2023.11.17 hadoop之HDFS进阶
目录
HDFS的机制
元数据简介
元数据存储流程:namenode 生成了多个edits文件和一个fsimage文件
edits和fsimage文件
SecondaryNameNode辅助NameNode的方式:
HDFS的存储原理
写入数据原理: 发送写入请求,获取主节点同意,开始写入,写入完成
读取数据原理:发送读取请求,获取主节点同意,开始读取,读取完成
HDFS安全机制
HDFS归档机制
HDFS垃圾桶机制
分布式存储:一台计算机无法进行存储,则由多台计算机来存储,分布式存储最早是由谷歌提出的,其目的是通过廉价的服务器来提供使用与大规模,高并发场景下的 Web 访问问题。它 采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
接着此前的内容
https://blog.csdn.net/m0_49956154/article/details/134324386?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_49956154/article/details/134298109?spm=1001.2014.3001.5501
hive切块的作用:为了方便统一管理
hive副本的作用:默认3个,为了保证数据的安全性
HDFS的机制
副本机制: 为了保证数据安全和效率,block块信息存储多个副本,第一副本保存在客户端所在服务器,第二副本保存在和第一副本不同机架服务器上,第三副本保存在和第二副本相同机架不同服务器
负载均衡机制: namenode为了保证不同的datanode中block块信息大体一样,分配存储任务的时候会优先保存在余量比较大的datanaode上
心跳机制: datanode每隔3秒钟向namenode汇报自己的状态信息,如果某个时刻,datanode连续10次不汇报了(30秒),namenode会认为datanode有可能宕机了,namenode就会每5分钟(300000毫秒)发送一次确认消息,连续2次没有收到回复,就认定datanode此时一定宕机了(确认datanode宕机总时间3*10+5*2*60=630秒)
元数据简介
元数据:为了描述数据的数据
元数据: 内存元数据 和 文件元数据 两种分别在内存和磁盘上
内存元数据: namnode运行过程中产生的元数据会先保存在内存中,再保存到文件元数据中。
内存元数据优缺点: 优点: 因为内存处理数据的速度要比磁盘快。 缺点: 内存一断电,数据全部丢失
文件元数据: Edits 编辑日志文件和fsimage 镜像文件
Edits编辑日志文件: 存放的是Hadoop文件系统的所有更改操作(文件创建,删除或修改)的日志,文件系统客户端执行的更改操作首先会被记录到edits文件中
Fsimage镜像文件: 是元数据的一个持久化的检查点,包含Hadoop文件系统中的所有目录和文件元数据信息,但不包含文件块位置的信息。文件块位置信息只存储在内存中,是在 datanode加入集群的时候,namenode询问datanode得到的,并且不间断的更新
元数据存储流程:namenode 生成了多个edits文件和一个fsimage文件

