助力水泥基建裂痕自动化巡检,基于yolov5融合ASPP开发构建多尺度融合目标检测识别系统
道路场景下的自动化智能巡检、洞体场景下的壁体类建筑缺陷自动检测识别等等已经在现实生活中不断地落地应用了,在我们之前的很多博文中也已经有过很多相关的实践项目经历了,本文的核心目的是想要融合多尺度感受野技术到yolov5模型中以期在较低参数量的情况下实现尽可能高的精度效果,话不多说,先看效果:
接下来看下我们自主构建的数据集:


数据标注实例如下所示:
0 0.429688 0.133789 0.080078 0.248047
0 0.461426 0.365723 0.067383 0.217773
0 0.694824 0.147949 0.086914 0.293945
0 0.642578 0.372070 0.064453 0.142578
0 0.512207 0.516113 0.043945 0.083008
0 0.575684 0.725586 0.071289 0.548828
0 0.958984 0.817383 0.080078 0.107422
0 0.937988 0.965820 0.124023 0.068359
我们这里选择的是yolov5m这款参数量级的模型作为基准模型,如下所示:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 1 # number of classes
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# Backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# Head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
作为对比改进的模型,这里我们选择的是讲多尺度感受野ASPP方法融合进来。
ASPP(Atrous Spatial Pyramid Pooling)是一种用于目标检测模型的技术,它主要用于处理不同尺度下的目标。ASPP通过引入多个空洞卷积(atrous convolution)和金字塔池化(pyramid pooling)操作来获取多尺度的上下文信息。
首先,ASPP使用不同的空洞率(atrous rate)进行卷积操作,这可以增大感受野(receptive field)的大小,从而捕捉更大范围的上下文信息。通过使用多个空洞率的卷积,ASPP可以获得多个尺度的特征表示。
其次,ASPP使用金字塔池化操作来进一步增强多尺度的特征表示。金字塔池化通过在不同大小的池化窗口上进行池化操作,可以捕捉不同尺度下的特征。
