2023.11.19 hadoop之MapReduce
目录
1.简介
2.分布式计算框架-Map Reduce
3.mapreduce的步骤
4.MapReduce底层原理
map阶段
shuffle阶段
reduce阶段
1.简介
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上;
什么是计算,分布式计算?
计算:对数据进行处理,使用统计分析等手段得到需要的结果
分布式计算:多台服务器协同工作,共同完成一个计算任务
分布式计算常见的2中工作模式?
分散->汇总
(Map Reduce就是这种模式)
中心调度->步骤执行
(大数据体系的Spark、Flink等是这种模式)
2.分布式计算框架-Map Reduce
分布式计算框架-Map Reduce
Map Reduce的思想核心:分而治之
所谓分而治之就是把一个复杂的问题按一定的分解方法分为规模较小的若干部分,然后逐个解决,分别找出各部分的解,再把把各部分的解组成整个问题的解。
Map:负责分,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行
计算,几乎没有依赖关系。
Reduce:负责合,即对map阶段的结果进行全局汇总。
Map Reduce是“分散->汇总”模式的分布式计算框架,可供开发人员开发相关程序进行分布式数据计算。
Map功能接口提供了“分散”的功能,由服务器分布式对数据进行处理
Reduce功能接口提供了“汇总(聚合)”的功能,将分布式的处理结果汇总统计
3.mapreduce的步骤
shuffe是map的后期,reduce的前期
输入-map负责分-shuffe(分区_排序_规约_分组)-reduce负责和-输出
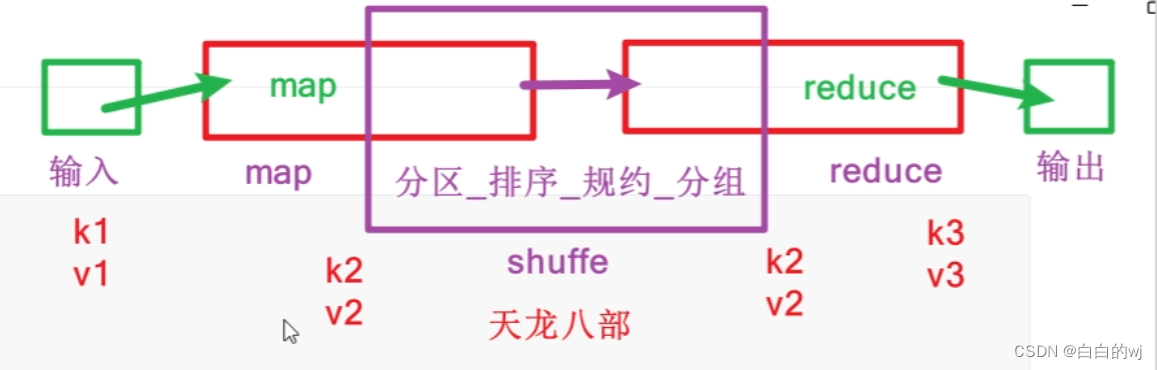
词频统计命令的流程:
已知文件内容:
hadoop hive hadoop spark hive
flink hive linux hive mysql
input结果:
k1(行偏移量) v1(每行文本内容)
0 hadoop hive hadoop spark hive
30 flink hive linux hive mysql
map结果:
k2(split切割后的单词) v2(拼接1)
hadoop 1
hive 1
hadoop 1
spark 1
hive 1
flink 1
hive 1
linu 1
hive 1
mysql 1
分区/排序/规约/分组结果:
k2(排序分组后的单词) v2(每个单词数量的集合)
flink [1]
hadoop [1,1]
hive [1,1,1,1]
linux [1]
mysql [1]
spark [1]
reduce结果:
k3(排序分组后的单词) v3(聚合后的单词数量)
flink 1
hadoop 2
hive 4
linux 1
mysql 1
spark 1
output结果: 注意: 输出目录一定不要存在,否则报错
flink 1
hadoop 2
hive 4
linux 1
mysql 1
spark 1
4.MapReduce底层原理