edits和fsimage文件
edits文件会被合并到fsimage中,这个合并由SecondaryNamenode来操作.
namenode管理元数据: 基于edits和FSImage的配合,完成整个文件系统文件的管理。每次对HDFS的操作,均被edits文件记录, edits达到大小上限后,开启新的edits记录,定期进行edits的合并操作
如当前没有fsimage文件, 将全部edits合并为第一个fsimage文件
如当前已存在fsimage文件,将全部edits和已存在的fsimage进行合并,形成新的fsimage
edits编辑文件: 记录hdfs每次操作(namenode接收处理的每次客户端请求)
fsimage镜像文件: 记录某一个时间节点前的当前文件系统全部文件的状态和信息(namenode所管理的文件系统的一个镜像)
SecondaryNameNode辅助NameNode的方式:
SecondaryNameNode辅助合并元数据: SecondaryNameNode会定期从NameNode拉取数据(edits和fsimage)然后合并完成后提供给NameNode使用。
对于元数据的合并,是一个定时过程,基于两个条件:(也叫checkpoint)
dfs.namenode.checkpoint.period:默认3600(秒)即1小时
dfs.namenode.checkpoint.txns: 默认1000000,即100W次事务
dfs.namenode.checkpoint.check.period: 检查是否达到上述两个条件,默认60秒检查一次,只要有一个达到条件就执行拉取合并
HDFS的存储原理
写入数据原理: 发送写入请求,获取主节点同意,开始写入,写入完成
1.客户端发起写入数据的请求给namenode
2.namenode接收到客户端请求,开始校验(是否有权限,路径是否存在,文件是否存在等),如果校验没问题,就告知客户端可以写入
3.客户端收到消息,开始把文件数据分割成默认的128m大小的的block块,并且把block块数据拆分成64kb的packet数据包,放入传输序列
4.客户端携带block块信息再次向namenode发送请求,获取能够存储block块数据的datanode列表
5.namenode查看当前距离上传位置较近且不忙的datanode,放入列表中返回给客户端
6.客户端连接datanode,开始发送packet数据包,第一个datanode接收完后就给客户端ack应答(客户端就可以传入下一个packet数据包),同时第一个datanode开始复制刚才接收到的数据包给node2,node2接收到数据包也复制给node3(复制成功也需要返回ack应答),最终建立了pipeline传输通道以及ack应答通道
7.其他packet数据根据第一个packet数据包经过的传输通道和应答通道,循环传入packet,直到当前block块数据传输完成(存储了block信息的datanode需要把已经存储的块信息定期的同步给namenode)
8.其他block块数据存储,循环执行上述4-7步,直到所有block块传输完成,意味着文件数据被写入成功(namenode把该文件的元数据保存上)
9.最后客户端和namenode互相确认文件数据已经保存完成(也会汇报不能使用的datanode)
读取数据原理:发送读取请求,获取主节点同意,开始读取,读取完成
1.客户端发送读取文件请求给namenode
2.namdnode接收到请求,然后进行一系列校验(路径是否存在,文件是否存在,是否有权限等),如果没有问题,就告知可以读取
3.客户端需要再次和namenode确认当前文件在哪些datanode中存储
4.namenode查看当前距离下载位置较近且不忙的datanode,放入列表中返回给客户端
5.客户端找到最近的datanode开始读取文件对应的block块信息(每次传输是以64kb的packet数据包),放到内存缓冲区中
6.接着读取其他block块信息,循环上述3-5步,直到所有block块读取完毕(根据块编号拼接成完整数据)
7.最后从内存缓冲区把数据通过流写入到目标文件中
8.最后客户端和namenode互相确认文件数据已经读取完成(也会汇报不能使用的datanode)
序列化-本地到内存
反序列化 - 内存到本地
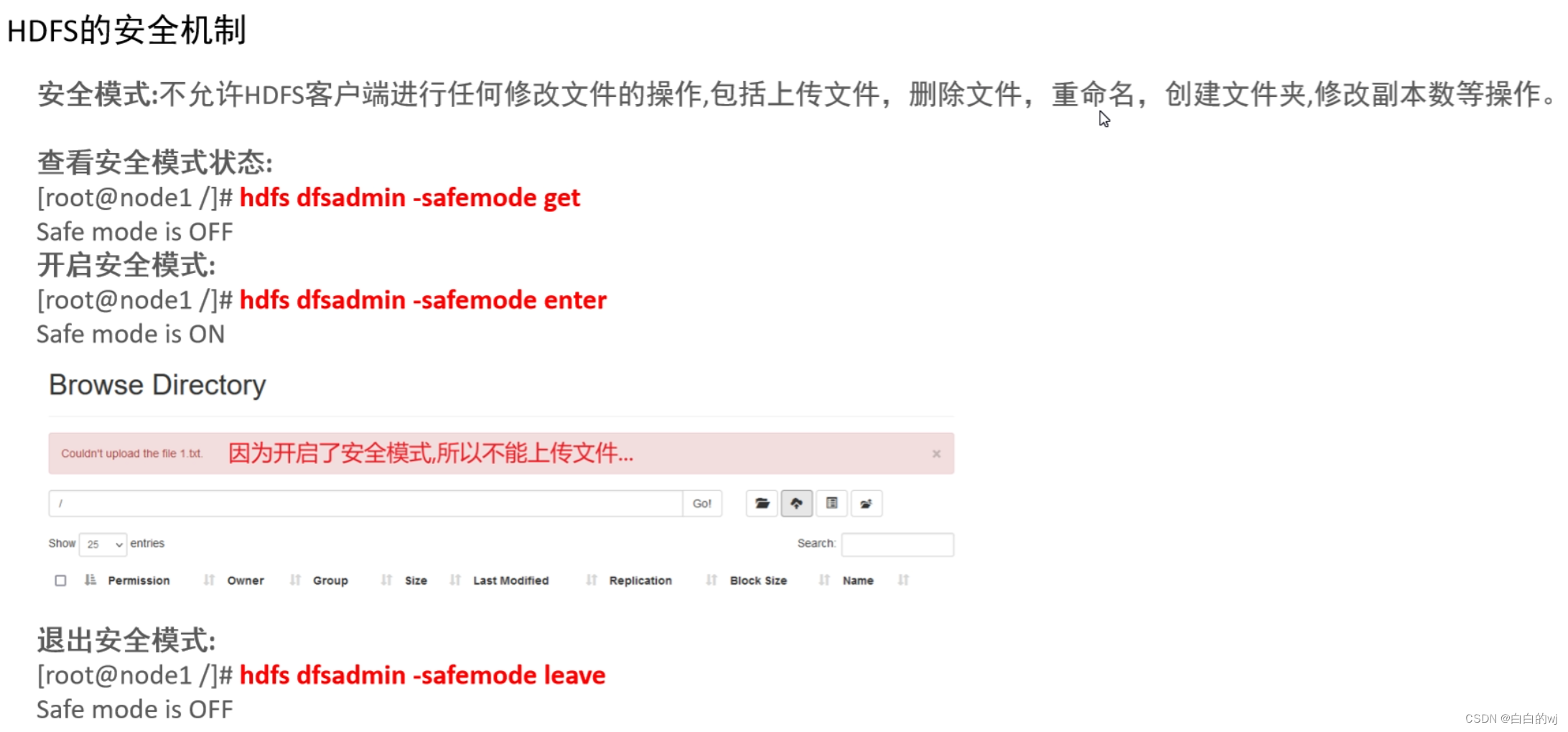
HDFS安全机制
#查看安全模式状态:
[root@node1 /]# hdfs dfsadmin -safemode get
Safe mode is OFF
#开启安全模式:
[root@node1 /]# hdfs dfsadmin -safemode enter
Safe mode is ON
#退出安全模式:
[root@node1 /]# hdfs dfsadmin -safemode leave
Safe mode is OFF开启后在网页端上传文件会提示:
首页也会进行提示

