中文rlhf数据集50w条数据解析
中文rlhf数据集50w条数据解析
- 解析代码
- 数据名
- 代码解析
解析代码
import jieba
from tqdm import tqdm
import re
import pandas as pd
import numpy as npdef find_non_english_text(text):pattern = re.compile(r'[^a-zA-Z]')return pattern.sub('', text)def find_chinese_text(text):pattern = re.compile(r'[^\u4e00-\u9fff]')return pattern.sub('', text)json_list = pd.read_parquet("E:/data_sets/train-rm-static-m2m100-zh-jianti.parquet")
data_list = []
basic_list = ["<|User|>", "<|Ash|>"] * 100for _, one_data in tqdm(json_list.iterrows()):ins = "".join(one_data["prompt"].split("\n\n")[1:-1])# inp=one_data["input"]out = one_data["response"]ins = np.hstack([i.split("Human:") for i in ins.split("Assistant:")])[1:].tolist()ins = [i for i in ins if len(i)>0]ins_len = len(ins)try:ins = np.hstack([[i, j] for i, j in zip(basic_list[:ins_len], ins)]).tolist()ins += [basic_list[ins_len], out]data_list.append(ins)except:continue
with open("data_set_five.txt", "a", encoding="utf-8") as f:voc_set = set()for one_data in tqdm(data_list):ins = []for one in one_data:if one in ["<|User|>", "<|Ash|>"]:ins += [one]else:one = jieba.lcut(one)try:one = np.hstack([list(i) if len(find_chinese_text(i)) > 0 else i for i in one]).tolist()except:breakins += onevoc_set |= set(ins)f.write(str(ins) + "\n")
数据名
在hf上搜方可
train-rm-static-m2m100-zh-jianti.parquet
数据地址
代码解析
import jieba: 导入分词库jieba。from tqdm import tqdm: 导入tqdm库,用于在循环中显示进度条。import re: 导入正则表达式库。import pandas as pd: 导入pandas库,用于处理数据。import numpy as np: 导入numpy库,用于处理数组。def find_non_english_text(text): 定义一个函数,用于查找非英文文本。该函数输入一个文本,使用正则表达式找到文本中的非英文字符,并用空字符替换。def find_chinese_text(text): 定义一个函数,用于查找中文文本。该函数输入一个文本,使用正则表达式找到文本中的非中文字符,并用空字符替换。json_list = pd.read_parquet("E:/data_sets/train-rm-static-m2m100-zh-jianti.parquet"): 读取parquet格式的文件,并将数据赋值给json_list。data_list = []: 定义一个空列表,用于存储最终的数据。basic_list = ["<|User|>", "<|Ash|>"] * 100: 定义一个列表,其中包含两个字符串"<|User|>“和”<|Ash|>",并将其重复100次。for _, one_data in tqdm(json_list.iterrows()):: 遍历json_list,并使用tqdm在循环中显示进度条。其中,_表示索引值,one_data表示每一行数据。ins = "".join(one_data["prompt"].split("\n\n")[1:-1]): 从one_data中获取prompt字段,并去除字段中的换行符。然后,取出prompt中除第一行和最后一行之外的所有内容,并将其赋值给ins。out = one_data["response"]: 从one_data中获取response字段,并将其赋值给out。ins = np.hstack([i.split("Human:") for i in ins.split("Assistant:")])[1:].tolist(): 将ins根据"Assistant:"分割成多个子串,然后将子串中的"Human:"去除,并将子串合并为一个列表。最后,将列表中的第一个元素去除,并将其转换为列表类型。ins_len = len(ins): 获取ins列表的长度,并将其赋值给ins_len。ins = np.hstack([[i, j] for i, j in zip(basic_list[:ins_len], ins)]).tolist(): 将basic_list中与ins长度相同的元素取出,然后将basic_list和ins中的元素一一配对组成元素为两个字符串的列表,并将这些列表合并为一个列表。最后,将这个列表转换为列表类型。data_list.append(ins): 将ins添加到data_list中。with open("data_set_five.txt", "a", encoding="utf-8") as f:: 打开一个文件"data_set_five.txt",并将其赋值给变量f。打开文件时,使用"a"模式表示追加数据到文件末尾。voc_set = set(): 定义一个空集合,用于存储数据中的所有词汇。for one_data in tqdm(data_list):: 遍历data_list,并使用tqdm在循环中显示进度条。其中,one_data表示每一个元素。ins = []: 定义一个空列表,用于存储分词后的文本。for one in one_data:: 遍历one_data中的每一个元素,并将其赋值给变量one。if one in ["<|User|>", "<|Ash|>"]:: 判断one是否等于"<|User|>“或”<|Ash|>"。ins += [one]: 如果one等于"<|User|>“或”<|Ash|>",则将one加入ins中。else:: 如果one不等于"<|User|>“或”<|Ash|>"。one = jieba.lcut(one): 使用jieba对one进行分词。try:: 开始异常处理。one = np.hstack([list(i) if len(find_chinese_text(i)) > 0 else i for i in one]).tolist(): 对于one中的每个分词,如果其包含中文字符,则将其拆分成单个字符,否则不做处理。然后,将处理后的结果合并为一个列表,并将这个列表转换为列表类型。voc_set |= set(ins): 将ins中的所有元素加入voc_set中。f.write(str(ins) + "\n"): 将ins转换为字符串,并将其写入文件中,同时在字符串末尾加入换行符。
相关文章:

中文rlhf数据集50w条数据解析
中文rlhf数据集50w条数据解析 解析代码数据名代码解析 解析代码 import jieba from tqdm import tqdm import re import pandas as pd import numpy as npdef find_non_english_text(text):pattern re.compile(r[^a-zA-Z])return pattern.sub(, text)def find_chinese_text(t…...
:UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte xxx)
解决解析PDF编码报错(以pdfminer为例):UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte xxx
解决方法 博主使用的是pdfminer解析PDF文档,这个解决方法是通用的,只需要使PDFParser传入的文件为二进制文件即可,示例程序: from pdfminer.pdfparser import PDFParserpdf_parser PDFParser(open("pdf文件.pdf", &q…...
)
chatGPT2:如何构建一个可以回答有关您网站问题的 AI 嵌入(embeddings)
感觉这个目前没有什么用,因为客户可以直接问通用chatGPT,实时了解你网站内的信息,除非你的网站chatGPT无法访问。 不过自动预订、买票等用嵌入还是挺有用的。 什么是嵌入? OpenAI的嵌入(embeddings)是一种…...

Vue3-新特性defineOptions和defineModel
defineOptions 问题:用了<script setup>后,就无法添加与其平级的属性了,比如定义组件的name或其他自定义的属性。 为了解决这一问题,引入了defineProps与defineEmits这两个宏,但这只解决了props与emits这两个属…...
【计算机基础】通过插件plantuml,实现在VScode里面绘制状态机
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨ 📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍…...
Linux常用基础命令及重要目录,配置文件功能介绍
目录 一,Linux常用必备基础命令 1,网络类命令 2,文件目录类命令 3,操作类命令 4,关机重启命令 5,帮助命令 6,查看显示类命令 7,命令常用快捷键 二,Linux重要目录…...

Oracle登录认证方式详解
文章目录 一、简介二、OS认证三、口令认证四、remote_login_passwordfile 详解 一、简介 在数据库管理中,登录认证是确保数据库安全性的重要环节。Oracle数据库提供 了两种认证方式,一种是“操作系统认证”,一种是“口令文件认证,…...

ate测试原理及ate测试系统(软件)知识科普 -纳米软件
ATE(Automatic Test Equipment)测试也叫自动化测试,通过计算机控制测试仪器对被测对象进行测试。以计算机编程代替人工测试,基于测试程序控制仪器并对待测品进行输入和输出信号检测分析,从而判断待测品的性能是否符合要求。 ATE测试需要根据测…...
Linux | 创建 | 删除 | 查看 | 基本命名详解
Linux | 创建 | 删除 | 查看 | 基本命名详解 文章目录 Linux | 创建 | 删除 | 查看 | 基本命名详解前言一、安装Linux1.1 方法一:云服务器方式1.2 方法二:虚拟机方式 二、ls2.2 ll 三、which3.1 ls -ld 四、pwd五、cd5.1 cd .\.5.2 ls -al5.3 重新认识命…...

