【2023 云栖】阿里云刘一鸣:Data+AI 时代大数据平台建设的思考与发布
云布道师
本文根据 2023 云栖大会演讲实录整理而成,演讲信息如下:
演讲人:刘一鸣 | 阿里云自研大数据产品负责人
演讲主题:Data+AI 时代大数据平台应该如何建设
今天分享的主题是 Data+AI 时代大数据平台应该如何建设,这个话题既是对我们过去一年工作的反思和总结,同时也是希望通过这个反思和总结,不管大家是否使用阿里云的平台和技术,在未来大数据平台的选型、运维、创新上都可以有一些启发,同时也会思考未来大数据人的角色、工作方式是否有一些新的变化。
阿里云大数据的核心是两款分布式计算引擎,在 ODPS(Open Data Processing Platform)品牌之下,今天的分享也会更多围绕 ODPS 的两个核心引擎来讲(面向批量数据加工和海量存储的 MaxCompute、面向实时数仓以及交互式分析场景的Hologres)。下面进入正题,希望跟大家分享我们过去做平台时候的反思,什么能力是关键能力,以及今年我们做了哪些能力的提升。
降本能力:灵活的付费模式驱动大数据成本的显著下降
降本能力是每个大数据平台的核心能力,特别是作为公共云上的服务方,我们不希望大家使用云上的大数据平台是一个成本的黑洞,越用越贵,每年老板说钱花哪里去还说不清楚,我们希望不仅给用户提供一个成本费用说得清楚用得明白的平台,也希望给用户提供一个通过正确使用产品可以不断降低单位拥有成本的平台。降本从不意味着要使用更便宜的规格,更少的资源,这会潜在牺牲平台的服务质量,不是正确的降本姿势,低价往往质量缺少保障,最后会收获更低质量的服务,更低质量的研发投入,最后导致平台无法维系。
合理的降本方式首先是选择合适的采购策略、付费策略,选择一个合适的技术。以MaxCompute 为例,平台提供多种付费方式,从比较经典的预付费或者叫包年包月,到用得最多的后付费或者叫按量付费的模型。预付费对预算控制更精确,费用提前说清楚,但资源使用受限制,无法满足临时性需求,也会产生闲置资源的空闲浪费。按量付费模型根据实际业务规模产生费用,无需提前做容量规划,但实际费用容易超出预算控制。现在我们希望把两种模式做一些结合。
我们看到大部分数据加工作业都具备一定的时间规律,夜间往往高峰期,早上上班看到计算结果,白天相对水位是低峰期,这里可以利用 MaxCompute 的分时弹性能力,日常低水位运行,高峰期弹性出来额外资源。分时弹性去年上线的,今年通过对库存管理的优化,实现库存效率上的提升,在 9 月 20 日开始 MaxCompute 弹性部分的 CU 单价直接降低 50%。如果一天有 8h 作业跑不满的情况,采用分时作业的方式一定是降本的,希望每个用户可以根据大家实际使用场景去选择分时策略。
原理类似 ECS 上的 Spot Instance,MaxCompute 今年推出了闲时作业,也通常叫做 SpotJob,定价直接是按量付费定价的三分之一,闲时作业是把大数据集群的闲置资源服务出来,不一定保障每天运行的时候都能得到一样的资源,执行一样快,在集群繁忙时会有更多的作业等待时间,但对于延时不敏感的作业,如历史数据的导入、日常开发调试作业的场景,通过使用闲时作业可以有效降本 66%。
分时弹性既能满足弹性,也能满足预算的管理,那么该怎么设置是最优的?MaxCompute 发布了成本优化器,帮助用户分析过去 30 天所有作业的资源分布特征,展示出高峰期和低谷期,给出弹性策略应该怎么设计的建议。在弹性的基础上,我们给作业增加了一个关键的约束条件叫基线,基线之前的作业需要足够的资源保障,让结果准时计算出来,基线之后的作业可以跑慢一些,更节省资源和费用,这样就区分了作业的优先级和重要性。绝大部分用户使用成本优化器之后,通常有 20% 以上成本降低,建议大家可以尽快采用起来。
接下来我们谈谈存储如何降本。数据在实际使用时会分特征,有些数据是高频访问,数据的重要性有可能更高,有些数据是低频访问数据,一个月就读取一两次,有的数据是审计要求,不可以删除,一年不一定访问一次。数据有价值分配,那么我们的数据成本是否也应该有分层设计呢?当然。MaxCompute 为不同访问特征,不同价值数据提供不同的存储能力,分层存储提供了分层的单价。通过分层存储的方式可以看到一些低频访问的数据,长期访问的数据成本可以降到以前的三分之一。
