动手学深度学习——循环神经网络的从零开始实现(原理解释+代码详解)
文章目录
- 循环神经网络的从零开始实现
- 1. 独热编码
- 2. 初始化模型参数
- 3. 循环神经网络模型
- 4. 预测
- 5. 梯度裁剪
- 6. 训练
循环神经网络的从零开始实现
从头开始基于循环神经网络实现字符级语言模型。
# 读取数据集
%matplotlib inline
import math
import torchfrom torch import nn
from torch.nn import functional as F
from d2l import torch as d2lbatch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
1. 独热编码
每个词元都有一个对应的索引,表示为特征向量,即每个索引映射为相互不同的单位向量。
词元表不同词元个数为N,词元索引范围为0到N-1。词元的索引为整数,那么将创建一个长度为N的全0向量,并将第i处元素设置为1。则此向量是原始词元的一个独热编码。
假如有2个词元"cat"和"dog"
- "cat"对应:[1, 0]
- "dog"对应:[0, 1]
索引为0和2的独热向量
# 索引为0和2的独热向量
F.one_hot(torch.tensor([0, 2]), len(vocab))
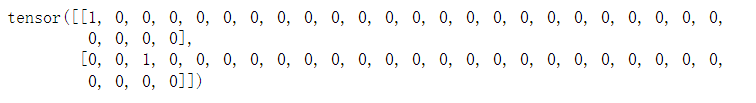
采样的小批量数据形状为二维张量:(批量大小,时间步数),one_hot函数将其转换为三维张量:(时间步数,批量大小,词表大小)
# 采样的小批量数据形状为二维张量:(批量大小,时间步数)
# one_hot函数将其转换为三维张量:(时间步数,批量大小,词表大小)
# 方便我们通过最外层维度,一步一步更新小批量数据的隐状态
X = torch.arange(10).reshape((2, 5))
print(F.one_hot(X.T, 28).shape)
# 显示第一行
F.one_hot(X.T, 28)[0,:,:]

2. 初始化模型参数
隐藏单元数num_hiddens是一个可调的超参数
训练语言模型时,输入和输出来自相同的词表,具有相同的维度即词表大小
"""
初始化模型参数:1、隐藏层参数2、输出层参数3、附加梯度
"""
# (词表大小,隐藏层数,设备)
def get_params(vocab_size, num_hiddens, device):num_inputs = num_outputs = vocab_size# 定义函数normal(),初始化模型的参数def normal(shape):return torch.randn(size=shape, device=device) * 0.01# 隐藏层参数W_xh = normal((num_inputs, num_hiddens))W_hh = normal((num_hiddens, num_hiddens))b_h = torch.zeros(num_hiddens, device=device)# 输出层参数W_hq = normal((num_hiddens, num_outputs))b_q = torch.zeros(num_outputs, device=device)# 附加梯度params = [W_xh, W_hh, b_h, W_hq, b_q]for param in params:param.requires_grad_(True)return params
3. 循环神经网络模型
定义init_rnn_state函数在初始化时返回隐状态,该函数的返回是一个张量,张量全用0填充,形状为(批量大小,隐藏单元数)。
# 定义init_rnn_state函数在初始化时返回隐状态
# 该函数的返回是一个张量,张量全用0填充,形状为(批量大小,隐藏单元数)
def init_rnn_state(batch_size, num_hiddens, device):return (torch.zeros((batch_size, num_hiddens), device=device), )

