关于缓存和数据库一致性问题的深入研究
如何保证缓存和数据库一致性,这是一个老生常谈的话题了。
但很多人对这个问题,依旧有很多疑惑:
- 到底是更新缓存还是删缓存?
- 到底选择先更新数据库,再删除缓存,还是先删除缓存,再更新数据库?
- 为什么要引入消息队列保证一致性?
- 延迟双删会有什么问题?到底要不要用?
- ...
这篇文章,我们就来把这些问题讲清楚。
这篇文章干货很多,希望你可以耐心读完。
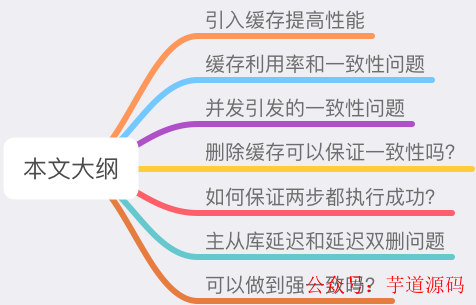
引入缓存提高性能
我们从最简单的场景开始讲起。
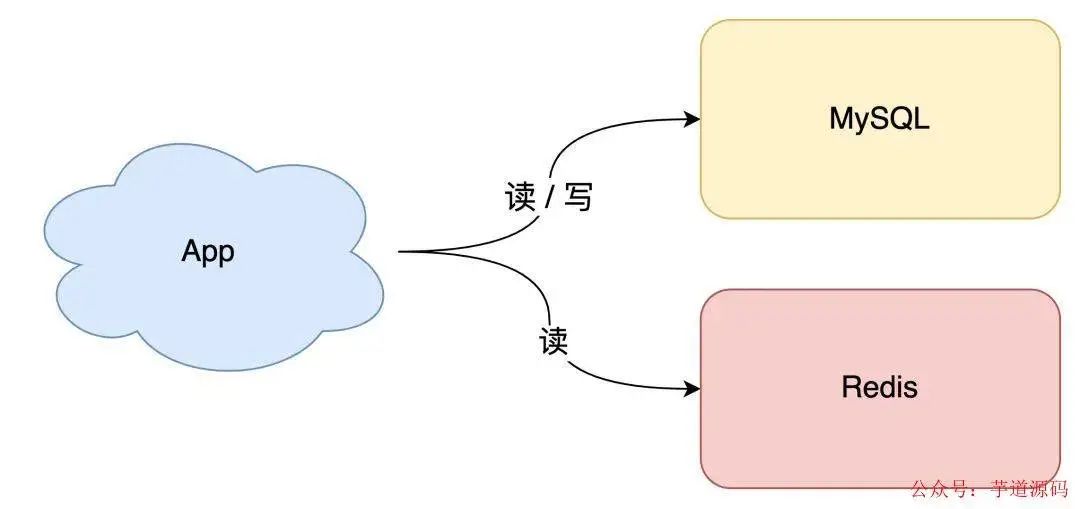
如果你的业务处于起步阶段,流量非常小,那无论是读请求还是写请求,直接操作数据库即可,这时你的架构模型是这样的:

但随着业务量的增长,你的项目请求量越来越大,这时如果每次都从数据库中读数据,那肯定会有性能问题。
这个阶段通常的做法是,引入「缓存」来提高读性能,架构模型就变成了这样:
当下优秀的缓存中间件,当属 Redis 莫属,它不仅性能非常高,还提供了很多友好的数据类型,可以很好地满足我们的业务需求。
但引入缓存之后,你就会面临一个问题:之前数据只存在数据库中,现在要放到缓存中读取,具体要怎么存呢?
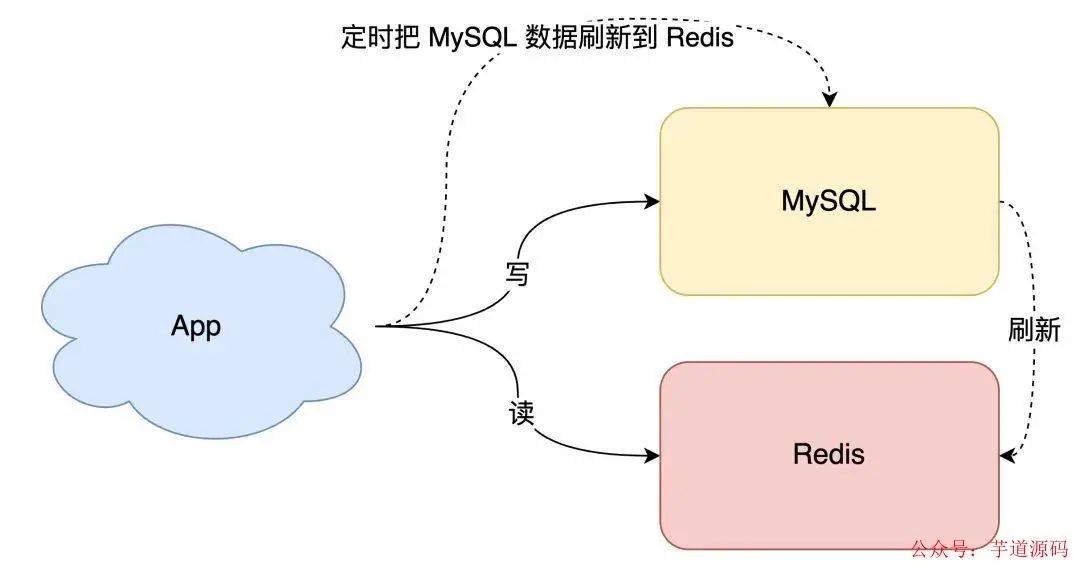
最简单直接的方案是「全量数据刷到缓存中」:
- 数据库的数据,全量刷入缓存(不设置失效时间)
- 写请求只更新数据库,不更新缓存
- 启动一个定时任务,定时把数据库的数据,更新到缓存中
这个方案的优点是,所有读请求都可以直接「命中」缓存,不需要再查数据库,性能非常高。
但缺点也很明显,有 2 个问题:
- 缓存利用率低 :不经常访问的数据,还一直留在缓存中
- 数据不一致 :因为是「定时」刷新缓存,缓存和数据库存在不一致(取决于定时任务的执行频率)
所以,这种方案一般更适合业务「体量小」,且对数据一致性要求不高的业务场景。
那如果我们的业务体量很大,怎么解决这 2 个问题呢?
推荐下自己做的 Spring Boot 的实战项目:
https://github.com/YunaiV/ruoyi-vue-pro
缓存利用率和一致性问题
先来看第一个问题,如何提高缓存利用率?
想要缓存利用率「最大化」,我们很容易想到的方案是,缓存中只保留最近访问的「热数据」。但具体要怎么做呢?
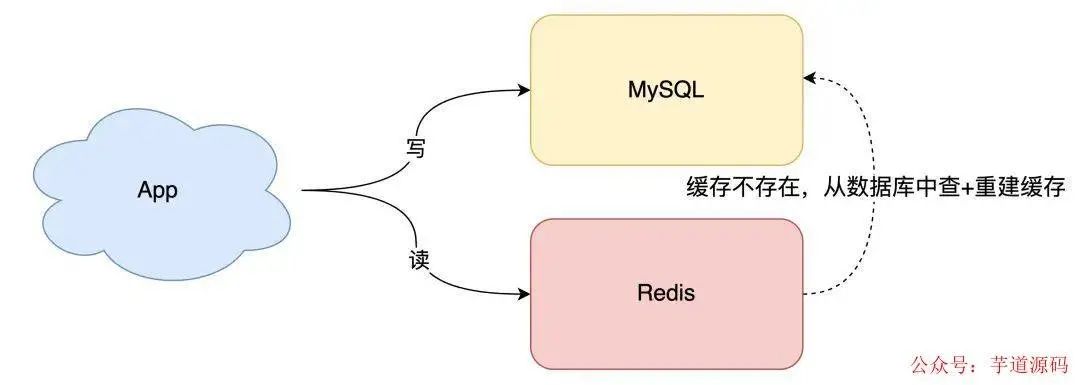
我们可以这样优化:
- 写请求依旧只写数据库
- 读请求先读缓存,如果缓存不存在,则从数据库读取,并重建缓存
- 同时,写入缓存中的数据,都设置失效时间
这样一来,缓存中不经常访问的数据,随着时间的推移,都会逐渐「过期」淘汰掉,最终缓存中保留的,都是经常被访问的「热数据」,缓存利用率得以最大化。
再来看数据一致性问题。
要想保证缓存和数据库「实时」一致,那就不能再用定时任务刷新缓存了。
所以,当数据发生更新时,我们不仅要操作数据库,还要一并操作缓存。具体操作就是,修改一条数据时,不仅要更新数据库,也要连带缓存一起更新。
但数据库和缓存都更新,又存在先后问题,那对应的方案就有 2 个:
- 先更新缓存,后更新数据库
- 先更新数据库,后更新缓存
哪个方案更好呢?
先不考虑并发问题,正常情况下,无论谁先谁后,都可以让两者保持一致,但现在我们需要重点考虑「异常」情况。
因为操作分为两步,那么就很有可能存在「第一步成功、第二步失败」的情况发生。
这 2 种方案我们一个个来分析。
1) 先更新缓存,后更新数据库
如果缓存更新成功了,但数据库更新失败,那么此时缓存中是最新值,但数据库中是「旧值」。
虽然此时读请求可以命中缓存,拿到正确的值,但是,一旦缓存「失效」,就会从数据库中读取到「旧值」,重建缓存也是这个旧值。
这时用户会发现自己之前修改的数据又「变回去」了,对业务造成影响。
2) 先更新数据库,后更新缓存
如果数据库更新成功了,但缓存更新失败,那么此时数据库中是最新值,缓存中是「旧值」。
之后的读请求读到的都是旧数据,只有当缓存「失效」后,才能从数据库中得到正确的值。
这时用户会发现,自己刚刚修改了数据,但却看不到变更,一段时间过后,数据才变更过来,对业务也会有影响。
可见,无论谁先谁后,但凡后者发生异常,就会对业务造成影响。那怎么解决这个问题呢?
别急,后面我会详细给出对应的解决方案。
我们继续分析,除了操作失败问题,还有什么场景会影响数据一致性?
这里我们还需要重点关注:并发问题 。
推荐下自己做的 Spring Cloud 的实战项目:
https://github.com/YunaiV/onemall
并发引发的一致性问题
假设我们采用「先更新数据库,再更新缓存」的方案,并且两步都可以「成功执行」的前提下,如果存在并发,情况会是怎样的呢?
有线程 A 和线程 B 两个线程,需要更新「同一条」数据,会发生这样的场景:
- 线程 A 更新数据库(X = 1)
- 线程 B 更新数据库(X = 2)
- 线程 B 更新缓存(X = 2)
- 线程 A 更新缓存(X = 1)
最终 X 的值在缓存中是 1,在数据库中是 2,发生不一致。
也就是说,A 虽然先于 B 发生,但 B 操作数据库和缓存的时间,却要比 A 的时间短,执行时序发生「错乱」,最终这条数据结果是不符合预期的。
同样地,采用「先更新缓存,再更新数据库」的方案,也会有类似问题,这里不再详述。
除此之外,我们从「缓存利用率」的角度来评估这个方案,也是不太推荐的。
这是因为每次数据发生变更,都「无脑」更新缓存,但是缓存中的数据不一定会被「马上读取」,这就会导致缓存中可能存放了很多不常访问的数据,浪费缓存资源。
而且很多情况下,写到缓存中的值,并不是与数据库中的值一一对应的,很有可能是先查询数据库,再经过一系列「计算」得出一个值,才把这个值才写到缓存中。
由此可见,这种「更新数据库 + 更新缓存」的方案,不仅缓存利用率不高,还会造成机器性能的浪费。
所以此时我们需要考虑另外一种方案:删除缓存 。
删除缓存可以保证一致性吗?
删除缓存对应的方案也有 2 种:
- 先删除缓存,后更新数据库
- 先更新数据库,后删除缓存
经过前面的分析我们已经得知,但凡「第二步」操作失败,都会导致数据不一致。
这里我不再详述具体场景,你可以按照前面的思路推演一下,就可以看到依旧存在数据不一致的情况。
这里我们重点来看「并发」问题。
1) 先删除缓存,后更新数据库
如果有 2 个线程要并发「读写」数据,可能会发生以下场景:
- 线程 A 要更新 X = 2(原值 X = 1)
- 线程 A 先删除缓存
- 线程 B 读缓存,发现不存在,从数据库中读取到旧值(X = 1)
- 线程 A 将新值写入数据库(X = 2)
- 线程 B 将旧值写入缓存(X = 1)
最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),发生不一致。
可见,先删除缓存,后更新数据库,当发生「读+写」并发时,还是存在数据不一致的情况。
2) 先更新数据库,后删除缓存
依旧是 2 个线程并发「读写」数据:
- 缓存中 X 不存在(数据库 X = 1)
- 线程 A 读取数据库,得到旧值(X = 1)
- 线程 B 更新数据库(X = 2)
- 线程 B 删除缓存
- 线程 A 将旧值写入缓存(X = 1)
最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),也发生不一致。
这种情况「理论」来说是可能发生的,但实际真的有可能发生吗?
其实概率「很低」,这是因为它必须满足 3 个条件:
- 缓存刚好已失效
- 读请求 + 写请求并发
- 更新数据库 + 删除缓存的时间(步骤 3-4),要比读数据库 + 写缓存时间短(步骤 2 和 5)
仔细想一下,条件 3 发生的概率其实是非常低的。
因为写数据库一般会先「加锁」,所以写数据库,通常是要比读数据库的时间更长的。
这么来看,「先更新数据库 + 再删除缓存」的方案,是可以保证数据一致性的。
所以,我们应该采用这种方案,来操作数据库和缓存。
好,解决了并发问题,我们继续来看前面遗留的,第二步执行「失败」导致数据不一致的问题 。
如何保证两步都执行成功?
前面我们分析到,无论是更新缓存还是删除缓存,只要第二步发生失败,那么就会导致数据库和缓存不一致。
保证第二步成功执行,就是解决问题的关键。
想一下,程序在执行过程中发生异常,最简单的解决办法是什么?
答案是:重试 。
是的,其实这里我们也可以这样做。
无论是先操作缓存,还是先操作数据库,但凡后者执行失败了,我们就可以发起重试,尽可能地去做「补偿」。
那这是不是意味着,只要执行失败,我们「无脑重试」就可以了呢?
答案是否定的。现实情况往往没有想的这么简单,失败后立即重试的问题在于:
- 立即重试很大概率「还会失败」
- 「重试次数」设置多少才合理?
- 重试会一直「占用」这个线程资源,无法服务其它客户端请求
看到了么,虽然我们想通过重试的方式解决问题,但这种「同步」重试的方案依旧不严谨。
那更好的方案应该怎么做?
答案是:异步重试 。什么是异步重试?
其实就是把重试请求写到「消息队列」中,然后由专门的消费者来重试,直到成功。
或者更直接的做法,为了避免第二步执行失败,我们可以把操作缓存这一步,直接放到消息队列中,由消费者来操作缓存。
到这里你可能会问,写消息队列也有可能会失败啊?而且,引入消息队列,这又增加了更多的维护成本,这样做值得吗?
这个问题很好,但我们思考这样一个问题:如果在执行失败的线程中一直重试,还没等执行成功,此时如果项目「重启」了,那这次重试请求也就「丢失」了,那这条数据就一直不一致了。
所以,这里我们必须把重试或第二步操作放到另一个「服务」中,这个服务用「消息队列」最为合适。这是因为消息队列的特性,正好符合我们的需求:
- 消息队列保证可靠性 :写到队列中的消息,成功消费之前不会丢失(重启项目也不担心)
- 消息队列保证消息成功投递 :下游从队列拉取消息,成功消费后才会删除消息,否则还会继续投递消息给消费者(符合我们重试的场景)
至于写队列失败和消息队列的维护成本问题:
- 写队列失败 :操作缓存和写消息队列,「同时失败」的概率其实是很小的
- 维护成本 :我们项目中一般都会用到消息队列,维护成本并没有新增很多
所以,引入消息队列来解决这个问题,是比较合适的。这时架构模型就变成了这样:

那如果你确实不想在应用中去写消息队列,是否有更简单的方案,同时又可以保证一致性呢?
方案还是有的,这就是近几年比较流行的解决方案:订阅数据库变更日志,再操作缓存 。
具体来讲就是,我们的业务应用在修改数据时,「只需」修改数据库,无需操作缓存。
那什么时候操作缓存呢?这就和数据库的「变更日志」有关了。
拿 MySQL 举例,当一条数据发生修改时,MySQL 就会产生一条变更日志(Binlog),我们可以订阅这个日志,拿到具体操作的数据,然后再根据这条数据,去删除对应的缓存。
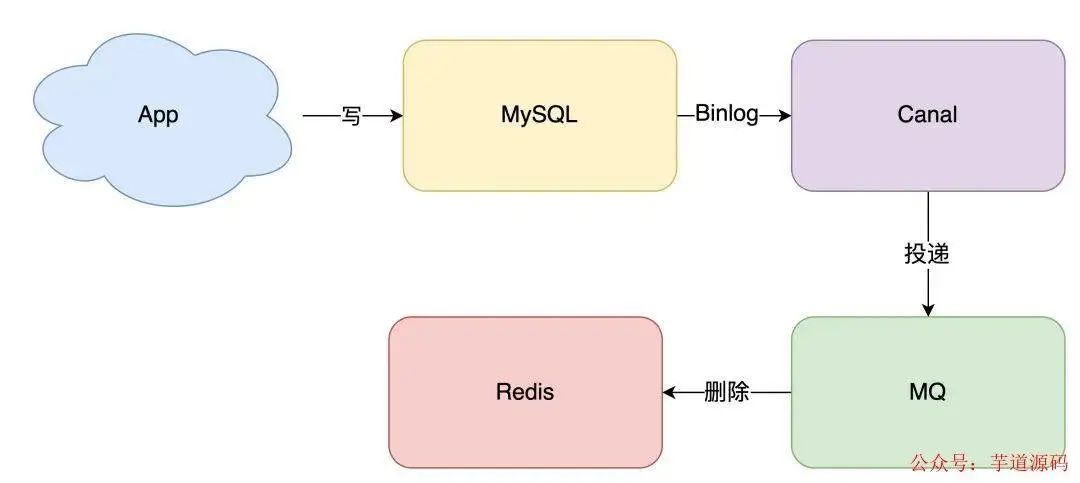
订阅变更日志,目前也有了比较成熟的开源中间件,例如阿里的 canal,使用这种方案的优点在于:
- 无需考虑写消息队列失败情况 :只要写 MySQL 成功,Binlog 肯定会有
- 自动投递到下游队列 :canal 自动把数据库变更日志「投递」给下游的消息队列
当然,与此同时,我们需要投入精力去维护 canal 的高可用和稳定性。
如果你有留意观察很多数据库的特性,就会发现其实很多数据库都逐渐开始提供「订阅变更日志」的功能了,相信不远的将来,我们就不用通过中间件来拉取日志,自己写程序就可以订阅变更日志了,这样可以进一步简化流程。
至此,我们可以得出结论,想要保证数据库和缓存一致性,推荐采用「先更新数据库,再删除缓存」方案,并配合「消息队列」或「订阅变更日志」的方式来做 。
主从库延迟和延迟双删问题
到这里,还有 2 个问题,是我们没有重点分析过的。
第一个问题 ,还记得前面讲到的「先删除缓存,再更新数据库」方案,导致不一致的场景么?
这里我再把例子拿过来让你复习一下:
2 个线程要并发「读写」数据,可能会发生以下场景:
- 线程 A 要更新 X = 2(原值 X = 1)
- 线程 A 先删除缓存
- 线程 B 读缓存,发现不存在,从数据库中读取到旧值(X = 1)
- 线程 A 将新值写入数据库(X = 2)
- 线程 B 将旧值写入缓存(X = 1)
最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),发生不一致。
第二个问题 :是关于「读写分离 + 主从复制延迟」情况下,缓存和数据库一致性的问题。
在「先更新数据库,再删除缓存」方案下,「读写分离 + 主从库延迟」其实也会导致不一致:
- 线程 A 更新主库 X = 2(原值 X = 1)
- 线程 A 删除缓存
- 线程 B 查询缓存,没有命中,查询「从库」得到旧值(从库 X = 1)
- 从库「同步」完成(主从库 X = 2)
- 线程 B 将「旧值」写入缓存(X = 1)
最终 X 的值在缓存中是 1(旧值),在主从库中是 2(新值),也发生不一致。
看到了么?这 2 个问题的核心在于:缓存都被回种了「旧值」 。
那怎么解决这类问题呢?
最有效的办法就是,把缓存删掉 。
但是,不能立即删,而是需要「延迟删」,这就是业界给出的方案:缓存延迟双删策略 。
按照延时双删策略,这 2 个问题的解决方案是这样的:
解决第一个问题 :在线程 A 删除缓存、更新完数据库之后,先「休眠一会」,再「删除」一次缓存。
解决第二个问题 :线程 A 可以生成一条「延时消息」,写到消息队列中,消费者延时「删除」缓存。
这两个方案的目的,都是为了把缓存清掉,这样一来,下次就可以从数据库读取到最新值,写入缓存。
但问题来了,这个「延迟删除」缓存,延迟时间到底设置要多久呢?
- 问题1:延迟时间要大于「主从复制」的延迟时间
- 问题2:延迟时间要大于线程 B 读取数据库 + 写入缓存的时间
但是,这个时间在分布式和高并发场景下,其实是很难评估的 。
很多时候,我们都是凭借经验大致估算这个延迟时间,例如延迟 1-5s,只能尽可能地降低不一致的概率。
所以你看,采用这种方案,也只是尽可能保证一致性而已,极端情况下,还是有可能发生不一致。
所以实际使用中,我还是建议你采用「先更新数据库,再删除缓存」的方案,同时,要尽可能地保证「主从复制」不要有太大延迟,降低出问题的概率。
可以做到强一致吗?
