【DQN】基于pytorch的强化学习算法Demo
目录
- 简介
- 代码
简介
DQN(Deep Q-Network)是一种基于深度神经网络的强化学习算法,于2013年由DeepMind提出。它的目标是解决具有离散动作空间的强化学习问题,并在多个任务中取得了令人瞩目的表现。
DQN的核心思想是使用深度神经网络来逼近状态-动作值函数(Q函数),将当前状态作为输入,输出每个可能动作的Q值估计。通过不断迭代和更新网络参数,DQN能够逐步学习到最优的Q函数,并根据Q值选择具有最大潜在回报的动作。
DQN的训练过程中采用了两个关键技术:经验回放和目标网络。经验回放是一种存储并重复使用智能体经历的经验的方法,它可以破坏数据之间的相关性,提高训练的稳定性。目标网络用于解决训练过程中的估计器冲突问题,通过固定一个与训练网络参数较为独立的目标网络来提供稳定的目标Q值,从而减少训练的不稳定性。
DQN还采用了一种策略称为epsilon-贪心策略来在探索和利用之间进行权衡。初始时,智能体以较高的概率选择随机动作(探索),随着训练的进行,该概率逐渐降低,让智能体更多地依靠Q值选择最佳动作(利用)。
DQN在许多复杂任务中取得了显著的成果,特别是在Atari游戏等需要视觉输入的任务中。它的成功在很大程度上得益于深度神经网络的强大拟合能力和经验回放的效果,使得智能体能够通过与环境的交互进行自主学习。
代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import gym# Hyper Parameters
BATCH_SIZE = 32
LR = 0.01 # learning rate
EPSILON = 0.9 # greedy policy
GAMMA = 0.9 # reward discount
TARGET_REPLACE_ITER = 100 # target update frequency
MEMORY_CAPACITY = 2000
env = gym.make('CartPole-v1',render_mode="human")
#env = gym.make('CartPole-v0')
env = env.unwrapped
N_ACTIONS = env.action_space.n
N_STATES = env.observation_space.shape[0]
ENV_A_SHAPE = 0 if isinstance(env.action_space.sample(), int) else env.action_space.sample().shape # to confirm the shapeclass Net(nn.Module):def __init__(self, ):super(Net, self).__init__()self.fc1 = nn.Linear(N_STATES, 50)self.fc1.weight.data.normal_(0, 0.1) # initializationself.out = nn.Linear(50, N_ACTIONS)self.out.weight.data.normal_(0, 0.1) # initializationdef forward(self, x):x = self.fc1(x)x = F.relu(x)actions_value = self.out(x)return actions_valueclass DQN(object):def __init__(self):self.eval_net, self.target_net = Net(), Net()self.learn_step_counter = 0 # for target updatingself.memory_counter = 0 # for storing memoryself.memory = np.zeros((MEMORY_CAPACITY, N_STATES * 2 + 2)) # initialize memoryself.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=LR)self.loss_func = nn.MSELoss()def choose_action(self, x):x = torch.unsqueeze(torch.FloatTensor(x), 0)# input only one sampleif np.random.uniform() < EPSILON: # greedyactions_value = self.eval_net.forward(x)action = torch.max(actions_value, 1)[1].data.numpy()action = action[0] if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE) # return the argmax indexelse: # randomaction = np.random.randint(0, N_ACTIONS)action = action if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE)return actiondef store_transition(self, s, a, r, s_):transition = np.hstack((s, [a, r], s_))# replace the old memory with new memoryindex = self.memory_counter % MEMORY_CAPACITYself.memory[index, :] = transitionself.memory_counter += 1def learn(self):# target parameter updateif self.learn_step_counter % TARGET_REPLACE_ITER == 0:self.target_net.load_state_dict(self.eval_net.state_dict())self.learn_step_counter += 1# sample batch transitionssample_index = np.random.choice(MEMORY_CAPACITY, BATCH_SIZE)b_memory = self.memory[sample_index, :]b_s = torch.FloatTensor(b_memory[:, :N_STATES])b_a = torch.LongTensor(b_memory[:, N_STATES:N_STATES+1].astype(int))b_r = torch.FloatTensor(b_memory[:, N_STATES+1:N_STATES+2])b_s_ = torch.FloatTensor(b_memory[:, -N_STATES:])# q_eval w.r.t the action in experienceq_eval = self.eval_net(b_s).gather(1, b_a) # shape (batch, 1)q_next = self.target_net(b_s_).detach() # detach from graph, don't backpropagateq_target = b_r + GAMMA * q_next.max(1)[0].view(BATCH_SIZE, 1) # shape (batch, 1)loss = self.loss_func(q_eval, q_target)self.optimizer.zero_grad()loss.backward()self.optimizer.step()dqn = DQN() # 创建 DQN 对象print('\nCollecting experience...')
for i_episode in range(400): # 进行 400 个回合的训练s, info = env.reset() # 环境重置,获取初始状态 s 和其他信息ep_r = 0 # 初始化本回合的总奖励 ep_r 为 0while True:env.render() # 显示环境,通过调用 render() 方法,可以将当前环境的状态以图形化的方式呈现出来.a = dqn.choose_action(s) # 根据当前状态选择动作 a# 下一个状态(nextstate):返回智能体执行动作a后环境的下一个状态。在示例中,它存储在变量s_中。奖励(reward):返回智能体执行动作a后在环境中获得的奖励。在示例中,它存储在变中。# 完成标志(doneflag):返回一个布尔值,指示智能体是否已经完成了当前环境。在示例中,它存储在变量done中。# 截断标志(truncatedflag):返回一个布尔值,表示当前状态是否是由于达到了最大时间步骤或其他特定条件而被截断。在示例中,它存储在变量truncated中。# 其他信息(info):返回一个包含其他辅助信息的字典或对象。在示例中,它存储在变量info中。# 执行动作,获取下一个状态 s_,奖励 r,done 标志位,以及其他信息s_, r, done, truncated, info = env.step(a)# 修改奖励值#根据智能体在x方向和theta方向上与目标位置的偏离程度,计算两个奖励值r1和r2。具体计算方法是将每个偏离程度除以相应的阈值,然后减去一个常数(0.8和0.5)得到奖励值。这样,如果智能体在这两个方向上的偏离程度越小,奖励值越高。x, x_dot, theta, theta_dot = s_ # 从 s_ 中提取参数r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8 # 根据 x 的偏离程度计算奖励 r1r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5 # 根据 theta 的偏离程度计算奖励 r2r = r1 + r2 # 组合两个奖励成为最终的奖励 rdqn.store_transition(s, a, r, s_) # 存储状态转换信息到经验池ep_r += r # 更新本回合的总奖励if dqn.memory_counter > MEMORY_CAPACITY: # 当经验池中的样本数量超过阈值 MEMORY_CAPACITY 时进行学习dqn.learn()if done: # 如果本回合结束print('Ep: ', i_episode,'| Ep_r: ', round(ep_r, 2)) # 打印本回合的回合数和总奖励if done: # 如果任务结束break # 跳出当前回合的循环s = s_ # 更新状态,准备进行下一步动作选择
相关文章:

