【Pytorch笔记】7.torch.nn (Convolution Layers)
我们常用torch.nn来封装网络,torch.nn为我们封装好了很多神经网络中不同的层,如卷积层、池化层、归一化层等。我们会把这些层像是串成一个牛肉串一样串起来,形成网络。
先从最简单的,都有哪些层开始学起。
Convolution Layers - 卷积层
torch.nn.Conv1d()
1维卷积层。
torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
in_channels:输入tensor的通道数;
out_channels:输出tensor的通道数;
kernel_size:卷积核的大小;
stride:步长;
padding:输入tensor的边界填充尺寸;
dilation:卷积核之间的间距(下面这个图为dilation=2),默认为1;

groups:从输入通道到输出通道的阻塞连接数。in_channel和out_channel需要能被groups整除。更具体地:
groups=1时所有输入均与所有输出进行卷积,groups=2时该操作相当于并排设置两个卷积层,每卷积层看到一半的输入通道,产生一半的输出通道,然后将两个卷积层连接起来。groups=in_channel时输入的每个通道都和相应的卷积核进行卷积;
bias:是否添加可学习的偏差值,True为添加,False为不添加。
padding_mode:填充模式,有以下取值:zeros(这个是默认值)、reflect、replicate、circular。
import torch
import torch.nn as nnm = nn.Conv1d(in_channels=16,out_channels=33,kernel_size=3,stride=2)
# input: 批大小为20,每个数据通道为16,size=50
input = torch.randn(20, 16, 50)
output = m(input)
print(output.size())
输出
# output: 批大小为20,每个数据通道为33,size=24
torch.Size([20, 33, 24])
torch.nn.Conv2d()
2维卷积层。
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
参数与Conv1d()基本一样,不再赘述。
import torch
import torch.nn as nnm = nn.Conv2d(in_channels=2,out_channels=3,kernel_size=3,stride=2)
input = torch.randn(20, 2, 5, 6)
output = m(input)
print(output.size())
输出
torch.Size([20, 3, 2, 2])
torch.nn.Conv3d()
3维卷积层。
torch.nn.Conv3d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
参数与Conv1d()基本一样,不再赘述。
import torch
import torch.nn as nnm = nn.Conv3d(in_channels=2,out_channels=3,kernel_size=3,stride=2)
input = torch.randn(20, 2, 4, 5, 6)
output = m(input)
print(output.size())
输出
torch.Size([20, 3, 1, 2, 2])
