大数据基础设施搭建 - Kafka(with ZooKeeper)
文章目录
- 一、简介
- 二、单机部署
- 2.1 上传压缩包
- 2.2 解压压缩包
- 2.3 修改配置文件
- (1)配置zookeeper地址
- (2)修改kafka运行日志(数据)存储路径
- 2.4 配置环境变量
- 2.5 启动/关闭
- 2.6 测试
- (1)查看当前服务器中的所有topic
- (2)创建topic等增删改查操作未测试,担心后面升级为集群模式时出问题。
- 三、集群部署
- 3.0 清空log.dirs目录并删除zookeeper的kafka节点
- 3.1 同步到其他机器
- (1)同步Kafka软件
- (2)修改其他机器的broker.id
- (3)配置其他机器的环境变量
- 3.2 启动/停止集群
- 3.3 测试
- (1)查看当前服务器中的所有topic
- (2)创建topic
- (3)删除topic
- (4)发送消息
- (5)消费消息
- (6)查看某个Topic的详情
- (7)修改分区数
- 四、监控(kafka-eagle单机模式)
- 4.0 上传并解压kafka-eagle压缩包
- 4.1 修改Kafka集群配置
- (1)暴露JMX端口
- (2)调大Kafka内存
- (3)分发配置
- 4.2 配置kafka-eagle
- 4.2.1 修改配置文件
- (1)配置zk地址
- (2)Kafka Offset的存储地址
- (3)配置MySQL地址
- (4)其他配置
- 4.2.2 配置环境变量
- 4.3 启动
- 4.3.1 启动Kafka集群
- 4.3.2 启动kafka-eagle
- 4.3.3 关闭kafka-eagle
- 4.4 测试
一、简介
Kafka官网:https://kafka.apache.org/intro
Kafka是Scala开发的,运行依赖JVM,所以安装Kafka前需要先安装JDK。
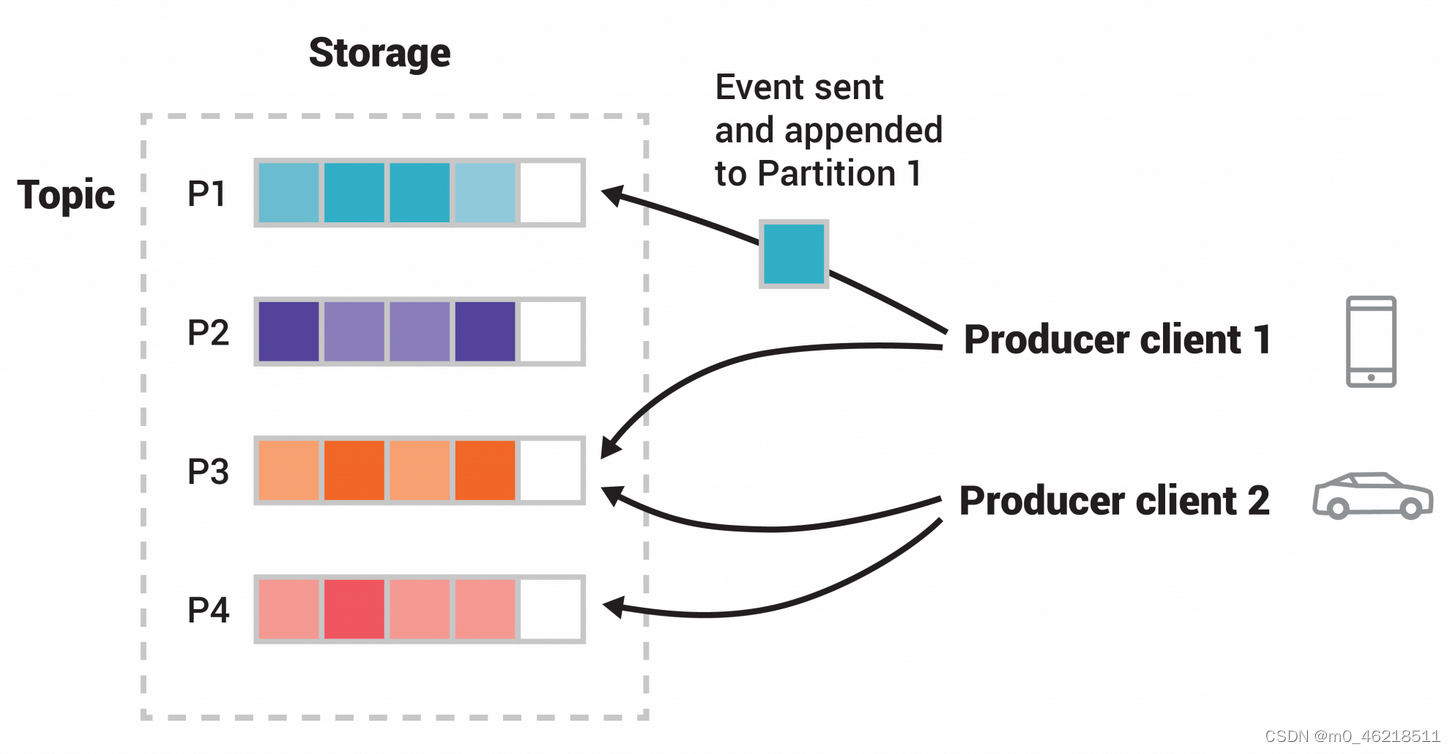
二、单机部署
Kafka集群化部署需要分布式协调服务来帮助Kafka实现高可用,分布式协调服务可以使用通用解决方案Zookeeper或Kafka内部实现的KRaft。ZooKeeper充当的角色是帮助提供公平的选举机制选举leader等作用。本例采用的模式是Kafka with ZooKeeper(参考资料丰富)。
2.1 上传压缩包
2.2 解压压缩包
[hadoop@hadoop102 software]$ tar -zxvf kafka_2.11-2.4.1.tgz -C /opt/module/
2.3 修改配置文件
[hadoop@hadoop102 config]$ vim server.properties
(1)配置zookeeper地址
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
(2)修改kafka运行日志(数据)存储路径
log.dirs=/opt/module/kafka_2.11-2.4.1/datas
2.4 配置环境变量
[hadoop@hadoop102 config]$ sudo vim /etc/profile.d/my_env.sh
新增内容:
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka_2.11-2.4.1
export PATH=$PATH:$KAFKA_HOME/bin
使环境变量生效:
[hadoop@hadoop102 config]$ source /etc/profile
2.5 启动/关闭
[hadoop@hadoop102 config]$ cd /opt/module/kafka_2.11-2.4.1/
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-server-start.sh -daemon config/server.properties
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-server-stop.sh stop
2.6 测试
(1)查看当前服务器中的所有topic
两种查看方式,一种是连kafka查看,一种是连zookeeper看,topic信息存zookeeper上了????
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka --list
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list
(2)创建topic等增删改查操作未测试,担心后面升级为集群模式时出问题。
三、集群部署
从Kafka单机模式升级到Kafka集群模式,一定要先清空log.dirs目录,否则其他机器会启动失败。需要清空zookeeper中kafka信息吗?
3.0 清空log.dirs目录并删除zookeeper的kafka节点
[hadoop@hadoop102 kafka_2.11-2.4.1]$ rm -r datas/
# 启动zookeeper客户端
[zk: localhost:2181(CONNECTED) 5] deleteall /kafka
3.1 同步到其他机器
(1)同步Kafka软件
[hadoop@hadoop102 ~]$ mytools_rsync /opt/module/kafka_2.11-2.4.1/