最后,ASPP将多个尺度的特征进行融合,得到一个综合的特征表示。这个综合的特征表示可以用于目标检测任务中的分类和定位。
总之,ASPP技术通过引入多尺度的上下文信息,可以提升目标检测模型在不同尺度下的性能。它是目标检测领域中常用的技术之一,能够有效改善模型的性能。
改进后的模型文件如下:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 1 # number of classes
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# Backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, ASPP, [1024]], # 9]# Head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
对比如下:
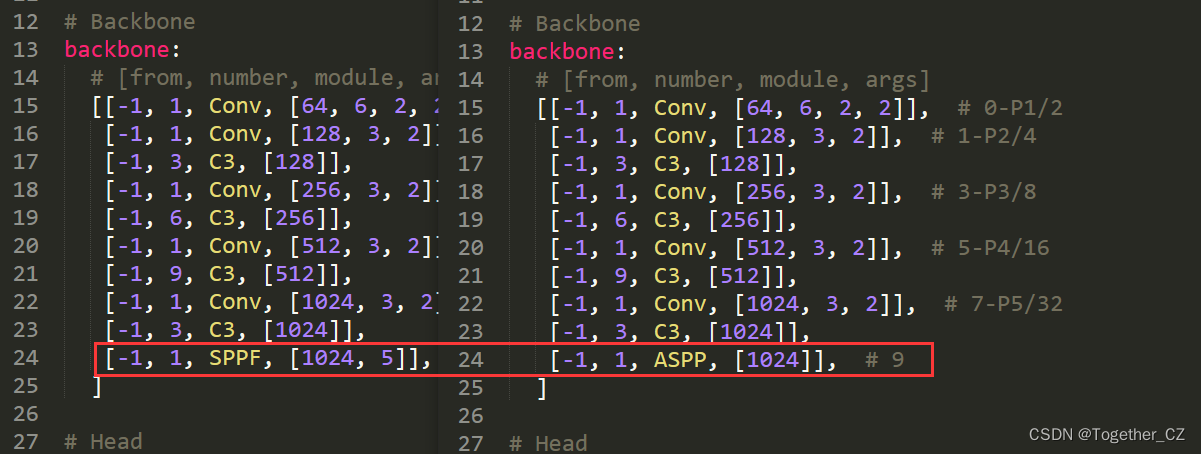
在骨干网络里面加入了ASPP模块。
默认完全相同的训练参数,100次epoch的迭代计算,接下来我们来看下结果对比:
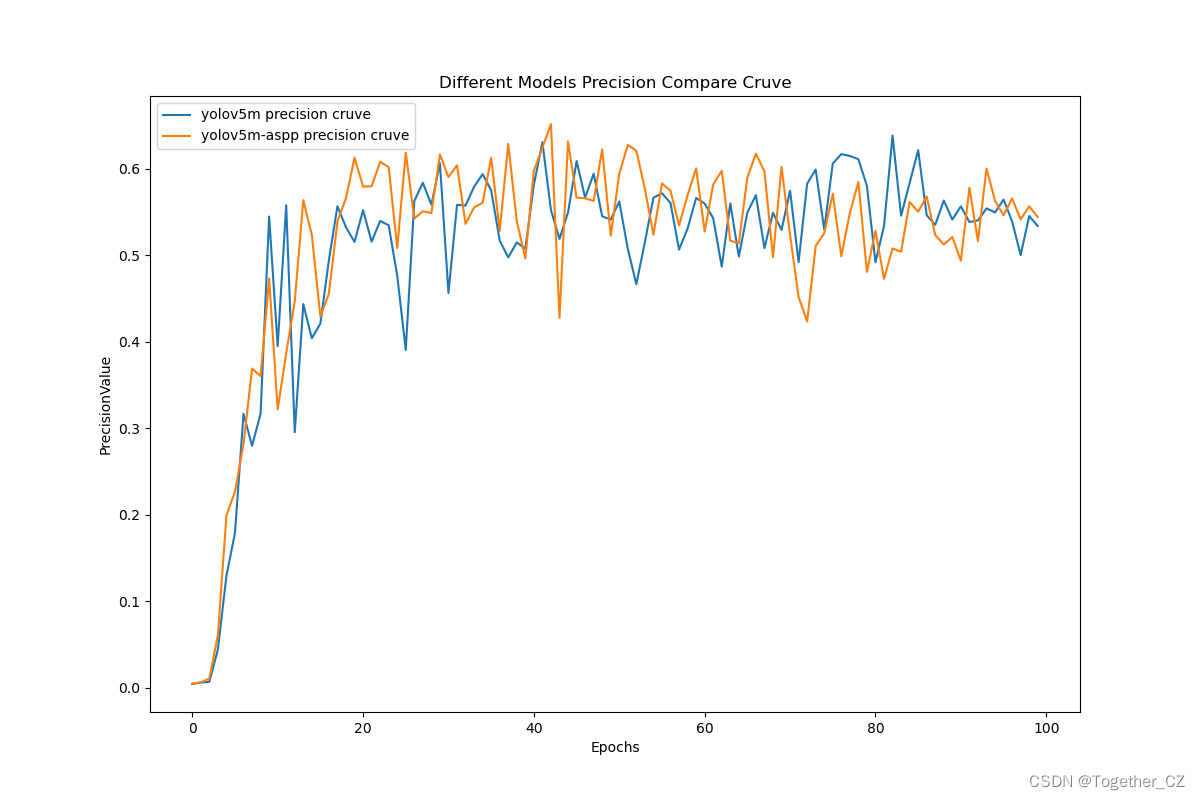
【Precision曲线】
精确率曲线(Precision-Recall Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
绘制精确率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率和召回率。
将每个阈值下的精确率和召回率绘制在同一个图表上,形成精确率曲线。
根据精确率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察精确率曲线,我们可以根据需求确定最佳的阈值,以平衡精确率和召回率。较高的精确率意味着较少的误报,而较高的召回率则表示较少的漏报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
精确率曲线通常与召回率曲线(Recall Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
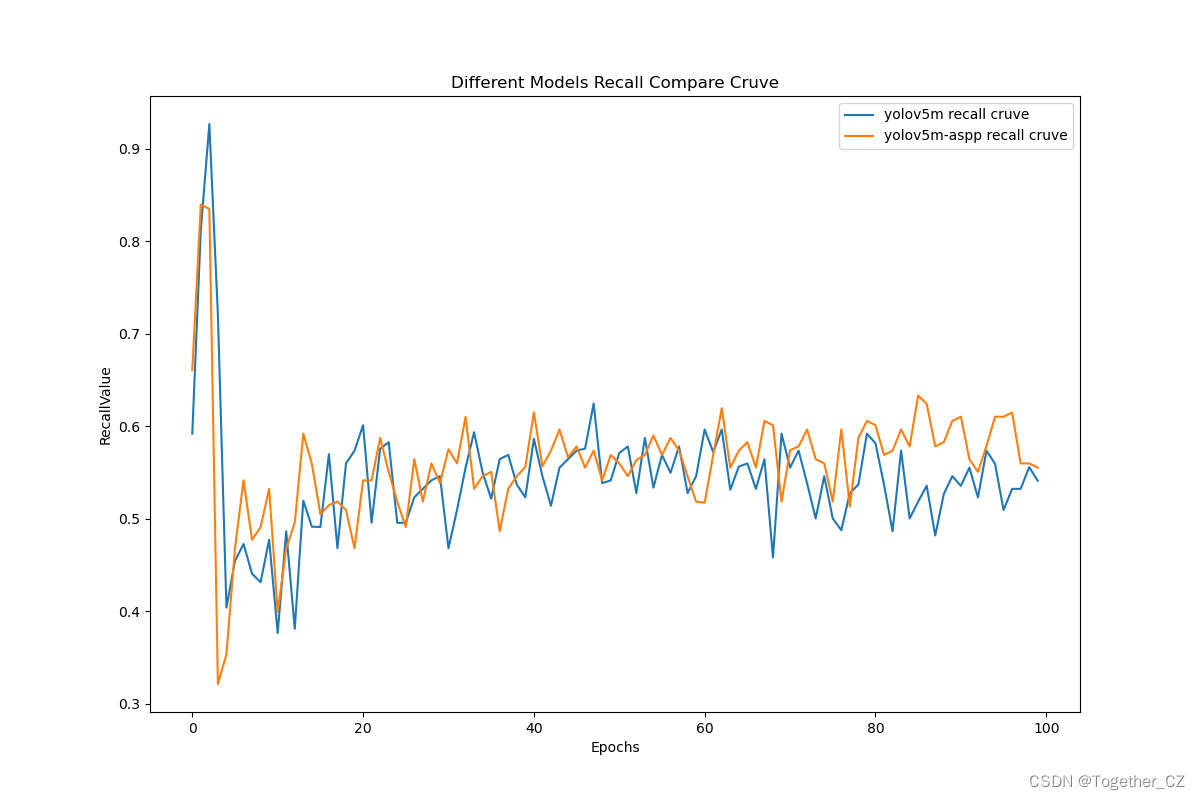
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。