HDFS归档机制
归档原因: 每个小文件单独存放到hdfs中(占用一个block块),那么hdfs就需要依次存储每个小文件的元数据信息,相对来说浪费资源
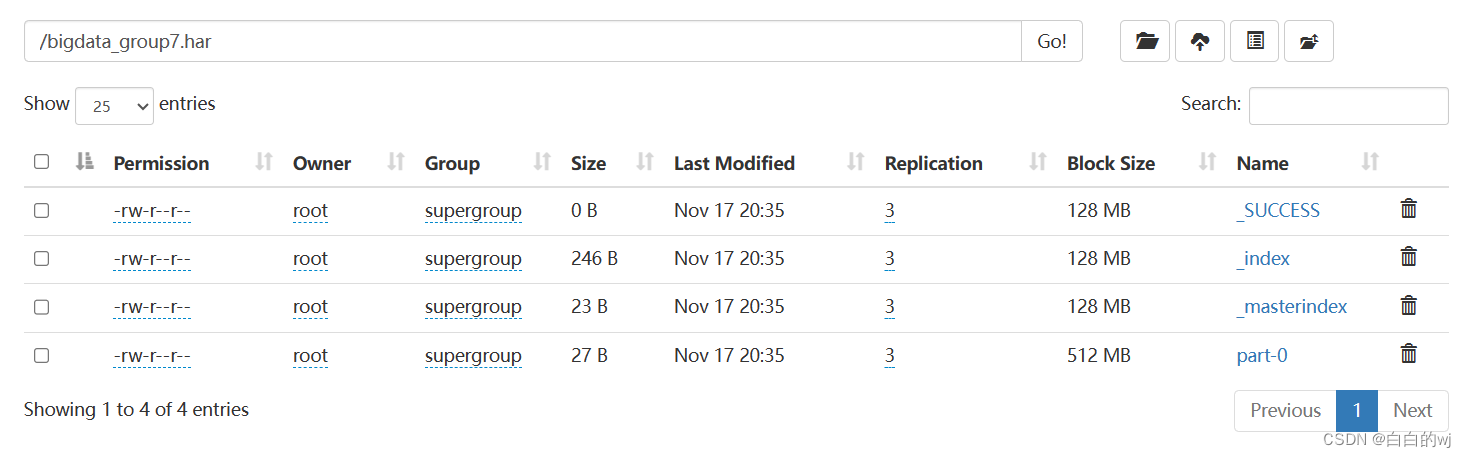
归档格式: hadoop archive -archiveName 归档名.har -p 原始文件的目录 归档文件的存储目录
[root@node1 ~]# hadoop archive -archiveName bigdata_group7.har -p /input /
结果