【DQN】基于pytorch的强化学习算法Demo
目录 简介代码 简介 DQN(Deep Q-Network)是一种基于深度神经网络的强化学习算法,于2013年由DeepMind提出。它的目标是解决具有离散动作空间的强化学习问题,并在多个任务中取得了令人瞩目的表现。 DQN的核心思想是使用深度神经网…...
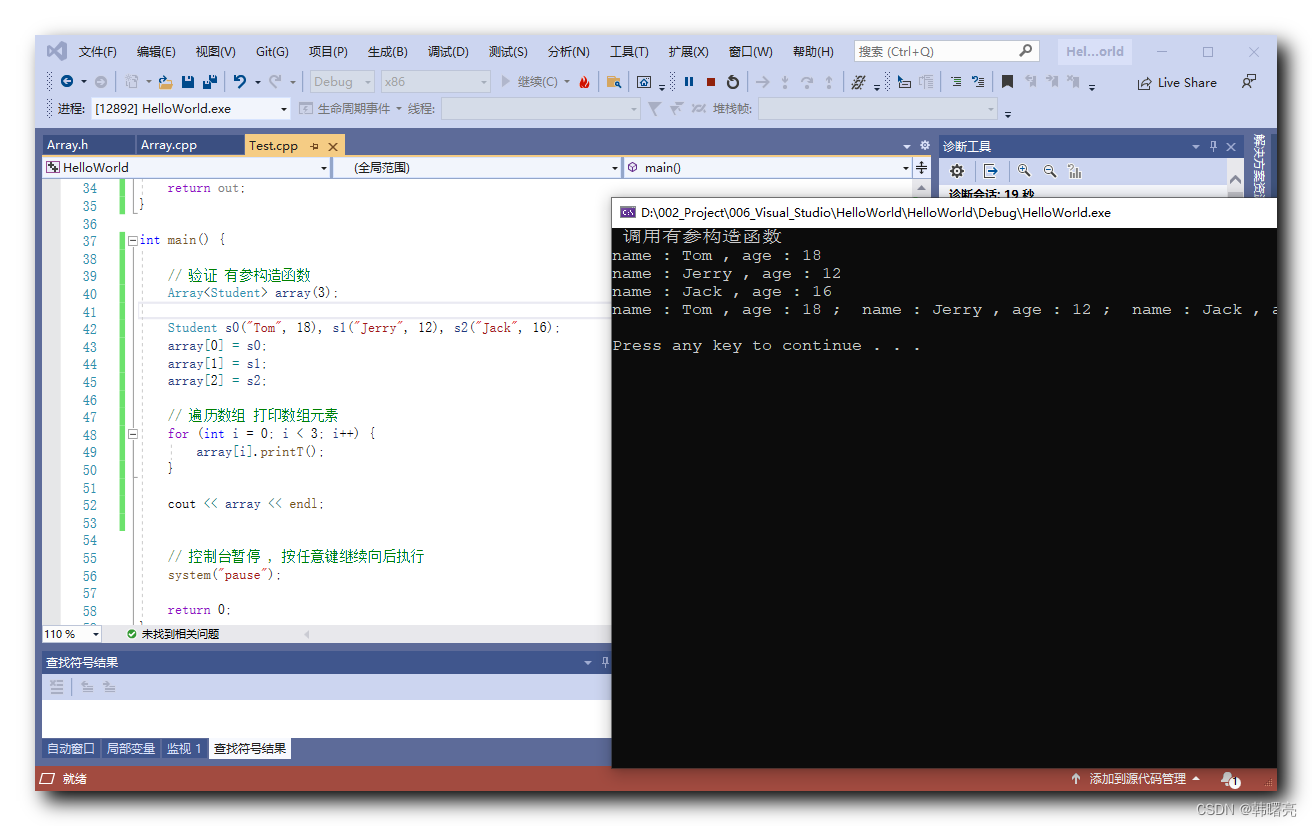
【C++】泛型编程 ⑭ ( 类模板示例 - 数组类模板 | 容器思想 | 自定义类可拷贝 - 深拷贝与浅拷贝 | 自定义类可打印 - 左移运算符重载 )
文章目录 一、容器思想1、自定义类可拷贝 - 深拷贝与浅拷贝2、自定义类可拷贝 - 代码示例3、自定义类可打印 - 左移运算符重载 二、代码示例1、Array.h 头文件2、Array.cpp 代码文件3、Test.cpp 主函数代码文件4、执行结果 一、容器思想 1、自定义类可拷贝 - 深拷贝与浅拷贝 上…...

