2023.11.17-hive调优的常见方式
目录
0.设置hive参数
1.数据压缩
2.hive数据存储格式
3.fetch抓取策略
4.本地模式
5.join优化操作
6.SQL优化(列裁剪,分区裁剪,map端聚合,count(distinct),笛卡尔积)
6.1 列裁剪:
6.2 分区裁剪:
6.3 map端聚合(group by):
6.4 count(distinct):
6.5 笛卡尔积:
7.动态分区
8.MapReduce并行度调整
9.并行执行严格模式
并发(看起来是同时,其实是超快速切换):
并行(真正的同时):
9.1hive提供一种严格模式
10.JVM重用
11.推测执行
12.执行计划explain
hive官方配置url: Configuration Properties - Apache Hive - Apache Software Foundation
本地模式:默认是false关闭的,适用于小任务
并行执行和严格模式:默认是false关闭的,需要自己的资源足够足,比较空闲才有用,否则也并行不起来
explain执行计划是辅助调优的,属于查看,也是要自己手动去查
0.设置hive参数
hive参数配置的意义: 开发Hive应用/调优时,不可避免地需要设定Hive的参数。设定Hive的参数可以调优HQL代码的执行效率,或帮助定位问题。然而实践中经常遇到的一个问题是,为什么我设定的参数没有起作用?这是对hive参数配置几种方式不了解导致的!
hive参数设置范围 : 配置文件参数 > 命令行参数 > set参数声明
hive参数设置优先级: set参数声明 > 命令行参数 > 配置文件参数
注意: 一般执行SQL需要指定的参数, 都是通过 set参数声明 方式进行配置,因为它属于当前会话的临时设置,断开后就失效了
1.数据压缩
做压缩,提升传输文件的效率,减少了占用的内存,减少map到reduce的传输量
-- 开启压缩(map阶段或者reduce阶段)
--开启hive支持中间结果的压缩方案
set hive.exec.compress.intermediate; -- 查看默认
set hive.exec.compress.intermediate=true ;
--开启hive支持最终结果压缩
set hive.exec.compress.output; -- 查看默认
set hive.exec.compress.output=true;--开启MR的map端压缩操作
set mapreduce.map.output.compress; -- 查看默认
set mapreduce.map.output.compress=true;
--设置mapper端压缩的方案
set mapreduce.map.output.compress.codec; -- 查看默认
set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;-- 开启MR的reduce端的压缩方案
set mapreduce.output.fileoutputformat.compress; -- 查看默认
set mapreduce.output.fileoutputformat.compress=true;
-- 设置reduce端压缩的方案
set mapreduce.output.fileoutputformat.compress.codec; -- 查看默认
set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
--设置reduce的压缩类型
set mapreduce.output.fileoutputformat.compress.type; -- 查看默认
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
2.hive数据存储格式
之前的内容
https://blog.csdn.net/m0_49956154/article/details/134444484?spm=1001.2014.3001.5501
行存储的特点: 查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
列存储的特点: 因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。行存储: textfile和squencefile
优点: 每行数据连续存储 select * from 表名; 查询速度相对较快
缺点: 每列类型不一致,空间利用率不高 select 列名 from 表名; 查询速度相对较慢
列存储: orc和parquet
优点: 每列数据连续存储 select 列名 from 表名; 查询速度相对较快
缺点: 因为每行数据不是连续存储 select * from 表名;查询速度相对较慢
注意: ORC文件格式的数据, 默认内置一种压缩算法:zlib , 在实际生产中一般会将ORC压缩算法替换为 snappy使用,格式为: STORED AS orc tblproperties ("orc.compress"="SNAPPY")
存储依赖压缩
行存储的特点: 查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
