“开源 vs. 闭源:大模型的未来发展趋势预测“——探讨大模型未来的发展方向
文章目录
- 每日一句正能量
- 前言
- 什么是大模型的开源与闭源
- 开源与闭源的定义和特点
- 开源的意义
- 开源和闭源的优劣势比较
- 不同的大模型企业,开源、闭源的策略不尽相同。
- 企业在开发垂类模型时选择开源还是闭源大模型
- 开源vs 闭源:两者并非选择题
- 后记
每日一句正能量
依赖别人的人等于折断了自己的翅膀,永远体会不到飞翔的快乐。
前言
在当今快速发展的技术和商业环境下,大模型在各个领域都有着广泛的应用。然而,开源和闭源两种不同的开发模式一直是业界争论的热点。本篇文章将探讨这两种模式对大模型未来发展的影响,以及其中的利弊和走向。
什么是大模型的开源与闭源
“开源”一词,起源于软件开发领域,其全称为“开放源代码”,在版权限制范围内,任何人都可以公开获取源代码,并进行修改甚至重新开发。与之相反,在闭源的情况下,只有源代码所有者掌握代码修改的权力,其他人只能向其购买软件。
在企业竞争中,开源和闭源是两种完全不同的竞争策略,如互联网时代下开源Linux和闭源Windows之争,移动互联网时代下开源Andriod和闭源iOS之争。
如今,人工智能大模型也出现了开源、闭源之争,大模型的开源和闭源主要是指模型的源代码和训练数据是否公开。大模型的闭源是指模型的源代码和训练数据不公开,只有模型所属企业企业才能使用和修改它们,如OpenAI的GPT-4。大模型的开源是指公开模型的源代码和训练数据,任何人都可以查看、使用。在实际应用中,很多企业选择部分开源,如Meta的LLaMA 2开放了源代码,但没有公开训练数据。
开源与闭源的定义和特点
-
开源软件是指源代码对公众开放,并且允许用户查看、使用、修改和分发的软件。它通常由一个社群或组织开发和维护,可以免费使用。开源软件在透明性、灵活性和社区参与度方面具有优势,因此能够迅速演进和改进。
-
闭源软件则是指源代码不对公众开放的软件,由公司或组织私下开发、销售和使用。闭源软件通常需要付费购买或订阅,并受到知识产权保护。闭源软件在商业化和技术支持方面具有优势,因为它们往往由专业团队负责开发和维护。
开源的意义
开源的意义在哪里?小米副总裁崔宝秋曾指出,开源的本质是协同和创新,协同是全世界所有人各方开源力量的协同,创新是一个技术的创新。
简单来说,开源大模型将能汇聚更多的技术创新力量,在这里,全球开发者、研究机构、科技企业将一同协同共建,大家一块让模型的数据更加丰富、模型更加优化、工具更加完善、应用更加全面…可以说是“众人拾柴火焰高”,从而加速大模型技术的迭代升级、应用的丰富发展,为大模型的发展方向打开更多的可能性,同时也惠及更多的人群。
此外,开源也就意味着个人开发者和中小型企业能够以最低的成本调用大模型,而不是花费高昂的成本采购闭源大模型,这也有利于开源大模型用户的吸纳与培养以及大模型开源生态的构建。
可以说,开源是吸纳、培养用户、确定行业标准的重要途经,也是避免当下AI大模型企业一轮又一轮重复造轮子、低成本试错的理想商业化手段。
开源和闭源的优劣势比较
-
开源的优势:由于开源软件的透明性和社区参与度,它在技术社群中得到了广泛的推崇和支持。开源软件能够快速迭代和改进,吸引了大量开发者和用户的参与,形成了强大的生态系统和产业链。此外,开源软件还可以降低成本,提高可定制性和可移植性。
-
闭源的优势:闭源软件通常由专业团队开发,具有较高的稳定性和性能。由于付费购买或订阅的原因,闭源软件通常提供更全面的技术支持和服务。此外,闭源软件还可以保护知识产权,防止源代码被恶意使用或篡改。
不同的大模型企业,开源、闭源的策略不尽相同。
第一,从开源走向闭源,最典型的即为OpenAI。2018年其发布的GPT-1完全对外开源;2019年发布GPT-2,分四次开源完整代码;2020年发布GPT-3,通过论文公开了技术细节,同时用户可通过调用API的方式使用模型资源,属于部分开源;2022年11月推出GPT-3.5,官方没有发布论文披露细节,2023年3月开放API;最近的GPT-4,目前也仅处于开放API状态,技术细节不得而知。
第二,坚持开源,最典型的即为Meta。2023年3月,Meta发布开源大模型LLaMA,可免费用于研究,研究人员向Meta提出申请和审核后即可使用;2023年7月,Meta发布LLaMA 2,公开了技术论文和源代码,可免费用于研究和商业。
第三,坚持闭源,最典型的即为华为。在发布盘古大模型3.0时,华为云公开表示,盘古大模型全栈技术均是由华为自主创新的,没有采用任何开源技术,盘古大模型在未来也不会开源。
第四,从闭源走向开源、闭源并行,最典型的即为智谱。根据智谱AI的官网,GLM2不限实例+不限推理或微调工具包的私有化报价此前是一年30万。2023年7月,智谱AI和清华KEG发布公告,称为了更好地支持国产大模型开源生态,ChatGLM-6B和ChatGLM2-6B权重对学术研究完全开放,并且在完成企业登记获得授权后,允许免费商业使用。同时,ChatGLM2-12B、ChatGLM2-32B、ChatGLM2-66B、ChatGLM2-130B 等模型仍为闭源。
从我国大模型来看,超半数已开源。根据《中国人工智能大模型地图研究报告》,截至2023年5月28日,我国大模型数量已达79个,超半数已开源,如清华大学的ChatGLM-6B、复旦大学的MOSS。
部分国内外大模型企业的开源、闭源情况如下图所示。

