什么是缓存雪崩、击穿、穿透?
背景
数据一般是存储于数据库中,数据库中的数据都是存在磁盘上的,磁盘读写的速度相较于内存或者CPU中的寄存器来说是非常慢的了。
如果用户的请求都直接访问数据库的话,请求数量一上来,数据库很容易就崩溃了,所以为了避免用户直接访问数据库,会用 Redis 作为缓存层。
因为Redis 是内存数据库,我们可以直接将数据库的数据缓存在 Redis 中,相当于数据缓存在内存,内存的读写速度比硬盘快很多,这样大大提升了系统的性能。
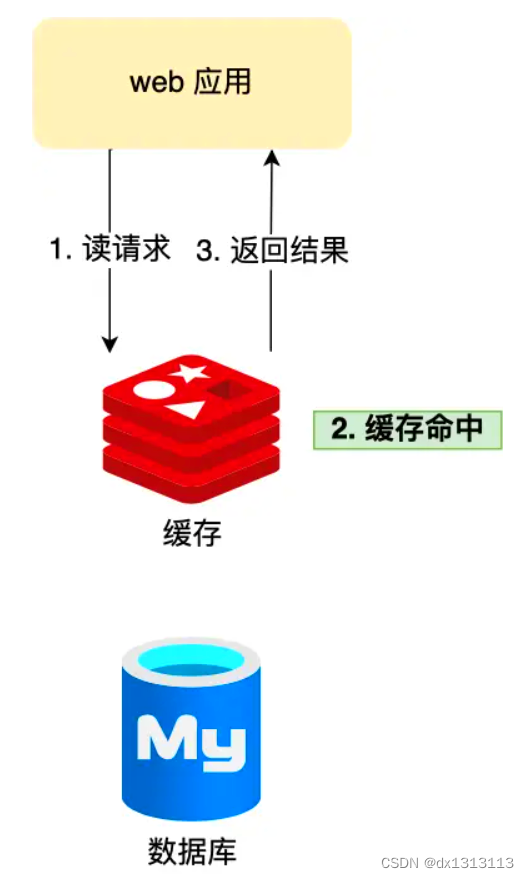
引入了缓存层,就会有缓存异常的三个问题,分别是缓存雪崩、缓存击穿、缓存穿透。
缓存雪崩
通常为了保证缓存中的数据与数据库中数据的一致性,会给 Redis 里的数据设置过期时间,当缓存数据过期后,用户访问的数据如果不在数据库中,业务系统就需要重新生成缓存,因此会去访问数据库,并将数据缓存到 Redis 中,这样后续再次请求就可以直接命中缓存了。
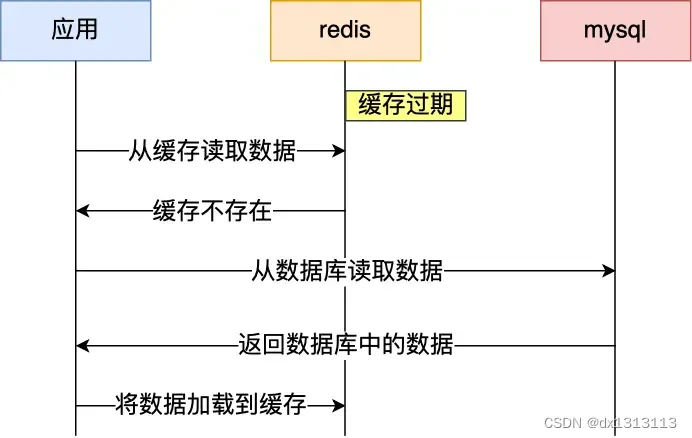
当大量缓存数据在同一时间过期(失效)或者 Redis 故障宕机时,此时如果有大量的用户请求都无法命中缓存,就会全部访问数据库,从而导致数据库的压力剧增,严重的会造成数据库宕机,从而形成一系列的连锁反应,造成整个系统崩溃,这就是缓存雪崩。
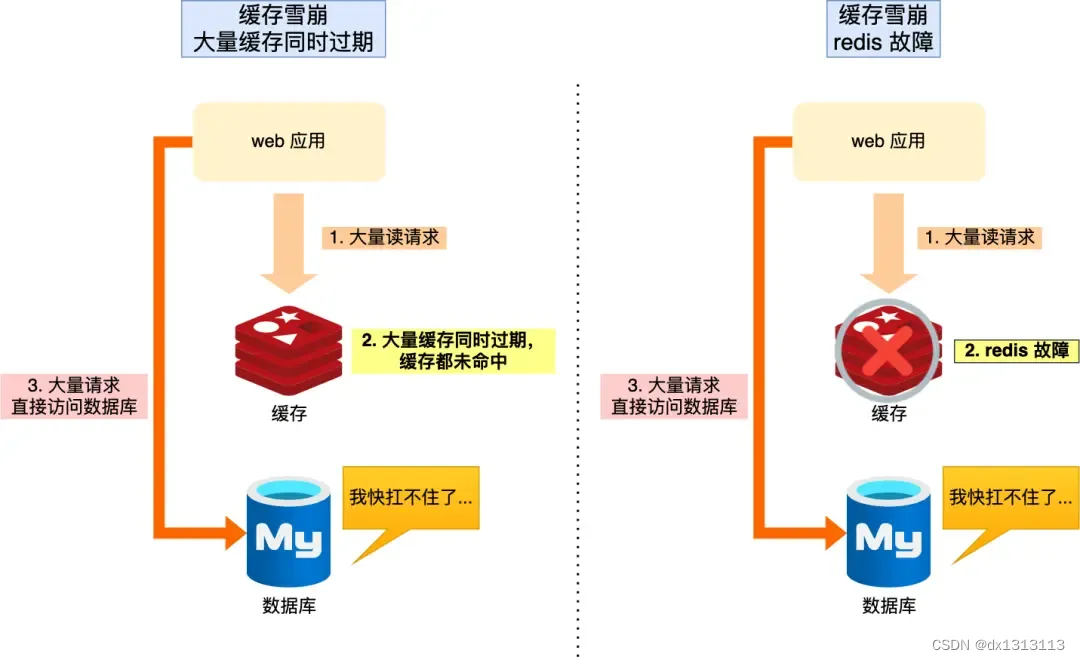
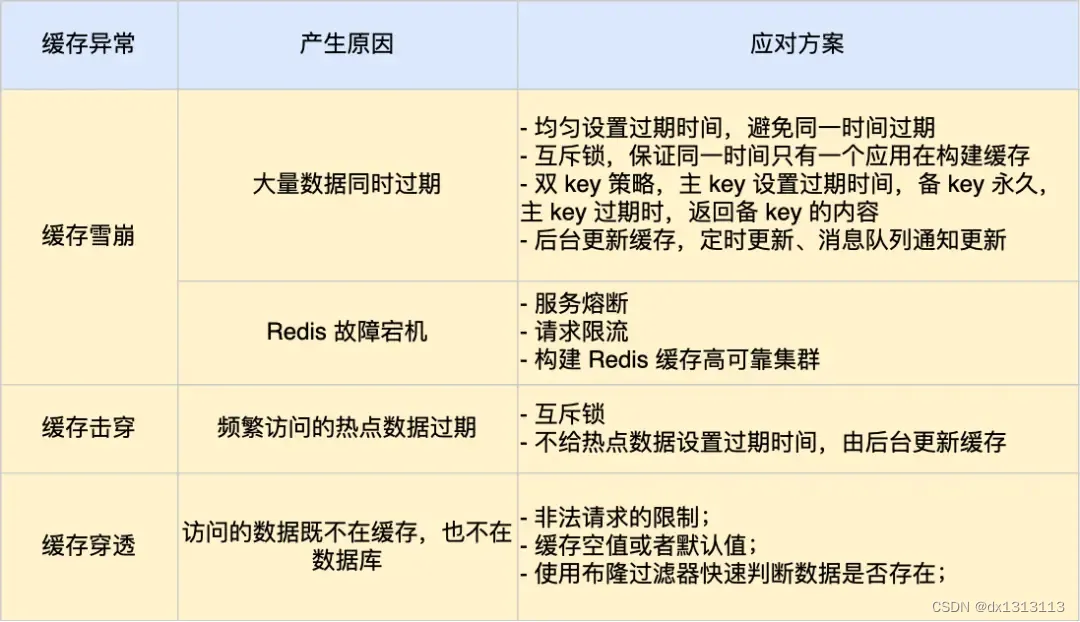
缓存雪崩发生的两个原因:
- 大量数据同时过期或失效
- Redis 故障宕机
大量数据同时过期
解决方法:
- 均匀设置过期时间
- 互斥锁
- 后台更新缓存
1. 均匀设置过期时间
避免将大量的数据设置成同一个过期时间。可以在对缓存数据设置过期时间的时候,给这些数据的过期时间加上一个随机数,这样就保证数据不会再同一时刻过期。
2. 互斥锁
当业务线程在处理用户请求时,如果发现访问的数据不在 Redis 里,就加一个互斥锁,保证同一时间内只有一个请求在构建缓存(从数据库中读取数据,再将数据更新到Redis),当缓存构建完成后,再释放锁。未能获取互斥锁的请求,要么等待锁的释放后再去请求缓存,要么直接返回空值。
3. 后台更新缓存
业务线程不再负责更新缓存,缓存也不设置有效期,而是让缓存“永久有效”,并将更新缓存的工作交给后台线程定时更新。
事实上,缓存数据不设置有效期,缓存中的数据也不会一直留存在内存中,因为当系统内存紧张的时候,有些缓存数据会被淘汰,而在缓存被淘汰到下一次后台定时更新缓存的这段时间内,业务线程读取缓存失败会返回空值,业务的视角就是数据丢失了。
解决上面的问题有两种方法:
方式一:
后台线程不仅负责定时更新缓存,而且负责频繁地检测缓存是否有效,检测到缓存失效了,原因可能是系统紧张而被淘汰的,于是就要马上从数据库中获取数据,并更新到缓存。
