论文导读 | 大语言模型与知识图谱复杂逻辑推理
前 言
大语言模型,尤其是基于思维链提示词(Chain-of Thought Prompting)[1]的方法,在多种自然语言推理任务上取得了出色的表现,但不擅长解决比示例问题更难的推理问题上。本文首先介绍复杂推理的两个分解提示词方法,再进一步介绍将提示词方法应用于知识图谱复杂逻辑推理的工作。

文章一:“Least-to-Most Prompting”[2]
让大模型学会处理更复杂的推理
本文首先提出了Least-to-Most Prompting方法的动机,是人类智慧与机器学习之间的三个差异:
(1)面对一个新问题时,人类可以通过很少的示例中解决它,但机器通常需要大规模的标注语料;
(2)人类可以很清楚的阐释所做预测的隐含原因,但机器学习是一个黑盒子;
(3)人类可以解决比之前见过的问题更难的问题,但机器学习只能解决与之前相同难度的问题。
Google Brain在2022年提出Chain-of-Thought方法,利用few-shot prompting尝试填补人类智慧和机器学习之间的差距,但他不能解决比实例问题更难的问题。为此,该团队提出了Least-to-Most Prompting方法,该方法分为两个阶段:第一阶段将一个复杂问题分解为一个简单子问题序列;第二阶段按顺序解决子问题,且回答后续子问题会依赖前序子问题的答案。
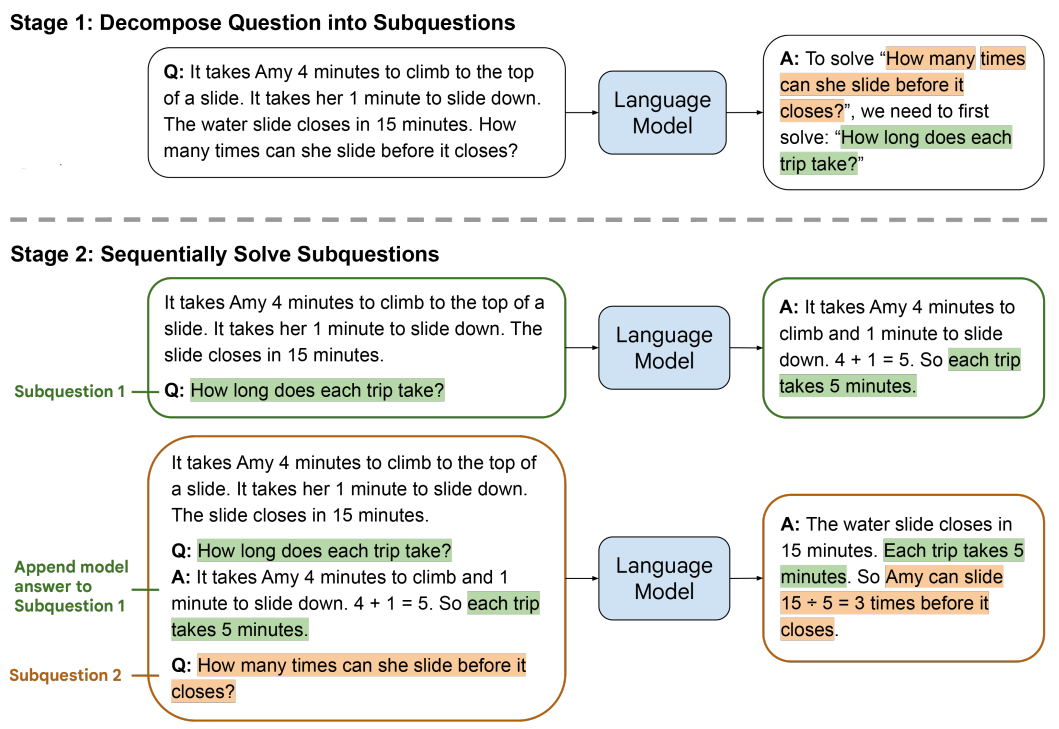
下图给出了Least-to-Most Prompting方法解决一个数学问题的示例:
(1)将复杂问题分解为简单子问题;
(2)按序解决子问题,其中,回答第二个子问题时使用了第一个子问题的答案。
实验部分,论文通过符号操作(symbolic manipulation)、组合泛化(compositional generalization)和数学推理(math reasoning)三类任务来验证Least-to-Most Prompting的效果,并与Chain-of-Thought Prompting方法进行比较。
符号操作任务的输入是一个单词列表,对应输出是将这个单词列表中所有单词最后一个字母连接起来。如,“thinking machine”的输出为“ge”。
如图,Least-to-Most Prompting方法首先将一个长的单词序列转化为子序列,

再逐步解决每个子序列最后一个字母的连接问题,并且在解决更复杂的问题时,会根据前序简单问题的答案(如已知“think, machine” outputs “ke”)得到后序问题的结果。

Chain-of-Thought Prompting则与此不同,如下图,该方法不会顺序的解决子问题,而是每一次都将符号操作的问题作为一个独立的新问题给出具有推理过程的提示词示例。

在连接最后一个字母这类符号操作的任务中,随着不同单词量L的变化,Least-to-Most Prompting方法的准确率都远好于其他提示词方法,尤其是当单词量变大时,Chain-of-Thought方法准确率下降速度远大于Least-to-Most方法,这也说明Least-to-Most方法处理比示例更难的问题时更具有优势。