表1 部分国内外大模型企业的开源、闭源情况
企业在开发垂类模型时选择开源还是闭源大模型
任何一家企业如果自己从零开发大模型,对算力、数据的要求极高,研发投入很大。根据Meta发布的数据,参数量最大的LLaMA-65B模型,使用2048块A100-80GB的GPU,训练数据量1.4万亿tokens,耗时为21天;如果采取租用云计算方式来训练算法,按照Microsoft Azure以1.36美元/小时提供A100租用价计算,训练成本约140万美元。
因此,企业一般会选择基于已有大模型来开发针对某一垂直领域或垂直场景的垂类模型。这类模型通常基于通用大模型底座,用垂类数据进行训练,进行模型微调后形成。

图1 从通用模型到垂类模型 资料来源:北京大学人工智能研究院公众号
那么在这一过程中,模型底座选择开源大模型还是闭源大模型?通过访谈调研,我们发现大部分企业一般从以下几个维度综合考虑:使用成本、场景容错率、技术能力、客户响应、数据安全等。
- 使用成本:闭源大模型提供明确报价,开源大模型二次开发成本自主把控
在选择大模型时,企业需要根据自己的财务预算,结合闭源大模型和开源大模型的使用成本进行综合考虑。
一般来说,闭源大模型有直接的报价体系。如果直接调用大模型一般会衡量千token的费用,比如ChatGPT API接入的模型——GPT 3.5-turbo收费标准是0.002美元/1K tokens。1个token大约等于4个英文字符,大约等于3/4个单词,假定每天需要处理1000个小文本块,每个文本块对应一页文本(500个单词,约667个token),日均成本约为1.3美元。但如果每天需要处理上百万份这类文档,日均约1300美元,每年约50万美元。而中文要用的token数是英文数量的1.2到2.7倍。随着垂类企业用户量的攀升,这会成为一笔不小的费用。
也有一些闭源大模型也提供私有化服务,如智谱提供云端私有化服务,ChatGLM-12B、ChatGLM-32B、ChatGLM-66B、ChatGLM-130B的报价分别为25万元/年、50万元/年、100万元/年、120万元/年。同时,智谱也提供本地私有化服务,ChatGLM-12B、ChatGLM-32B、ChatGLM-66B、ChatGLM-130B的报价分别为180万元/年、680万元/年、1680万元/年、3960万元/年。
而对于开源大模型,企业主要需要考虑的则是二次开发成本,主要表现在迁移学习和微调的成本。对于迁移学习,以基于LLaMA-65B进行二次开发、训练拥有100亿tokens的行业数据的垂直大模型为例,如果采用租用云计算的方式,训练算力费用为:100/14000*140=1万美元。如果采用自有算力,前期算力集群初始投入费用会比较高(NVIDIA DGX A100每台售价约20万美元),但此时单大模型的成本仅包含平摊的硬件成本和能耗这两部分费用,训练成本可大幅降低。对于微调,斯坦福大学发布的模型Alpaca,是基于LLaMA-7B底座,使用5.2万指令,8块80GB的A100微调,耗时仅3小时,总成本还不到600美元,由于性能接近GPT-3.5,有“平替版GPT-3.5”之称。
就目前而言,尚不能笼统定义开源、闭源的成本一定孰高孰低,不同企业的需求不同,所需成本也就不同。因此,对于企业来说,更重要的是根据预算标准和使用场景等诸多因素综合选择性价比较高的模型。
- 场景容错率:与闭源大模型相比,开源大模型更适合容错率更高的场景
现有的开源、闭源模型中,闭源模型的准确度均高于开源模型。如果企业垂类模型的应用场景容错率低、对大模型准确性要求较高,那么选择闭源大模型是更好的选择,反之可以选择开源大模型。
目前大模型技术最顶尖的即为OpenAI闭源的GPT-4,其率先解决了模型架构设计、调参方式及多模态的探索。Meta将Llama 2-70B 的结果,与GPT进行了比较,结果在MMLU和GSM8K上接近GPT-3.5,但在编码基准上,还存在显著差距,不少数据在多样性和质量方面有所欠缺。同时,Meta 在其研究论文中承认,LLaMA 2 和 GPT-4 之间在性能上仍有很大差距。由斯坦福大学计算机系研究团队发表的《Holistic Evaluation of Language Models》论文中,作者对国外30个主流语言模型在准确率、鲁棒性、公平性、推理等主要指标进行评测后发现,开源模型在大多数指标上表现弱于闭源或部分开源的模型,如下图所示。

