最强英文开源模型Llama2架构与技术细节探秘
prerequisite: 最强英文开源模型LLaMA架构探秘,从原理到源码
Llama2
Meta AI于2023年7月19日宣布开源LLaMA模型的二代版本Llama2,并在原来基础上允许免费用于研究和商用。
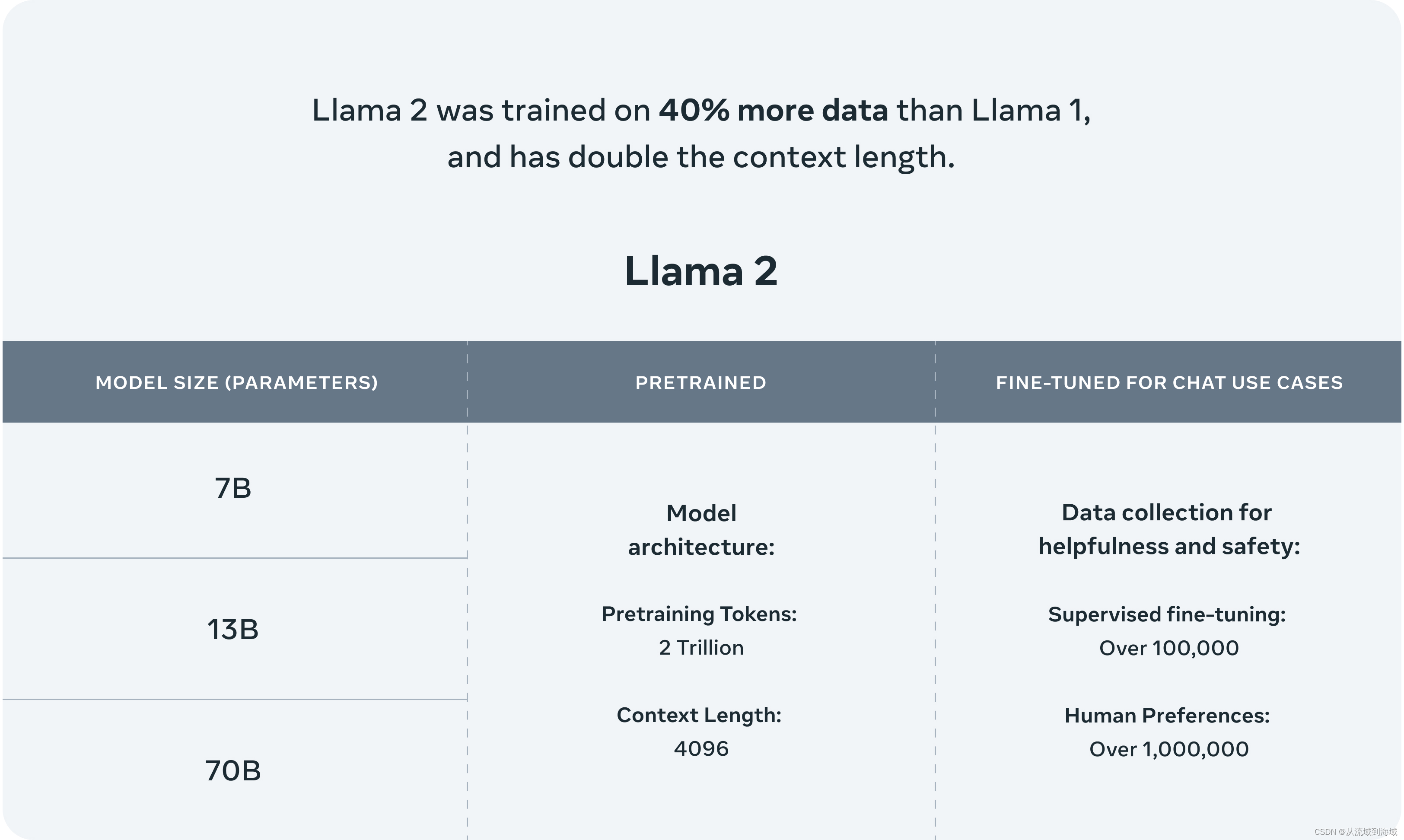
作为LLaMA的延续和升级,Llama2的训练数据扩充了40%,达到2万亿token,并且可处理的上下文增倍,达到4096个token。整体finetuning过程使用了1百万人工标记数据。开源的基座模型包括7B、13B、70B3个版本,并提供了对话增强版本的Llama chat和代码增强版本的Code Llama,供开发者和研究人员使用。
两代模型架构区别
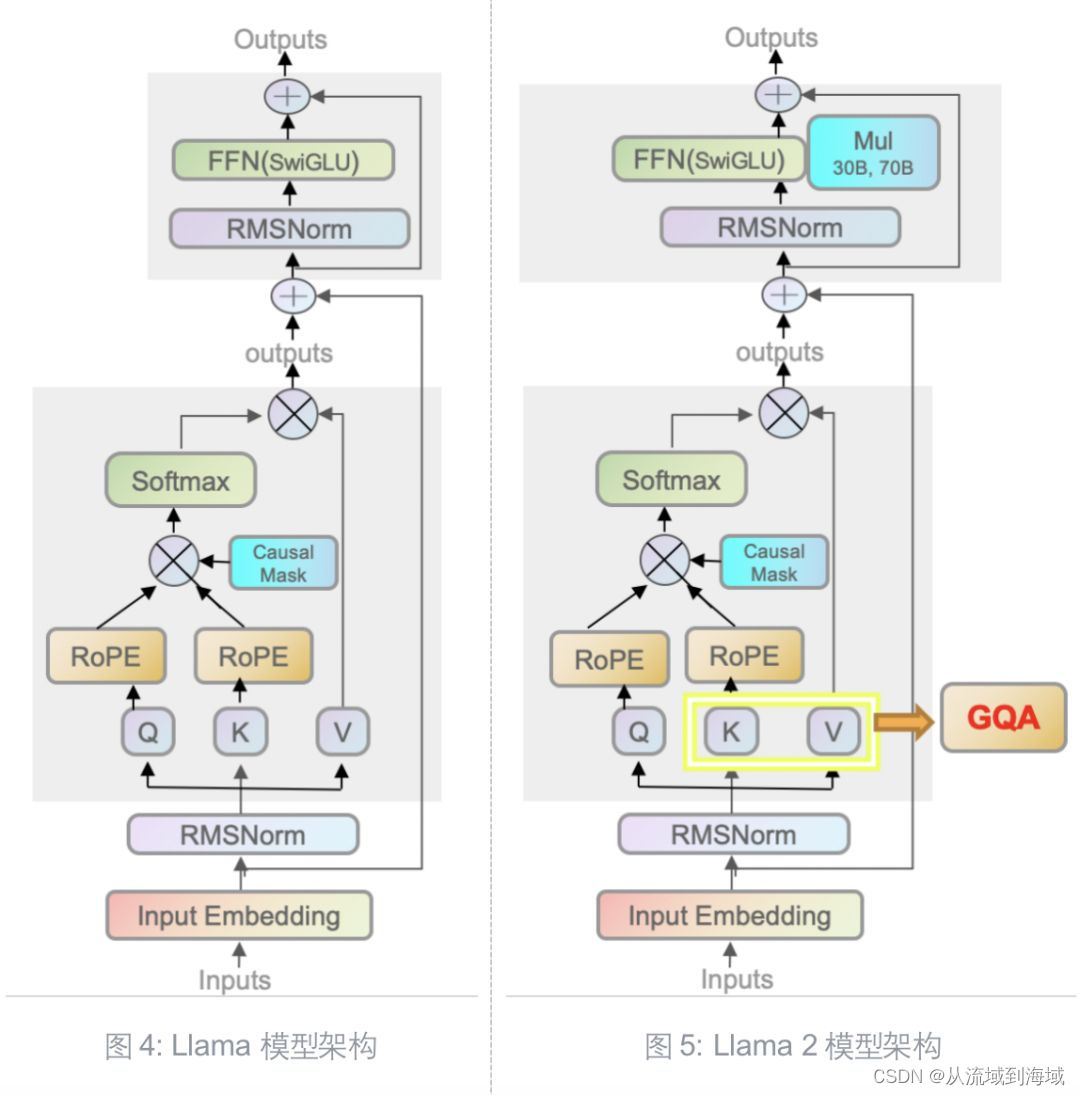
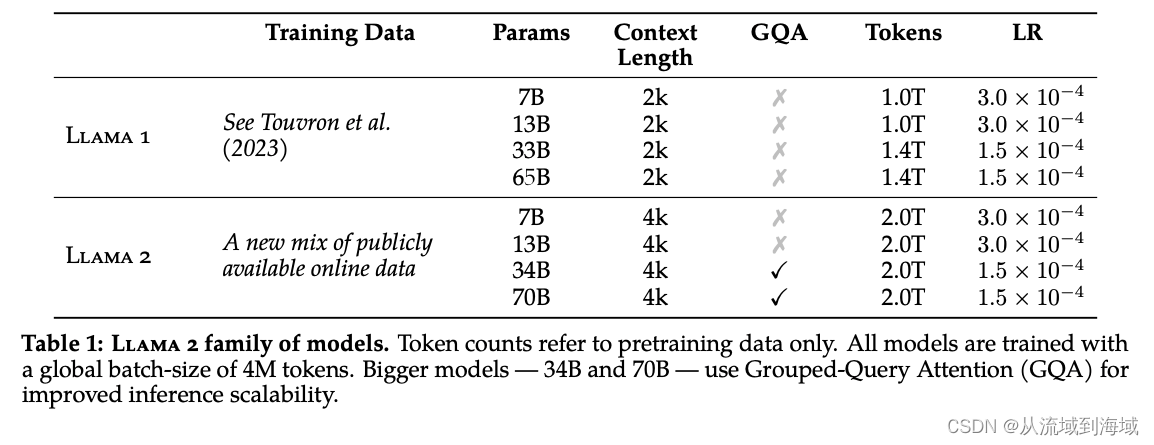
