LLM大模型4位量化实战【GPTQ】
权重量化方面的最新进展使我们能够在消费类硬件上运行大量大型语言模型,例如 RTX 3090 GPU 上的 LLaMA-30B 模型。 这要归功于性能下降最小的新型 4 位量化技术,例如 GPTQ、GGML 和 NF4。
在上一篇文章中,我们介绍了简单的 8 位量化技术和出色的 LLM.int8()。 在本文中,我们将探索流行的 GPTQ 算法,以了解其工作原理并使用 AutoGPTQ 库实现它。
你可以在 Google Colab 和 GitHub 上找到代码。

在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器
1、最优大脑量化
让我们首先介绍我们要解决的问题。 对于网络中的每一层 ℓ,我们希望找到原始权重 Wₗ 的量化版本 Ŵₗ。 这称为分层压缩问题。 更具体地说,为了最大限度地减少性能下降,我们希望这些新权重的输出 (ŴᵨXᵨ) 尽可能接近原始权重 (WᵨXᵨ)。 换句话说,我们想要找到:
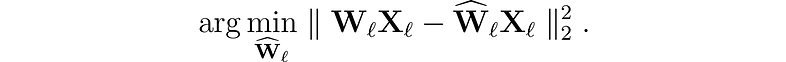
人们提出了不同的方法来解决这个问题,但我们对这里的最优大脑量化器(OBQ:Optimal Brain Quantizer)框架感兴趣。
该方法的灵感来自于一种修剪(pruning)技术,该技术可以仔细地从经过充分训练的密集神经网络(最佳脑外科医生)中去除权重。 它使用近似技术,并为要删除的最佳单个权重 w和最佳更新 δ提供显式公式,以调整剩余非量化权重 F 的集合以弥补删除:
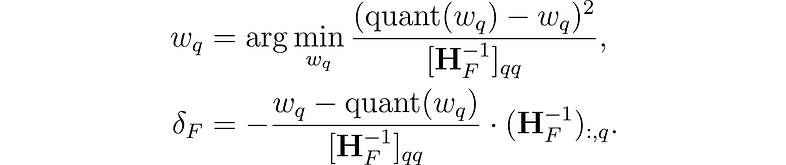
其中 quant(w) 是量化给出的权重舍入,H 是 Hessian 矩阵。
使用 OBQ,我们可以首先量化最简单的权重,然后调整所有剩余的非量化权重以补偿这种精度损失。 然后我们选择下一个要量化的权重,依此类推。
这种方法的一个潜在问题是当存在异常权重时,这可能会导致高量化误差。 通常,当剩下很少的非量化权重可以调整以补偿大误差时,这些离群值将最后被量化。 当一些权重因中间更新而被进一步推到网格之外时,这种效果可能会恶化。 应用一个简单的启发式方法来防止这种情况:异常值一出现就被量化。
这个过程的计算量可能很大,尤其是对于KKM而言。 为了解决这个问题,OBQ 方法使用了一种技巧,可以避免每次简化权重时都重新进行整个计算。 量化权重后,它通过删除与该权重关联的行和列(使用高斯消除)来调整计算中使用的矩阵(Hessian):
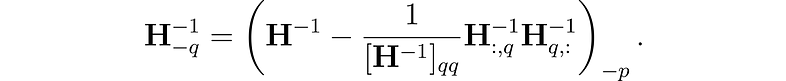
该方法还采用矢量化来一次处理多行权重矩阵。 尽管其效率很高,但 OBQ 的计算时间随着权重矩阵大小的增加而显着增加。 这种立方增长使得在具有数十亿参数的大型模型上使用 OBQ 变得困难。
2、GPTQ 算法
由 Frantar 等人提出,GPTQ 算法从 OBQ 方法中汲取灵感,但进行了重大改进,以将其扩展到(非常)大型语言模型。
第 1 步:任意排序洞察
OBQ 方法按一定的顺序选择权重(模型中的参数)进行量化,所确定的权重将增加最少的附加误差。 然而,GPTQ 观察到,对于大型模型,以任何固定顺序量化权重都可以获得同样的效果。 这是因为,即使某些权重可能会单独引入更多误差,但它们会在过程中稍后进行量化,因为此时几乎没有其他权重可能会增加误差。 所以顺序并不像我们想象的那么重要。
基于这一见解,GPTQ 旨在以相同的顺序量化矩阵所有行的所有权重。 这使得过程更快,因为某些计算只需为每列执行一次,而不是为每个权重执行一次。
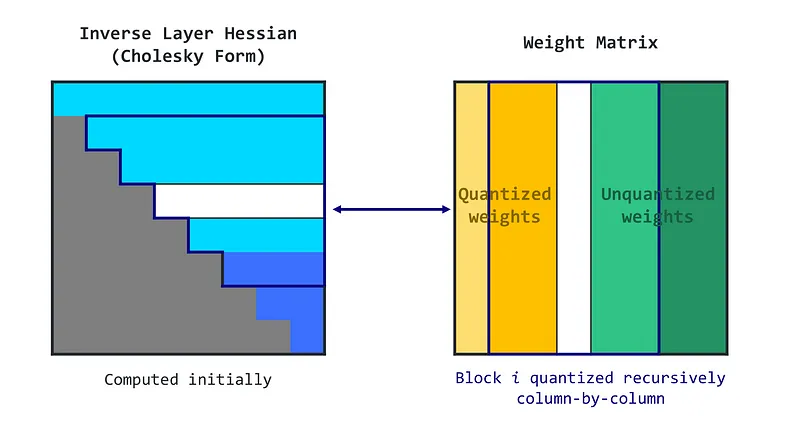
第 2 步:惰性批量更新
该方案不会很快,因为它需要更新一个巨大的矩阵,并且每个条目的计算量很少。 此类操作无法充分利用 GPU 的计算能力,并且会因内存限制(内存吞吐量瓶颈)而减慢速度。
为了解决这个问题,GPTQ 引入了“惰性批量”更新。 事实证明,给定列的最终舍入决策仅受对该列执行的更新的影响,而不受后续列上执行的更新的影响。 因此,GPTQ 可以一次将该算法应用于一批列(例如 128 列),仅更新这些列和矩阵的相应块。 完全处理一个块后,算法对整个矩阵执行全局更新。
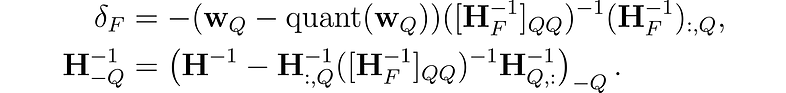
步骤 3:Cholesky 重构
然而,还有一个问题需要解决。 当算法扩展到非常大的模型时,数值不准确可能会成为一个问题。 具体来说,重复应用某个运算可能会累积数值误差。
为了解决这个问题,GPTQ 使用 Cholesky 分解,这是一种用于解决某些数学问题的数值稳定方法。 它涉及使用 Cholesky 方法从矩阵中预先计算一些所需的信息。 这种方法与轻微的“阻尼”(向矩阵的对角元素添加一个小常数)相结合,有助于算法避免数值问题。
完整的算法可以概括为以下几个步骤:
