PostgreSQL 数据定义语言 DDL
文章目录
- 表创建
- 主键约束
- 非空
- 唯一约束
- 检查约束
- 外键约束
- 默认值约束
- 触发器
- 表空间
- 构建表空间
- 视图
- 索引
- 索引的基本概念
- 索引的分类
- 创建索引
- 物化视图
表创建
PostgreSQL表的构建语句与所有数据库都一样,结构如下,其核心在于构建表时,要指定上一些约束,例如主键、非空、唯一、检查、外键、默认值等。
CREATE TABLE table_name ( column1 datatype, column2 datatype, column3 datatype, ...
);
主键约束
-- 主键约束
drop table test;
create table test(id bigserial primary key ,name varchar(32)
);
非空
-- 非空约束
drop table test;
create table test(id bigserial primary key ,name varchar(32) not null
);
唯一约束
drop table test;
create table test(id bigserial primary key ,name varchar(32) not null,id_card varchar(32) unique
);
insert into test (name,id_card) values ('张三','333333333333333333');
insert into test (name,id_card) values ('李四','333333333333333333');
insert into test (name,id_card) values (NULL,'433333333333333333');
检查约束
-- 检查约束
-- 价格的表,price,discount_price
drop table test;
create table test(id bigserial primary key,name varchar(32) not null,price numeric check(price > 0),discount_price numeric check(discount_price > 0),check(price >= discount_price)
);
insert into test (name,price,discount_price) values ('粽子',122,12);
外键约束
不用
默认值约束
一般公司内,要求表中除了主键和业务字段之外,必须要有5个字段:created,create_id,updated,update_id,is_delete ,通常可以给这些字段设置默认值。
-- 默认值
create table test(id bigserial primary key,created timestamp default current_timestamp
);
触发器
触发器Trigger,是由事件出发的一种存储过程,当进行insert,update,delete,truncate操作时,会触发表的Trigger。
这里以学生信息和学生分数为例,在删除学生信息的同时,自动删除学生的分数。
先构建表信息,填充数据
create table student(id int,name varchar(32)
);
create table score(id int,student_id int,math_score numeric,english_score numeric,chinese_score numeric
);
insert into student (id,name) values (1,'张三');
insert into student (id,name) values (2,'李四');
insert intoscore
(id,student_id,math_score,english_score,chinese_score)values
(1,1,66,66,66);insert intoscore
(id,student_id,math_score,english_score,chinese_score)values
(2,2,55,55,55);select * from student;
select * from score;
为了完成级联删除的操作,需要编写pl/sql。
先查看一下PGSQL支持的plsql,查看一下PGSQL的plsql语法
[ <<label>> ]
[ DECLAREdeclarations ]
BEGINstatements
END [ label ];
触发器函数允许使用一些特殊变量
NEW
数据类型是RECORD;该变量为行级触发器中的INSERT/UPDATE操作保持新数据行。在语句级别的触发器以及DELETE操作,这个变量是null。OLD
数据类型是RECORD;该变量为行级触发器中的UPDATE/DELETE操作保持新数据行。在语句级别的触发器以及INSERT操作,这个变量是null。
构建一个删除学生分数的函数。
-- 构建一个删除学生分数的触发器函数。
create function trigger_function_delete_student_score() returns trigger as $$
begindelete from score where student_id = old.id;return old;
end;
$$ language plpgsql;
在学生信息表删除时,执行声明的函数
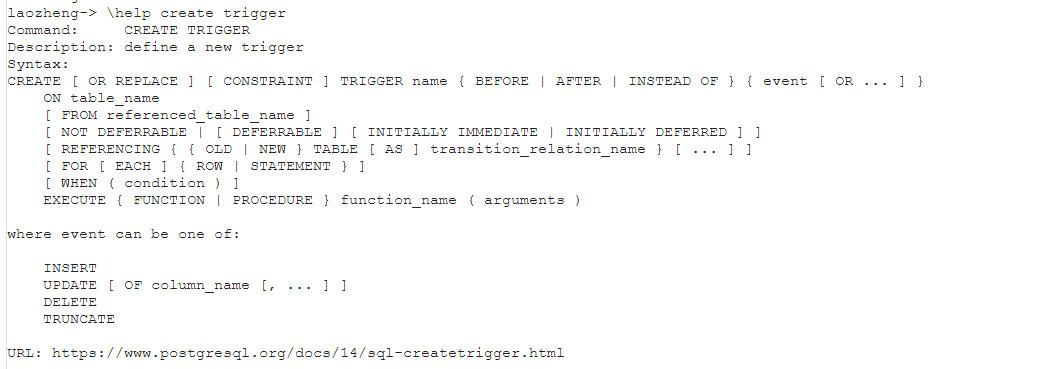
CREATE [ OR REPLACE ] [ CONSTRAINT ] TRIGGER name { BEFORE | AFTER | INSTEAD OF } { event [ OR ... ] }ON table_name[ FROM referenced_table_name ][ NOT DEFERRABLE | [ DEFERRABLE ] [ INITIALLY IMMEDIATE | INITIALLY DEFERRED ] ][ REFERENCING { { OLD | NEW } TABLE [ AS ] transition_relation_name } [ ... ] ][ FOR [ EACH ] { ROW | STATEMENT } ][ WHEN ( condition ) ]EXECUTE { FUNCTION | PROCEDURE } function_name ( arguments )where event can be one of:INSERTUPDATE [ OF column_name [, ... ] ]DELETETRUNCATE
当
CONSTRAINT选项被指定,这个命令会创建一个 约束触发器 。这和一个常规触发器相同,不过触发该触发器的时机可以使用SET CONSTRAINTS调整。约束触发器必须是表上的AFTER ROW触发器。它们可以在导致触发器事件的语句末尾被引发或者在包含该语句的事务末尾被引发。在后一种情况中,它们被称作是被 延迟 。一个待处理的延迟触发器的引发也可以使用SET CONSTRAINTS立即强制发生。当约束触发器实现的约束被违背时,约束触发器应该抛出一个异常。
编写触发器,指定在删除某一行学生信息时,触发当前触发器,执行trigger_function_delete_student_score()函数
create trigger trigger_student
after
delete
on student
for each row
execute function trigger_function_delete_student_score();
-- 测试效果
select * from student;
select * from score;
delete from student where id = 1;
表空间
在存储数据时,数据肯定要落到磁盘上,基于构建的tablespace,指定数据存放在磁盘上的物理地址。如果没有自己设计tablespace,PGSQL会自动指定一个位置作为默认的存储点。可以通过一个函数,查看表的物理数据存放在了哪个磁盘路径下。
-- 查询表存储的物理地址
select pg_relation_filepath('student');