循环神经网络通过最外层的维度实现循环,以便时间步更新小批量数据的隐状态H
# 循环神经网络通过最外层的维度实现循环,以便时间步更新小批量数据的隐状态H
def rnn(inputs, state, params):# inputs的形状:(时间步数量,批量大小,词表大小)W_xh, W_hh, b_h, W_hq, b_q = paramsH, = stateoutputs = []# X的形状:(批量大小,词表大小)for X in inputs:# 激活函数tanh,更新隐状态HH = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)Y = torch.mm(H, W_hq) + b_qoutputs.append(Y)return torch.cat(outputs, dim=0), (H,)
创建一个类来包装这些函数, 并存储从零开始实现的循环神经网络模型的参数
"""
从零开始实现的循环神经网络模型:
1、定义网络模型的参数
2、对词表进行独热编码
3、初始化模型参数并返回隐状态
"""
class RNNModelScratch: #@save"""从零开始实现的循环神经网络模型"""# 定义类的初始化,将传入的参数赋值给对象的属性,以便后续使用def __init__(self, vocab_size, num_hiddens, device,get_params, init_state, forward_fn):self.vocab_size, self.num_hiddens = vocab_size, num_hiddensself.params = get_params(vocab_size, num_hiddens, device)self.init_state, self.forward_fn = init_state, forward_fndef __call__(self, X, state):# 对输入进行独热编码,返回状态及参数X = F.one_hot(X.T, self.vocab_size).type(torch.float32)return self.forward_fn(X, state, self.params)def begin_state(self, batch_size, device):# 初始化参数return self.init_state(batch_size, self.num_hiddens, device)
检查输出是否具有正确的形状。 例如,隐状态的维数是否保持不变。
num_hiddens = 512
# 网络模型
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn)
# 获得网络初始状态
state = net.begin_state(X.shape[0], d2l.try_gpu())
# 将X移到GPU上,并且返回输出Y和状态
Y, new_state = net(X.to(d2l.try_gpu()), state)
Y.shape, len(new_state), new_state[0].shape
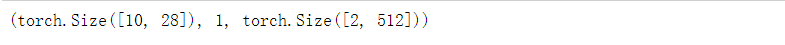
可以看到输出形状是(时间步数x批量大小,词表大小), 而隐状态形状保持不变,即(批量大小,隐藏单元数)。
4. 预测
定义预测函数
"""
定义预测函数:
1、prefix是用户提供的字符串;
2、循环遍历prefix的开始字符时不输出,不断将隐状态传递给下一个时间步;
3、在此期间模型进行自我更新(隐状态),不进行预测;
4、2和3步骤称为预热期,预热期过后隐状态的值更适合预测,从而预测字符并输出。
"""
# prefix:前缀字符串
def predict_ch8(prefix, num_preds, net, vocab, device): #@save"""在prefix后面生成新字符"""state = net.begin_state(batch_size=1, device=device)outputs = [vocab[prefix[0]]]# 匿名函数:改变输出的形状get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1))# 预热期:不进行输出for y in prefix[1:]: # 预热期_, state = net(get_input(), state)outputs.append(vocab[y])# 预热期过了之后,进行预测for _ in range(num_preds): # 预测num_preds步y, state = net(get_input(), state)outputs.append(int(y.argmax(dim=1).reshape(1)))return ''.join([vocab.idx_to_token[i] for i in outputs])
测试predict_ch8函数。 我们将前缀指定为time traveller, 并基于这个前缀生成10个后续字符
# 测试predict_ch8函数。 我们将前缀指定为time traveller, 并基于这个前缀生成10个后续字符。
# 未训练模型,输出预测结果没有联系
predict_ch8('time traveller ', 10, net, vocab, d2l.try_gpu())

5. 梯度裁剪
为什么要梯度裁剪:
1、对于长度为T的序列,我们在迭代中计算T个时间步上的梯度,在反向传播过程中产生长度为T的矩阵乘法链;
2、T较大时,会导致数值不稳定,例如梯度消失或者梯度爆炸。
一个流行的替代方案是通过将梯度g投影回给定半径 (例如θ)的球来裁剪梯度g。