列存储的特点: 因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
3.fetch抓取策略
能不走MR,就不走MR
以下是查询sql时不走mr的情况
1) 全表扫描
2) 查询某个列数据
3) 执行一些简答查询操作
4) 执行limit操作
而这些操作, 没有走MR原因, 就是hive默认以及开启本地抓取的策略方案:
hive.fetch.task.conversion: 设置本地抓取策略
可选:
more (默认值): 可以保证在执行全表扫描, 查询某几个列, 进度limit操作,还有简单条件查询4种情况都不会走MR
minimal : 保证执行全表扫描以,查询某几个列,简单limit操作,3种情况可以不走MR
none : 全部的查询的SQL 都执行MR
4.本地模式
让MR能走本地,就走本地(小任务能自己干就自己干)
如何开启:
set hive.exec.mode.local.auto=true; 默认值为: false开启本地模式后, 在什么情况下执行本地MR: 只有当输入的数据满足以下两个特性后, 才会执行本地MR
set hive.exec.mode.local.auto.inputbytes.max=51234560; 默认为 128M
设置本地MR最大处理的数据量
set hive.exec.mode.local.auto.input.files.max=10; 默认值为4
设置本地MR最大处理的文件的数量
5.join优化操作
帮助reduce分担一部分工作量,提高效率,join也有解决数据倾斜的作用,符合小表条件,提前join
小表join大表:
Map端Join 如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成在Reduce阶段完成join。 容易发生数据倾斜。可以用MapJoin把小表全部加载到内存在map端进行join,避免reducer处理。
大表join大表:
能在join之前过滤操作, 一定要在join前过滤, 以减少join的数据量, 从而提升效率
如果join字段上, 有很多的空值null值,获取其他无效数据, 这些值越多 就会导致出现数据倾斜,用rand()解决
6.SQL优化(列裁剪,分区裁剪,map端聚合,count(distinct),笛卡尔积)
6.1 列裁剪:
(只读取sql语句需要的字段,查询中所需要用到的列,而忽略其他列,节省读取开销,提升效率)
hive.optimize.cp=true;
6.2 分区裁剪:
如果操作的表是一张分区表, 那么建议一定要带上分区字段, 以减少扫描的数据量, 从而提升效率
hive.optimize.pruner=true
6.3 map端聚合(group by):
两个reduce,一个解决效率,一个解决倾斜
方案一:
--(1)是否在Map端进行聚合,默认为True
set hive.map.aggr = true;
--(2)在Map端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000;方案二: 官方称为 负载均衡
--(3)有数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skewindata = true;
第一个MR Job中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;
第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
6.4 count(distinct):
找了group by进行去重和分组,再去进行统计操作,这样的做法, 虽然会运行两个MR, 但是当数据量足够庞大的时候, 此操作绝对是值得的, 如果数据量比较少, 此操作效率更低
-- count(distinct)优化
set hive.optimize.countdistinct; -- 默认就是true
set hive.optimize.countdistinct = true;
原有:
select count(distinct ip) from ip_tab;
优化:
select
count(ip)
from
(select ip from ip_tab group by ip) tmp;
6.5 笛卡尔积:
避免笛卡尔积:
1) 表join的时候要加on条件,同时避免无效的on条件
2) 关联条件不要放置在where语句, 因为底层, 先产生笛卡尔积 然后基于where进行过滤 , 建议放置on条件上
3) 如果实际开发中无法确定表与表关联条件 建议与数据管理者重新对接, 避免出现问题
7.动态分区
本来进行分区的时候是手动,比如year=2023,设置动态分区就可以自动分配,动态生成分区目录
默认是严格模式:strict,老版本需要手动关闭严格模式后,才能使用动态分区,新版本可以不关
非严格模式:nonstrict 就是动态分区支持
作用: 帮助一次性灌入多个分区的数据
参数:
set hive.exec.dynamic.partition.mode=nonstrict; -- 开启非严格模式 默认为 strict(严格模式)