召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
绘制召回率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的召回率和对应的精确率。
将每个阈值下的召回率和精确率绘制在同一个图表上,形成召回率曲线。
根据召回率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察召回率曲线,我们可以根据需求确定最佳的阈值,以平衡召回率和精确率。较高的召回率表示较少的漏报,而较高的精确率意味着较少的误报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
召回率曲线通常与精确率曲线(Precision Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能。
F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
绘制F1值曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率、召回率和F1分数。
将每个阈值下的精确率、召回率和F1分数绘制在同一个图表上,形成F1值曲线。
根据F1值曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
F1值曲线通常与接收者操作特征曲线(ROC曲线)一起使用,以帮助评估和比较不同模型的性能。它们提供了更全面的分类器性能分析,可以根据具体应用场景来选择合适的模型和阈值设置。
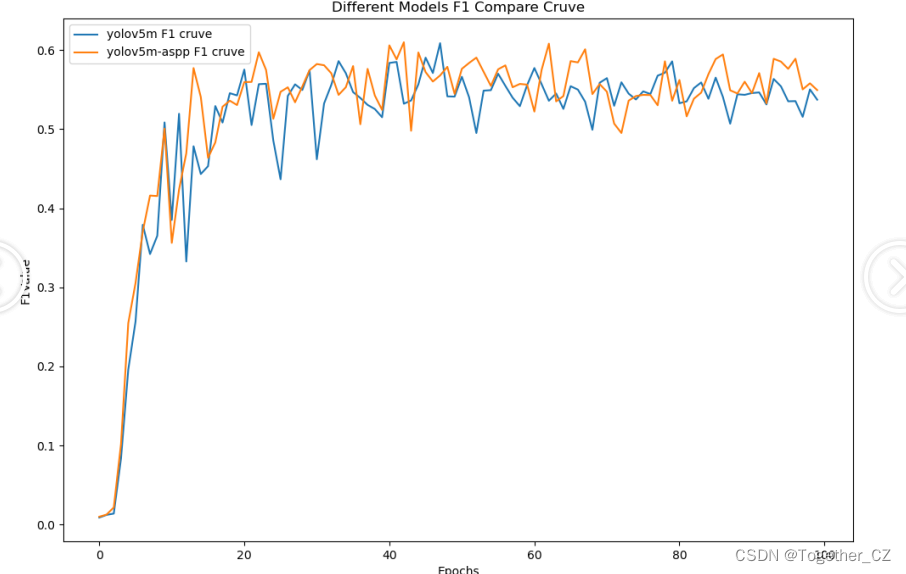
整体来看:改进后的模型在整体指标上都优于原生的模型。
我们进一步来看下融合ASPP的结果详情:
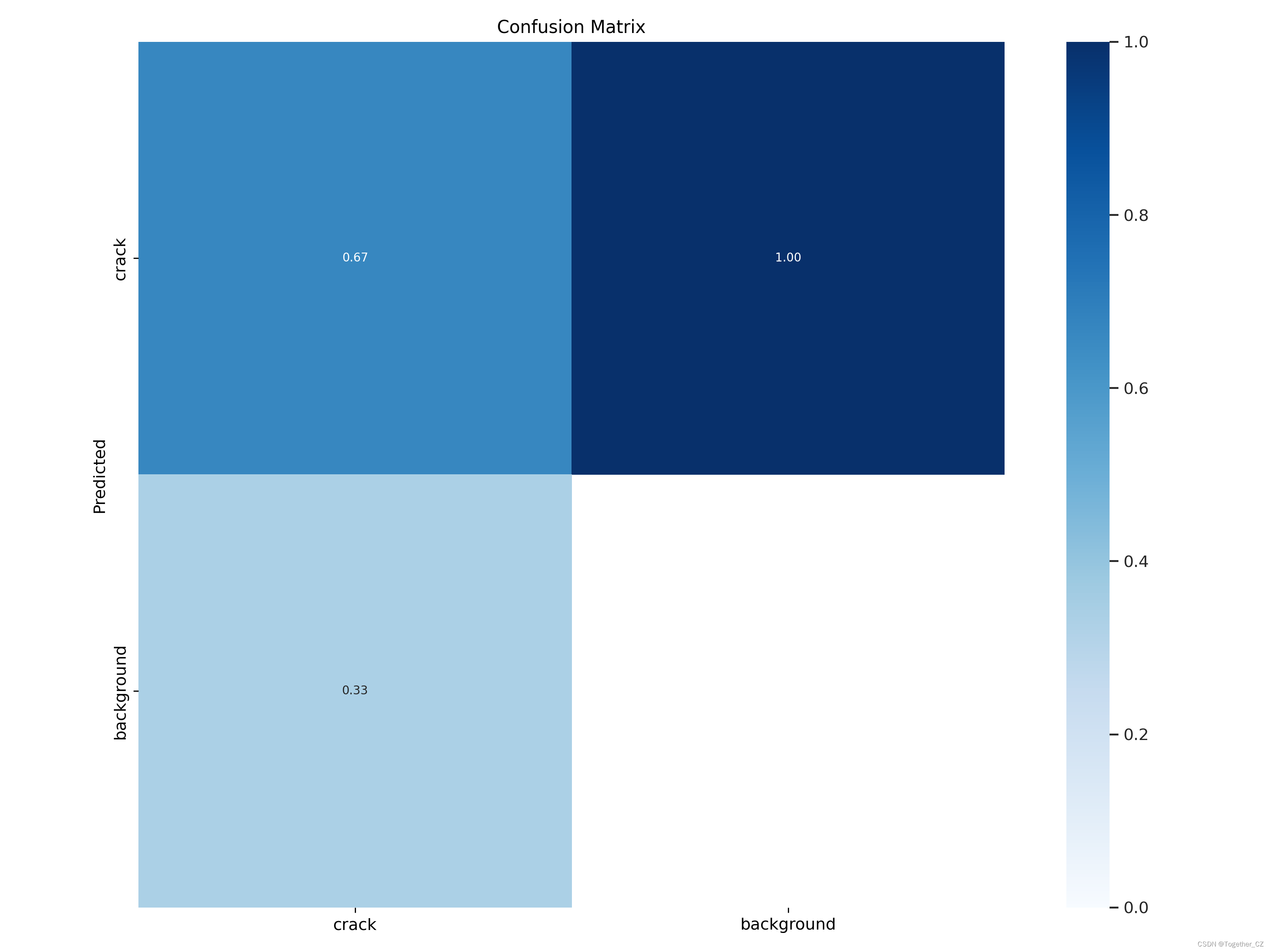
【混淆矩阵】
Predicted Class-----------------| Positive | Negative |
Actual Class |--------------|--------------|| True Pos | False Neg ||--------------|--------------|| False Pos | True Neg |-----------------其中,行表示实际的类别,列表示模型预测的类别。混淆矩阵的每个元素表示在预测过程中,模型正确或错误地将样本分为四个不同的类别:
- True Positive(真正例):模型将正例预测为正例。