torch.nn.ConvTranspose1d()
1维转置卷积层。
torch.nn.ConvTranspose1d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros', device=None, dtype=None)
参数与Conv1d()基本一样,不再赘述。
唯一不同的是output_padding,与padding不同的是,output_padding是输出tensor的每一个边,外面填充的层数。
(padding是输入tensor的每个边填充的层数)
import torch
import torch.nn as nnm = nn.ConvTranspose1d(in_channels=2,out_channels=3,kernel_size=3,stride=1)
input = torch.randn(20, 2, 2)
output = m(input)
print(output.size())
输出
torch.Size([20, 3, 4])
torch.nn.ConvTranspose2d()
2维转置卷积层。
torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros', device=None, dtype=None)
参数与Conv1d()基本一样,不再赘述。
import torch
import torch.nn as nnm = nn.ConvTranspose2d(in_channels=2,out_channels=3,kernel_size=3,stride=1)
input = torch.randn(20, 2, 2, 2)
output = m(input)
print(output.size())
输出
torch.Size([20, 3, 4, 4])
torch.nn.ConvTranspose3d()
3维转置卷积层。
torch.nn.ConvTranspose3d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros', device=None, dtype=None)
参数与Conv1d()基本一样,不再赘述。
import torch
import torch.nn as nnm = nn.ConvTranspose3d(in_channels=2,out_channels=3,kernel_size=3,stride=1)
input = torch.randn(20, 2, 2, 2, 2)
output = m(input)
print(output.size())
输出
torch.Size([20, 3, 4, 4, 4])
torch.nn.LazyConv1d()
1维延迟初始化卷积层,当in_channel不确定时可使用这个层。
关于延迟初始化,大家可以参考这篇文章,我认为讲的很好:
俱往矣… - 延迟初始化——【torch学习笔记】
torch.nn.LazyConv1d(out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
LazyConv1d没有in_channel参数。
这不代表这个层没有输入的通道,而是在调用时自动适配,并进行初始化。
引用文章中的一段代码,改成LazyConv1d,讲述使用方法。
import torch
import torch.nn as nnnet = nn.Sequential(nn.LazyConv1d(256, 2),nn.ReLU(),nn.Linear(9, 10)