这个位置是在$PG_DATA后的存放地址,41000就是存储数据的物理文件。
$PG_DATA == /var/lib/pgsql/12/data/
构建表空间
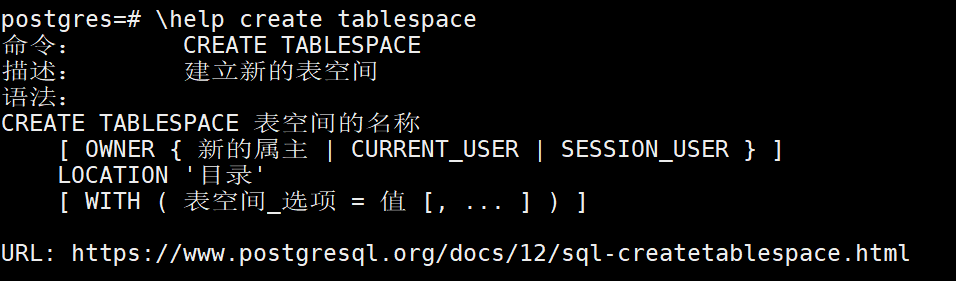
构建表空间,构建表空间需要用户权限是超级管理员,其次需要指定的目录已经存在
create tablespace tp_test location '/var/lib/pgsql/12/tp_test';

