lxml基本使用
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高
XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。
XPath的选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有我们想要定位的节点,都可以用XPath来选择
lxml使用流程
lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档,下面简单介绍一下 lxml 库的使用流程:
(1)导入模块
from lxml import etree
(2)创建解析对象
调用etree模块的HTML() 方法来创建HTML解析对象:
parse_html = etree.HTML(html)
HTML()方法能够将HTML标签字符串解析为HTML文件,该方法可以自动修正HTML 文本。
(3)调用xpath表达式
最后使用第二步创建的解析对象调用xpath()方法,完成数据的提取。
r_list = parse_html.xpath('xpath表达式')
xpath常用规则
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| @* | 选取所有属性 |
| [@attrib] | 选取具有给定属性的所有元素 |
| [@attrib=‘value’] | 选取给定属性具有给定值的所有元素 |
| [tag] | 选取所有具有指定元素的直接子节点 |
| [tag=‘text’] | 选取所有具有指定元素并且文本内容是text节点 |
下面结合lxml使用流程和xpath常用规则举几个例子,假定我们要处理的HTML代码如下:
<div class="wrapper"><a href="www.biancheng.net/product/" id="site">website product</a><ul id="sitename"><li><a href="http://www.biancheng.net/" title="编程帮">编程</a></li><li><a href="http://world.sina.com/" title="新浪娱乐">微博</a></li><li><a href="http://www.baidu.com" title="百度">百度贴吧</a></li><li><a href="http://www.taobao.com" title="淘宝">天猫淘宝</a></li><li><a href="http://www.jd.com/" title="京东">京东购物</a></li><li><a href="http://c.bianchneg.net/" title="C语言中文网">编程</a></li><li><a href="http://www.360.com" title="360科技">安全卫士</a></li><li><a href="http://www.bytesjump.com/" title=字节">视频娱乐</a></li><li><a href="http://bzhan.com/" title="b站">年轻娱乐</a></li><li><a href="http://hao123.com/" title="浏览器">搜索引擎</a></li></ul>
</div>
(1)提取所有a标签内的文本信息
from lxml import etree
# 创建解析对象
parse_html=etree.HTML(html)
# 书写xpath表达式,提取文本最终使用text()
xpath_bds='//a/text()'
# 提取文本数据,以列表形式输出
r_list=parse_html.xpath(xpath_bds)
# 打印数据列表
print(r_list)
(2)获取所有href的属性值
from lxml import etree
# 创建解析对象
parse_html=etree.HTML(html)
# 书写xpath表达式,提取文本最终使用text()
xpath_bds='//a/@href'
# 提取文本数据,以列表形式输出
r_list=parse_html.xpath(xpath_bds)
# 打印数据列表
print(r_list)
(3)获取ul标签下的li标签下的a标签的href属性值