看到这里你可能会想,这些方案还是不够完美,我就想让缓存和数据库「强一致」,到底能不能做到呢?
其实很难。
要想做到强一致,最常见的方案是 2PC、3PC、Paxos、Raft 这类一致性协议,但它们的性能往往比较差,而且这些方案也比较复杂,还要考虑各种容错问题。
相反,这时我们换个角度思考一下,我们引入缓存的目的是什么?
没错,性能 。
一旦我们决定使用缓存,那必然要面临一致性问题。性能和一致性就像天平的两端,无法做到都满足要求。
而且,就拿我们前面讲到的方案来说,当操作数据库和缓存完成之前,只要有其它请求可以进来,都有可能查到「中间状态」的数据。
所以如果非要追求强一致,那必须要求所有更新操作完成之前期间,不能有「任何请求」进来。
虽然我们可以通过加「分布锁」的方式来实现,但我们要付出的代价,很可能会超过引入缓存带来的性能提升。
所以,既然决定使用缓存,就必须容忍「一致性」问题,我们只能尽可能地去降低问题出现的概率。
同时我们也要知道,缓存都是有「失效时间」的,就算在这期间存在短期不一致,我们依旧有失效时间来兜底,这样也能达到最终一致。(缓存中的最终一致性通过失效时间来保证)
总结
好了,总结一下这篇文章的重点。
1、想要提高应用的性能,可以引入「缓存」来解决
2、引入缓存后,需要考虑缓存和数据库一致性问题,可选的方案有:「更新数据库 + 更新缓存」、「更新数据库 + 删除缓存」
3、更新数据库 + 更新缓存方案,在「并发」场景下无法保证缓存和数据一致性,且存在「缓存资源浪费」和「机器性能浪费」的情况发生
4、在更新数据库 + 删除缓存的方案中,「先删除缓存,再更新数据库」在「并发」场景下依旧有数据不一致问题,解决方案是「延迟双删」,但这个延迟时间很难评估,所以推荐用「先更新数据库,再删除缓存」的方案
5、在「先更新数据库,再删除缓存」方案下,为了保证两步都成功执行,需配合「消息队列」或「订阅变更日志」的方案来做,本质是通过「重试」的方式保证数据一致性
6、在「先更新数据库,再删除缓存」方案下,「读写分离 + 主从库延迟」也会导致缓存和数据库不一致,缓解此问题的方案是「延迟双删」,凭借经验发送「延迟消息」到队列中,延迟删除缓存,同时也要控制主从库延迟,尽可能降低不一致发生的概率
后记
本以为这个老生常谈的话题,写起来很好写,没想到在写的过程中,还是挖到了很多之前没有深度思考过的细节。
在这里我也分享 4 点心得给你:
1、性能和一致性不能同时满足,为了性能考虑,通常会采用「最终一致性」的方案
2、掌握缓存和数据库一致性问题,核心问题有 3 点:缓存利用率、并发、缓存 + 数据库一起成功问题
3、失败场景下要保证一致性,常见手段就是「重试」,同步重试会影响吞吐量,所以通常会采用异步重试的方案
4、订阅变更日志的思想,本质是把权威数据源(例如 MySQL)当做 leader 副本,让其它异质系统(例如 Redis / Elasticsearch)成为它的 follower 副本,通过同步变更日志的方式,保证 leader 和 follower 之间保持一致
很多一致性问题,都会采用这些方案来解决,希望我的这些心得对你有所启发。
- END -
相关文章:
关于缓存和数据库一致性问题的深入研究
如何保证缓存和数据库一致性,这是一个老生常谈的话题了。 但很多人对这个问题,依旧有很多疑惑: 到底是更新缓存还是删缓存?到底选择先更新数据库,再删除缓存,还是先删除缓存,再更新数据库&…...
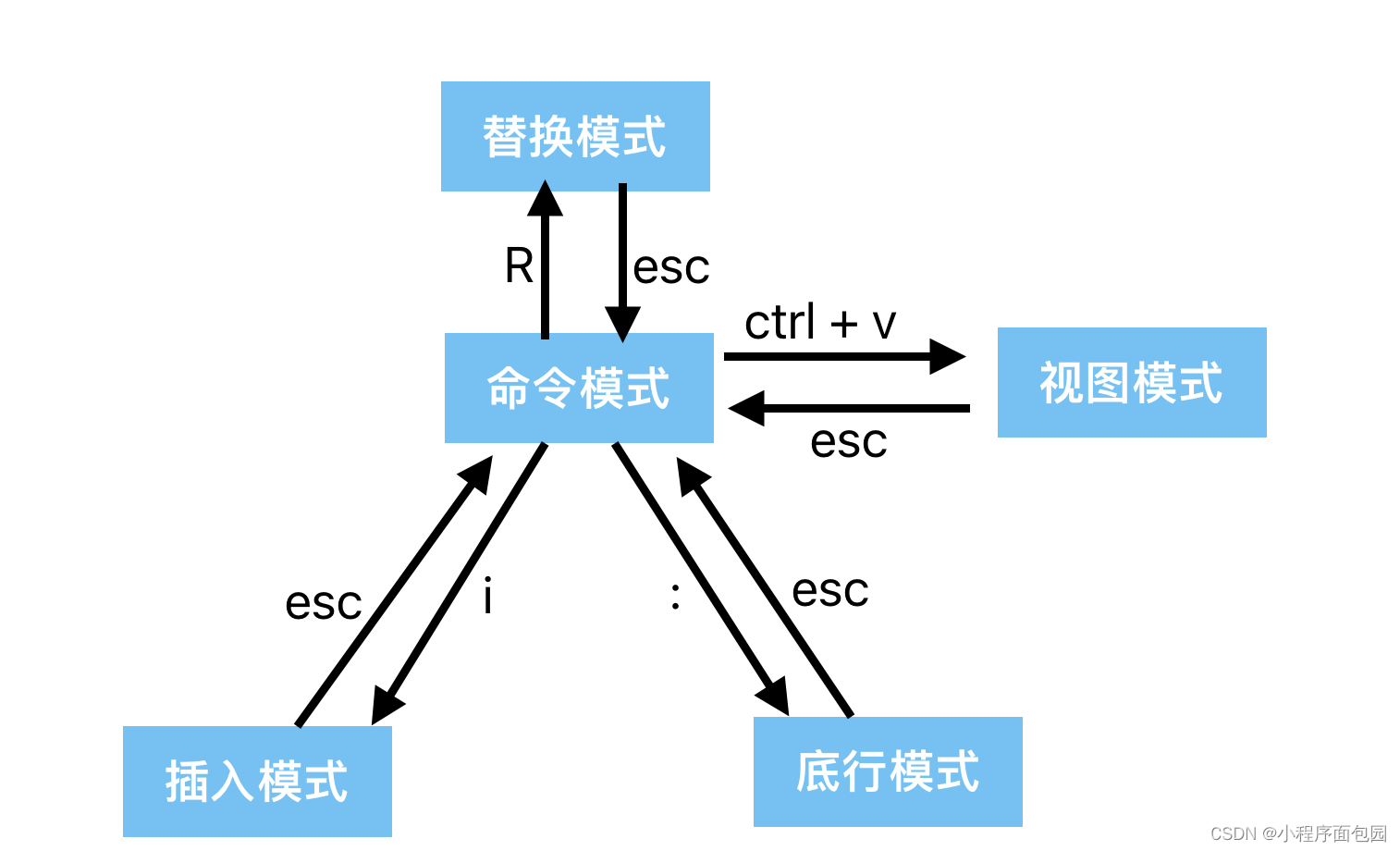
vim模式用法总结
0.前言 我们用gcc编译文件的时候,如果发生了下面的错误,那么如何用vim打开的时候就定位到? 我们可以知道,这是第6行出现了错误; 所以我们使用vim打开的时候多输入个这个,我们就可以快速定位了 vim test.c 6…...
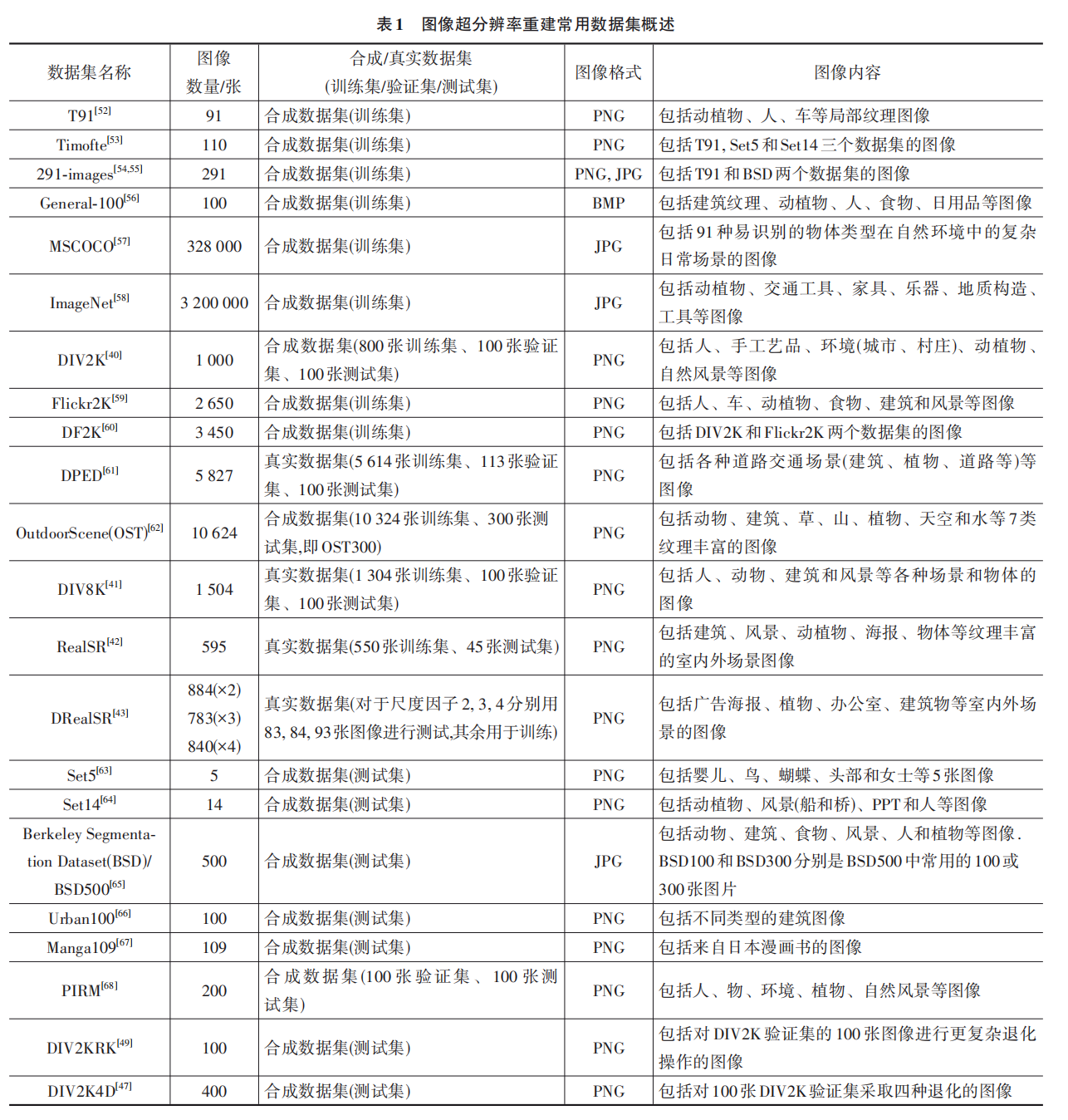
基于深度学习的单帧图像超分辨率重建综述
论文标题:基于深度学习的单帧图像超分辨率重建综述作者: 吴 靖,叶晓晶,黄 峰,陈丽琼,王志锋,刘文犀发表日期:2022 年9 月阅读日期 :2023.11.18研究背景: 图像…...