组合泛化任务是给出一个指令,将其翻译为一个动作序列。

下图给出了Least-to-Most Prompting方法第一步将复杂指令分解为简单指令的提示词示例,

和第二步解决每个简单指令给出的提示词序列。

在SCAN数据集上,Least-to-Most Prompting方法的准确率都远优于其他提示词方法,该方法仅需要少数的提示词示例,就可以解决同等或更难的推理问题,具有较好的泛化能力。

在数学推理任务中,Least-to-Most Prompting也是先通过分解问题,将下图中的复杂问题分解为两个简单子问题,再依次解决这个两个子问题得到最终的答案。

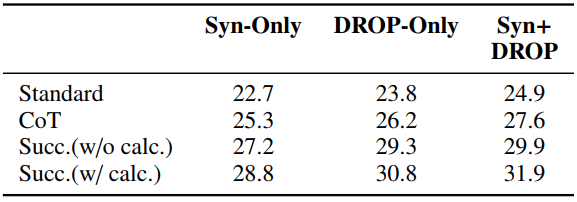
在DROP和GSM8K数据集上,Least-to-Most Prompting的方法都具有较高的准确率,尤其是DROP数据集上效果提升更加明显。


文章二:”Successive Prompting”[3]
连续提示词解决复杂任务
Successive Prompting工作与Least-to-Most Prompting是同时期的工作,他们的核心思想类似,都是将复杂的问题先分解为简单的问题再分别解决。但Successive Prompting方法并不是在一开始就将复杂问题分解为多个子问题,而是每一次都分解出下一个要解决的子问题,让大语言模型去回答该子问题。再将复杂问题和上一个问题的答案一起输入,去分解下一个要解决的子问题,并进行回答。一直重复上述过程,直到大模型给出没有问题需要回答,最后一个子问题的答案就是复杂问题的答案。
Successive Prompting方法可以看做是一个迭代的提示词方法,下图给出了该方法每一个迭代过程,以及没有其他问题后得到最终的过程示例。
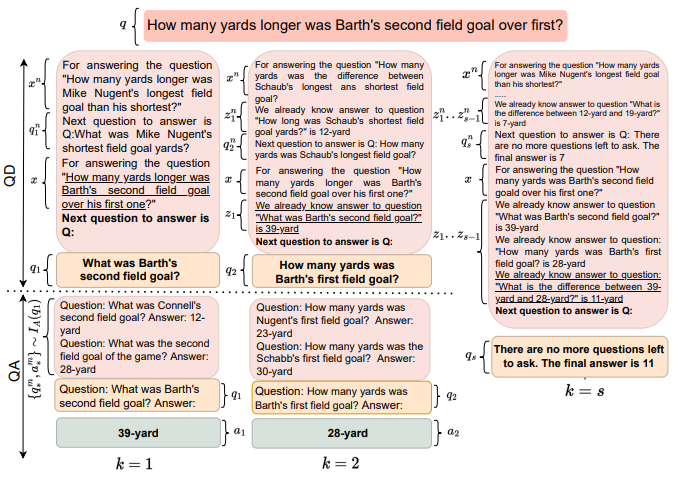
该方法还引入了一些数据集外的prompt示例的构造方式与一些符号化的构造方式,最终,在DROP数据集上取得了较高的准确率。
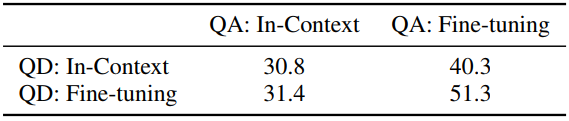
此外,论文的实验部分还比较了Prompting方法与Fine-tuning方法的效果,分别在问题分解部分和问题回答部分使用In-Context Prompting方法和Fine-tuning方法,我们可以看到Fine-tuning方法均带来了准确率提升。且在问题分解部分(QD)使用Fine-tuning会带来更大幅提升,这说明大预言模型“具有”回答简单的子问题的能力,问题分解是限制复杂推理准确率的“瓶颈”。