def grad_clipping(net, theta): #@save"""裁剪梯度"""if isinstance(net, nn.Module):# 附加梯度的参数params = [p for p in net.parameters() if p.requires_grad]else:# 梯度的范数:对应图里作为分母的"||g||"params = net.paramsnorm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))# 如果梯度过大,将其限制到θif norm > theta:for param in params:param.grad[:] *= theta / norm
6. 训练
在一个迭代周期内训练模型:
1、序列数据的不同采样方法(随机采样和顺序分区)将导致状态初始化的差异;
2、在更新模型参数之前裁剪梯度,这样可以保证训练过程中如果某点发生梯度爆炸,模型也不会发散;
3、用困惑度评价模型,使得不同长度的序列也有了可比性。
- 顺序分区:只在每个迭代周期的开始位置初始化隐状态。
- 随机抽样:每个样本都是在一个随机位置抽样的,因此需要在每个迭代周期重新初始化隐状态。
#@save
"""
训练网络一个迭代周期:
1、初始化状态,将数据传到GPU上
2、计算损失,进行梯度裁剪并更新模型参数
"""
def train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter):"""训练网络一个迭代周期(定义见第8章)"""# 状态,时间state, timer = None, d2l.Timer()metric = d2l.Accumulator(2) # 训练损失之和,词元数量for X, Y in train_iter:if state is None or use_random_iter:# 在第一次迭代或使用随机抽样时初始化statestate = net.begin_state(batch_size=X.shape[0], device=device)else:if isinstance(net, nn.Module) and not isinstance(state, tuple):# state对于nn.GRU是个张量# detach_()将张量从计算图中分离出来,不会影响到原始张量state.detach_()else:# state对于nn.LSTM或对于我们从零开始实现的模型是个张量for s in state:s.detach_()# 将Y 进行转置并展平成一维向量y = Y.T.reshape(-1)# 将X,y移动到设备上,并且输入到模型中X, y = X.to(device), y.to(device)y_hat, state = net(X, state)l = loss(y_hat, y.long()).mean()# 如果更新器 updater 是 torch.optim.Optimizer 类型,则调用 updater.step() 方法进行参数更新;# 否则调用 updater(batch_size=1) 进行参数更新。if isinstance(updater, torch.optim.Optimizer):updater.zero_grad() # 梯度置零l.backward() # 反向传播,知道如何调整参数以最小化损失函数grad_clipping(net, 1) # 梯度裁剪updater.step() # 使用优化器来更新参数else:l.backward()grad_clipping(net, 1)# 因为已经调用了mean函数updater(batch_size=1)# y.numel()计算y中元素数量metric.add(l * y.numel(), y.numel())# 使用指数损失函数计算累积平均困惑度 math.exp(metric[0] / metric[1]) 和训练速度 metric[1] / timer.stop()。return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
- updater.zero_grad(): 这一行代码将模型参数的梯度置零,以便在每次迭代中计算新的梯度。
- l.backward(): 这一行代码使用反向传播算法计算损失函数对模型参数的梯度。通过计算梯度,我们可以知道如何调整模型参数以最小化损失函数。
- grad_clipping(net, 1): 这一行代码对模型的梯度进行裁剪,以防止梯度爆炸的问题。梯度爆炸可能会导致训练不稳定,裁剪梯度可以限制梯度的范围。
- updater.step(): 这一行代码使用优化器(如SGD、Adam等)来更新模型的参数。优化器根据计算得到的梯度和预定义的学习率来更新模型参数,以使模型更好地拟合训练数据。
循环神经网络的训练函数也支持高级API实现
# 循环神经网络的训练函数也支持高级API实现
#@save
def train_ch8(net, train_iter, vocab, lr, num_epochs, device,use_random_iter=False):"""训练模型(定义见第8章)"""loss = nn.CrossEntropyLoss()# 动画窗口:窗口显示一个图例,图例名称为 "train",x 轴的范围从 10 到 num_epochsanimator = d2l.Animator(xlabel='epoch', ylabel='perplexity',legend=['train'], xlim=[10, num_epochs])# 初始化if isinstance(net, nn.Module):updater = torch.optim.SGD(net.parameters(), lr)else:updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device)# 训练和预测for epoch in range(num_epochs):ppl, speed = train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter)# 每10个epoch,对输入字符串进行预测,并将预测结果添加到动画中if (epoch + 1) % 10 == 0:print(predict('time traveller'))animator.add(epoch + 1, [ppl])print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')print(predict('time traveller'))print(predict('traveller'))
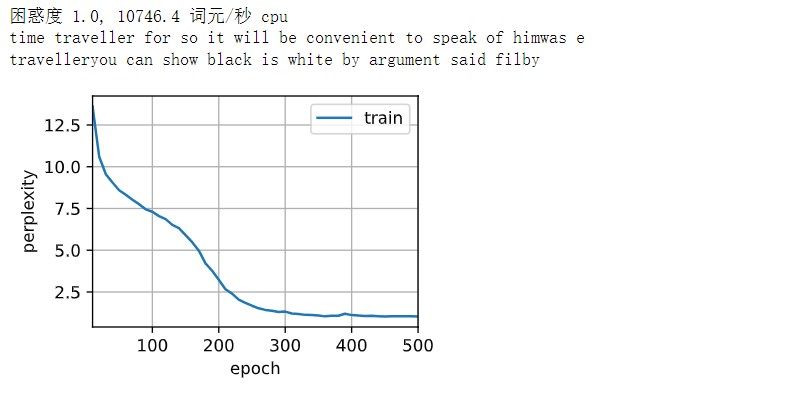
在数据集中只使用了10000个词元, 所以模型需要更多的迭代周期来更好地收敛
# 在数据集中只使用了10000个词元, 所以模型需要更多的迭代周期来更好地收敛
num_epochs, lr = 500, 1
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu())
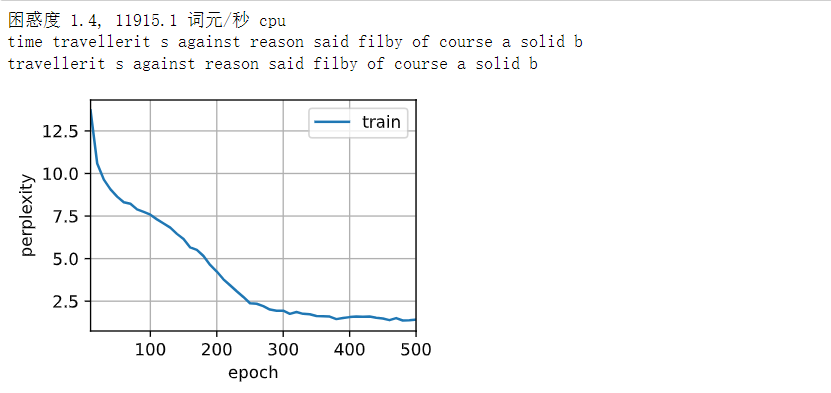
检查一下随机抽样方法的结果
# 检查一下随机抽样方法的结果
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn)
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu(),use_random_iter=True)
相关文章:
动手学深度学习——循环神经网络的从零开始实现(原理解释+代码详解)
文章目录 循环神经网络的从零开始实现1. 独热编码2. 初始化模型参数3. 循环神经网络模型4. 预测5. 梯度裁剪6. 训练 循环神经网络的从零开始实现 从头开始基于循环神经网络实现字符级语言模型。 # 读取数据集 %matplotlib inline import math import torchfrom torch import …...

