特征缩放和转换以及自定义Transformers(Machine Learning 研习之九)
特征缩放和转换
您需要应用于数据的最重要的转换之一是功能扩展。除了少数例外,机器学习算法在输入数值属性具有非常不同的尺度时表现不佳。住房数据就是这种情况:房间总数约为6至39320间,而收入中位数仅为0至15间。如果没有任何缩放,大多数模型将倾向于忽略收入中位数,而更多地关注房间数。
有两种常见的方法使所有属性具有相同的尺度:最小-最大尺度和标准化。
与所有估计器一样,重要的是仅将标量拟合到训练数据:永远不要对训练集以外的任何对象使用fit()或fit_transform()。一旦你有了一个训练好的定标器,你就可以用它来变换()任何其他的集合,包括验证集、测试集和新的数据。请注意,虽然培训集值将始终缩放到指定的范围,但如果新的数据包含异常值,则这些值最终可能会缩放到该范围之外。如果要避免这种情况,只需将剪辑超参数设置为True即可。
最小-最大缩放(许多人称之为标准化)是最简单的:对于每个属性,值被移位和重新缩放,以便它们最终的范围从0到1。这是通过减去最小值并除以最小值和最大值之间的差来实现的。Scikit-Learn为此提供了一个名为MinMaxScaler的转换器。它有一个feature_range超参数,如果出于某种原因,不希望0-1(例如,神经网络在零均值输入下工作得最好,所以最好在-1到1的范围内工作)。是相当好用的:
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler(feature_range=(-1, 1))
housing_num_min_max_scaled = min_max_scaler.fit_transform(housing_num)
标准化是不同的:首先它减去平均值(所以标准化值有一个零均值),然后它除以标准差(所以标准-化值的标准差等于1)。不像最小最大缩放,标准化化不会将值限制在特定的范围内。然而,标准化受到离群值的影响要小得多。例如,假设一个地区的收入中位数等于100(误打误撞),而不是通常的0-15。将最小最大值缩放到0-1范围会将这个离群值映射到1并将所有其他值压缩到0-0.15,而标准化不会受到太大影响。Scikit-Learn提供了一个名为StandardScaler的转换器用于标准化:
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
housing_num_std_scaled = std_scaler.fit_transform(housing_num)
如果你想缩放一个稀疏矩阵而不首先将其转换为稠密矩阵,你可以使用一个标准缩放器,它的with_mean超参数设置为False它只会除以标准差,而不会减去均值(因为这会破坏稀疏性
当特征的分布具有重尾时(即,当远离平均值的值不是指数罕见时),最小-最大缩放和标准化都会将大多数值压缩到一个小范围内。 机器学习模型通常根本不喜欢这种情况,因此,在缩放特征之前,您应该首先对其进行变换以缩小重尾,并且如果可能的话,使分布大致对称。 例如,对于右侧有重尾部的正特征,执行此操作的常见方法是用其平方根替换特征(或将特征提高到 0 到 1 之间的幂)。 如果该特征具有非常长且重的尾部,例如幂律分布,则用其对数替换该特征可能会有所帮助。 例如,人口特征大致遵循幂律:拥有 10,000 名居民的地区的出现频率仅比拥有 1,000 名居民的地区低 10 倍,而不是呈指数级下降。 下图 显示了当你计算它的对数时这个特征看起来有多好:它非常接近高斯分布(即钟形)。