map阶段
第一阶段是把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认情况下Split size 等于 Block size。每一个切片由一个MapTask处理(当然也可以通过参数单独修改split大小)
第二阶段是对切片中的数据按照一定的规则解析成对。默认规则是把每一行文本内容解析成键值对。key是每一行的起始位置(单位是字节),value是本行的文本内容。(TextInputFormat)
第三阶段是调用Mapper类中的map方法。上阶段中每解析出来的一个,调用一次map方法。每次调用map方法会输出零个或多个键值对
第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务
第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。
如果有第六阶段,那么进入第六阶段;如果没有,直接输出到文件中
第六阶段是对数据进行局部聚合处理,也就是combiner处理。键相等的键值对会调用一次reduce方法。经过这一阶段,数据量会减少。本阶段默认是没有的。
shuffle阶段
shuffle是Mapreduce的核心,它分布在Mapreduce的map阶段和reduce阶段。一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。
Collect阶段:将MapTask的结果输出到默认大小为100M的环形缓冲区,保存的是key/value,Partition分区信息等
Spill阶段:当内存中的数据量达到一定的阀值(80%)的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序
Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件
Copy阶段: ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上
Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可。
reduce阶段
第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对。Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中。
相关文章:
2023.11.19 hadoop之MapReduce
目录 1.简介 2.分布式计算框架-Map Reduce 3.mapreduce的步骤 4.MapReduce底层原理 map阶段 shuffle阶段 reduce阶段 1.简介 Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架; Mapreduce核心功能是…...

力扣第841题 钥匙和房间 C++ DFS BFS 附Java代码
题目 841. 钥匙和房间 中等 相关标签 深度优先搜索 广度优先搜索 图 有 n 个房间,房间按从 0 到 n - 1 编号。最初,除 0 号房间外的其余所有房间都被锁住。你的目标是进入所有的房间。然而,你不能在没有获得钥匙的时候进入锁住的房间…...
React 中 react-i18next 切换语言( 项目国际化 )
背景 平时中会遇到需求,就是切换语言,语种等。其实总的来说都是用i18n来实现的 思路 首先在项目中安装i18n插件,然后将插件引入到项目,然后配置语言包(语言包需要你自己来进行配置,自己编写语言包ÿ…...

antd design 5 版本 文件上传
<UploadcustomRequest{customRequest}accept".csv" showUploadList{false}><Button icon{<UploadOutlined />}>上传 CSV 文件</Button></Upload> accept 代表限制的上传类型 也可设置 .excel // 文件上传 ( CSV ) const customReques…...

