Python技术栈 —— 语言基础
Python基础
- 语法拾遗
- List与Tuple的区别
- yield关键字
- for in enumerate
- for in zip
- 精彩片段
- 测量程序用时
语法拾遗
List与Tuple的区别
| List | Tuple | |
|---|---|---|
| 建立后是否可变 | 可变 | 不可变 |
| 建立后是否可添加元素 | 可添加 | 不可添加 |
# list and tuple
List = [1, 2, 3, 4, 5]
Tuple = (1, 2, 3, 4, 5)
print(List)
print(Tuple)def change_element():"""# diff1list中元素,建立后可改变tuple中元素,建立后不可改变"""print("【1.change element】")List[0] = 0# Tuple[0] = 0 # errorprint(List)print(Tuple)def add_element():"""# diff2list可添加元素tuple不可添加元素"""print("【2.add element】")List.append(6)print(List)print(Tuple)def resize():l2 = List + Listt2 = Tuple + Tupleprint(l2)print(t2)def nest():List[0] = [6, 8, 10]# Tuple[0] = (6,8,10) # errorprint(List)tuple = (1, 2, 3, 4, (5, 6, 7, 8))print(tuple)def in_and_notin():print("1 in", List, "is", 1 in List)print("1 in", Tuple, "is", 1 in Tuple)print("100 not in", List, "is", 100 not in List)print("100 not in", Tuple, "is", 100 not in Tuple)passdef is_and_equal():"""is, is not 比较的是两个变量的内存地址== 比较的是两个变量的值:return:"""x = "hello"y = "hello"print(x is y, x == y) # True,Trueprint(x is not y, x != y) # False,Falsea = ["hello"]b = ["hello"]print(a is b, a == b) # False Trueprint(a is not b, a != b) # True Falsec = ("hello")d = ("hello")print(c is d, c == d) # True,Trueprint(c is not d, c != d) # False,Falsedef complement_code(x):"""求一个数的补码https://tianchi.aliyun.com/notebook/169961方法来源,阿里天池:param x::return:"""if x >= 0:return bin(x)else:return bin(x & 0xffffffff)if __name__ == "__main__":# change_element()# add_element()# resize()# nest()# in_and_notin()# is_and_equal()# print(complement_code(-3))yield关键字
《Python中yield的使用》—— 设计学院:这篇文章说使代码逻辑更加清晰,易于理解和维护,可yield的缺点就是不好阅读和理解,不是西方人写的所有东西都是好的。
Python Yield - NBShare
def my_generator():yield 1yield 2yield 3g = my_generator()
print(next(g)) # 输出:1
print(next(g)) # 输出:2
print(next(g)) # 输出:3###############################
def my_generator():yield 1yield 2yield 3if __name__ == '__main__':for i in my_generator():print(i)
# 输出:
# 1
# 2
# 3
###############################
#惰性计算指的是在需要的时候才计算数据,而不是一次性计算所有的数据。通过yield,我们可以将计算分成多个阶段,每次只计算一部分数据,从而减少了计算的时间和内存消耗。
def fib():a, b = 0, 1while True:yield aa, b = b, a + bf = fib()
print(next(f)) # 输出:0
print(next(f)) # 输出:1
print(next(f)) # 输出:1
print(next(f)) # 输出:2
###############################
#协程是一种在单线程中实现多任务的技术,可以实现任务之间的切换和并发执行。
#yield可以用来实现协程,通过yield可以在函数执行过程中暂停,并切换到其他任务。这种方式可以大幅度提高程序的并发性和响应性。
#通过yield语句实现了程序的暂停和切换。使用send()方法可以向协程中传递数据,并在需要的时候继续执行程序。
def coroutine():while True:value = yieldprint(value)c = coroutine()
next(c)
c.send("Hello") # 输出:Hello
c.send("World") # 输出:World
我是这么理解的,yield相当于把断点调试写成了一个语法特性,每调用一次这个关键字生成的generator就生成下一个结果。我发现,国内网站UI颜值普遍低,还是说国内的技术栈,像我海军某少校参观俄罗斯舰艇所感一样,“感受到了厚重的历史”。
for in enumerate
《用法介绍for in enumerate》—— 设计学院
######## 1.基本用法
animals = ['cat', 'dog', 'fish']
for idx, animal in enumerate(animals):print('Index:', idx, 'Animal:', animal)# Index: 0 Animal: cat
# Index: 1 Animal: dog
# Index: 2 Animal: fish######## 2.指定遍历的起始索引值
fruits = ['apple', 'banana', 'melon']