多数非开源模型准确率高于已完全开源模型 资料来源:《Holistic Evaluation of Language Models》
开源大模型虽然性能没有达到顶尖水平,但对于很多容错率较高的场景,也可以满足企业开发垂类模型的需求。开源大模型LLaMA 2-70B在MMLU(大模型评测数据集之一)和GSM8K(大模型评测数据集之一)上接近 GPT-3.5。正如美国斯坦福大学基金会模型研究中心主任 Percy Liang表示:“LLaMA 2不是GPT-4,但对于许多应用场景来说,你不需要GPT-4。相较于一个庞大、复杂的专有模型,一个更可定制、更透明的模型比如LLaMA 2,可能会帮助公司更快地创造产品和服务。”
- 技术能力:与闭源大模型相比,部署开源大模型对企业技术能力要求高
闭源大模型具有完整的工具链和工具平台,企业可以直接调用其接口,同时能够获得大模型企业及时的、高效的技术支持,例如,智谱为垂类企业提供了PLM、GLM等多个预训练大模型,同时能够提供模型微调、数据处理、模型训练、模型部署、模型推理等工具包,以及技术咨询服务等,因此对企业技术能力要求相对较低。
基于开源大模型,企业往往需要进行二次开发,对机器学习、自然语言处理、数据科学等方面的专业能力要求高。现在,一些大模型第三方服务商的出现一定程度上降低了企业对开源大模型的部署难度。如阿里云在国内推出针对Llama2全系列版本的训练和部署方案,便于开发者进行再训练,搭建专属大模型,并支持开发者在云上进行模型微调,通过Web UI及API的方式部署Llama2。
因此,企业在选择大模型时,应综合考虑自身技术能力水平和开发垂类模型的具体需求,选择与自身能力水平更适配的模型。
- 客户响应:与闭源大模型相比,开源大模型能够减小客户响应时间
与闭源大模型相比,基于开源大模型开发垂类模型能够有效减小客户响应时间。
大模型主要涉及两类延迟,一个是计算延迟,指模型处理输入和生成输出所需的时间;一个是网络延迟,指远程托管下数据传输所需的时间。如果垂类企业想要提升客户体验,对客户实时响应,这两类延迟越小越好。
如果用闭源大模型,企业无法控制延迟,模型提供者倾向于选择批处理请求,可能导致高延迟,还可能遇到违反速率限制导致的API延迟和中断。如果用开源大模型,企业可以通过优化模型来降低计算延迟,还可以改变批处理请求的设置以降低网络延迟,从而减小客户响应时间。此外,基于开源大模型,企业还可以构建参数更少的小模型,在保证模型准确率的情况下,提升客户响应速度。
- 数据安全:与闭源大模型相比,开源大模型可更好保护数据隐私
一些闭源大模型无法进行私有化部署,客户数据都会流经大模型企业的服务器,可能引发数据泄漏风险。例如ChatGPT产生的所有数据都会流经OpenAI和微软的公共服务器,据韩国媒体《economist》报道,三星引入聊天机器人ChatGPT不到20天,发生三起涉及ChatGPT误用与滥用案例,包括两起“设备信息泄露”和一起“会议内容泄露”。报道称,半导体设备测量资料、产品良率等内容或已被存入ChatGPT学习资料库中。
开源大模型可被垂类企业进行私有化部署,能够更好地保护数据隐私。数据成为生产要素之后,数据资产成为企业生产、经营、管理的命脉。开源大模型初创企业Huging Face表示,有大量客户希望把自己的私有数据或专业数据用来训模型,并不想把这些数据给到 OpenAI。开源大模型允许企业定制化开发、私有化部署、定向训练数据,不禁止用户修改模型后闭源,能够有效保护企业的数据隐私。如果企业在数据安全方面有较高需求,且自身数据安全保护做得相对较好,开源大模型不失为一种更好的选择。
开源vs 闭源:两者并非选择题
开源大模型出现后,随之而来的便是一道选择题:模型的底座选择到底是开源还是闭源?
尽管开源“免费的饭很香”,但也并非不存在问题,或者说,在很多层面,闭源大模型仍保持着领先优势。
一方面,在模型质量上,闭源大模型的质量更高,比如说最前沿的GPT-4便是闭源大模型,正如前文所言,哪怕是当下可以说是最强势的Llama-2 还与GPT-3.5存在显著差距。
数据显示,在学术界广为引用的、由斯坦福大学计算机系研究团队发表的《Holistic Evaluation of Language Models》论文中,对国外30个主流语言模型在准确率、鲁棒性、公平性、推理等主要指标进行评测,便发现:开源(Open)模型在大多数指标上表现弱于闭源(Close)或部分开源(Limited)的模型。
另一方面,大模型最终指向的还是产业落地,在商业化落地上,闭源大模型的能力更强。大模型要想落地就必须与企业业务相结合,这需要专业的人提供专业的服务能力,让大模型的能力与业务场景完美融合,并非一朝一夕的事情,需要长期赋能,这不是免费的开源大模型能做到的事情。
此外,大多数的开源大模型是“站在巨人肩膀上”推出的,也就是说处于领先水平的开源模型都是由大企业开发,话语权也都掌握在他们手中,繁荣的背后也存在着一丝不确定性。
换言之,着眼当下,闭源大模型是大模型落地商业化更优的选择,但这不代表,只能选择闭源大模型,放眼未来,开源大模型是让AI普惠化实现的重要方向。
俗话说,小孩子才做选择,大人的世界是全都要,开源与闭源并非选择题,也正如百川智能创始人王小川所言:“今天不能简单的说我们未来大模型就是走向OpenAI——闭源的中心化的模型。开源实际上是具备着很大的可能性,有可能蕴含着极大商业模式和价值。”
市场需求驱使下,开源与闭源之间的战争不断演绎,并在大模型领域中取得竞争优势。开源的灵活性和社区力量使其在人工智能和机器学习社群中占据重要地位,而闭源软件则通过保护知识产权和提供全面支持来吸引企业和组织的选择。
未来,随着技术的不断发展和市场的变化,开源和闭源之间的竞争将继续进行。无论是开源还是闭源大模型,都将在满足用户需求和推动技术进步方面发挥重要作用。最终,市场需求将决定开源与闭源谁主导了大模型的未来。
总言之,在大模型这场竞赛中,我们期待看到闭源大模型深扎产业,让AI的智能力量真正飞入“千万家”,也期待着开源大模型根深叶茂,肆意生长为大模型的迭代、AI产业的发展开拓更多的想象空间。
后记
无论是开源还是闭源,都有其存在的价值与意义。中国大模型要高水平发展,既要有全球领先的闭源大模型打头阵,也要有具备世界影响力的大模型开源社区。
对于大模型企业来说,既可以开发闭源大模型,也可以开发开源大模型,就像百川智能;对于想要开发垂类模型的企业来说,既可以调用闭源大模型,又可以基于开源大模型进行私有化部署。开源与闭源并非企业必做的二选一的选择题,而是要结合实际情况,明确企业的具体需求,再做决策。
转载自:https://blog.csdn.net/u014727709/article/details/134450984
欢迎 👍点赞✍评论⭐收藏,欢迎指正
相关文章:
“开源 vs. 闭源:大模型的未来发展趋势预测“——探讨大模型未来的发展方向
文章目录 每日一句正能量前言什么是大模型的开源与闭源开源与闭源的定义和特点开源的意义开源和闭源的优劣势比较不同的大模型企业,开源、闭源的策略不尽相同。企业在开发垂类模型时选择开源还是闭源大模型开源vs 闭源:两者并非选择题后记 每日一句正能量…...