(2)修改其他机器的broker.id
不同机器的brokerid不能相同
[hadoop@hadoop103 config]$ vim server.properties
# 修改内容:broker.id=1
[hadoop@hadoop104 config]$ vim server.properties
# 修改内容:broker.id=2
(3)配置其他机器的环境变量
[hadoop@hadoop103 config]$ sudo vim /etc/profile.d/my_env.sh
[hadoop@hadoop104 config]$ sudo vim /etc/profile.d/my_env.sh
新增内容:
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka_2.11-2.4.1
export PATH=$PATH:$KAFKA_HOME/bin
使环境变量生效:
[hadoop@hadoop103 config]$ source /etc/profile
[hadoop@hadoop104 config]$ source /etc/profile
3.2 启动/停止集群
# 启动
[hadoop@hadoop102 config]$ cd /opt/module/kafka_2.11-2.4.1/
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-server-start.sh -daemon config/server.properties
[hadoop@hadoop103 config]$ cd /opt/module/kafka_2.11-2.4.1/
[hadoop@hadoop103 kafka_2.11-2.4.1]$ bin/kafka-server-start.sh -daemon config/server.properties
[hadoop@hadoop104 config]$ cd /opt/module/kafka_2.11-2.4.1/
[hadoop@hadoop104 kafka_2.11-2.4.1]$ bin/kafka-server-start.sh -daemon config/server.properties# 停止
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-server-stop.sh stop
[hadoop@hadoop103 kafka_2.11-2.4.1]$ bin/kafka-server-stop.sh stop
[hadoop@hadoop104 kafka_2.11-2.4.1]$ bin/kafka-server-stop.sh stop
3.3 测试
(1)查看当前服务器中的所有topic
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list
(2)创建topic
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --replication-factor 2 --partitions 1 --topic first-topic
选项说明:
–topic 定义topic名
–replication-factor 定义副本数
–partitions 定义分区数
(3)删除topic
需要先停掉producer和consumer,否则会自动创建topic
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --delete --topic first-topic
(4)发送消息
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first-topic
发送内容:
>hello
>hi~
>are you ok?
(5)消费消息
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first-topic
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first-topic
消费者组内的消费者数和topic的分区数的关系?
(6)查看某个Topic的详情
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first-topic
(7)修改分区数
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first-topic --partitions 3
四、监控(kafka-eagle单机模式)
用于监控Kafka的消息堆积、消息延迟等情况。
注意:需要提前准备好MySQL环境,kafka-eagle会将监控数据保存到MySQL中。
4.0 上传并解压kafka-eagle压缩包
注意:压缩包里面还有一个压缩包,需要解压两次
[hadoop@hadoop102 software]$ cd /opt/software/
[hadoop@hadoop102 software]$ tar -zxvf kafka-eagle-bin-1.4.8.tar.gz
[hadoop@hadoop102 software]$ cd kafka-eagle-bin-1.4.8/