这种方式检测间隔不能太长,否则在间隔期间内用户获取数据也是有误的,所以检测时间最好是毫秒级,但是有时间间隔用户体验一般。
方式二:
在业务线程发现缓存数据失效后,通过消息队列发送一条消息通知后台线程更新缓存,后台线程收到消息后,在更新缓存前可以判断缓存是否存在,存在就不执行更新缓存操作;不存在就读取数据库数据,并将数据加载到缓存。这种方式比第一种方式缓存的更新会更及时,用户体验较好。
Redis 故障宕机
针对Redis 故障宕机而引发的缓存雪崩的问题,常见的应对方法有两种:
- 服务熔断或请求限流机制
- 构建Redis 缓存高可靠集群
1. 服务熔断或请求限流机制
因为Redis 故障宕机而导致换保存雪崩问题时,我们可以启动服务熔断机制,暂停业务应用对缓存服务的访问,直接返回错误,不再继续访问数据库,从而降低对数据库的访问压力,保证数据库的正常运行,然后等到 Redis 恢复后,再允许业务应用访问缓存服务。
服务熔断机制虽然保护了数据库的正常运行,但是暂停了业务访问数据,全部业务无法正常工作。为了减少对业务的影响,我们可以启用请求限流机制,只将少部分的请求发送到数据库进行处理,再多的请求就在入口处直接拒绝服务,等到 Redis 恢复正常并把缓存预热后,再移除对请求限流机制。
2. 构建Redis缓存高可用集群
服务熔断或请求限制机制是缓存雪崩发生后的应对方案,最好可以通过主从节点的方式构建Redis缓存高可靠集群。
如果Redis缓存的主节点宕机,从节点可以切换成为主节点,继续提供缓存服务,避免了由于Redis故障宕机而导致的缓存雪崩的问题。
缓存击穿
在业务中通常会有几个数据会被频繁地访问,这些数据被称为热点数据。
如果缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮,这就是缓存击穿。
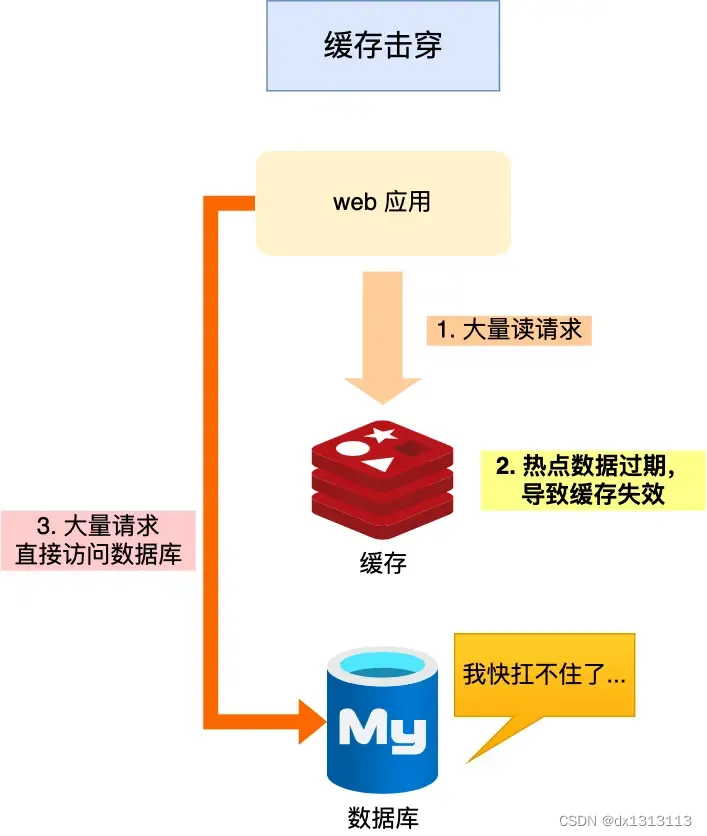
可以发现缓存击穿和缓存雪崩相似,可以认为缓存击穿时缓存雪崩的一种特殊情况。
应对缓存击穿可以采取缓存雪崩中说的两种解决方案:
- 互斥锁:保证同一时刻只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待互斥锁释放后重新读取缓存,要么返回空值或者默认值
- 不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备过期前,提前通知后台线程更新缓存以及重新设置过期时间。
缓存穿透
当用户访问的数据,既不在缓存中,又不在数据库中,导致请求在访问缓存时,发现缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据,没办法构建缓存数据,来服务后续的请求。那么当有大量这样的请求到来时,数据库的压力骤增,这就是缓存穿透的问题。