)
print(net)
[net[i].state_dict() for i in range(len(net))]low = torch.finfo(torch.float32).min / 10
high = torch.finfo(torch.float32).max / 10
X = torch.zeros([2, 20, 10], dtype=torch.float32).uniform_(low, high)
net(X)
print(net)
输出
Sequential((0): LazyConv1d(0, 256, kernel_size=(2,), stride=(1,))(1): ReLU()(2): Linear(in_features=9, out_features=10, bias=True)
)
Sequential((0): Conv1d(20, 256, kernel_size=(2,), stride=(1,))(1): ReLU()(2): Linear(in_features=9, out_features=10, bias=True)
)
可以看出,未进行初始化时,in_features=0。只有传入参数使用网络后才会根据输入进行初始化。
torch.nn.LazyConv2d()
2维延迟初始化卷积层。
torch.nn.LazyConv2d(out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
torch.nn.LazyConv3d()
3维延迟初始化卷积层。
torch.nn.LazyConv3d(out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
torch.nn.LazyConvTranspose1d()
1维延迟初始化转置卷积层。
torch.nn.LazyConvTranspose1d(out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros', device=None, dtype=None)
torch.nn.LazyConvTranspose2d()
2维延迟初始化转置卷积层。
torch.nn.LazyConvTranspose2d(out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros', device=None, dtype=None)
torch.nn.LazyConvTranspose3d()
3维延迟初始化转置卷积层。
torch.nn.LazyConvTranspose3d(out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros', device=None, dtype=None)
torch.nn.Unfold()
从一个批次的输入张量中提取出滑动的局部区域块。
torch.nn.Unfold(kernel_size, dilation=1, padding=0, stride=1)
kernel_size:滑动块的大小;
dilation:卷积核之间的间距(torch.nn.Conv1d中有图示);
padding:输入tensor的边界填充尺寸;
stride:滑块滑动的步长。
这里的输入必须是4维的tensor,否则会报这样的错误:
NotImplementedError: Input Error: Only 4D input Tensors are supported (got 2D)
示例
import torch