[hadoop@hadoop102 kafka-eagle-bin-1.4.8]$ tar -zxvf kafka-eagle-web-1.4.8-bin.tar.gz -C /opt/module/
4.1 修改Kafka集群配置
先关闭Kafka集群
[hadoop@hadoop102 bin]$ vim kafka-server-start.sh
(1)暴露JMX端口
JMX(Java Management Extensions)是一个为应用程序植入管理功能的框架。JMX是一套标准的代理和服务,实际上,用户能够在任何Java应用程序中使用这些代理和服务实现管理。用人话说,就是对外暴露更多数据,方便某些监控之类的插件来使用
(2)调大Kafka内存
默认初始化内存、运行内存为1G,使用kafka-eagle监控,1G内存不够用。需要增加到2G。
修改内容:
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"export JMX_PORT="9999"
fi
(3)分发配置
[hadoop@hadoop102 bin]$ mytools_rsync kafka-server-start.sh
4.2 配置kafka-eagle
4.2.1 修改配置文件
[hadoop@hadoop102 ~]$ cd /opt/module/kafka-eagle-web-1.4.8/conf/
[hadoop@hadoop102 conf]$ vim system-config.properties
(1)配置zk地址
为什么要配置zk的地址,因为Kafka的配置信息存储在了zk中。
修改内容:
kafka.eagle.zk.cluster.alias=cluster1
cluster1.zk.list=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
(2)Kafka Offset的存储地址
kafka-eagle需要监控Kafka的offset,所以需要知道Kafka的offset存储在了哪里,存储位置是在Kafka集群中配置的,Kafka默认将offset存储在了kafka的topic中。
修改内容:
cluster1.kafka.eagle.offset.storage=kafka
(3)配置MySQL地址
修改内容:
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://mall:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=123456
(4)其他配置
# 是否启动监控图表
kafka.eagle.metrics.charts=true
4.2.2 配置环境变量
[hadoop@hadoop102 conf]$ sudo vim /etc/profile.d/my_env.sh
新增内容:
# kafkaEagle
export KE_HOME=/opt/module/kafka-eagle-web-1.4.8
export PATH=$PATH:$KE_HOME/bin
使环境变量生效:
[hadoop@hadoop102 conf]$ source /etc/profile
4.3 启动
4.3.1 启动Kafka集群
见本文3.2内容
4.3.2 启动kafka-eagle
启动前先放开MySQL所在机器的3306端口号,因为kafka-eagle启动后会进行初始化操作,需要在MySQL中创建ke数据库等。如果不放开,kafka-eagle无法访问该机器的3306端口,初始化数据库会失败!
注意:即使是阿里云内网之间均关闭了防火墙也需要放开对应端口号。因为防火墙关注的是ip通信,而不是端口通信。
[hadoop@hadoop102 conf]$ cd /opt/module/kafka-eagle-web-1.4.8/bin
# 给启动文件执行权限
[hadoop@hadoop102 bin]$ chmod 777 ke.sh
[hadoop@hadoop102 bin]$ cd /opt/module/kafka-eagle-web-1.4.8/
[hadoop@hadoop102 kafka-eagle-web-1.4.8]$ bin/ke.sh start
4.3.3 关闭kafka-eagle
[hadoop@hadoop102 kafka-eagle-web-1.4.8]$ bin/ke.sh stop
4.4 测试
安全组放开8048端口
访问:http://hadoop102:8048/ke
Account:admin
Password:123456
相关文章:
大数据基础设施搭建 - Kafka(with ZooKeeper)
文章目录 一、简介二、单机部署2.1 上传压缩包2.2 解压压缩包2.3 修改配置文件(1)配置zookeeper地址(2)修改kafka运行日志(数据)存储路径 2.4 配置环境变量2.5 启动/关闭2.6 测试(1)查看当前服务器中的所有…...
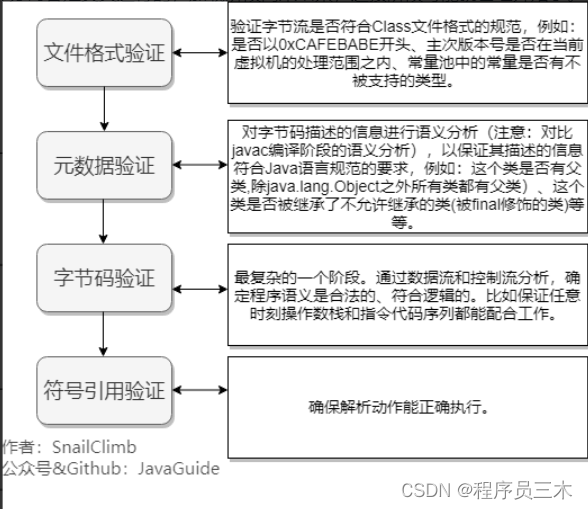
[JVM] 京东一面~说一下Java 类加载过程
系统加载 Class 类型的文件主要三步:加载->连接->初始化。连接过程又可分为三步:验证->准备->解析。 通过全限定名来加载生成 class 对象到内存中,然后进行验证这个 class 文件,包括文件格式校验、元数据验证…...