- GPTQ 算法从 Hessian 逆矩阵(帮助决定如何调整权重的矩阵)的 Cholesky 分解开始
- 然后它循环运行,一次处理一批列。
- 对于批次中的每一列,它都会量化权重,计算误差,并相应地更新块中的权重。
- 处理完该批次后,它会根据块的错误更新所有剩余的权重。
GPTQ 算法在各种语言生成任务上进行了测试。 它与其他量化方法进行了比较,例如将所有权重四舍五入到最接近的量化值(RTN)。 GPTQ 与 BLOOM(176B 参数)和 OPT(175B 参数)模型系列一起使用,并使用单个 NVIDIA A100 GPU 对模型进行量化。
3、使用 AutoGPTQ 量化 LLM
GPTQ 在创建可在 GPU 上高效运行的 4 位精度模型方面非常流行。 你可以在 Hugging Face Hub 上找到许多示例,尤其是来自 TheBloke 的示例。 如果你正在寻找一种对 CPU 更友好的方法,GGML 目前是你的最佳选择。 最后,带有 bitsandbytes 的 Transformer 库允许你在使用 load_in_4bit=true 参数加载模型时对其进行量化,这需要下载完整模型并将其存储在 RAM 中。
让我们使用 AutoGPTQ 库实现 GPTQ 算法并量化 GPT-2 模型。 这需要 GPU,但 Google Colab 上的免费 T4 就可以了。 我们首先加载库并定义我们想要量化的模型(在本例中为 GPT-2)。
!BUILD_CUDA_EXT=0 pip install -q auto-gptq transformersimport randomfrom auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
from datasets import load_dataset
import torch
from transformers import AutoTokenizer# Define base model and output directory
model_id = "gpt2"
out_dir = model_id + "-GPTQ"我们现在要加载模型和分词器。 分词器是使用 Transformers 库中的经典 AutoTokenizer 类加载的。 另一方面,我们需要传递特定的配置(BaseQuantizeConfig)来加载模型。
在此配置中,我们可以指定要量化的位数(此处,bits=4)和组大小(惰性批次的大小)。 请注意,该组大小是可选的:我们还可以对整个权重矩阵使用一组参数。 在实践中,这些组通常以非常低的成本提高量化质量(特别是在 group_size=1024 的情况下)。 此处的 hum_percent 值用于帮助 Cholesky 重新公式化,不应更改。
最后,desc_act(也称为行为顺序)是一个棘手的参数。 它允许你根据减少的激活来处理行,这意味着首先处理最重要或最有影响力的行(由采样的输入和输出确定)。 该方法旨在将大部分量化误差(在量化过程中不可避免地引入)置于不太重要的权重上。 这种方法通过确保以更高的精度处理最重要的权重,提高了量化过程的整体准确性。 然而,当与组大小一起使用时,由于需要频繁重新加载量化参数,desc_act 可能会导致性能下降。 因此,我们不会在这里使用它(但是将来可能会修复它)。
# Load quantize config, model and tokenizer
quantize_config = BaseQuantizeConfig(bits=4,group_size=128,damp_percent=0.01,desc_act=False,
)
model = AutoGPTQForCausalLM.from_pretrained(model_id, quantize_config)
tokenizer = AutoTokenizer.from_pretrained(model_id)量化过程很大程度上依赖于样本来评估和提高量化质量。 它们提供了一种比较原始模型和新量化模型产生的输出的方法。 提供的样本数量越多,进行更准确和有效比较的潜力就越大,从而提高量化质量。
在本文中,我们利用 C4(Colossal Clean Crawled Corpus)数据集来生成样本。 C4 数据集是从 Common Crawl 项目收集的大规模、多语言的网络文本集合。 这个庞大的数据集经过专门清理和准备,用于训练大规模语言模型,使其成为此类任务的重要资源。 维基文本数据集是另一个流行的选择。
在下面的代码块中,我们从 C4 数据集中加载 1024 个样本,对它们进行标记并格式化。
# Load data and tokenize examples
n_samples = 1024
data = load_dataset("allenai/c4", data_files="en/c4-train.00001-of-01024.json.gz", split=f"train[:{n_samples*5}]")