开源与闭源:创新与安全的平衡
目录 一、开源和闭源的优劣势比较 一、开源软件的优劣势 优势 劣势 二、闭源软件的优劣势 优势 劣势 二、开源和闭源对大模型技术发展的影响 一、机器学习领域 二、自然语言处理领域 三、数据共享、算法创新与业务拓展的差异 三、开源与闭源的商业模式比较 一、盈…...

C# 22H2之后的windows版本使用SetDynamicTimeZoneInformation设置时区失败处理
使用SetDynamicTimeZoneInformation设置时区返回false,设置失败。 使用PowerShell设置Set-TimeZone成功。 /// <summary> /// 设置本地时区 /// 参数取值"China Standard Time",即可设置为中国时区 /// </summary> /// <param …...
分布式与微服务 —— 初始
前言 距今微服务的提出已经过去快十个春秋,网络上的博文讲微服务也是一抓一大把,但是荔枝仍然觉得还是有必要自己梳理一下整个知识体系。在这篇文章中,荔枝将会以一个初学者的角度来切入,从分布式系统和微服务架构引入,…...
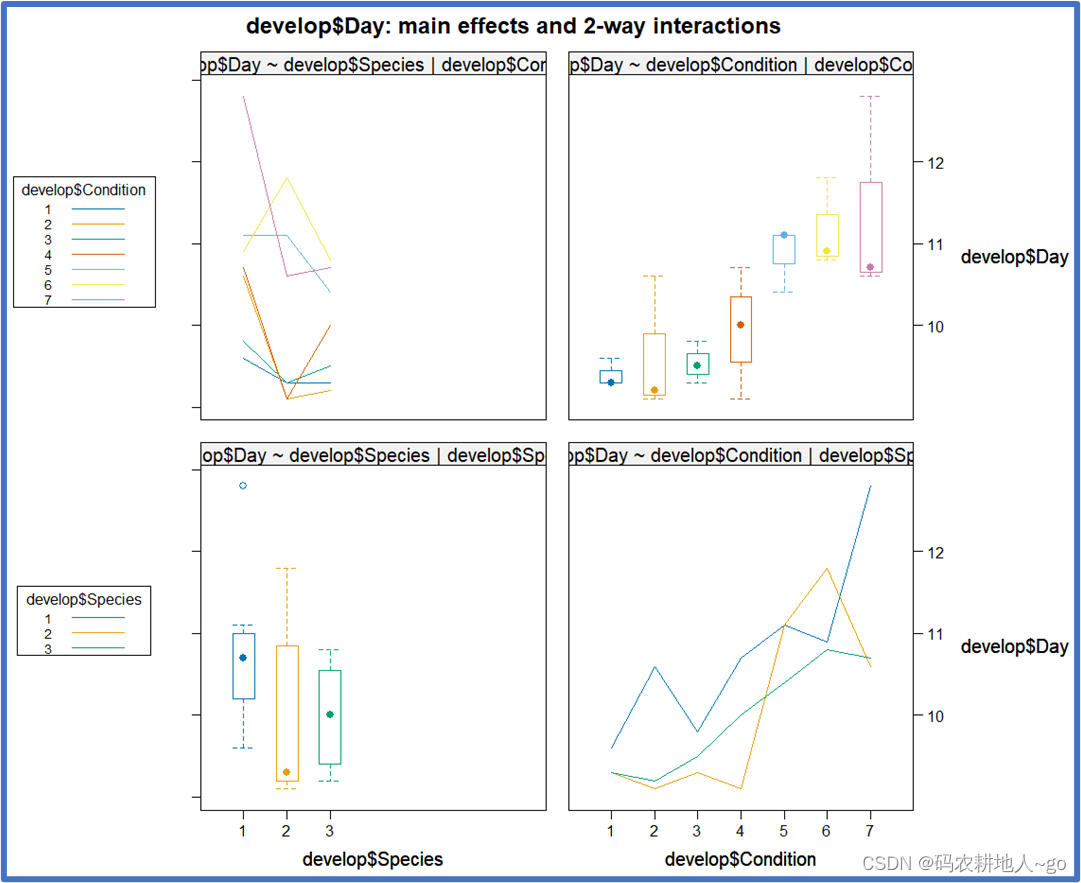
多因素方差分析(Multi-way Analysis of Variance) R实现
1, data0507 flower 是某种植物在两个海拔和两个气温下的开花高度,采用合适 的统计方法,检验该种植物的开花高度在不同的海拔之间和不同的气温之间有无差异?如果有差异,具体如何差异的?(说明依据、结论等关…...
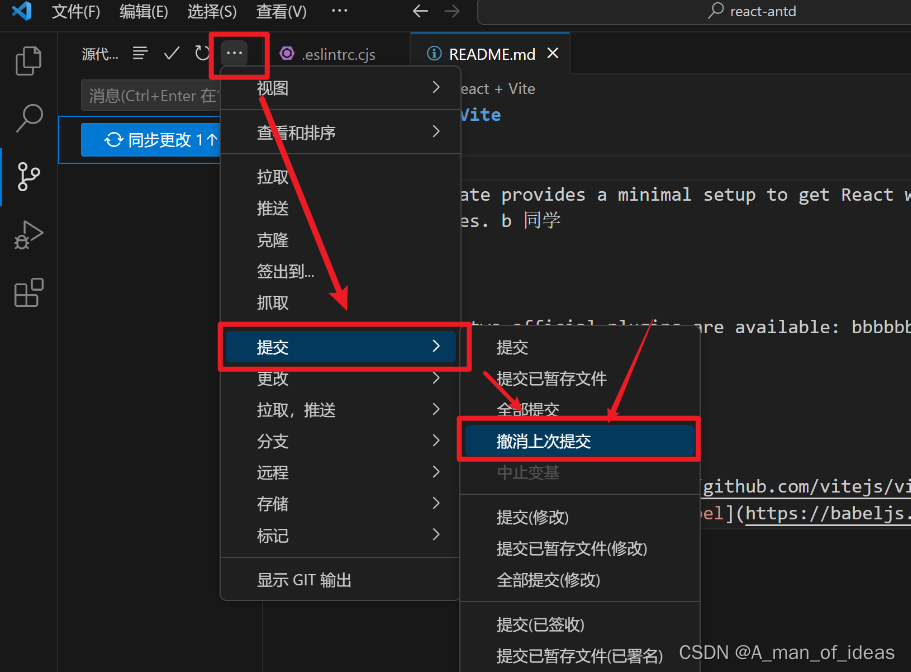
git撤销某一次commit提交
一:撤销上一次commit提交,但不删除修改的代码 可以使用使用VSCode 二:使用 git reset --hard命令删除提交时,将会删除该提交及其之后的所有更改(相当于你想要回滚到的提交的提交ID) git reset --hard 版本…...
数据结构详细笔记——图
文章目录 图的定义图的存储邻接矩阵法邻接表法邻接矩阵法与邻接表法的区别 图的基本操作图的遍历广度优先遍历(BFS)深度优先遍历(DFS)图的遍历和图的连通性 图的定义 图G由顶点集V和边集E组成,记为G(V,E),…...
黑马React18: 基础Part II
黑马React: 基础2 Date: November 16, 2023 Sum: 受控表单绑定、获取DOM、组件通信、useEffect、Hook、优化B站评论 受控表单绑定 受控表单绑定 概念:使用React组件的状态(useState)控制表单的状态 准备一个React状态值 const [value, se…...
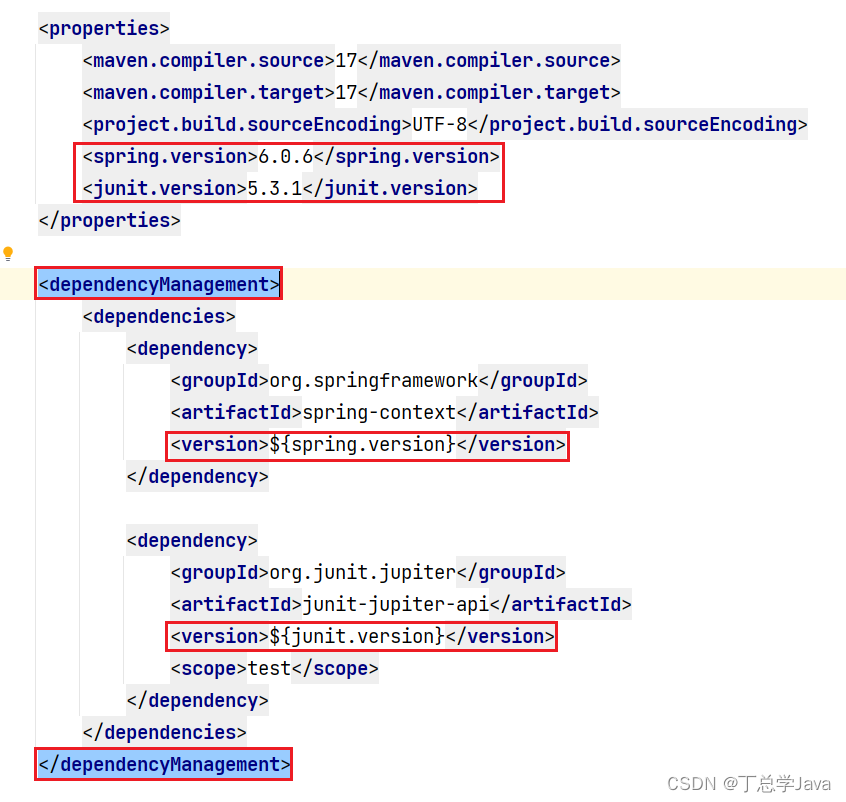
Maven工程继承关系,多个模块要使用同一个框架,它们应该是同一个版本,项目中使用的框架版本需要统一管理。
1、父工程pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/PO…...
Selenium UI 自动化
一、Selenium 自动化 1、什么是Selenium? Selenium是web应用中基于UI的自动化测试框架。 2、Selenium的特点? 支持多平台、多浏览器、多语言。 3、自动化工作原理? 通过上图,我们可以注意到3个角色,下面具体讲解一…...