for idx, fruit in enumerate(fruits, start=1):print('Index:', idx, 'Fruit:', fruit)# Index: 1 Fruit: apple
# Index: 2 Fruit: banana
# Index: 3 Fruit: melon######## 3.使用for in enumerate遍历字典时,会输出字典中每个键值对的索引值和key,而非value。
fruits = {'apple': 1, 'banana': 2, 'melon': 3}
for idx, fruit in enumerate(fruits):print('Index:', idx, 'Fruit:', fruit)# Index: 0 Fruit: apple
# Index: 1 Fruit: banana
# Index: 2 Fruit: melon######## 4.遍历嵌套列表
neste_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
for i, lst in enumerate(neste_list):for j, element in enumerate(lst):print('i:', i, 'j:', j, 'element:', element)# i: 0 j: 0 element: 1
# i: 0 j: 1 element: 2
# i: 0 j: 2 element: 3
# i: 1 j: 0 element: 4
# i: 1 j: 1 element: 5
# i: 1 j: 2 element: 6
# i: 2 j: 0 element: 7
# i: 2 j: 1 element: 8
# i: 2 j: 2 element: 9######## 5.K-折交叉验证遍历
fold = KFold(5,shuffle=False)
y_train_data = pd.DataFrame([11,12,13,14,15, 16,17,18,19,20])
print(type(fold.split(y_train_data))) # generator, the yield feature are used in this function,用到了yield关键字.
print(fold.split(y_train_data))
# for iteration, indices in enumerate(fold.split(y_train_data), start = 0): # Try it
for iteration, indices in enumerate(fold.split(y_train_data), start = 1): # fold.split(): Generate 'indices' to split data into training and test set.print('iteration = ',iteration)print(indices[0])print(indices[1])# <class 'generator'>
# <generator object _BaseKFold.split at 0x7f31ba7479e8>
# iteration = 1
# [2 3 4 5 6 7 8 9]
# [0 1]
# iteration = 2
# [0 1 4 5 6 7 8 9]
# [2 3]
# iteration = 3
# [0 1 2 3 6 7 8 9]
# [4 5]
# iteration = 4
# [0 1 2 3 4 5 8 9]
# [6 7]
# iteration = 5
# [0 1 2 3 4 5 6 7]
# [8 9]
for in zip
《用法介绍for in zip》—— 设计学院
######## 1.基本用法
iter1 = [1, 2, 3]
iter2 = ['a', 'b', 'c']result = zip(iter1, iter2)
print(type(result))
for x, y in result:print(x, y)
# 输出结果:
# <class 'zip'>
# 1 a
# 2 b
# 3 c######## 2.合并列表并输出
list1 = [1, 2, 3]
list2 = ['a', 'b', 'c']result = list(zip(list1, list2))
print(result) # 输出结果:[(1, 'a'), (2, 'b'), (3, 'c')]######## 3.并行处理
import multiprocessingdef process_data(data):# 处理数据的函数print(type(data))print(data,end='')return 'THE RESULT'input_data1 = [1, 2, 3, 4, 5]
input_data2 = ['a', 'b', 'c', 'd', 'e']
pool = multiprocessing.Pool()# 这里的map(func, param),就是将param(可迭代即可)中的每个值,传入func进行并行计算,然后map函数本身的返回值,就是分别计算的结果,以list为形式返回。
ret_list = pool.map(process_data, zip(input_data1, input_data2)) # Apply `func` to each element in `iterable`, collecting the results in a list that is returned.
print(ret_list)# 由于是并行的,可能连续输出,换行不一定是规整的,这似乎证明了一件事,那就是print输出并非原子操作,中间是可以被插入其它运算的
#<class 'tuple'><class 'tuple'><class 'tuple'><class 'tuple'><class 'tuple'>
#(4, 'd')(1, 'a')
#(5, 'e')(3, 'c')(2, 'b')['THE RESULT', 'THE RESULT', 'THE RESULT', 'THE RESULT', 'THE RESULT']######## 4.将两个列表转换成字典
keys = ['a', 'b', 'c']
values = [1, 2, 3]result = dict(zip(keys, values))
print(result) # 输出结果:{'a': 1, 'b': 2, 'c': 3}
精彩片段
测量程序用时
import time
start = time.time()
# Your python code
end = time.time()
print('The time for the code executed:', end - start)
相关文章:

Python技术栈 —— 语言基础
Python基础 语法拾遗List与Tuple的区别yield关键字for in enumeratefor in zip 精彩片段测量程序用时 语法拾遗 List与Tuple的区别 ListTuple建立后是否可变可变不可变建立后是否可添加元素可添加不可添加 # list and tuple List [1, 2, 3, 4, 5] Tuple (1, 2, 3, 4, 5) p…...

redis cluster搭建
k8s部署 Redis Insight k8s部署redis集群_mob6454cc6c6291的技术博客_51CTO博客 占用的内存竟然这么小,才200M左右 随便选个节点进去,看能否连接上其他节点 redis-cli -h redis-cluster-v1-0.redis-cluster.project-gulimall.svc.cluster.local 再创建个…...

windows 11 本地运行ER-NeRF及pytorch3D安装
ER-NeRF本地运行只要梳理好依赖版本,运行起来就很顺畅 conda create -n ernerf python3.10 创建本项目虚拟环境conda install pytorch1.12.1 torchvision0.13.1 cudatoolkit11.3 -c pytorch 若windows有多个版本的cuda,需要在环境变量中切换至cuda 11.3&…...

mysql客户端navicat的一些错误合集
关于mysql的客户端的使用的一些问题 问题描述: 在使用navicat prenium客户端的时候,连接数据库出现 Table ‘performance_schema.session_variables’ doesn’t exist 错误 解决方案: 首先找到mysql的bin目录 然后winR 进入到cmd界面 输入…...
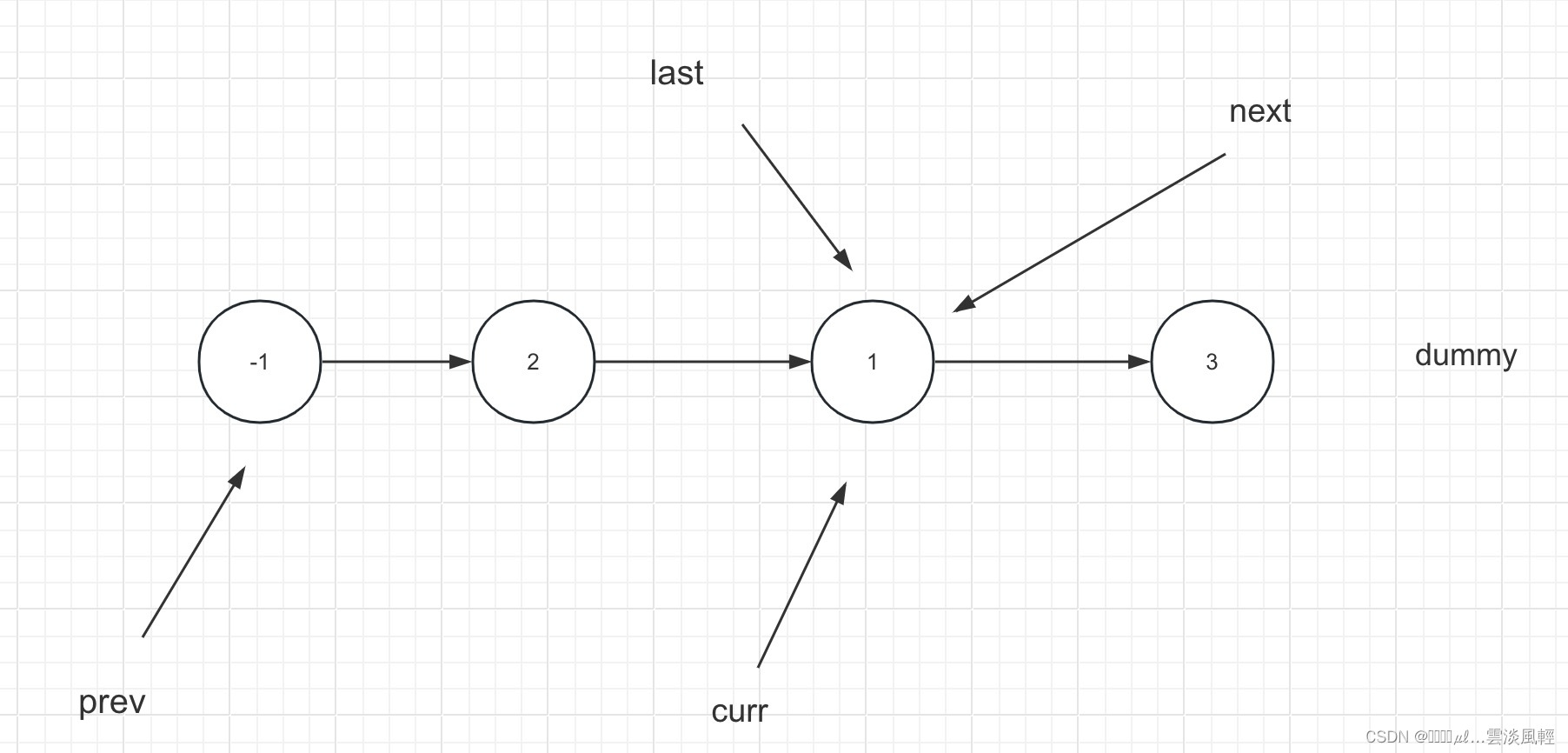
【力扣面试经典150题】(链表)K 个一组翻转链表
题目描述 力扣原文链接 给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。 k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。 你不能只…...
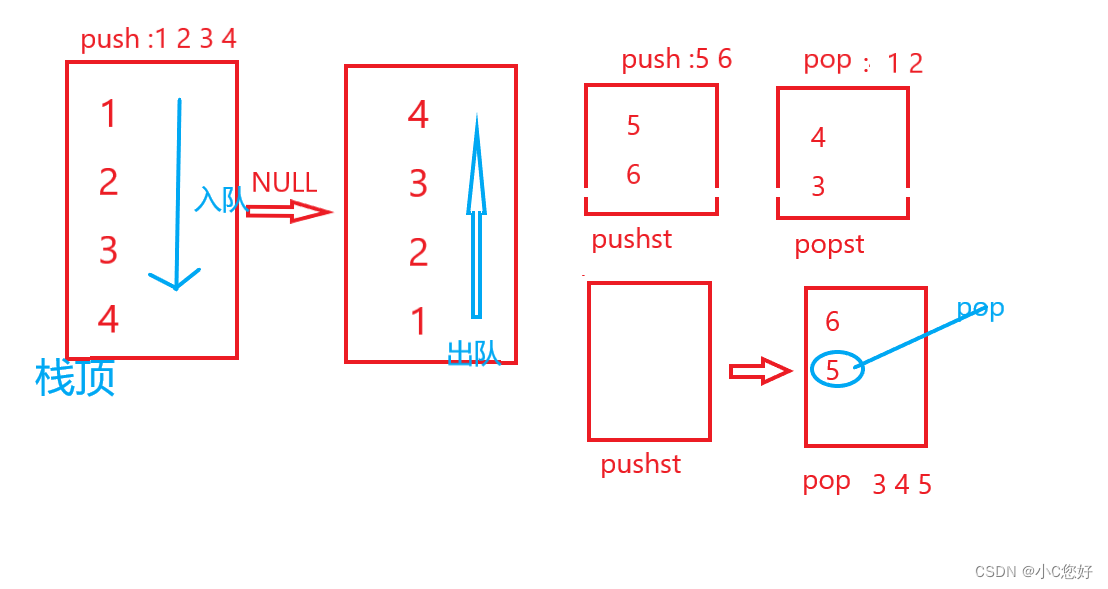
数据结构刷题
空间复杂度:临时开辟的空间、空间是可以重复利用的 递归为O(n) 时间复杂度:程序执行次数 消失的数字 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 思路1:利用连续的特点求等差和然后减去所有元素得到的就是消…...