tokenized_data = tokenizer("\n\n".join(data['text']), return_tensors='pt')# Format tokenized examples
examples_ids = []
for _ in range(n_samples):i = random.randint(0, tokenized_data.input_ids.shape[1] - tokenizer.model_max_length - 1)j = i + tokenizer.model_max_lengthinput_ids = tokenized_data.input_ids[:, i:j]attention_mask = torch.ones_like(input_ids)examples_ids.append({'input_ids': input_ids, 'attention_mask': attention_mask})现在数据集已准备就绪,我们可以开始批大小为 1 的量化过程。我们还可以选择使用 OpenAI Triton(CUDA 的替代方案)与 GPU 进行通信。 完成此操作后,我们将分词器和模型保存为安全张量格式。
# Quantize with GPTQ
model.quantize(examples_ids,batch_size=1,use_triton=True,
)# Save model and tokenizer
model.save_quantized(out_dir, use_safetensors=True)
tokenizer.save_pretrained(out_dir)像往常一样,然后可以使用 AutoGPTQForCausalLM 和 AutoTokenizer 类从输出目录加载模型和标记生成器。
device = "cuda:0" if torch.cuda.is_available() else "cpu"# Reload model and tokenizer
model = AutoGPTQForCausalLM.from_quantized(out_dir,device=device,use_triton=True,use_safetensors=True,
)
tokenizer = AutoTokenizer.from_pretrained(out_dir)让我们检查一下模型是否正常工作。 AutoGPTQ 模型(大部分)作为普通transformer模型工作,这使得它与推理管道兼容,如以下示例所示:
from transformers import pipelinegenerator = pipeline('text-generation', model=model, tokenizer=tokenizer)
result = generator("I have a dream", do_sample=True, max_length=50)[0]['generated_text']
print(result)I have a dream," she told CNN last week. "I have this dream of helping my mother find her own. But, to tell that for the first time, now that I'm seeing my mother now, just knowing how wonderful it is that我们成功地从量化的 GPT-2 模型中获得了令人信服的完成结果。 更深入的评估需要测量量化模型与原始模型的复杂度。 但是,我们将其排除在本文的讨论范围之外。
4、结束语
在本文中,我们介绍了 GPTQ 算法,这是一种在消费级硬件上运行 LLM 的最先进的量化技术。 我们展示了它如何基于具有任意顺序洞察、惰性批量更新和 Cholesky 重构的改进 OBS 技术来解决分层压缩问题。 这种新颖的方法显着降低了内存和计算需求,使LLM可供更广泛的受众使用。
此外,我们在免费的 T4 GPU 上量化了我们自己的 LLM 模型,并运行它来生成文本。 你可以在 Hugging Face Hub 上推送自己的 GPTQ 4 位量化模型版本。 正如简介中提到的,GPTQ 并不是唯一的 4 位量化算法:GGML 和 NF4 都是优秀的替代方案,但范围略有不同。 我鼓励你更多地了解它们并尝试一下!
原文链接:GPTQ 4位量化实战 - BimAnt
相关文章:
LLM大模型4位量化实战【GPTQ】
权重量化方面的最新进展使我们能够在消费类硬件上运行大量大型语言模型,例如 RTX 3090 GPU 上的 LLaMA-30B 模型。 这要归功于性能下降最小的新型 4 位量化技术,例如 GPTQ、GGML 和 NF4。 在上一篇文章中,我们介绍了简单的 8 位量化技术和出…...