竞赛 题目:基于深度学习的图像风格迁移 - [ 卷积神经网络 机器视觉 ]
文章目录 0 简介1 VGG网络2 风格迁移3 内容损失4 风格损失5 主代码实现6 迁移模型实现7 效果展示8 最后 0 简介 🔥 优质竞赛项目系列,今天要分享的是 基于深度学习卷积神经网络的花卉识别 该项目较为新颖,适合作为竞赛课题方向,…...
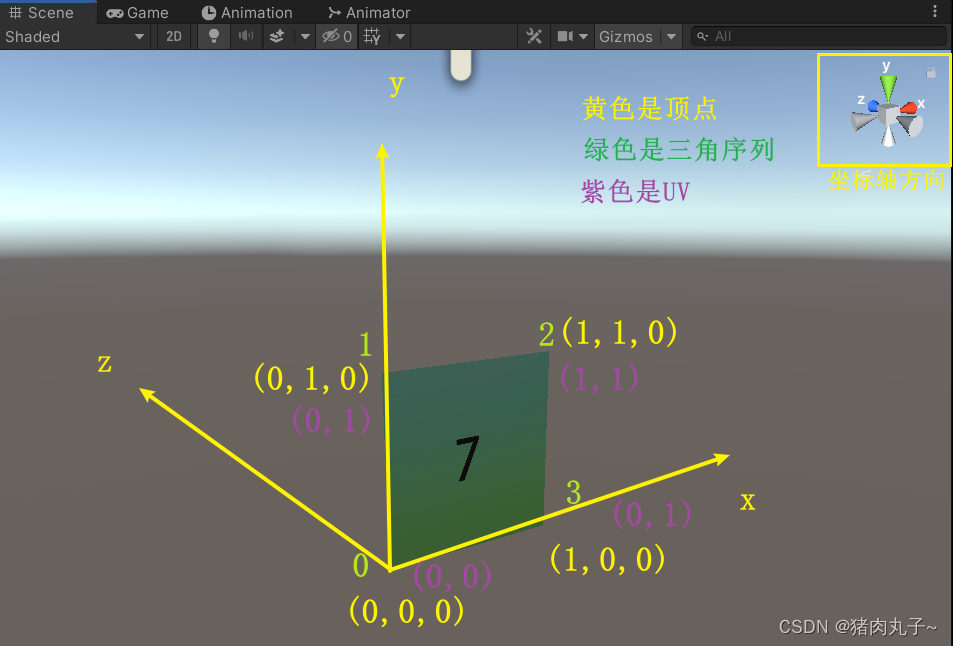
【unity3D-网格编程】01:Mesh基础属性以及用代码创建一个三角形
💗 未来的游戏开发程序媛,现在的努力学习菜鸡 💦本专栏是我关于游戏开发的网格编程方面学习笔记 🈶本篇是unity的网格编程系列01-mesh基础属性 网格编程系列01 mesh基础属性实践操作用代码初始化一个三角形在三角形的基础上改成正…...
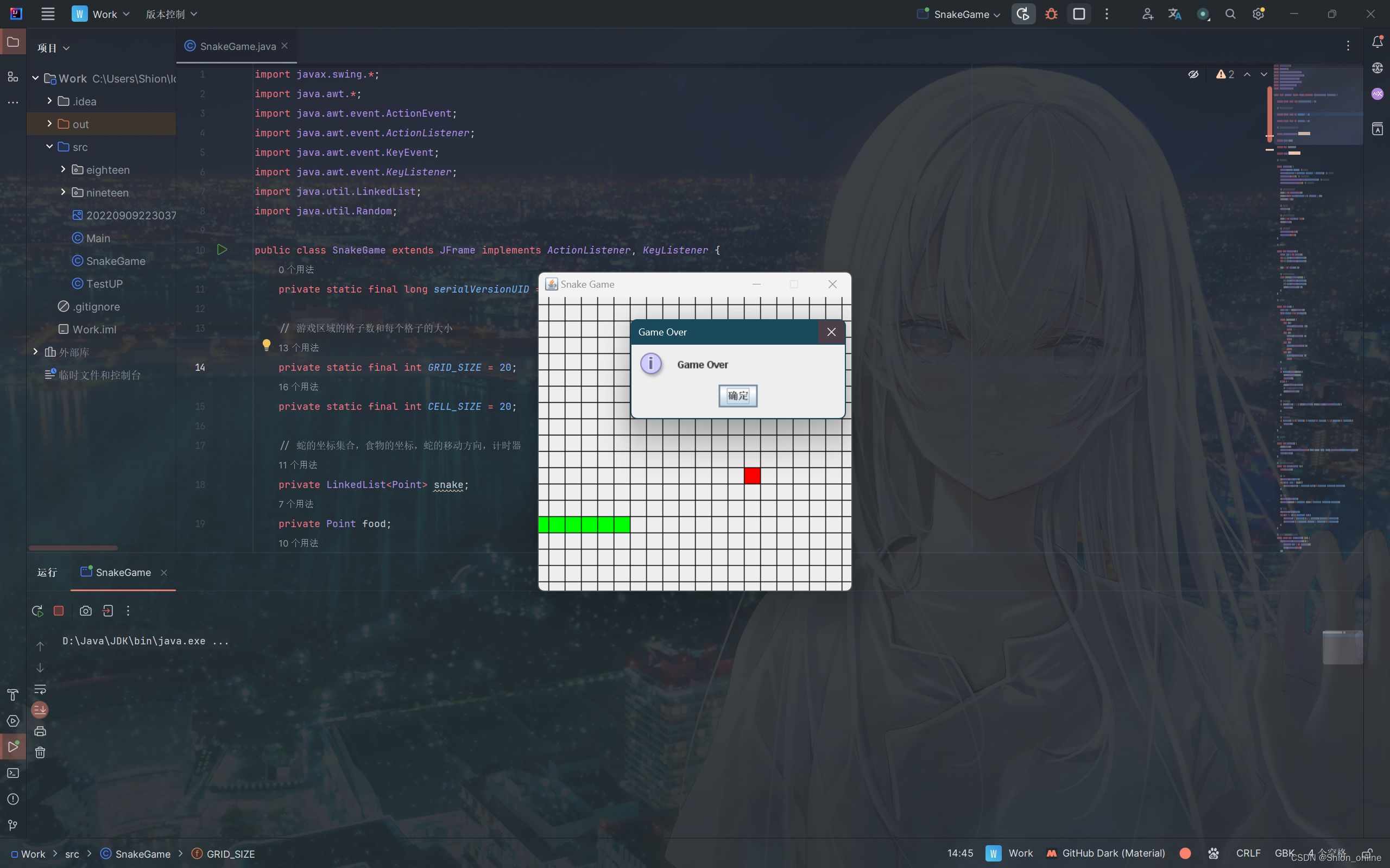
Java贪吃蛇小游戏
Java贪吃蛇小游戏 import javax.swing.*; import java.awt.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import java.awt.event.KeyEvent; import java.awt.event.KeyListener; import java.util.LinkedList; import java.util.Random;publi…...
)
Linux:系统基本信息扫描(1)
#系统基本信息: uname -a #Linux发行版信息: lsb_release -a #内核与发行版信息: cat /proc/version #linux 用户 cat /etc/passwd #Linux 组查询 cat /etc/group #CPU详细信息:lscpu -a #获取CPU模式: cat /sys/devices/system/cpu/cpu0/cpufreq/scaling\_governor #per…...