文章三:利用大预言模型解决知识图谱中的复杂逻辑推理问题[4]
知识图谱的复杂逻辑查询通常指一阶逻辑查询(First-Order Logical Queries),即由合取(conjunction, ∧),析取(disjunctions, ∨),存在量词(existential quantifiers, ∃)和非(negation, ¬)操作构成的逻辑语句。
在之前的工作中,复杂逻辑查询通常使用图表达学习的方法寻找答案,将节点、边和查询图都表达为低维向量空间中的某种形状,距离查询图的表达最近的节点即为查询的答案。但这类方法有以下三个缺点:一是对查询图的形式高度依赖,没有在训练集中出现过的查询图形式很难推断出正确的答案;二是泛化能力差,在一个图上训练的表达无法泛化到其他图;三是基于图表达的方法要求图的规模不能太大,而且对新加入的节点无法学习其表达。
因此,本文提出了一种基于大语言模型来回答知识图谱上一阶逻辑查询的方法LARK(Language-guided Abstract Reasoning over Knowledge graphs)。LARK通过查询中的实体和关系找到知识图谱中的相关子图作为上下文,利用大预言模型中农的prompting方法对分解后的query进行解答,具体的流程如下图。
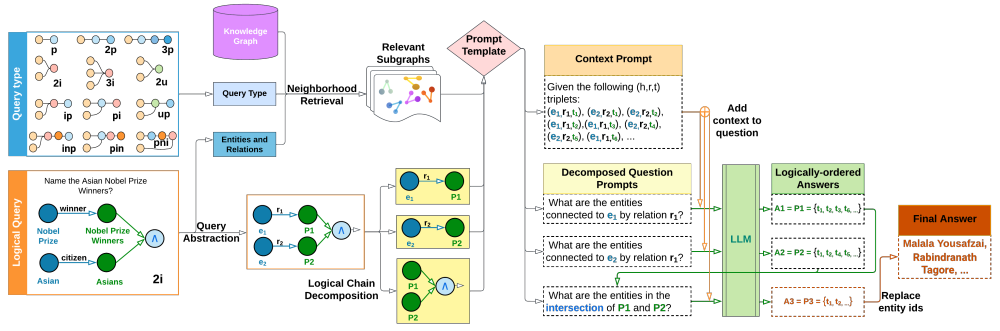
首先,Query Abstraction将所有的实体和关系都用ID来表示,以提高不同图谱和查询上的泛化能力。Neighborhood Retrieval将所有查询图中出现实体和关系的k跳内子图检索出来,作为上下文。
下一步,Logical Chain Decomposition将逻辑查询分解为一个子查询序列,利用k跳内的子图作为上下文提示词,按序回答每一个分解的子问题,最终得到查询的答案。
实验部分分为以下几个部分,分别解答下列问题。
问题1:LARK在复杂推理任务上的有效性
如下图,在大部分query形式中,LARK都是效果最好的方法。
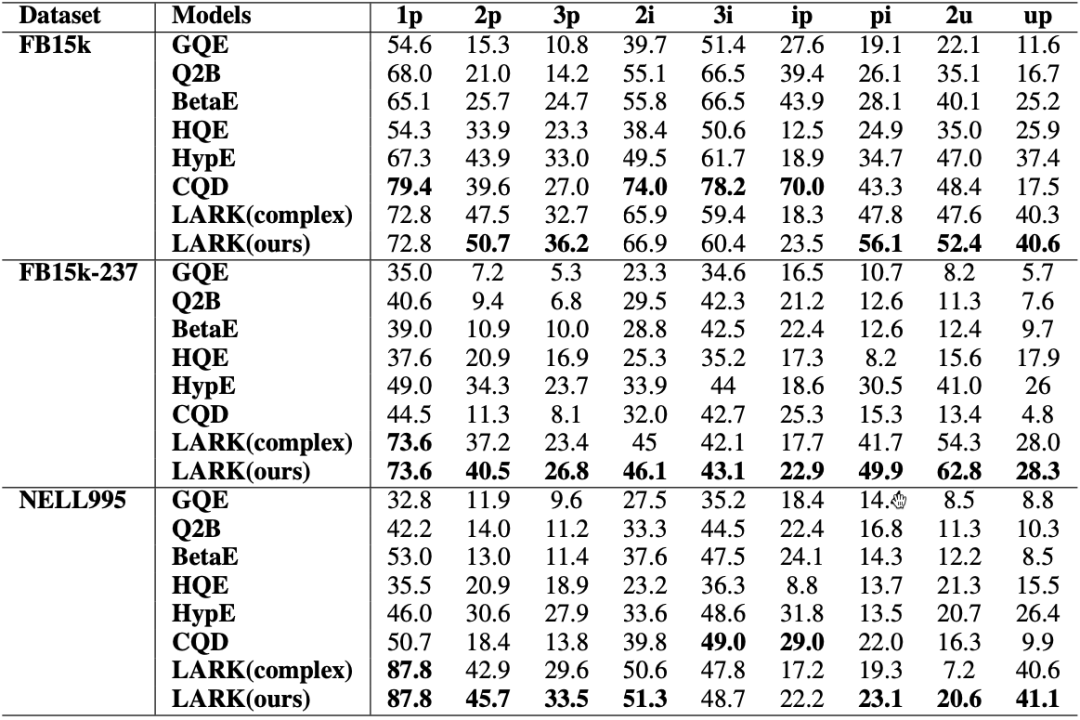
问题2:将查询图链式分解的优势
由上图,我们可以看到跳数多的查询下,LARK带来的效果提升更为明显。
问题3:大预言模型的规模对效果的影响
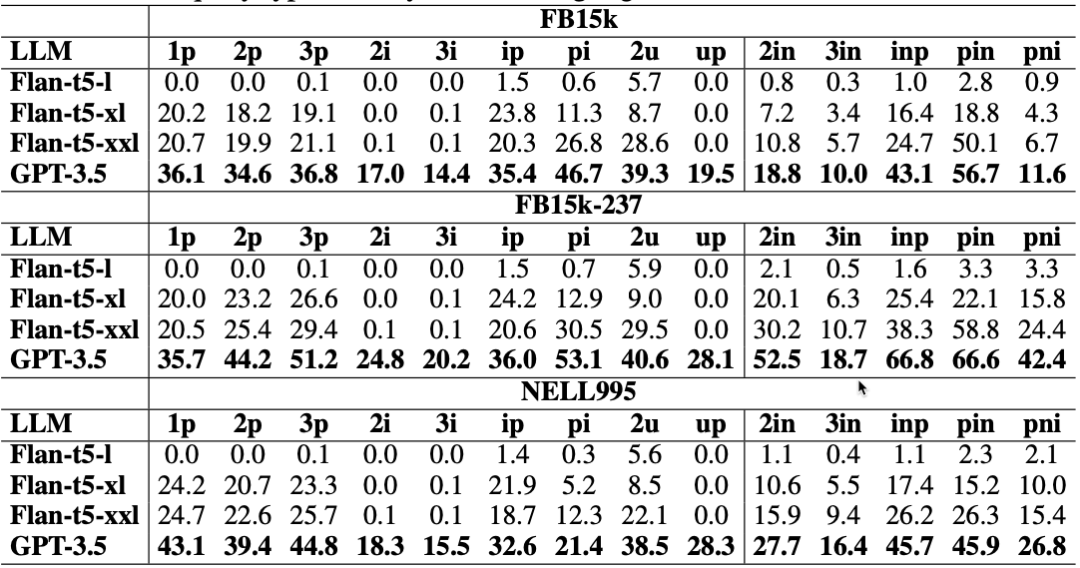
毋庸置疑,在所有的查询形式下,参数量更大的语言模型都会得到更好的表现。