2023 年 认证杯 小美赛 ABC题 国际大学生数学建模挑战赛 |数学建模完整代码+建模过程全解全析
当大家面临着复杂的数学建模问题时,你是否曾经感到茫然无措?作为2022年美国大学生数学建模比赛的O奖得主,我为大家提供了一套优秀的解题思路,让你轻松应对各种难题。 cs数模团队在认证杯 小美赛前为大家提供了许多资料的内容呀&am…...
N-134基于java实现捕鱼达人游戏
开发工具eclipse,jdk1.8 文档截图: package com.qd.fish;import java.awt.Graphics; import java.io.File; import java.util.ArrayList; import java.util.List;import javax.imageio.ImageIO;public class Fishes {//定义一个集合来管理鱼List<Fish> fish…...
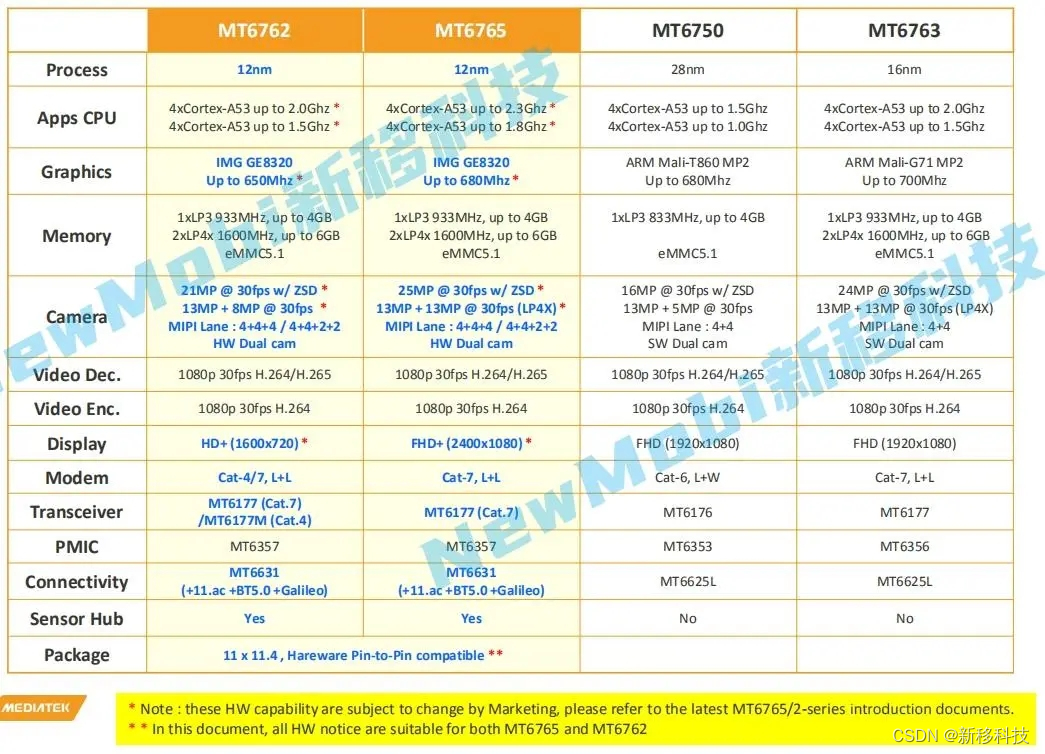
MTK联发科MT6762/MT6763/MT6765安卓核心板参数规格比较
MT6762安卓核心板 MTK6762安卓核心板是一款工业级高性能、可运行 android9.0 操作系统的 4G智能模块。 CPU:4xCortex-A53 up to 2.0Ghz/4xCortex-A53 up to 1.5GhzGraphics:IMG GE8320 Up to 650MhzProcess:12nmMemory:1xLP3 9…...