set hive.exec.dynamic.partition=true; -- 开启动态分区支持, 默认就是true
可选的参数:
set hive.exec.max.dynamic.partitions=1000; -- 在所有执行MR的节点上,最大一共可以创建多少个动态分区。
set hive.exec.max.dynamic.partitions.pernode=100; -- 每个执行MR的节点上,最大可以创建多少个动态分区
set hive.exec.max.created.files=100000; -- 整个MR Job中,最大可以创建多少个HDFS文件
8.MapReduce并行度调整
分解和合并的数量并不是越多越好,就像班上不能人人都是一个组,要根据实际需求调整
一个块对应一个map任务,一个结果对应一个reduce
如何调整mapTask数量:
小文件场景:当input的文件都很小,把小文件进行合并归档,减少map数, 设置map数量:
-- 每个Map最大输入大小(这个值决定了合并后文件的数量)
set mapred.max.split.size=256000000;
-- 一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=1;
-- 一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=1;
-- 执行Map前进行小文件合并默认CombineHiveInputFormat
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
大文件场景:当input的文件都很大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加Map数,来使得每个map处理的数据量减少,从而提高任务的执行效率。
-- 查看reduces数量
-- 该值默认为-1,由hive自己根据任务情况进行判断。
set mapred.reduce.tasks;
set mapreduce.job.reduces;
-- (1)每个Reduce处理的数据量默认是256MB左右
set hive.exec.reducers.bytes.per.reducer=256000000;
-- (2)每个任务最大的reduce数,默认为1009;
set hive.exec.reducers.max=1009;
9.并行执行严格模式
在执行一个SQL语句的时候, SQL会被翻译为MR, 一个SQL有可能被翻译成多个MR, 那么在多个MR之间, 有些MR之间可能不存在任何的关联, 此时可以设置让这些没有关联的MR 并行执行, 从而提升效率 , 默认是 一个一个来
如何配置:
set hive.exec.parallel=false; --打开任务并行执行,默认关闭
set hive.exec.parallel.thread.number=8; --同一个sql允许最大并行度,默认为8。前提:
服务器必须有资源, 如果没有 即使支持并行, 也没有任何作用
前提:
服务器必须有资源, 如果没有 即使支持并行, 也没有任何作用
并发(看起来是同时,其实是超快速切换):
在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行,但任一个时刻点上只有一个程序在处理机上运行。
并行(真正的同时):
真正的同时,最大化使用cpu的资源
9.1hive提供一种严格模式
主要目的, 是为了限制一些 效率极低的SQL 放置其执行时间过长, 影响其他的操作,也就是为了避免全表扫描
严格模式最新版默认是关闭的. 严格模式的好处在特定场景下才能发挥
屏蔽以下操作:
1) 执行order by 不加 limit
2) 出现笛卡尔积的现象SQL
3) 查询分区表, 不带分区字段
如何配置
set hive.mapred.mode = strict; --开启严格模式
set hive.mapred.mode = nostrict; --开启非严格模式 最新默认
10.JVM重用
当资源被借用的时候,每次都要把资源还回来,重用就可以直接由借走资源的人再借给别人
运行containers容器可以被重复使用.
jvm重用:
默认情况下, container资源容器 只能使用一次,不能重复使用, 开启JVM重用, 运行container容器可以被重复使用,在hive2.x已经默认支持了
11.推测执行
根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。
根据现在的情况判断是否能完成任务,如果判断不能,就直接新开一个任务
如果用户因为输入数据量很大而需要执行长时间的map或者Reduce task的话,那么启动推测执行造成的浪费是非常巨大。
hive本身也提供了配置项来控制reduce-side的推测执行:
set hive.mapred.reduce.tasks.speculative.execution=true;
12.执行计划explain
使用示例:explain [...] sql查询语句;
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。帮助我们了解底层原理,hive调优,排查数据倾斜等有很有帮助 