- False Negative(假反例):模型将正例预测为反例。
- False Positive(假正例):模型将反例预测为正例。
- True Negative(真反例):模型将反例预测为反例。
基于混淆矩阵,我们可以计算出一些分类模型的评估指标,包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)和 F1 分数(F1-Score)等。
- 准确率(Accuracy):表示模型正确预测的样本数占总样本数的比例,计算公式为 (TP + TN) / (TP + TN + FP + FN)。
- 精确率(Precision):表示模型在预测为正例中的正确率,计算公式为 TP / (TP + FP)。
- 召回率(Recall):表示模型正确预测为正例的样本数占实际正例样本数的比例,计算公式为 TP / (TP + FN)。
- F1 分数(F1-Score):综合考虑了精确率和召回率,计算公式为 2 * (Precision * Recall) / (Precision + Recall)。
混淆矩阵及其相关的评估指标可以帮助我们了解模型在不同类别上的性能表现,从而进行模型的优化和改进。
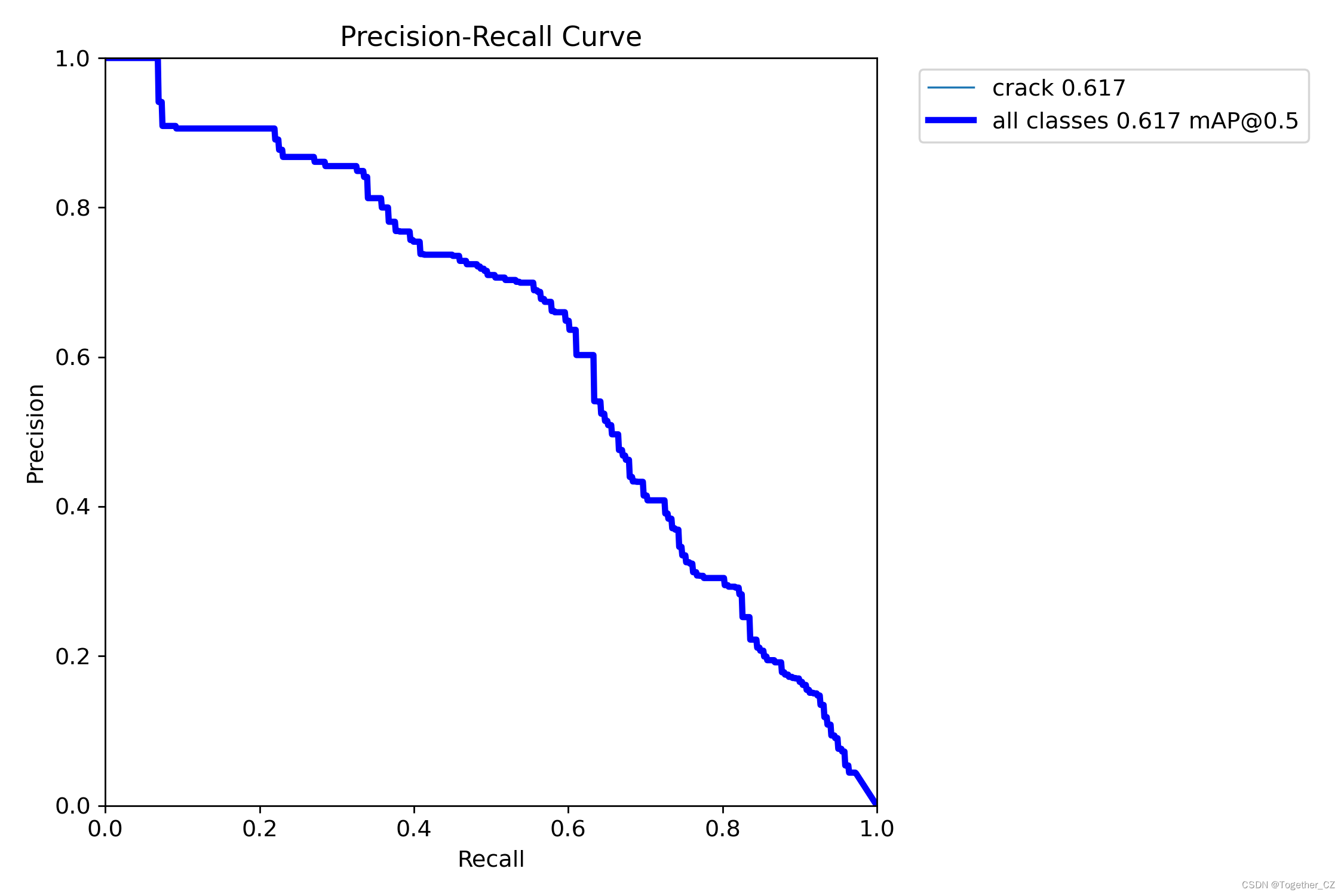
【PR曲线】
精确率-召回率曲线(Precision-Recall Curve)是一种用于评估二分类模型性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)和召回率(Recall)之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
绘制精确率-召回率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率和召回率。
将每个阈值下的精确率和召回率绘制在同一个图表上,形成精确率-召回率曲线。
根据曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
精确率-召回率曲线提供了更全面的模型性能分析,特别适用于处理不平衡数据集和关注正例预测的场景。曲线下面积(Area Under the Curve, AUC)可以作为评估模型性能的指标,AUC值越高表示模型的性能越好。
通过观察精确率-召回率曲线,我们可以根据需求选择合适的阈值来权衡精确率和召回率之间的平衡点。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
【Batch计算实例】