另一种处理重尾特征的方法是对特征进行反向转换。这意味着将其分布切割成大致相等大小的桶,并将每个特征值替换为它所属的桶的索引,就像我们创建收入猫特征一样(尽管我们只在分层抽样时使用它)。例如,您可以将每个值替换为其百分位数。使用相同大小的bucket处理会产生一个几乎均匀分布的特性,因此不需要进一步的缩放,或者您可以只除以bucket的数目来强制值到0-1的范围。
当一个特征具有多峰分布(即,有两个或两个以上清晰的峰值,称为模式)时,例housing_median_age特征,对它进行bucket ization也是有帮助的,但这次将bucket ID作为类别处理,而不是作为数值。这意味着必须对桶索引进行编码,例如使用OneHotEncoder(所以你通常不想用太多桶)。这种方法将允许回归模型更容易地为该特征值的不同范围学习不同的规则。例如,也许35年前建造的房子有一种独特的风格,已经过时了,因此它们比它们的年龄更便宜。
转换多峰分布的另一种方法是为每个模式(至少是主要模式)添加一个特征,表示住房中位年龄和该特定模式之间的相似性。相似性度量通常使用径向基函数(RBF)来计算–任何只依赖于输入值与不动点之间距离的函数。最常用的RBF是高斯RBF,其输出值随着输入值远离固定点而呈指数衰减。例如,高斯RBF相似度与房龄x和35由方程exp (-y (x-35)2)给出。超参数y(gamma)确定当x远离35时相似性度量衰减的速度。使用Scikit-Learn的rbf_kernel()函数,您可以创建一个新的高斯RBF特征来测量房屋中位年龄和35:
from sklearn.metrics.pairwise import rbf_kernel
age_simil_35 = rbf_kernel(housing[["housing_median_age"]], [[35]], gamma=0.1)
下图显示了这一新特征作为住房中位数年龄的函数(实线)。它还显示了如果使用较小的gamma值,该功能将是什么样子。如图所示,新的年龄相似性特征在35岁时达到峰值,正好在住房中位年龄分布的峰值附近:如果这个特定的年龄组与较低的价格有很好的相关性,那么这个新特征将有很好的机会发挥作用。

到目前为止,我们只看了输入特性,但是目标值可能也需要转换。例如,若目标分布具有较重的尾部,您可以选择将目标替换为其对数。但是,如果你这样做,回归模型现在将预测的房屋价值中位数的对数,而不是房屋价值中位数本身。如果您想要预测的房屋中值,则需要计算模型预测的指数值。
幸运的是,大多数Scikit-Learn的转换器都有一个inverse_transform()方法,这使得计算转换的逆运算变得很容易。例如,下面的代码示例显示了如何使用StandardScaler缩放标签(就像我们对输入所做的那样),然后在缩放后的标签上训练一个简单的线性回归模型,并使用它对一些新数据进行预测,然后使用经过训练的缩放器的inverse_transform()方法将这些数据转换回原始尺度。请注意,我们将标签从Pandas Series转换为DataFrame,因为标准Scaler期望2D输入。此外,为了简单起见,在本示例中,我们仅使用单个原始输入特征(中值收入)对模型进行训练:
from sklearn.linear_model import LinearRegression
target_scaler = StandardScaler()
scaled_labels = target_scaler.fit_transform(housing_labels.to_frame())
model = LinearRegression()
model.fit(housing[["median_income"]], scaled_labels)
some_new_data = housing[["median_income"]].iloc[:5] # pretend this is new data
scaled_predictions = model.predict(some_new_data)
predictions = target_scaler.inverse_transform(scaled_predictions)
这工作得很好,但更简单的选择是使用TransformedTargetRegressor。我们只需要构造它,给它回归模型和标签转换器,然后使用原始的未缩放标签将其拟合到训练集上。它将自动使用转换器缩放标签,并在缩放后的标签上训练回归模型,就像我们之前所做的那样。然后,当我们想要进行预测时,它将调用回归模型的predict()方法,并使用scaler的inverse_trans form()方法生成预测:
from sklearn.compose import TransformedTargetRegressor
model = TransformedTargetRegressor(LinearRegression(),
transformer=StandardScaler())
model.fit(housing[["median_income"]], housing_labels)
predictions = model.predict(some_new_data)
自定义Transformers
虽然Scikit-Learn提供了许多有用的转换器,但您需要编写自己的任务,如自定义转换、清理操作或组合特定属性。
对于不需要任何训练的转换,您可以只编写一个函数,该函数接受NumPy数组作为输入,并输出转换后的数组。例如,如前一节所述,通过将具有重尾分布的特征替换为它们的对数(假设特征为正数且尾部位于右侧),通常是一个好主意。让我们创建一个log-transformer,并将其应用于人口特征:
from sklearn.preprocessing import FunctionTransformer
log_transformer = FunctionTransformer(np.log, inverse_func=np.exp)
log_pop = log_transformer.transform(housing[["population"]])
inverse_func参数是可选的。它允许您指定一个逆变换函数,例如,如果您计划在
TransformedTargetRegressor中使用您的转换器。转换函数可以接受超参数作为附加参数。例如,以下是如何创建一个转换器,计算与前面相同的高斯RBF相似性度量:
rbf_transformer = FunctionTransformer(rbf_kernel,
kw_args=dict(Y=[[35.]], gamma=0.1))
age_simil_35 = rbf_transformer.transform(housing[["housing_median_age"]]
注意,RBF核没有反函数,因为在距离一个固定点的给定距离上总是有两个值(距离0除外)。还要注意rbf_kernel()不会单独处理这些特性。如果你给它传递一个有两个特征的数组,它会测量二维距离(欧几里得)来测量相似性。例如,以下是如何添加一个功能,该功能将测量每个区和旧金山之间的地理相似性:
sf_coords = 37.7749, -122.41
sf_transformer = FunctionTransformer(rbf_kernel,
kw_args=dict(Y=[sf_coords], gamma=0.1))
sf_simil = sf_transformer.transform(housing[["latitude", "longitude"]])
自定义transformers对于组合功能也很有用。例如,这里有一个FunctionTransformer,它计算输入特征0和1之间的比率:

FunctionTransformer非常方便,但是如果您希望您的转换器是可训练的,在fit()方法中学习一些参数,然后在transform()方法中使用它们,那该怎么办呢?为此,您需要编写一个自定义类。Scikit-Learn依赖于duck类型,所以这个类不必从任何特定的基类继承。它只需要三个方法:fit()(必须返回self)、
transform () 和fit_transform()。
只需添加TransformerMixin作为基类,就可以免费获得fit_transform():默认实现将只调用fit(),然后再调用transform()。如果将BaseEstimator添加为基类(并避免使用*args和**kwargs),您还将获得两个额外的方法:get_params ()和set_params()。这些对于自动超参数调优非常有用。
例如,这里有一个自定义 transformer,其行为与StandardScaler非常相似:
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.utils.validation import check_array, check_is_fitted
class StandardScalerClone(BaseEstimator, TransformerMixin):def __init__(self, with_mean=True): # no *args or **kwargs!self.with_mean = with_meandef fit(self, X, y=None): # y is required even though we don't use itX = check_array(X) # checks that X is an array with finite float valuesself.mean_ = X.mean(axis=0)self.scale_ = X.std(axis=0)self.n_features_in_ = X.shape[1] # every estimator stores this in fit()return self # always return self!def transform(self, X):check_is_fitted(self) # looks for learned attributes (with trailing _)X = check_array(X)assert self.n_features_in_ == X.shape[1]if self.with_mean:X = X - self.mean_return X / self.scal
这里有几点需要注意:
- sklearn.utils.validation包包含几个我们可以用来验证输入的函数。为了简单起见,我们将在本书的其余部分跳过这样的测试,但是产品代码应该有这些测试。
- Scikit-Learn管道要求fit()方法有两个参数X和y,这就是为什么我们需要y=没有参数,即使我们不使用y。
- 所有Scikit-Learn估计器都在fit()方法中设置n_features_in_,并且它们确保传递给transform()或predict()的数据具有此数量的特征。_
- .fit ()方法必须返回self。
- 这个实现不是100%完成的:所有的估算器都应该在拟合中设置feature_
names_in_ ()方法时,它们被传递一个DataFrame。此外,所有的转换器都
应该提供get_feature_names_out()方法,以及当它们的转换可以被逆转时
的inverse_transform()方法。更多细节请参见本章最后一个练习。
自定义转换器可以(而且经常)在其实现中使用其他估计器。例如,以下代码演示了自定义转换器,该转换器在fit()方法中使用KMeans聚类器来识别训练数据中的主要聚类,然后在transform()方法中使用rbf
kernel ()来衡量每个样本与每个聚类中心的相似程度:
from sklearn.cluster import KMeans
class ClusterSimilarity(BaseEstimator, TransformerMixin):def __init__(self, n_clusters=10, gamma=1.0, random_state=None):self.n_clusters = n_clustersself.gamma = gammaself.random_state = random_statedef fit(self, X, y=None, sample_weight=None):self.kmeans_ = KMeans(self.n_clusters, random_state=self.random_state)self.kmeans_.fit(X, sample_weight=sample_weight)return self # always return self!def transform(self, X):return rbf_kernel(X, self.kmeans_.cluster_centers_, gamma=self.gamma)def get_feature_names_out(self, names=None):return [f"Cluster {i} similarity" for i in range(self.n_clusters)]
k-means是一种在数据中定位聚类的聚类算法。它搜索的数量由n_clusters超参数控制。训练后,可以通过cluster_centers_属性使用聚类中心。KMeans的fit()方法支持一个可选参数sample_weight,该参数允许用户指定样本的相对权重。K-means是一种随机算法,这意味着它依赖随机性来定位聚类,因此若您想要可重现的结果,则必须设置random_state参数。正如您所看到的,尽管任务很复杂,但代码相当简单。现在让我们使用这个自定义的变压器:
cluster_simil = ClusterSimilarity(n_clusters=10, gamma=1., random_state=42)
similarities = cluster_simil.fit_transform(housing[["latitude", "longitude"]],
sample_weight=housing_labels)
这段代码创建一个ClusterSimilarity转换器,将集群数设置为10.然后调用fit_transform(),输入训练集中每个区的纬度和经度,并根据每个区的房屋中值对每个区进行加权。变压器采用k-均值定位聚类,
然后测量每个区域与所有10个聚类中心之间的高斯RBF相似性。结果是一个矩阵,每个区有一行,每个集群有一列。先看前三行,四舍五入到小数点后两位:

下图显示了通过k-means找到的10个聚类中心。根据它们与最近的集群中心的地理相似性,对这些区域进行着色。正如您所看到的,大多数集群都位于人口密集且价格昂贵的地区。

相关文章:
特征缩放和转换以及自定义Transformers(Machine Learning 研习之九)
特征缩放和转换 您需要应用于数据的最重要的转换之一是功能扩展。除了少数例外,机器学习算法在输入数值属性具有非常不同的尺度时表现不佳。住房数据就是这种情况:房间总数约为6至39320间,而收入中位数仅为0至15间。如果没有任何缩放,大多数…...

前端算法面试之堆排序-每日一练
如果对前端八股文感兴趣,可以留意公重号:码农补给站,总有你要的干货。 今天分享一个非常热门的算法--堆排序。堆的运用非常的广泛,例如,Python中的heapq模块提供了堆排序算法,可以用于实现优先队列…...
C++之set/multise容器
C之set/multise容器 set基本概念 set构造和赋值 #include <iostream> #include<set> using namespace std;void PrintfSet(set<int>&s) {for(set<int>::iterator it s.begin();it ! s.end();it){cout<<*it<<" ";}cout&l…...

本地部署AutoGPT
我们都了解ChatGPT,是Openai退出的基于GPT模型的新一代 AI助手,可以帮助解决我们在多个领域的问题。但是你会发现,在某些问题上,ChatGPT 需要经过不断的调教与沟通,才能得到接近正确的答案。对于你不太了解的领域领域&…...