计算机网络——物理层-信道的极限容量(奈奎斯特公式、香农公式)
目录 介绍 奈氏准则 香农公式 介绍 信号在传输过程中,会受到各种因素的影响。 如图所示,这是一个数字信号。 当它通过实际的信道后,波形会产生失真;当失真不严重时,在输出端还可根据已失真的波形还原出发送的码元…...

【算法挨揍日记】day31——673. 最长递增子序列的个数、646. 最长数对链
673. 最长递增子序列的个数 673. 最长递增子序列的个数 题目解析: 给定一个未排序的整数数组 nums , 返回最长递增子序列的个数 。 注意 这个数列必须是 严格 递增的。 解题思路: 算法思路: 1. 状态表⽰: 先尝试…...
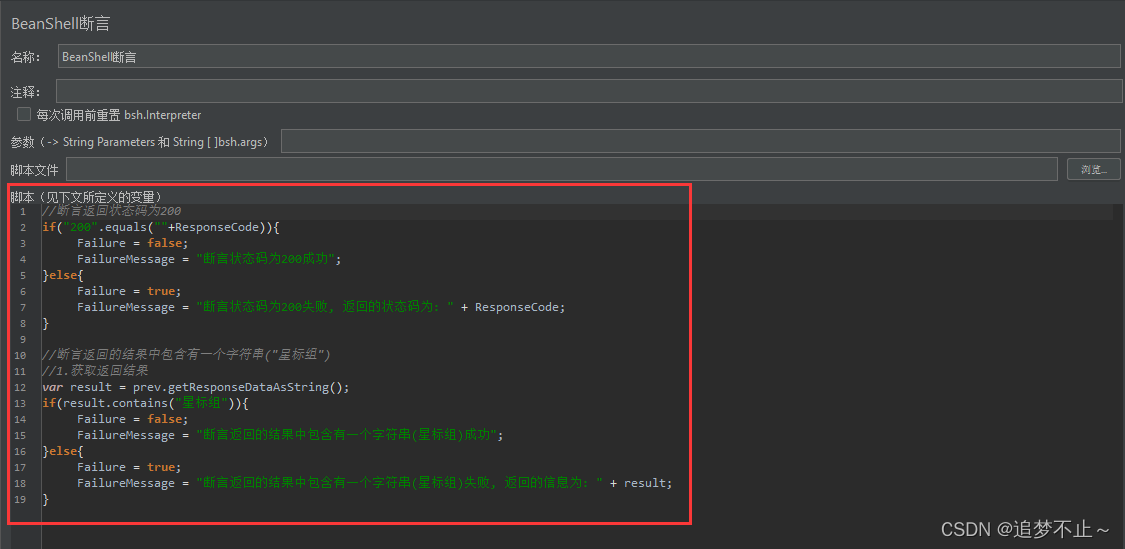
Jmeter做接口测试
1.Jmeter的安装以及环境变量的配置 Jmeter是基于java语法开发的接口测试以及性能测试的工具。 jdk:17 (最新的Jeknins,只能支持到17) jmeter:5.6 官网:http://jmeter.apache.org/download_jmeter.cgi 认识JMeter的目录࿱…...