【操作系统】文件系统的逻辑结构与目录结构
文章目录 文件的概念定义属性基本操作 文件的结构文件的逻辑结构文件的目录结构文件控制块(FCB)索引节点目录结构 文件的概念 定义 在操作系统中,文件被定义为:以计算机硬盘为载体的存储在计算机上的信息集合。 属性 描述文件…...
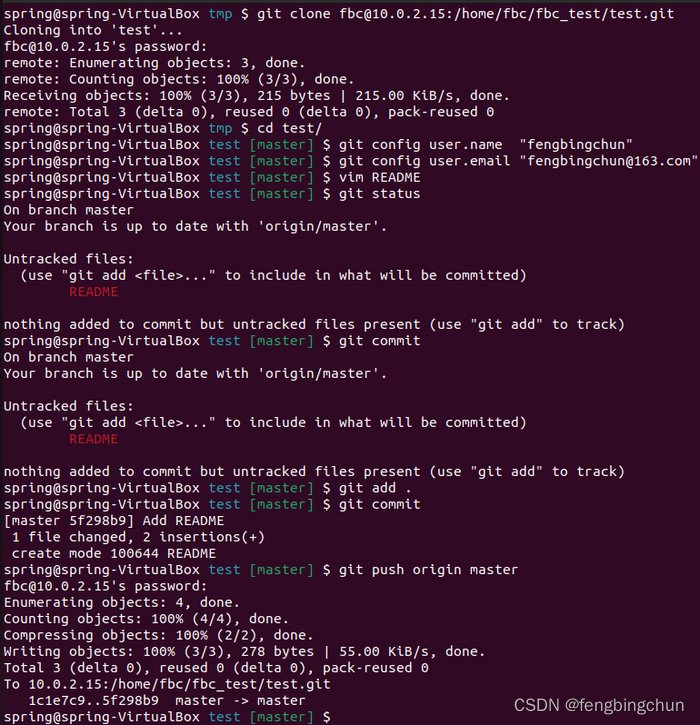
局域网内Ubuntu上搭建Git服务器
1.在局域网内选定一台Ubuntu电脑作为Git服务端: (1).新建用户如为fbc,执行如下命令:需设置密码,此为fbc sudo adduser fbc (2).切换到fbc用户:需密码,此前设置为fbc su fbc (3).建一个空目录作为仓…...