构建数据库,以及表,指定到这个表空间中
其实指定表空间的存储位置后,PGSQL会在$PG_DATA目录下存储一份,同时在咱们构建tablespace时,指定的路径下也存储一份。
这两个绝对路径下的文件都有存储表中的数据信息。
/var/lib/pgsql/12/data/pg_tblspc/41015/PG_12_201909212/41016/41020
/var/lib/pgsql/12/tp_test/PG_12_201909212/41016/41020
进一步会发现,其实在PGSQL的默认目录下,存储的是一个link,连接文件,类似一个快捷方式
视图
跟MySQL一样,把一些复杂的操作封装起来,还可以隐藏一些敏感数据。
视图对于用户来说,就是一张真实的表,可以直接基于视图查询一张或者多张表的信息。视图对于开发来说,就是一条SQL语句。
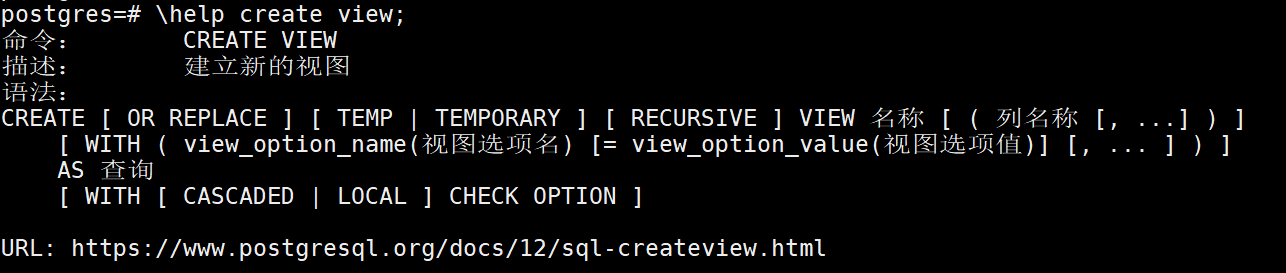
在PGSQL中,简单(单表)的视图是允许写操作的。但是强烈不推荐对视图进行写操作,虽然PGSQL默认允许(简单的视图),写入的时候,其实修改的是表本身。
简单视图
-- 构建一个
create view vw_score as
(select id,math_score from score);select * from vw_score;
update vw_score set math_score = 99 where id = 2;
多表视图
-- 复杂视图(两张表关联)
create view vw_student_score as
(select stu.id as id ,stu.name as name ,score.math_score from student stu,score score where stu.id = score.student_id);select * from vw_student_score;update vw_student_score set math_score =999 where id = 2;