from lxml import etree
# 创建解析对象
parse_html=etree.HTML(html)
# 书写xpath表达式,提取文本最终使用text()
xpath_bds='//ul[@id="sitename"]/li/a/@href'
# 提取文本数据,以列表形式输出
r_list=parse_html.xpath(xpath_bds)
# 打印数据列表
print(r_list)
案例——爬取某一地区所有企业名称
这里有一个网站:http://m.54114.cn/luoyang/。以洛阳为例,里面按行业列出了该地区所有企业的名称。
通过进入不同的行业内查看,我们能发现他的url是有规律的:
http://m.54114.cn/luoyang/hangye1/、http://m.54114.cn/luoyang/hangye2/、……、一直到huangye20。
在翻看不同页的内容时,我们也发现url是有规律的:比如第二页的url是http://m.54114.cn/luoyang/hangye1_p2/,第三页的最后就是p3,依次类推。虽然第一页没有“_p1”的后缀,但是我们按照此规律进行尝试,发现也可以访问,这就简单了。
点进某一行业的页面,有几个东西是我们感兴趣的。首先就是这个标题。
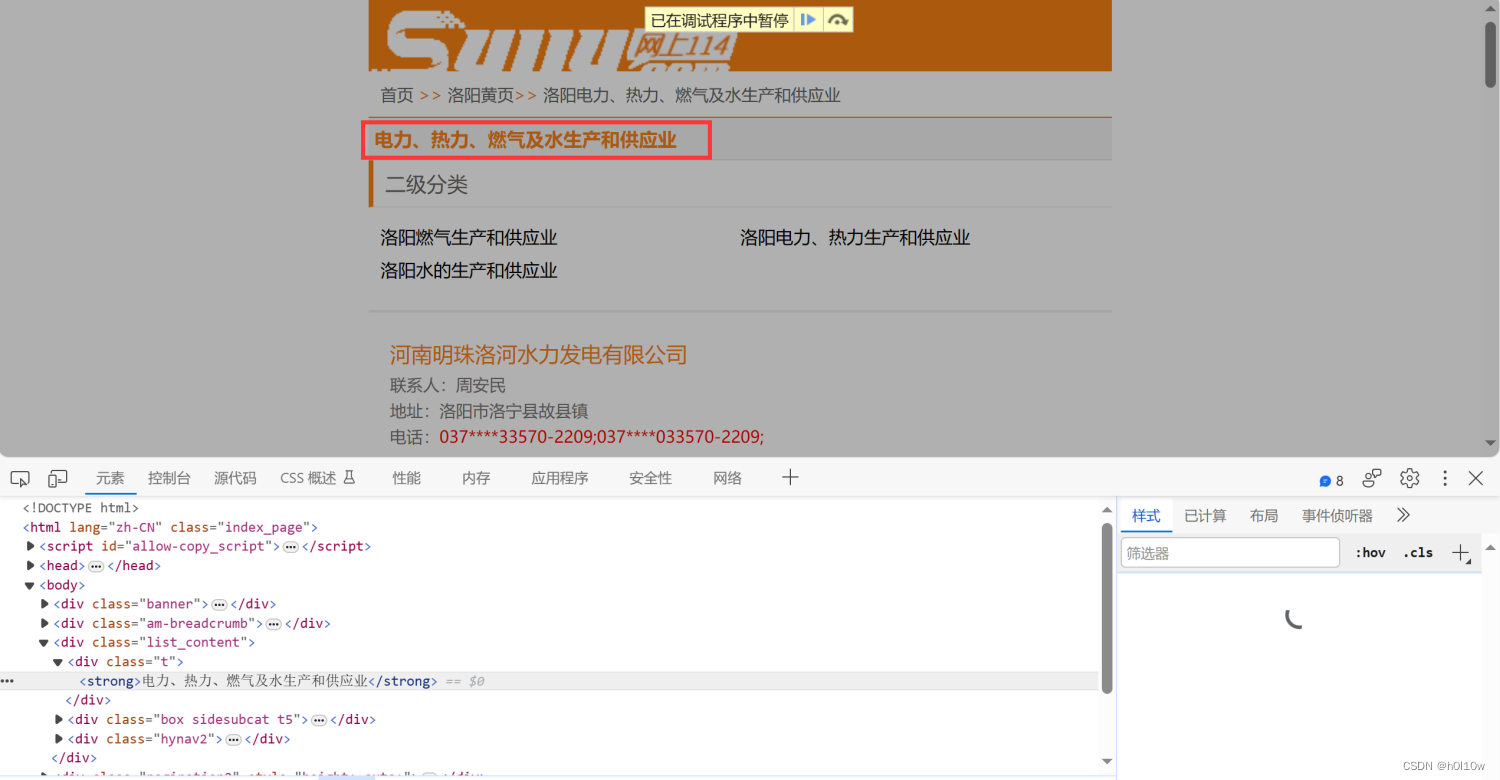
通过html文档结构,我们能得到其对应的xpath为://div[@class="list_content"]/div[1]/strong/text()
然后就是这个总页数
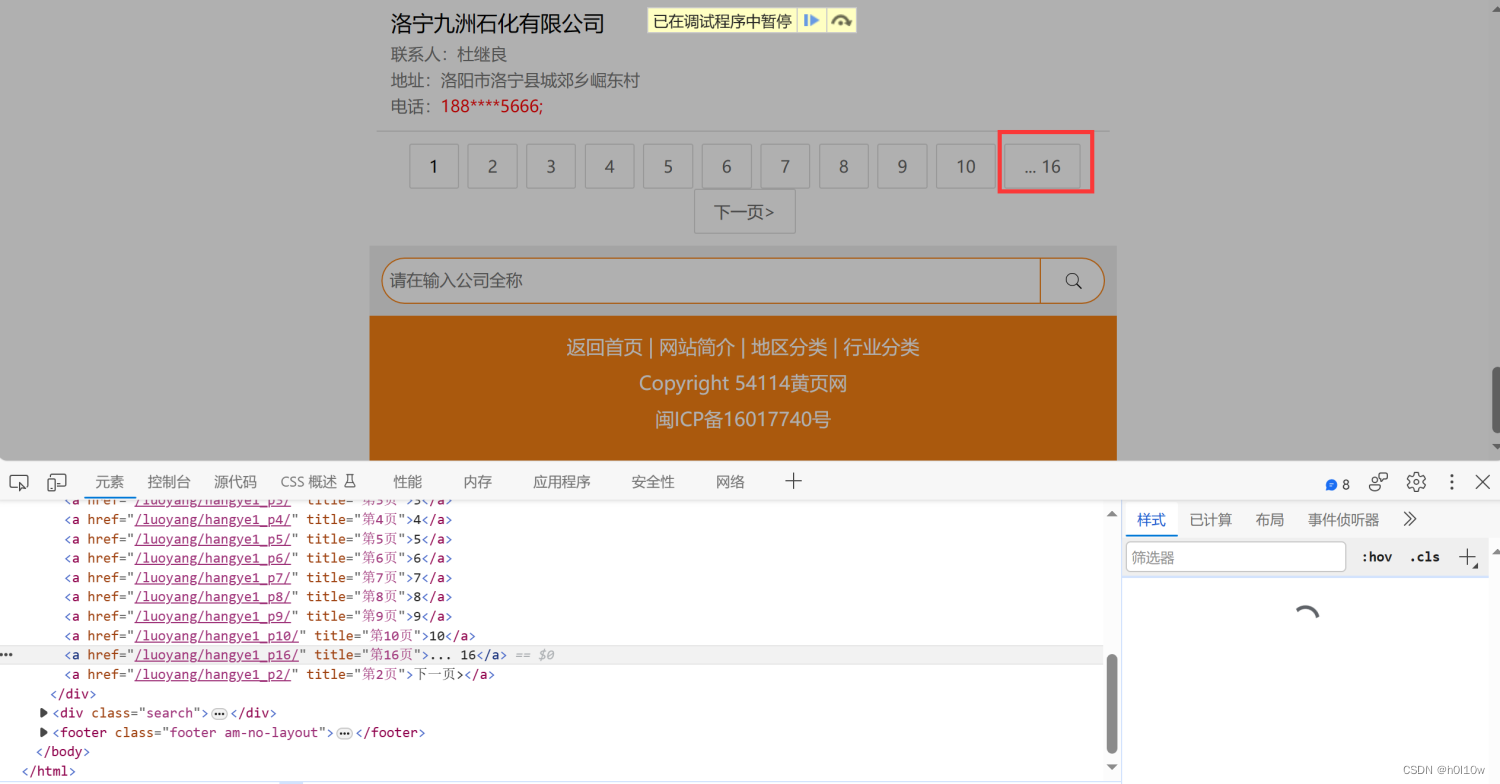
总页数是倒数第二个a标签,所以我们能得到其对应的xpath为://div[@class="pagination2"]/a[last()-1]/@title。
最后就是我们关心的企业名称
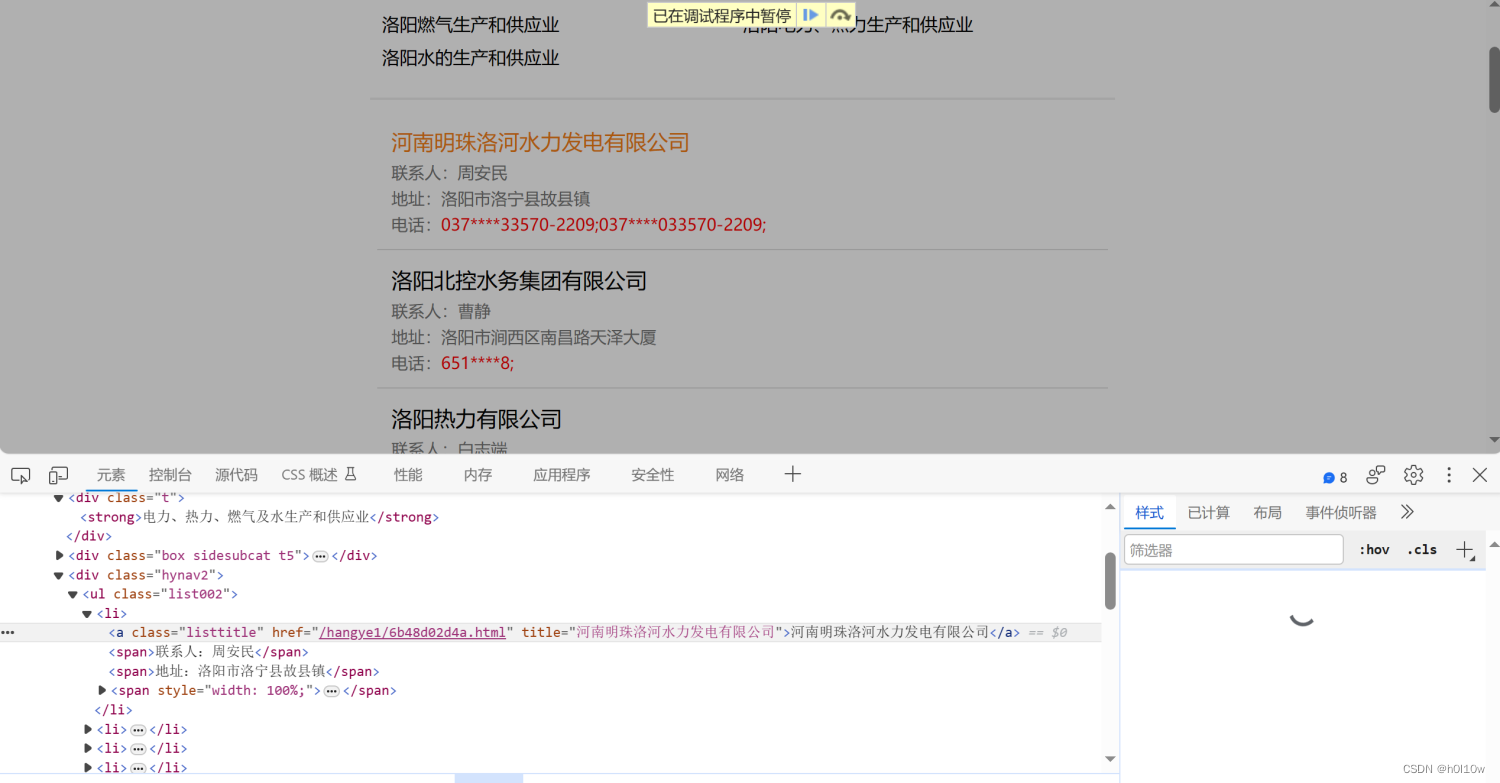
xpath为://div[@class="list_content"]/div[3]/ul/li/a/text()
最后得到总的爬取脚本:
import requests
from lxml import etree# url = 'http://m.54114.cn/luoyang/hangye12_p1/'
headers = {'User-ASgent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0','Host': 'm.54114.cn','Cookie': 'ZDEDebuggerPresent=php,phtml,php3'
}def get_content(url, xpath):response = requests.get(url, headers=headers)tree = etree.HTML(response.text)target = tree.xpath(xpath)return targetfor i in range(1, 21):url = f'http://m.54114.cn/luoyang/hangye{i}_p1/'response = requests.get(url, headers=headers)tree = etree.HTML(response.text)filename = tree.xpath('//div[@class="list_content"]/div[1]/strong/text()')[0]pages = tree.xpath('//div[@class="pagination2"]/a[last()-1]/@title')if len(pages) == 0:continuepages = int(pages[0][1:-1])file = open('./luoyang/' + filename + '.txt', 'w')for j in range(1, pages + 1):url = f'http://m.54114.cn/luoyang/hangye{i}_p{j}/'xpath = '//div[@class="list_content"]/div[3]/ul/li/a/text()'names = get_content(url, xpath)for name in names:file.write(name + '\n')file.close()执行完的效果如下

