python正则表达式处理文本-re模块
python正则表达式处理文本-re模块
1.概述
正则表达式通常用于含有大量文本处理的应用当中。例如,它们经常用作开发者使用的文本编辑程序的搜索模式,包括 vi,emacs 和现代集成开发环境。它们也是 Unix 命令行工具的组成部分,例如 sed、grep 和 awk。很多编程语言是在语法中支持正则表达式(Perl、Ruby、Awk 和 Tcl),但 C、C++ 和 Python 等其他语言,通过扩展库来支持正则表达式。
正则表达式存在多个开源实现,每个实现都共享一个通用的核心语法,但对高级特性有不同的扩展和修改。Python 的 re 库使用的语法基于 Perl 的正则表达式语法,并且有一些特定于 Python 的增强。
尽管「正则表达式」的正式定义仅限于描述正则语言的表达式,但 re 支持的一些扩展已经超出了正则语言的范畴。在这里,「正则表达式」术语有点更通用的感觉,意味着是任何可以被 Python 的 re 模块所描述的表达式。
2.re模块介绍
python中re模块赋予了正则更强的表达能力:
尽管「正则表达式」的正式定义仅限于描述正则语言的表达式,但 re 模块支持的一些扩展已经超出了正则语言的范畴。
在这里,「正则表达式」术语有点更通用的感觉,意味着是任何可以被 Python 的 re 模块所描述的表达式。
re模块结构介绍
re模块由9个常量、12个函数、1个异常构成,下面通过示例详细介绍他们使用方法,应用到开发中解决实际的问题。
re模块常用函数介绍
re模块提供了许多的函数对文本做不同的处理,下面是函数处理文本的职责。
- match函数
使用一个模式匹配文本,如果匹配成功就返回匹配到的内容,否则返回None - compile 函数
用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用 - search函数
扫描整个字符串并返回第一个成功的匹配,如果没有匹配,就返回一个 None。 - findall函数
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。注意: match 和 search 是匹配一次 findall 匹配所有。 - finditer函数
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。 - sub函数
sub是substitute的所写,表示替换,将匹配到的数据进⾏替换。 - subn函数
行为与sub()相同,但是返回一个元组 (字符串, 替换次数)。 - split函数
根据匹配进⾏切割字符串,并返回⼀个列表。
3.re模块常量介绍
3.1.常量介绍
re模块常量是定义在一个继承Int类型的枚举类中,有9个常量,常量的值都是int类型。
class RegexFlag(enum.IntFlag):ASCII = A = sre_compile.SRE_FLAG_ASCII # assume ascii "locale"IGNORECASE = I = sre_compile.SRE_FLAG_IGNORECASE # ignore caseLOCALE = L = sre_compile.SRE_FLAG_LOCALE # assume current 8-bit localeUNICODE = U = sre_compile.SRE_FLAG_UNICODE # assume unicode "locale"MULTILINE = M = sre_compile.SRE_FLAG_MULTILINE # make anchors look for newlineDOTALL = S = sre_compile.SRE_FLAG_DOTALL # make dot match newlineVERBOSE = X = sre_compile.SRE_FLAG_VERBOSE # ignore whitespace and comments# sre extensions (experimental, don't rely on these)TEMPLATE = T = sre_compile.SRE_FLAG_TEMPLATE # disable backtrackingDEBUG = sre_compile.SRE_FLAG_DEBUG # dump pattern after compilation
1.IGNORECASE
语法: re.IGNORECASE 或简写为 re.I
作用: 进行忽略大小写匹配
下面的例子查询match时会将大写和小写都查询出来
import repattern = 'match'
text = 'Does this text match the pattern, Match text'print('默认区分大小写:', re.findall(pattern, text), end='\n')print('IGNORECASE属性忽略大小写', re.findall(pattern, text, re.IGNORECASE))
查找文本时使用re.IGNORECASE常量忽略了match的大小写,大写和小写的match都会查询到。
默认区分大小写: ['match']
IGNORECASE忽略大小写 ['match', 'Match']
2.ASCII码
语法: re.ASCII 或简写为 re.A
作用: 顾名思义,ASCII表示ASCII码的意思,让 \w, \W, \b, \B, \d, \D, \s 和 \S 只匹配ASCII,而不是Unicode。
import re
pattern = r'\w+'
text = 'a白日依山尽b,黄河入海流c'print('Unicode模式查找结果:', re.findall(pattern, text))print('ASCII模式查找结果:', re.findall(pattern, text, re.ASCII))
在默认匹配模式下\w+匹配到了所有字符串,而在ASCII模式下,只匹配到了a、b、c(ASCII编码支持的字符)。
Unicode模式查找结果: ['a白日依山尽b', '黄河入海流c']
ASCII模式查找结果: ['a', 'b', 'c']
3.DOTALL
语法: re.DOTALL 或简写为 re.S
作用: DOT表示.,ALL表示所有,连起来就是.匹配所有,包括换行符\n。默认模式下.是不能匹配行符\n的。
import re
pattern = r'.*'
text = '白日依山尽,\n黄河入海流'
print('默认匹配:', re.findall(pattern, text))print('.匹配所有:', re.findall(pattern, text, re.DOTALL))
在默认匹配模式下.并没有匹配换行符\n,而是将字符串分开匹配;而在re.DOTALL模式下,换行符\n与字符串一起被匹配到。
默认匹配: ['白日依山尽,', '', '黄河入海流', '']
.匹配所有: ['白日依山尽,\n黄河入海流', '']
4. MULTILINE
语法: re.MULTILINE 或简写为 re.M
作用: 多行模式,当某字符串中有换行符\n,默认模式下是不支持匹配下一行行头匹配。而多行模式下是支持匹配行开头的。
正则表达式中^表示匹配行的开头,默认模式下它只能匹配字符串的开头;而在多行模式下,它还可以匹配 换行符\n后面的字符。
注意:正则语法中^匹配行开头、\A匹配字符串开头,单行模式下它两效果一致,多行模式下\A不能识别\n。
import re
pattern = r'^黄'
text = '白日依山尽,\n黄河入海流'
print('默认匹配:', re.findall(pattern, text))
print('多行匹配行头', re.findall(pattern, text, re.MULTILINE))
多行模式匹配到了第二行开头黄 字符
默认匹配: []
多行匹配行头 ['黄']
5. VERBOSE
语法: re.VERBOSE 或简写为 re.X
作用: 详细模式,可以在正则表达式中加注解!
import re
pattern = r'''
白日 # 白天的太阳
'''
text = '白日依山尽,\n黄河入海流'
print('默认匹配:', re.findall(pattern, text))
print('详细模式匹配注释', re.findall(pattern, text, re.VERBOSE))
默认模式下并不能识别正则表达式中的注释,而详细模式是可以识别的。
默认匹配: []
详细模式匹配注释 ['白日']
6.LOCALE
语法: re.LOCALE 或简写为 re.L
作用: 由当前语言区域决定 \w, \W, \b, \B 和大小写敏感匹配,这个标记只能对byte样式有效。这个标记官方已经不推荐使用,因为语言区域机制很不可靠,它一次只能处理一个 "习惯”,而且只对8位字节有效。
7.UNICODE
语法: re.UNICODE 或简写为 re.U
作用: 与 ASCII 模式类似,匹配unicode编码支持的字符,但是 Python 3 默认字符串已经是Unicode,所以有点冗余。
8. DEBUG
语法: re.DEBUG
作用: 显示编译时的debug信息。
import re
pattern = r'白日'
text = '白日依山尽,\n黄河入海流'
print('默认匹配:', re.findall(pattern, text))
print('debug模式', re.findall(pattern, text, re.DEBUG))
运行结果
默认匹配: ['白日']
LITERAL 30333
LITERAL 260850. INFO 10 0b11 2 2 (to 11)prefix_skip 2prefix [0x767d, 0x65e5] ('白日')overlap [0, 0]
11: LITERAL 0x767d ('白')
13. LITERAL 0x65e5 ('日')
15. SUCCESS
debug模式 ['白日']9.TEMPLATE
语法: re.TEMPLATE 或简写为 re.T
作用:disable backtracking(禁用回溯)
3.2.常量组合使用
常量可叠加使用,因为常量值都是2的幂次方值,所以是可以叠加使用的,叠加时请使用 | 符号,请勿使用+ 符号!
import repattern = '^match'
text = 'Does this text match the pattern, \nMatch text'print('默认区分大小写:', re.findall(pattern, text), end='\n')print('多个模式组合使用', re.findall(pattern, text, re.IGNORECASE | re.MULTILINE))
上面使用了忽略大小写和多行模式组合查询出Match开头的字符。
默认区分大小写: []
IGNORECASE属性忽略大小写 ['Match']
4.re模块函数
re模块有12个函数可以查找匹配文本,根据他们的功能分类如下:
4.1.查找一个匹配项
查找并返回一个匹配项的函数有3个:search、match、fullmatch,他们的区别分别是
- search: 查找任意位置的匹配项
- match: 必须从字符串开头匹配
- fullmatch: 整个字符串与正则完全匹配
1.查找一个匹配项示例
这个例子分别使用search、match、fullmatch 三个函数测试查询一个匹配项的区别。
import re
pattern = '白日'
text = 'A白日依山尽,白日依山尽'print('search:', re.search(pattern, text).group())print('match', re.match(pattern, text))print('fullmatch:', re.fullmatch(pattern, text))
search函数在字符串任意位置匹配,符合表达式模式就会返回结果。
match函数需要从头匹配,在文本中开头有个A字符,因此他没有匹配到结果。
fullmatch函数匹配的内容需要与文本完全相同,因此返回的结果也是空。
search: 白日
match None
fullmatch: None
2.查询结果处理函数
使用search、match、fullmatch 三个函数查询字符串返回值是一个Match(Generic[AnyStr])类型对象,在该对象中提供了一些方法用来处理返回值。
下面介绍下处理匹配结果常用方法
- start:获取匹配结果开始索引地址
- end:获取匹配结果结束索引地址
- group:分组截取字符串
import re
pattern = '白日'
text = '白日依山尽,白日依山尽'search_result = re.search(pattern, text)
print(search_result)
# search 获取查询开始和结尾索引
s = search_result.start()
e = search_result.end()# search_result.re.pattern 获取匹配模式, search_result.string获取匹配的文本
print('Found "{}"\nin "{}"\nfrom {} to {} ("{}")'.format(search_result.re.pattern, search_result.string, s, e, text[s:e]))print('gourp 分组显示查询结果', search_result.group())
print('span 返回查询结果起止下标:', search_result.span())
运行结果
<re.Match object; span=(0, 2), match='白日'>
Found "白日"
in "白日依山尽,白日依山尽"
from 0 to 2 ("白日")
gourp 分组显示查询结果 白日
span 返回查询结果起止下标: (0, 2)4.2.查找多个匹配项
查找多项函数主要有:findall函数 与 finditer函数
两个方法基本类似,只不过一个是返回列表,一个是返回迭代器。我们知道列表是一次性生成在内存中,而迭代器是需要使用时一点一点生成出来的,节省内存。
- findall: 从字符串任意位置查找,返回一个列表
- finditer:从字符串任意位置查找,返回一个迭代器
import re
pattern = '白日'
text = '白日依山尽,白日依山尽'search_sult = re.search(pattern, text)
print('查找一个匹配项:', search_sult.group())findall_sult = re.findall(pattern, text)
print('查找多个匹配项:', findall_sult)
查找同一个文本,使用search查找结果只有一个。使用findall查找所有符合条件的值。
查找一个匹配项: 白日
查找多个匹配项: ['白日', '白日']
4.3.分割文本
re.split(pattern, string, maxsplit=0, flags=0) 函数作用就是根据分割模式对文本进行分隔,他不是查找字符。
- pattern相当于str.split()中的sep,分隔符的意思,不但可以是字符串,也可以为正则表达式
- maxsplit表示最多进行分割次数,
- flags表示模式,就是上面我们讲解的常量
1.不限制分割次数
import re
pattern = '[a-b]'
text = '1,2,3,4,a,5,6,7,8,b,9,10,11,12'split_sult = re.split(pattern, text, maxsplit=0, flags=re.IGNORECASE)
print('split分割', split_sult)
# 列表索引切片操作获取数据
print(split_sult[0])
print(split_sult[:2])
上面使用[a-b] 模式分割文本,maxsplit设置为0表示为不显示分割次数,split函数将在文本中遇到a或b字符就会将文本分割一次,返回的结果是一个列表,可以通过索引获取每个值。
split分割 ['1,2,3,4,', ',5,6,7,8,', ',9,10,11,12']
1,2,3,4,
['1,2,3,4,', ',5,6,7,8,']
2.限制分割次数
import re
pattern = '[a-b]'
text = '1,2,3,4,a,5,6,7,8,b,9,10,11,12'split_sult = re.split(pattern, text, maxsplit=1, flags=re.IGNORECASE)
print('split分割', split_sult)
设置split分割一次,下面分割后列表中有两个元素。
split分割 ['1,2,3,4,', ',5,6,7,8,b,9,10,11,12']
4.4.替换
替换主要有sub函数 与 subn函数
re.sub(pattern, repl, string, count=0, flags=0) 函数:
- repl替换掉string中被pattern匹配的字符
- count表示最大替换次数
- flags表示正则表达式的常量
re.subn(pattern, repl, string, count=0, flags=0) 函数与 re.sub函数 功能一致,只不过返回一个元组 (字符串, 替换次数)
1.sub替换文本
sub函数中的入参:repl替换内容既可以是字符串,也可以是一个函数哦! 如果repl为函数时,只能有一个入参:Match匹配对象。
import re
pattern = '在'
repl = '尽'
text = '白日依山在,黄河入海流'
sub_sult = re.sub(pattern, repl, text)
print('sub替换文本:',sub_sult)
4.5.编译正则模板
re模块执行过程
re模块匹配文本时需要执行两个步骤,编译正则表达式,然后用表达式匹配文本。
为什么要预编译表达式
如果每次匹配文本都要编译一次正则表达式效率会降低,因此我们可以可通过compile函数预编译表达式,每次匹配文本时就省去了编译步骤。
编译表达式对象函数
compile函数 与 template函数 将正则表达式的样式编译为一个 正则表达式对象 ,这个对象与re模块有同样的正则函数。
注意
不论你是否使用预编译表达式,python在re模块的源码中默认使用compile预编译模式执行匹配文本。
查看 findall(), search(), match()的源码
def search(pattern, string, flags=0):"""Scan through string looking for a match to the pattern, returninga Match object, or None if no match was found."""# 调用 _compile函数,编译表达式,然后在调用search查询文本return _compile(pattern, flags).search(string)1.compile函数编译表达式
import re
pattern = '白日'
# 预编译表达式
pattern_obj = re.compile(pattern)
text = '白日依山尽,白日依山尽'compile_sult = pattern_obj.search(text).group()
print('编译正则模板:',compile_sult)
运行结果
编译正则模板: 白日
2.template函数
template函数 与 compile函数 类似,只不过是增加了我们之前说的re.TEMPLATE 模式,我们可以看看源码。
def template(pattern, flags=0):"Compile a template pattern, returning a Pattern object"return _compile(pattern, flags|T)
4.6.转义特殊字符
re.escape(pattern) 可以转义正则表达式中具有特殊含义的字符,比如:. 或者 *
import re
pattern = '白日*'
text = '白日*依山尽,黄河.入海流'
search_sult = re.search(pattern, text)
print('search查询结果:', search_sult.group())# 输出转义字符
escape_sult = re.escape(pattern)
print('escape转义字符输出结果:', escape_sult)
使用普通的search函数输出时没有将*特殊字符输出,escape函数将*特殊字符转义后输出,但是它的输出显示转义有问题在*前面加上了\ 因此不建议使用它转义,还是手动转义好。
search查询结果: 白日
escape转义字符输出结果: 白日\*
下面是在表达式中手动对特殊字符转义。
import re
# 手动转义
pattern = '白日\*'
text = '白日*依山尽,黄河.入海流'
search_sult = re.search(pattern, text)
print('search查询结果:', search_sult.group())
运行结果符合我们查找的结果
search查询结果: 白日*
4.7.清除正则表达式缓存
re.purge() 函数作用就是清除 正则表达式缓存,具体有什么缓存呢?我们先看看源码
def purge():"Clear the regular expression caches"_cache.clear()_compile_repl.cache_clear()
5.正则语法
使用好re模块解决工作中遇到的问题,除了掌握re模块提供的函数,还要掌握正则本身的语法。
正则语法是标准的语法在网上也是非常容易找到,这里提供了菜鸟教程的正则语法,方便在工作中查阅正则语法。
菜鸟正则语法:https://www.runoob.com/regexp/regexp-syntax.html
相关文章:

python正则表达式处理文本-re模块
python正则表达式处理文本-re模块 1.概述 正则表达式通常用于含有大量文本处理的应用当中。例如,它们经常用作开发者使用的文本编辑程序的搜索模式,包括 vi,emacs 和现代集成开发环境。它们也是 Unix 命令行工具的组成部分,例如…...
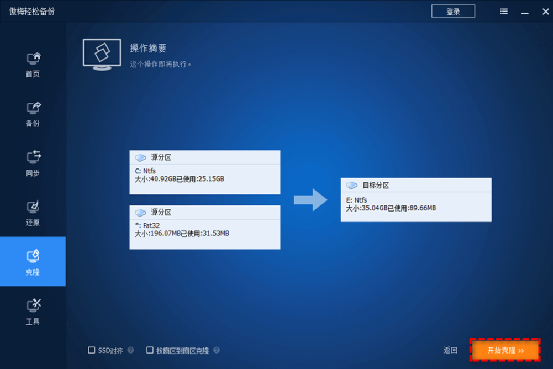
换了固态硬盘需要重装系统吗?教你如何实现不重装系统!
电脑大家都用过嘛,如果您的计算机装的还是机械硬盘,想必阁下肯定是修身养性的高手,因为在这个浮躁的社会中,是很少有人能够忍受5分钟甚至更久的开机时间的,不仅开机慢,应用程序的响应速度也很慢,…...