缓存穿透有两种情况:
- 业务误操作,缓存中的数据和数据库中的数据都被误删除了,所以导致缓存和数据库中都没有数据
- 恶意攻击,故意大量访问某些读取不存在数据的业务
应对缓存穿透的方案有三种:
- 非法请求限制
- 缓存空值或者默认值
- 使用布隆过滤器快速判断数据是否存在,避免通过查询数据来判断数据是否存在
1. 非法请求限制
当有大量的请求访问不存在的数据的时候,也会发生缓存穿透,因此在API入口处判断请求参数是否合理,请求参数是否含有非法值、请求字段是否存在,如果判断出是恶意请求就直接返回错误,避免进一步访问缓存和数据库。
2. 缓存空值或默认值
当线上业务发现缓存穿透的现象时,可以针对查询的数据,在缓存中设置一个空值或者默认值,这样后续请求就可以从缓存中读取到空值或者默认值,返回给应用,而不会继续查询数据库。
3. 使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在
可以在写数据库数据的时候,使用布隆过滤器做个标记,然后再用户请求到来时,业务线程先确定缓存失效后,可以通过查询布隆过滤器快速判断数据是否存在,如果不存在,就不用查询数据库来判断数据是否存在。
即使发生了缓存穿透,大量请求也只会查询缓存和布隆过滤器,而不会查询数据库,保证了数据库能正常运行,Redis 自身也是支持布隆过滤器的。
总结
相关文章:
什么是缓存雪崩、击穿、穿透?
背景 数据一般是存储于数据库中,数据库中的数据都是存在磁盘上的,磁盘读写的速度相较于内存或者CPU中的寄存器来说是非常慢的了。 如果用户的请求都直接访问数据库的话,请求数量一上来,数据库很容易就崩溃了,所以为了…...

