基于PyTorch搭建你的生成对抗性网络

前言
你听说过GANs吗?还是你才刚刚开始学?GANs是2014年由蒙特利尔大学的学生 Ian Goodfellow 博士首次提出的。GANs最常见的例子是生成图像。有一个网站包含了不存在的人的面孔,便是一个常见的GANs应用示例。也是我们将要在本文中进行分享的。
生成对抗网络由两个神经网络组成,生成器和判别器相互竞争。我将在后面详细解释每个步骤。希望在本文结束时,你将能够从零开始训练和建立自己的生财之道对抗性网络。所以闲话少说,让我们开始吧。
目录
步骤0: 导入数据集
步骤1: 加载及预处理图像
步骤2: 定义判别器算法
步骤3: 定义生成器算法
步骤4: 编写训练算法
步骤5: 训练模型
步骤6: 测试模型
步骤0: 导入数据集
第一步是下载并将数据加载到内存中。我们将使用 CelebFaces Attributes Dataset (CelebA)来训练你的对抗性网络。主要分以下三个步骤:
1. 下载数据集:
https://s3.amazonaws.com/video.udacity-data.com/topher/2018/November/5be7eb6f_processed-celeba-small/processed-celeba-small.zip;
2. 解压缩数据集;
3. Clone 如下 GitHub地址:
https://github.com/Ahmad-shaikh575/Face-Generation-using-GANS
这样做之后,你可以在 colab 环境中打开它,或者你可以使用你自己的 pc 来训练模型。
导入必要的库
#import the neccessary libraries
import pickle as pkl
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch
from torchvision import datasets
from torchvision import transforms
import torch
import torch.optim as optim步骤1: 加载及预处理图像
在这一步中,我们将预处理在前一节中下载的图像数据。
将采取以下步骤:
-
调整图片大小
-
转换成张量
-
加载到 PyTorch 数据集中
-
加载到 PyTorch DataLoader 中
# Define hyperparameters
batch_size = 32
img_size = 32
data_dir='processed_celeba_small/'# Apply the transformations
transform = transforms.Compose([transforms.Resize(image_size),transforms.ToTensor()])
# Load the dataset
imagenet_data = datasets.ImageFolder(data_dir,transform= transform)# Load the image data into dataloader
celeba_train_loader = torch.utils.data.DataLoader(imagenet_data,batch_size,shuffle=True)图像的大小应该足够小,这将有助于更快地训练模型。Tensors 基本上是 NumPy 数组,我们只是将图像转换为在 PyTorch 中所必需的 NumPy 数组。
然后我们加载这个转换成的 PyTorch 数据集。在那之后,我们将把我们的数据分成小批量。这个数据加载器将在每次迭代时向我们的模型训练过程提供图像数据。
随着数据的加载完成。现在,我们可以预处理图像。
图像的预处理
我们将在训练过程中使用 tanh 激活函数。该生成器的输出范围在 -1到1之间。我们还需要对这个范围内的图像进行缩放。代码如下所示:
def scale(img, feature_range=(-1, 1)):'''Scales the input image into given feature_range'''min,max = feature_rangeimg = img * (max-min) + minreturn img这个函数将对所有输入图像缩放,我们将在后面的训练中使用这个函数。
现在我们已经完成了无聊的预处理步骤。
接下来是令人兴奋的部分,现在我们需要为我们的生成器和判别器神经网络编写代码。
步骤2: 定义判别器算法
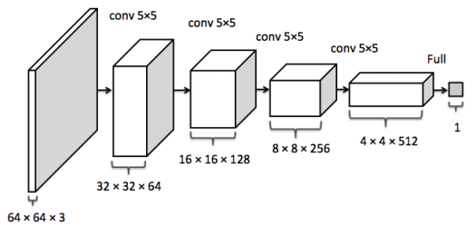
判别器是一个可以区分真假图像的神经网络。真实的图像和由生成器生成的图像都将提供给它。
我们将首先定义一个辅助函数,这个辅助函数在创建卷积网络层时非常方便。
# helper conv function
def conv(in_channels, out_channels, kernel_size, stride=2, padding=1, batch_norm=True):layers = []conv_layer = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=False)#Appending the layerlayers.append(conv_layer)#Applying the batch normalization if it's given trueif batch_norm:layers.append(nn.BatchNorm2d(out_channels))# returning the sequential containerreturn nn.Sequential(*layers)这个辅助函数接收创建任何卷积层所需的参数,并返回一个序列化的容器。现在我们将使用这个辅助函数来创建我们自己的判别器网络。
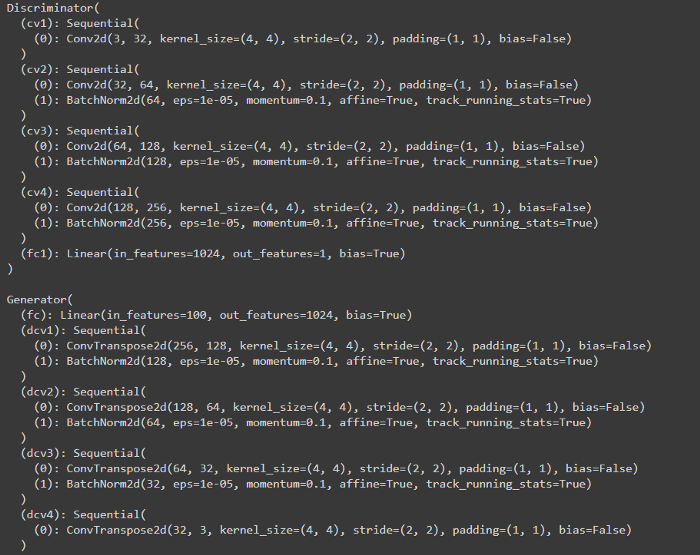