问题4:大预言模型Token数对效果的影响
在实验中,T5模型的token限制设置为2048,GPT-3.5的token限制为4096,实验选取了上下文token数大于2048的查询进行测试,由于模型学到的上下文更加丰富,这些查询使用更大token数的语言模型会得到更好的效果。
总 结
利用大语言模型解决自然语言复杂推理问题是近期的热点问题,将复杂问题拆解为易得到正确答案的子问题是其中的关键问题之一。知识图谱的逻辑查询图天然的有向无环图形式为复杂问题精准拆解为具有拓扑序的简单子问题序列带来了天然的优势。将大语言模型的推理能力与知识图谱的结构化知识融合,带来更好的推理能力是未来可能的研究方向。
参考文献
[1] J. Wei, X. Wang, D. Schuurmans, et al. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems.
[2] D. Zhou, N. Schärli, L. Hou, et al. (2023). Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. The Eleventh International Conference on Learning Representations.
[3] D. Dua, S. Gupta, S. Singh, et al. (2022). Successive Prompting for Decomposing Complex Questions. Conference on Empirical Methods in Natural Language Processing.
[4] N. Choudhary, C. Reddy. (2023). Complex Logical Reasoning over Knowledge Graphs using Large Language Models. Arxiv.
相关文章:
论文导读 | 大语言模型与知识图谱复杂逻辑推理
前 言 大语言模型,尤其是基于思维链提示词(Chain-of Thought Prompting)[1]的方法,在多种自然语言推理任务上取得了出色的表现,但不擅长解决比示例问题更难的推理问题上。本文首先介绍复杂推理的两个分解提示词方法&a…...

数智竞技何以成为“科技+体育”新样本?
文 | 智能相对论 作者 | 青月 “欢迎来到,钢铁突袭。” 三人一组,头戴VR设备,中国香港队和泰国队在数实融合的空间里捉对厮杀,通过互相射击对方能量铠甲获取积分。 虽然双方都展现出了极强的机动性,但显然中国香港队…...

Vue项目Jenkins自动化部署
1. 需求描述 我们希望提交uat分支时,UAT项目能够自动发布,提交master分支时,无需自动发布,管理员手工发布 2. 效果展示 3. 采用技术 Jenkins + K8S + Docker + Nginx 4. 具体实现 4.1 编写default.conf 在Vue项目根目录新建default.conf文件,主要进行代理配置、首页…...
特效!视频里的特效在哪制作——Adobe After Effects
今天,我们来谈谈一款在Adobe系列中推出的一款图形视频处理软件,适用于从事设计和视频特技的机构,包括电视台、动画制作公司、个人后期制作工作室以及多媒体工作室的属于层类型后期软件——Adobe After Effects。 Adobe After Effects…...
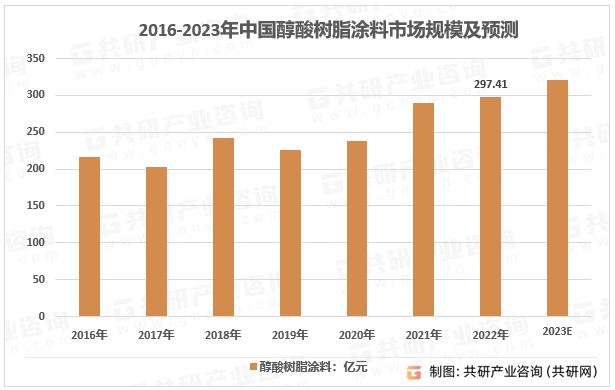
2023年中国醇酸树脂涂料需求量、应用领域及市场规模前景分析[图]
醇酸树脂指多元醇和多元酸与脂肪酸经过酯化缩聚生成的高聚物,其由邻苯二甲酸酐、多元醇和脂肪酸或甘油三脂肪酸酯缩合聚合而成。醇酸树脂固化成膜后,具有耐磨性好、绝缘性佳等优势,在涂料领域应用广泛。2022年醇酸树脂产量约336.3万吨&#x…...
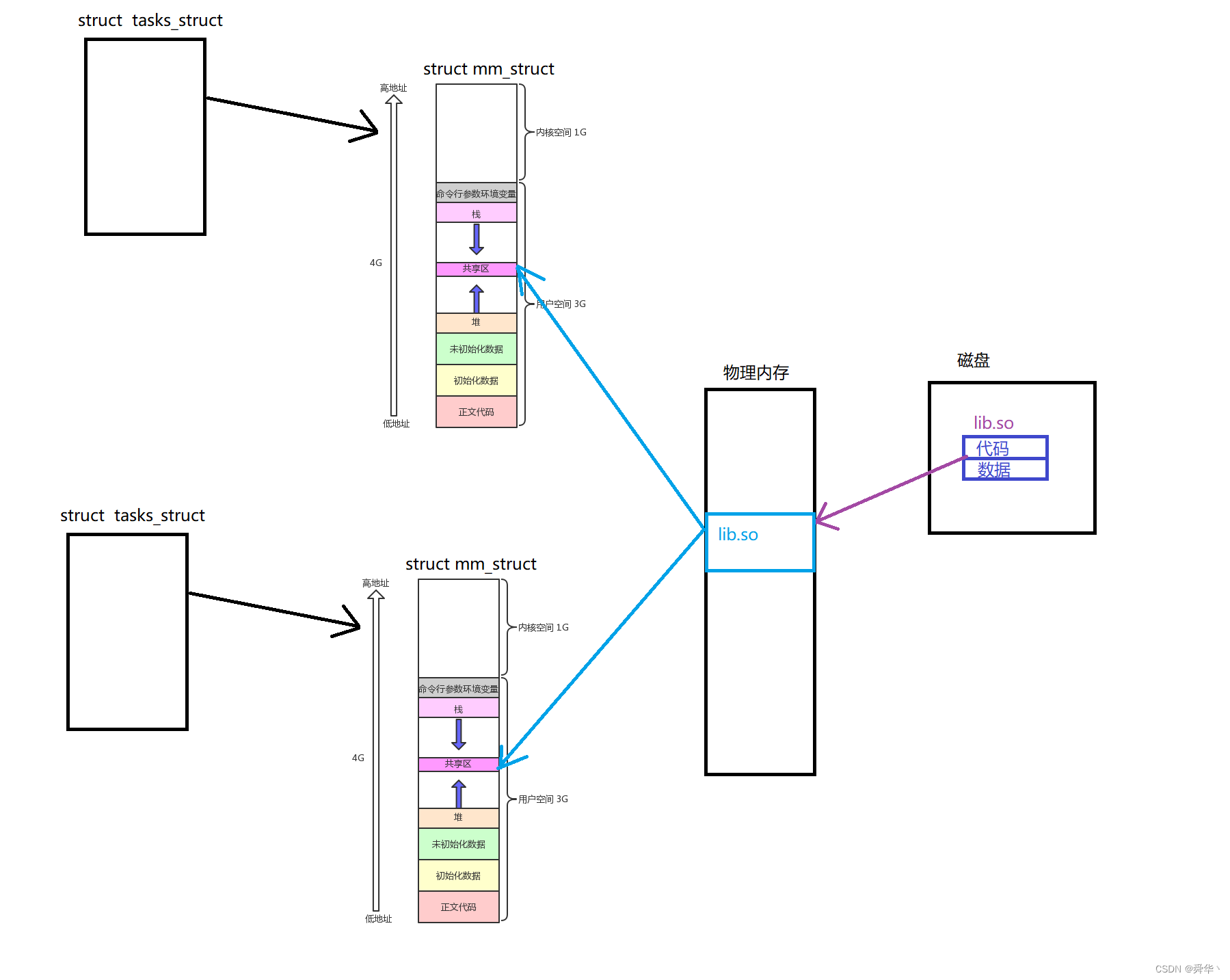
【Linux进阶之路】动静态库
文章目录 回顾一. 静态库1.代码传递的方式2.简易制作3.原理 二. 动态库1.简易制作2.基本原理 尾序 回顾 前面在gcc与g的使用中,我们简单的介绍了动态库与静态库的各自的优点与区别: 动态链接库,也就是所有的程序公用一份代码,虽然方便省空间&…...