可以通过电脑远程控制安卓设备的软件
有些时候,我们需要用电脑远程控制安卓设备,比如远程维护门店设备、安卓系统的户外广告牌等等。我们来探索和比较几款允许用户通过电脑远程控制安卓设备的软件。 1、Splashtop Business Splashtop 是一种多功能远程访问解决方案,以其高性能流…...

HP惠普暗影精灵9笔记本电脑OMEN by HP Transcend 16英寸游戏本16-u0000原厂Windows11系统
惠普暗影9恢复出厂开箱状态,原装出厂Win11-22H2系统ISO镜像 下载链接:https://pan.baidu.com/s/17ftbBHEMFSEOw22tnYvPog?pwd91p1 提取码:91p1 适用型号:16-u0006TX、16-u0007TX、16-u0008TX、16-u0009TX、16-u0017TX 原厂系…...

vue2+elementUI 仿照SPC开发CPK分析工具
源码地址请访问 Vue CPK分析工具页面设计源码(支持左右可拖拽和表格可编辑、复制粘贴)仿照SPC开发-CSDN博客...
云ES使用集群限流插件(aliyun-qos)
aliyun-qos插件是阿里云Elasticsearch团队自研的插件,能够提高集群的稳定性。该插件能够实现集群级别的读写限流,在关键时刻对指定索引降级,将流量控制在合适范围内。例如当上游业务无法进行流量控制时,尤其对于读请求业务,可根据aliyun-qos插件设置的规则,按照业务的优先…...