基础课10——自然语言生成
自然语言生成是让计算机自动或半自动地生成自然语言的文本。这个领域涉及到自然语言处理、语言学、计算机科学等多个领域的知识。 1.简介 自然语言生成系统可以分为基于规则的方法和基于统计的方法两大类。基于规则的方法主要依靠专家知识库和语言学规则来生成文本࿰…...

xpath
xpath 使用 使用 from lxml import etree或者 from lxml import htmlet etree.XML(xml) et etree.HTML(html) res et.xpath("/book") # 返回列表项目Valueet.xpath(“/book”)/表示根节点/div/a子节点用/依次表示/name/text()text()取文本/book//nick//表示标签…...
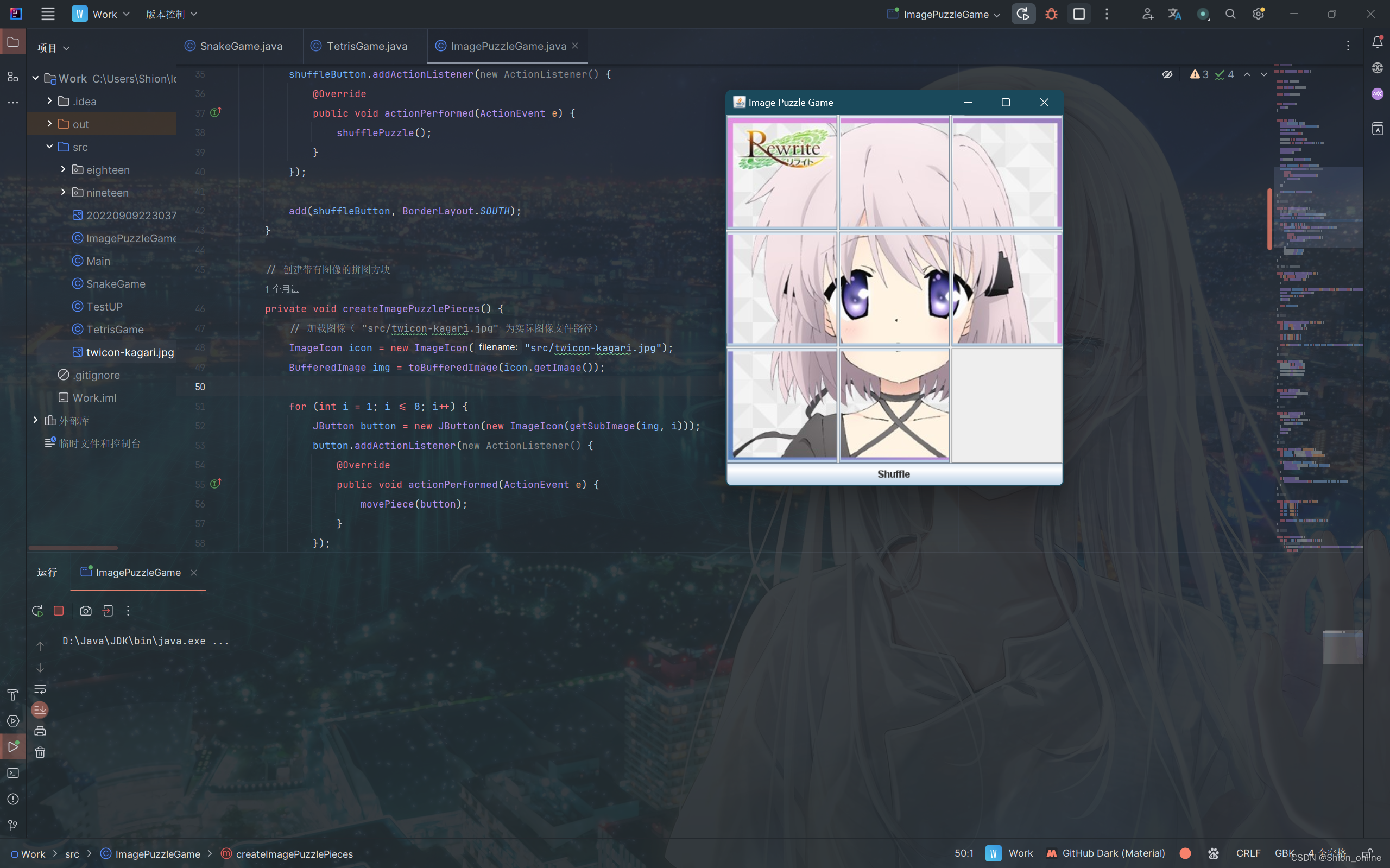
Java拼图小游戏
Java拼图小游戏 import javax.swing.*; import java.awt.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import java.awt.image.BufferedImage; import java.util.ArrayList; import java.util.Collections; import java.util.List;public cla…...