计算和存储可以通过平台的使用策略来节省成本,其实还可以通过存储技术的创新实现进一步的降本。JSON 是互联网上使用非常广泛的数据结构,半结构化,查询灵活,存储也方便,Schema 可以随时调整,但过去 JSON 如果用字符串去存储的时候,哪怕仅仅访问一个字节,也需要把几兆字节全部解析出来,对计算和IO都是极大的浪费。另一种方案是 JSON 数据落库前,提前进行 JSON 结构的打宽,需要大量的加工作业,也是对计算资源的浪费。
如何有效提升 JSON 数据类型的存储和访问效率成为大数据平台的关键能力,今年包括 MaxCompute 和 Hologres,都提供 JSON 原生化的管理能力,包括元数据支持和存储列式压缩,把半结构化作为一级处理类型来支持,在用户实践中,绝大部分用户的 JSON 存储成本会降到以前的五分之一,而且查询会变得更快。
轻运维能力:Serverless 变革大数据运维模式
云上大数据平台,应该提供运维足够简单易用,把脏活累活帮助使用者运维掉,帮助大数据工程师实现角色升级,从过去相对被动每天考虑系统平台的稳定性、扩展性、资源如何分配、备份、容灾、升级、修 bug 这些脏活累活中解脱出来,转变成数据的分析师,变成AI专家,变成领域专家,而不是做重复的运维工作。
我们认为 Serverless 架构是解决运维问题的关键,那么如何做 Serverless 架构呢?从大数据架构上讲,通常我们分三种:1.Shared-Nothing 架构,存算一体。通过节点之间的横向扩展,实现计算力和存储能力的提升。2.Shared-Everything,计算存储全部解耦开来,所有的资源都可以共享。3. Shared-Data,Data 部分是共享,计算部分隔离开来,提供更好的隔离能力。每个技术会选择不同架构。
MaxCompute 选择 Shared-Everything,对平台侧的隔离技术实现要求很高,对运维侧、调度侧要求更高,所有计算资源、存储资源是共享在统一的公共集群里。Hologres 选择 Shared-Data 架构,这个系统需要更多考虑在线服务场景下资源的隔离和稳定性,所以不同系统选择不同架构。
这个架构背后我们会把整个集群当做一个统一的计算资源来管理。对用户来说最大价值是,不仅是使用成本的降低,不需要提前做容量规划,更重要的是,不需要处理复杂的升级运维,让用户可以实现零停机的方式实现版本的迭代,这都是 Serverless 架构创造的价值,平台侧希望把脏活累活,包括升级、备份、灾备、弹性这些事情通过架构的方式把它解决,这也是 Serverless 背后核心的理念。
大家过去讲 Serverless 更多讲资源上省钱,只为使用的资源付费,而我相信Serverless 更多是把运维方式转变,让工程师更聚焦到价值的创造上。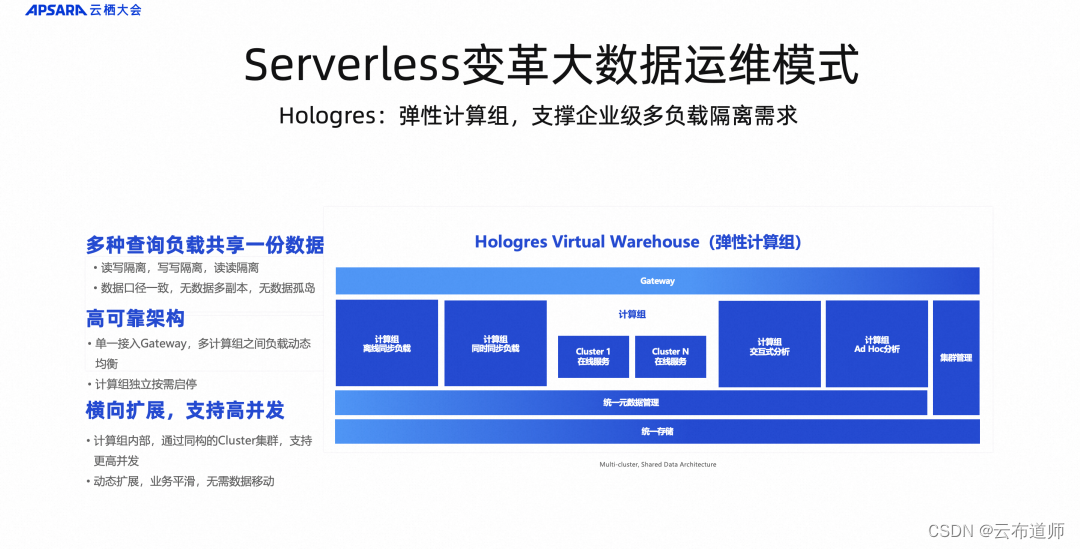
Hologres 在 Serverless 架构上一直演进,今年提出了弹性计算组的概念,这个计算组概念背后是共享数据,共享接入层,但在计算节点上做了资源切分,当不同业务团队使用同一份数据的时候,每个团队可以为自己的使用场景去弹性分配资源,同时保障数据的一致性,支持实时写入,实时查询,这是在 Hologres 上做的创新。
开放能力:湖仓一体与开放性
在谈到大数据平台的开放性时,更多讲 Open Storage + Open Format,今天阿里的大数据平台希望做到更多一层。云计算对技术的开放性要求会更高,一方面云厂商不希望自己变成绑架用户的角色,MaxCompute 也不希望大家使用之后就被绑架在平台上,不可以切换。另一方面云平台上不同技术之间交互的强度、密度是远大于线下的,技术之间需要分钟级部署,分钟级打通,用户对技术的交互性要求很高,我们希望把开放性做得很彻底,我们不希望把创新只放在自己手里,我们希望把创新交还给用户。