相关文章:
lxml基本使用
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高 XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文…...
【数据结构初阶】链表OJ
链表OJ 题目一:移除链表元素题目二:反转链表题目三:链表的中间节点题目四:链表中倒数第k个结点题目五:合并两个有序链表题目六:链表分割题目七:链表的回文结构题目八:相交链表题目九…...

【Vue渲染】 条件渲染 | v-if | v-show | 列表渲染 | v-for
目录 前言 v-if和v-show的区别和联系 v-show和v-if如何选择 条件渲染|v-if|v-show v-if v-if v-else v-if v-else-if v-else template v-show 列表渲染|v-for v-for 前言 本文介绍Vue渲染,包含条件渲染v-if和v-show的区别和联系以及列表渲染v-for v-if和…...

开源网安解决方案荣获四川数实融合创新实践优秀案例
11月16日,2023天府数字经济峰会在成都圆满举行。本次峰会由四川省发展和改革委员会、中共四川省委网络安全和信息化委员会办公室、四川省经济和信息化厅等部门联合指导,聚焦数字经济与实体经济深度融合、数字赋能经济社会转型发展等话题展开交流研讨。…...

debian/ubuntu/linux如何快速安装vscode
前言 这里写一篇简短的文字用来记录如何在Linux发行版上快速安装VScode,主要使用的一个软件snap,做一个简单介绍: Snap Store 是 Ubuntu、Debian、Fedora 和其他几个 Linux 发行版中的一个应用商店,提供了数千个应用程序和工具的…...
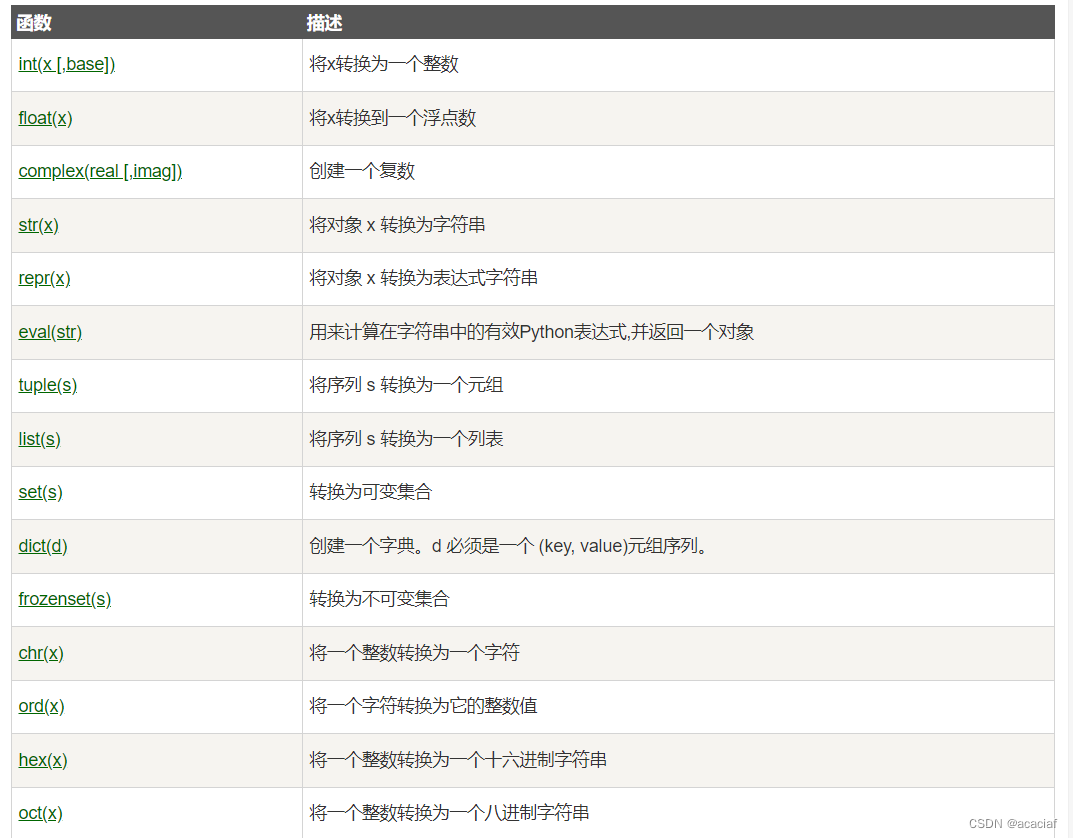
Python3语法总结-数据转换②
Python3语法总结-数据转换② Python3语法总结二.Python数据类型转换隐式类型转换显示类型转换 Python3语法总结 二.Python数据类型转换 有时候我们,需要对数据内置的类型进行转换,数据类型的转换。 Python 数据类型转换可以分为两种: 隐式类…...
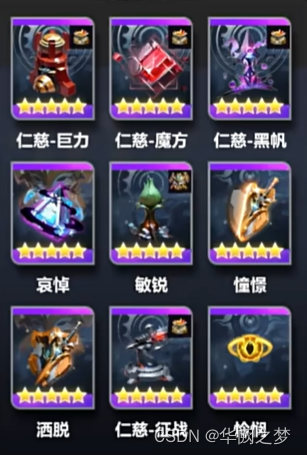
【火炬之光-魔灵装备】
文章目录 装备天赋追忆石板技能魂烛刷图策略 装备 头部胸甲手套鞋子武器盾牌项链戒指腰带神格备注盾牌其余的装备要么是召唤物生命,要么是技能等级,鞋子的闪电技能等级加2不是核心,腰带的话主要是要冷却有冷却暗影的技能是不会断的ÿ…...