2023.11.17 hadoop之HDFS进阶
目录 HDFS的机制 元数据简介 元数据存储流程:namenode 生成了多个edits文件和一个fsimage文件 edits和fsimage文件 SecondaryNameNode辅助NameNode的方式: HDFS的存储原理 写入数据原理: 发送写入请求,获取主节点同意,开始写入,写入完成 读取数据原理:发送读取请求,获取…...
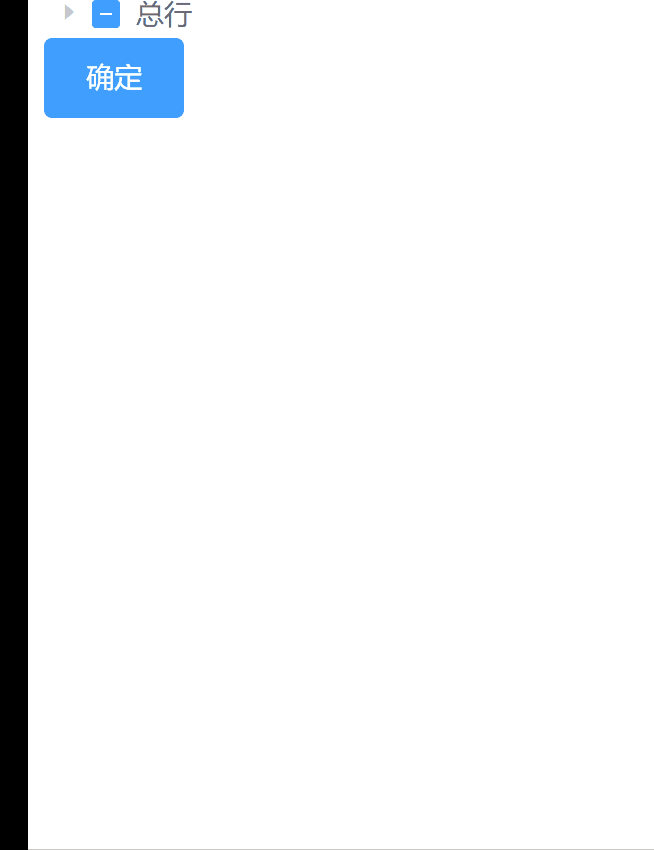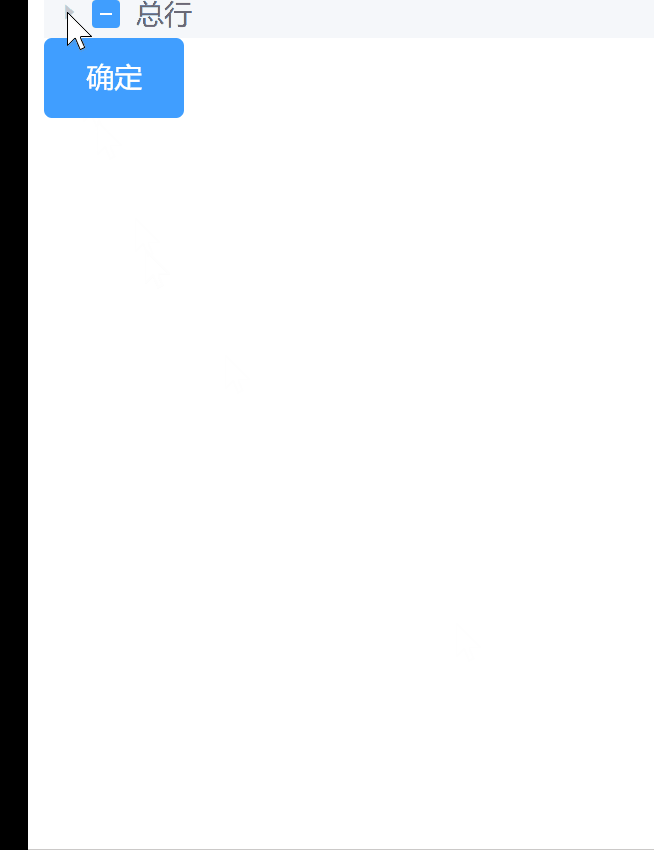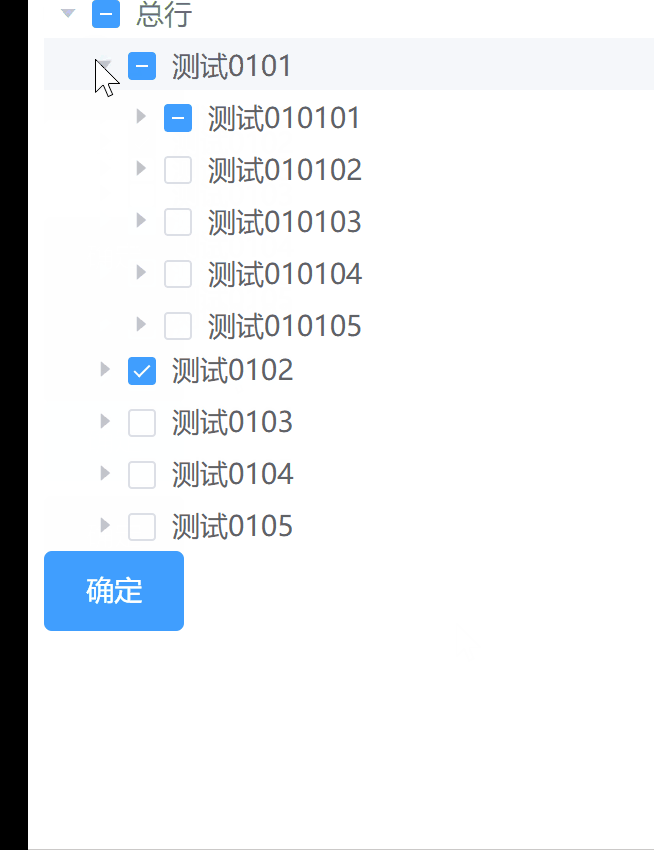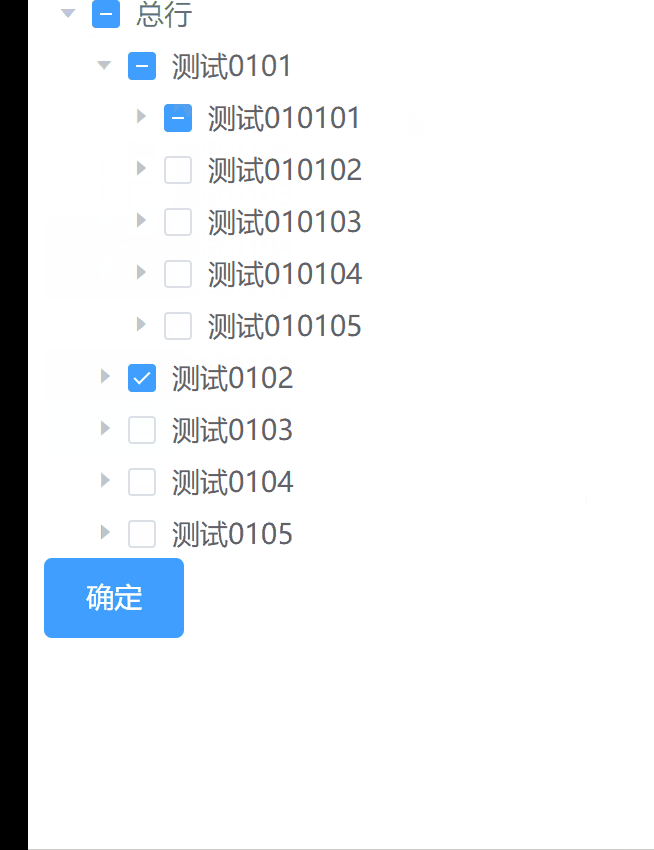
如何在el-tree懒加载并且包含下级的情况下进行数据回显-01
在项目中做需求,遇到一个比较棘手的问题,el-tree懒加载在包含下级的时候,需要做回显,将选中的数据再次勾选上,在处理这个需求的时候有两点是比较困难的: el-tree是懒加载的,包含下级需要一层一…...