VR全景打造亮眼吸睛创意内容:三维模型、实景建模
随着VR技术在不同行业之间应用落地,市场规模也在快速扩大,VR全景这种全新的视觉体验为我们生活中的许多方面都带来了无限的可能。更加完整的呈现出一个场景或是物体的所有细节,让浏览者感受到自己仿佛置身于现场一般;其次…...
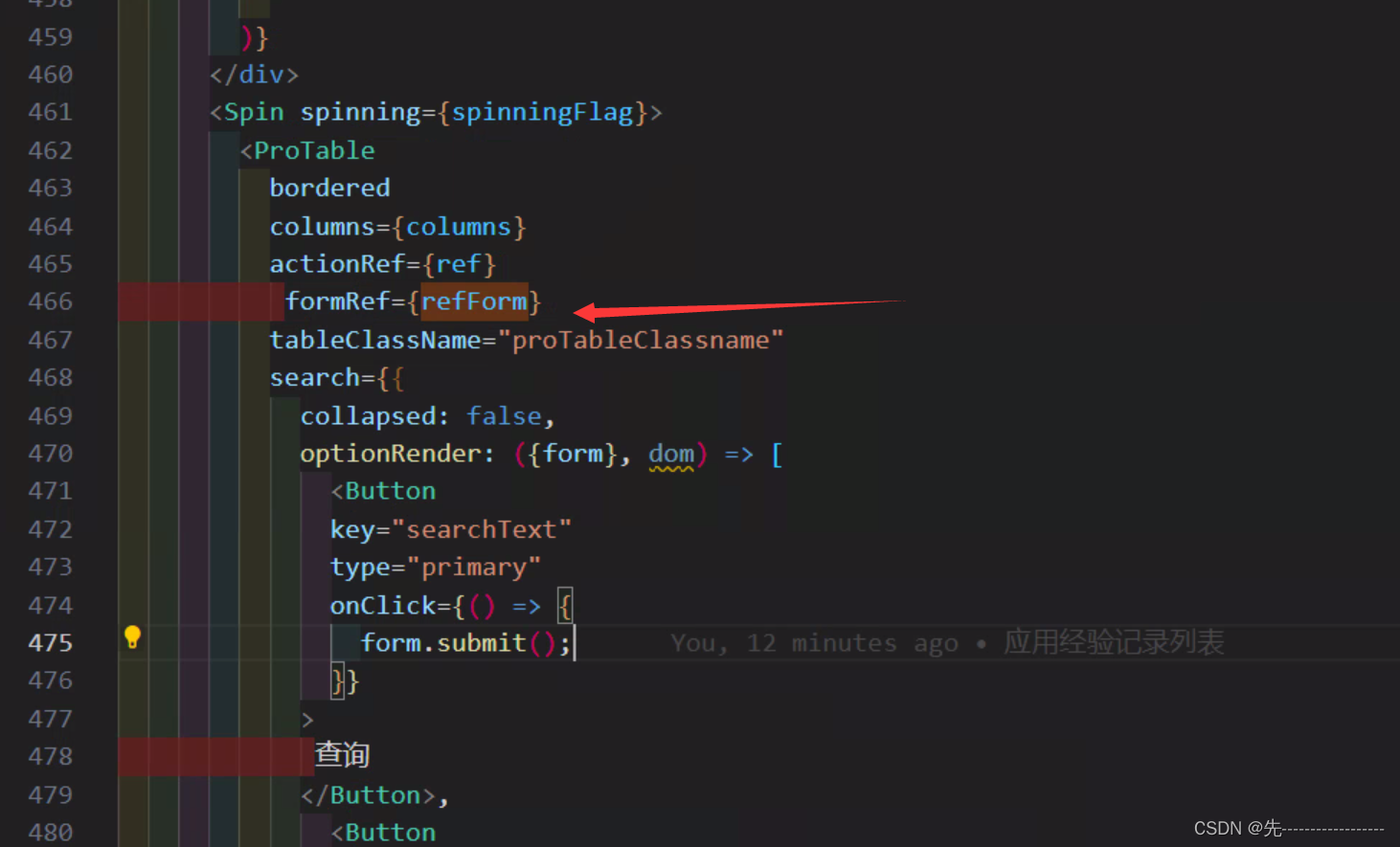
ProTable高级表格获取表单数据
隐藏高级表格中的收起按钮 手动控制高级表格中的搜索按钮 获取高级表格中的表单数据 Forminstance 引入 然后在代码中定义 const refForm useRef(); 使用 refForm.current.getFileDsValue();...