javascript选择器的封装,只需要写元素名或css类及id都可以选择到元素
//模仿jquery选择器样式,只需要写元素名或css类及id都可以选择到元素 <html><head><meta http-equiv"Content-Type:text/html;charsetutf8"/><link rel"shortcut icon" href"#"/><title>封装选择器&l…...
机器学习第7天:逻辑回归
文章目录 介绍 概率计算 逻辑回归的损失函数 单个实例的成本函数 整个训练集的成本函数 鸢尾花数据集上的逻辑回归 Softmax回归 Softmax回归数学公式 Softmax回归损失函数 调用代码 参数说明 结语 介绍 作用:使用回归算法进行分类任务 思想:…...

努力奋斗,遇上对的人
...

基于单片机音乐弹奏播放DS1302万年历显示及源程序
一、系统方案 1、本设计采用51单片机作为主控器。 2、DS1302计时显示年月日时分秒。 3、按键可以弹奏以及播放音乐,内置16首音乐。 二、硬件设计 原理图如下: 三、单片机软件设计 1、首先是系统初始化 /时钟显示**/ void init_1602_ds1302() { write…...

ceph学习笔记
ceph ceph osd lspoolsrbd ls -p testpool#查看 ceph 集群中有多少个 pool,并且每个 pool 容量及利 用情况 rados dfceph -sceph osd tree ceph dfceph versionsceph osd pool lsceph osd crush rule dumpceph auth print-key client.adminceph orch host lsceph crash lsceph…...
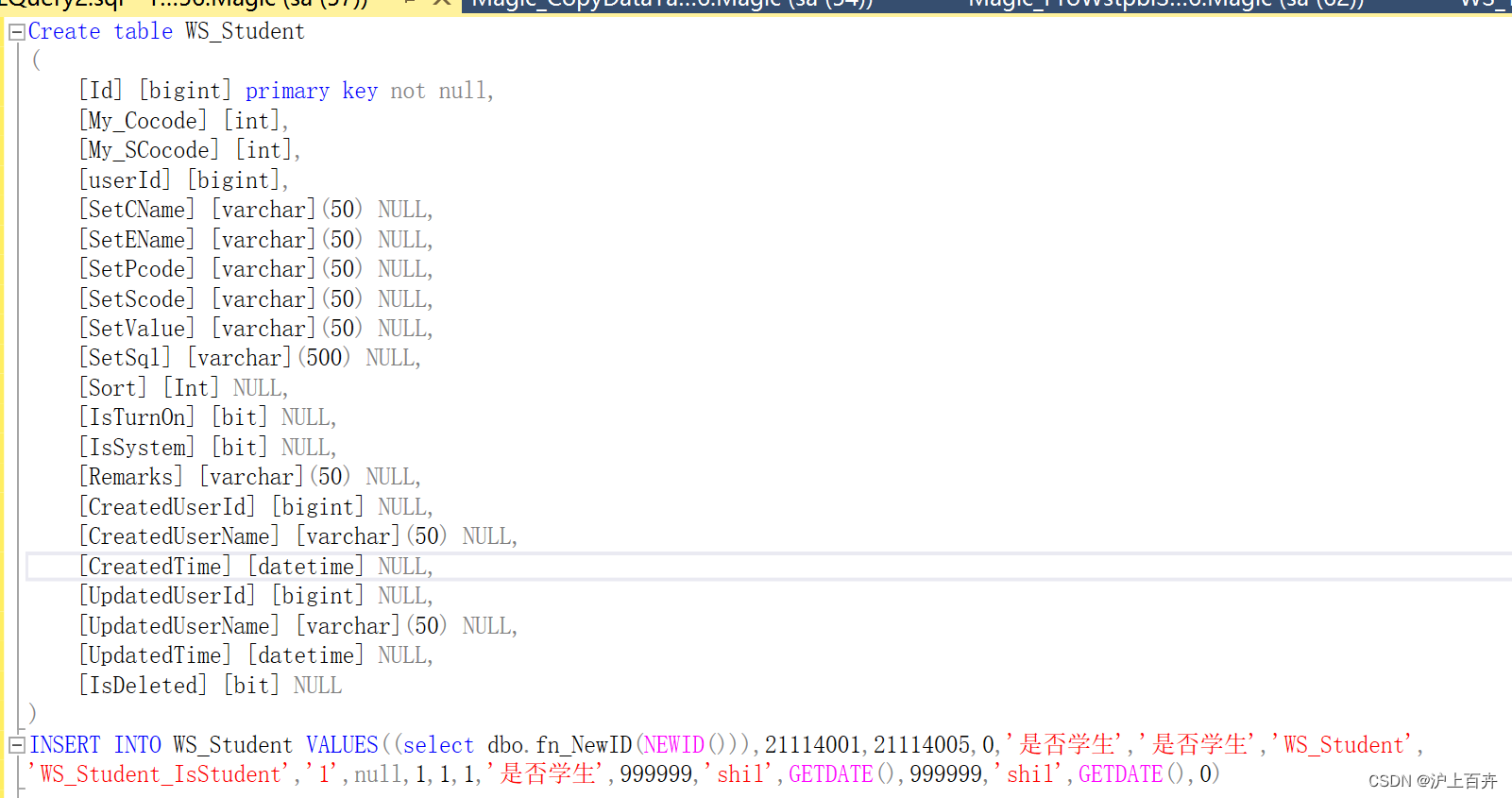
SQLSERVER 遍历循环的两种方式很详细有源码(2)
2.游标循环 Create table WS_Student ( [Id] int primary key not null, [My_Cocode] [int], [My_SCocode] [int], [userId] [bigint], [SetCName] [varchar](50) NULL, [SetEName] [varchar](50) NULL, [SetPcode] [varchar](50) NULL, [Se…...