首先,阿里云的大数据完全拥抱 Open Storage + Open Format,提供了湖仓一体的解决方案,为用户提供接近原生的元数据管理和数据读写体验。对于什么是湖仓一体,行业内有两个思路,一个是在湖上长出一个仓,把湖变成仓。典型特点是把湖上的数据结构提供更好的更新能力,接近数据库的开发体验。另一个方式从仓的管理能力拓展外表能力,实现湖上半结构化、非结构化数据以元数据方式管理起来,相当于仓去管理湖,这也是湖仓一体的形态。MaxCompute 是第二种形态,用仓去管湖,把存在 OSS 上的 Hudi 格式、Delta Lake 等格式,包括今年阿里自己创新的 Paimon 格式,都可以在 MaxCompute 和 Hologres 中作为外表直接访问。同时也做了一些创新,把 OSS上 的非结构化文件定义为抽象的目录表,这样在数仓里可以用更加精细化的安全管控方式去做授权,哪些用户可以访问哪些文件,怎么访问,包括审计都可以记录下来。
湖仓一体最关键是元数据的管理,数据不管存在仓上、湖上,需要有一个统一的视图可以看到所有的元数据,数据被谁定义,数据怎么解析,这是湖仓一体核心的概念,而并不是一定是一个系统还是两个系统。
MaxCompute 今年在开放性上有很大的变化。大家过去认为仓的理念是数据计算都在这儿,但我们今天希望把 MaxCompute 存储作为独立的产品形态对外提供服务,把Storage这一层提供产品化的能力,提供 Storage API,支持高吞吐、高性能的原生 IO 接口。不管使用机器学习的 PAI 平台还是使用 Spark、Presto,都可以像MaxCompute 原生的 SQL 引擎一样去访问仓里的数据,我们希望把自研大数据平台的数据开放出去,支持用户使用第三方引擎持续创新。
智能优化能力:AI 加持的智能数仓
过去做优化的时候很依赖于 DBA 同学对一个数仓技术原理的理解,在云的时代,用户把数据托管到云平台上,云平台就有很大责任帮助用户做好优化这件事。我们希望从过去基于经验的运维向智能化运维前进。
比如 MaxCompute 通过物化视图把公共的 SQL 计算子集推荐出来,实现资源的复用,这是一种空间换时间非常有效的方法。经过一年多时间的迭代,在推荐效率上已经做了很大的改进,绝大部分推荐出来的物化视图质量都是很高,可以做到成本的节省和效率上的提升。
大数据成为 AI 的基础设施
今年 AI 很热,很多了不起的创新,但其实 AI 的创新中,大数据也扮演了关键的基础设施角色。同时我们也希望用了云上大数据平台的用户,不需要再做那些低效繁重的运维工作,而是更多做一些 AI 上的场景和应用创新。我们也提出了大数据 AI 一体化,事实上大数据 AI 是各有分工,大数据为 AI 提供数据的支撑,这包括大数据平台要做好规模数据的处理,提供分布式计算框架,提供科学计算的一站式开发环境,其次机器学习平台也会为大数据平台提供优化的算法、优化的模型。
在过去 SQL 的基础上,我们认为 Python 也应该成为 MaxCompute 平台的一级开发语言。MaxCompute 全新发布,One Env+One Data+One Code,这背后核心就是提供一个 Python 的运行环境,一个Notebook的交互式开发体验,让有 SQL 基础的同学,有 Python 经验的同学,需要利用 Python Library 进行数据处理的场景,可以在统一的开发环境下,实现高效率的开发和调试,实现 Python 和coMaxCompute 数据的原生打通。
全面升级 DataFrame 能力,发布分布式计算框架 MaxFrame,100% 兼容 Pandas 等数据处理接口,通过一行代码即可将原生 Pandas 自动转为 MaxFrame 分布式计算,打通数据管理、大规模数据分析、处理到 ML 开发全流程,打破大数据及 AI 开发使用边界,大大提高开发效率。
最后讲下向量数据库,Hologres 内置达摩院向量引擎 Proxima,支持高性能、实时化的向量检索服务。使用 SQL 接口可以访问向量数据,在原有交互式分析场景下帮助大家更好使用 AI 场景。
相关文章:
【2023 云栖】阿里云刘一鸣:Data+AI 时代大数据平台建设的思考与发布
云布道师 本文根据 2023 云栖大会演讲实录整理而成,演讲信息如下: 演讲人:刘一鸣 | 阿里云自研大数据产品负责人 演讲主题:DataAI 时代大数据平台应该如何建设 今天分享的主题是 DataAI 时代大数据平台应该如何建设࿰…...