第14届蓝桥杯青少组python试题解析:23年5月省赛
选择题 T1. 执行以下代码,输出结果是()。 lst "abc" print(lstlst)abcabc abc lstlst abcabc T2. 执行以下代码,输出的结果是()。 age {16,18,17} print(type(sorted(age)))<class set&…...
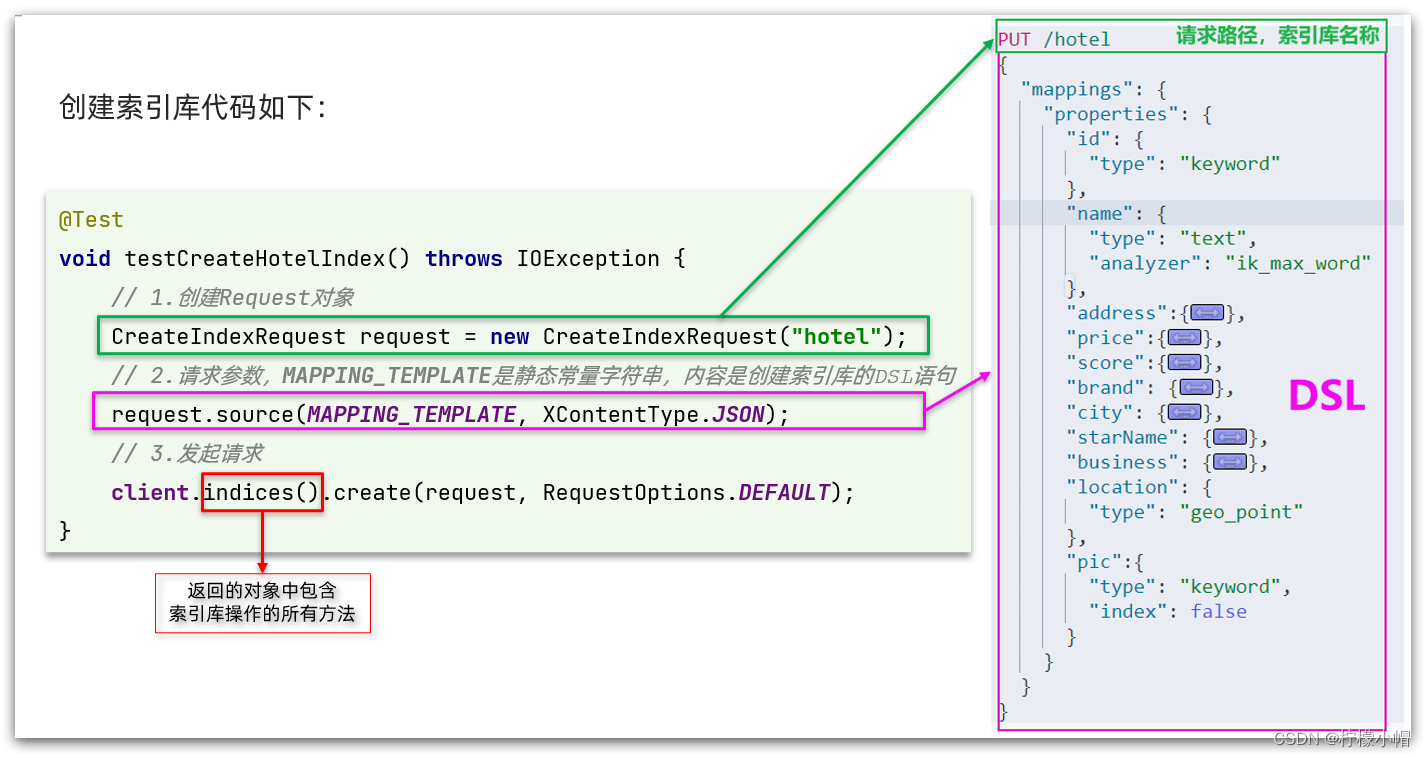
SpringCloud 微服务全栈体系(十四)
第十一章 分布式搜索引擎 elasticsearch 四、RestAPI ES 官方提供了各种不同语言的客户端,用来操作 ES。这些客户端的本质就是组装 DSL 语句,通过 http 请求发送给 ES。官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/…...

【开题报告】基于微信小程序的个人健康管理系统的设计与实现
1.选题背景与意义 在现代社会,人们对健康的关注日益增加。随着生活方式的变化和工作压力的增加,许多人意识到保持良好的身体健康对于提高生活质量和幸福感的重要性。 然而,许多人在日常生活中缺乏对自身健康状况的了解和管理。他们可能没有…...