flutter背景图片设置
本地图片设置 1、在配置文件pubspec.yaml中,设置以下代码 assets:- assets/- assets/test/2、如果目录中没有assets文件夹,则创建一个文件夹,并且取名为assets,在此文件夹中存放图片资源即可,如果想分文件夹管理&…...
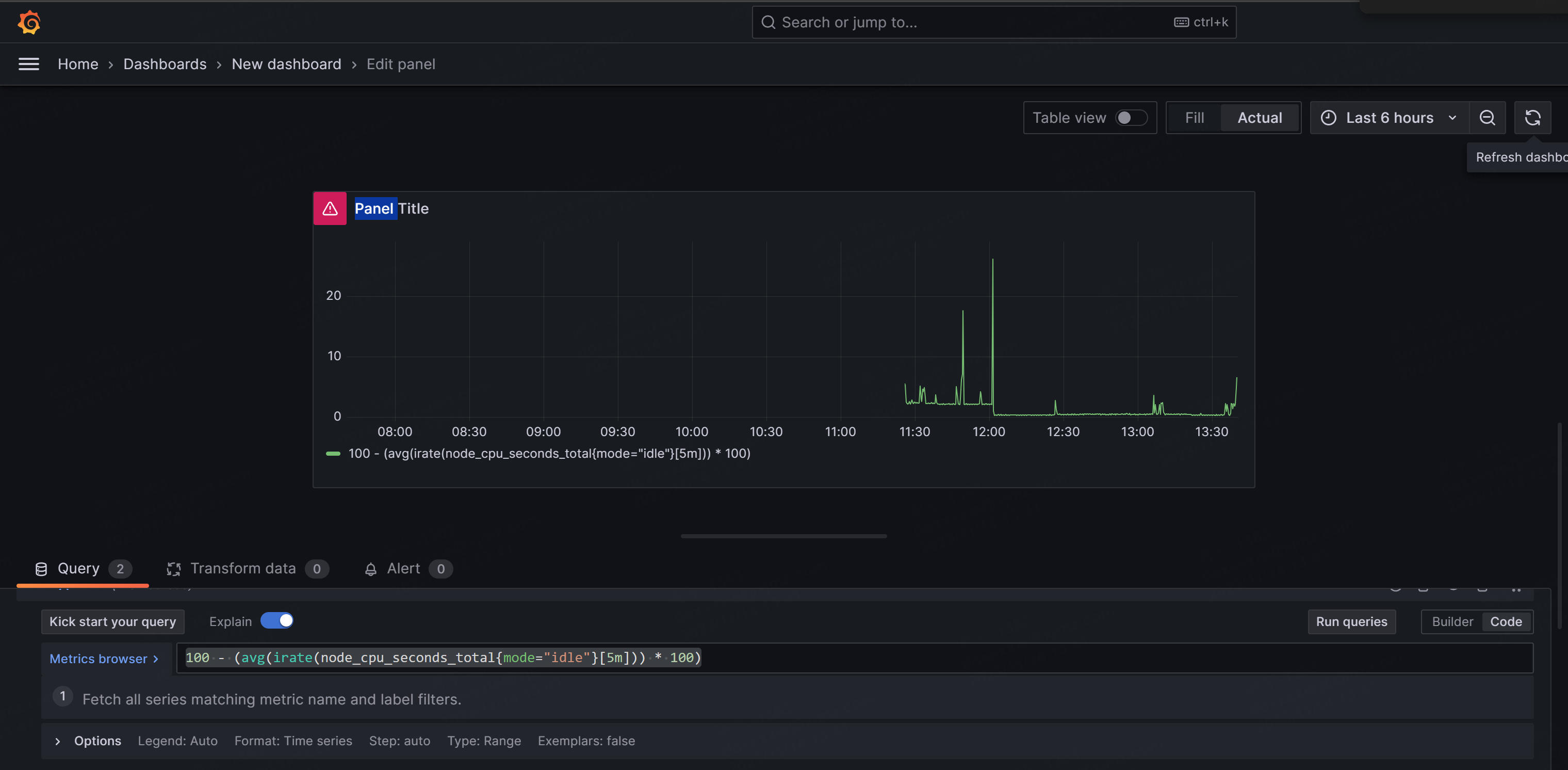
【运维 监控】Grafana + Prometheus,监控Linux
安装和配置Grafana与Prometheus需要一些步骤,下面是一个简单的指南: 安装 Prometheus: 使用包管理器安装 Prometheus。在 Debian/Ubuntu 上,可以使用以下命令: sudo apt-get update sudo apt-get install prometheus在…...