class Discriminator(nn.Module):def __init__(self, conv_dim):super(Discriminator, self).__init__()self.conv_dim = conv_dim#32 x 32self.cv1 = conv(3, self.conv_dim, 4, batch_norm=False)#16 x 16self.cv2 = conv(self.conv_dim, self.conv_dim*2, 4, batch_norm=True)#4 x 4self.cv3 = conv(self.conv_dim*2, self.conv_dim*4, 4, batch_norm=True)#2 x 2self.cv4 = conv(self.conv_dim*4, self.conv_dim*8, 4, batch_norm=True)#Fully connected Layerself.fc1 = nn.Linear(self.conv_dim*8*2*2,1)def forward(self, x):# After passing through each layer# Applying leaky relu activation functionx = F.leaky_relu(self.cv1(x),0.2)x = F.leaky_relu(self.cv2(x),0.2)x = F.leaky_relu(self.cv3(x),0.2)x = F.leaky_relu(self.cv4(x),0.2)# To pass throught he fully connected layer# We need to flatten the image firstx = x.view(-1,self.conv_dim*8*2*2)# Now passing through fully-connected layerx = self.fc1(x)return x步骤3: 定义生成器算法
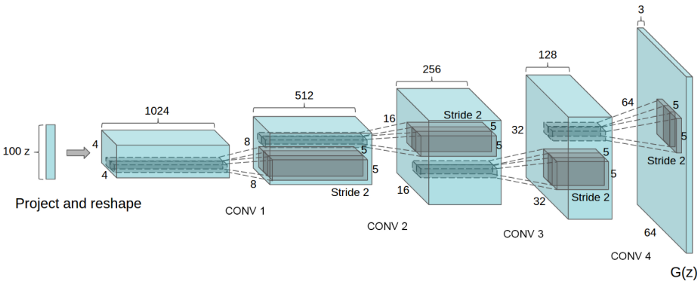
正如你们从图中看到的,我们给网络一个高斯矢量或者噪声矢量,它输出 s 中的值。图上的“ z”表示噪声,右边的 G (z)表示生成的样本。
与判别器一样,我们首先创建一个辅助函数来构建生成器网络,如下所示:
def deconv(in_channels, out_channels, kernel_size, stride=2, padding=1, batch_norm=True):layers = []convt_layer = nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride, padding, bias=False)# Appending the above conv layerlayers.append(convt_layer)if batch_norm:# Applying the batch normalization if Truelayers.append(nn.BatchNorm2d(out_channels))# Returning the sequential containerreturn nn.Sequential(*layers)现在,是时候构建生成器网络了! !
class Generator(nn.Module):def __init__(self, z_size, conv_dim):super(Generator, self).__init__()self.z_size = z_sizeself.conv_dim = conv_dim#fully-connected-layerself.fc = nn.Linear(z_size, self.conv_dim*8*2*2)#2x2self.dcv1 = deconv(self.conv_dim*8, self.conv_dim*4, 4, batch_norm=True)#4x4self.dcv2 = deconv(self.conv_dim*4, self.conv_dim*2, 4, batch_norm=True)#8x8self.dcv3 = deconv(self.conv_dim*2, self.conv_dim, 4, batch_norm=True)#16x16self.dcv4 = deconv(self.conv_dim, 3, 4, batch_norm=False)#32 x 32def forward(self, x):# Passing through fully connected layerx = self.fc(x)# Changing the dimensionx = x.view(-1,self.conv_dim*8,2,2)# Passing through deconv layers# Applying the ReLu activation functionx = F.relu(self.dcv1(x))x= F.relu(self.dcv2(x))x= F.relu(self.dcv3(x))x= F.tanh(self.dcv4(x))#returning the modified imagereturn x为了使模型更快地收敛,我们将初始化线性和卷积层的权重。根据相关研究论文中的描述:所有的权重都是从0中心的正态分布初始化的,标准差为0.02。
我们将为此目的定义一个功能如下:
def weights_init_normal(m):classname = m.__class__.__name__# For the linear layersif 'Linear' in classname:torch.nn.init.normal_(m.weight,0.0,0.02)m.bias.data.fill_(0.01)# For the convolutional layersif 'Conv' in classname or 'BatchNorm2d' in classname:torch.nn.init.normal_(m.weight,0.0,0.02)现在我们将超参数和两个网络初始化如下:
# Defining the model hyperparamameters
d_conv_dim = 32
g_conv_dim = 32
z_size = 100 #Size of noise vectorD = Discriminator(d_conv_dim)
G = Generator(z_size=z_size, conv_dim=g_conv_dim)
# Applying the weight initialization
D.apply(weights_init_normal)
G.apply(weights_init_normal)print(D)
print()
print(G)输出结果大致如下:
判别器损失:
根据 DCGAN Research Paper 论文中描述:
判别器总损失 = 真图像损失 + 假图像损失,即:d_loss = d_real_loss + d_fake_loss。
不过,我们希望鉴别器输出1表示真正的图像和0表示假图像,所以我们需要设置的损失来反映这一点。
我们将定义双损失函数。一个是真正的损失,另一个是假的损失,如下:
def real_loss(D_out,smooth=False):batch_size = D_out.size(0)if smooth:labels = torch.ones(batch_size)*0.9else:labels = torch.ones(batch_size)labels = labels.to(device)criterion = nn.BCEWithLogitsLoss()loss = criterion(D_out.squeeze(), labels)return lossdef fake_loss(D_out):batch_size = D_out.size(0)labels = torch.zeros(batch_size)labels = labels.to(device)criterion = nn.BCEWithLogitsLoss()loss = criterion(D_out.squeeze(), labels)return loss生成器损失:
根据 DCGAN Research Paper 论文中描述:
生成器的目标是让判别器认为它生成的图像是真实的。
现在,是时候为我们的网络设置优化器了:
lr = 0.0005
beta1 = 0.3
beta2 = 0.999 # default value
# Optimizers
d_optimizer = optim.Adam(D.parameters(), lr, betas=(beta1, beta2))
g_optimizer = optim.Adam(G.parameters(), lr, betas=(beta1, beta2))我将为我们的训练使用 Adam 优化器。因为它目前被认为是对GANs最有效的。根据上述介绍论文中的研究成果,确定了超参数的取值范围。他们已经尝试了它,这些被证明是最好的!超参数设置如下:
步骤4: 编写训练算法
我们必须为我们的两个神经网络编写训练算法。首先,我们需要初始化噪声向量,并在整个训练过程中保持一致。
# Initializing arrays to store losses and samples
samples = []
losses = []# We need to initilialize fixed data for sampling
# This would help us to evaluate model's performance
sample_size=16
fixed_z = np.random.uniform(-1, 1, size=(sample_size, z_size))
fixed_z = torch.from_numpy(fixed_z).float()对于判别器:
我们首先将真实的图像输入判别器网络,然后计算它的实际损失。然后生成伪造图像并输入判别器网络以计算虚假损失。
在计算了真实和虚假损失之后,我们对其进行求和,并采取优化步骤进行训练。
# setting optimizer parameters to zero
# to remove previous training data residue
d_optimizer.zero_grad()# move real images to gpu memory
real_images = real_images.to(device)# Pass through discriminator network
dreal = D(real_images)# Calculate the real loss
dreal_loss = real_loss(dreal)# For fake images# Generating the fake images
z = np.random.uniform(-1, 1, size=(batch_size, z_size))
z = torch.from_numpy(z).float()# move z to the GPU memory
z = z.to(device)# Generating fake images by passing it to generator
fake_images = G(z)# Passing fake images from the disc network
dfake = D(fake_images)
# Calculating the fake loss
dfake_loss = fake_loss(dfake)#Adding both lossess
d_loss = dreal_loss + dfake_loss
# Taking the backpropogation step
d_loss.backward()
d_optimizer.step()对于生成器:
对于生成器网络的训练,我们也会这样做。刚才在通过判别器网络输入假图像之后,我们将计算它的真实损失。然后优化我们的生成器网络。
## Training the generator for adversarial loss
#setting gradients to zero
g_optimizer.zero_grad()# Generate fake images
z = np.random.uniform(-1, 1, size=(batch_size, z_size))
z = torch.from_numpy(z).float()
# moving to GPU's memory
z = z.to(device)# Generating Fake images
fake_images = G(z)# Calculating the generator loss on fake images
# Just flipping the labels for our real loss function
D_fake = D(fake_images)
g_loss = real_loss(D_fake, True)# Taking the backpropogation step
g_loss.backward()
g_optimizer.step()步骤5: 训练模型
现在我们将开始100个epoch的训练: D
经过训练,损失的图表看起来大概是这样的:
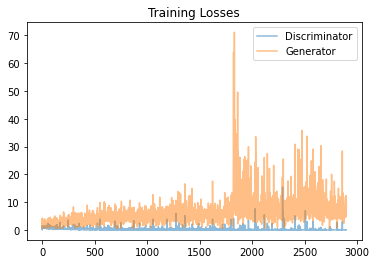
我们可以看到,判别器 Loss 是相当平滑的,甚至在100个epoch之后收敛到某个特定值。而生成器的Loss则飙升。
我们可以从下面步骤6中的结果看出,60个时代之后生成的图像是扭曲的。由此可以得出结论,60个epoch是一个最佳的训练节点。
步骤6: 测试模型
10个epoch之后:

20个epoch之后:

30个epoch之后:

40个epoch之后:

50个epoch之后:

60个epoch之后:

70个epoch之后:

80个epoch之后:

90个epoch之后:

100个epoch之后:

总结
我们可以看到,训练一个生成对抗性网络并不意味着它一定会产生好的图像。
从结果中我们可以看出,训练40-60个 epoch 的生成器生成的图像相对比其他更好。
您可以尝试更改优化器、学习速率和其他超参数,以使其生成更好的图像!
相关文章:
基于PyTorch搭建你的生成对抗性网络
前言 你听说过GANs吗?还是你才刚刚开始学?GANs是2014年由蒙特利尔大学的学生 Ian Goodfellow 博士首次提出的。GANs最常见的例子是生成图像。有一个网站包含了不存在的人的面孔,便是一个常见的GANs应用示例。也是我们将要在本文中进行分享的…...
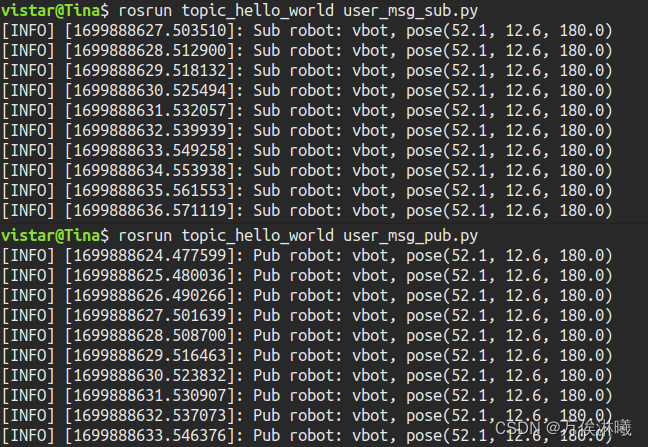
ROS话题(Topic)通信:自定义msg - 例程与讲解
在 ROS 通信协议中,数据是以约定好的结构传输的,即数据类型,比如Topic使用的msg,Service使用的srv,ROS 中的 std_msgs 封装了一些原生的数据类型,比如:Bool、Char、Float32、Int64、String等&am…...

【Vue配置项】 computed计算属性 | watch侦听属性
目录 前言 computed计算属性 什么是计算属性? Vue的原有属性是什么? 得到的全新的属性是什么? 计算属性怎么用? 计算属性的作用是什么? 为什么说代码执行率高了? computed计算属性中的this指向 co…...
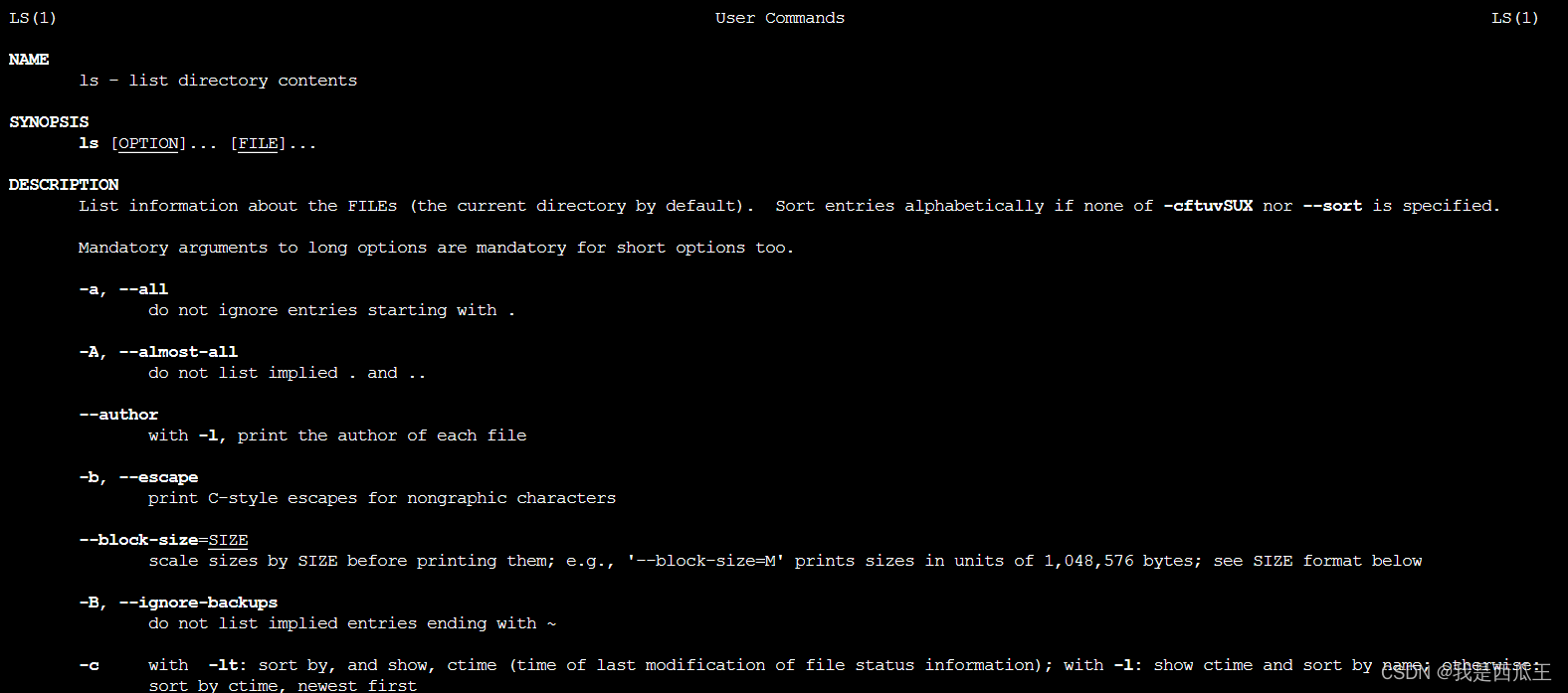
linux 查看命令使用说明
查看命令的使用说明的命令有三种,但并不是每个命令都可以使用这三种命令去查看某个命令的使用说明,如果一种不行就使用另外一种试一试。 1.whatis 命令 概括命令的作用 2.命令 --help 命令的使用格式和选项的作用 3.man 命令 命令的作用和选项的详细…...