感兴趣的话也都可以自己动手实践下!
相关文章:
助力水泥基建裂痕自动化巡检,基于yolov5融合ASPP开发构建多尺度融合目标检测识别系统
道路场景下的自动化智能巡检、洞体场景下的壁体类建筑缺陷自动检测识别等等已经在现实生活中不断地落地应用了,在我们之前的很多博文中也已经有过很多相关的实践项目经历了,本文的核心目的是想要融合多尺度感受野技术到yolov5模型中以期在较低参数量的情…...

rk3588使用vscode远程debug 配置文件
进入调试口,需要本地和远程都装C/C estension 下面是在调mpi_enc_test的launch.json 文件自己make生成的 makefile 没改过 args项是输入参数,配置了相机输入,具体参数看他的demo说明, 记录一下,方便以后拷贝方便 {// …...
隐私协议 Secret Network 宣布使用 Octopus Network 构建的 NEAR-IBC 连接 NEAR 生态
2023年11月 NearCon2023 活动期间,基于 Cosmos SDK 构建的隐私协议 Secret Network,宣布使用 Octopus Network 开发的 NEAR-IBC,于2024年第一季度实现 Secret Network 与 NEAR Protocol 之间的跨链交互。 这将会是Cosmos 生态与 NEAR 之间的首…...
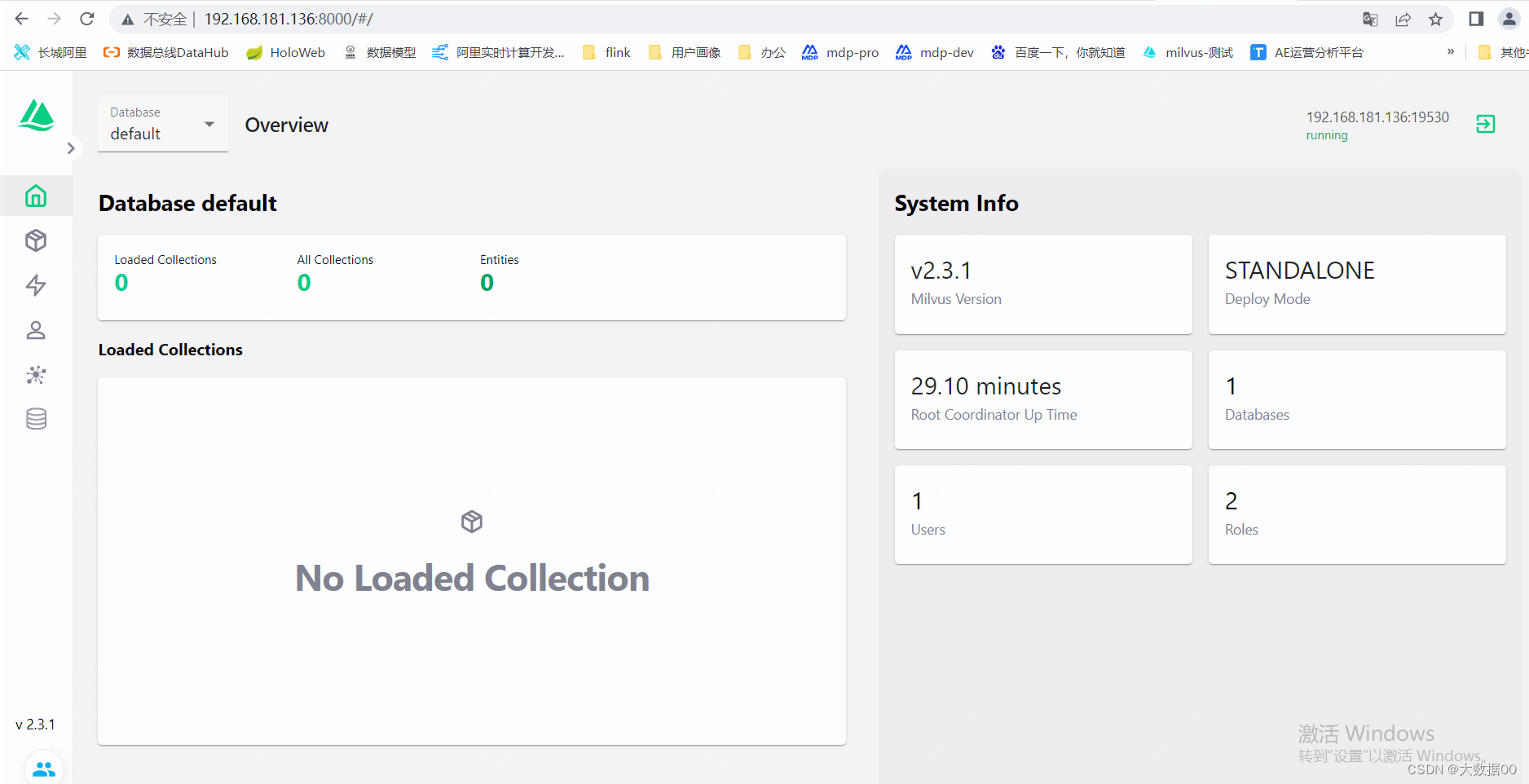
Milvus Standalone安装
使用Docker Compose安装 Milvus standalone(即单机版),进行一个快速milvus的体验。 前提条件: 1.系统可以使用centos 2.系统已经安装docker和docker-compose 3.milvus版本这里选择2.3.1 由于milvus依赖etcd和minio,…...