系列六、JVM的内存结构【栈】
一、产生背景 由于跨平台性的设计,Java的指令都是根据栈来设计的,不同平台的CPU架构不同,所以不能设计为基于寄存器的。 二、概述 栈也叫栈内存,主管Java程序的运行,是在线程创建时创建,线程销毁时销毁&…...
技巧篇:在Pycharm中配置集成Git
一、在Pycharm中配置集成Git 我们使用git需要先安装git工具,这里给出下载地址,下载后一路直接安装即可: https://git-for-windows.github.io/ 0. git中的一些常用词释义 Repository name: 仓库名称 Description(可选):…...
Yolov5
Yolov5 Anchor 1.Anchor是啥? anchor字面意思是锚,是个把船固定的东东(上图),anchor在计算机视觉中有锚点或锚框,目标检测中常出现的anchor box是锚框,表示固定的参考框…...
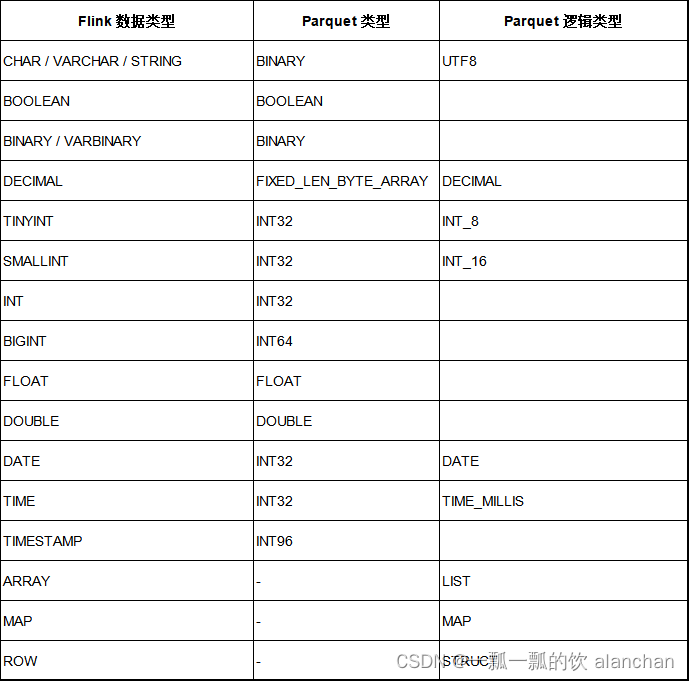
36、Flink 的 Formats 之Parquet 和 Orc Format
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...
--安装)
Docker 笔记(一)--安装
Docker 笔记(一)–安装 记录Docker 安装操作记录,便于查询。 参考 链接: Docker 入门到实战教程(二)安装Docker链接: docker入门(利用docker部署web应用)链接: 阿里云容器镜像服务/镜像加速器/操作文档链接: 网易镜像中心链接: 阿里云镜像…...