网上医疗预约挂号系统
技术:Java、JSP等摘要:网上医疗预约挂号系统是主要是对居民的保健、护理、疾病预防等健康信息实行有效的预约挂号管理。医疗机构为居民建立完整的健康档案,安排体检以及实施免疫等预防措施。而基于Web的远程保健平台以网上医疗预约挂号系统为…...
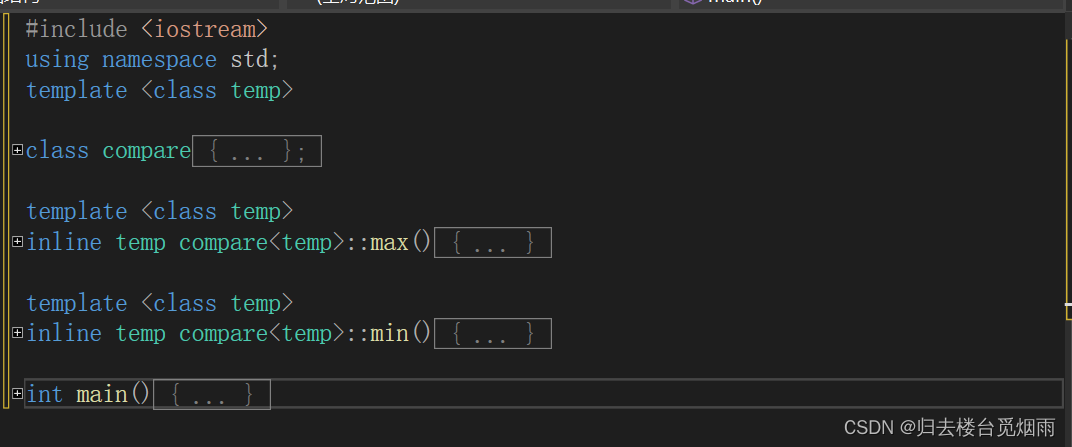
专题:一看就会的C++类模板讲解 (1)
目录 一.类模板的作用 二.类模板的定义: 三.类模板的声明格式: 四.类模板对象 五.再举一个例子 一.类模板的作用 面向对象的程序设计编程实践中,我们可能会面临这样的问题:要实现比较两个数的大小。明明比较两个数的方法都一样…...