【如何学习Python自动化测试】—— 浏览器操作
4 、 浏览器操作 4.1 浏览器最大化 Webdriver 打开浏览器后,默认不是最大化,如果需要界面最大化,需要通过 maximize_window()方法来实现,代码如下: maximize_window()方法是Selenium WebDriver提供的一个方法…...
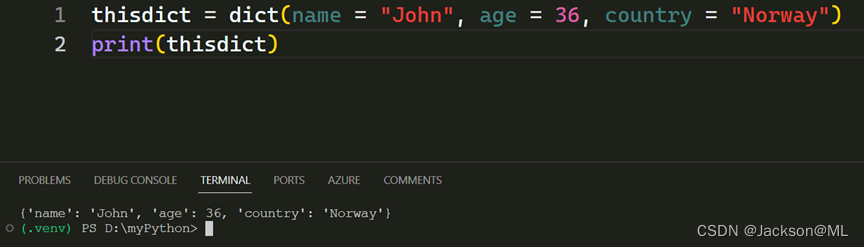
Python编程技巧 – 使用字典
Python编程技巧 – 使用字典 Python Programming Skills – Using Dictionary Dictionary, 即字典,这是Python语言的一种重要的数据结构;Python字典是以键(key)值(value)对为元素,来存储数据的集合。 前文提到Python列…...
el-tree 与table表格联动
html部分 <div class"org-left"><el-input v-model"filterText" placeholder"" size"default" /><el-tree ref"treeRef" class"filter-tree" :data"treeData" :props"defaultProp…...
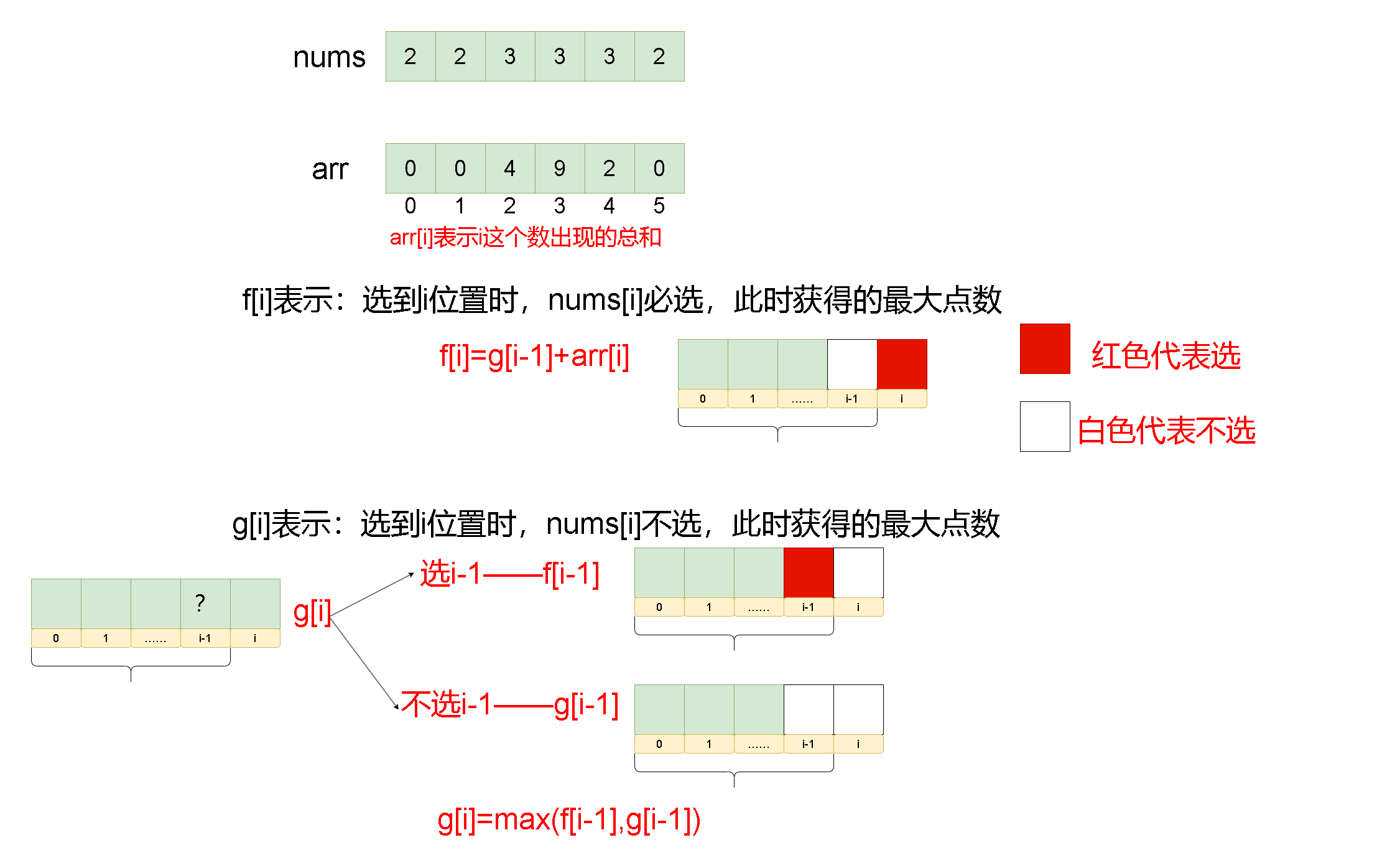
Leetcode刷题详解——删除并获得点数
1. 题目链接:740. 删除并获得点数 2. 题目描述: 给你一个整数数组 nums ,你可以对它进行一些操作。 每次操作中,选择任意一个 nums[i] ,删除它并获得 nums[i] 的点数。之后,你必须删除 所有 等于 nums[i] …...