ProtocolBuffers(protobuf)详解
目录 前言特点语法定义关键字JSON与Protocol Buffers互相转换gRPC与Protocol Buffers的关系 前言 Protocol Buffers(通常简称为protobuf)是Google公司开发的一种数据描述语言,它能够将结构化数据序列化,可用于数据存储、通信协议…...
HTTP 到 HTTPS 再到 HSTS 的转变
近些年,随着域名劫持、信息泄漏等网络安全事件的频繁发生,网站安全也变得越来越重要,也促成了网络传输协议从 HTTP 到 HTTPS 再到 HSTS 的转变。 HTTP HTTP(超文本传输协议) 是一种用于分布式、协作式和超媒体信息系…...
清华学霸告诉你:如何自学人工智能?
清华大学作为中国顶尖的学府之一,培养了许多优秀的人才,其中不乏在人工智能领域有所成就的学霸。通过一位清华学霸的经验分享,揭示如何自学人工智能,帮助你在这场科技浪潮中勇往直前。 一、夯实基础知识 数学基础:学习…...
Ubuntu 安装VMware Tools选项显示灰色,如何安装VMware Tools
切换apt源为阿里云: https://qq742971636.blog.csdn.net/article/details/134291339 只要你的网络没问题,你直接执行这几个命令,重启ubuntu虚拟机即可、 sudo dpkg --configure -a sudo apt-get autoremove open-vm-tools sudo apt-get ins…...