【DP】mobiusp正在创作乐曲
输入样例1: 5 2 1 7 7 1 3 输出样例1: 2 输入样例2: 10 3 2 5 6 4 4 5 7 3 5 6 输出样例2: 1 #include<iostream> #include<cstring> #include<algorithm> #include<vector> using namespace std; typede…...
docker国内镜像加速
创建或修改 /etc/docker/daemon.json 文件,修改为如下形式 {"registry-mirrors": ["https://registry.docker-cn.com","http://hub-mirror.c.163.com","https://docker.mirrors.ustc.edu.cn"] } Docker中国区官方镜像htt…...

Calling PeopleTools APIs 调用PeopleTools API
Calling PeopleTools APIs 调用PeopleTools API You can call all of the PeopleTools APIs from an Application Engine program. When using APIs, remember that: 您可以从应用程序引擎程序调用所有PeopleTools API。使用API时,请记住: All the PeopleTools …...

强化学习,快速入门与基于python实现一个简单例子(可直接运行)
文章目录 一、什么是“强化学习”二、强化学习包括的组成部分二、Q-Learning算法三、迷宫-强化学习-Q-Learning算法的实现全部代码(复制可用)可用状态空间检查是否超出边界epsilon 的含义更新方程 总结 一、什么是“强化学习” 本文要记录的大概内容&am…...
【手写实现一个简单版的Dubbo,深刻理解RPC框架的底层实现原理】
手写实现一个简单版的Dubbo,深刻理解RPC框架的底层实现原理 RPC框架简介了解Dubbo的实现原理服务暴露服务引入服务调用 手写实现一个简单版的Dubbo服务暴露ServiceBeanProxyFactory#getInvokerProtocol#exportRegistryProtocol#export 服务引入RegistryProto#referD…...
计数问题+约瑟夫问题(map)
目录 一、计数问题 二、约瑟夫问题 一、计数问题 #include<iostream> #include<map> using namespace std; int main() {int n,x;cin>>n>>x;map<int,int>m;for(int i1;i<n;i){if(i>1 && i<10){m[i];}else{int temp i;while (…...