HTTP四种请求方式,状态码,请求和响应报文
1.get请求 一般用于获取数据请求参数在URL后面请求参数的大小有限制 2.post请求 一般用于修改数据提交的数据在请求体中提交数据的大小没有限制 3.put请求 一般用于添加数据 4.delete请求 一般用于删除数据 5.一次完整的http请求过程 域名解析:使用DNS协议…...
Python - Wave2lip 环境配置与 Wave2lip x GFP-GAN 实战 [超详细!]
一.引言 前面介绍了 GFP-GAN 的原理与应用,其用于优化图像画质。本文关注另外一个相关的项目 Wave2lip,其可以通过人物视频与自定义音频进行适配,改变视频中人物的嘴型与音频对应。 二.Wave2Lip 简介 Wave2lip 研究 lip-syncing 以达到视频…...

2311rust,1.31版本更新
1.31.0稳定版 Rust1.31可能是最激动人心的版本! 使用Cargo创建一个新项目: cargo new foo以下是Cargo.toml的内容: [package] name "foo" version "0.1.0" authors ["名字"] edition "2018" //版本. [dependencies]在[package]…...

文心一言-情感关怀之旅
如何让LLM更有温度。 应用介绍...

下厨房网站月度最佳栏目菜谱数据获取及分析PLus
目录 概要 源数据获取 写Python代码爬取数据 Scala介绍与数据处理 1.Sacla介绍 2.Scala数据处理流程 数据可视化 最终大屏效果 小结 概要 本文的主题是获取下厨房网站月度最佳栏目近十年数据,最终进行数据清洗、处理后生成所需的数据库表,最终进…...
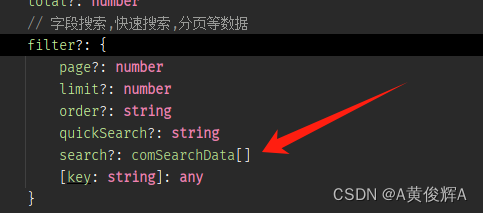
buildadmin+tp8表格操作(5)自定义组装搜索的查询
有时候我们会自定义组装一些数据,发送给后端,让后端来进行筛选,这里有一个示例 const onComSearchIdEq () > {// 展开公共搜索baTable.table.showComSearch true/*** 公共搜索表单赋值* 范围搜索有两个输入框,输入框绑定变量…...

企业级固态硬盘如何稳定运行?永铭固液混合铝电解电容来帮忙
企业级 固态硬盘 永铭固液混合铝电解电容 企业级固态硬盘(SSD)主要应用于互联网、云服务、金融和电信等客户的数据中心,企业级SSD具备更快传输速度、更大单盘容量、更高使用寿命以及更高的可靠性要求。 企业级固态硬盘的运行要求—固液混合电…...

【MISRA C 2012】Rule 4.2 不应该使用三连符
1. 规则1.1 原文1.2 分类 2. 关键描述3. 代码实例 1. 规则 1.1 原文 Rule 4.2 Trigraphs should not be used Category Advisory Analysis Decidable, Single Translation Unit Applies to C90, C99 1.2 分类 规则4.2:不应该使用三连符 Advisory建议类规范。 2…...

spring boot加mybatis puls实现,在新增/修改时,对某些字段进行处理,使用的@TableField()
1.先说场景,在对mysql数据库表数据插入或者更新时都得记录时间和用户id 传统实现有点繁琐,这里还可以封装一下公共方法。 2.解决方法: 2.1:使用aop切面编程(记录一下,有时间再攻克)。 2.2&…...
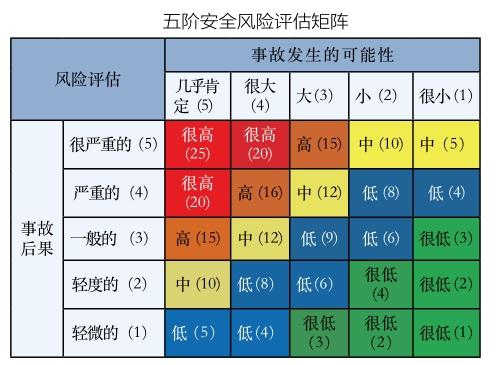
如何构建风险矩阵?3大注意事项
风险矩阵法(RMA)是确定威胁优先级别的最有效工具之一,可以帮助项目团队识别和评估项目中的风险,帮助项目团队对风险进行排序,清晰地展示风险的可能性和严重性,为项目团队制定风险管理策略提供依据。 如果没…...