什么是“奥卡姆剃刀”,如何用“奥卡姆剃刀”解决复杂问题?复杂问题简单化
什么是“奥卡姆剃刀”,如何用“奥卡姆剃刀”解决复杂问题?复杂问题简单化问题什么是“奥卡姆剃刀”?如何使用“奥卡姆剃刀”解决问题复杂问题简单化“汉隆剃刀”小结问题 假设你在夜空中看到一颗闪闪发光的「不明飞行物」,你认为这会是什么呢…...
)
角谷定理(递归)
已知有角谷定理: 输入一个自然数,若为偶数,则把它除以2,若为奇数,则把它乘以3加1。经过如此有限次运算后,总可以得到自然数值1。求经过多少次可得到自然数1。如:例如数据22的变化过程ÿ…...
)
数学小课堂:微积分复盘(高等数学本质上是对趋势的动态描述,是对各种相关性抽象的表述。)
文章目录 引言I 复盘1.1 概念和表述1.2 现实与虚构1.3 有穷和无穷1.4 静态和动态1.5 直觉和逻辑II 通过数学逻辑,理解人生。2.1 精明与聪明2.2 朋友和理性的对手2.3 攒钱和赚钱2.4 荣誉和财富引言 高等数学本质上是对趋势的动态描述,是对各种相关性抽象的表述。 I 复盘 1.…...
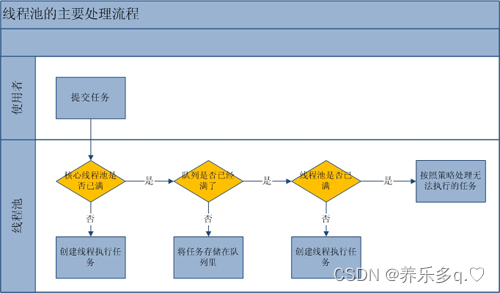
JAVA线程池原理详解一
JAVA线程池原理详解一 一. 线程池的优点 线程是稀缺资源,使用线程池可以减少创建和销毁线程的次数,每个工作线程都可以重复使用。可以根据系统的承受能力,调整线程池中工作线程的数量,防止因为消耗过多内存导致服务器崩溃。 二…...