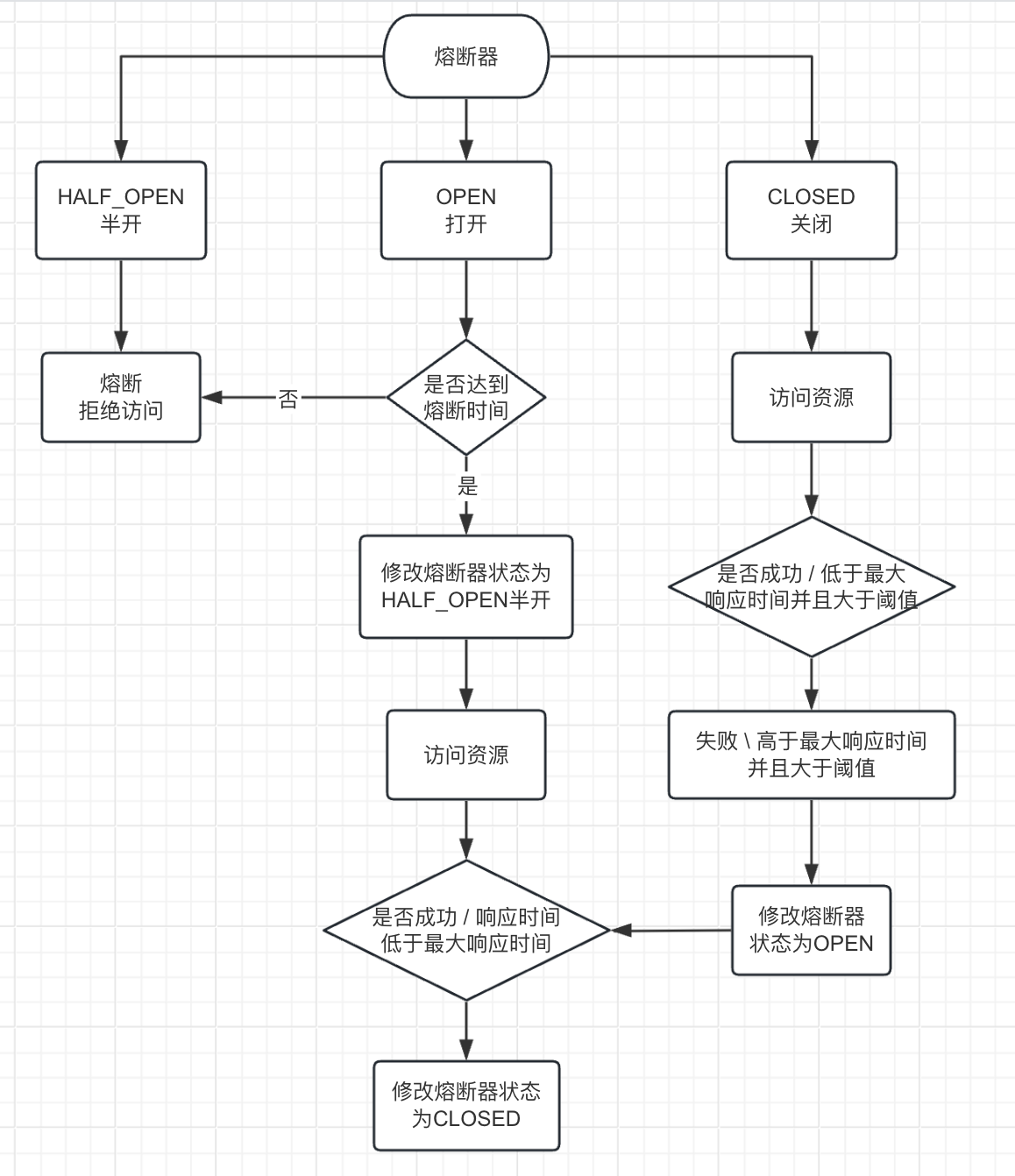
Sentinel底层原理(下)
1、概述 Sentinel的核心原理,也就是前面提到暗流涌动的SphU.entry(…)这行代码背后的逻辑。 Sentinel会为每个资源创建一个处理链条,就是一个责任链,第一次访问这个资源的时候创建,之后就一直复用,所以这个处理链条每…...
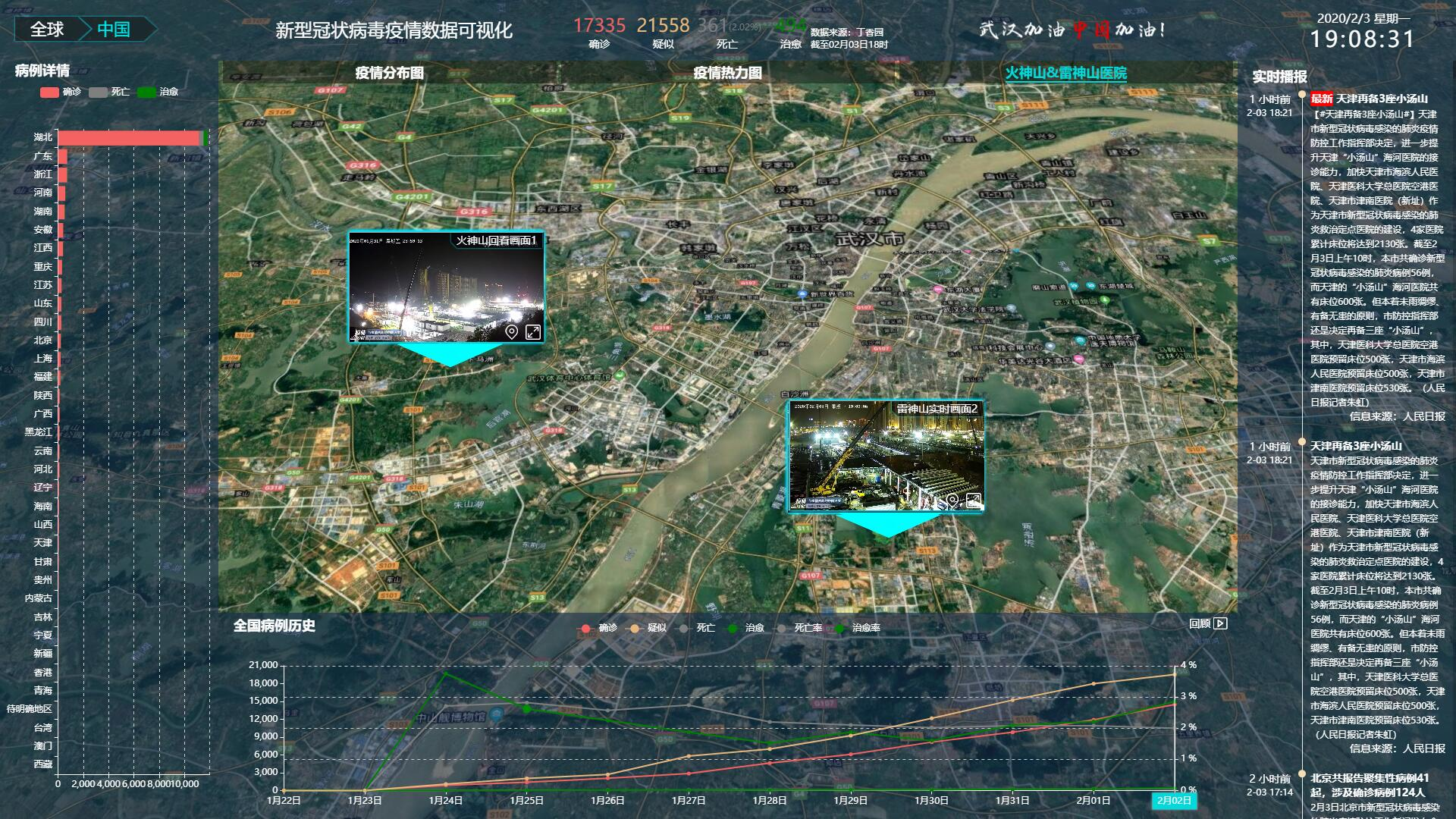
竞赛选题 疫情数据分析与3D可视化 - python 大数据
文章目录 0 前言1 课题背景2 实现效果3 设计原理4 部分代码5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 大数据全国疫情数据分析与3D可视化 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐࿰…...