相关文章:
2023.11.17-hive调优的常见方式
目录 0.设置hive参数 1.数据压缩 2.hive数据存储格式 3.fetch抓取策略 4.本地模式 5.join优化操作 6.SQL优化(列裁剪,分区裁剪,map端聚合,count(distinct),笛卡尔积) 6.1 列裁剪: 6.2 分区裁剪: 6.3 map端聚合(group by): 6.4 count(distinct): 6.5 笛卡尔积: 7…...

ts 联合react 实现ajax的封装,refreshtoken的功能
react ts混合双打,实现ajax的封装,以及401的特殊处理 import axios from axios import {AMDIN_EXPIRES_KEY,AMDIN_KEY,AMDIN_REFRESH_EXPIRES_KEY,AMDIN_REFRESH_KEY,COMMID_KEY,getToken,removeToken } from ../utils/user-token import { showMessage…...
)
CISP模拟试题(一)
免责声明 文章仅做经验分享用途,利用本文章所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,作者不为此承担任何责任,一旦造成后果请自行承担!!! 1.下面关于信息安全保障的说法错误的是:C A.信息安全保障的概念是与信息安全的概念同时产生的 …...

轻量封装WebGPU渲染系统示例<35>- HDR环境数据应用到PBR渲染材质
当前示例源码github地址: https://github.com/vilyLei/voxwebgpu/blob/feature/rendering/src/voxgpu/sample/BasePbrMaterialTest.ts 当前示例运行效果: 微调参数之后的效果: 此示例基于此渲染系统实现,当前示例TypeScript源码如下: export class BasePbrMateri…...
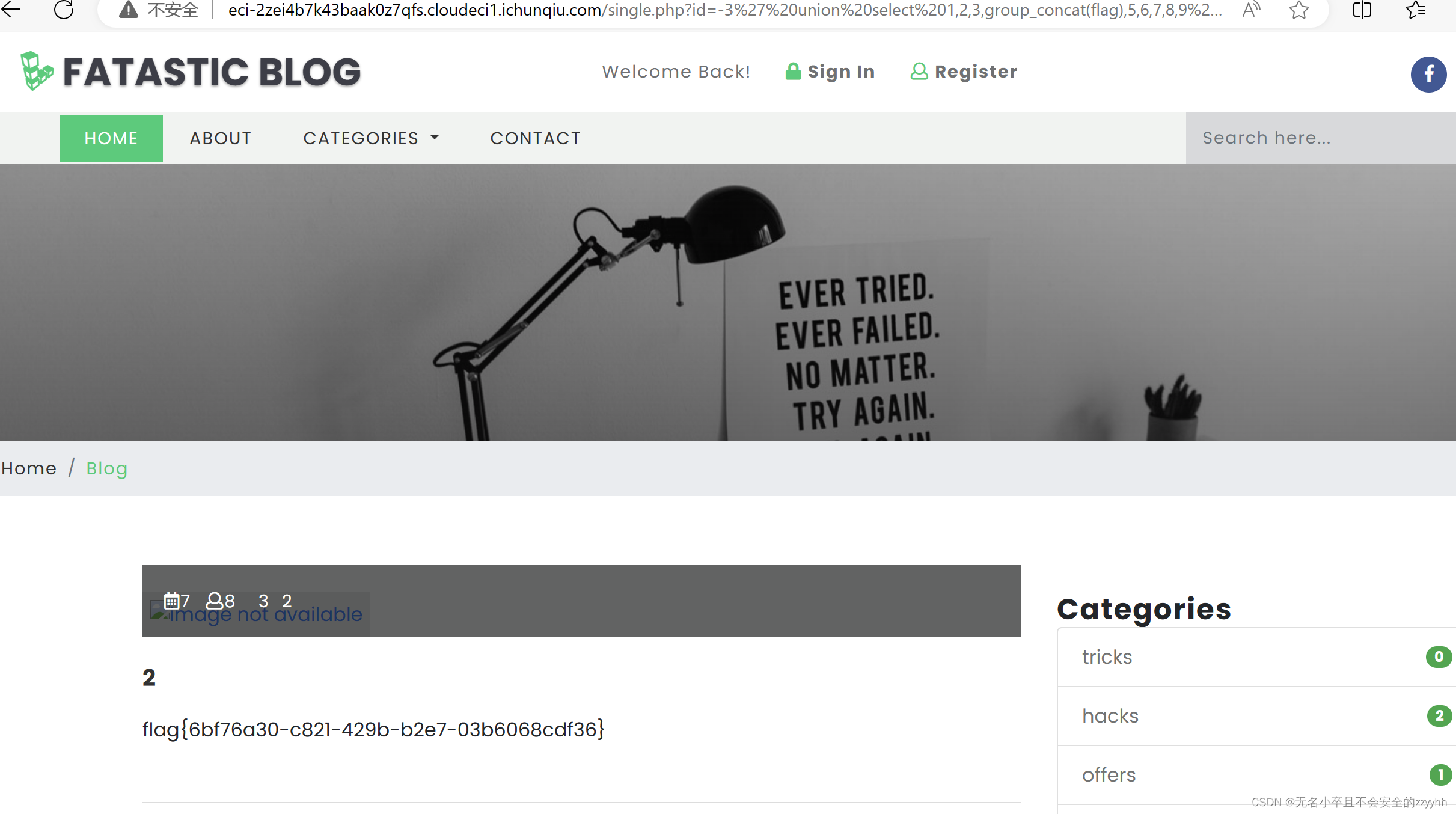
春秋云境靶场CVE-2022-28512漏洞复现(sql手工注入)
文章目录 前言一、CVE-2022-28512靶场简述二、找注入点三、CVE-2022-28512漏洞复现1、判断注入点2、爆显位个数3、爆显位位置4 、爆数据库名5、爆数据库表名6、爆数据库列名7、爆数据库数据 总结 前言 此文章只用于学习和反思巩固sql注入知识,禁止用于做非法攻击。…...