【Android】设置全局标题栏
序言 在做项目的时候,有时候需要一个全局统一的标题栏,保证项目风格的统一,但是如果在每个activity上面都写一遍这个标题栏就很麻烦了,我们经常用的方法就是写个基类Activity,然后当某个Activity需要这个统一的标题栏…...

R语言的入门学习
目录 准备工作导入csv数据集选择前200行作为数据集展示数据集的前/后几N行宏观分析删除缺失值构建直方图导出为图片 R语言常见图像类型例1:散点图例2:散点矩阵图 准备工作 安装教程: R语言和RStudio的下载安装(非常简便舒适&…...

【开源】基于Vue和SpringBoot的民宿预定管理系统
项目编号: S 058 ,文末获取源码。 \color{red}{项目编号:S058,文末获取源码。} 项目编号:S058,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 用例设计2.2 功能设计2.2.1 租客角色…...

nacos集群部署
GitHub - nacos-group/nacos-k8s: This project contains a Nacos Docker image meant to facilitate the deployment of Nacos on Kubernetes using StatefulSets. 需要修改两个文件 --- apiVersion: v1 kind: Service metadata:name: nacos-headlessnamespace: project-guli…...

9、传统计算机视觉 —— 边缘检测
本节介绍一种利用传统计算机视觉方法来实现图片边缘检测的方法。 什么是边缘检测? 边缘检测是通过一些算法来识别图像中物体之间,或者物体与背景之间的边界,也就是边缘。 边缘通常是图像中灰度变化显著的地方,标志着不同区域的分界线。 在一张图像中,边缘可以是物体的…...