from torch import nnt = torch.tensor([[[[1., 2., 3., 4.],[5., 6., 7., 8.],[9., 10., 11., 12.],[13., 14., 15., 16.],]]])unfold = nn.Unfold(kernel_size=(2, 2), dilation=1, padding=0, stride=1)
output = unfold(t)
print(output)
输出
tensor([[[ 1., 2., 3., 5., 6., 7., 9., 10., 11.],[ 2., 3., 4., 6., 7., 8., 10., 11., 12.],[ 5., 6., 7., 9., 10., 11., 13., 14., 15.],[ 6., 7., 8., 10., 11., 12., 14., 15., 16.]]])
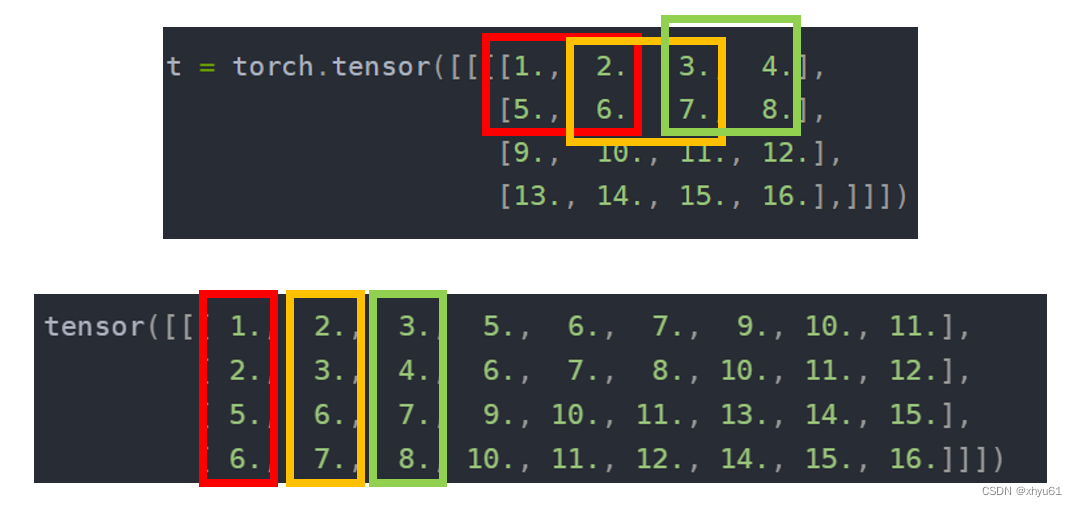
torch.nn.Fold()
Unfold()的逆操作。当Unfold()时出现滑块有重复覆盖时会导致结果和原来不一样。因为Fold()的过程中对于同一个位置的元素进行加法处理。
torch.nn.Fold(output_size, kernel_size, dilation=1, padding=0, stride=1)
下面是Unfold()和Fold()结合的代码,Unfold()部分和上面代码相同。
import torch
from torch import nnt = torch.tensor([[[[1., 2., 3., 4.],[5., 6., 7., 8.],[9., 10., 11., 12.],[13., 14., 15., 16.]]]])unfold = nn.Unfold(kernel_size=(2, 2), dilation=1, padding=0, stride=1)
output = unfold(t)
print(output)
fold = nn.Fold(output_size=(4, 4), kernel_size=(2, 2))
out = fold(output)
print(out)
输出
tensor([[[ 1., 2., 3., 5., 6., 7., 9., 10., 11.],[ 2., 3., 4., 6., 7., 8., 10., 11., 12.],[ 5., 6., 7., 9., 10., 11., 13., 14., 15.],[ 6., 7., 8., 10., 11., 12., 14., 15., 16.]]])
tensor([[[[ 1., 4., 6., 4.],[10., 24., 28., 16.],[18., 40., 44., 24.],[13., 28., 30., 16.]]]])
相关文章:
【Pytorch笔记】7.torch.nn (Convolution Layers)
我们常用torch.nn来封装网络,torch.nn为我们封装好了很多神经网络中不同的层,如卷积层、池化层、归一化层等。我们会把这些层像是串成一个牛肉串一样串起来,形成网络。 先从最简单的,都有哪些层开始学起。 Convolution Layers -…...
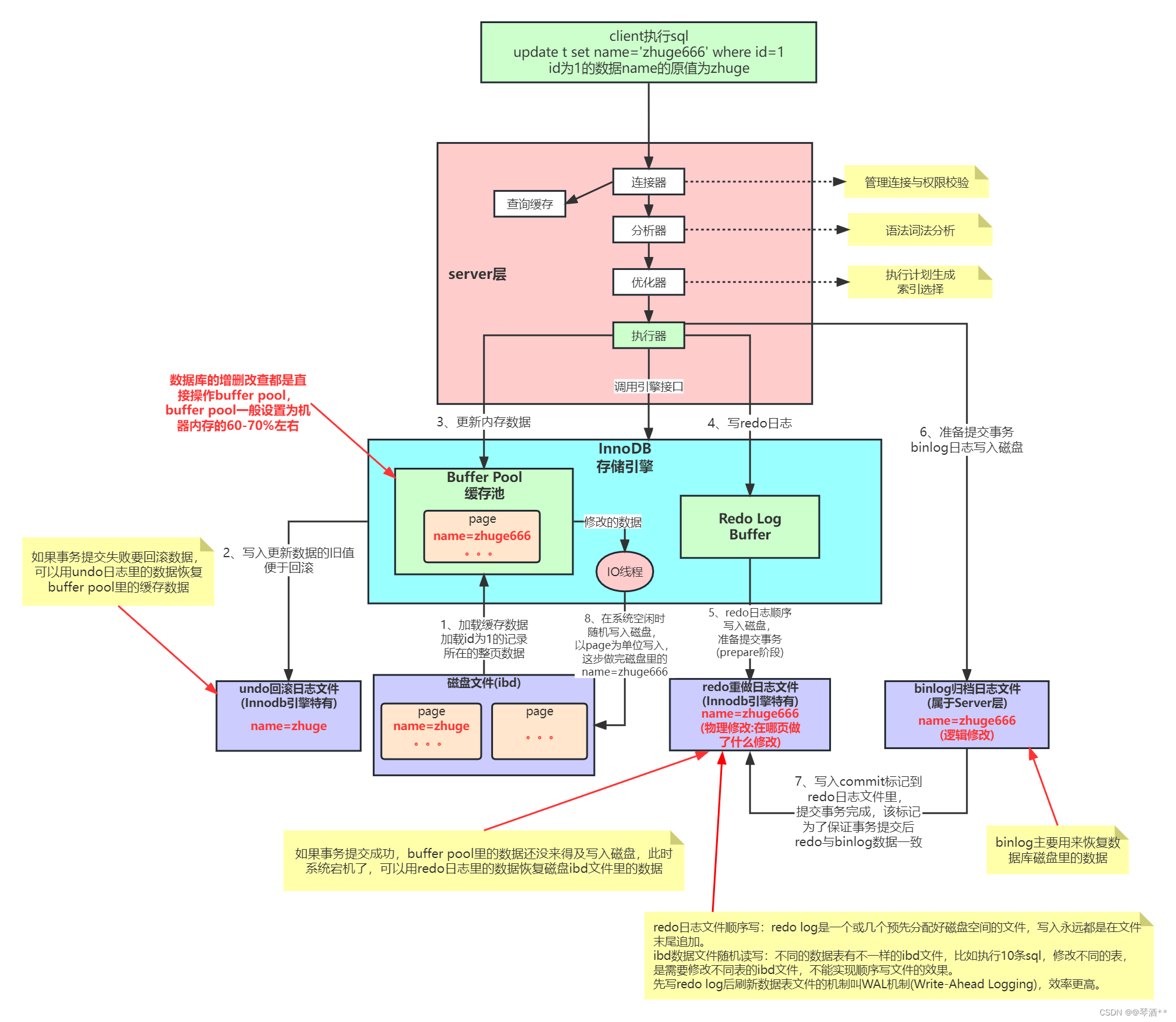
MySQL内部组件与日志详解
MySQL的内部组件结构 MySQL 可以分为 Server 层和存储引擎层两部分。 Server 层主要包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等)&am…...