砖家测评:腾讯云标准型S5服务器和s6性能差异和租用价格
腾讯云服务器CVM标准型S5和S6有什么区别?都是标准型云服务器,标准型S5是次新一代云服务器规格,标准型S6是最新一代的云服务器,S6实例的CPU处理器主频性能要高于S5实例,同CPU内存配置下的标准型S6实例要比S5实例性能更好…...

Linux常用命令——blkid命令
在线Linux命令查询工具 blkid 查看块设备的文件系统类型、LABEL、UUID等信息 补充说明 在Linux下可以使用blkid命令对查询设备上所采用文件系统类型进行查询。blkid主要用来对系统的块设备(包括交换分区)所使用的文件系统类型、LABEL、UUID等信息进行…...
ES 万条以外分页检索功能实现及注意事项
背景 以 ES 存储日志,且需要对日志进行分页检索,当数据量过大时,就面临 ES 万条以外的数据检索问题,如何利用滚动检索实现这个需求呢?本文介绍 ES 分页检索万条以外的数据实现方法及注意事项。 需求分析 用 ES 存储数…...
【MySQL】mysql中不推荐使用uuid或者雪花id作为主键的原因以及差异化对比
文章目录 前言什么是UUID?什么是雪花ID?什么是MySql自增ID?优缺点对比UUID:优点1.全球唯一性2.无需数据库支持 缺点1.存储空间大2.索引效率低3.查询效率低 雪花ID:优点1.分布式环境下唯一性 缺点1.依赖于机器时钟2.存储空间较大3.查询效率低 MYSQL自增:优点1.简单…...
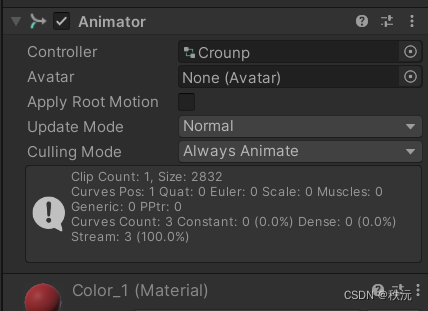
【Unity细节】Default clip could not be found in attached animations list.(动画机报错)
👨💻个人主页:元宇宙-秩沅 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 秩沅 原创 😶🌫️收录于专栏:unity细节和bug 😶🌫️优质专栏 ⭐【…...
VsCode连接远程Linux编译环境的便捷处理
1.免输登录密码 免输命令的正确方法是使用公钥和私鈅在研发设备,和linux服务器上校验身份。公钥和私钥可在windows系统上生成。公钥要发送到linux服务器。私钥需要通知给本地的ssh客户端程序,相关的操作如下: 生成 SSH Key: 打开…...
【UE】用样条线实现测距功能(下)
目录 效果 步骤 一、实现多次测距功能 二、通过控件蓝图来进行测距 在上一篇(【UE】用样条线实现测距功能(上))文章基础上继续实现多次测距和清除功能。 效果 步骤 一、实现多次测距功能 打开蓝图“BP_Spline”,…...
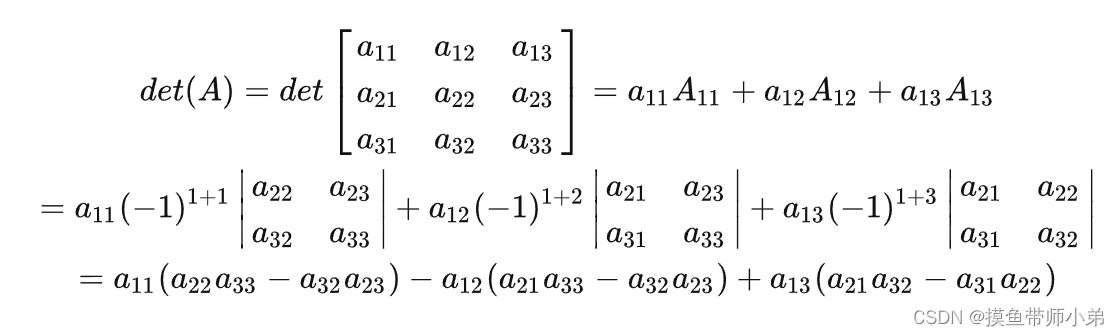
矩阵知识补充
正交矩阵 定义: 正交矩阵是一种满足 A T A E A^{T}AE ATAE的方阵 正交矩阵具有以下几个重要性质: A的逆等于A的转置,即 A − 1 A T A^{-1}A^{T} A−1AT**A的行列式的绝对值等于1,即 ∣ d e t ( A ) ∣ 1 |det(A)|1 ∣det(A)∣…...