SpringSecurity5|12.实现RememberMe 及 实现原理分析
security/day08 这个功能大家还熟悉么?我们在登录网站的时候,除了让你输入用户名和密码,还会有个勾选框: 记住我!!!不是让大家记住我哈。 值得一提的是,Spring Security 也提供了这个…...
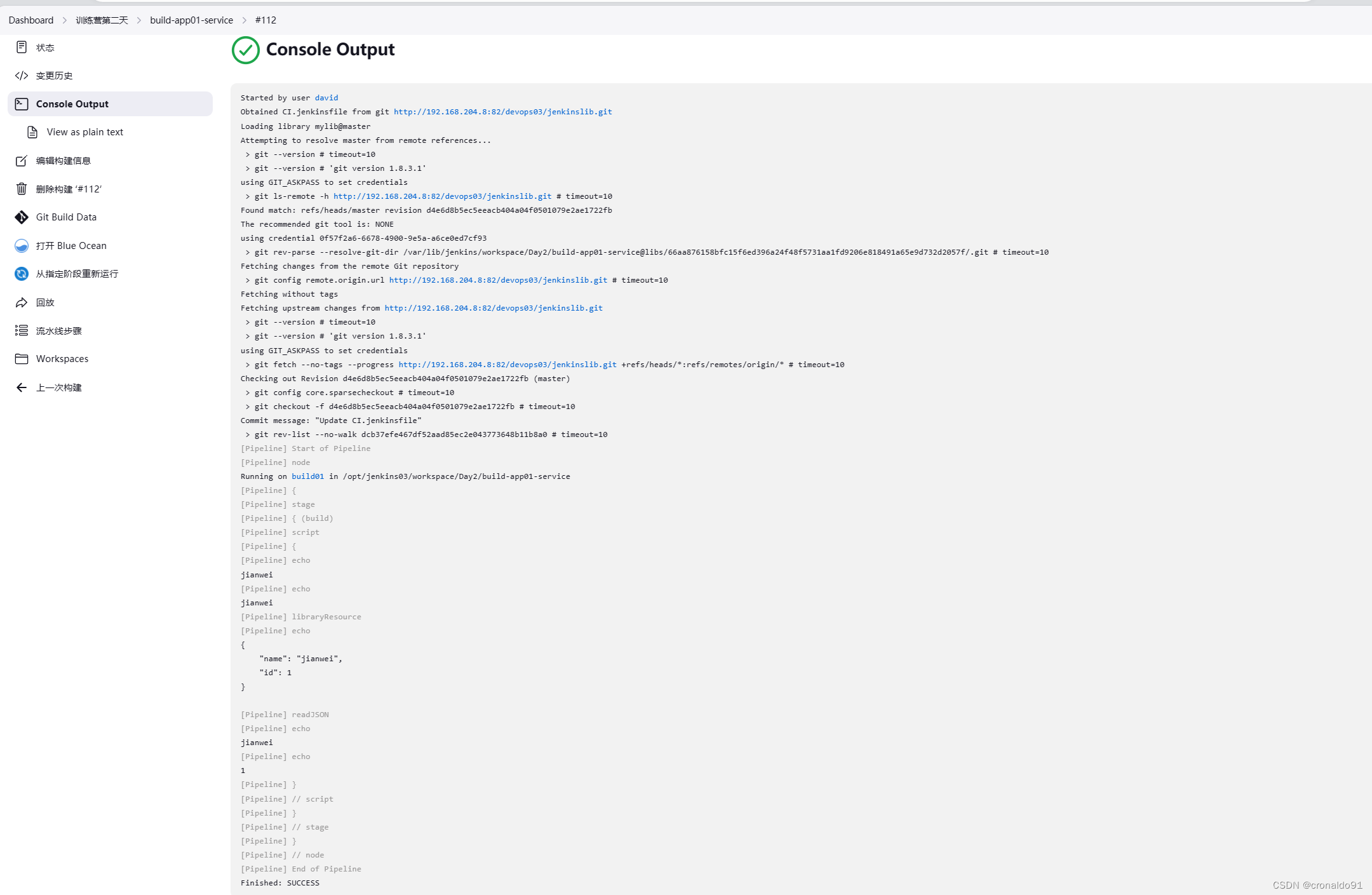
持续集成交付CICD:Jenkins Sharedlibrary 共享库
目录 一、理论 1.共享库 2.共享库配置 3.使用共享库 4.共享库扩展 二、实验 1.连接共享库 2.使用共享库 三、问题 1.路径报错 2.readJSON 报错 一、理论 1.共享库 (1)概念 1)共享库这并不是一个全新的概念,其实在编…...