HDFS垃圾桶机制
设置了垃圾桶机制好处: 文件不会立刻消失,可以去垃圾桶里把文件恢复,继续使用

在hdfs的网页里删除就是永久删除
在linux里面远程命令删除,就会放到回收站里
在虚拟机中rm命令删除文件,默认是永久删除
在虚拟机中需要手动设置才能使用垃圾桶回收: 把删除的内容放到: /user/root/.Trash/Current/ 先关闭服务: 在 node1 中执行 stop-all.sh 新版本不关闭服务也没有问题 再修改文件 core-site.xml : 进入/export/server/hadoop-3.3.0/etc/hadoop目录下进行修改:
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
# 没有开启垃圾桶效果
[root@node1 hadoop]# hdfs dfs -rm /binzi/hello.txt
Deleted /binzi/hello.txt# 开启垃圾桶
[root@node1 ~]#cd /export/server/hadoop-3.3.0/etc/hadoop
[root@node1 hadoop]# vim core-site.xml
# 注意: 放到<configuration>内容</configuration>中间
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property># 开启垃圾桶效果
[root@node1 hadoop]# hdfs dfs -rm -r /test1.har
2023-05-24 15:07:33,470 INFO fs.TrashPolicyDefault: Moved: 'hdfs://node1.itcast.cn:8020/test1.har' to trash at: hdfs://node1.itcast.cn:8020/user/root/.Trash/Current/test1.har# 开启垃圾桶后并没有真正删除,还可以恢复
[root@node1 hadoop]# hdfs dfs -mv /user/root/.Trash/Current/test1.har /
相关文章:
2023.11.17 hadoop之HDFS进阶
目录 HDFS的机制 元数据简介 元数据存储流程:namenode 生成了多个edits文件和一个fsimage文件 edits和fsimage文件 SecondaryNameNode辅助NameNode的方式: HDFS的存储原理 写入数据原理: 发送写入请求,获取主节点同意,开始写入,写入完成 读取数据原理:发送读取请求,获取…...
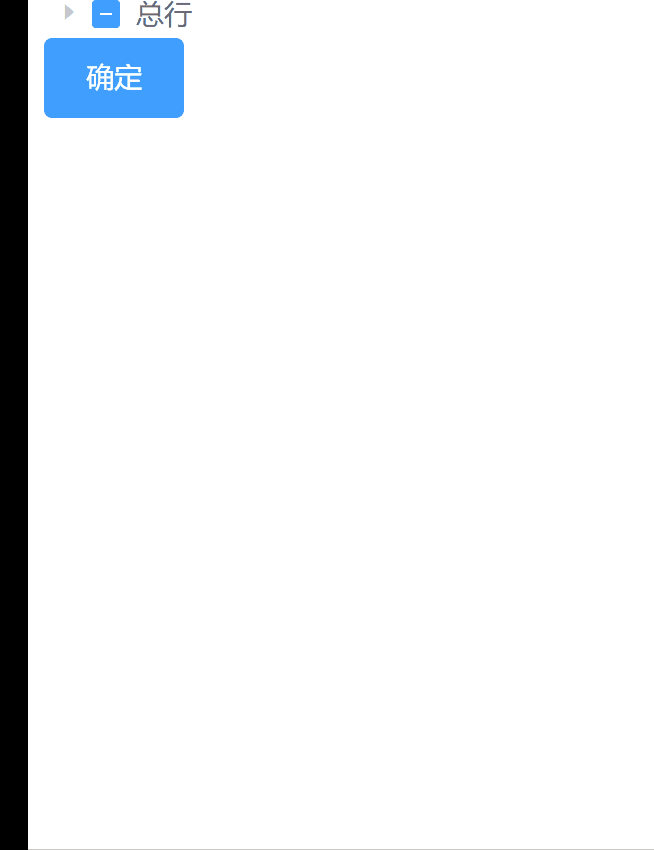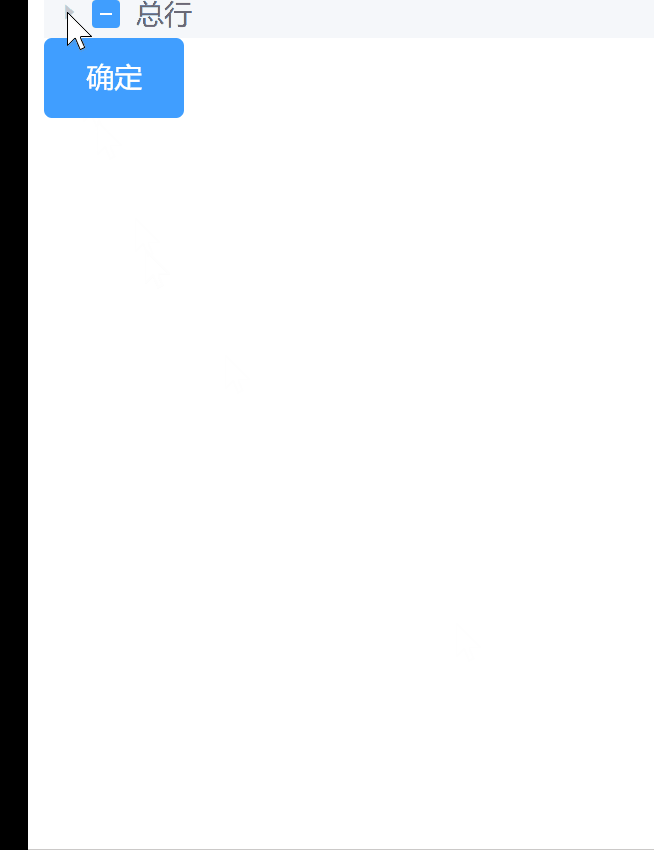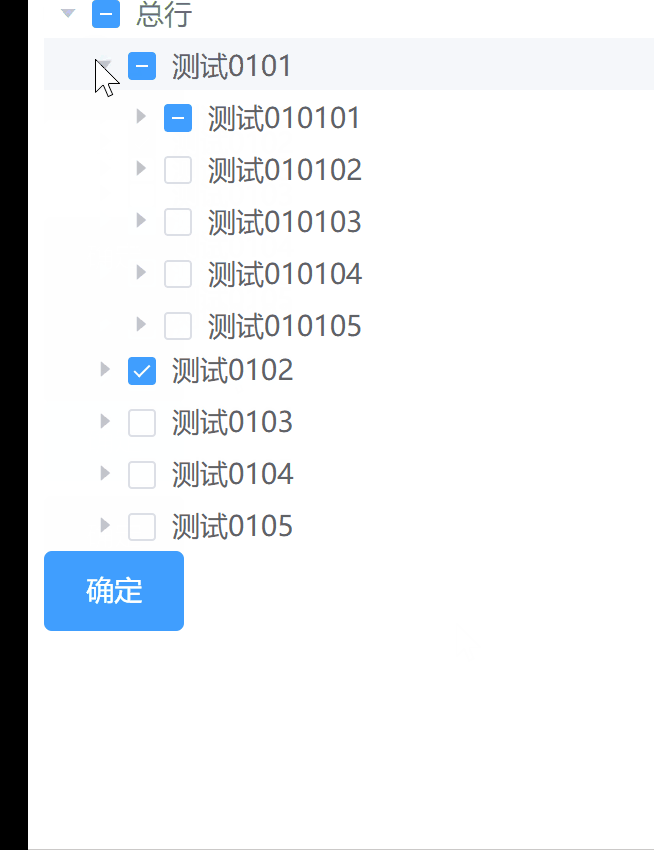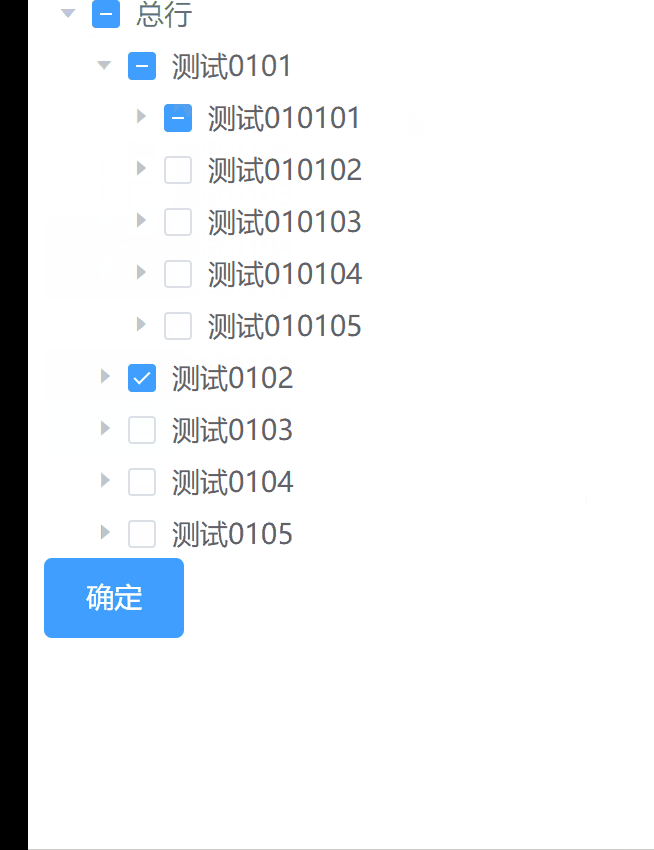
如何在el-tree懒加载并且包含下级的情况下进行数据回显-01
在项目中做需求,遇到一个比较棘手的问题,el-tree懒加载在包含下级的时候,需要做回显,将选中的数据再次勾选上,在处理这个需求的时候有两点是比较困难的: el-tree是懒加载的,包含下级需要一层一…...