机器学习之数据清洗和预处理
目录 Box_Cox Box_Cox Box-Cox变换是一种用于数据预处理和清洗的方法,旨在使数据更符合统计模型的假设,特别是对于线性回归模型。这种变换通过调整数据的尺度和形状,使其更加正态分布。 Box-Cox变换的定义是: y ( λ ) { y λ − 1 λ , i…...

【SpringBoot系列】SpringBoot日志配置
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

庖丁解牛:NIO核心概念与机制详解 06 _ 连网和异步 I/O
文章目录 Pre概述异步 I/OSelectors打开一个 ServerSocketChannel选择键内部循环监听新连接接受新的连接删除处理过的 SelectionKey传入的 I/O回到主循环 Pre 庖丁解牛:NIO核心概念与机制详解 01 庖丁解牛:NIO核心概念与机制详解 02 _ 缓冲区的细节实现…...
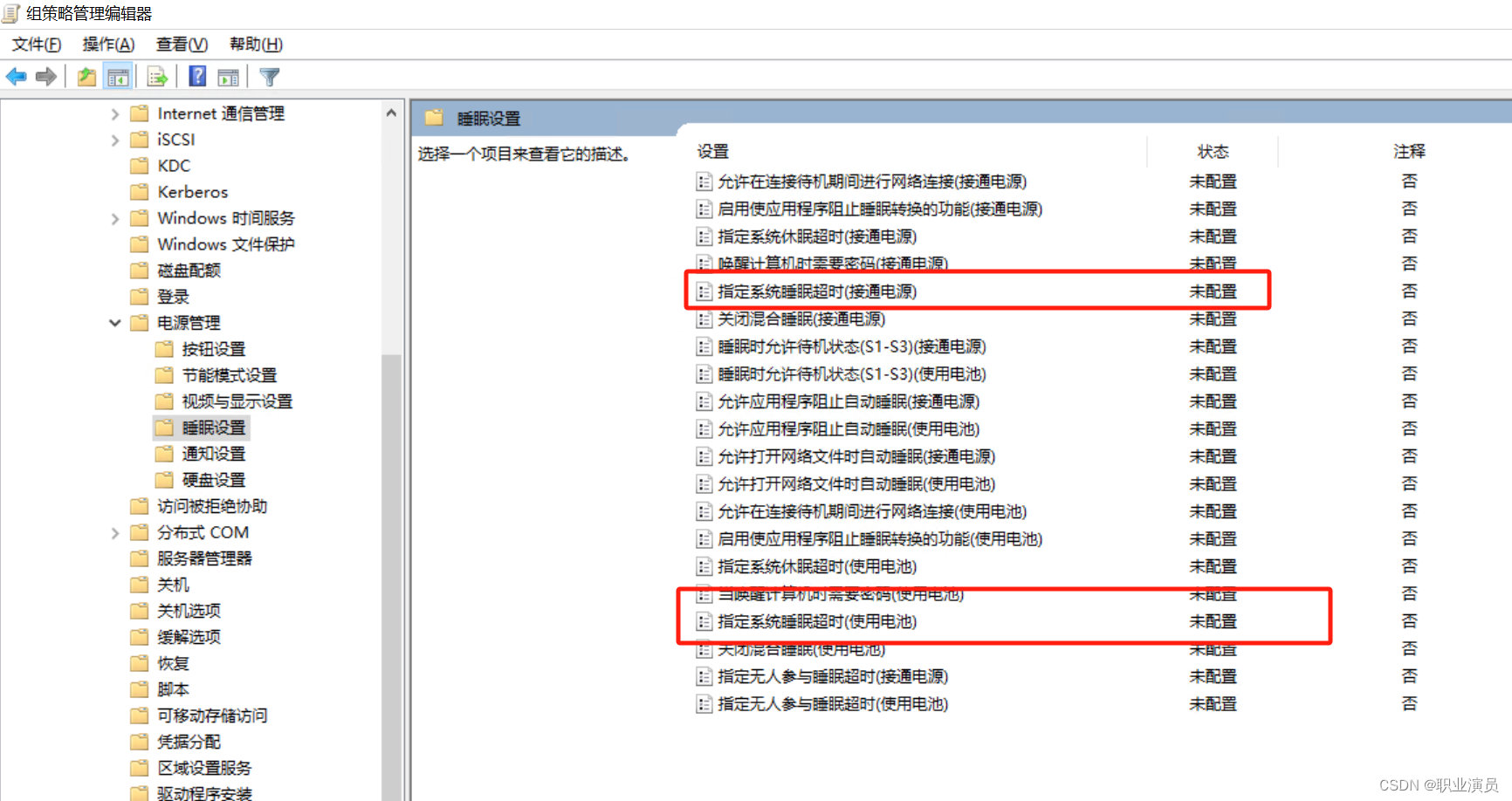
域控操作五:统一熄屏睡眠时间
直接看图路径,我只设置了熄屏,如果要睡眠就下面那个启用设置时间...