搭配:基于OpenCV的边缘检测实战
引言 计算机中的目标检测与人类识别物体的方式相似。作为人类,我们可以分辨出狗的形象,因为狗的特征是独特的。尾巴、形状、鼻子、舌头等特征综合在一起,帮助我们把狗和牛区分开来。 同样,计算机能够通过检测与估计物体的结构和性…...

AI大发展:人机交互、智能生活全解析
目录 编辑 人工智能对我们的生活影响有多大 人工智能的应用领域 一、机器学习与深度学习 二、计算机视觉 三、自然语言处理 四、机器人技术 五、智能推荐系统 六、智能城市和智能家居 编辑 自己对人工智能的应用 自己的人工智能看法:以ChatGPT为例 …...
Django DRF序列化器serializer
以下案例由浅到深,逐步深入,通过实例介绍了序列化器的使用方法,和遇到的常见问题的解决方法。 一、序列化器serializers.Serializer 1、urls.py urlpatterns [path("api/<str:version>/depart/",views.DepartView.as_vie…...

【开源】基于JAVA的衣物搭配系统
项目编号: S 016 ,文末获取源码。 \color{red}{项目编号:S016,文末获取源码。} 项目编号:S016,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、研究内容2.1 衣物档案模块2.2 衣物搭配模块2.3 衣…...
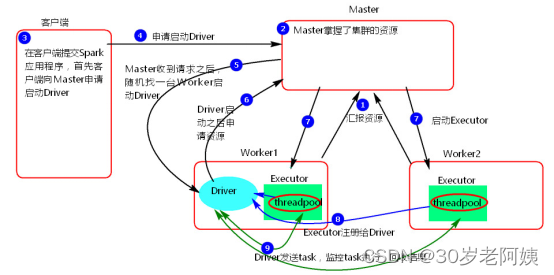
Spark---基于Standalone模式提交任务
Standalone模式两种提交任务方式 一、Standalone-client提交任务方式 1、提交命令 ./spark-submit --master spark://mynode1:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.3.1.jar 100 或者 ./spark-submit --master spark…...

webrtc的RTCPeerConnection使用
背景: 平时我们很少会需要使用到点对点单独的通讯,即p2p,一般都是点对服务端通讯,但p2p也有自己的好处,即通讯不经过服务端,从服务端角度这个省了带宽和压力,从客户端角度,通讯是安全,且快速的,当然有些情况下可能速度并不一定快。那么如何实现p2p呢? 解决办法: …...