Swagger笔记
一、导包 <!--引入swagger--> <dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.9.2</version> </dependency> <!--前端的UI界面--> <dependency><…...
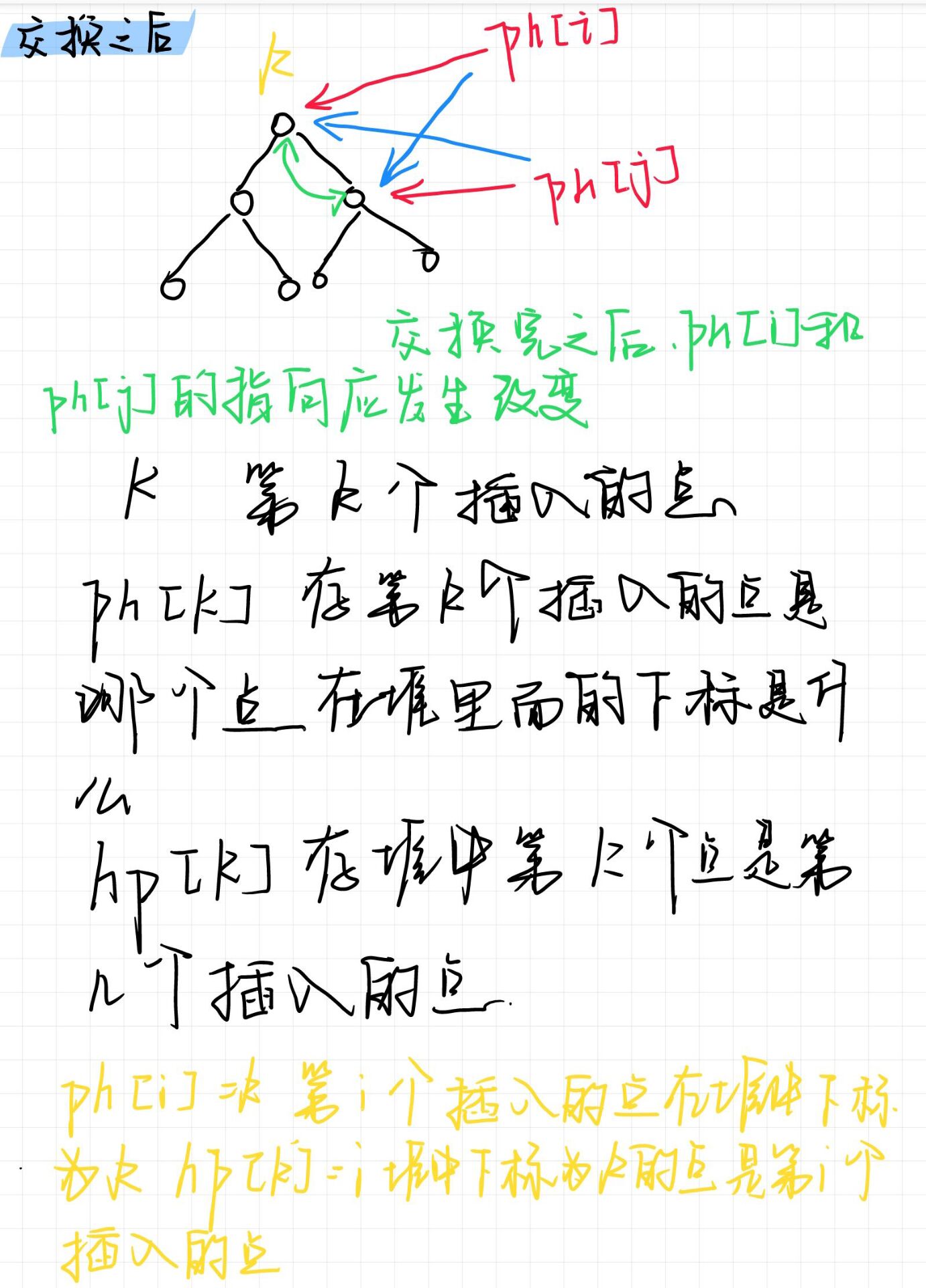
数据结构 堆
手写堆,而非stl中的堆 如何手写一个堆? //将数组建成堆 <O(n) for (int i n / 2;i;i--) //从n/2开始down down(i); 从n/2元素开始down,最下面一层元素的个数是n/2,其余上面的元素的个数是n/2,从最下面一层到最高层…...
将 ONLYOFFICE 文档编辑器与 Node.js 应用集成
我们来了解下,如何将 ONLYOFFICE 文档编辑器与您的 Web 应用集成。 许多 Web 应用都可以从文档编辑功能中获益。但是要从头开始创建这个功能,需要花费大量时间和精力。幸运的是,您可以使用 ONLYOFFICE——这是一款开源办公套件,可…...