Maven聚合项目发布至私服指定模块
无论是从事框架开发工作还是公共服务模块开发,为了解决通用性问题,常常需要发布一些依赖组件至maven私服。然而通常我们得maven工程都是由多个模块组成得聚合工程(一个父工程下有多个模块)。 这个时候可能会面临两个窘境…...
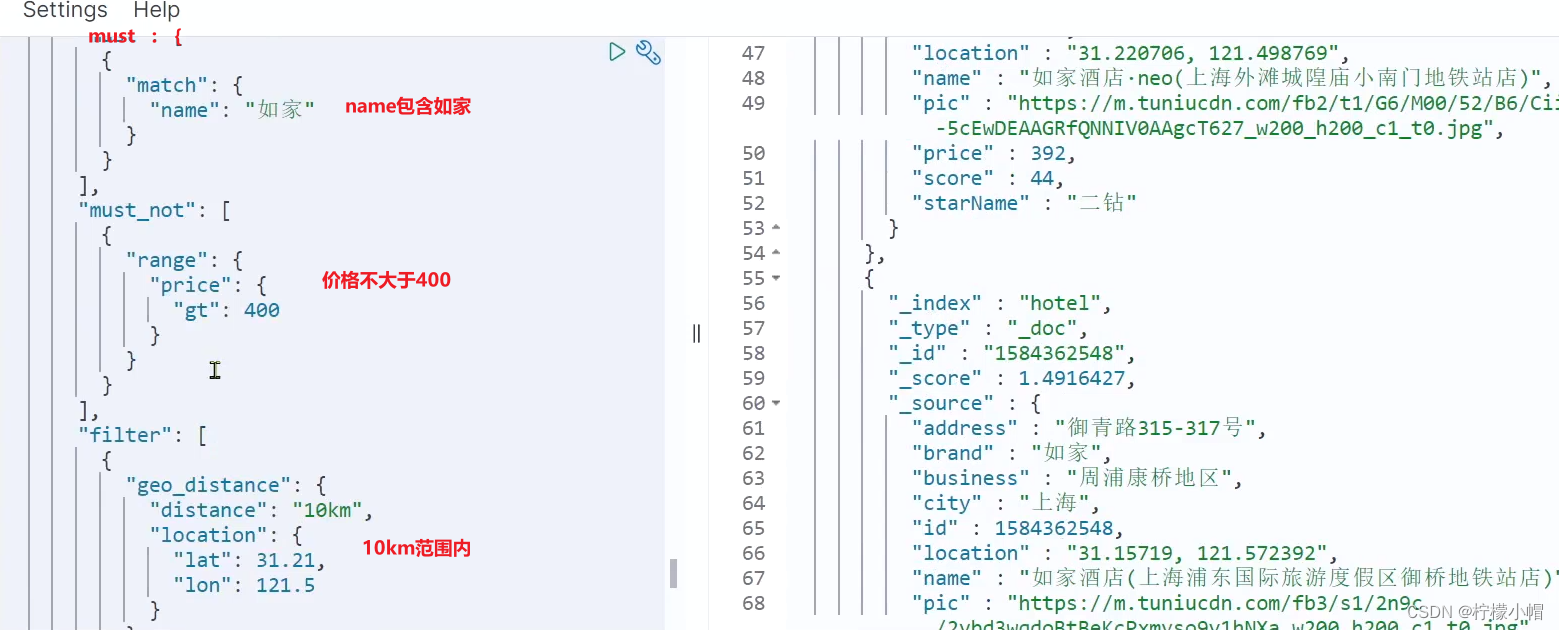
SpringCloud 微服务全栈体系(十六)
第十一章 分布式搜索引擎 elasticsearch 六、DSL 查询文档 elasticsearch 的查询依然是基于 JSON 风格的 DSL 来实现的。 1. DSL 查询分类 Elasticsearch 提供了基于 JSON 的 DSL(Domain Specific Language)来定义查询。常见的查询类型包括࿱…...