二分查找算法合集
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。 时间复杂度 O(logn) 自己写二分算法 左闭右开 左开右闭C算法&a…...
)
SELinux零知识学习十八、SELinux策略语言之类型强制(3)
接前一篇文章:SELinux零知识学习十七、SELinux策略语言之类型强制(2) 二、SELinux策略语言之类型强制 2. 类型、属性和别名 (3)关联类型和属性 1)使用type语句关联类型和属性 迄今为止,我们…...

人工智能引领环境保护的新浪潮:技术应用及其影响
在全球范围内,环境保护已经成为一个迫切的话题。随着人工智能技术的发展,它开始在环境保护领域扮演越来越重要的角色。AI不仅能够帮助更有效地监测环境变化,还能提出解决方案来应对环境问题。 污染监测与控制: AI系统可以分析来自…...

第三十四节——组合式API使用路由
<template> <div><div>我是第一个页面</div><button click"link2">跳转到第二个页面</button></div> </template> <script setup>// 从vue-router引入 useRouter这个钩子import { useRouter } from vue-route…...
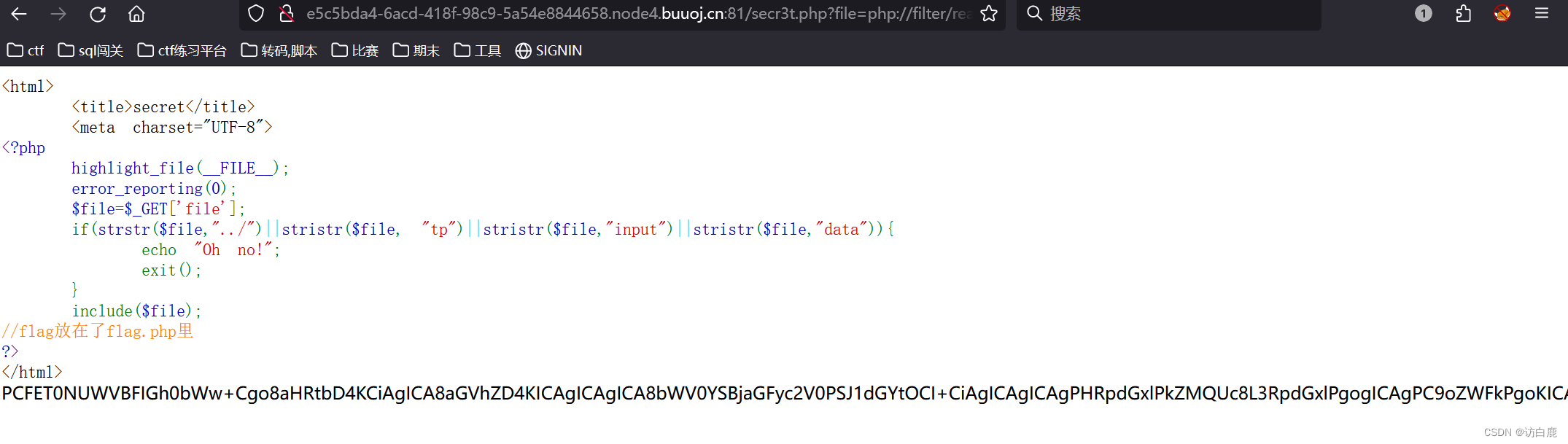
文件隐藏 [极客大挑战 2019]Secret File1
打开题目 查看源代码发现有一个可疑的php 访问一下看看 点一下secret 得到如下页面 响应时间太短我们根本看不清什么东西,那我们尝试bp抓包一下看看 提示有个secr3t.php 访问一下 得到 我们看见了flag.php 访问一下可是什么都没有 那我们就进行代码审计 $file$_…...
)
Linux CentOS 8(MariaDB的数据类型)
Linux CentOS 8(MariaDB的数据类型) 目录 一、项目描述二、相关知识三、项目分析3.1 数据类型的分类3.2 数据类型属性 一、项目描述 Jan16公司为满足部门之间数据共享、减少数据冗余度和保持数据独立性等要求,需要对数据库中的数据类型拥有一…...

云端援手:智能枢纽应对数字资产挑战 ——华为云11.11应用集成管理与创新专区优惠限时购
现新客3.96元起,下单有机会抽HUAWEI P60 Art 福利仅限双十一 机会唾手可得,立即行动! 「有效管理保护应用与数据的同时实现高效互通」——华为云全力满足企业需求,推出全套「应用集成管理与创新」智能解决方案:华为云…...

Azure的AI使用-(语言检测、图像分析、图像文本识别)
1.语言检测 安装包: # 语言检测 %pip install azure-ai-textanalytics5.2.0 需要用到密钥和资源的终结点,所以去Azure上创建资源,我这个是创建好的了然后点击密钥和终结者去拿到key和终结点 两个密钥选择哪个都行 语言检测代码示例&#…...