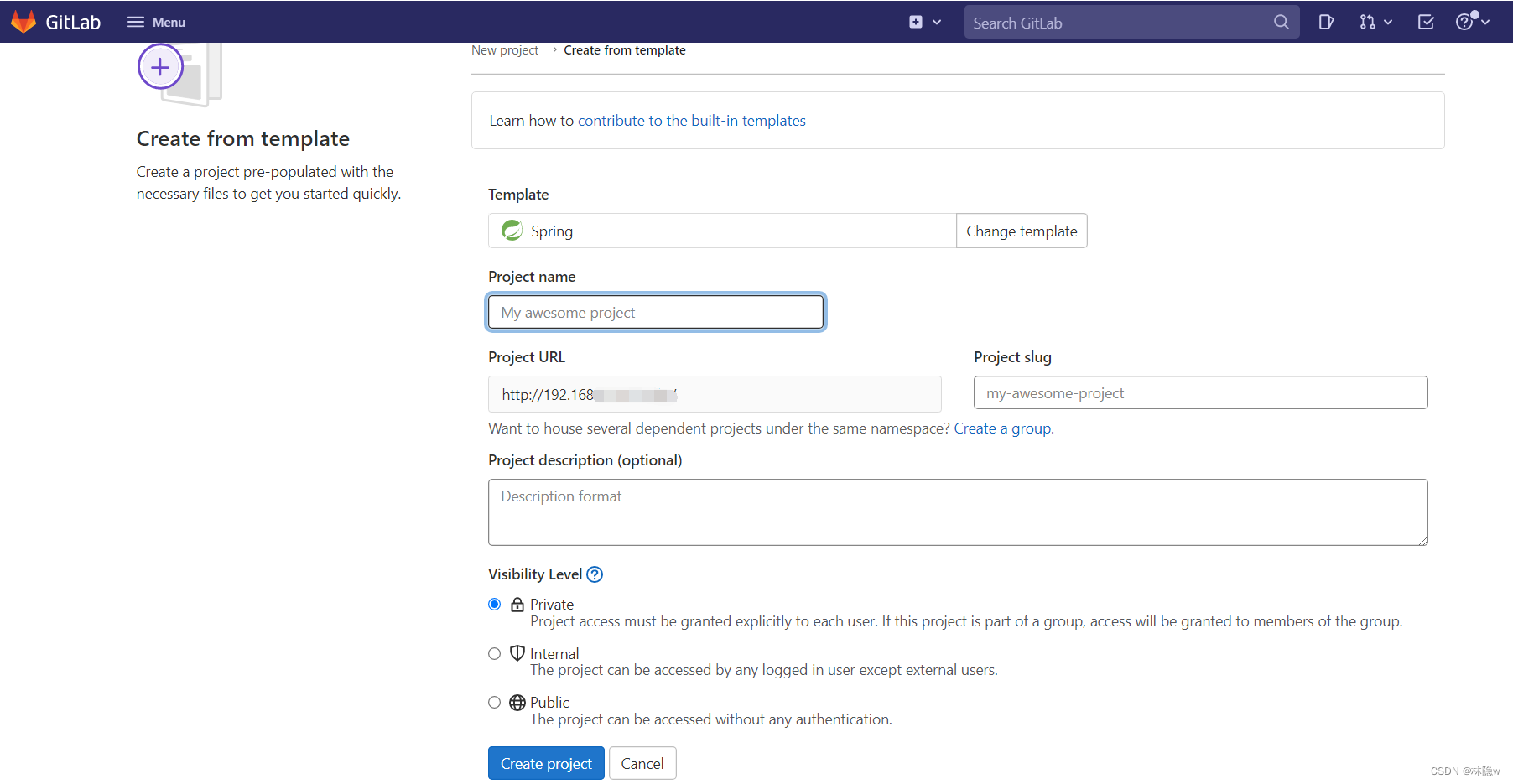
CentOS 7搭建Gitlab流程
目录 1、查询docker镜像gitlab-ce 2、拉取镜像 3、查询已下载的镜像 4、新建gitlab文件夹 5、在gitlab文件夹下新建相关文件夹 6、创建运行gitlab的容器 7、查看docker容器 8、根据Linux地址访问gitlab 9、进入docker容器,设置用户名的和密码 10、登录git…...
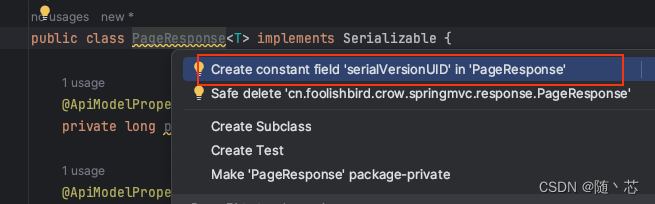
Idea安装完成配置
目录: 环境配置Java配置Maven配置Git配置 基础设置编码级设置File Header自动生成序列化编号配置 插件安装MyBtisPlusRestfulTooklkit-fix 环境配置 Java配置 Idea右上方,找到Project Settings. 有些版本直接有,有些是在设置下的二级菜单下…...