索引
索引的基本概念
索引是数据库中快速查询数据的方法。在提升查询效率的同时,也会带来一些问题:
- 增加了存储空间
- 写操作时,花费的时间比较多
索引可以提升效率,甚至还可以给字段做一些约束。
索引的分类
-
B-Tree索引:最常用的索引。
-
Hash索引:跟MySQL类似,做等值判断。
-
GIN索引:针对字段的多个值的类型,比如数组类型。
创建索引
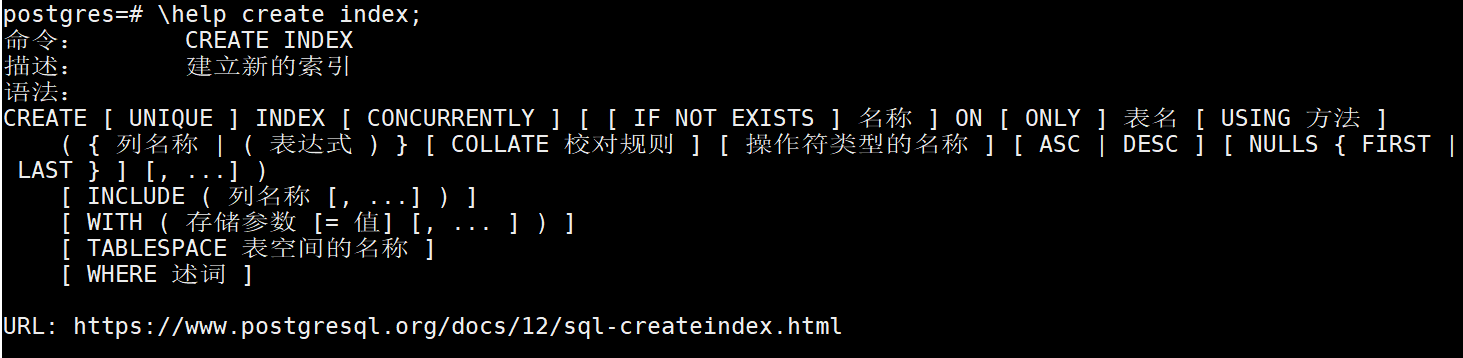
准备大量测试数据,方便查看索引效果
-- 测试索引效果
create table tb_index(id bigserial primary key,name varchar(64),phone varchar(64)[]
);-- 添加300W条数据测试效果
do $$
declarei int := 0;
beginwhile i < 3000000 loopi = i + 1;insert intotb_index(name,phone) values(md5(random()::text || current_timestamp::text)::uuid,array[random()::varchar(64),random()::varchar(64)]);end loop;
end;
$$ language plpgsql;
在没有索引的情况下,先基于name做等值查询,看时间,同时看执行计划
-- c0064192-1836-b019-c649-b368c2be31ca
select * from tb_index where id = 2222222;
select * from tb_index where name = 'c0064192-1836-b019-c649-b368c2be31ca';
explain select * from tb_index where name = 'c0064192-1836-b019-c649-b368c2be31ca';
-- Seq Scan 代表全表扫描
-- 时间大致0.3秒左右
在有索引的情况下,再基于name做等值查询,看时间,同时看执行计划
-- name字段构建索引(默认就是b-tree)
create index index_tb_index_name on tb_index(name);
-- 测试效果
select * from tb_index where name = 'c0064192-1836-b019-c649-b368c2be31ca';
explain select * from tb_index where name = 'c0064192-1836-b019-c649-b368c2be31ca';
-- Index Scan 使用索引
-- 0.1s左右
测试GIN索引效果
在没有索引的情况下,基于phone字段做包含查询
-- phone:{0.6925242730781953,0.8569644964711074}
select * from tb_index where phone @> array['0.6925242730781953'::varchar(64)];
explain select * from tb_index where phone @> array['0.6925242730781953'::varchar(64)];
-- Seq Scan 全表扫描
-- 0.5s左右
给phone字段构建GIN索引,在查询
-- 给phone字符串数组类型字段构建一个GIN索引
create index index_tb_index_phone_gin on tb_index using gin(phone);
-- 查询
select * from tb_index where phone @> array['0.6925242730781953'::varchar(64)];
explain select * from tb_index where phone @> array['0.6925242730781953'::varchar(64)];
-- Bitmap Index 位图扫描
-- 0.1s以内完成
物化视图
前面的普通视图,本质就是一个SQL语句,普通的视图并不会在本地磁盘存储,每次查询视图都是执行这个SQL,效率有点问题。
物化视图从名字上就可以看出来,必然是要持久化一份数据的。使用套路和视图基本一致。这样一来查询物化视图,就相当于查询一张单独的表。相比之前的普通视图,物化视图就不需要每次都查询复杂SQL,每次查询的都是真实的物理存储地址中的一份数据(表),并且可以单独设置索引等信息来提升物化视图的查询效率。
但是有好处就有坏处,更新时间不太好把控。 如果更新频繁,对数据库压力也不小。 如果更新不频繁,会造成数据存在延迟问题,实时性就不好了。
如果要更新物化视图,可以采用触发器的形式,当原表中的数据被写后,可以通过触发器执行同步物化视图的操作。或者就基于定时任务去完成物化视图的数据同步。

-- 构建物化视图
create materialized view mv_test as (select id,name,price from test);
-- 操作物化视图和操作表的方式没啥区别。
select * from mv_test;
-- 操作原表时,对物化视图没任何影响
insert into test values (4,'月饼',50,10);
-- 物化视图的添加操作(不允许写物化视图),会报错
insert into mv_test values (5,'大阅兵',66);
PostgreSQL中,对物化视图的同步,提供了两种方式,一种是全量更新,另一种是增量更新。
全量更新语法,没什么限制,直接执行,全量更新
-- 查询原来物化视图的数据
select * from mv_test;
-- 全量更新物化视图
refresh materialized view mv_test;
-- 再次查询物化视图的数据
select * from mv_test;
增量更新,增量更新需要一个唯一标识,来判断哪些是增量,同时也会有行数据的版本号约束。
-- 查询原来物化视图的数据
select * from mv_test;
-- 给物化视图添加唯一索引。
create unique index index_mv_test on mv_test(id);
-- 增量更新物化视图
refresh materialized view concurrently mv_test;
-- 再次查询物化视图的数据
select * from mv_test;
-- 增量更新时,即便是修改数据,物化视图的同步,也会根据一个xmin和xmax的字段做正常的数据同步update test set name = '汤圆' where id = 5;
insert into test values (5,'猪头肉',99,40);
select * from test;
相关文章:
PostgreSQL 数据定义语言 DDL
文章目录 表创建主键约束非空唯一约束检查约束外键约束默认值约束 触发器表空间构建表空间 视图索引索引的基本概念索引的分类创建索引 物化视图 表创建 PostgreSQL表的构建语句与所有数据库都一样,结构如下,其核心在于构建表时,要指定上一些…...