终于有人把数据资产入表知识地图总结出来了,轻松看懂
在当前数字化的浪潮下,数据已经成为劳动、土地、知识、技术以后的第五大生产要素,“数据就是资源”已成为共识。如今数据资产“入表”已成定局,数据资产化迫在眉睫。 2023年8月21日,财政部正式印发《企业数据资源相关会计处理暂行…...
白鳝:聊聊IvorySQL的Oracle兼容技术细节与实现原理
两年前听瀚高的一个朋友说他们要做一个开源数据库项目,基于PostgreSQL,主打与Oracle的兼容性,并且与PG社区版内核同步发布。当时我听了有点不太相信,瀚高的Highgo是在PG内核上增加了一定的Oracle兼容性的特性,一般也会…...
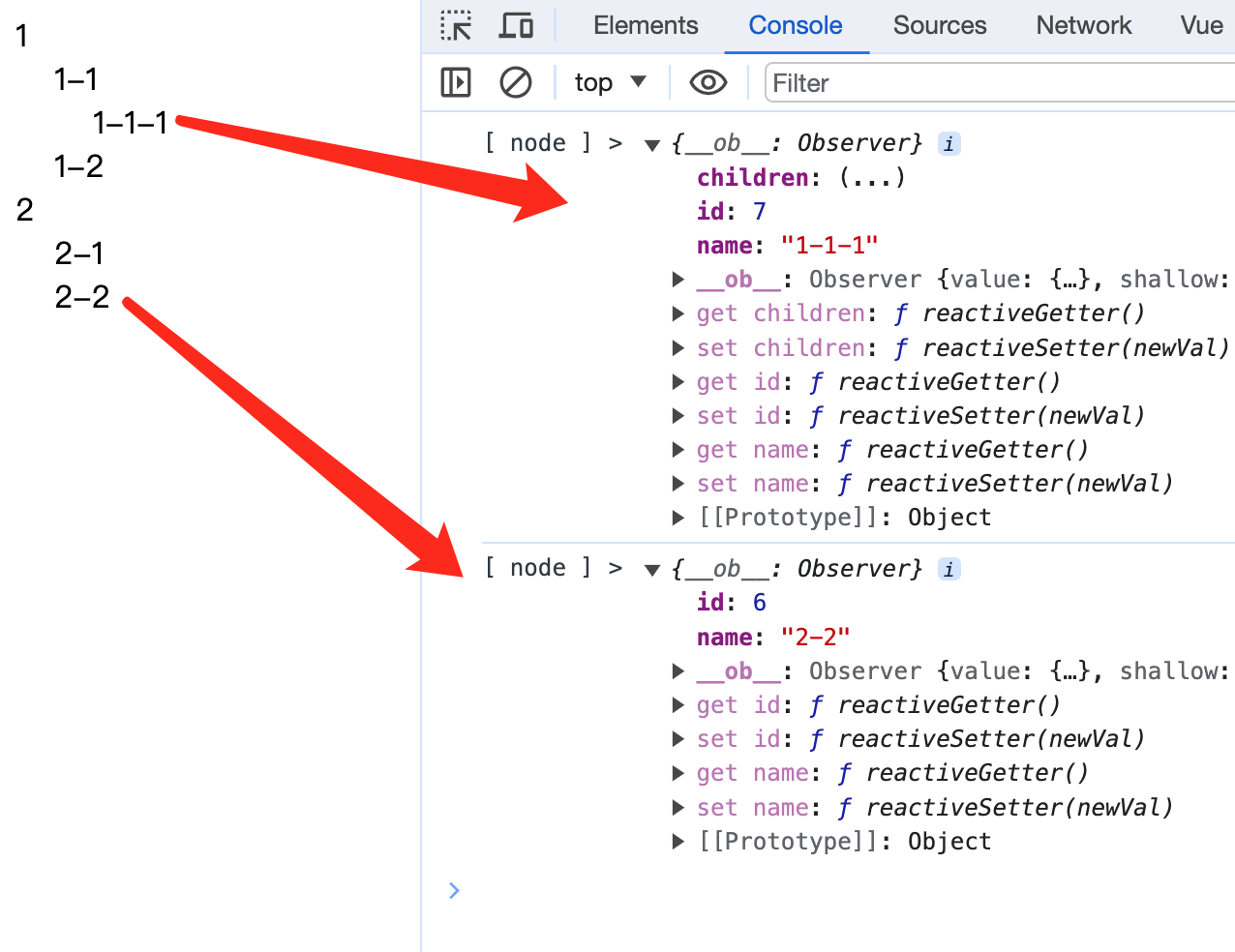
vue和uni-app的递归组件排坑
有这样一个数组数据,实际可能有很多级。 tree: [{id: 1,name: 1,children: [{ id: 2, name: 1-1, children: [{id: 7, name: 1-1-1,children: []}]},{ id: 3, name: 1-2 }]},{id: 4,name: 2,children: [{ id: 5, name: 2-1 },{ id: 6, name: 2-2 }]} ]要渲染为下面…...