「快学Docker」监控和日志记录容器的健康和性能
「快学Docker」监控和日志记录容器的健康和性能 1. 容器健康状态监控2. 性能监控3. 日志记录几种采集架构图 4. 监控工具和平台cAdvisor(Container Advisor)PrometheusGrafana 5. 自动化运维 1. 容器健康状态监控 方法1:需要实时监测容器的运…...

midjourney过时了?如何使用基于LCM的绘图技术画出你心中的画卷。
生成 AI 艺术在近年来迅速发展,吸引了数百万用户。然而,传统的生成 AI 艺术需要等待几秒钟或几分钟才能生成,这对于快节奏的现代社会来说并不理想。 近日,中国清华大学和 AI 代码共享平台 HuggingFace 联合开发了一项新的机器学习…...

【代码随想录】算法训练计划28
回溯 1、子集 题目: 给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 输入:nums [1,2,3] 输出:[[],[1],[2…...

量化交易:筹码理论的探索-筹码分布计算的实现
前言 很多朋友习惯了同花顺、大智慧等看盘软件,经常问到筹码分布如何计算。 说起来筹码分布的理论在庄股时代堪称是一个划时代产品,虽然历经level2数据、资金流统计、拆单算法与反拆单算法等新型技术的变革,庄股时代也逐渐淡出市场…...

常用Redis的键命令参考
一、DEL DEL key [key …] 删除给定的一个或多个 key 。 不存在的 key 会被忽略。 #删除单个键127.0.0.1:6379> set name zhangsan OK 127.0.0.1:6379> del name (integer) 1# 删除一个不存在的 key, 失败,没有 key 被删除127.0.0.1:6379> E…...