SpringBoot 2.x 实战仿B站高性能后端项目
SpringBoot 2.x 实战仿B站高性能后端项目 下栽の地止:请看文章末尾 通常SpringBoot新建项目,默认是集成了Maven,然后所有内容都在一个主模块中。 如果项目架构稍微复杂一点,就需要用到Maven多模块。 本文简单概述一下,…...
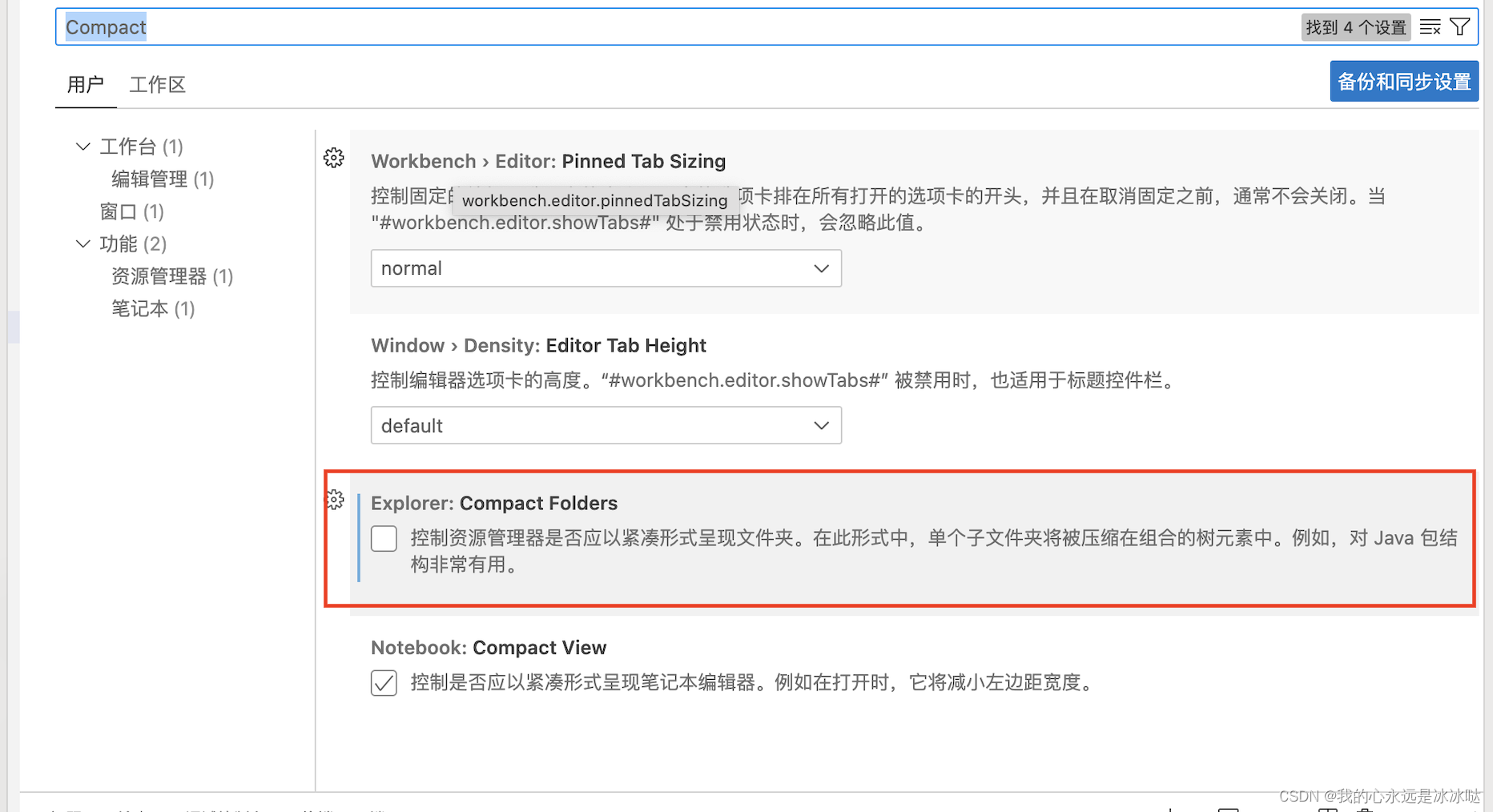
vscode文件夹折叠问题
今天发现一个vscode的文件夹显示的问题,首先是这样的,就是我的文件夹里又一个子文件夹,子文件夹里有一些文件,但是我发现无法折叠起这个子文件夹,总是显示全部的文件,这让我备份很难,具体参考 h…...
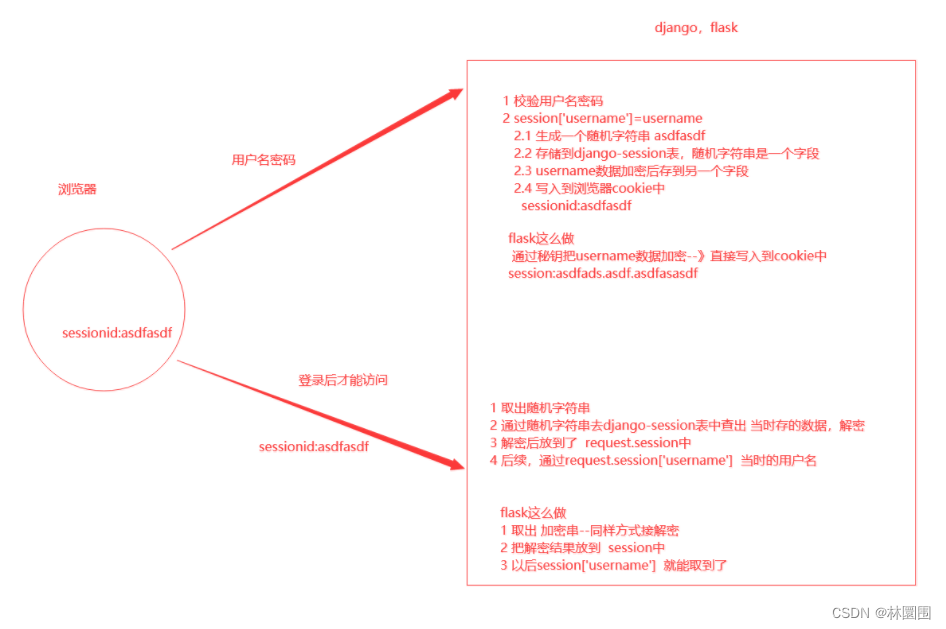
4-flask-cbv源码、Jinja2模板、请求响应、flask中的session、flask项目参考
1 flask中cbv源码 2 Jinja2模板 3 请求响应 4 flask中的session 5 flask项目参考 1 flask中cbv源码 ***flask的官网文档:***https://flask.palletsprojects.com/en/3.0.x/views/1 cbv源码执行流程1 请求来了,路由匹配成功---》执行ItemAPI.as_view(item…...
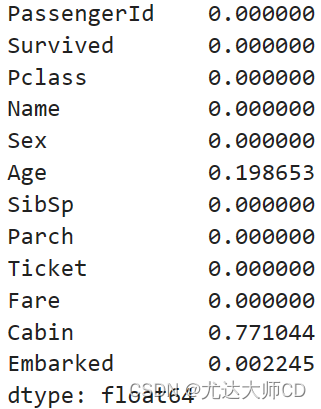
2.Pandas数据预处理
2.1 数据清洗 以titanic数据为例。 df pd.read_csv(titanic.csv) 2.1.1 缺失值 (1)缺失判断 df.isnull() (2)缺失统计 # 列缺失统计 df.isnull().sum(axis0) # 行缺失统计 df.isnull().sum(axis1) # 统计缺失率 df.isnu…...