Llama 2和初代模型相比,仍然延续Transformer’s decoder-only架构,仍然使用Pre-normalization、SwiGLU激活函数、旋转嵌入编码(RoPE),区别仅在于前述的40%↑的训练数据、更长的上下文和分组查询注意力机制(GQA, Grouped-Query Attention)。
Group-Query Attention
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
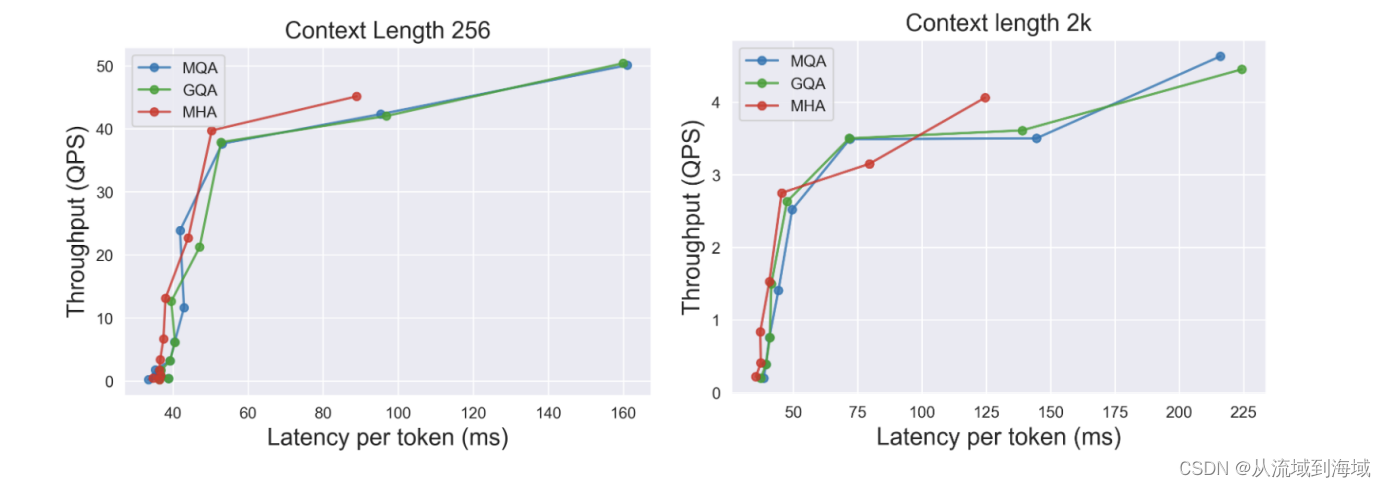
引入GQA的主要目的是提升推理速度,这种注意力机制有transformer的Multi-head Attention简化而来,再辅以KV cache的checkpoint机制进一步提速。
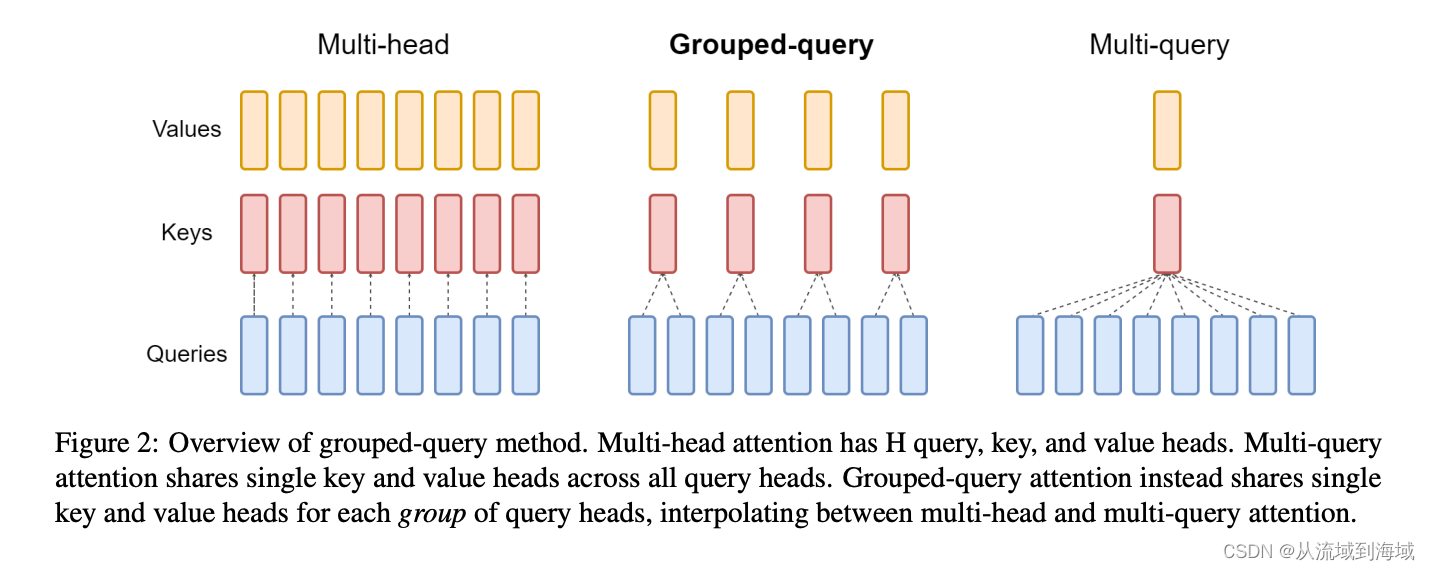
如上图:
- 左边是transformer原始的Multi-head Attention,它有H个query,key,value,即每个query单独配一个key和value
- 右边是其他研究者提出的Multi-query Attention,它在多个query共享同一个key和value