QDateEdit开发详解
文章目录 一、创建 `QDateEdit` 对象二、设置日期范围三、设置当前日期四、获取选择的日期五、显示日历弹出窗口六、信号与槽七、格式化日期显示1. `QDateTime` 类2. 日期时间格式化字符串3. 自定义格式化字符串4. 本地化日期格式5. `QDate` 和 `QTime` 的格式化6. 时间戳转日期…...
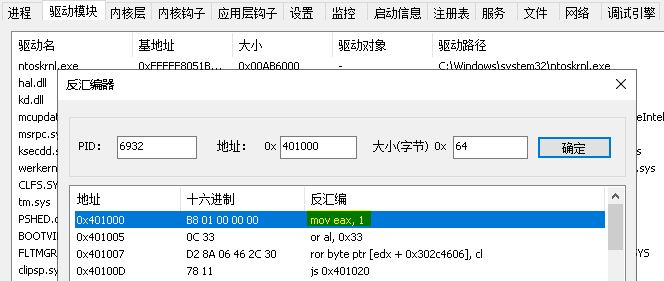
3.6 Windows驱动开发:内核进程汇编与反汇编
在笔者上一篇文章《内核MDL读写进程内存》简单介绍了如何通过MDL映射的方式实现进程读写操作,本章将通过如上案例实现远程进程反汇编功能,此类功能也是ARK工具中最常见的功能之一,通常此类功能的实现分为两部分,内核部分只负责读写…...

zsh和ohmyzsh安装指南+插件推荐
文章目录 1. 安装指南2. 插件配置指南3. 参考信息 1. 安装指南 1. 安装 zsh sudo apt install zsh2. 安装 Oh My Zsh 国内访问GitHub sh -c "$(curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"这将安装 Oh My Zsh 和所…...

VS中修改解决方案名称和项目名称
如何修改visual studio2019中的项目名 - 知乎 (zhihu.com) 查了很多,还是这个可行。虽然文中说不是最简单的,但在所查找资料中是可行且最简单的。 要点主要是: 1、比如我们复制一个解决方案,最好是带代码哈,也就是添…...

iOS UITableView获取到的contentSize不正确
在开发中遇到一个需求,就是将一个tableView的contentsize设置成该 tableView的frame的size,但是 经过调试,发现获取到的contentsize不争确,后来发现是 没有设置一个属性 if (available(iOS 15.0, *)) {_tableView.sectionHeaderTopPadding …...
C++二分查找算法:查找和最小的 K 对数字
相关专题 二分查找相关题目 题目 给定两个以 非递减顺序排列 的整数数组 nums1 和 nums2 , 以及一个整数 k 。 定义一对值 (u,v),其中第一个元素来自 nums1,第二个元素来自 nums2 。 请找到和最小的 k 个数对 (u1,v1), (u2,v2) … (uk,vk) 。 示例 1:…...
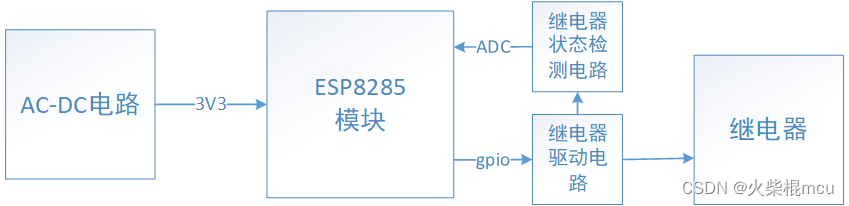
开源WIFI继电器之方案介绍
一、实物 1、外观 2、电路板 二、功能说明 输出一路继电器常开信号,最大负载电流10A输入一路开关量检测联网方式2.4G Wi-Fi通信协议MQTT配网方式AIrkiss,SmartConfig设备管理本地Web后台管理,可配置MQTT参数供电AC220V其它一个功能按键&…...
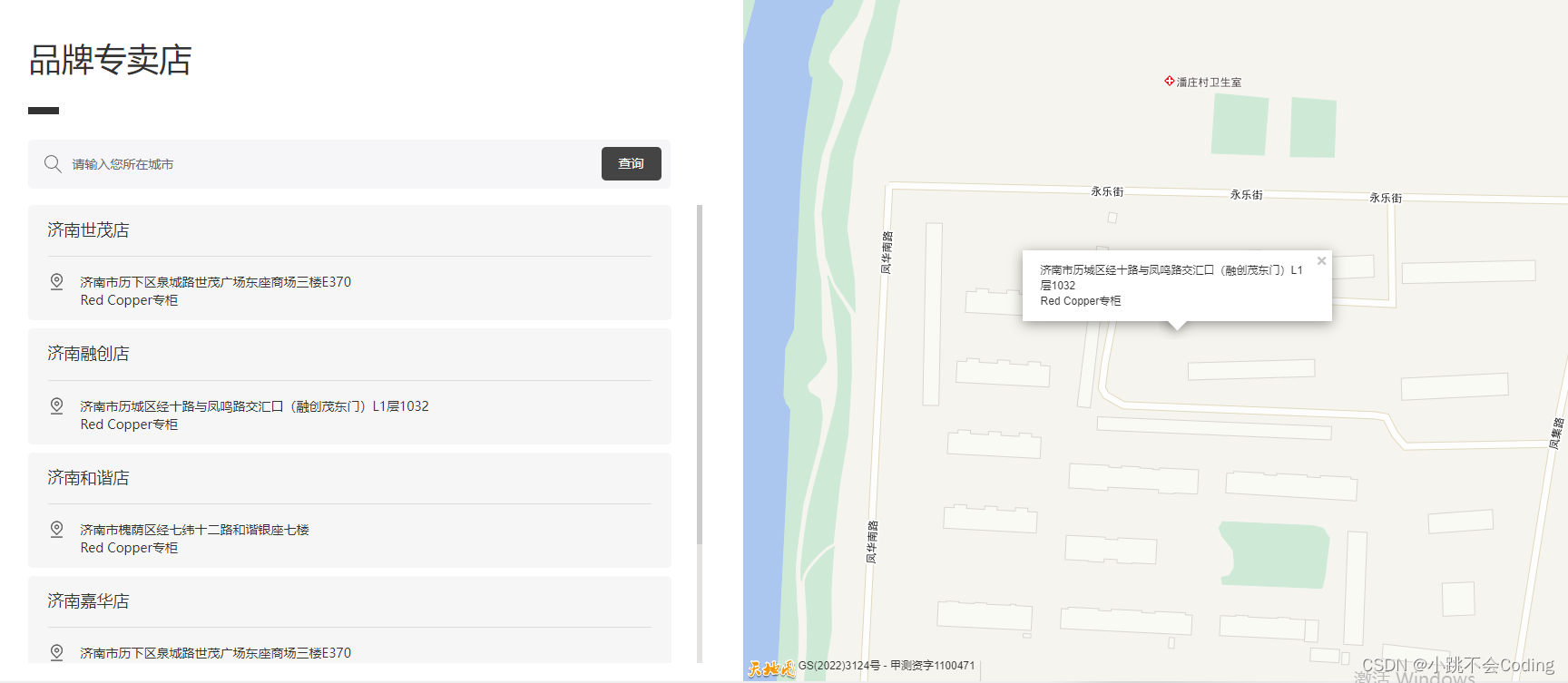
html使用天地图写一个地图列表
一、效果图: 点击左侧地址列表,右侧地图跟着改变。 二、代码实现: 一进入页面时,通过body调用onLoad"onLoad()"函数,确保地图正常显示。 <body onLoad"onLoad()"><!--左侧代码-->…...