安装keras、tensorflow
看起来你仍然面临SSL证书验证失败的问题。这可能是由于你的网络环境或代理设置引起的。你可以尝试以下几个步骤: 检查网络连接: 确保你的计算机能够正常访问互联网。 关闭代理: 如果你使用了代理,尝试暂时关闭它,然后…...

ffmpeg知识点整理
使用FFmepg进行视频转码、视频格式转换、图片提取等!_ffmepg -c:v-CSDN博客 中文文档: ffmpeg 中文手册 (beandrewang.github.io) 笔记: 通用规则是,所有选项作用于其后边的第一个文件。因此,顺序是非常重要的&…...
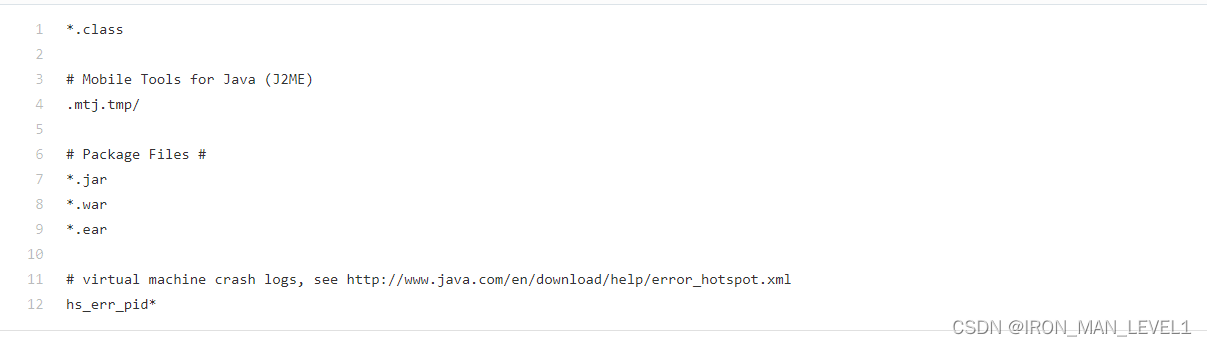
Git 笔记之gitignore
解释为:git ignore 即,此类型的文件将会被忽略掉,从而不会进行管理 具体的模板可以从 GitHub 网站上来进行设置 GitHub - github/gitignore: A collection of useful .gitignore templates Common_gitignore: gitignoregithub开源项目&…...

【配置】Redis常用配置详解
文章目录 IP地址绑定设置密码 IP地址绑定 默认情况下,如果未指定 “bind” 配置指令,Redis 将监听服务器上所有可用的网络接口的连接。 可以使用 “bind” 配置指令来仅监听一个或多个选定的接口,后跟一个或多个 IP 地址 示例:bin…...

Linux(Ubuntu)安装JDK环境
系统环境 Ubuntu20.04 下载JDK压缩包 前往Oracle官网进行后续下载或单击下载JDK压缩包 下拉找到JDK8,在Linux板块下选择适配系统架构的压缩包文件(后缀为tar.gz),系统架构可通过uname -m命令查看 安装JDK 安装环境通常放在/usr/local下,进入…...