系列六、JVM的内存结构【栈】
一、产生背景 由于跨平台性的设计,Java的指令都是根据栈来设计的,不同平台的CPU架构不同,所以不能设计为基于寄存器的。 二、概述 栈也叫栈内存,主管Java程序的运行,是在线程创建时创建,线程销毁时销毁&…...
技巧篇:在Pycharm中配置集成Git
一、在Pycharm中配置集成Git 我们使用git需要先安装git工具,这里给出下载地址,下载后一路直接安装即可: https://git-for-windows.github.io/ 0. git中的一些常用词释义 Repository name: 仓库名称 Description(可选):…...
Yolov5
Yolov5 Anchor 1.Anchor是啥? anchor字面意思是锚,是个把船固定的东东(上图),anchor在计算机视觉中有锚点或锚框,目标检测中常出现的anchor box是锚框,表示固定的参考框…...
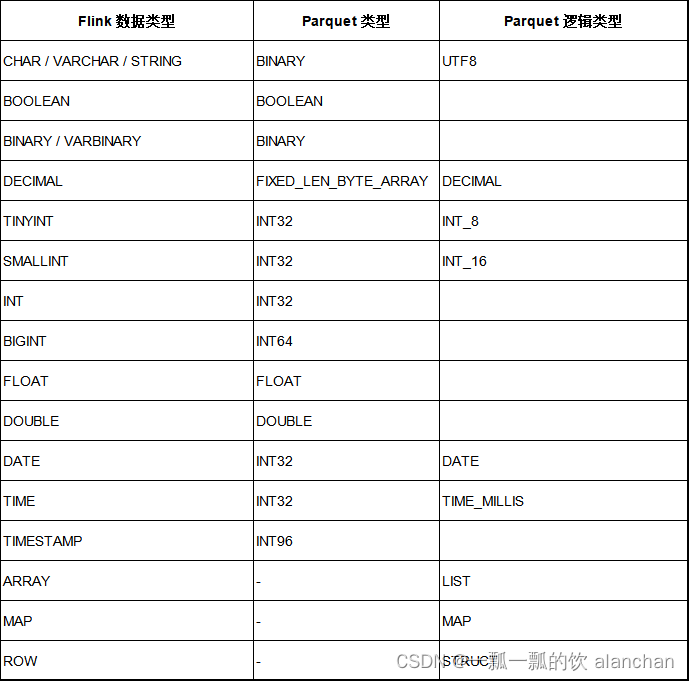
36、Flink 的 Formats 之Parquet 和 Orc Format
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...
--安装)
Docker 笔记(一)--安装
Docker 笔记(一)–安装 记录Docker 安装操作记录,便于查询。 参考 链接: Docker 入门到实战教程(二)安装Docker链接: docker入门(利用docker部署web应用)链接: 阿里云容器镜像服务/镜像加速器/操作文档链接: 网易镜像中心链接: 阿里云镜像…...