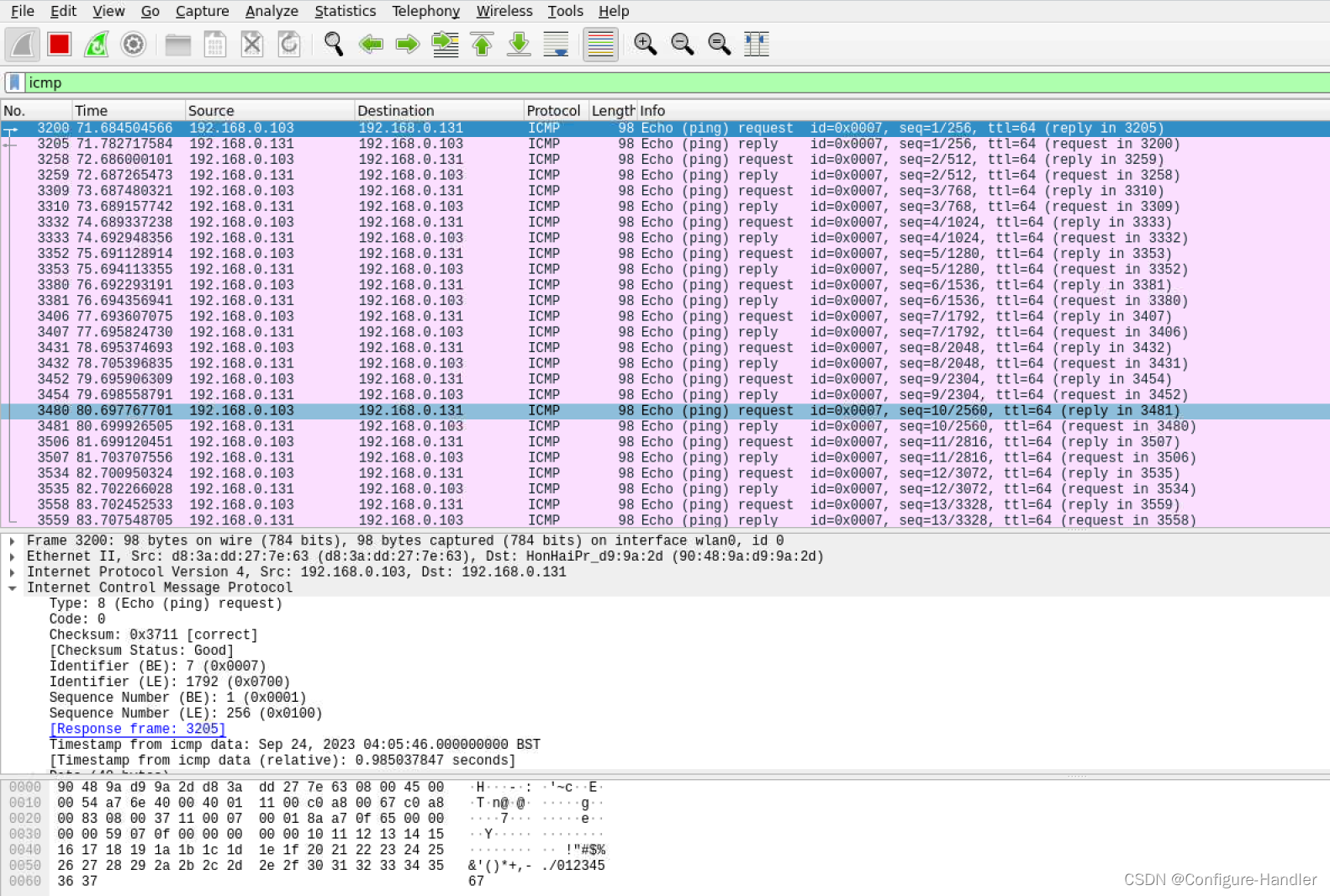
Linux tc 使用
tc模拟延时丢包等网络故障依赖的内核驱动 /lib/modules/5.15.0-52-generic/kernel/net/sched/sch_netem.ko有些系统并不是默认就安装上该驱动的,如果没有安装该驱动,构造网络故障时会报错。 root:curtis# tc qdisc change dev enp4s0 root netem delay…...

从0开始学习JavaScript--JavaScript 数字与日期
JavaScript中的数字和日期是处理数值计算和时间相关任务的核心。本文将深入研究JavaScript中数字的表示、常见运算,以及日期对象的创建、格式化等操作,并通过丰富的示例代码,可以更全面地了解和应用这些概念。 JavaScript数字基础 JavaScri…...

从关键新闻和最新技术看AI行业发展(2023.11.6-11.19第十期) |【WeThinkIn老实人报】
Rocky Ding 公众号:WeThinkIn 写在前面 【WeThinkIn老实人报】旨在整理&挖掘AI行业的关键新闻和最新技术,同时Rocky会对这些关键信息进行解读,力求让读者们能从容跟随AI科技潮流。也欢迎大家提出宝贵的优化建议,一起交流学习&…...
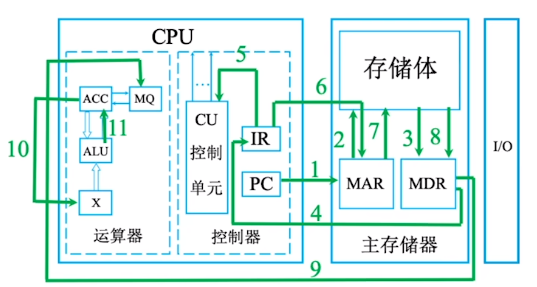
计算机硬件的基本组成
一、冯诺依曼结构 存储程序: “存储程序”的概念是指将指令以二进制代码的形式事先输入计算机的主存储器,然后按其在存储器中的首地址执行程序的第一条指令,以后就按该程序的规定顺序执行其他指令,直至程序执行结束。 冯诺依曼计…...