endnote20如何导入已经下载好的ris和pdf文件
查看此链接 1 文献导入 1.1 PDF导入 (1)方法一 打开:菜单栏–>Import–>FIle或folder 单个导入PDF或导入一个文件夹的PDF或通过拖曳多个PDF进入空白处完成导入 1.3 导入已经整理好的文献资料 已有的ris文件 打开:菜单栏–…...
x程无忧sign逆向分析
x程无忧sign逆向分析: 详情页sign: 详情页网站: import base64 # 解码 result base64.b64decode(aHR0cHM6Ly9qb2JzLjUxam9iLmNvbS9ndWFuZ3pob3UvMTUxODU1MTYyLmh0bWw/cz1zb3Vfc291X3NvdWxiJnQ9MF8wJnJlcT0zODQ4NGQxMzc2Zjc4MDY2M2Y1MGY2Y…...

Rust8.1 Smart Pointers
Rust学习笔记 Rust编程语言入门教程课程笔记 参考教材: The Rust Programming Language (by Steve Klabnik and Carol Nichols, with contributions from the Rust Community) Lecture 15: Smart Pointers src/main.rs use crate::List::{Cons, Nil}; use std::ops::Deref…...

MATLAB与Excel的数据交互
准备阶段 clear all % 添加Excel函数 try Excel=actxGetRunningServer(Excel.Application); catch Excel=actxserver(Excel.application); end % 设置Excel可见 Excel.visible=1; 插入数据 % % 激活eSheet1 % eSheet1.Activate; % 或者 % Activate(eSheet1); % % 打开…...

使用.NET 4.0、3.5时,UnmanagedFunctionPointer导致堆栈溢出
本文介绍了使用.NET 4.0、3.5时,UnmanagedFunctionPointer导致堆栈溢出的处理方法,对大家解决问题具有一定的参考价值,需要的朋友们下面随着小编来一起学习吧! 问题描述 我在带有try catch块的点击处理程序中有一个简单的函数。…...
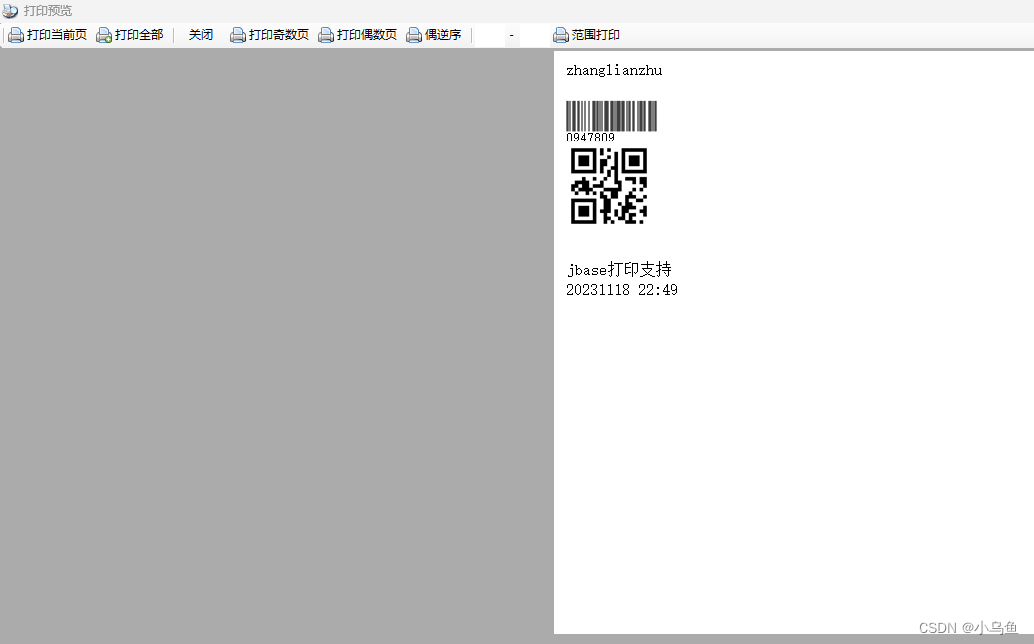
jbase打印导出实现
上一篇实现了虚拟M层,这篇基于虚拟M实现打印导出。 首先对接打印层 using Newtonsoft.Json; using System; using System.Collections.Generic; using System.Linq; using System.Net; using System.Text; using System.Threading.Tasks; using System.Xml;namesp…...