【LeetCode】94. 二叉树的中序遍历
94. 二叉树的中序遍历 难度:简单 题目 给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。 示例 1: 输入:root [1,null,2,3] 输出:[1,3,2]示例 2: 输入:root [] 输出:[]示…...

IP-guard WebServer 命令执行漏洞复现
简介 IP-guard是一款终端安全管理软件,旨在帮助企业保护终端设备安全、数据安全、管理网络使用和简化IT系统管理。在旧版本申请审批的文件预览功能用到了一个开源的插件 flexpaper,使用的这个插件版本存在远程命令执行漏洞,攻击者可利用该漏…...

TensorFlow案例学习:图片风格迁移
准备 官方教程: 任意风格的快速风格转换 模型下载地址: https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2 学习 加载要处理的内容图片和风格图片 # 用于将图像裁剪为方形def crop_center(image):# 图片原始形状shape image…...
解密网络世界的秘密——Wireshark Mac/Win中文版网络抓包工具
在当今数字化时代,网络已经成为了人们生活和工作中不可或缺的一部分。然而,对于网络安全和性能的监控和分析却是一项重要而又复杂的任务。为了帮助用户更好地理解和解决网络中的问题,Wireshark作为一款强大的网络抓包工具,应运而生…...

自学ansible笔记
一、认识ansible Ansible是一款开源自动化运维工具。它有如下特点: 1、不需要安装客户端,通过sshd去通信,比较轻量化; 2、基于模块工作,模块可以由任何语言开发,比较自由和开放; 3、不仅支持命…...
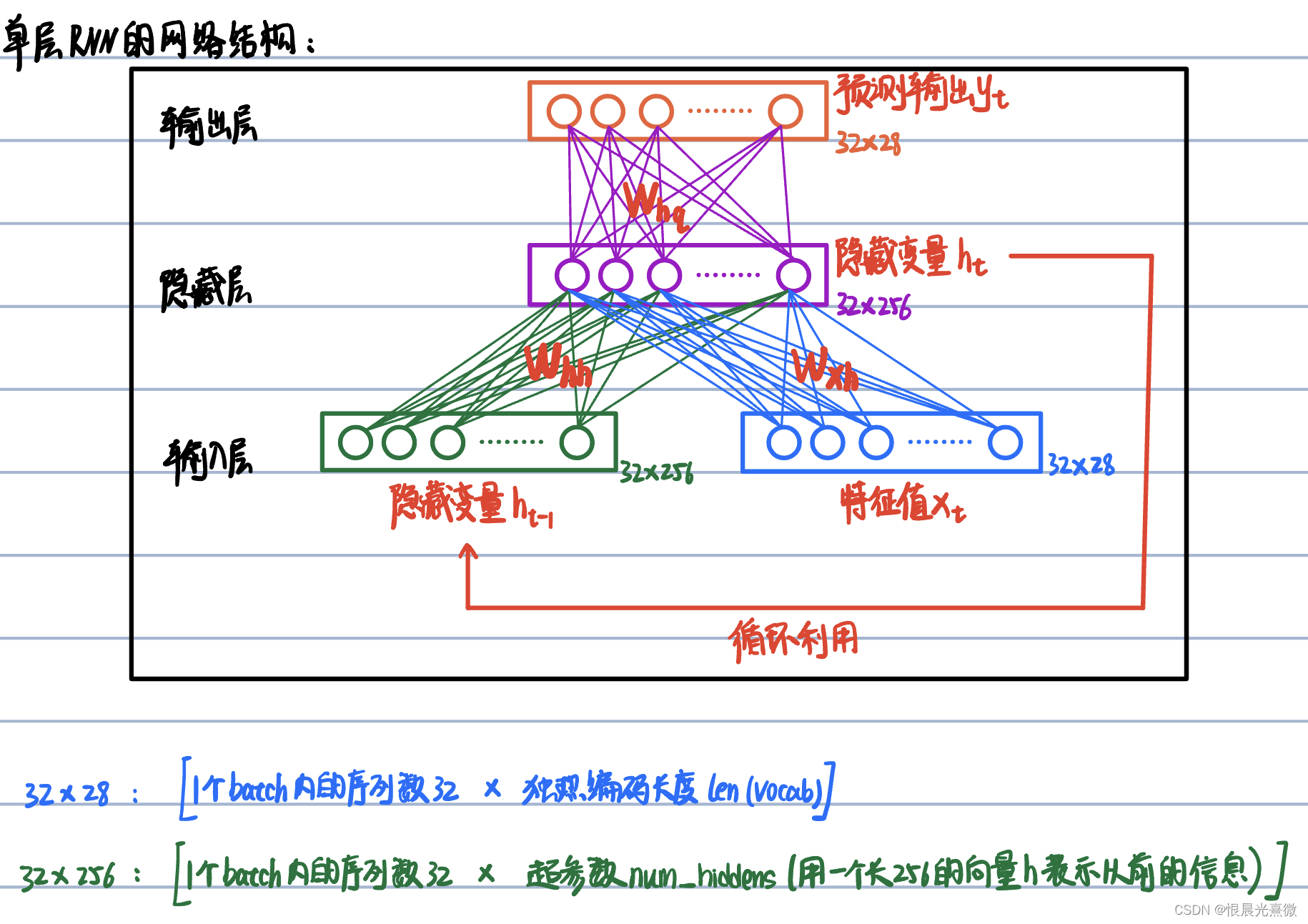
笔记53:torch.nn.rnn() 函数详解
参数解释: (1)input_size():即输入信息 Xt 的每个序列的独热编码向量的长度,即 len(vocab) (2)hidden_size():即隐变量 h 的维度(维度是多少,就代表用几个数…...
【Spring】使用三方包进行数据源对象(数据库)管理
在这里使用alibaba的druid来连接数据库,然后再Spring Config下配置数据库 目录 第一步:在pom.xml中导入坐标第二步:在bean中配置连接注 第一步:在pom.xml中导入坐标 在dependencies下写: <dependency><grou…...
EfficientNet:通过模型效率彻底改变深度学习
一、介绍 EfficientNet 是深度学习领域的里程碑,代表了神经网络架构方法的范式转变。EfficientNet 由 Google Research 的 Mingxing Tan 和 Quoc V. Le 开发,在不影响性能的情况下满足了对计算高效模型不断增长的需求。本文深入探讨了 EfficientNet 背后…...
asp.net core mvc之 布局
一、布局是什么? 布局是把每个页面的公共部分,提取成一个布局页面(头、导航、页脚)。 二、默认布局 _Layout.cshtml 默认的布局是在 /Views/Shared 目录的 _Layout.cshtml文件。通常Shared目录中的视图都是公共视图。该目录下的…...