OpenCV C++ 张正友相机标定【相机标定原理、相机标定流程、图像畸变矫正】
文章目录 3.1 标定原理3.2 相机标定流程步骤1:采集棋盘格图像,批处理(调整尺寸、重命名)步骤2:提取棋盘格内角点坐标步骤3:进一步提取亚像素角点信息在棋盘标定图上绘制找到的内角点(非必须,仅为了显示)步骤4:相机标定--计算出相机内参数矩阵和畸变系数步骤5:畸变图像…...
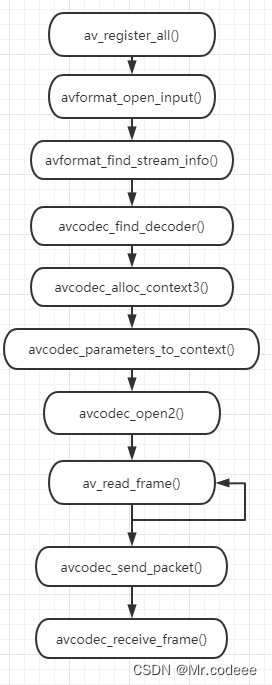
SDL2 播放音频(MP4)
1.简介 这里引入FFmpeg库,获取音频流数据,然后通过FFmpeg将视频流解码成pcm原始数据,再将pcm数据送入到SDL库中实现音频播放。 2.FFmpeg的操作流程 注册API:av_register_all()构建输入AVFormatContext上下文:avform…...

WMS仓库管理系统库位功能
后端 using Infrastructure.Attribute; using Model.Dto.WarehouseManagement; using Model.Page; using Model.WarehouseManagement; using Repository; using Service.Interface.WarehouseManagement; using SqlSugar;namespace Service.WarehouseManagement {[…...
)
vue2组件通信中的一些拓展(props,emit,ref父子双向传参)
说明 我上一篇文章中基本对vue所有的数据通信方法进行了一个整理归纳。 其实我并没有像传统的那样去罗列,比如父传子有props,ref,子传父为emit,兄弟用$bus等等。 因为在我的实际练习和业务开发中,props,emit,ref等可以实现父子数据互传,这里就涉及一个比较重要的编程思维,函…...

Flink1.17 DataStream API
目录 一.执行环境(Execution Environment) 1.1 创建执行环境 1.2 执行模式 1.3 触发程序执行 二.源算子(Source) 2.1 从集合中读取数据 2.2 从文件读取数据 2.3 从 RabbitMQ 中读取数据 2.4 从数据生成器读取数据 2.5 …...

数据结构中树、森林 与 二叉树的转换
1 树转换为 二叉树 将树转换成二叉树的步骤是: 加线。在所有的兄弟结点之间加一条线。去线。对于树中的每个结点,只保留它与第一个孩子结点的连线,删除该结点其他孩子结点之间的连线。调整。以树的根结点为轴心,将整个树顺时针旋…...

力扣labuladong——一刷day43
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、力扣257. 二叉树的所有路径二、力扣129. 求根节点到叶节点数字之和三、力扣199. 二叉树的右视图四、力扣662. 二叉树最大宽度 前言 一般来说,如…...

MapApp 地图应用
1. 简述 1.1 重点 1)更好地理解 MVVM 架构 2)更轻松地使用 SwiftUI 框架、对齐、动画和转换 1.2 资源下载地址: Swiftful-Thinking:https://www.swiftful-thinking.com/downloads 1.3 项目结构图: 1.4 图片、颜色资源文件图: 1.5 启动图片配置图: 2. Mo…...

Java之反射获取和赋值字段
在Java中,反射能够使得代码更加通用,往往用于工具类中。 但常常我们在获取或者赋值反射的属性时,会出现没有赋值成功的结果,往往是由于这个属性在父级中而导致的,这个时候我们就不能用getDeclaredField方法单独获取字段…...

ckplayer自己定义风格播放器的开发记录
CKplayer是一款基于Flash和HTML5技术的开源视频播放器,支持多种格式的音视频播放,并且具有优秀的兼容性和扩展性。 它不仅可以在网页上播放本地或者网络上的视频,还可以通过代码嵌入到网页中,实现更加个性化的播放效果。CKplayer…...
)
全网最全Django面试题整理(一)
Django 中的 MTV 是什么意思? 在Django中,MTV指的是“Model-Template-View”,而不是常见的MVC(Model-View-Controller)架构。Django的设计理念是基于MTV的 Model(模型) 模型代表数据存取层&am…...

vue统一登录
说明: 统一登录其实就是前端去判断Url地址的token 之后如果有token未过期就直接跳转到首页。 说到浏览器输入url地址,那从浏览器输入地址一共发生了几件事大致如下: DNS解析域名,获取IP地址 --》 建立TCP连接(三次握…...