Ubuntu磁盘扩展容量
gparted扩展...
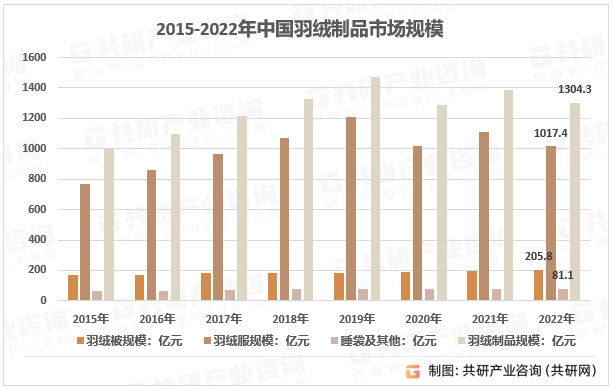
2023年中国羽绒制品需求现状、市场规模及细分产品规模分析[图]
羽绒羽毛指生长在水禽类动物(鹅、鸭)腋下、腹部羽绒和羽毛的统称,属于上游鹅鸭肉食品工业副产品的综合利用,是下游羽绒制品的填充料。根据国家标准,绒子含量≥50%的称为羽绒,绒子含量<50%的称为…...
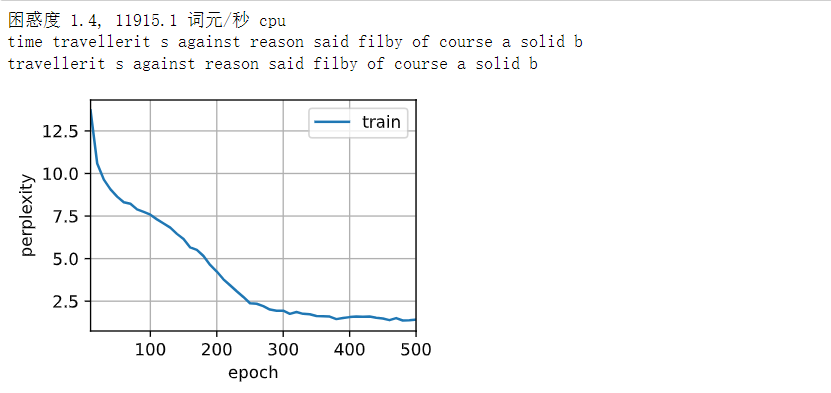
动手学深度学习——循环神经网络的从零开始实现(原理解释+代码详解)
文章目录 循环神经网络的从零开始实现1. 独热编码2. 初始化模型参数3. 循环神经网络模型4. 预测5. 梯度裁剪6. 训练 循环神经网络的从零开始实现 从头开始基于循环神经网络实现字符级语言模型。 # 读取数据集 %matplotlib inline import math import torchfrom torch import …...