【QT HTTP】使用QtNetwork模块制作基于HTTP请求的C/S架构
目录 0 引言1 HTTP基本知识1.1 请求类型1.2 HTTP请求报文格式1.3 HTTP响应报文格式1.4 拓展:GET vs POST 请求方法GET请求请求报文:响应报文 POST请求请求报文响应报文 其他注意事项示例:GET请求示例POST请求示例 2 实战2.1 QtNetwork模块介绍…...
R语言绘制精美图形 | 火山图 | 学习笔记
一边学习,一边总结,一边分享! 教程图形 前言 最近的事情较多,教程更新实在是跟不上,主要原因是自己没有太多时间来学习和整理相关的内容。一般在下半年基本都是非常忙,所有一个人的精力和时间有限&#x…...

远程创建分支本地VScode看不到分支
在代码存放处右击,点击Git Bash Here 输入git fetch–从远程仓库中获取最新的分支代码和提交历史 就OK啦,现在分支可以正常查看了...

python后台框架简介
python后台框架 Python是一种流行的编程语言,它有许多优点,如简洁、易读、灵活和功能强大。Python也是一种常用的后端开发语言,它可以用来构建各种类型的网站和应用程序。Python有许多后端框架,可以帮助开发者快速地开发和部署后…...

spring boot validation使用
spring-boot-starter-validation 是 Spring Boot 中用于支持数据验证的模块。它建立在 Java Validation API(JSR-380)之上,提供了一种方便的方式来验证应用程序中的数据。以下是使用 spring-boot-starter-validation 的基本方法: …...
Hadoop3.3.4分布式安装
安装前提:已经配置好java环境,所有机器之间ssh的免密登录。 注意:下文中的flinkv1、flinkv2、flinkv3是三台服务器的别名 1.集群部署规划 注意:NameNode和SecondaryNameNode不要安装在同一台服务器 注意:ResourceMan…...

SQL ALTER TABLE 语句||SQL AUTO INCREMENT 字段
SQL ALTER TABLE 语句 ALTER TABLE 语句 ALTER TABLE 语句用于在现有表中添加、删除或修改列。 SQL ALTER TABLE 语法 若要向表中添加列,请使用以下语法: ALTER TABLE table_name ADD column_name datatype 若要删除表中的列&am…...

【源码系列】短剧系统开发国际版短剧系统软件平台介绍
系统介绍 短剧是一种快节奏、紧凑、有趣的戏剧形式,通过短时间的精彩表演,向观众传递故事的情感和思考。它以其独特的形式和魅力,吸引着观众的关注,成为了当代戏剧娱乐中不可或缺的一部分。短剧每一集都是一个小故事,…...
JavaWeb[总结]
文章目录 一、Tomcat1. BS 与 CS 开发介绍1.1 BS 开发1.2 CS 开发 2. 浏览器访问 web 服务过程详解(面试题)2.1 回到前面的 JavaWeb 开发技术栈图2.2 浏览器访问 web 服务器文件的 UML时序图(过程) ! 二、动态 WEB 开发核心-Servlet1. 为什么会出现 Servlet2. 什么是…...