- 中间则是折中的Grouped-query Attention,它将query进行了分组,仅在组内共享同一个key和value
具体而言,Llama2使用了8组KV映射,即GQA-8,实测效果上接近MHA,推理速度上接近MQA,尽可能做到了效果和速度兼得。
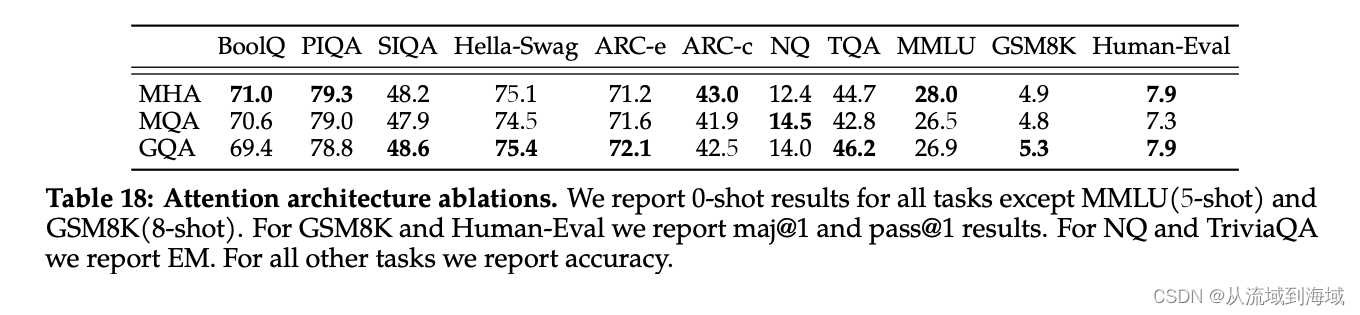
对比其他模型
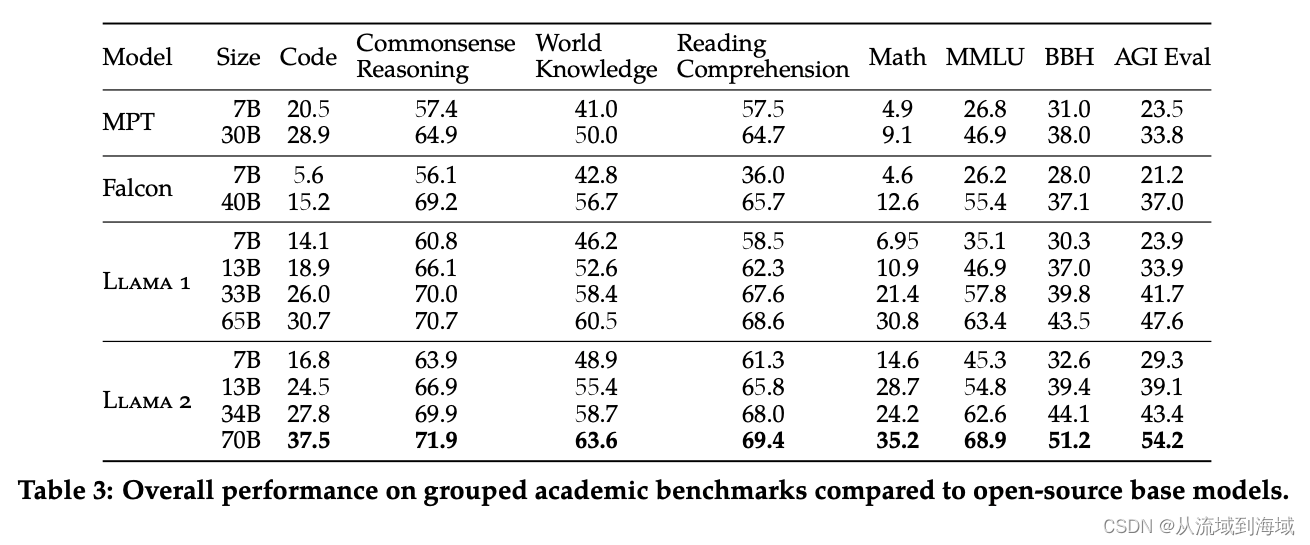
Llama2在一众开源模型中遥遥领先。
笔者注:模型架构没有太大变化,GQA只是推理加速,但效果提升,那也就是说明主要得益于新增的那40%的数据。坦白讲,大模型阶段模型架构已经不那么重要了,可以保证一定的推理速度即可,效果上dataset is all you need。
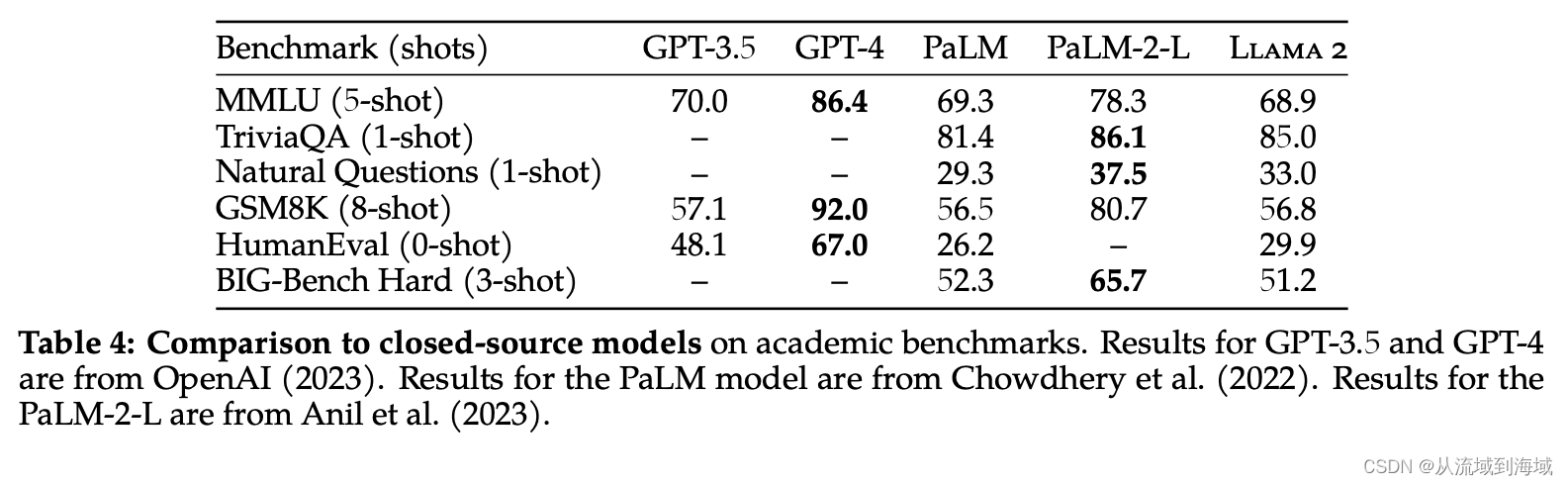
但在闭源模型的比较上,Llama2仅领先PaLM,且仅能做到在MMLU和GSM8K两个数据集上接近GPT3.5,与PaLM-2-L和GPT-4相比,仍然落后不少。
Llama-chat训练流程

