机,安全演练Linux分区合并与扩容全流程
GParted实战:从虚拟机沙盒到实体机,安全演练Linux分区合并与扩容全流程在虚拟机的安全环境中练习Linux分区操作,就像飞行员在模拟器中训练紧急情况处理一样重要。GParted作为Linux系统管理员的"瑞士军刀",其强大功能背后…...