不同品牌路由器也能玩桥接?TP-LINK AC1200主路由+FAST FWR303副路由详细配置指南
跨品牌路由器桥接实战:TP-LINK AC1200与FAST FWR303混合组网全解析 现代家庭网络环境中,信号死角问题如同房间角落的灰尘一样难以避免。特别是当房屋结构复杂或面积较大时,单台路由器往往力不从心。此时,利用家中闲置的旧路由器进…...

重构macOS开发流程:OpenInTerminal如何提升开发者环境切换效率
重构macOS开发流程:OpenInTerminal如何提升开发者环境切换效率 【免费下载链接】OpenInTerminal ✨ Finder Toolbar app for macOS to open the current directory in Terminal, iTerm, Hyper or Alacritty. 项目地址: https://gitcode.com/gh_mirrors/op/OpenInT…...

3个步骤实现教育资源高效获取:电子教材下载工具全攻略
3个步骤实现教育资源高效获取:电子教材下载工具全攻略 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具 项目地址: https://gitcode.com/GitHub_Trending/tc/tchMaterial-parser tchMaterial-parser是一款专为教育工作者和学习…...

Opyrator UI设计技巧:5个Streamlit自动生成界面教程
Opyrator UI设计技巧:5个Streamlit自动生成界面教程 【免费下载链接】opyrator 🪄 Turns your machine learning code into microservices with web API, interactive GUI, and more. 项目地址: https://gitcode.com/gh_mirrors/op/opyrator Opyr…...

深入解析原生HTTP与MCP服务器的交互机制
1. 原生HTTP与MCP服务器交互的核心机制 当你第一次听说MCP服务器时,可能会觉得这是个高大上的概念。其实简单来说,MCP(Model Context Protocol)就是一种让客户端和AI模型服务端进行高效通信的协议。而HTTP作为互联网最基础的通信协…...
)
华为ENSP实战:手把手教你搭建住宅小区网络拓扑(附完整配置脚本)
华为ENSP实战:从零构建智能小区网络的全栈解决方案 当清晨第一缕阳光透过窗帘洒进房间,现代人睁开眼的第一件事往往是拿起手机查看消息——这种习以为常的场景背后,是无数个日夜运行的住宅小区网络在默默支撑。作为网络工程师,我…...
)
ccmusic-database从零开始:基于ccmusic-database微调新增流派(如国风/电子)
ccmusic-database从零开始:基于ccmusic-database微调新增流派(如国风/电子) 1. 项目介绍与背景 音乐流派分类是音频分析领域的重要应用,ccmusic-database项目基于深度学习技术,能够自动识别音频文件的音乐流派。这个…...

智科毕业设计易上手选题100例
0 选题推荐 - 汇总篇 毕业设计是大家学习生涯的最重要的里程碑,它不仅是对四年所学知识的综合运用,更是展示个人技术能力和创新思维的重要过程。选择一个合适的毕业设计题目至关重要,它应该既能体现你的专业能力,又能满足实际应用…...

Java函数冷启动优化不是“选配”,而是SLA硬指标!一线大厂SRE团队正在紧急落地的6项Kubernetes调度增强策略
第一章:Java函数冷启动的本质与SLA倒逼机制Java函数冷启动并非单纯“首次加载慢”的表象,而是JVM生命周期、类加载机制、字节码验证、即时编译(JIT)预热及运行时元数据初始化等多层系统行为在无预热上下文下的集中爆发。当Serverl…...

SQLite Indexed By: 高效索引策略解析与应用
SQLite Indexed By: 高效索引策略解析与应用 引言 SQLite 是一款轻量级的关系型数据库管理系统,以其小巧的体积和强大的功能在移动应用、嵌入式系统和网络应用中得到了广泛的应用。索引是数据库中不可或缺的一部分,它能够极大地提高查询效率。本文将深入探讨 SQLite 的索引…...