【考研】数据结构(更新到顺序表)
声明:所有代码都可以运行,可以直接粘贴运行(只有库函数没有声明) 线性表的定义和基本操作 基本操作 定义 静态: #include<stdio.h> #include<stdlib.h>#define MaxSize 10//静态 typedef struct{int d…...

汇编-指针
一个变量如果包含的是另一个变量的地址, 则该变量就称为指针(pointer) 。指针是操作数组和数据结构的极好工具,因为它包含的地址在运行时是可以修改的。 .data arrayB byte 10h, 20h, 30h, 40h ptrB dword arrayB ptrB1 dword OFFSET arrayBarray…...

常见Web安全
一.Web安全概述 以下是百度百科对于web安全的解释: Web安全,计算机术语,随着Web2.0、社交网络、微博等等一系列新型的互联网产品的诞生,基于Web环境的互联网应用越来越广泛,企业信息化的过程中各种应用都架设在Web平台…...

milvus数据库搜索
一、向量相似度搜索 在Milvus中进行向量相似度搜索时,会计算查询向量和集合中具有指定相似性度量的向量之间的距离,并返回最相似的结果。通过指定一个布尔表达式来过滤标量字段或主键字段,您可以执行混合搜索。 1.加载集合 执行操作的前提是…...

HEVC参考帧技术
为了增强参考帧管理的抗差错能力,HEVC采用了参考帧集技术,通过直接在每一帧的片头码流中传输DPB中各个帧的状态变化,将当前帧以及后续帧可能用到的参考帧在DPB中都进行描述,描述以POC作为一帧的身份标识。因此,不需要依…...

QT小记:The QColor ctor taking ints is cheaper than the one taking string literals
这个警告意味着在使用 Qt 的 C 代码中,使用接受整数参数的 QColor 构造函数比使用接受字符串字面值的构造函数更有效率。 要解决这个警告,你可以修改你的代码,尽可能使用接受整数参数的 QColor 构造函数,而不是字符串字面值。例如…...

机器人走迷宫问题
题目 1.房间有XY的方格组成,例如下图为64的大小。每一个方格以坐标(x,y) 描述。 2.机器人固定从方格(0, 0)出发,只能向东或者向北前进,出口固定为房间的最东北角,如下图的 方格(5,3)。用例保证机器人可以从入口走到出口。 3.房间…...

轻量封装WebGPU渲染系统示例<36>- 广告板(Billboard)(WGSL源码)
原理不再赘述,请见wgsl shader实现。 当前示例源码github地址: https://github.com/vilyLei/voxwebgpu/blob/feature/rendering/src/voxgpu/sample/BillboardEntityTest.ts 当前示例运行效果: WGSL顶点shader: group(0) binding(0) var<uniform> objMat :…...

Java 多线程进阶
1 方法执行与进程执行 GetMapping("/demo1")public void demo1(){//方法调用new ThreadTest1("run1").run();//线程调用new ThreadTest1("run2").start();} 下断点调试信息,可以看到run()方法当前线程是“main1” 继续运行到run里面&…...