C# IEnumerable<T>介绍
IEnumerable 是 C# 中的一个接口,它是 .NET Framework 中的集合类型的基础。任何实现了 IEnumerable 接口的对象都可以进行 foreach 迭代。 IEnumerable 只有一个方法,即 GetEnumerator,该方法返回一个 IEnumerator 对象。IEnumerator 对象用…...

九洲
《九洲》 作者/罗光记 九洲春色映朝阳, 洲渚风光似画廊。 柳絮飘飞花似雪, 九州繁华共锦裳。 水波荡漾鱼儿跃, 洲边鸟语唤晨光。 春风拂过千里岸, 九洲儿女笑语扬。...

基于Genio 700 (MT8390)芯片的AR智能眼镜方案
AR眼镜是一种具有前所未有发展机遇的设备,无论是显示效果、体积还是功能都有明显的提升。AR技术因其智能、实时、三维、多重交互和开放世界的特点备受关注。 AR眼镜集成了AR技术、语音识别、智能控制等多项高科技功能,可以帮助用户实现更加便捷、高效、个…...
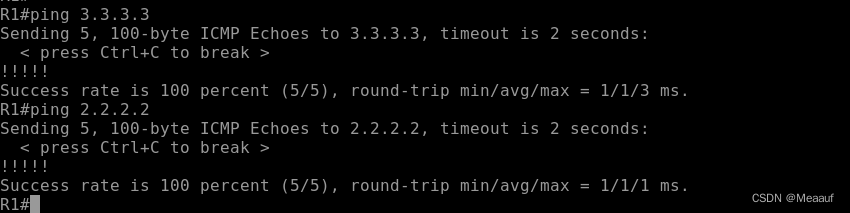
锐捷OSPF认证
一、知识补充 1、基本概述 OSPF区域认证和端口认证是两种不同的认证机制,用于增强OSPF协议的安全性。 OSPF区域认证(OSPF Area Authentication):这种认证机制是基于区域的。在OSPF网络中,每个区域都可以配置一个区域…...

M2 Mac Xcode编译报错 ‘***.framework/‘ for architecture arm64
In /Users/fly/Project/Pods/YYKit/Vendor/WebP.framework/WebP(anim_decode.o), building for iOS Simulator, but linking in object file built for iOS, file /Users/fly/Project/Pods/YYKit/Vendor/WebP.framework/WebP for architecture arm64 这是我当时编译模拟器时报…...

Python算法题2023 输出123456789到98765432中完全不包含2023的数有多少
题目: 无输入,只需输出结果🤐 这个数字比较大,小伙伴们运行的时候要给代码一点耐心嗷つ﹏⊂ ,下面是思路,代码注释也很详细,大致看一下吧(^∀^●)…...
SpringBoot整合Thymeleaf
Thymeleaf 支持 HTML 原型,可以让前端工程师在浏览器中直接打开查看样式,也可以让后端工程师结合真实数据查看显示效果 Thymeleaf 除了展示基本的 HTML ,进行页面渲染之外,也可以作为一个 HTML 片段进行渲染,例如我们在…...