设计模式-行为型模式-策略模式
一、什么是策略模式 策略模式是一种行为设计模式,它允许在运行时选择算法或行为,并将其封装成独立的对象,使得这些算法或行为可以相互替换,而不影响使用它们的客户端。(ChatGPT生成) 主要组成部分ÿ…...
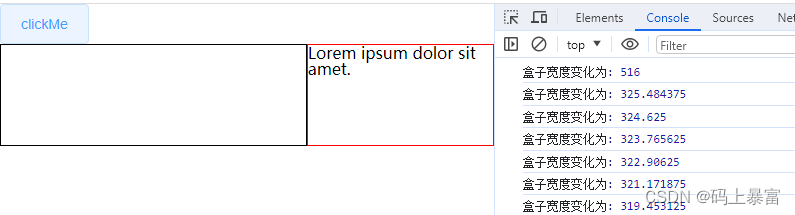
ResizeObserver观察元素宽度的变化
ResizeObserver观察元素宽度的变化 ResizeObserver观察元素宽度的变化 ResizeObserver观察元素宽度的变化 ResizeObserver 构造函数创建一个新的 ResizeObserver 对象,它可以用于监听 Element 内容盒或边框盒或者 SVGElement 边界尺寸的大小。查看详细说明 案例 &l…...

斐波那契数列,剑指offer,力扣
目录 题目地址: 我们直接看题解吧: 解题方法: 难度分析: 审题目事例提示: 解题思路(动态规划): 代码实现: 补充说明: 代码(优化)&…...

Mac安装CocoaPods
安装HomeBrew 安装 % /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"安装失败 % /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"curl: (28) F…...
)
APP专项测试方法和工具的使用(测试新手必看)
APP专项测试 1、网络测试 可使用抓包工具辅助网格测试推荐:fiddler,Charles (1)网络切换2G-3G-4G-wifi-网络信号差--无网(2)网络信号弱关注是否出现ANR、crash 2、中断测试 (1)…...

WordPress网站迁移实战经验
前几日,网站服务器到期,换了服务商,就把我的WordPress的网站迁移到本地电脑了。方便以后文章迁移。 本次迁移网站主要经历以下几个步骤。 1.域名转出。 2.备份数据库及网站文件下载。 3.重新搭建WordPress网站。 4.网站文件及数据库导入。 下面详细介绍下每个步骤的操作…...

3D全景视角,足不出户感知真实场景的魅力
近年来,随着科技的快速发展,普通的平面静态视角已经无法满足我们了,不管是视角框架的限制还是片面的环境展示,都不足以让我们深入了解场景环境。随着VR全景技术的日益成熟,3D全景技术的出现为我们提供了全新的视觉体验…...
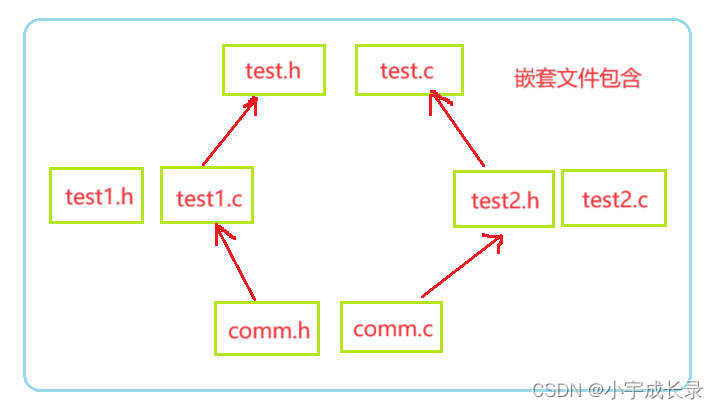
C编译环境和预处理(非常详细,建议收藏)
C编译环境和预处理(非常详细,建议收藏) 一、程序的翻译环境和执行环境二、 详解编译链接2.1 翻译环境2.2 编译本身的几个阶段符号汇总、符号表、合并段表、符号表的合并和重定位分别是什么? 2.2 运行环境 三、预处理详解3.1 预定义…...