Lombok @With 的纯弊端及如何避免
由于是第一篇写关于 Lombok 的日志,所以有些不情愿去开门见山直接触及 With, 而要先提一提本人对 Lombok 的接触过程。 两三年之前写 Java 代码一直都是全手工打造。一个数据类,所有必须的 setter/getter, toString, hashcode() 等全体现在源代码中&…...
无重复字符的最长字串)
C语言每日一题(38)无重复字符的最长字串
力扣 3 无重复字符的最长字串 题目描述 给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1: 输入: s "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。示例 2: 输入: s…...
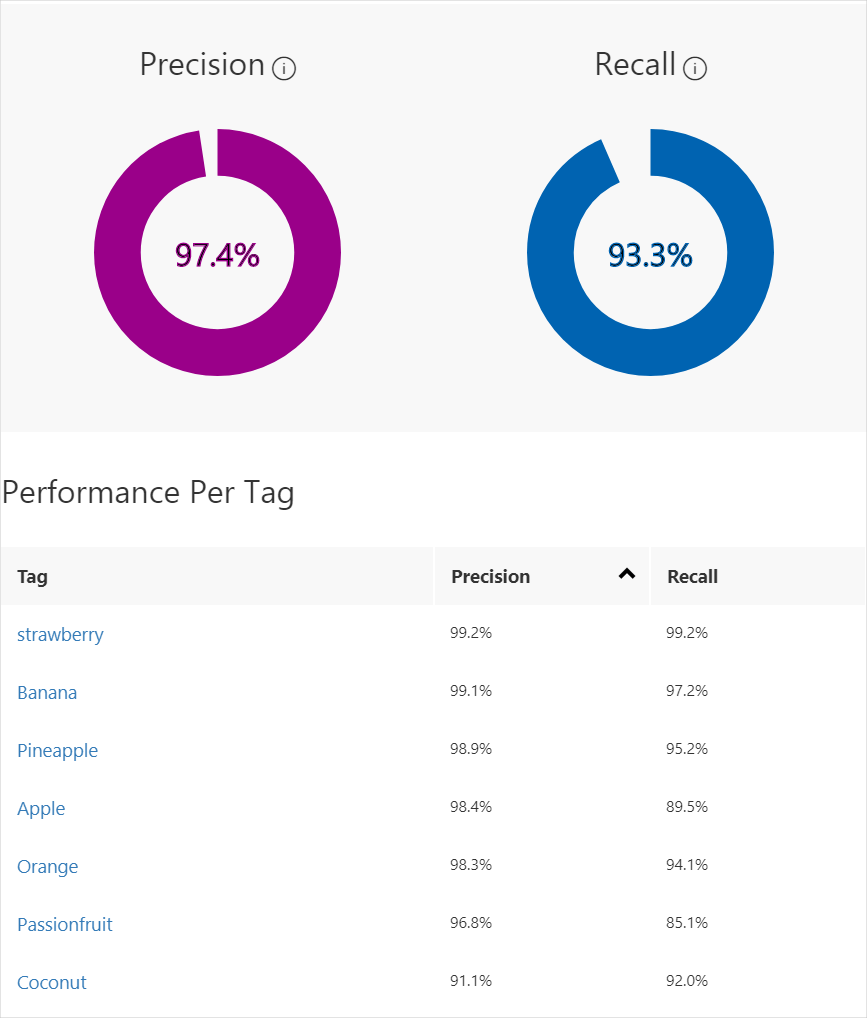
Azure Machine Learning - Azure可视化图像分类操作实战
目录 一、数据准备二、创建自定义视觉资源三、创建新项目四、选择训练图像五、上传和标记图像六、训练分类器七、评估分类器概率阈值 八、管理训练迭代 在本文中,你将了解如何使用Azure可视化页面创建图像分类模型。 生成模型后,可以使用新图像测试该模型…...

PaddleOCR学习笔记
Paddle 功能特性 PP-OCR系列模型列表 https://github.com/PaddlePaddle/PaddleOCR#%EF%B8%8F-pp-ocr%E7%B3%BB%E5%88%97%E6%A8%A1%E5%9E%8B%E5%88%97%E8%A1%A8%E6%9B%B4%E6%96%B0%E4%B8%AD PP-OCR系列模型列表(V4,2023年8月1日更新) 配置文…...
安卓用SQLite数据库存储数据
什么是SQLite? SQLite是安卓中的轻量级内置数据库,不需要设置用户名和密码就可以使用。资源占用较少,运算速度也比较快。 SQLite支持:null(空)、integer(整形)、real(小…...
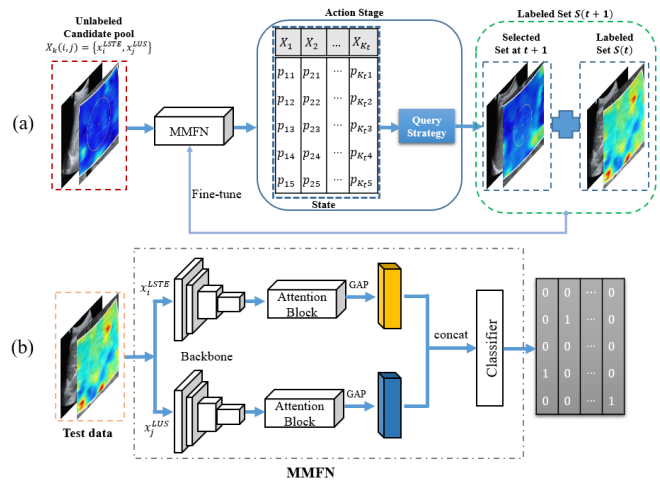
MMFN-AL
MMFN means ‘multi-modal fusion network’ 辅助信息 作者未提供代码...