endnote20如何导入已经下载好的ris和pdf文件
查看此链接 1 文献导入 1.1 PDF导入 (1)方法一 打开:菜单栏–>Import–>FIle或folder 单个导入PDF或导入一个文件夹的PDF或通过拖曳多个PDF进入空白处完成导入 1.3 导入已经整理好的文献资料 已有的ris文件 打开:菜单栏–…...
x程无忧sign逆向分析
x程无忧sign逆向分析: 详情页sign: 详情页网站: import base64 # 解码 result base64.b64decode(aHR0cHM6Ly9qb2JzLjUxam9iLmNvbS9ndWFuZ3pob3UvMTUxODU1MTYyLmh0bWw/cz1zb3Vfc291X3NvdWxiJnQ9MF8wJnJlcT0zODQ4NGQxMzc2Zjc4MDY2M2Y1MGY2Y…...

Rust8.1 Smart Pointers
Rust学习笔记 Rust编程语言入门教程课程笔记 参考教材: The Rust Programming Language (by Steve Klabnik and Carol Nichols, with contributions from the Rust Community) Lecture 15: Smart Pointers src/main.rs use crate::List::{Cons, Nil}; use std::ops::Deref…...

MATLAB与Excel的数据交互
准备阶段 clear all % 添加Excel函数 try Excel=actxGetRunningServer(Excel.Application); catch Excel=actxserver(Excel.application); end % 设置Excel可见 Excel.visible=1; 插入数据 % % 激活eSheet1 % eSheet1.Activate; % 或者 % Activate(eSheet1); % % 打开…...