ceph修复pg inconsistent( scrub errors)
异常情况 1、收到异常情况如下: OSD_SCRUB_ERRORS 12 scrub errors PG_DAMAGED Possible data damage: 1 pg inconsistentpg 6.d is activeremappedinconsistentbackfill_wait, acting [5,7,4]2、查看详细信息 登录后复制 #ceph health detail HEALTH_ERR 12 scrub errors…...

【论文精读】VOYAGER: An Open-Ended Embodied Agent with Large Language Models
Understanding LSTM Networks 前言Abstract1 Introduction2 Method2.1 Automatic Curriculum2.2 Skill Library2.3 Iterative Prompting Mechanism 3 Experiments3.1 Experimental Setup3.2 Baselines3.3 Evaluation Results3.4 Ablation Studies3.5 Multimodal Feedback from …...
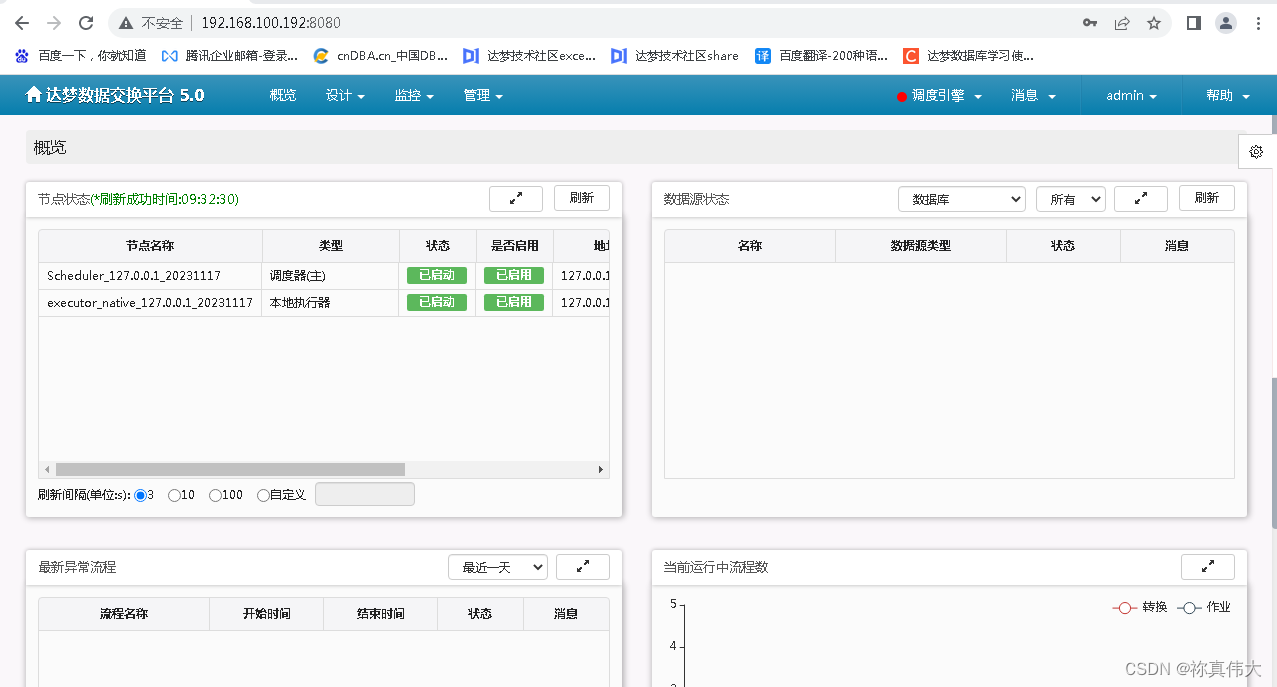
Linux安装DMETL5与卸载
Linux安装DMETL5与卸载 环境介绍1 DM8数据库配置1.1 DM8数据库安装1.2 初始化达梦数据库1.3 创建DMETL使用的数据库用户 2 配置DMETL52.1 解压DMETL5安装包2.2 安装调度器2.3 安装执行器2.4 安装管理器2.5 启动dmetl5 调度器2.6 启动dmetl5 执行器2.7 启动dmetl5 管理器2.8 查看…...
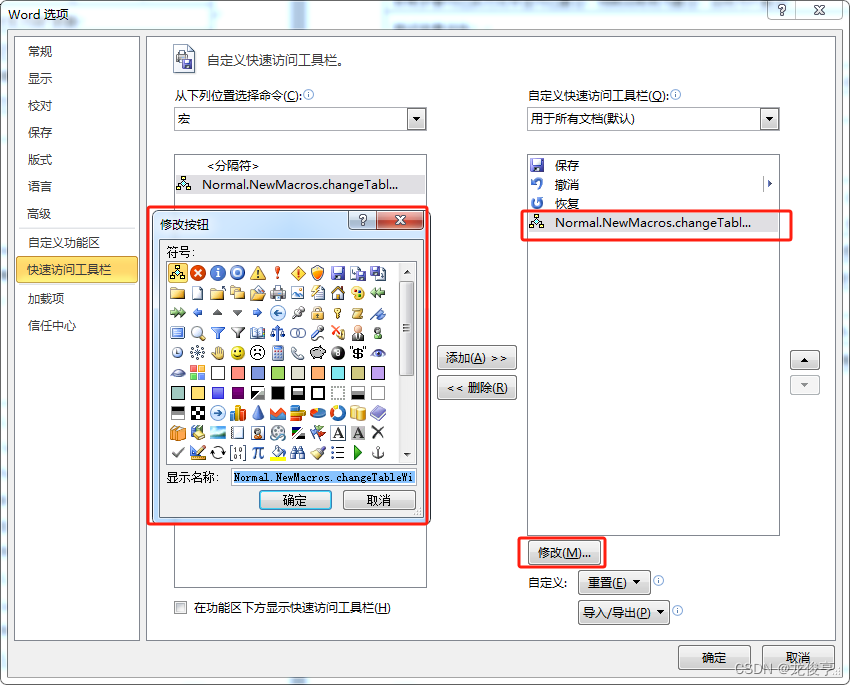
Office Word 中的宏