仿ChatGPT对话前端页面(内含源码)
仿ChatGPT对话前端页面(内含源码) 前言布局样式和Js部分关键点全部源码 前言 本文主要讲解如何做出类似ChatGPT的前端页面。具体我们的效果图是长这样,其中除了时间是动态的之外,其他都是假数据。接下来让我们从布局和样式的角度…...
js粒子效果(一)
效果: 代码: <!doctype html> <html> <head><meta charset"utf-8"><title>HTML5鼠标经过粒子散开动画特效</title><style>html, body {position: absolute;overflow: hidden;margin: 0;padding: 0;width: 100%;height: 1…...

程序员必备工具篇 / 程序员必备基础:Git
前言 掌握 Git 命令是每位程序员必备的基础,之前一直是用 smartGit 工具,直到看到大佬们都是在用 Git 命令操作的,回想一下,发现有些 Git 命令我都忘记了,于是写了这篇博文,复习一下~ https://github.com/whx123/JavaHome 公众号:顺哥轻创 文章目录 Git 是什么?Git …...

MacBook使用指南
一、安装及卸载Windows系统 1、卸载Windows系统 步骤① 点击下侧任务栏中的“启动台”,进入程序坞,点击"其他",选择“启动转换助理” 步骤② 点击“继续”,接着点击“恢复”,即可卸载Windows系统 2、安装Windows系统 …...