LeetCode669. Trim a Binary Search Tree
文章目录 一、题目二、题解 一、题目 Given the root of a binary search tree and the lowest and highest boundaries as low and high, trim the tree so that all its elements lies in [low, high]. Trimming the tree should not change the relative structure of the …...

YOLOv8优化策略:轻量级Backbone改进 | VanillaNet极简神经网络模型 | 华为诺亚2023
🚀🚀🚀本文改进:一种极简的神经网络模型 VanillaNet,支持vanillanet_5, vanillanet_6, vanillanet_7, vanillanet_8, vanillanet_9, vanillanet_10, vanillanet_11等版本 🚀🚀🚀YOLOv8改进专栏:http://t.csdnimg.cn/hGhVK 学姐带你学习YOLOv8,从入门到创新,…...
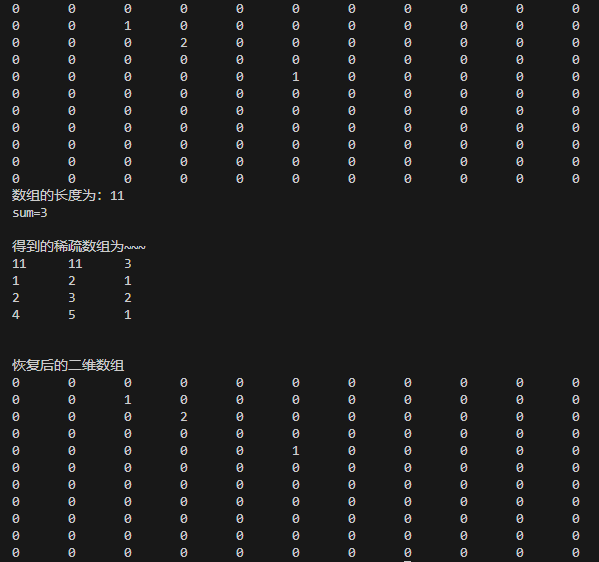
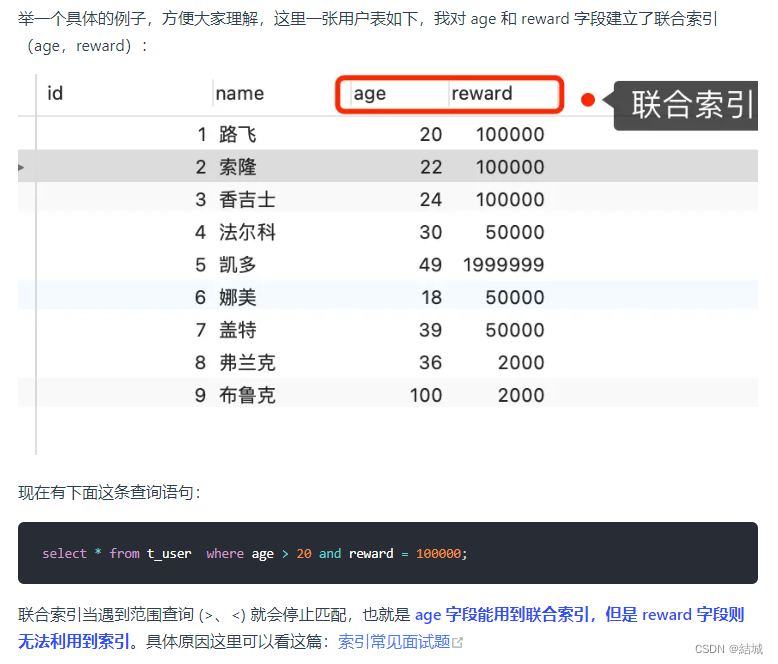
【数据结构(二)】稀疏 sparsearray 数组(1)
文章目录 1. 稀疏数组的应用场景1.1. 一个实际的需求1.2. 基本介绍 2. 稀疏数组转换的思路分析3. 稀疏数组的代码实现3.1. 二维数组转稀疏数组3.2. 稀疏数组转二维数组 4. 课后练习 1. 稀疏数组的应用场景 1.1. 一个实际的需求 问题: 编写的五子棋程序中&…...
MySQL的执行器是怎么工作的
作为优化器后的真正执行语句的层,执行器有三种方式和存储引擎(一般是innoDB)交互 主键索引查询 查询的条件用到了主键,这个是全表唯一的,优化器会选择const类型来查询,然后while循环去根据主键索引的B树结…...