【操作系统】文件系统的逻辑结构与目录结构
文章目录 文件的概念定义属性基本操作 文件的结构文件的逻辑结构文件的目录结构文件控制块(FCB)索引节点目录结构 文件的概念 定义 在操作系统中,文件被定义为:以计算机硬盘为载体的存储在计算机上的信息集合。 属性 描述文件…...
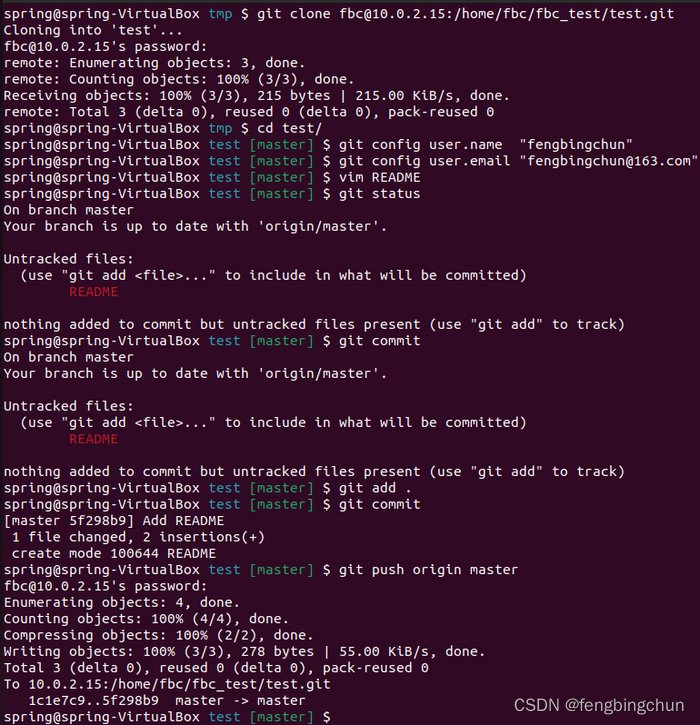
局域网内Ubuntu上搭建Git服务器
1.在局域网内选定一台Ubuntu电脑作为Git服务端: (1).新建用户如为fbc,执行如下命令:需设置密码,此为fbc sudo adduser fbc (2).切换到fbc用户:需密码,此前设置为fbc su fbc (3).建一个空目录作为仓…...

基础课10——自然语言生成
自然语言生成是让计算机自动或半自动地生成自然语言的文本。这个领域涉及到自然语言处理、语言学、计算机科学等多个领域的知识。 1.简介 自然语言生成系统可以分为基于规则的方法和基于统计的方法两大类。基于规则的方法主要依靠专家知识库和语言学规则来生成文本࿰…...

xpath
xpath 使用 使用 from lxml import etree或者 from lxml import htmlet etree.XML(xml) et etree.HTML(html) res et.xpath("/book") # 返回列表项目Valueet.xpath(“/book”)/表示根节点/div/a子节点用/依次表示/name/text()text()取文本/book//nick//表示标签…...
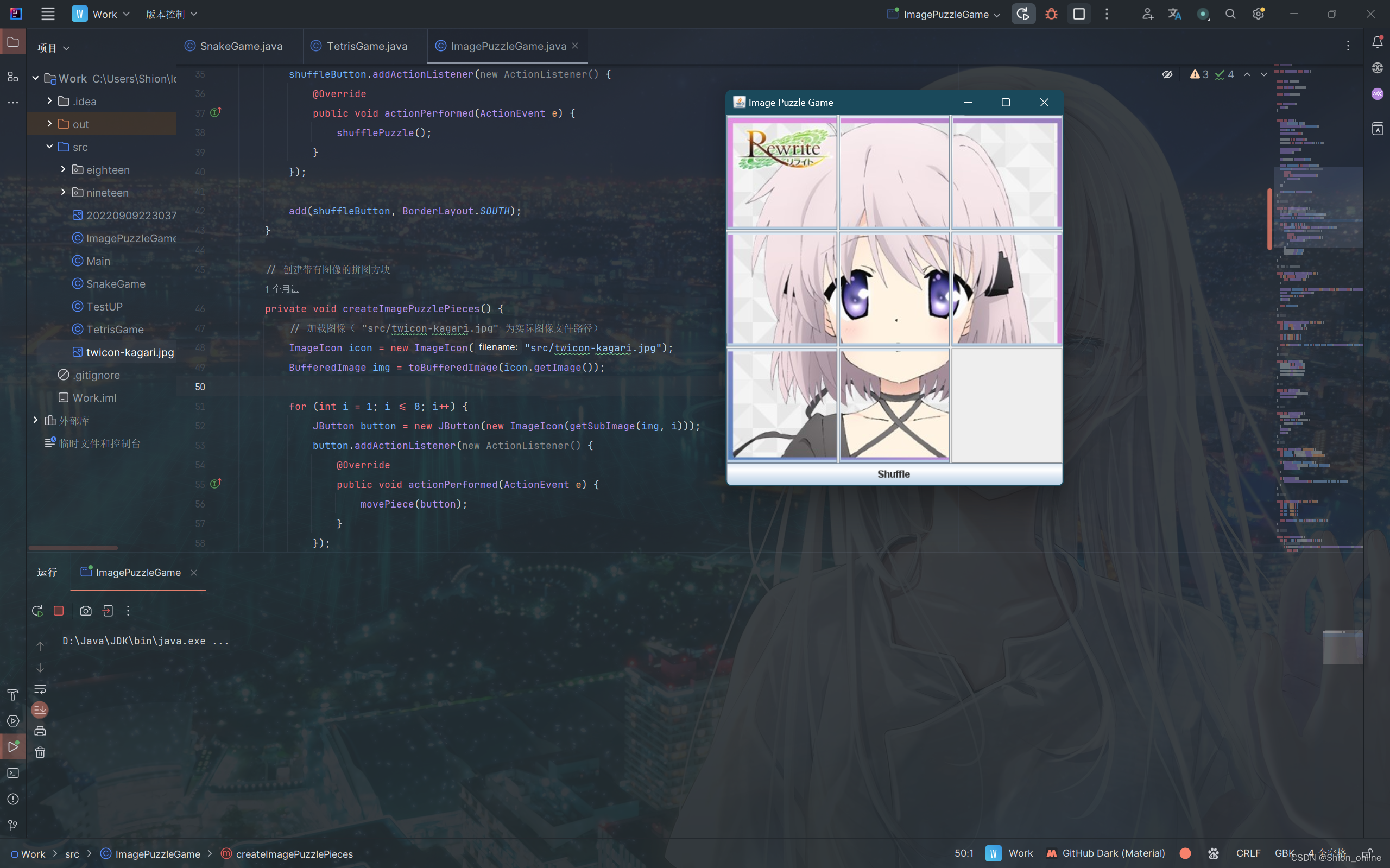
Java拼图小游戏
Java拼图小游戏 import javax.swing.*; import java.awt.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import java.awt.image.BufferedImage; import java.util.ArrayList; import java.util.Collections; import java.util.List;public cla…...