数字化文化的守护之星:十八数藏的非遗创新之道
在数字时代的浪潮中,十八数藏犹如一颗璀璨的守护之星,为传统文化注入了新的生命力。这个非遗创新项目以数字化为工具,以守护为使命,开辟了文化传承的新航道。 十八数藏是文化数字守护的引领者,通过数字技术࿰…...

[机缘参悟-119] :反者道之动与阴阳太极
目录 一、阴阳对立、二元对立的规律 1.1 二元对立 1.2 矛盾的对立与统一 二、阴阳互转、阴阳变化、变化无常 》无序变化和有序趋势的规律 三、阴阳合一、佛魔一体、善恶同源 四、看到积极的一面 五、反者道之动 5.1 概述 5.2 "否极泰来" 5.3 “乐极生悲”…...
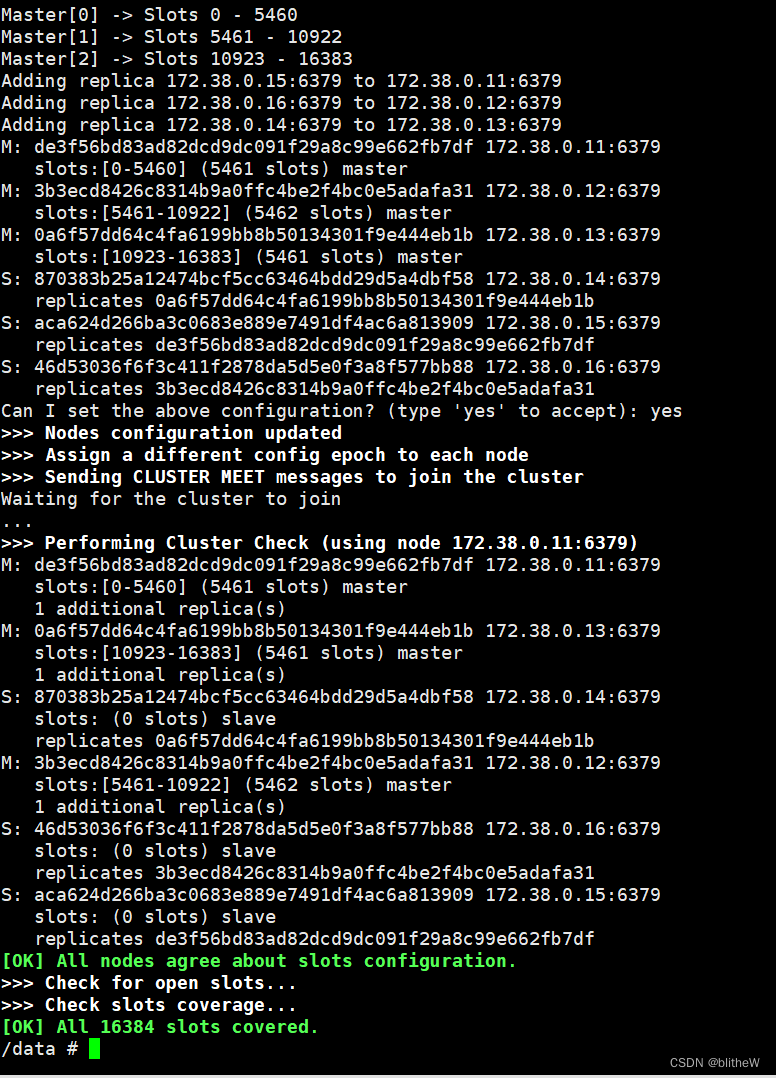
Docker搭建Redis集群
Docker搭建Redis集群 创建一个专属redis的网络 docker network create redis --subnet 172.38.0.0/16通过shell脚本创建并启动6个redis服务 #通过脚本一次创建6个redis配置 for port in $(seq 1 6); \ do \ mkdir -p /mydata/redis/node-${port}/conf touch /mydata/redis/n…...
代码——2.OpenCV初探)
学习Opencv(蝴蝶书/C++)代码——2.OpenCV初探
文章目录 0. 图像读取与显示1. 视频文件读取与操作1.1 示例代码1.1 OpenCV支持的视频格式2. 加入滑动条2.1 示例代码2.2 报错/Warning2.3 关于toolbar3. 简易视频播放器3.1 OpenCV检测方向键被按下3.1.1 Windows下3.1.2 linux下3.1 方向键控制视频变化4. 简单的变换5. 写视频5.…...