【视觉SLAM十四讲学习笔记】第三讲——Eigen库
专栏系列文章如下: 【视觉SLAM十四讲学习笔记】第一讲——SLAM介绍 【视觉SLAM十四讲学习笔记】第二讲——初识SLAM 【视觉SLAM十四讲学习笔记】第三讲——旋转矩阵 本章将介绍视觉SLAM的基本问题之一:如何描述刚体在三维空间中的运动? Eigen…...
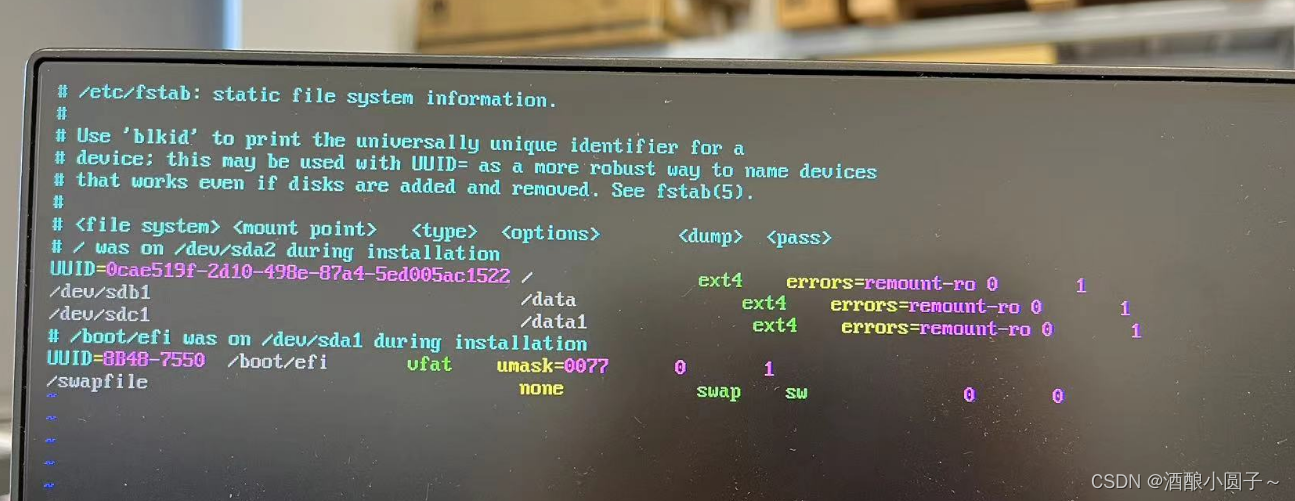
Ubuntu开机显示recovering journal,进入emergency mode
在一次正常的shutdown -r now之后,服务器启动不起来了,登录界面显示recovering journal,主要报错信息如下所示: /dev/sda2:recovering journal /dev/sda2:Clearn... You are in emergency mode. After logging in, type journalc…...

C++_String增删查改模拟实现
C_String增删查改模拟实现 前言一、string默认构造、析构函数、拷贝构造、赋值重载1.1 默认构造1.2 析构函数1.3 拷贝构造1.4 赋值重载 二、迭代器和范围for三、元素相关:operator[ ]四、容量相关:size、resize、capacity、reserve4.1 size、capacity4.2…...
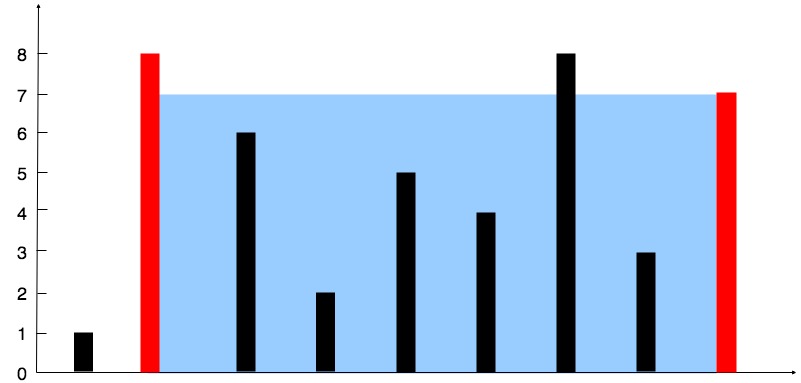
LeeCode前端算法基础100题(2)- 最多水的容器
一、问题详情: 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明:…...

排序算法--归并排序
实现逻辑 ① 将序列每相邻两个数字进行归并操作,形成floor(n/2)个序列,排序后每个序列包含两个元素 ② 将上述序列再次归并,形成floor(n/4)个序列,每个序列包含四个元素 ③ 重复步骤②,直到所有元素排序完毕 void pri…...