终于有人把数据资产入表知识地图总结出来了,轻松看懂
在当前数字化的浪潮下,数据已经成为劳动、土地、知识、技术以后的第五大生产要素,“数据就是资源”已成为共识。如今数据资产“入表”已成定局,数据资产化迫在眉睫。 2023年8月21日,财政部正式印发《企业数据资源相关会计处理暂行…...
白鳝:聊聊IvorySQL的Oracle兼容技术细节与实现原理
两年前听瀚高的一个朋友说他们要做一个开源数据库项目,基于PostgreSQL,主打与Oracle的兼容性,并且与PG社区版内核同步发布。当时我听了有点不太相信,瀚高的Highgo是在PG内核上增加了一定的Oracle兼容性的特性,一般也会…...
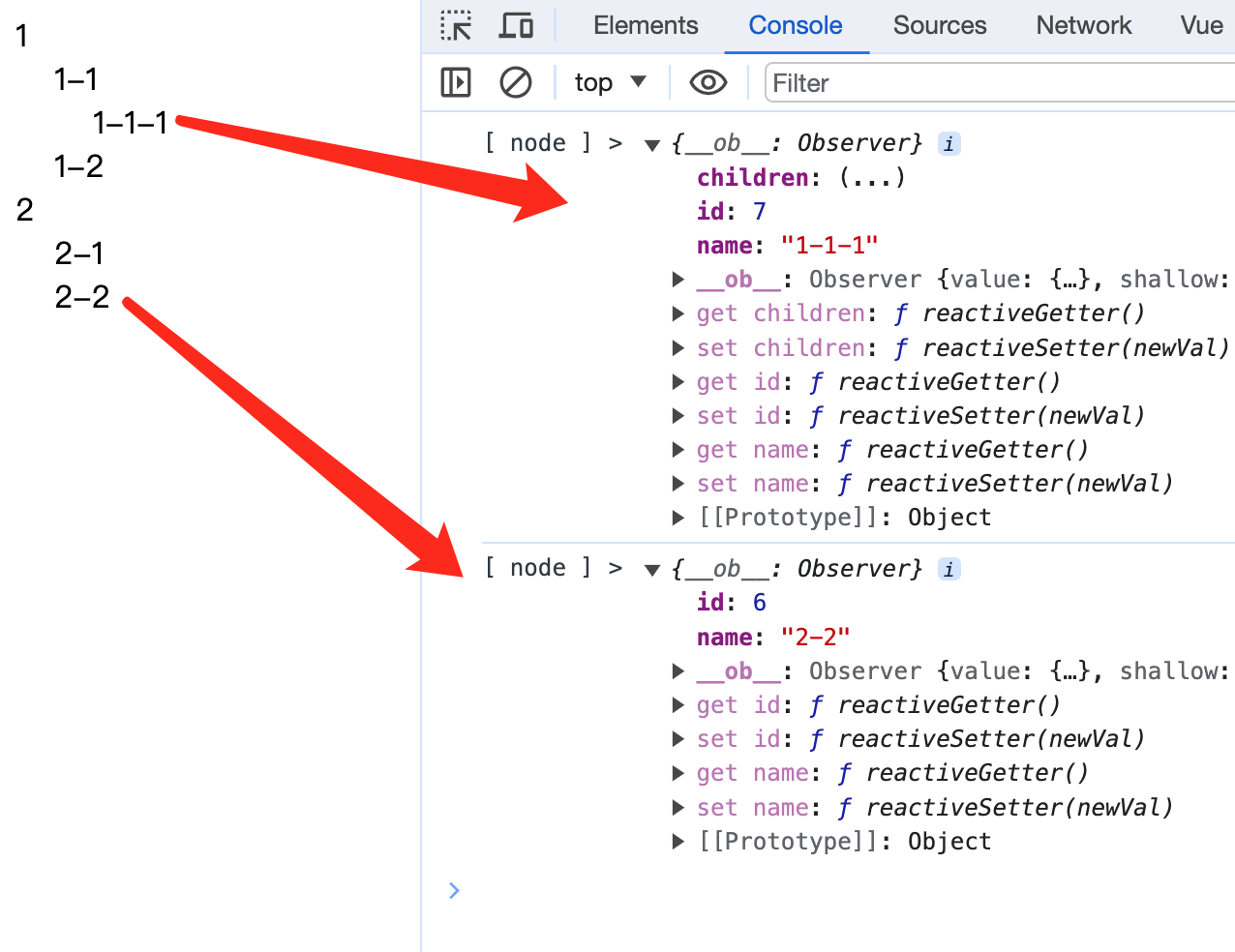
vue和uni-app的递归组件排坑
有这样一个数组数据,实际可能有很多级。 tree: [{id: 1,name: 1,children: [{ id: 2, name: 1-1, children: [{id: 7, name: 1-1-1,children: []}]},{ id: 3, name: 1-2 }]},{id: 4,name: 2,children: [{ id: 5, name: 2-1 },{ id: 6, name: 2-2 }]} ]要渲染为下面…...