【目标测距】雷达投影测距
文章目录 前言一、读取点云二、点云投影图片三、读取检测信息四、点云投影测距五、学习交流 前言 雷达点云投影相机。图片目标检测,通过检测框约束等等对目标赋予距离。计算消耗较大,适合离线验证操作。在线操作可以只投影雷达检测框。 一、读取点云 py…...

uniapp、小程序canvas相关
1、圆形or圆形头像 //示例 const ctx uni.createCanvasContext(myCanvas); //canvas const round uni.upx2px(72) / 2; // 半径 const x uni.upx2px(92); //目标x轴位置 const y uni.upx2px(236); //目标y轴位置//if 图片是不是静态资源 async > const imgSrc https:/…...
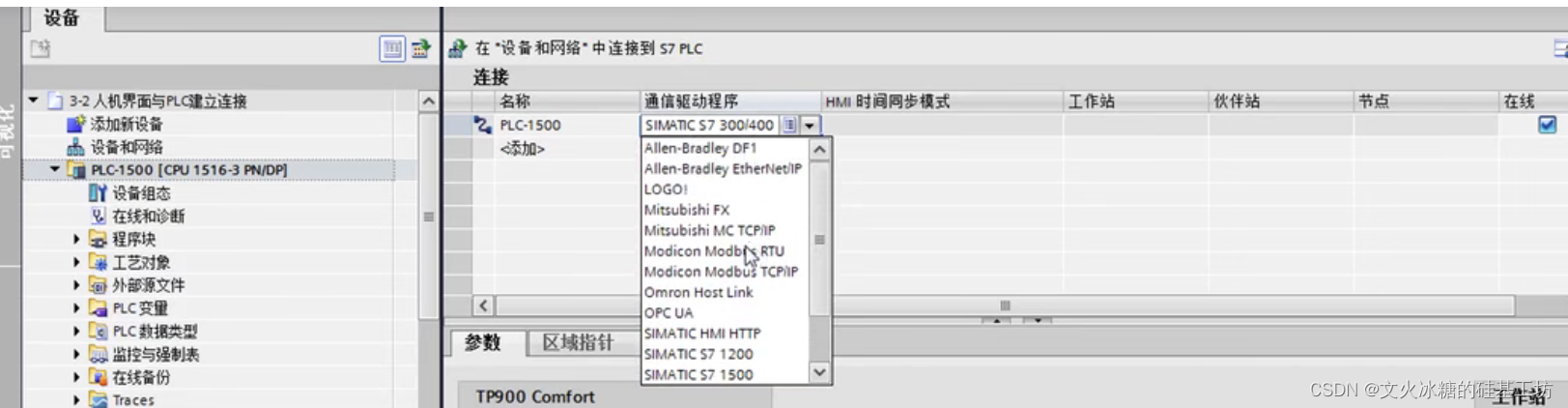
[工业自动化-23]:西门子S7-15xxx编程 - 软件编程 - 西门子PLC人机界面交互HMI功能概述、硬件环境准备、软件环境准备
目录 一、什么是人机界面 二、什么是PLC人机交互界面HMI 三、人机界面设计的功能列表 四、开发主机与PLC的连接方式 五、开发主机与HMI的连接方式 六、HMI组态 一、什么是人机界面 人机界面是指人与机器或系统之间的交互界面。它是人类与计算机或其他设备之间进行信息交换…...

在Ubuntu系统中安装VNC并结合内网穿透实现公网远程访问
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

java基础练习缺少项目?看这篇文章就够了(上)!
公众号:全干开发 。 专注分享简洁但高质量的动图技术文章! 项目概述 本教程适合刚学习完java基础语法的同学,涉及if语句、循环语句、类的封装、集合等基础概念,使用大量gif图帮助读者演示代码操作、效果等,是一个非常…...

鸿蒙为什么使用typescript 作为开发语言 而不是 flutter 或者 kotlin
猜想如下 dev studio 是基于 idea 二次开发的 ,使用kotlin 应该是更合理 变成 jetbrain 全家桶, 但是 现在android 开发也是kotlin 是不是为了做分割 ,所以不使用kotlin flutter 是谷歌的 安卓也是谷歌的 所以不采用 typescript 是微软的…...