CentOS上搭建SVN并自动同步至web目录
一、搭建svn环境并创建仓库: 1、安装Subversion: yum install svn2、创建版本库: //先建目录 cd /www mkdir wwwsvn cd wwwsvn //创建版本库 svnadmin create xiangmumingcheng二、创建用户组及用户: 1、 进入版本库中的配…...
.Net中Redis的基本使用
前言 Redis可以用来存储、缓存和消息传递。它具有高性能、持久化、高可用性、扩展性和灵活性等特点,尤其适用于处理高并发业务和大量数据量的系统,它支持多种数据结构,如字符串、哈希表、列表、集合、有序集合等。 Redis的使用 安装包Ser…...

DPlayer实战指南:构建现代化弹幕视频播放器的核心技巧
DPlayer实战指南:构建现代化弹幕视频播放器的核心技巧 【免费下载链接】DPlayer :lollipop: Wow, such a lovely HTML5 danmaku video player 项目地址: https://gitcode.com/gh_mirrors/dp/DPlayer 当你需要在Web应用中集成一个功能丰富、性能优秀的视频播放…...

如何永久守护你的微信记忆?WeChatMsg让珍贵对话永不消散
如何永久守护你的微信记忆?WeChatMsg让珍贵对话永不消散 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeC…...

3个核心痛点:为什么硬件开发者需要跨平台串口调试工具
3个核心痛点:为什么硬件开发者需要跨平台串口调试工具 【免费下载链接】sscom Linux/Mac版本 串口调试助手 项目地址: https://gitcode.com/gh_mirrors/ss/sscom 在嵌入式开发和硬件调试领域,串口通信是连接计算机与硬件设备的核心桥梁。然而&…...
)
SAP S/4HANA数据迁移避坑指南:LTMC服务激活失败?检查这4个关键点(含WEBGUI测试)
SAP S/4HANA数据迁移避坑指南:LTMC服务激活失败的深度排查手册 当你在深夜的机房盯着屏幕上"Service not available"的红色错误提示时,那种挫败感我深有体会。作为经历过数十次SAP数据迁移的老兵,我想分享一些教科书上不会写的实战…...

别再手动描边了!用Altium Designer的DXF导入功能,5分钟搞定CAD机械结构图转PCB外框
高效机电协同:Altium Designer DXF导入功能在PCB设计中的实战应用 在硬件产品开发流程中,机械结构与电子设计的无缝对接一直是影响项目进度的关键节点。传统的手动描边方法不仅耗时费力,还容易引入人为误差——据统计,约37%的板框…...

逆向工程调用Google Bard:Python库实现非官方API访问与实战应用
1. 项目概述:当Bard不再是“官方应用” 如果你和我一样,对前沿的AI对话模型充满好奇,并且不满足于仅仅在网页端使用,那么你很可能已经注意到了GitHub上这个名为“LarryDpk/Google-Bard”的项目。乍一看,这似乎是一个“…...

Diablo Edit2:暗黑破坏神2角色编辑器完整指南 - 5分钟打造完美角色
Diablo Edit2:暗黑破坏神2角色编辑器完整指南 - 5分钟打造完美角色 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾在暗黑破坏神2中因为技能点分配错误而懊悔?是否…...

视频播放效率革命:如何用Video Speed Controller每天节省2小时
视频播放效率革命:如何用Video Speed Controller每天节省2小时 【免费下载链接】videospeed HTML5 video speed controller (for Google Chrome) 项目地址: https://gitcode.com/gh_mirrors/vi/videospeed 你是否厌倦了在线视频的固定播放速度?在…...

AI应用成本管理利器:tokencost库精准计算LLM API调用开销
1. 项目概述:一个AI成本计算的“账房先生”如果你最近在折腾大语言模型(LLM)应用,无论是自己写个智能客服,还是搞个文档总结工具,大概率会遇到一个灵魂拷问:“这玩意儿跑一次,到底花…...

NestJS微服务架构实战:从模块化设计到AI辅助开发
1. 项目概述:一个为现代开发者量身定制的NestJS后端起点 如果你正在寻找一个能让你快速启动、结构清晰且面向未来的NestJS后端项目模板,那么 nestjs-vibe-coding 这个项目很可能就是你需要的。它不是又一个简单的“Hello World”示例,而是…...