2023APMCM亚太杯数学建模选题建议及初步思路
大家好呀,亚太杯数学建模开始了,来说一下初步的选题建议吧: 首先定下主基调,本次亚太杯推荐选择B题。 C题如果想做好,搜集数据难度并不低,并且模型比较简单,此外目前选择的人数过多,…...

ORA-28003: password verification for the specified password failed,取消oracl密码复杂度
自己在测试环境想要使自己的Oracle数据库用户使用简单的密码方便测试,结果指定密码的密码验证失败 SQL> alter user zzw identified by zzw; alter user zzw identified by zzw * ERROR at line 1: ORA-28003: password verification for the specified password…...

【DevOps】Git 图文详解(九):工作中的 Git 实践
本系列包含: Git 图文详解(一):简介及基础概念Git 图文详解(二):Git 安装及配置Git 图文详解(三):常用的 Git GUIGit 图文详解(四)&a…...

外贸自建站服务器怎么选?网站搭建的工具?
外贸自建站服务器用哪个好?如何选海洋建站的服务器? 外贸自建站是企业拓展海外市场的重要手段之一。而在这个过程中,选择一个适合的服务器对于网站的稳定运行和优化至关重要。海洋建站将为您介绍如何选择适合的外贸自建站服务器。 外贸自建…...

010 OpenCV中的4种平滑滤波
目录 一、环境 二、平滑滤波 2.1、均值滤波 2.2、高斯滤波 2.3、中值滤波 2.4、双边滤波 三、完整代码 一、环境 本文使用环境为: Windows10Python 3.9.17opencv-python 4.8.0.74 二、平滑滤波 2.1、均值滤波 在OpenCV库中,blur函数是一种简…...

Oracle-客户端连接报错ORA-12545问题
问题背景: 用户在客户端服务器通过sqlplus通过scan ip登陆访问数据库时,偶尔会出现连接报错ORA-12545: Connect failed because target host or object does not exist的情况。 问题分析: 首先,登陆到连接有问题的客户端数据库上,…...

cv_unet_image-colorization部署案例:Kubernetes集群中高可用服务编排
cv_unet_image-colorization部署案例:Kubernetes集群中高可用服务编排 1. 项目概述 在现代AI应用部署中,确保服务的高可用性和弹性扩展能力至关重要。cv_unet_image-colorization作为基于UNet架构的深度学习图像上色工具,在生产环境中需要稳…...