第70篇:Vibe Coding时代:AI Coding 平台运维手册,解决 Agent 上线后故障排查没有 SOP 的问题
第70篇:Vibe Coding时代:AI Coding 平台运维手册,解决 Agent 上线后故障排查没有 SOP 的问题 一、问题场景:Agent 平台上线了,但一出问题大家都不知道怎么查 当 AI Coding Agent 进入团队使用后,常见故障会越来越多: 1. 用户说任务一直不动 2. 任务状态卡在 RUNNING 3…...

JDspyder终极指南:如何用Python自动化脚本实现京东茅台抢购
JDspyder终极指南:如何用Python自动化脚本实现京东茅台抢购 【免费下载链接】JDspyder 京东预约&抢购脚本,可以自定义商品链接 项目地址: https://gitcode.com/gh_mirrors/jd/JDspyder 在电商促销和限量商品抢购的激烈竞争中,手动…...

2026年中小企业性能测试平台:低成本易落地选型指南
中小企业在性能测试方面面临痛点:专业测试人员匮乏、预算有限、IT 架构相对简单、测试需求集中在基础接口与核心业务场景,无需复杂的企业级管控与大规模并发压测能力。因此,中小企业对性能测试平台的核心需求是:低成本、易落地、易…...
实战教程)
146.轻量化部署口罩检测!YOLOv8 模型导出(ONNX/TensorRT)实战教程
摘要 YOLO(You Only Look Once)作为目标检测领域里程碑式的算法,以其端到端、单阶段、高实时性的特点,成为工业界最广泛应用的检测框架。本文从YOLO的进化脉络出发,深入剖析其核心原理,包括网格划分、边界框回归、损失函数设计与非极大值抑制。通过一个完整的可运行案例…...

AwaDB:纯Python实现的轻量级本地向量数据库实践指南
1. 项目概述:当向量数据库遇上本地化与轻量化最近在折腾一些AI应用的原型,特别是RAG(检索增强生成)和智能问答系统,发现向量数据库的选择是个绕不开的话题。市面上有Pinecone、Weaviate这样的云服务,也有Mi…...

代码托管工具在GEO工具中表现分析
随着生成式引擎优化(GEO)在技术选型决策中的影响持续扩大,AI搜索工具对代码托管、DevOps及制品管理工具的推荐结果,正在成为企业评估平台价值的重要参考。2026年,不同规模和需求的团队在借助AI搜索获取工具推荐时&…...

长沙化妆培训哪家专业
在长沙学化妆,很多人都会问:“哪家更靠谱?”其实,选培训机构,关键不是看广告打得多响,而是看它能不能真正帮你学到能上手、能就业的本事。今天想跟你聊聊一个在本地口碑不错的机构——尚美新时代美业培训&a…...

PostgreSQL17高级特性实战
PostgreSQL 17 高级特性实战:JSON 增强、增量备份与逻辑复制深度指南 🐘 PostgreSQL 17 是 2024 年最重要的数据库版本更新之一——JSON 能力大幅增强、备份恢复效率翻倍、逻辑复制全面升级。本文带你深入每个新特性的实战用法。 📌 前言 PostgreSQL 一直是「最先进」的开…...

3PEAK思瑞浦 TPA1731-S5TR SOT23-5 运算放大器
特性 供电电压:4.5伏至36伏 偏移电压:最大士75伏 差分输入电压范围至电源轨,可作为比较器工 作 轨到轨输入和输出 带宽:3MHz 斜率:4V/us 低噪声:21nV/vHz(1kHz时) 高电容负载驱动能力:10nF 工作温度范围:-40C至125C...

086、Python数据压缩与归档:zipfile与tarfile实战笔记
086、Python数据压缩与归档:zipfile与tarfile实战笔记 一、从线上故障说起 上周排查一个生产环境问题:某服务每天生成的日志文件把磁盘撑满了。 查看代码发现,开发同事用 open().write() 直接写文本,一年下来积累了上千个文件。 其实这类场景最适合用压缩归档——既节省空…...