如何通过手机APP远程控制微信自动化:wxauto移动端管理完整指南
如何通过手机APP远程控制微信自动化:wxauto移动端管理完整指南 【免费下载链接】wxauto Windows版本微信客户端(非网页版)自动化,可实现简单的发送、接收微信消息,简单微信机器人 项目地址: https://gitcode.com/gh_…...

保姆级教程:用Arduino IDE给GRBL固件刷机,手把手搞定激光雕刻机大脑
GRBL固件刷机全指南:从零构建激光雕刻机控制核心 当你第一次拿到激光雕刻机的控制板时,最关键的步骤莫过于为它注入"灵魂"——GRBL固件。作为开源CNC控制领域的标杆,GRBL以其高效稳定的运动控制算法赢得了全球创客的青睐。但面对A…...

如何免费解锁Windows隐藏功能?3步让iPhone照片在Windows中完美预览
如何免费解锁Windows隐藏功能?3步让iPhone照片在Windows中完美预览 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 还…...

音频标注工具完全指南:免费开源方案解决你的音频处理难题
音频标注工具完全指南:免费开源方案解决你的音频处理难题 【免费下载链接】audio-annotator A JavaScript interface for annotating and labeling audio files. 项目地址: https://gitcode.com/gh_mirrors/au/audio-annotator 你是否正在为海量音频数据的标…...
基于ASR与LLM的视频字幕翻译:ChatGPT-Subtitle-Translator实战指南
1. 项目概述:一个能“听懂”视频的翻译官如果你经常需要观看外语视频,无论是技术教程、学术讲座还是娱乐内容,肯定遇到过字幕翻译的难题。机器翻译生硬、专业术语错漏百出,手动翻译又耗时耗力。今天要聊的这个项目,就是…...

Kaspa AI Agent开发框架:构建链上智能体的核心技术解析
1. 项目概述:一个为Kaspa网络量身定制的AI Agent开发框架最近在探索区块链与AI的交叉领域时,我注意到一个非常有意思的项目:gryszzz/Top-Ai-Agent-Developer-For-Kaspa。这个项目名直译过来,就是“为Kaspa设计的顶级AI Agent开发者…...

体验Taotoken聚合路由在高峰时段的请求成功率与响应延迟
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken聚合路由在高峰时段的请求成功率与响应延迟 在依赖大模型API进行业务开发的场景中,服务的稳定性与响应速度…...

从《只狼》到你的项目:聊聊UE4布娃娃系统如何做出更‘有戏’的死亡动画
从《只狼》到你的项目:用UE4布娃娃系统打造叙事级死亡动画 在《只狼》中,当敌人从悬崖坠落时扭曲的肢体,或是Boss战败后跪地缓缓倒下的瞬间,这些死亡动画远不止是技术实现——它们成为玩家情感体验的延伸。作为UE4开发者ÿ…...

IMDB-WIKI人脸数据集:从数据爬取到年龄标注的完整解析
1. IMDB-WIKI数据集概览 IMDB-WIKI人脸数据集是目前最大规模的公开人脸年龄识别数据集之一,包含超过52万张名人面部图像。这个数据集最初由瑞士苏黎世联邦理工学院(ETH Zurich)计算机视觉实验室发布,主要用于年龄估计和性别识别的…...

初创公司如何利用Taotoken的Token Plan套餐控制AI开发成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何利用Taotoken的Token Plan套餐控制AI开发成本 对于预算敏感的初创公司而言,将大模型能力集成到产品原型中…...