Office Word 中的宏 简介宏的使用将自定义创建的宏放入文档标题栏中的“自定义快速访问工具栏”插入指定格式、内容的字符选中word中的指定文字查找word中的指定文字A,并替换为指定文字B插入文本框并向内插入文字word 表格中的宏操作遍历表格中的所有内容批量设置表…...

qt中d指针
在Qt中,d指针是一种常见的设计模式,也称为"PIMPL"(Private Implementation)或者"Opaque Pointer"。它主要用于隐藏类的实现细节,提供了一种封装和隔离的方式,以便在不影响公共接口的情…...

交易者最看重什么?anzo Capital这点最重要!
交易者最看重什么?有人会说技术,有人会说交易策略,有人会说盈利,但anzo Capital认为Vishal 最看重的应该是眼睛吧! 29岁的Vishal Agraval在9年前因某种原因失去了视力,然而,他的失明并未能阻…...
window 搭建 MQTT 服务器并使用
1. 下载 安装 mosquitto 下载地址: http://mosquitto.org/files/binary/ win 使用 win32 看自己电脑下载相应版本: 一直安装: 记住安装路径:C:\Program Files\mosquitto 修改配置文件: allow_anonymous false 设置…...
Prometheus+Ansible+Consul实现服务发现
一、简介 1、Consul简介 Consul 是基于 GO 语言开发的开源工具,主要面向分布式,服务化的系统提供服务注册、服务发现和配置管理的功能。Consul 提供服务注册/发现、健康检查、Key/Value存储、多数据中心和分布式一致性保证等功能。 在没有使用 consul 服…...
【原创】java+swing+mysql校园活动管理系统设计与实现
前言: 本文介绍了一个校园活动管理系统的设计与实现。该系统基于JavaSwing技术,采用C/S架构,使用Java语言开发,以MySQL作为数据库。系统实现了活动发布、活动报名、活动列表查看等功能,方便了校园活动的发布和管理&am…...