下面我们来聊一聊llama-chat的训练流程,详见原技术论文,以下仅做流程概述:
- 自监督预训练
- 监督精调
- RLHF
a. 自人类偏好数据集中训练2个奖励模型,分别是Safety Reward Model和Helpful Reward Model,一个用于对人类偏好进行奖励建模,一个对安全合规进行奖励建模
b. 先使用Helpful Reward模型进行RLHF,基于Rejection Sampling和PPO
c. 在helpful的基础上进一步提升安全性,使用Safety Reward Model进行RLHF,也是基于Reject Sampling和PPO,实验证明,Safety RLHF能在不损害helpfulness的前提下有更好的长尾safety棒性
重要的细节上:
- PPO(Proximal Policy Optimization),即标准的RLHF使用的方法
- Rejection Sampling fine-tuning(拒绝采样微调):采样模型的k个输出,并选择奖励模型认为最好的样本作为输出进行梯度更新
两种RL算法的区别是:
- 广度上:PPO仅进行一次生成;Reject Sampling会生成k个样本,从中选取奖励最大化的样本
- 深度上:PPO的第t步训练过程的样本是t-1步更新的模型策略函数;Reject Sampling的训练过程相当于对模型当前策略下的所有输出进行采样,相当于是构建了一个新的数据集,然后在进行类似于SFT的微调
Meta仅在最大的Llama2 70B使用了Reject Sampling,其余模型仅使用了PPO。
Code-Llama
2023年8月24日,Meta推出了面向代码的可商用代码大模型Code Llama,开源了3个版本7B/13B/34B。支持多种编程语言,包括Python、C++、Java、PHP、Typescript (Javascript)、C#和Bash。
训练流程如下图:
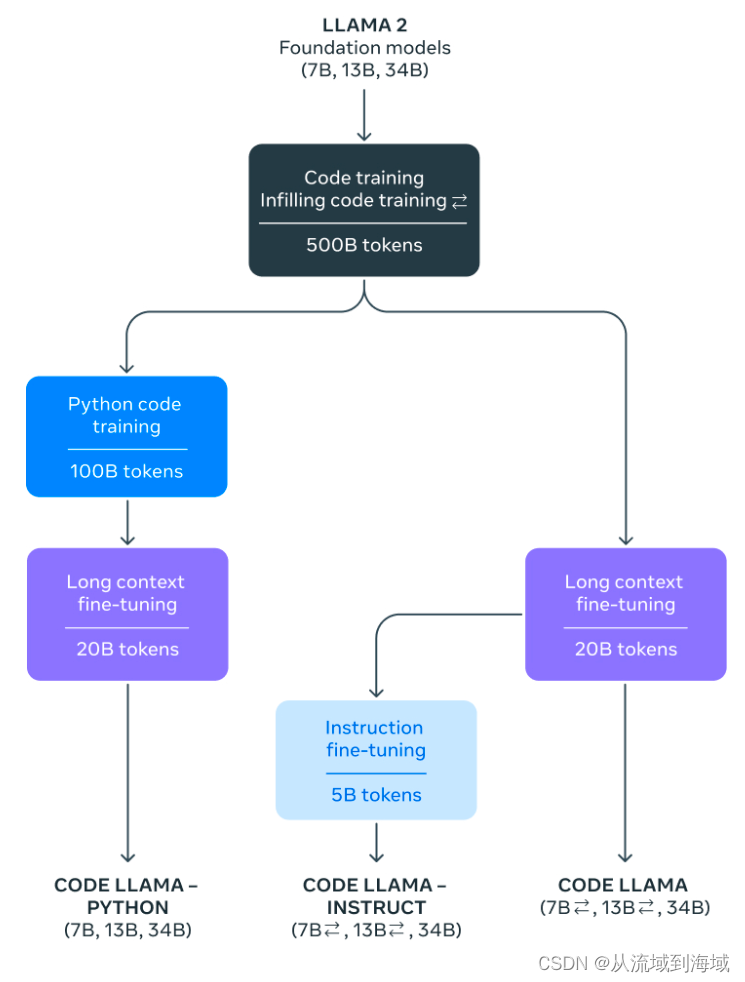
如图所示,包含3个分支模型,每个分支模型的第一步都是使用500B的token进行Code Training和Infilling code training
- Code Llama-Python(面向python语言的代码模型),第一步之后先用100B token的python代码进行训练,然后再使用20B的token在长上下文的场景上进行finetuning得到最终模型
- Code Llama(通用代码模型),第一步之后使用20B的token在长上下文的场景上进行finetuning得到最终模型
- Code Llama-Instruct(面向对话的代码模型),第一步之后同Code Llama使用20B的token在长上下文的场景上进行finetuning,然后再在5B的token上进行指令精调
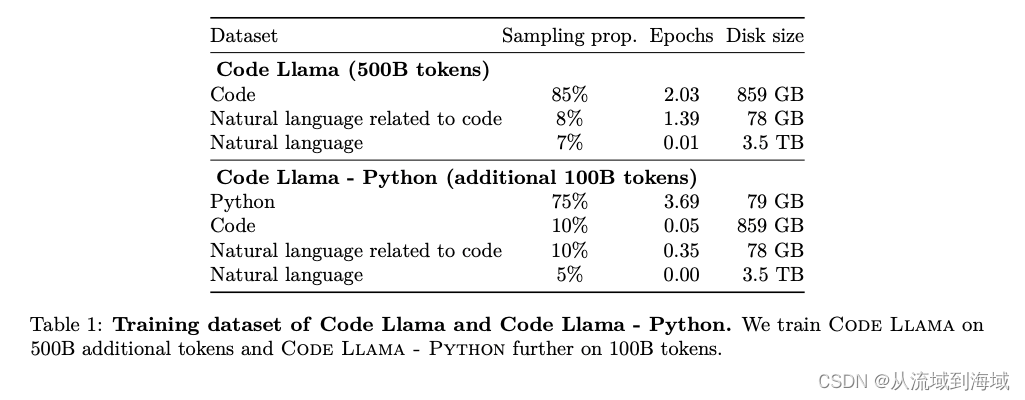