XML 与 CSS:构建现代网页的关键技术
XML 与 CSS:构建现代网页的关键技术 引言 在当今的互联网时代,网页设计已经远远超出了简单的文字和图片展示。随着技术的不断发展,XML(可扩展标记语言)和CSS(层叠样式表)成为了构建现代网页不可或缺的技术。本文将深入探讨XML和CSS的基本概念、应用场景以及它们如何协…...

平衡二叉树的奥秘:AVLTree高效实现解析
平衡二叉树(AVLTree)平衡二叉树(AVLTree)是一种自平衡二叉搜索树,由 Adelson-Velsky 和 Landis 于 1962 年提出。它通过维护每个节点的平衡因子(定义为左子树高度减去右子树高度)来确保树的高度…...

认知几何学:思维的几何革命与跨学科价值研究
认知几何学:思维的几何革命与跨学科价值研究作者:方见华 单位:世毫九实验室 引言 在人类认知研究的漫长历程中,从莱布尼兹1679年提出"思维几何学"设想以来,认知科学经历了符号主义、联结主义、具身认知等多个…...

3分钟实战指南:高效解决网易云音乐NCM格式播放难题
3分钟实战指南:高效解决网易云音乐NCM格式播放难题 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM加密格式文件无法在其他设备播放而烦恼吗?ncmdump是一款专为解决NCM格式兼容性问…...

别再死记硬背欧拉公式了!用Python可视化平面图,5分钟搞懂n-m+r=2
用Python可视化平面图:5分钟玩转欧拉公式的几何奥秘 第一次接触欧拉公式时,那个简洁的n-mr2让我既惊叹又困惑——为什么节点、边和面之间会存在如此精确的数学关系?直到我用代码亲手绘制出各种平面图,看着程序自动计算出的数值完…...

从Razor页面到Blazor组件:深入聊聊C#三元运算符在前端渲染里的妙用
从Razor页面到Blazor组件:深入聊聊C#三元运算符在前端渲染里的妙用 在ASP.NET Core的Web开发中,动态UI渲染一直是开发者需要频繁处理的场景。传统的条件渲染方式如if指令虽然功能强大,但在处理简单条件判断时往往显得冗长。C#的三元运算符&am…...

2026年降AI工具免费版和付费版区别:哪些场景下付费版才值得买
2026年降AI工具免费版和付费版区别:哪些场景下付费版才值得买 研究生群里聊起AI率的问题,发现十个人里起码六七个都在用工具降。主流的选择其实就那几款,关键是选对了能省很多麻烦。 综合价格和效果,我主推嘎嘎降AI(…...

2025届必备的六大AI科研工具横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 此工具乃是借助先进的深度学习跟自然语言处理技术精雕细琢造就出来的。在用户输入主题之后&a…...

AGI让机器人真正“理解”指令,还是只是更高级的拟人幻觉?SITS2026现场实测结果颠覆认知
第一章:AGI让机器人真正“理解”指令,还是只是更高级的拟人幻觉?SITS2026现场实测结果颠覆认知 2026奇点智能技术大会(https://ml-summit.org) 在SITS2026主会场B3展台,我们对三款宣称搭载“类脑AGI推理引擎”的服务机器人&…...

如何用ModAssistant快速解决Beat Saber模组安装的3大痛点
如何用ModAssistant快速解决Beat Saber模组安装的3大痛点 【免费下载链接】ModAssistant Simple Beat Saber Mod Installer 项目地址: https://gitcode.com/gh_mirrors/mo/ModAssistant 你是否曾因Beat Saber模组安装的复杂依赖关系而头痛?是否遇到过版本冲突…...