Windows平台Unity Camera场景实现轻量级RTSP服务和RTMP推送
技术背景随着VR技术在医疗、军事、农业、学校、景区、消防、公共安全、研学机构、展厅展馆,商场等场所普及,开发者对Unity平台下的直播体验提出了更高的要求。技术实现Unity平台下的RTMP推流、RTMP、RTSP播放前几年已经覆盖了Windows、Linux、Android、i…...

LSB 题解
今天来刷一道Misc的题目,LSB原理进行图片隐写 LSB原理 LSB是一种利用人类视觉的局限性设计的幻术 PNG和BMP图片中的图像像素一般是由RGB(RED红 GREEN绿 BLUE蓝)三原色组成 记住,JPG图片是不适合使用LSB隐写的,JPG图片对像数进行了有损压缩…...

离线部署docker与镜像
离线部署docker与镜像 1.离线部署docker 1).在docker官网上下载,合适的安装文件 本次使用的是“docker-20.10.9.tgz ” 下载地址:https://download.docker.com/linux/static/stable/x86_64/ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下…...
)
Linux文件系统介绍(上)
使用 Linux 系统时,需要作出的决策之一就是为存储设备选用什么文件系统。大多数 Linux 发行版在安装时会非常贴心地提供默认的文件系统,大多数入门级用户想都不想就用了默认的那个。 使用默认文件系统未必就不好,但了解一下可用的选择有时也会…...

创建SpringBoot注意事项
作为一个java小白,你是否因为创建SpringBoot项目那些莫名其妙的错误搞得头皮发麻。不要慌张,这篇文章能帮你解决90%的问题【持续更新…】 本文结合创建SpringBoot项目的完整过程来讲 在idea中新建项目 虽然SpringBoot项目是由maven内核组成的࿰…...

2023年全国最新二级建造师精选真题及答案9
百分百题库提供二级建造师考试试题、二建考试预测题、二级建造师考试真题、二建证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 11.关于施工合同违约赔偿损失范围的说法,正确的是()。 A.…...

解决MySQL的 Row size too large (> 8126).
📢欢迎点赞 :👍 收藏 ⭐留言 📝 如有错误敬请指正,赐人玫瑰,手留余香!📢本文作者:由webmote 原创📢作者格言:无尽的折腾后,终于又回到…...

最优传输问题和Sinkhorn
最优传输问题 假设有M堆土,每堆土的大小是ama_mam,有N个坑,每个坑的大小是bnb_nbn,把单位土从土堆m运送到坑n的代价是c(m,n)c(m,n)c(m,n),如何找到一种运输方法填满坑,并且代价最小,这就是…...

Netty核心组件EventLoop源码解析
源码解析目标 分析最核心组件EventLoop在Netty运行过程中所参与的事情,以及具体实现 源码解析 依然用netty包example下Echo目录下的案例代码,单我们写一个NettyServer时候,第一句话就是 EventLoopGroup bossGroup new NioEventLoopGroup(…...

排障命令-汇总
目录 日志查询 1. grep 2. zgrep cpu 1. top 内存 1. free tcp相关 1. netstat 2. ulimit 3. lsof jvm常用 1. jps 2. jinfo 3. jstack 4. jmap 5. jstat 进制转换 1. 十进制转16进制 日志查询 1. grep 定义:(global regular expression) 命令用于查…...

python+pytest接口自动化(4)-requests发送get请求
python中用于请求http接口的有自带的urllib和第三方库requests,但 urllib 写法稍微有点繁琐,所以在进行接口自动化测试过程中,一般使用更为简洁且功能强大的 requests 库。下面我们使用 requests 库发送get请求。requests库简介requests 库中…...