【考研】数据结构(更新到顺序表)
声明:所有代码都可以运行,可以直接粘贴运行(只有库函数没有声明) 线性表的定义和基本操作 基本操作 定义 静态: #include<stdio.h> #include<stdlib.h>#define MaxSize 10//静态 typedef struct{int d…...

汇编-指针
一个变量如果包含的是另一个变量的地址, 则该变量就称为指针(pointer) 。指针是操作数组和数据结构的极好工具,因为它包含的地址在运行时是可以修改的。 .data arrayB byte 10h, 20h, 30h, 40h ptrB dword arrayB ptrB1 dword OFFSET arrayBarray…...

常见Web安全
一.Web安全概述 以下是百度百科对于web安全的解释: Web安全,计算机术语,随着Web2.0、社交网络、微博等等一系列新型的互联网产品的诞生,基于Web环境的互联网应用越来越广泛,企业信息化的过程中各种应用都架设在Web平台…...

免费解锁B站4K大会员视频下载:三步完成离线观看的终极指南
免费解锁B站4K大会员视频下载:三步完成离线观看的终极指南 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 还在为B站大会员…...

QueryExcel终极指南:5分钟搞定上百个Excel文件的批量查询神器
QueryExcel终极指南:5分钟搞定上百个Excel文件的批量查询神器 【免费下载链接】QueryExcel 多Excel文件内容查询工具。 项目地址: https://gitcode.com/gh_mirrors/qu/QueryExcel 你是否曾经面对过堆积如山的Excel文件,需要在几十甚至上百个表格中…...

U-Net与自编码器在医学图像分割与特征提取中的实战应用
1. 项目概述:从像素到洞察的桥梁在医学影像分析领域,我们每天面对的是海量的CT、MRI、病理切片图像。对于临床医生和研究员而言,仅仅“看到”图像是不够的,关键在于“理解”和“量化”。比如,一张肺部CT中,…...

终极Jable视频下载指南:3分钟掌握Chrome插件+一键保存全流程
终极Jable视频下载指南:3分钟掌握Chrome插件一键保存全流程 【免费下载链接】jable-download 方便下载jable的小工具 项目地址: https://gitcode.com/gh_mirrors/ja/jable-download 还在为无法离线保存Jable.tv上的精彩视频而烦恼吗?想要轻松将喜…...

【ETL实战】StreamSets零代码构建实时数据管道
1. StreamSets:零代码ETL的神器 第一次接触StreamSets时,我被它的可视化界面震惊了。作为一个常年和代码打交道的工程师,很难想象ETL(数据抽取、转换、加载)这种复杂的数据处理流程,竟然可以不用写一行代码…...

Arm Musca-B1时钟系统架构与低功耗配置详解
1. Arm Musca-B1时钟系统架构解析 在嵌入式系统开发中,时钟管理是决定系统性能和功耗的关键因素。Arm Musca-B1测试芯片采用了一套高度灵活的时钟架构,通过寄存器配置可以实现精确的时钟控制。这套架构主要由以下几个核心组件构成: PLL&…...

测试数据管理的艺术:如何在合规前提下制造有效数据
一、测试数据管理:软件质量的隐形基石在软件测试领域,测试数据的重要性堪比建筑工程中的钢筋水泥。它是验证软件功能、性能、安全性的核心载体,直接决定了测试结果的可信度与有效性。然而,随着数据隐私法规的日益严苛(…...

CANN/Hunyuan3D昇腾适配
在昇腾训练平台上适配Hunyuan3D 2.0 模型的推理 【免费下载链接】cann-recipes-spatial-intelligence 本项目针对空间智能业务中的典型模型、加速算法,提供基于CANN平台的优化样例 项目地址: https://gitcode.com/cann/cann-recipes-spatial-intelligence Hu…...

Haft:AI辅助开发中的工程治理与决策可追溯性实践
1. 项目概述:Haft——AI辅助软件交付的工程治理层在AI编码助手(如Claude Code、Cursor)日益普及的今天,我们正面临一个全新的工程挑战:代码生成的速度前所未有,但生成代码背后的决策质量、长期可维护性以及…...

AI智能体工作区管理技能:结构化项目模板与自动化实践
1. 项目概述与核心价值如果你和我一样,每天要在多个项目、不同领域的文档和代码仓库之间来回切换,那你一定对“工作区混乱”这件事深恶痛绝。今天要聊的这个workspace-manager-skill,就是专门为解决这个痛点而生的。它不是一个独立的应用&…...