macos 配置ndk环境
选择Android Studio下默认的ndk环境 mac电脑的ndk默认路径一般是 /Users/user_name/Library/Android/sdk/ndk/version_code 其中user_name为自己电脑的用户名,version_code为自己ndk安装的版本号,比如我这里电脑的ndk路径就是 /Users/zhangsan/Libra…...
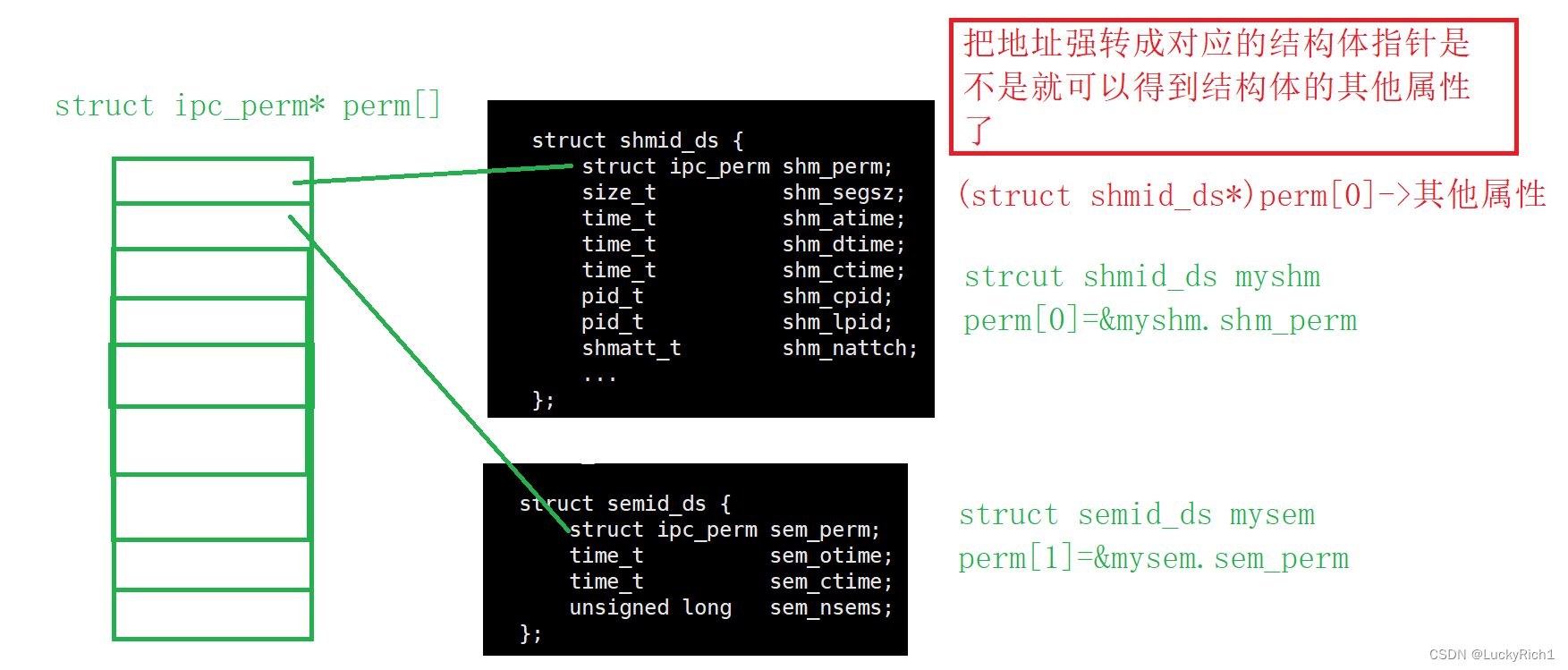
【linux】进行间通信——共享内存+消息队列+信号量
共享内存消息队列信号量 1.共享内存1.1共享内存的原理1.2共享内存的概念1.3接口的认识1.4实操comm.hppservice.cc (写)clint.cc (读) 1.5共享内存的总结1.6共享内存的内核结构 2.消息队列2.1原理2.2接口 3.信号量3.1信号量是什么3…...
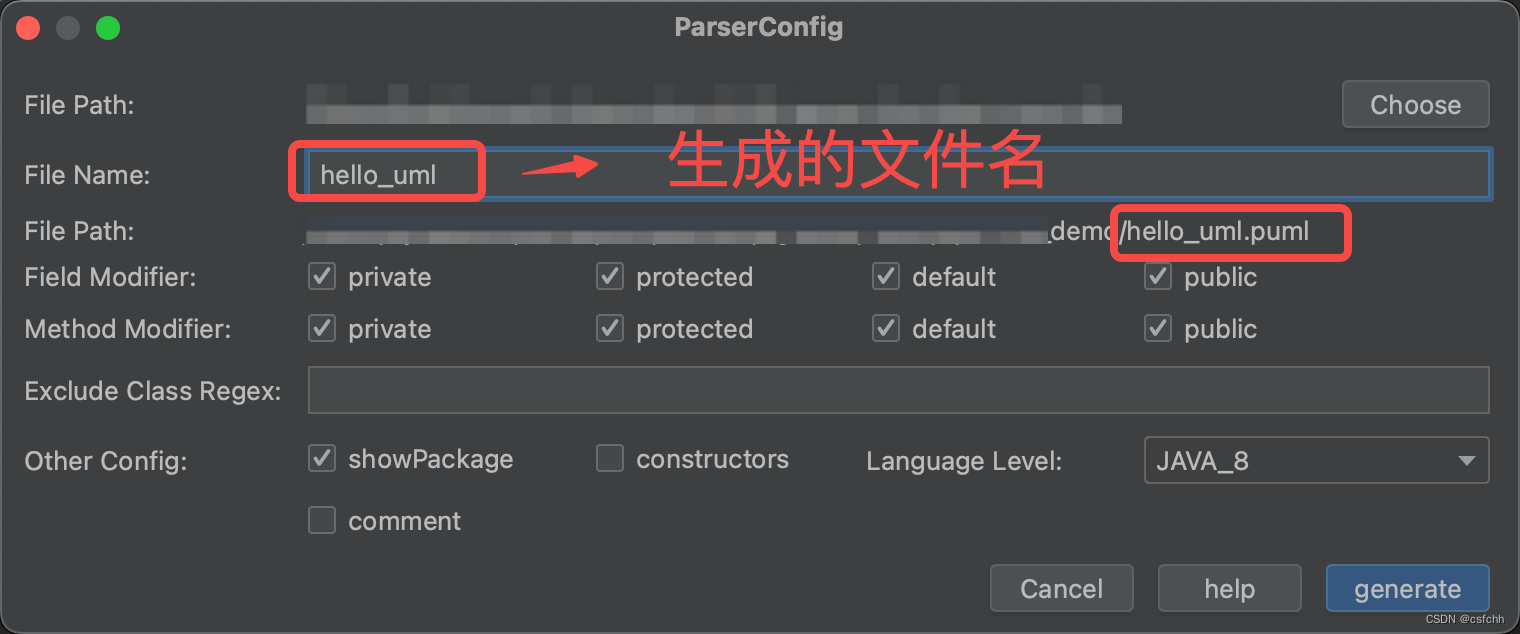
PlantUML基础使用教程
环境搭建 IDEA插件下载 打开IEDA系列IDE,从FIle–>Settings–>Plugins–>Marketplace 进入到插件下载界面,搜索PlantUML,安装PlantUML Integration和PlantUML Parser两个插件,并重启IDE 安装和配置Graphviz 进入官网…...