开源电子书工具Calibre 6.3 发布
Calibre 开源项目是 Calibre 官方出的电子书管理工具。它可以查看,转换,编辑和分类所有主流格式的电子书。Calibre 是个跨平台软件,可以在 Linux、Windows 和 macOS 上运行。Calibre 6.3 正式发布,此次更新内容如下:新…...

彻底解决机械键盘连击问题:免费开源工具KeyboardChatterBlocker完全指南
彻底解决机械键盘连击问题:免费开源工具KeyboardChatterBlocker完全指南 【免费下载链接】KeyboardChatterBlocker A handy quick tool for blocking mechanical keyboard chatter. 项目地址: https://gitcode.com/gh_mirrors/ke/KeyboardChatterBlocker 你是…...

基于RK3568与CODESYS的工业边缘控制器:软PLC如何重塑自动化设备核心
1. 为什么工业自动化需要软PLC? 记得五年前我第一次接触传统PLC时,被它的价格吓了一跳。一台西门子S7-1200基础型号就要上万元,加上各种扩展模块轻松突破两万。更让我头疼的是,每次设备升级都要重新采购硬件,旧设备只能…...

做电力仪器选显示屏踩坑3年,终于摸透这四个选型标准
我是电力仪器设备厂的生产测试主管,干这行快7年了,前前后后负责过继保测试仪、变比测试仪、互感器校验仪等七八款产品的配件选型,光显示屏就换过四家供应商,踩过强电磁下跳数、低温黑屏、交期拖垮项目的坑,直到用上恒域…...

Unity 2D横版闯关游戏:从零到一构建像素风丛林冒险
1. 像素风游戏的前期准备 第一次打开Unity时,看着空荡荡的场景视图,我完全不知道从哪里开始。后来发现,制作2D横版游戏就像搭积木,需要先准备好所有零件。这里分享我制作《丛林法则》时的完整筹备过程。 像素风游戏最迷人的就是那…...

如何轻松下载B站4K大会员视频?这款开源工具让你三步搞定离线收藏
如何轻松下载B站4K大会员视频?这款开源工具让你三步搞定离线收藏 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 想象一下…...

云原生存储优化:优化云原生环境的存储性能
云原生存储优化:优化云原生环境的存储性能 一、云原生存储优化概述 1.1 云原生存储优化的定义 云原生存储优化是指通过优化存储架构、配置和使用方式,提高云原生环境中存储的性能、可靠性和成本效益的过程。 1.2 云原生存储优化的价值 性能提升ÿ…...
zotero-pdf-translate自动翻译失效:5步快速诊断与修复指南
zotero-pdf-translate自动翻译失效:5步快速诊断与修复指南 【免费下载链接】zotero-pdf-translate Translate PDF, EPub, webpage, metadata, annotations, notes to the target language. Support 20 translate services. 项目地址: https://gitcode.com/gh_mirr…...

智能工厂能源监测管理平台解决方案
在某大型制造企业的生产园区,管理人员长期面临着一系列能源管理困境:由于厂区各个电表仍依赖人工抄录,数据滞后且易出错,导致管理层无法实时掌握每条生产线甚至每台关键设备的真实耗电情况;同时,由于电表分…...
:新手也能快速上手,高效搞定会议纪要)
腾讯会议AI助手使用教程(附避坑指南):新手也能快速上手,高效搞定会议纪要
【前言】最近腾讯会议AI助手彻底火了,身边不少程序员、职场人都在使用,都说“再也不用熬夜整理会议纪要了”。但很多新手第一次使用,会遇到“不知道怎么开启”“转写准确率低”“不会导出总结”等问题。今天就给大家带来一份详细的腾讯会议AI…...

实在Agent实测:解决采购合同审核流程冗长与原材料交付周期拉长的架构之道
大家好,我是企业架构师老王。站在2026年5月这个时间节点回看,全球供应链的复杂程度已远超三年前的预判。近期我在为几家制造型企业做数字化诊断时发现,一个幽灵般的困境正在吞噬企业的利润:采购合同审核流程冗长,直接导…...