使用.NET 4.0、3.5时,UnmanagedFunctionPointer导致堆栈溢出
本文介绍了使用.NET 4.0、3.5时,UnmanagedFunctionPointer导致堆栈溢出的处理方法,对大家解决问题具有一定的参考价值,需要的朋友们下面随着小编来一起学习吧! 问题描述 我在带有try catch块的点击处理程序中有一个简单的函数。…...
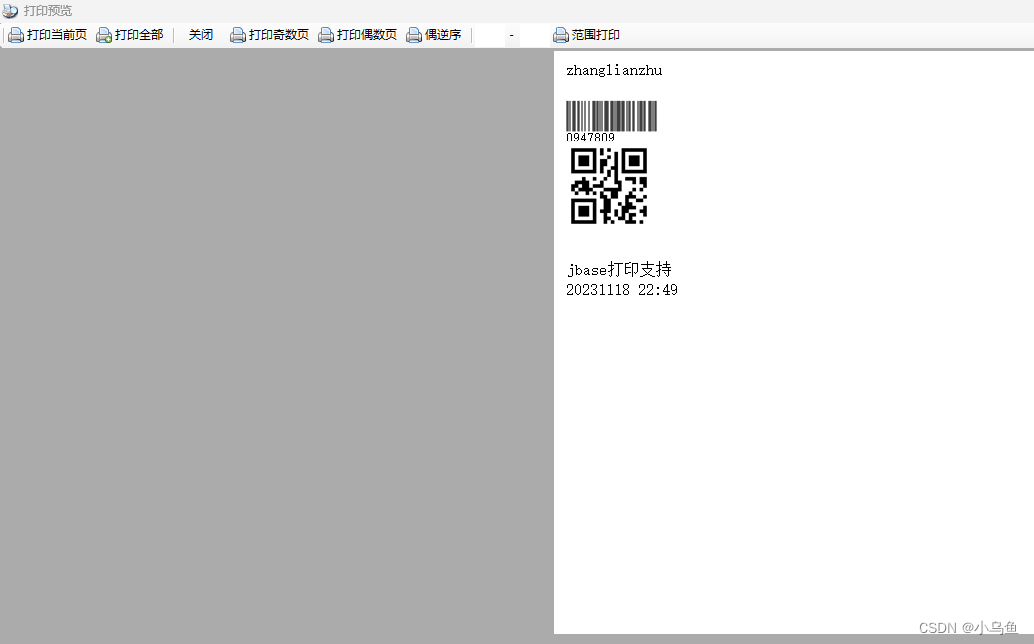
jbase打印导出实现
上一篇实现了虚拟M层,这篇基于虚拟M实现打印导出。 首先对接打印层 using Newtonsoft.Json; using System; using System.Collections.Generic; using System.Linq; using System.Net; using System.Text; using System.Threading.Tasks; using System.Xml;namesp…...

特征缩放和转换以及自定义Transformers(Machine Learning 研习之九)
特征缩放和转换 您需要应用于数据的最重要的转换之一是功能扩展。除了少数例外,机器学习算法在输入数值属性具有非常不同的尺度时表现不佳。住房数据就是这种情况:房间总数约为6至39320间,而收入中位数仅为0至15间。如果没有任何缩放,大多数…...

前端算法面试之堆排序-每日一练
如果对前端八股文感兴趣,可以留意公重号:码农补给站,总有你要的干货。 今天分享一个非常热门的算法--堆排序。堆的运用非常的广泛,例如,Python中的heapq模块提供了堆排序算法,可以用于实现优先队列…...
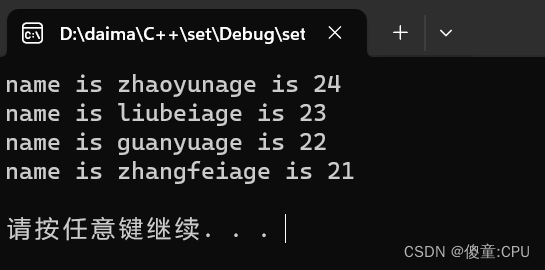
C++之set/multise容器
C之set/multise容器 set基本概念 set构造和赋值 #include <iostream> #include<set> using namespace std;void PrintfSet(set<int>&s) {for(set<int>::iterator it s.begin();it ! s.end();it){cout<<*it<<" ";}cout&l…...

本地部署AutoGPT
我们都了解ChatGPT,是Openai退出的基于GPT模型的新一代 AI助手,可以帮助解决我们在多个领域的问题。但是你会发现,在某些问题上,ChatGPT 需要经过不断的调教与沟通,才能得到接近正确的答案。对于你不太了解的领域领域&…...