特征缩放和转换以及自定义Transformers(Machine Learning 研习之九)
特征缩放和转换 您需要应用于数据的最重要的转换之一是功能扩展。除了少数例外,机器学习算法在输入数值属性具有非常不同的尺度时表现不佳。住房数据就是这种情况:房间总数约为6至39320间,而收入中位数仅为0至15间。如果没有任何缩放,大多数…...

前端算法面试之堆排序-每日一练
如果对前端八股文感兴趣,可以留意公重号:码农补给站,总有你要的干货。 今天分享一个非常热门的算法--堆排序。堆的运用非常的广泛,例如,Python中的heapq模块提供了堆排序算法,可以用于实现优先队列…...

opencv利用freetype写中文
1、ubuntu需要安装环境 sudo apt install libfreetype6-dev libharfbuzz-dev 2、opencv和opencv_contril编译,勾选下面按钮 3、下载字体库 https://github.com/StellarCN/scp_zh/tree/master/fonts 下载SimHei.ttf 4、代码 #include <opencv2/freetype.hpp…...

TikTok GMXMAX广告优化全攻略
在2026年,TikTok广告投放逐渐向自动化模型演进,其中GMX MAX(GMV Max)成为很多团队用来提升ROI和放量的重要方式。相比传统广告模式,它可以自动完成受众匹配与预算分配,减少大量人工干预。不过在实际操作中&…...
)
别再死记硬背了!用Multisim仿真带你玩转计数器与数据选择器(附FPGA引脚配置)
用Multisim仿真与FPGA实战:计数器与数据选择器的设计艺术 数字电路课程中那些抽象的概念,是否曾让你感到困惑?模5计数器、序列信号发生器这些名词听起来高深莫测,但通过Multisim仿真和FPGA实战,你会发现它们其实可以很…...
)
【Matlab】MATLAB教程:拟合效果评估(案例:计算R²、残差;应用:量化评估拟合质量)
MATLAB教程:拟合效果评估(案例:计算R、残差;应用:量化评估拟合质量) 在实验数据分析、工程建模、科研拟合等场景中,很多人完成曲线拟合后,仅凭肉眼观察曲线是否“贴近数据”就判断拟合效果好坏,这种方式极具主观性:看似平滑的曲线,可能存在较大隐性误差;看似贴合局…...
:3D重建模型压缩终极指南)
Torch-Pruning支持神经辐射场(NERF):3D重建模型压缩终极指南
Torch-Pruning支持神经辐射场(NERF):3D重建模型压缩终极指南 【免费下载链接】Torch-Pruning [CVPR 2023] Towards Any Structural Pruning; LLMs / Diffusion / Transformers / YOLOv8 / CNNs 项目地址: https://gitcode.com/gh_mirrors/to/Torch-Pruning 神…...

比迪丽WebUI保姆级教程:从服务器IP获取到首张图生成全过程
比迪丽WebUI保姆级教程:从服务器IP获取到首张图生成全过程 1. 前言:为什么选择比迪丽WebUI? 如果你对《龙珠》里的比迪丽(Videl)这个角色情有独钟,想用AI画出她的各种形象,那么今天这个教程就…...

别光看论文!手把手带你复现CVPR 2025扩散模型加速新星:TinyFusion与DiG的代码实战
别光看论文!手把手带你复现CVPR 2025扩散模型加速新星:TinyFusion与DiG的代码实战 如果你已经厌倦了在arXiv上收藏一堆永远打不开第二次的论文链接,或是被那些充满数学符号却缺少可运行代码的"理论创新"搞得头大,那么这…...

Minecraft Masa Mods汉化包终极指南:三分钟告别英文界面困扰
Minecraft Masa Mods汉化包终极指南:三分钟告别英文界面困扰 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为Masa Mods系列模组的英文界面而烦恼吗?每次打…...
)
若依框架下,如何让JimuReport积木报表乖乖认你的登录状态?(附完整前后端代码)
若依框架与JimuReport深度整合:实现无缝登录状态管理的全链路实践 在当今企业级应用开发中,权限控制与单点登录已成为基础需求。当我们将若依(RuoYi)这一流行后台管理系统框架与JimuReport报表工具集成时,如何确保两者间的登录状态无缝衔接&a…...
)
全学科适用AI写作辅助网站排行榜(2026 实测推荐)
基于功能完整性、学术适配性、用户反馈及操作便捷性,以下是当前主流AI论文写作工具的实测排名,按综合使用价值从高到低依次呈现,并附上各平台的核心优势与适用人群。🏆 第一梯队:全流程学术解决方案(★★★…...