OpenAI的多函数调用(Multiple Function Calling)简介
我在六月份写了一篇关于GPT 函数调用(Function calling) 的博客https://blog.csdn.net/xindoo/article/details/131262670,其中介绍了函数调用的方法,但之前的函数调用,在一轮对话中只能调用一个函数。就在上周,OpenAI…...

终极指南:如何免费搭建专业的电子实验室笔记本系统
终极指南:如何免费搭建专业的电子实验室笔记本系统 【免费下载链接】elabftw :notebook: eLabFTW is the most popular open source electronic lab notebook for research labs. 项目地址: https://gitcode.com/gh_mirrors/el/elabftw eLabFTW是一款功能强大…...

嵌入式存储优化实战:如何为你的AUTOSAR FEE模块选择合适的FeeMainFunctionPeriod与FeeMaxBytesPerCycle?
嵌入式存储优化实战:AUTOSAR FEE模块参数配置与性能调优 在汽车电子控制单元(ECU)的开发中,存储管理一直是影响系统性能和可靠性的关键因素。AUTOSAR的Flash EEPROM Emulation(FEE)模块作为非易失性数据存储…...

从数据备份到模型部署:深入理解Numpy的.npy/.npz文件在机器学习流水线中的角色
从数据备份到模型部署:深入理解Numpy的.npy/.npz文件在机器学习流水线中的角色 在机器学习项目的完整生命周期中,数据的高效存储与快速读取往往是决定工程效率的关键因素之一。当我们谈论数据处理工具时,Numpy无疑是Python生态中不可忽视的核…...
)
保姆级教程:用PHPStudy+Nginx一键部署新麦同城V3开源版(附数据库配置避坑点)
零基础30分钟部署新麦同城V3:PHPStudyNginx全流程避坑指南 第一次接触本地部署开源系统时,最怕的不是代码复杂,而是明明按教程操作却卡在某个配置环节。本文将以真实踩坑记录为核心,手把手带你在Windows环境下用PHPStudy快速搭建…...

i.MX6ULL电容触摸驱动开发:从硬件原理到Linux输入子系统实战
1. 项目概述:从零到一,搞定i.MX6ULL电容触摸最近在搞一个基于i.MX6ULL的工控HMI项目,客户要求界面操作必须流畅跟手,这就对触摸屏的响应速度和精度提出了硬性要求。市面上很多现成的模块要么驱动兼容性差,要么调试信息…...

用PyTorch复现BCNet息肉分割模型:从论文到代码的保姆级实践指南
用PyTorch复现BCNet息肉分割模型:从论文到代码的保姆级实践指南 医学影像分析领域,息肉分割一直是内窥镜诊断的关键技术。传统方法依赖医生手动标注,效率低下且易受主观因素影响。近年来,深度学习在医学图像分割领域展现出强大潜…...

20+终极Obsidian模板:简单快速构建你的卡片盒笔记系统
20终极Obsidian模板:简单快速构建你的卡片盒笔记系统 【免费下载链接】Obsidian-Templates A repository containing templates and scripts for #Obsidian to support the #Zettelkasten method for note-taking. 项目地址: https://gitcode.com/gh_mirrors/ob/O…...

2026年计算机专业就业现状,不想35岁被淘汰?网络安全或许是程序员的最佳转型方向!
计算机专业虽进入分化阶段,但网络安全人才缺口达300万,高端领域供不应求。高校扩招与市场需求脱节导致供需失衡,未来"计算机行业"的复合型人才更具竞争力。建议早做规划,构建"T型能力体系",掌握前…...

给你的Alienware设备一次真正的解放:轻量级控制工具完全指南
给你的Alienware设备一次真正的解放:轻量级控制工具完全指南 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 你是否曾经为Alienware Comman…...

一线观察:赣州新房装修公司的可靠细节
上个月,有个老朋友找我帮他参谋新房装修的事。赣州章江新区某刚交付的高端盘,精装改毛坯,180平的大户型。他跟我说,前后跑了五六家装修公司,聊完最大的感觉是——云里雾里。报价单看不懂方案,总觉得藏着坑&…...