ProtocolBuffers(protobuf)详解
目录 前言特点语法定义关键字JSON与Protocol Buffers互相转换gRPC与Protocol Buffers的关系 前言 Protocol Buffers(通常简称为protobuf)是Google公司开发的一种数据描述语言,它能够将结构化数据序列化,可用于数据存储、通信协议…...
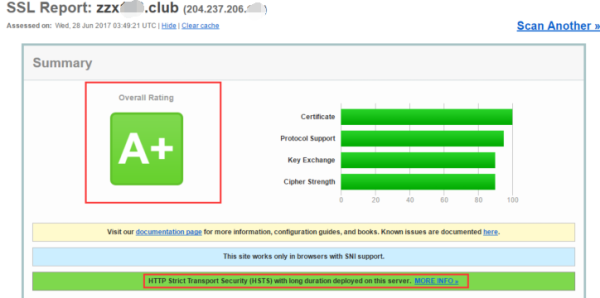
HTTP 到 HTTPS 再到 HSTS 的转变
近些年,随着域名劫持、信息泄漏等网络安全事件的频繁发生,网站安全也变得越来越重要,也促成了网络传输协议从 HTTP 到 HTTPS 再到 HSTS 的转变。 HTTP HTTP(超文本传输协议) 是一种用于分布式、协作式和超媒体信息系…...
清华学霸告诉你:如何自学人工智能?
清华大学作为中国顶尖的学府之一,培养了许多优秀的人才,其中不乏在人工智能领域有所成就的学霸。通过一位清华学霸的经验分享,揭示如何自学人工智能,帮助你在这场科技浪潮中勇往直前。 一、夯实基础知识 数学基础:学习…...

BilibiliDown:三分钟掌握跨平台B站视频批量下载终极方案
BilibiliDown:三分钟掌握跨平台B站视频批量下载终极方案 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors…...

【系统分析师_知识点整理】 8.项目管理
核心考向:进度管理(计算 选择最高频):关键路径、ES/EF/LS/LF、总浮动时间、自由浮动时间、PDM 四种依赖、进度偏差分析;范围管理:WBS、范围确认、范围控制、范围边界定义;成本管理:…...
)
【异常】设备时间戳时区偏差问题分析与解决(实际应为上午11点,但数据库存储为晚上7点)
一、问题现象 在生产环境中发现,IoT 设备上报的对话记录时间存在异常。具体表现为: 实际时间:2026年3月30日 上午 11:00 数据库存储时间:2026年3月30日 晚上 19:00 时间偏差:约 8 小时 数据库查询示例: -- 实际应为上午11点,但数据库存储为晚上7点 dialog_time: 2026-…...

5步搭建DeepSeek-OCR服务:从部署到调用完整教程
5步搭建DeepSeek-OCR服务:从部署到调用完整教程 1. 引言:为什么选择DeepSeek-OCR 1.1 OCR技术的实际应用场景 在日常工作和生活中,我们经常遇到需要从图片中提取文字的场景。比如: 扫描的合同或发票需要转为可编辑文本手机拍摄…...

别再为小Batch Size发愁了!手把手教你用Group Normalization稳定训练你的PyTorch模型
别再为小Batch Size发愁了!手把手教你用Group Normalization稳定训练你的PyTorch模型 当你在训练深度学习模型时,是否遇到过这样的困境:由于GPU显存限制,只能使用较小的batch size,结果模型训练变得极不稳定ÿ…...

SDMatte数据库课程设计案例:电商商品图库智能管理系统
SDMatte数据库课程设计案例:电商商品图库智能管理系统 1. 项目背景与需求分析 电商平台每天需要处理大量商品图片,传统人工修图方式存在效率低、成本高、风格不统一等问题。某服装电商平台希望开发一套智能图库管理系统,能够自动完成商品图…...

避坑指南:uniapp调用支付宝授权时常见的5个错误及解决方案
Uniapp支付宝授权实战:5个高频错误与深度解决方案 移动应用开发中,第三方授权登录是提升用户体验的关键环节。作为国内主流支付平台,支付宝授权在电商、生活服务类App中应用广泛。但许多Uniapp开发者在实现支付宝授权功能时,总会遇…...

为什么你的Markdown文档总是乱糟糟?vscode-markdownlint帮你告别格式噩梦
为什么你的Markdown文档总是乱糟糟?vscode-markdownlint帮你告别格式噩梦 【免费下载链接】vscode-markdownlint Markdown linting and style checking for Visual Studio Code 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-markdownlint 你是否曾因…...

如何用League-Toolkit提升30%游戏决策效率?完整指南
如何用League-Toolkit提升30%游戏决策效率?完整指南 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 价值定位…...

Go UUID终极指南:为什么选择go.uuid而非标准库的5大理由
Go UUID终极指南:为什么选择go.uuid而非标准库的5大理由 【免费下载链接】go.uuid UUID package for Go 项目地址: https://gitcode.com/gh_mirrors/go/go.uuid 在Go语言开发中,生成全局唯一标识符(UUID)是常见的需求。虽然…...