Flutter NestedScrollView 、SliverAppBar全解析,悬浮菜单的应用
在我们开发过程中经常会使用到悬浮菜单的使用,当我们滑动到指定位置后,菜单会自动悬浮。 实现效果如下(左为滑动前、右为滑动后): 上述便是通过NestedScrollView 、SliverAppBar实现的效果,通过两个控件我…...

RAG + Agent = 王炸组合:知识增强型Agent详解
完整版合集、面试题库、项目实战,全网同名【图解 AI 系列】前几篇文章我们讲了Agent的核心能力:调用工具、记忆系统、规划能力、多Agent协作。但有一个问题一直没解决:Agent的知识从哪来? 大模型的知识是训练时学到的,…...

用Python手把手复现NRBO优化算法:从数学公式到完整代码的保姆级教程
用Python手把手复现NRBO优化算法:从数学公式到完整代码的保姆级教程 优化算法在工程和科学计算中扮演着关键角色,而牛顿-拉弗森优化算法(NRBO)作为最新提出的智能优化方法,凭借其高效的收敛性能引起了广泛关注。本文将彻底拆解NRBO的核心机制…...

调查研究-142 全球机器人产业深度调研报告【04篇】机器人产业利润池全景:谁最容易赚钱与十大判断指标
TL;DR 场景:关注机器人产业投资、创业、就业方向的投资者、从业者、分析师结论:医疗机器人耗材/服务>高端核心零部件>系统集成>物流RaaS>工业本体>软件AI平台;人形机器人长期空间大但短期商业化仍早产出:三档利润池…...

AI工程师必备:三款主流工具的实操落地指南
1. 项目概述:一份真正“够用”的AI资讯简报,到底长什么样?你有没有过这种体验:每天早上打开邮箱,收进十几封AI领域的Newsletter——有的标题写着“深度解析LLM推理优化”,点开发现通篇是论文摘要堆砌&#…...

Sunshine游戏串流实战指南:构建跨平台私人云游戏服务器完整方案
Sunshine游戏串流实战指南:构建跨平台私人云游戏服务器完整方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经希望将高配置PC上的游戏体验延伸到客厅电视、…...

2026年国内镜像站安全与效率评测:GPT-5.5的真实体验
在国内访问海外大模型,延迟高、连接不稳、支付合规是老生常谈的三座大山。为了完成本次GPT-5.5的全流程实测,我借助库拉AI聚合平台完成了所有调用——该平台支持国内外主流AI模型的统一对接,国内可直连访问,注册用户每日提供可用额…...
)
Sora 2提示词失效真相大起底(92%用户踩中的3类语义断层陷阱)
更多请点击: https://kaifayun.com 第一章:Sora 2提示词失效的底层归因与认知重构 Sora 2提示词失效并非表层的语法错误或格式偏差,而是源于其多模态对齐机制中语义解码器与时空生成器之间的结构性错配。当用户输入“雨夜东京涩谷十字路口&a…...

机器学习驱动的中微子-核散射截面建模:从数据学习到振荡分析
1. 项目概述与核心价值 中微子物理正步入一个前所未有的“精密测量”时代。像DUNE(深地下中微子实验)这样的下一代长基线实验,目标是将中微子混合参数的测量精度推至百分之一量级。然而,一个长期存在的“拦路虎”限制了这一目标的…...

Bazzite:专为游戏玩家打造的Linux操作系统深度解析
Bazzite:专为游戏玩家打造的Linux操作系统深度解析 【免费下载链接】bazzite Bazzite makes gaming and everyday use smoother and simpler across desktop PCs, handhelds, tablets, and home theater PCs. 项目地址: https://gitcode.com/gh_mirrors/ba/bazzit…...

终极德州扑克GTO求解器完整指南:从零开始掌握博弈论最优策略的三大突破
终极德州扑克GTO求解器完整指南:从零开始掌握博弈论最优策略的三大突破 【免费下载链接】TexasSolver 🚀 A very efficient Texas Holdem GTO solver :spades::hearts::clubs::diamonds: 项目地址: https://gitcode.com/gh_mirrors/te/TexasSolver …...