vscode中vue项目引入的组件的颜色没区分解决办法
vscode中vue项目引入的组件的颜色没区分解决办法 图中引入组件和其他标签颜色一样没有区分,让开发者不易区分,很蓝瘦 这个就很直观,解决办法就是你当前的vscode版本不对,你得去找找其他版本,我的解决办法就是去官网历…...

uniapp: 实现pdf预览功能
目录 第一章 实现效果 第二章 了解并解决需求 2.1 了解需求 2.2 解决需求 2.2.1 方法一 2.2.2 方法二 第三章 资源下载 第一章 实现效果 第二章 了解并解决需求 2.1 了解需求 前端需要利用后端传的pdf临时路径实现H5端以及app端的pdf预览首先我们别像pc端一样&#…...
【Pytorch笔记】7.torch.nn (Convolution Layers)
我们常用torch.nn来封装网络,torch.nn为我们封装好了很多神经网络中不同的层,如卷积层、池化层、归一化层等。我们会把这些层像是串成一个牛肉串一样串起来,形成网络。 先从最简单的,都有哪些层开始学起。 Convolution Layers -…...
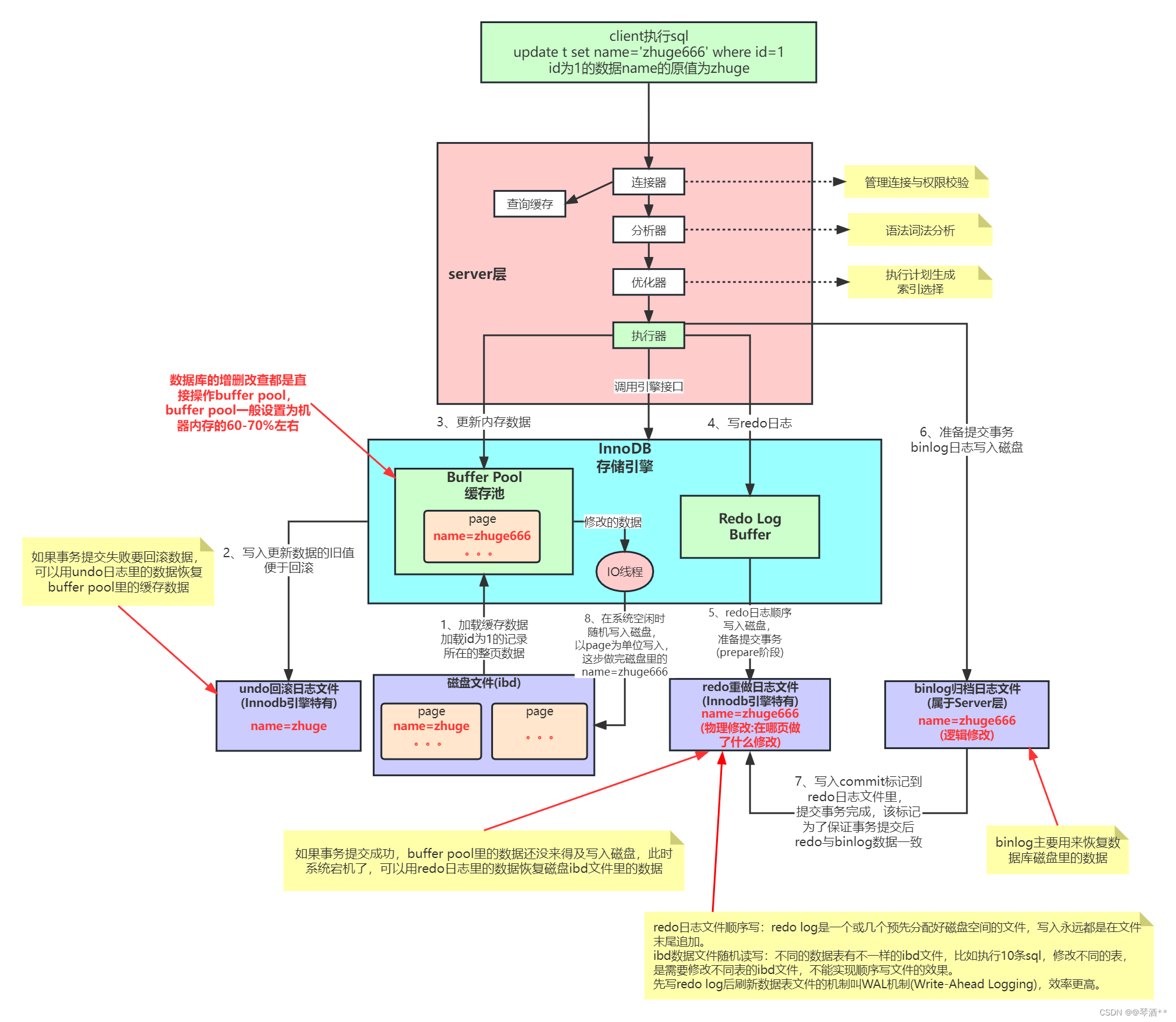
MySQL内部组件与日志详解
MySQL的内部组件结构 MySQL 可以分为 Server 层和存储引擎层两部分。 Server 层主要包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等)&am…...