高可靠工控机架构:C#上位机的分层设计与模块化开发实践
工控机上位机作为工业现场的“大脑”,需要在电磁干扰、电压波动、设备异构、724小时连续运行的严苛场景下保障可靠性。传统的“面条式”代码(业务、通信、UI耦合)往往导致故障难以定位、扩展困难、运行不稳定。而分层设计+模块化开发是构建高可靠工控机上位机的核心方法论—…...

DCGAN实战:生成MNIST手写数字的完整指南
1. 项目概述:用GAN生成手写数字的实战指南在计算机视觉领域,生成对抗网络(GAN)已经成为图像生成任务中最具革命性的技术之一。2014年Ian Goodfellow提出的这一框架,通过生成器与判别器的对抗训练,能够产生以…...

WeDLM-7B-Base实际效果:中文古文风格、现代白话、技术文档三体裁续写
WeDLM-7B-Base实际效果:中文古文风格、现代白话、技术文档三体裁续写 1. 模型概览 WeDLM-7B-Base是一款基于扩散机制(Diffusion)的高性能基座语言模型,拥有70亿参数规模。该模型在标准因果注意力机制基础上实现了并行掩码恢复技…...

终极Windows更新修复指南:5分钟解决系统更新卡死问题
终极Windows更新修复指南:5分钟解决系统更新卡死问题 【免费下载链接】Reset-Windows-Update-Tool Troubleshooting Tool with Windows Updates (Developed in Dev-C). 项目地址: https://gitcode.com/gh_mirrors/re/Reset-Windows-Update-Tool 你是否曾经遇…...
和toLocaleString()无法同时使用,最终结果不理想)
toFixed()和toLocaleString()无法同时使用,最终结果不理想
toLocaleString()将数字转换为带千分位的字符串格式toFixed(2) 将数字转化为保留两位小数的字符串格式var number123,456.899 没有保留2位小数number.toLocaleString().toFixed(2) //123,456.899 没有保留2位小数number.toFixed(2)r.toLocaleString() // 123,456.89 没有千分…...

别再只会用PWM调光了!拆解一个5050RGB灯珠的‘跑马呼吸灯’产品级驱动方案
5050RGB灯珠的跑马呼吸灯:逆向工程与产品级驱动方案设计 第一次拿到那个样品时,我被它的灯光效果惊艳到了——五个LED灯珠像彩虹般流动变换,色彩过渡丝滑得如同液体流动,呼吸效果自然得仿佛有生命。作为在消费电子行业摸爬滚打多年…...
✅)
计算机毕业设计:Python股票市场智能分析工具 django框架 request爬虫 协同过滤算法 数据分析 可视化 大数据 大模型(建议收藏)✅
1、项目介绍 技术栈 python、django框架、requests、BeautifulSoup、协同过滤算法、Echarts可视化、HTML 功能模块 登录注册界面个人信息修改收藏与取消收藏股票新闻爬取与展示股票数据展示(历史价格、成交量等)所有股票可视化展示单个证券多图表展示&am…...

告别QT WebEngine!用Electron + QWebChannel + Vue 3重构你的C++桌面应用界面
重构C桌面应用界面:Electron QWebChannel Vue 3全栈方案深度解析 在工业控制、仪器仪表、嵌入式系统等领域,C凭借其高性能和硬件级操作能力长期占据主导地位。但当这些专业工具需要面向现代用户时,开发者往往面临两难选择:要么忍…...

终极指南:如何用MAA明日方舟助手彻底解放你的游戏时间
终极指南:如何用MAA明日方舟助手彻底解放你的游戏时间 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://git…...
-收尾)
并发编程(10)-收尾
JMM基础-计算机原理 操作 响应时间 打开一个站点 几秒 数据库查询一条记录(有索引) 十几毫秒 1.6G的CPU执行一条指令 0.6纳秒 从机械磁盘顺序读取1M数据 2-10毫秒 从SSD磁盘顺序读取1M数据 0.3毫秒 从内存连续读取1M数据 250微秒 CPU读取一次内存 100纳秒 1G网卡,网络传输2k…...