训练集详情如下:
细节上:
- Code Training即使用代码数据进行训练
- Code Infilling值得是根据代码上下文预测残缺的代码部分,仅针对代码文本进行挖空预测,方法与Bert的挖空预测类似:
a. 从完整的代码中选择一部分进行掩码(mask)并替换为<MASK>符号,构成上下文作为输入
b. 然后采用自回归的方式对mask进行预测
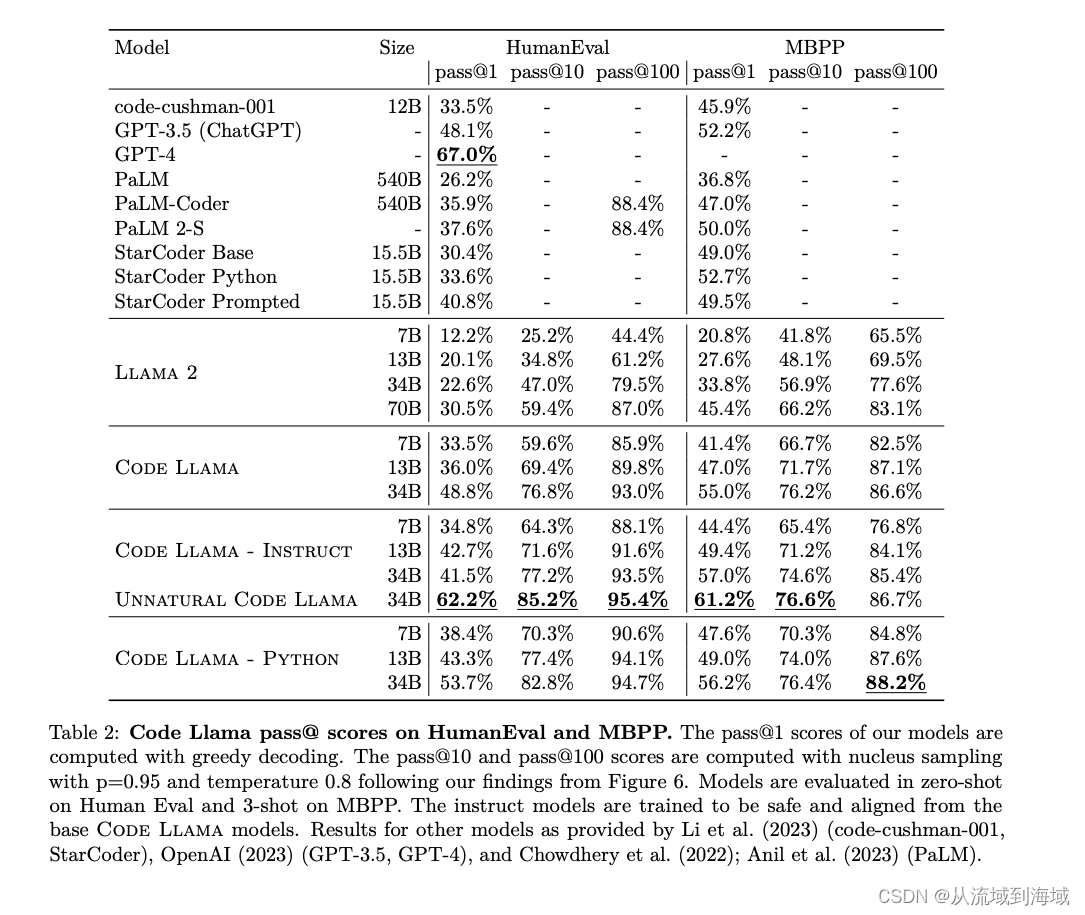
模型效果对比上,神秘的unnatural版本在HumanEval的pass@1上领先GPT-3,接近于GPT-4(5%左右差距),其余部分明显领先PaLM系列和StarCoder系列模型:
参考文献
- https://ai.meta.com/llama/
- Llama 2: Open Foundation and Fine-Tuned Chat Models
- 大模型技术实践(二)|关于Llama 2你需要知道的那些事儿
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
- 大规模预训练语言模型方法与实践,崔一鸣,北京BAAI,2023年8月26日
- https://ai.meta.com/blog/code-llama-large-language-model-coding/
- Code Llama: Open Foundation Models for Code
相关文章:
最强英文开源模型Llama2架构与技术细节探秘
prerequisite: 最强英文开源模型LLaMA架构探秘,从原理到源码 Llama2 Meta AI于2023年7月19日宣布开源LLaMA模型的二代版本Llama2,并在原来基础上允许免费用于研究和商用。 作为LLaMA的延续和升级,Llama2的训练数据扩充了40%,达到…...
编程刷题网站以及实用型网站推荐
1、牛客网在线编程 牛客网在线编程https://www.nowcoder.com/exam/oj?page1&tab%E8%AF%AD%E6%B3%95%E7%AF%87&topicId220 2、力扣 力扣https://leetcode.cn/problemset/all/ 3、练码 练码https://www.lintcode.com/ 4、PTA | 程序设计类实验辅助教学平台 PTA | 程…...
基于STC12C5A60S2系列1T 8051单片机的SPI总线器件数模芯片TLC5615实现数模转换应用
基于STC12C5A60S2系列1T 8051单片的SPI总线器件数模芯片TLC5615实现数模转换应用 STC12C5A60S2系列1T 8051单片机管脚图STC12C5A60S2系列1T 8051单片机I/O口各种不同工作模式及配置STC12C5A60S2系列1T 8051单片机I/O口各种不同工作模式介绍SPI总线器件数模芯片TLC5615介绍通过按…...