超详细~25考研规划~感恩现在努力的你!!!
25考研规划 俄语,翻译过来叫我爱你 考试时间 第一天 8.30-11.30政治——100分 2.00-5.00英语——100分 第二天 8.30-11.30数学——150分 2.00-5.00专业课——150分 1.什么是25考研 将在2024年12月参加考研,2025年本科毕业,9月读研究…...

智慧城市安全监控的新利器
在传统的城市管理中,井盖的监控一直是一个难题,而井盖异动传感器的出现为这一问题提供了有效的解决方案。它具有体积小、重量轻、安装方便等特点,可以灵活地应用于各种类型的井盖,实现对城市基础设施的全方位监控。 智能井盖监测终…...
)
【算法】石子合并(区间dp)
题目 设有 N 堆石子排成一排,其编号为 1,2,3,…,N。 每堆石子有一定的质量,可以用一个整数来描述,现在要将这 N 堆石子合并成为一堆。 每次只能合并相邻的两堆,合并的代价为这两堆石子的质量之和,合并后与这两堆石子…...

C++-特殊类和单例模式
1.请设计一个类,不能被拷贝 拷贝构造函数以及赋值运算符重载,因此想要让一个类禁止拷贝,只需让该类不能调用拷贝构造函数以及赋值运算符重载即可。 //该类不能发生拷贝class NonCopy{public:NonCopy(const NonCopy& Nc) delete;NonCopy&…...

【开源】基于Vue.js的智能教学资源库系统
项目编号: S 050 ,文末获取源码。 \color{red}{项目编号:S050,文末获取源码。} 项目编号:S050,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 数据中心模块2.2 课程档案模块2.3 课…...

C语言之qsort()函数的模拟实现
C语言之qsort()函数的模拟实现 文章目录 C语言之qsort()函数的模拟实现1. 简介2. 冒泡排序3. 对冒泡排序进行改造4. 改造部分4.1 保留部分的冒泡排序4.2 比较部分4.3 交换部分 5. bubble_sort2完整代码6. 使用bubble_sort2来排序整型数组7. 使用bubble_sort2来排序结构体数组7.…...

数字化未来:实时云渲染在智慧城市中的创新应用
数字中国战略"是国家推动数字经济发展的战略框架。这个战略旨在加速数字化转型,推动信息技术在各个领域的应用,提高社会经济效益和人民生活质量。而智慧城市作为其中的重要一环,重要性不言而喻。 智慧城市是当今城市发展的热点和趋势&a…...
Go语言常用命令详解(二)
文章目录 前言常用命令go bug示例参数说明 go doc示例参数说明 go env示例 go fix示例 go fmt示例 go generate示例 总结写在最后 前言 接着上一篇继续介绍Go语言的常用命令 常用命令 以下是一些常用的Go命令,这些命令可以帮助您在Go开发中进行编译、测试、运行和…...

基于强化学习与LLM的在线讨论不当言论自动改写技术
1. 项目概述与核心挑战 在社交媒体和在线论坛上,我们每天都能看到海量的讨论。其中,不乏一些言辞激烈、充满攻击性或者逻辑混乱的“不当言论”。传统的平台治理手段,比如关键词过滤、基于分类器的自动检测加上人工审核,更像是一个…...

智慧树刷课插件:3步安装,告别手动刷课的终极解决方案
智慧树刷课插件:3步安装,告别手动刷课的终极解决方案 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的繁琐网课学习而烦恼吗&…...

IEMOCAP数据集预处理实战:用Python和Librosa搞定语音情感识别的数据准备
IEMOCAP数据集预处理实战:用Python和Librosa搞定语音情感识别的数据准备语音情感识别(SER)作为人机交互领域的重要研究方向,其核心挑战之一是如何从原始音频中提取有效的特征表示。本文将手把手带你完成IEMOCAP数据集的预处理全流…...

Atmosphère系统架构深度解析:分层安全模型与模块化设计哲学
Atmosphre系统架构深度解析:分层安全模型与模块化设计哲学 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable Atmosphre作为Nintendo Switch的自定义固件,其核心价值在…...

7自由度机械臂逆运动学求解:13种算法对比与混合策略实战
1. 项目概述:当机械臂遇到“无限可能”的烦恼在机器人领域,让机械臂的“手”(末端执行器)精准地到达一个指定的位置和姿态,是一个看似简单实则复杂的基础问题,这就是逆运动学。对于常见的6自由度机械臂&…...

量子计算中的李群与李代数:从数学基石到时间最优控制实践
1. 从对称性到量子操控:李群与李代数的核心角色 在量子信息处理的世界里,我们每天都在与“对称性”打交道。一个量子比特的旋转,一个多体纠缠态的演化,甚至一个量子算法的设计,其背后都隐藏着一种优美的数学结构——连…...

Arm嵌入式工具链全解析:从获取到优化
1. Arm嵌入式工具链概述Arm Toolchain for Embedded是Arm公司为嵌入式系统开发提供的一套完整工具链集合,包含编译器、调试器、链接器等核心组件。作为嵌入式开发领域的标准工具链,它支持从Cortex-M系列微控制器到Cortex-A系列应用处理器的全系列Arm架构…...

Redis分布式锁进阶第五十六篇
Redis分布式锁进阶第二十五篇:联锁深度拆解 多资源交叉死锁根治 复杂业务多级加锁绝对有序方案一、本篇前置衔接 第二十四篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实…...

解决Keil C51项目中PL/M-51编译警告导致构建失败问题
1. 问题现象与背景分析当使用Keil Vision IDE进行C51项目开发时,许多工程师都遇到过这样一个棘手情况:在点击"Build target"或"Rebuild all target files"后,编译过程会在某个PL/M-51源文件处突然停止。输出窗口显示该文…...

二、Socket 编程 TCP
Socket 编程 TCP 一、TCP 编程整体认识 TCP 是面向连接的可靠传输协议。和 UDP 不同,UDP 可以直接 sendto/recvfrom 收发数据,而 TCP 通信之前必须先建立连接。 TCP 服务端基本流程: socket() -> bind() -> listen() -> accept(…...