【算法-哈希表3】四数相加2 和 赎金信
今天,带来哈希表相关算法的讲解。文中不足错漏之处望请斧正! 理论基础点这里 1. 四数相加2 分析题意 求符合条件的四元组的出现次数,条件: nums1nums2nums3nums4 从四个数组中的每一个数组取一个数 num1, num2, num3, num4&am…...
wpf devexpress自定义编辑器
打开前一个例子 步骤1-自定义FirstName和LastName编辑器字段 如果运行程序,会通知编辑器是空。对于例子,这两个未命名编辑器在第一个LayoutItem(Name)。和最终用户有一个访客左右编辑器查阅到First Name和Last Name字段,分别。如果你看到Go…...
文档向量化工具(一):Apache Tika介绍
Apache Tika是什么?能干什么? Apache Tika是一个内容分析工具包。 该工具包可以从一千多种不同的文件类型(如PPT、XLS和PDF)中检测并提取元数据和文本。 所有这些文件类型都可以通过同一个接口进行解析,这使得Tika在…...

学习c#的第二十一天
目录 C# 泛型(Generic) 泛型类型参数 类型参数的约束 约束多个参数 未绑定的类型参数 类型参数作为约束 notnull 约束 class 约束 default 约束 非托管约束 委托约束 枚举约束 类型参数实现声明的接口 泛型类 泛型方法 泛型和数组 泛型…...

Michael Jordan最新报告:去中心化机器学习中的契约、不确定性和激励
导读 11月3日,智源研究院学术顾问委员会委员、机器学习泰斗Michael Jordan在以“新一代人工智能前沿”为主题的2023北京论坛 新工科专题论坛上,发表了题为Contracts, Uncertainty, and Incentives in Decentralized Machine Learning(去…...

Claude Code 之父:2026 年我一行代码都没写,编程已被 AI 解决
2026 年,你还在一行一行敲代码吗?Claude Code 的创造者、Anthropic 核心人物 Boris Cherny,在公开访谈里抛出一句让整个行业震动的话:2026 年到现在,我没有写过一行代码。所有开发工作,100% 交给 AI 代理完…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...

脉冲神经网络加速器设计与边缘计算优化
1. 脉冲神经网络加速器的设计挑战与突破在边缘计算领域,脉冲神经网络(SNN)正以其独特的生物启发特性引发新一轮技术变革。与传统人工神经网络(ANN)相比,SNN通过离散的脉冲信号传递信息,模拟生物神经元的工作机制,理论上可实现超低…...

OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案
OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥有一台性能尚可但已被…...

WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求?
WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求? 【免费下载链接】WMPFDebugger Yet another WeChat miniapp debugger on Windows 项目地址: https://gitcode.com/gh_mirrors/wm/WMPFDebugger 在Windows平台的微信小程序开发中&#…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...

观察Token消耗明细,Taotoken用量看板如何帮助控制预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Token消耗明细,Taotoken用量看板如何帮助控制预算 对于个人开发者或项目管理者而言,在使用大模型API时…...

京东自动购物终极指南:告别缺货烦恼,智能抢购神器
京东自动购物终极指南:告别缺货烦恼,智能抢购神器 【免费下载链接】Jd-Auto-Shopping 京东商品补货监控及自动下单 项目地址: https://gitcode.com/gh_mirrors/jd/Jd-Auto-Shopping 还在为心仪商品瞬间售罄而苦恼吗?还在熬夜等待补货却…...

从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法
从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法在MOBA游戏中,野怪沿着固定路线巡逻时突然转向追击玩家;RTS战场上,上百个单位向同一目标点移动却能保持整齐队形;潜行游戏中&…...

Visual C++运行库一键安装指南:彻底解决Windows应用依赖问题
Visual C运行库一键安装指南:彻底解决Windows应用依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过打开软件时弹出"缺少…...