基于Python与LLM API构建轻量级命令行问答工具
1. 项目概述:一个轻量级命令行问答工具最近在折腾一些自动化脚本,经常需要在终端里快速查询一些信息,比如某个命令的用法、一个概念的简单解释,或者把一段代码从Python翻译成Go。每次都打开浏览器、切换标签页、输入关键词&#x…...
)
为什么你的低代码应用在MCP 2026沙箱环境总报“ContextNotBound”错误?(附官方未公开的调试模式启用密钥)
更多请点击: https://intelliparadigm.com 第一章:ContextNotBound错误的本质与MCP 2026沙箱的上下文生命周期模型 错误根源解析 ContextNotBound 是 MCP 2026 沙箱运行时的核心异常之一,表明当前执行线程试图访问一个尚未被显式绑定&#…...
)
MCP 2026调度策略迁移避坑指南,12个生产环境血泪案例(含某TOP3云厂商未公开故障复盘)
更多请点击: https://intelliparadigm.com 第一章:MCP 2026调度策略迁移的底层逻辑与演进全景 MCP(Multi-Cluster Policy)2026调度策略并非简单配置升级,而是面向异构算力联邦、跨云服务网格与实时SLA保障的范式重构。…...
)
MCP 2026漏洞利用链首现野火传播,你的监控系统是否还在用默认SNMPv2c?——4小时应急响应作战图(含IoC与YARA规则)
更多请点击: https://intelliparadigm.com 第一章:MCP 2026漏洞本质与野火传播机理剖析 MCP 2026(Mitigated Control Protocol)并非真实协议,而是安全研究社区对一类新型服务端控制通道混淆缺陷的代号——其核心在于攻…...

Amlogic S9xxx Armbian历史版本获取指南:解决新内核不兼容的实战方案
Amlogic S9xxx Armbian历史版本获取指南:解决新内核不兼容的实战方案 【免费下载链接】amlogic-s9xxx-armbian Supports running Armbian on Amlogic, Allwinner, and Rockchip devices. Support a311d, s922x, s905x3, s905x2, s912, s905d, s905x, s905w, s905, s…...
_kaic)
基于微信小程序的驾校预约平台(文档+源码)_kaic
第5章 系统实现进入到这个环节,也就可以及时检查出前面设计的需求是否可靠了。一个设计良好的方案在运用于系统实现中,是会帮助系统编制人员节省时间,并提升开发效率的。所以在系统的编程阶段,也就是系统实现阶段,对于…...

035、嵌入式与边缘场景:轻量化Agent的挑战与设计
一、从一次深夜调试说起 上周在客户现场蹲到凌晨三点,就为了查一个内存泄漏。Agent在树莓派4B上跑了72小时之后,进程突然僵死,看门狗都没拉回来。最后发现是JSON解析库在反复分配小内存块,碎片把32位系统的用户空间挤爆了。这件事让我重新审视边缘场景的残酷性:这里没有K…...
)
电池销售系统|基于java + vue电池销售系统(源码+数据库+文档)
电池销售系统 目录 基于springboot vue电池销售系统 一、前言 二、系统功能演示 三、技术选型 四、其他项目参考 五、代码参考 六、测试参考 七、最新计算机毕设选题推荐 八、源码获取: 基于springboot vue电池销售系统 一、前言 博主介绍:✌…...

使用Cython中prange函数实现for循环的并行
上一篇文章我们探讨了 GIL 的原理,以及如何释放 GIL 实现并行,做法是将函数声明为 nogil,然后使用 with nogil 上下文管理器即可。在使用上非常简单,但如果我们想让循环也能够并行执行,那么该方式就不太方便了…...