【并发编程】Synchronized的使用
📫作者简介:小明java问道之路,2022年度博客之星全国TOP3,专注于后端、中间件、计算机底层、架构设计演进与稳定性建设优化,文章内容兼具广度、深度、大厂技术方案,对待技术喜欢推理加验证,就职于…...

【Python】Python基础
文章目录 一、字面值常量和表达式二、变量2.1 定义变量2.2 变量的命名规则2.3 变量的类型2.4 不同类型大小2.5 动态类型 三、注释四、输入与输出五、运算符5.1 算术运算符5.2 关系运算符5.3 逻辑运算符5.4 赋值运算符 一、字面值常量和表达式 print(1 2 * 3) # 7 print(1 2 …...
gitlab环境准备
1.准备环境 gitlab只支持linux系统,本人在虚拟机下使用Ubuntu作为操作系统,gitlab镜像要使用和操作系统版本对应的版本,(ubuntu18.04,gitlab-ce_13.2.3-ce.0_amd64 .deb) book100ask:/$ lsb_release -a No LSB modules are available. Dist…...

Apache Doris (五十四): Doris Join类型 - Bucket Shuffle Join
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 目录...

【AI】行业消息精选和分析(23-11-20)
技术发展 🎨 LCM即时绘画,体验所见所得: - LCM LoRA支持即时绘图生成,体验直观。 - 在线体验地址提供直接访问。 - 清华大学SimianLuo开发,加速稳定扩散模型运行。 💊 VM Pill:可吞咽装置追踪生…...
Matplotlib实现Label及Title都在下方的最佳姿势
Matplotlib实现Label及Title都在下方的最佳姿势 1. 问题背景2. 基本思想(可以不看)3. 方法封装4. 调用实例5. 总结6. 起飞 1. 问题背景 用python绘制下面这种图的时候,一般用xlable作为子图的标题,这是因为plt.title()方法绘制的…...