【LeetCode】94. 二叉树的中序遍历
94. 二叉树的中序遍历 难度:简单 题目 给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。 示例 1: 输入:root [1,null,2,3] 输出:[1,3,2]示例 2: 输入:root [] 输出:[]示…...

IP-guard WebServer 命令执行漏洞复现
简介 IP-guard是一款终端安全管理软件,旨在帮助企业保护终端设备安全、数据安全、管理网络使用和简化IT系统管理。在旧版本申请审批的文件预览功能用到了一个开源的插件 flexpaper,使用的这个插件版本存在远程命令执行漏洞,攻击者可利用该漏…...

TensorFlow案例学习:图片风格迁移
准备 官方教程: 任意风格的快速风格转换 模型下载地址: https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2 学习 加载要处理的内容图片和风格图片 # 用于将图像裁剪为方形def crop_center(image):# 图片原始形状shape image…...

解密Qwen2VLImageProcessor:从RGB转换到时空补丁的完整预处理流水线
解密Qwen2VLImageProcessor:从RGB转换到时空补丁的完整预处理流水线 在计算机视觉与多模态模型融合的前沿领域,图像预处理流水线的设计质量直接影响着模型性能的天花板。Qwen2VLImageProcessor作为专为Qwen2-VL模型设计的预处理引擎,其独特之…...

突破微信设备限制:WeChatPad如何实现免Root双设备同时在线
突破微信设备限制:WeChatPad如何实现免Root双设备同时在线 【免费下载链接】WeChatPad 强制使用微信平板模式 项目地址: https://gitcode.com/gh_mirrors/we/WeChatPad 你是否曾因微信只能单设备登录而错失重要消息?是否渴望在手机和平板上同时接…...

杰理之spp收发数据处理没有找到的问题处理【篇】
原因:开启#define CONFIG_APP_BT_ENABLE 宏配置后,spp的收发处理的回调默认会被库里面接管,所以在app层是看不到的。...

猫抓插件:5分钟掌握浏览器视频下载终极指南
猫抓插件:5分钟掌握浏览器视频下载终极指南 【免费下载链接】cat-catch 猫抓 chrome资源嗅探扩展 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经遇到过想要保存网页视频却找不到下载按钮的烦恼?或者想收藏在线音乐却只…...

ColorControl专业调校指南:从问题诊断到显示优化的参数配置全流程
ColorControl专业调校指南:从问题诊断到显示优化的参数配置全流程 【免费下载链接】ColorControl Easily change NVIDIA display settings and/or control LG TVs 项目地址: https://gitcode.com/gh_mirrors/co/ColorControl 一、问题诊断:你的显…...

InstructPix2Pix在.NET平台的应用开发实战
InstructPix2Pix在.NET平台的应用开发实战 1. 引言:当AI修图遇上.NET开发 想象一下这样的场景:电商平台的商品图片需要批量调整风格,摄影工作室想要快速实现创意效果,或者内容创作者需要即时编辑社交媒体图片。传统图像处理方式…...

终极ESLyric歌词源配置指南:三步解锁酷狗QQ网易云逐字歌词
终极ESLyric歌词源配置指南:三步解锁酷狗QQ网易云逐字歌词 【免费下载链接】ESLyric-LyricsSource Advanced lyrics source for ESLyric in foobar2000 项目地址: https://gitcode.com/gh_mirrors/es/ESLyric-LyricsSource 想在Foobar2000中享受酷狗音乐、QQ…...

吃透Redis核心数据结构:从原理到实战,避开90%的坑
Redis之所以能成为分布式系统的“性能神器”,核心在于其高效的内存数据结构设计。很多开发者对Redis的认知停留在“SET/GET缓存”,只会用最基础的字符串类型,却忽略了List、Hash、Set、ZSet等核心结构的强大能力,导致代码冗余、性…...

C++ vcpkg:安装、使用、原理与选型
C vcpkg:安装、使用、原理与选型 vcpkg 是微软与社区维护的开源 C/C 包管理器,目标是统一第三方库的获取、构建与集成流程。它支持 Windows / Linux / macOS,并与 CMake、Visual Studio 等工具链深度协作。本文覆盖:是什么、如何…...

VCAM虚拟摄像头:革新移动设备视觉交互的技术探索
VCAM虚拟摄像头:革新移动设备视觉交互的技术探索 【免费下载链接】com.example.vcam 虚拟摄像头 virtual camera 项目地址: https://gitcode.com/gh_mirrors/co/com.example.vcam VCAM虚拟摄像头是一款基于Xposed框架的安卓应用,通过HOOK技术&…...