基于AVR单片机的便携式心电监测设备设计与实现
基于AVR单片机的便携式心电监测设备是一种常用的医疗设备,用于随时监测和记录人体的心电信号。本文将介绍便携式心电监测设备的设计原理和实现步骤,并提供相应的代码示例。 1. 设计概述 便携式心电监测设备是一种小巧、方便携带的设备,能够…...
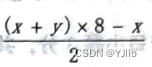
微机原理_14
一、单项选择题(本大题共15小题,每小题3分,共45分。在每小题给出的四个备选项中,选出一个正确的答案。) 1,下面寻址方式的操作数不在存储器中的是() A. 堆栈寻址 B. 寄存器间址 C.寄存器寻址 D. 直接寻址 2,条件转移指令JNE的条件是() A. CF…...
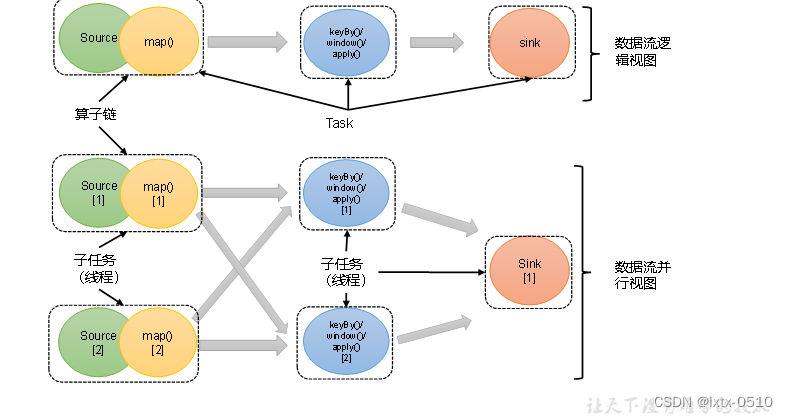
【Flink】核心概念:并行度与算子链
并行度(Parallelism) 当要处理的数据量非常大时,我们可以把一个算子操作,“复制”多份到多个节点,数据来了之后就可以到其中任意一个执行。这样一来,一个算子任务就被拆分成了多个并行的“子任务”&#x…...

milvus采坑一:启动服务就会挂掉
原因一 硬盘满了,Eric数据文件存储在硬盘上,当硬盘不足,它就会启动后就挂掉。 此时pymilvus连接一直是timeout。 解决方法:更换存储路径。...

WPF Visual, UIElement, FrameworkElement, Control这些类的区别
在WPF (Windows Presentation Foundation) 中,Visual, UIElement, FrameworkElement, 和 Control 这些类是一个类层次结构,它们分别在 WPF 的 UI 元素和控件模型中提供了不同级别的功能。下面是这些类的详细介绍: Visual:这是所有…...

Python-----PyInstaller的简单使用
PyInstaller简介 PyInstaller是一个Python库,可以将Python应用程序转换为独立的可执行文件。PyInstaller支持跨平台,可以在Windows、Linux和MacOS上生成可执行文件。 PyInstaller会分析Python程序,并将程序打包成一个完整的可执行文件&…...

8 Redis与Lua
LUA脚本语言是C开发的,类似存储过程,是为了实现完整的原子性操作,可以用来补充redis弱事务的缺点. 1、LUA脚本的好处 2、Lua脚本限流实战 支持分布式 import org.springframework.core.io.ClassPathResource; import org.springframework.data.redis…...