Nodejs后端服务接入Taotoken多模型API的完整配置指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Nodejs后端服务接入Taotoken多模型API的完整配置指南 对于Node.js后端开发者而言,将大模型能力集成到服务中已成为提升…...

TegraRcmGUI完整指南:Windows上最简单快速的Switch注入工具教程
TegraRcmGUI完整指南:Windows上最简单快速的Switch注入工具教程 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI TegraRcmGUI是Windows平台上最简…...

Perplexity搜索精度暴跌?揭秘92%开发者忽略的4个底层参数配置陷阱
更多请点击: https://intelliparadigm.com 第一章:Perplexity搜索精度暴跌?揭秘92%开发者忽略的4个底层参数配置陷阱 Perplexity 作为评估语言模型输出质量的核心指标,其数值异常飙升(如从 12.3 暴增至 89.7ÿ…...

AI LED调光控制器智能功率 MOSFET 完整选型方案
2026年随着 AI 技术在智能照明与调光控制中的深度渗透(如自适应色温、场景联动、人因节律照明),调光控制器对功率 MOSFET 提出更高要求:高精度PWM响应、超低导通损耗、高散热密度。微碧半导体(VBsemi)基于S…...

PCB线宽与电流关系详解:从原理到设计避坑指南
1. 项目概述:从一次烧板事故说起去年,我手头一个给电机驱动的小板子又冒烟了。排查了半天,发现不是芯片烧了,也不是电源接反了,问题出在一条给电机供电的电源走线上。那条线在板子上看着挺“粗壮”,但实际一…...

在Taotoken控制台中查看与分析API用量明细的实际操作
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken控制台中查看与分析API用量明细的实际操作 对于使用大模型API进行开发的团队或个人而言,清晰、准确地掌握AP…...

如何用Draw.io ECE插件绘制教科书级别的电路图?
如何用Draw.io ECE插件绘制教科书级别的电路图? 【免费下载链接】Draw-io-ECE Custom-made draw.io-shapes - in the form of an importable library - for drawing circuits and conceptual drawings in draw.io. 项目地址: https://gitcode.com/gh_mirrors/dr/D…...

从零上手Ranorex:录制、验证与参数化测试实战解析
1. Ranorex自动化测试入门指南 第一次接触Ranorex时,我和大多数测试工程师一样,被它强大的功能所震撼。作为一款专业的自动化测试工具,Ranorex能够显著提升测试效率,特别适合需要频繁回归测试的项目场景。记得我第一次用它完成计算…...

终极指南:4步让旧Mac运行最新macOS的完整教程
终极指南:4步让旧Mac运行最新macOS的完整教程 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 还在为你的老Mac无法升级最新系统而烦恼吗ÿ…...
)
动漫分镜图批量生成实战:用/mj batch+自定义--style raw指令链,单日产出24张电影级分镜(附可复用Prompt矩阵表)
更多请点击: https://intelliparadigm.com 第一章:动漫分镜图批量生成的核心价值与技术边界 动漫分镜图(Storyboard)是动画制作前期的关键资产,传统手绘或半自动流程耗时长、风格不一致、迭代成本高。批量生成技术通…...