力扣刷题第二十七天--二叉树
前言 题目大同小异,按要求来即可。 内容 一、二叉树的右视图 199.二叉树的右视图 给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。 广度优先搜索 取每层最后一个…...

一个快递包裹的跨国之旅
事情要从今年三月份说起,一位爱尔兰的同事在6月份结婚,团队同事准备了中国风的丝绸画轴、领带、丝巾作为礼物。3月份开始邮寄,4月初爱尔兰方面收件,5月份因为文件不足、不完整、不正确等原因被取消进口,7月份退回到大连…...

深入解析Baichuan-7B:从GPT架构到LoRA微调的实践指南
1. 项目概述:从开源大模型到“百川”入海 最近在和朋友聊起国内大模型的开源生态时,总绕不开一个名字——“百川”。我说的不是地理上的河流,而是由百川智能公司开源的Baichuan系列大语言模型。今天想重点聊聊的,是它的起点&#…...

ARM错误恢复中断机制与ERRERICR2寄存器详解
1. ARM错误恢复中断机制概述在ARM架构的可靠性、可用性和可维护性(RAS)系统中,错误恢复中断是实现硬件容错的关键机制。当处理器检测到可恢复的错误条件时,通过这套机制能够快速通知系统进行错误处理,而ERRERICR2寄存器…...

翁凯C语言MOOC编程题保姆级解析:从Hello World到GPS数据处理,新手避坑指南
翁凯C语言MOOC编程题深度解析:从入门到精通的实战指南 当你第一次打开翁凯老师的《程序设计入门——C语言》课程时,可能会被那些看似简单的编程题难住。Hello World之后,真正的挑战才刚刚开始。本指南将带你深入理解每道编程题背后的设计意图…...

GPU渲染管线ROP单元优化与体积渲染性能提升
1. GPU渲染管线中的ROP单元深度解析在图形渲染管线中,Render Output Unit(ROP)扮演着至关重要的角色。作为渲染流程的最后阶段,ROP负责执行深度测试(Z-Test)、模板测试(Stencil Test)…...
)
基于BS模式的小型房屋租赁系统(10016)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

AKShare架构深度解析:如何构建企业级金融数据接口平台
AKShare架构深度解析:如何构建企业级金融数据接口平台 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcode.com/gh_mirrors/aks/ak…...

电子围栏系统设计:基于基站定位的防疫隔离技术方案解析
1. 项目概述:电子围栏系统的核心逻辑与设计初衷在2020年初那场席卷全球的公共卫生事件中,如何有效管理居家隔离人员,防止疫情在社区内扩散,成了各国政府面临的共同难题。当时,我作为技术顾问,深度参与了一些…...

从Solyndra事件看美国太阳能产业转型与能源创新体系构建
1. 从Solyndra事件看美国太阳能产业的十字路口2011年秋天,加州弗里蒙特市,一家名为Solyndra的太阳能公司大门前,联邦官员正将一箱箱文件搬上卡车,而当地几乎所有的电视台摄像机都记录下了这一幕。这家曾获得美国能源部5.35亿美元贷…...

从温度计误差到数字设计:测量不确定性与工程信任链构建
1. 从“温控失灵”到“测量哲学”:一个硬件工程师的日常反思前几天,我家那个服役多年的老式温控器彻底“罢工”了——液晶屏花得连温度数字都看不清。我找来熟悉的暖通师傅奥兰,换上了一台崭新的数字温控器。本以为问题就此解决,但…...

手机号快速查询QQ号:3步找回遗忘账号的实用指南
手机号快速查询QQ号:3步找回遗忘账号的实用指南 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 你是否曾经因为忘记QQ号而无法登录?手机号查询QQ号工具正是为你量身打造的解决方案!这款基于Python…...