数据库的事务的基本特性,事务的隔离级别,事务隔离级别如何在java代码中使用,使用MySQL数据库演示不同隔离级别下的并发问题
文章目录 数据库的事务的基本特性事务的四大特性(ACID)4.1、原子性(Atomicity)4.2、一致性(Consistency)4.3、隔离性(Isolation)4.4、持久性(Durability) 事务的隔离级别5.1、事务不…...
Robust taboo search for the quadratic assignment problem-二次分配问题的鲁棒禁忌搜索
文章目录 摘要关键字结论研究背景1. Introduction 常用基础理论知识2. The quadratic assignment problem3. Taboo search3.1. Moves3.2 Taboo list3.3. Aspiration function3.4. Taboo list size4. Random problems5. Parallel taboo search 研究内容、成果7. Conclusion 潜在…...
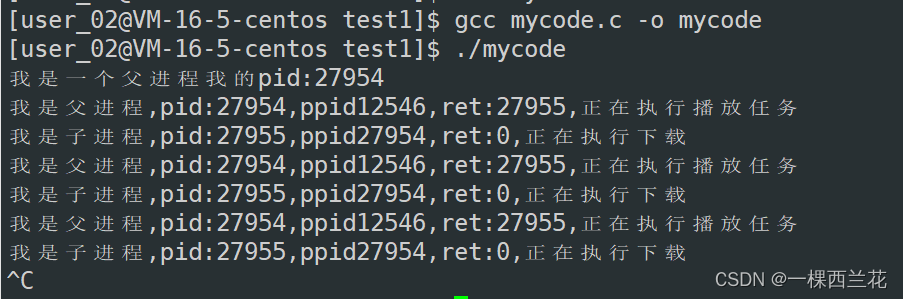
Linux:创建进程 -- fork,到底是什么?
相信大家在初学进程时,对fork函数创建进程一定会有很多的困惑,比如: 1.fork做了什么事情?? 2.为什么fork函数会有两个返回值?3.为什么fork的两个返回值,会给父进程谅回子进程pid,给子进程返回0?4.fork之后:父子进…...

基于SpringBoot+vue的token验证
后端: 1,写一个验证token的拦截器 import com.fasterxml.jackson.databind.ObjectMapper; import com.ffyc.news.model.CommonData; import org.springframework.web.servlet.HandlerInterceptor;import javax.servlet.http.HttpServletRequest; impor…...

Clickhouse设置多磁盘存储策略
设置多磁盘存储 clickhouse安装完成以后,配置了一个默认的存储空间, 这个只能配置一个目录,如果要使用多个磁盘目录,则需要配置磁盘组策略 查看当前的存储策略 select name, path, formatReadableSize(free_space) as free, fo…...
Python开发运维:Django 4.2.7 使用Celery 5.3.5 完成异步和定时任务
目录 一、实验 1.Django使用Celery完成异步和定时任务 二、问题 1. 如何查看Django版本 一、实验 1.Django使用Celery完成异步和定时任务 (1)安装Django (2)新建Django项目 (3)初始框架 (4)urls.py引用视图views from django.contrib import admin from django.urls imp…...

媒体增加日活量的有效策略
随着数字媒体的蓬勃发展,提高日活量成为媒体平台追求的重要目标之一。日活量的增加不仅意味着更广泛的影响力,还能为媒体平台带来更多的商业机会。以下是一些有效的策略,可帮助媒体提高日活量: admaoyan猫眼聚合 内容优质化&#…...

es6新特性总结
1、支持了let和const,为了防止var声明变量带来的变量提升 (1)、存在块级作用域不存在变量提升(考虑暂时性死区) (2)、不允许重复声明(包括普通变量和函数参数)变量提升…...