10个令人惊叹的Go语言技巧,让你的代码更加优雅
关注公众号【爱发白日梦的后端】分享技术干货、读书笔记、开源项目、实战经验、高效开发工具等,您的关注将是我的更新动力! 在开发生产项目的过程中,我注意到经常会发现自己在重复编写代码,使用某些技巧时没有意识到,直…...

vue3 setup展示数据
效果图 1.创建数据 content.js import { reactive } from vueconst data reactive({color:red,title: 二十四节气,subTitle: 节气,是干支历中表示自然节律变化以及确立“十二月建”(月令)的特定节令。,list: [{name: "立春",con…...
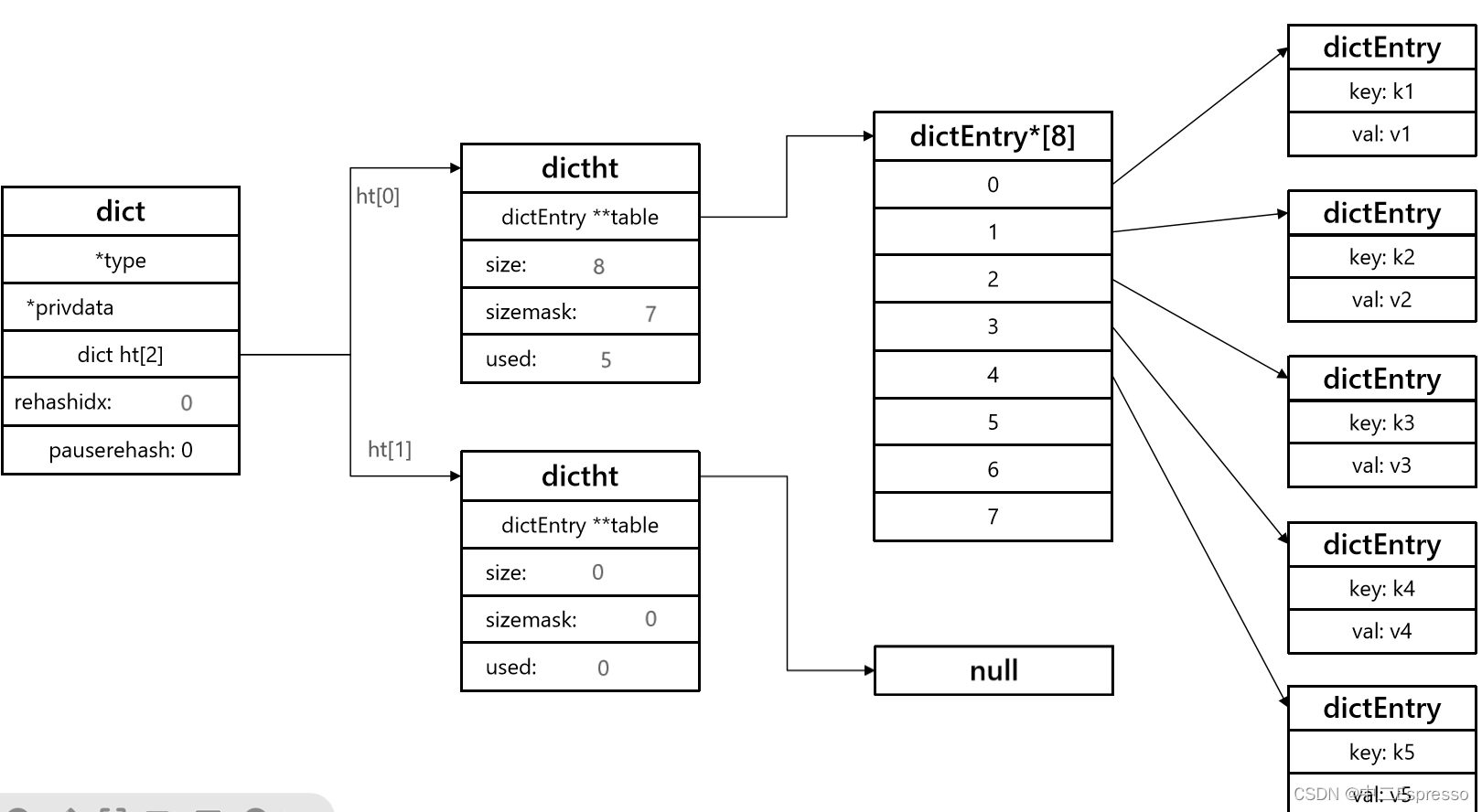
原理Redis-Dict字典
Dict 1) Dict组成2) Dict的扩容3) Dict的收缩4) Dict的rehash5) 总结 1) Dict组成 Redis是一个键值型(Key-Value Pair)的数据库,可以根据键实现快速的增删改查。而键与值的映射关系正是通过Dict来实现的。 Dict由三部分组成,分别…...