MVSNet论文笔记
MVSNet论文笔记 摘要1 引言2 相关基础2.1 多视图立体视觉重建(MVS Reconstruction)2.2 基于学习的立体视觉(Learned Stereo)2.3 基于学习的多视图的立体视觉(Learned MVS) 3 MVSNet3.1 网络架构3.2 提取图片…...
大型 APP 的性能优化思路
做客户端开发都基本都做过性能优化,比如提升自己所负责的业务的速度或流畅性,优化内存占用等等。但是大部分开发者所做的性能优化可能都是针对中小型 APP 的,大型 APP 的性能优化经验并不会太多,毕竟大型 APP 就只有那么几个&…...

洛雪音乐音源终极指南:3步解锁全网无损音乐自由
洛雪音乐音源终极指南:3步解锁全网无损音乐自由 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 还在为音乐平台会员费烦恼?或是被不同平台的独家版权搞得晕头转向ÿ…...

unplugin-dts完整指南:从vite-plugin-dts迁移到通用插件
unplugin-dts完整指南:从vite-plugin-dts迁移到通用插件 【免费下载链接】unplugin-dts An unplugin for generating declaration (dts) files. 项目地址: https://gitcode.com/gh_mirrors/vi/unplugin-dts unplugin-dts是一款功能强大的通用插件,…...

【国家级边缘AI项目总架构师内部复盘】:为什么92%的AI Agent边缘化失败?4个被忽视的实时性阈值与硬件协同校准公式
更多请点击: https://codechina.net 第一章:【国家级边缘AI项目总架构师内部复盘】:为什么92%的AI Agent边缘化失败?4个被忽视的实时性阈值与硬件协同校准公式 在2023–2024年覆盖17个省级工业物联网节点的国家级边缘AI落地验证中…...

Wifite2实战指南:从零开始掌握无线网络安全审计的3大核心能力
Wifite2实战指南:从零开始掌握无线网络安全审计的3大核心能力 【免费下载链接】wifite2 Rewrite of the popular wireless network auditor, "wifite" 项目地址: https://gitcode.com/gh_mirrors/wi/wifite2 想象一下,你只需一条命令就…...

洛雪音乐音源终极指南:如何免费获取全网高品质音乐资源
洛雪音乐音源终极指南:如何免费获取全网高品质音乐资源 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 你是否厌倦了在各个音乐平台之间切换,只为寻找一首高品质的音乐&…...
)
“AI点单员”真的能替代人工吗?——基于237家门店AB测试的转化率、客单价、复购率三重数据验证(含原始数据集索引)
更多请点击: https://kaifayun.com 第一章:AI Agent餐饮行业应用 AI Agent正以前所未有的深度融入餐饮行业全链路,从智能点餐、后厨协同到供应链优化与顾客情感分析,其核心价值在于将静态规则系统升级为具备感知、推理与自主决策…...

嵌入式气体传感器模组选型、集成与工程实践全解析
1. 项目概述:从“感知”到“决策”的桥梁在工业自动化、环境监测乃至我们日常的智能家居设备里,气体传感器模组正扮演着越来越关键的角色。它不像一个独立的传感器探头那么简单,而是一个集成了传感元件、信号调理、数据处理甚至通讯接口的完整…...

TPT线下工作坊:AIGC、云原生与数据合规的深度实践与碰撞
1. 活动缘起与核心价值:为什么一场线下工作坊如此重要?在数字营销和内容创作领域,我们每天都被海量的线上信息包围。线上会议、直播、社群讨论,这些形式高效且便捷,但总感觉隔着一层屏幕,少了些温度与深度。…...

TrollInstallerX深度探索:iOS越狱应用安装的革命性解决方案
TrollInstallerX深度探索:iOS越狱应用安装的革命性解决方案 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 还在为iOS设备上安装TrollStore而烦恼吗…...

容器镜像加速实战:3种方案彻底解决国内拉取难题
容器镜像加速实战:3种方案彻底解决国内拉取难题 【免费下载链接】public-image-mirror 很多镜像都在国外。比如 gcr 。国内下载很慢,需要加速。致力于提供连接全世界的稳定可靠安全的容器镜像服务。 项目地址: https://gitcode.com/GitHub_Trending/pu…...