使用 uWSGI 部署 Django 应用详解
概要 部署 Django 应用到生产环境是一个至关重要的步骤,其中选择合适的 WSGI 服务器对于确保应用的稳定性和性能至关重要。uWSGI 是一个流行的选择,它不仅高效、轻量,还非常灵活。本文将详细介绍如何使用 uWSGI 来部署 Django 应用ÿ…...

MyBatis在注解中使用动态查询
以前为了使用注解并在注解中融入动态查询,会使用Provider。后来发现只要加入"<script>包含动态查询的SQL语句</script>"就可以了。 例如: Select("<script>" "select v.*,u.avatar,u.nickname from videos…...

百云齐鲁 | 云轴科技ZStack成功实践精选(山东)
山东省作为我国重要的工业基地和北方地区经济发展的战略支点,在“十四五”规划中将数字强省建设分为数字基础设施、数字科技、数字经济、数字政府、数字社会、数字生态六大部分,涵盖政治、经济、民生等多个方面,并将大数据、云计算、人工智能…...
【Electron】electron-builder打包失败问题记录
文章目录 yarn下载的包不支持require()winCodeSign-2.6.0.7z下载失败nsis-3.0.4.1.7z下载失败待补充... yarn下载的包不支持require() 报错内容: var stringWidth require(string-width)^ Error [ERR_REQUIRE_ESM]: require() of ES Module /stuff/node_modules/…...
OpenCV快速入门:直方图、掩膜、模板匹配和霍夫检测
文章目录 前言一、直方图基础1.1 直方图的概念和作用1.2 使用OpenCV生成直方图1.3 直方图归一化1.3.1 直方图归一化原理1.3.2 直方图归一化公式1.3.3 直方图归一化代码示例1.3.4 OpenCV内置方法:normalize()1.3.4.1 normalize()方法介绍1.3.4.2 normalize()方法参数…...
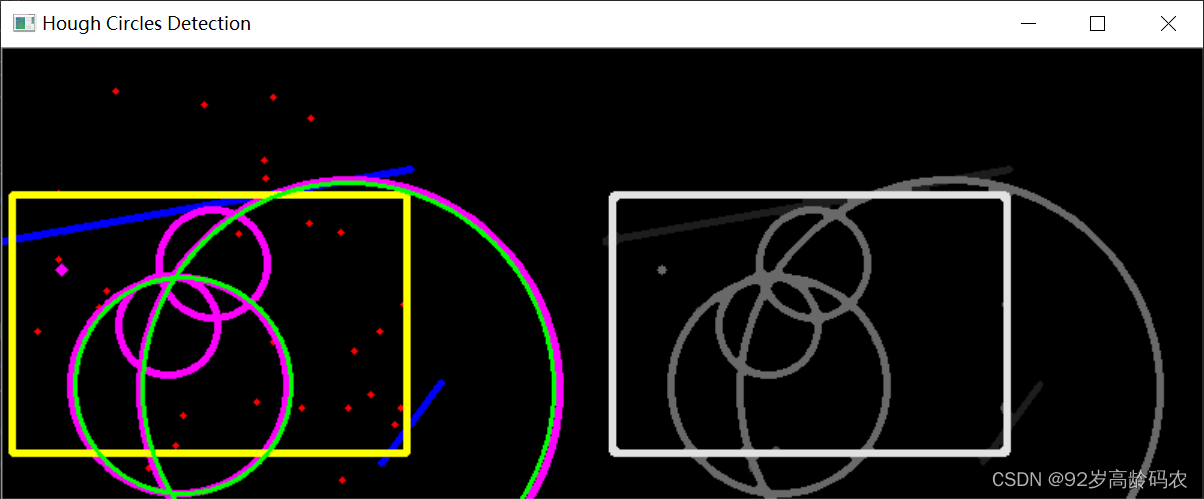
HDD与QLC SSD深度对比:功耗与存储密度的终极较量
在当今数据世界中,存储设备的选择对于整体系统性能和能耗有着至关重要的影响。硬盘HDD和大容量QLC SSD是两种主流的存储设备,而它们在功耗方面的表现是许多用户关注的焦点。 扩展阅读: 1.面对SSD的步步紧逼,HDD依然奋斗不息 2.…...