卷积神经网络(VGG-19)灵笼人物识别
文章目录 前期工作1. 设置GPU(如果使用的是CPU可以忽略这步)我的环境: 2. 导入数据3. 查看数据 二、数据预处理1. 加载数据2. 可视化数据3. 再次检查数据4. 配置数据集5. 归一化 三、构建VGG-19网络1. 官方模型(已打包好ÿ…...

如何一站式破解Widevine DRM加密视频:智能解密工具完全指南
如何一站式破解Widevine DRM加密视频:智能解密工具完全指南 【免费下载链接】video_decrypter Decrypt video from a streaming site with MPEG-DASH Widevine DRM encryption. 项目地址: https://gitcode.com/gh_mirrors/vi/video_decrypter 还在为付费视频…...

Blender 3MF插件:打破3D打印工作流的终极瓶颈
Blender 3MF插件:打破3D打印工作流的终极瓶颈 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 你是否曾在3D打印项目中遇到过这样的困境?精心设计的…...
)
OpenClaw Windows11 保姆级安装部署教程(专属优化、一次成功)
OpenClaw Windows11 保姆级安装部署教程(专属优化、一次成功)一、前言OpenClaw(圈内俗称「小龙虾」)是 GitHub 星标 28W 的开源本地 AI 智能体,主打全自动电脑操控能力,支持自动操作电脑、整理文件、浏览器…...

英雄联盟智能辅助工具Seraphine:三步快速上手的终极指南
英雄联盟智能辅助工具Seraphine:三步快速上手的终极指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 你是否厌倦了在英雄联盟排位赛中手忙脚乱地查询对手战绩?是否希望有一个智能助…...

Node.js异步数据库操作:nedb-promises封装原理与实战指南
1. 项目概述:告别回调地狱,拥抱异步数据库操作 如果你在Node.js项目中用过NeDB,大概率对它的回调函数(callback)模式又爱又恨。NeDB本身是一个轻量级的嵌入式数据库,API设计简单直观,但在现代异…...

Notflix高级技巧:5种高效搜索和流媒体传输方法
Notflix高级技巧:5种高效搜索和流媒体传输方法 【免费下载链接】notflix Notflix is a shell script to search and stream torrent. 项目地址: https://gitcode.com/gh_mirrors/no/notflix Notflix是一款强大的shell脚本工具,能够帮助用户快速搜…...

ChatterUI本地模式深度解析:在移动设备上运行LLM的完整指南
ChatterUI本地模式深度解析:在移动设备上运行LLM的完整指南 【免费下载链接】ChatterUI Simple frontend for LLMs built in react-native. 项目地址: https://gitcode.com/gh_mirrors/ch/ChatterUI ChatterUI是一款基于React Native构建的轻量级LLM前端应用…...

番茄小说下载器:打造个人专属离线小说图书馆的完整指南
番茄小说下载器:打造个人专属离线小说图书馆的完整指南 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾在通勤路上突然想读小说,却因为网络信号不佳而无法加…...

视觉语言模型心智理论评估:意图理解与视角采样的能力分离现象
1. 项目概述:当AI“读心术”遇到瓶颈最近在跟进多模态大模型的前沿进展时,一篇来自2025年“心智理论”国际研讨会的论文引起了我的注意。论文标题很有意思,叫《视觉语言模型看到你想看的,而非你看到的》。这个标题精准地概括了当前…...

C++异步日志系统
文章目录异步日志系统1. 项目背景2. 设计思路2.1 核心架构2.2 关键技术点3. 实现细节3.1 线程安全的日志队列 (LogQueue)3.2 动态格式化与回退机制 (formatMessage)3.3 自动化管理4. 接口说明日志级别 (LogLevel)核心方法5. 使用指南5.1 快速上手5.2 注意事项6. 总结7.Code异步…...