Spring Boot + hutool 创建海报图片
Spring Boot hutool 创建海报图片 /*** 分享,生成图片* param id* return*/GetMapping("/getShareImg")public void getShareImg(String id,HttpServletResponse response) throws IOException {CouponConsignSaleClassify byId couponConsignSaleClassifyService…...
0002Java程序设计-springboot在线考试系统小程序
文章目录 **摘 要****目录**系统实现开发环境 编程技术交流、源码分享、模板分享、网课分享 企鹅🐧裙:776871563 摘 要 本毕业设计的内容是设计并且实现一个基于springboot的在线考试系统小程序。它是在Windows下,以MYSQL为数据库开发平台&…...
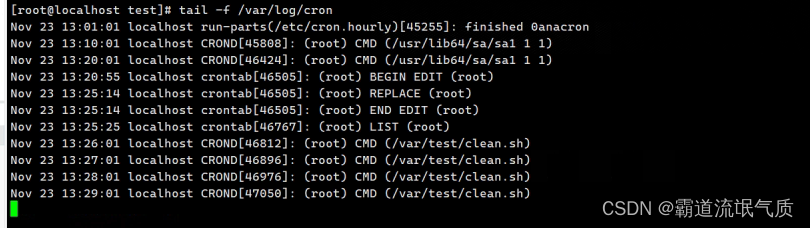
Linux(Centos)上使用crontab实现定时任务(定时执行脚本)
场景 Windows中通过bat定时执行命令和mysqldump实现数据库备份: Windows中通过bat定时执行命令和mysqldump实现数据库备份_mysqldump bat-CSDN博客 上面讲windows中使用bat实现定时任务的方式,如果是在linux上可以通过crontab实现。 cron是服务名称。…...

终极Visual C++运行库全家桶:一站式解决Windows软件运行难题
终极Visual C运行库全家桶:一站式解决Windows软件运行难题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 还在为软件启动失败、游戏无法运行而烦恼吗…...

DDrawCompat:让经典DirectX游戏在现代Windows系统上重获新生
DDrawCompat:让经典DirectX游戏在现代Windows系统上重获新生 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mirrors/dd/…...

Windows多显示器DPI独立控制:绕过系统限制的底层API实践
Windows多显示器DPI独立控制:绕过系统限制的底层API实践 【免费下载链接】SetDPI 项目地址: https://gitcode.com/gh_mirrors/se/SetDPI 在Windows多显示器工作环境中,不同分辨率的显示器需要独立的DPI缩放设置,但系统界面却将这一功…...

给爸妈手机装个Skype吧:一个账号搞定跨境/长途通话,操作比微信还简单
给父母手机装Skype:跨境通话的极简解决方案 当远隔重洋的视频通话成为日常,我们却常常忽略了一个更基础的需求——清晰稳定的语音沟通。许多海外游子发现,教会父母使用微信视频后,老人依然会下意识按下红色挂断键,只因…...

麒麟KYLINOS软件安装全攻略:从新手到高手的五种进阶路径
1. 初识麒麟KYLINOS:从Windows/macOS迁移者的第一课 第一次打开麒麟KYLINOS的桌面环境,那种既熟悉又陌生的感觉让我想起十年前第一次用Linux的场景。作为从Windows转战过来的用户,最迫切的问题就是:软件怎么装?在Windo…...

终极怪物猎人世界叠加层工具:HunterPie完整使用指南与实战配置
终极怪物猎人世界叠加层工具:HunterPie完整使用指南与实战配置 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_mirrors/hu/Hunt…...
)
保姆级教程:用ROS Noetic + Gazebo从零搭建一个能自主导航的仿真机器人(附避坑指南)
ROS Noetic Gazebo仿真机器人自主导航全流程实战指南 从零开始的机器人导航系统搭建 在机器人技术快速发展的今天,自主导航能力已成为智能机器人的核心功能之一。ROS(Robot Operating System)作为机器人开发的事实标准平台,配合G…...

oterm 入门指南:如何快速上手基于终端的 Ollama 客户端
oterm 入门指南:如何快速上手基于终端的 Ollama 客户端 【免费下载链接】oterm the terminal client for Ollama 项目地址: https://gitcode.com/gh_mirrors/ot/oterm oterm 是一款功能强大的终端客户端,专为 Ollama 设计,让你在命令行…...

抖音无水印下载神器:douyin-downloader 终极实战教程
抖音无水印下载神器:douyin-downloader 终极实战教程 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

如何通过PDown百度网盘高速下载器免费突破限速:终极指南
如何通过PDown百度网盘高速下载器免费突破限速:终极指南 【免费下载链接】pdown 百度网盘下载器,2020百度网盘高速下载 项目地址: https://gitcode.com/gh_mirrors/pd/pdown PDown是一款完全免费的百度网盘高速下载工具,无需登录账号即…...