医疗软件制造商如何实施静态分析,满足 FDA 医疗器械网络安全验证
随着 FDA 对网络安全验证和标准提出更多要求,医疗软件制造商需要采用静态分析来确保其软件满足这些新的安全标准。继续阅读以了解如何实施静态分析来满足这些安全要求。 随着 FDA 在其软件验证指南中添加更多网络安全要求,医疗设备制造商可以转向静态分…...

【设计模式】聊聊策略模式
策略模式的本质是为了消除if 、else代码,提供拓展点,对拓展开放,对修改关闭,也就是说我们开发一个功能的时候,要尽量的采用设计模式进行将不变的东西进行抽取出来,将变化的东西进行隔离开来,这样…...

二维偏序问题
偏序 偏序(Partial Order)的概念: 设 A 是一个非空集,P 是 A 上的一个关系,若 P 满足下列条件: Ⅰ 对任意的 a ∈ A,(a, a) ∈ P;(自反性 reflexlve)Ⅱ 若 (a, b) ∈ P,且 (b, a) ∈ P,则 a = b;(反对称性,anti-symmentric)Ⅲ 若 (a, b) ∈ P,(b, c) ∈ P,则 (a,…...

解析Spring Boot中的CommandLineRunner和ApplicationRunner:用法、区别和适用场景详解
在Spring Boot应用程序中,CommandLineRunner和ApplicationRunner是两个重要的接口,它们允许我们在应用程序启动后执行一些初始化任务。本文将介绍CommandLineRunner和ApplicationRunner的区别,并提供代码示例和使用场景,让我们更好…...

谷歌浏览器版本下载
Chrome 已是最新版本 版本 119.0.6045.160(正式版本) (64 位) 自定义chrome https://www.sysgeek.cn/chrome-new-tab-page-customize/ chrome怎么把标签放主页 https://g.pconline.com.cn/x/1615/16153935.html 谷歌浏览器怎么设…...

基于国产可控硅LTH16-08的电风扇无极调速方案设计与实践
1. 项目概述:当可控硅遇上电风扇 最近在帮一个做小家电的朋友优化一款电风扇的电路板,核心需求是想实现一个无极调速功能,让风扇的风量可以从微风到强风平滑过渡,而不是传统的三档或五档机械开关。这个需求听起来简单,…...

PyTorch新手必看:RuntimeError: mat1 and mat2 shapes cannot be multiplied 的三种常见场景与快速排查法
PyTorch矩阵维度冲突实战指南:从报错原理到精准修复 当你满怀期待地按下运行键,等待模型开始训练时,突然跳出的RuntimeError: mat1 and mat2 shapes cannot be multiplied就像一盆冷水浇下来。这个在PyTorch中频繁出现的矩阵乘法维度错误&am…...

2026年腾讯云OpenClaw/Hermes Agent配置Token Plan搭建保姆教程
2026年腾讯云OpenClaw/Hermes Agent配置Token Plan搭建保姆教程。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

5分钟快速上手!免费开源字幕编辑器Subtitle Edit终极使用指南
5分钟快速上手!免费开源字幕编辑器Subtitle Edit终极使用指南 【免费下载链接】subtitleedit the subtitle editor :) 项目地址: https://gitcode.com/gh_mirrors/su/subtitleedit 你是否正在寻找一款功能强大且完全免费的字幕编辑软件?Subtitle …...

企业级应用如何通过Taotoken聚合API管理多个大模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何通过Taotoken聚合API管理多个大模型调用 在构建企业级AI应用时,一个常见的需求是同时接入多个不同厂商的…...

SQLite Viewer:3分钟学会在线查看SQLite数据库的终极方案
SQLite Viewer:3分钟学会在线查看SQLite数据库的终极方案 【免费下载链接】sqlite-viewer View SQLite file online 项目地址: https://gitcode.com/gh_mirrors/sq/sqlite-viewer 想象一下,你收到一个SQLite数据库文件,需要立即查看其…...
二进制序列化)
(QBuffer配合 QDataStream)二进制序列化
QByteArray arr; QBuffer buf(&arr); buf.open(QIODevice::WriteOnly); QDataStream out(&buf); out << QString(“hello”) << 123; // 序列化 // 反序列化 buf.seek(0); QDataStream in(&buf); QString s; int n; in >> s >> n;...

VMware虚拟机安装及配置
密码 # 设置 root 用户密码 sudo passwd root修改国内镜像源 在 Ubuntu 24.04 之前,Ubuntu 的软件源配置文件路径为 /etc/apt/sources.list;从 Ubuntu 24.04 开始,Ubuntu 的软件源配置文件变更为 DEB822 格式,路径为 /etc/apt/so…...

大模型的“文字障眼法“:FlipAttack 文本反转越狱技术全解析
一、先打个比方:你听说过"倒着说话"绕过安检吗? 想象一下,有个调皮的小孩想带进游乐园一个违禁品。安检人员耳朵很尖,一听到"炸弹""刀具"这些词就会拦人。于是小孩想了个办法——把话说反。 “我要…...

Adobe-GenP:创意工作者的智能许可证管理解决方案
Adobe-GenP:创意工作者的智能许可证管理解决方案 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 在数字创意领域,Adobe Creative Cloud系列软…...