NLP实践——LLM生成过程中防止重复循环
NLP实践——LLM生成过程中防止重复
- 1. 准备工作
- 2. 问题分析
- 3. 创建processor
- 3.1 防止重复生成的processor
- 3.2 防止数字无规则循环的processor
- 4. 使用
本文介绍如何使用LogitsProcessor避免大模型在生成过程中出现重复的问题。
1. 准备工作
首先实例化一个大模型,以GLM2为例:
import re
import os
import json
import random
from typing import *
from copy import deepcopyimport torch
from transformers import AutoModel, AutoTokenizer, AutoModelForCausalLM
from transformers.generation.logits_process import LogitsProcessor, LogitsProcessorList
from transformers.generation.stopping_criteria import StoppingCriteriaList, MaxNewTokensCriteria, StoppingCriteria
创建模型:
tokenizer = AutoTokenizer.from_pretrained(".../ChatGLM2/", trust_remote_code=True)
model = AutoModel.from_pretrained(".../ChatGLM2/", trust_remote_code=True).half()
model.to('cuda:0')
2. 问题分析
接下来思考一下,如何防止模型不停的重复呢?重复分为几种情况,一个字符循环出现,或者多个字符循环出现,例如:
'abcdeeeeee'
'abcdededede'
从生成的过程来考虑,防止模型生成重复的内容,第一步自然是要判断模型陷入了重复,第二步就是打断它重复的过程,也就是将重复的token,在当前step生成的时候,将其概率设置为-inf,那么重复的过程自然就停止了。
3. 创建processor
3.1 防止重复生成的processor
先来解决如何判定重复。这里直接去leetcode上找一个题,获取一个字符串中最大的重复片段,解法如下:
def longest_dup_substring(s: str) -> str:# 生成两个进制a1, a2 = random.randint(26, 100), random.randint(26, 100)# 生成两个模mod1, mod2 = random.randint(10**9+7, 2**31-1), random.randint(10**9+7, 2**31-1)n = len(s)# 先对所有字符进行编码arr = [ord(c)-ord('a') for c in s]# 二分查找的范围是[1, n-1]l, r = 1, n-1length, start = 0, -1while l <= r:m = l + (r - l + 1) // 2idx = check(arr, m, a1, a2, mod1, mod2)# 有重复子串,移动左边界if idx != -1:l = m + 1length = mstart = idx# 无重复子串,移动右边界else:r = m - 1return s[start:start+length] if start != -1 else ""def check(arr, m, a1, a2, mod1, mod2):n = len(arr)aL1, aL2 = pow(a1, m, mod1), pow(a2, m, mod2)h1, h2 = 0, 0for i in range(m):h1 = (h1 * a1 + arr[i]) % mod1h2 = (h2 * a2 + arr[i]) % mod2# 存储一个编码组合是否出现过seen = {(h1, h2)}for start in range(1, n - m + 1):h1 = (h1 * a1 - arr[start - 1] * aL1 + arr[start + m - 1]) % mod1h2 = (h2 * a2 - arr[start - 1] * aL2 + arr[start + m - 1]) % mod2# 如果重复,则返回重复串的起点if (h1, h2) in seen:return startseen.add((h1, h2))# 没有重复,则返回-1return -1
效果如下:
longestDupSubstring('埃尔多安经济学可以重振经济,土耳其土耳其')
# '土耳其'
那么我们就可以写一个processor,在每一个step即将生成的时候,判定一下,是否之前已经生成的结果中,出现了重复。以及,如果出现了重复,则禁止重复部分的第一个token(例如上面例子中,土耳其的土字),在当前step被生成。
针对实际使用中由这个processor引发的一些其他的问题,我又对这个processor增加了一点规则限制,一个比较好用的版本如下。
其中的参数threshold是判断重复多少的情况算作循环,例如将threshold设置为10,那么如果重复部分的长度是3,重复了3次,3×3=9,则不被判定为陷入了循环,而如果重复了4次,3×4=12,则被判定为循环,此时processor将发挥效果了。
class ForbidDuplicationProcessor(LogitsProcessor):"""防止生成的内容陷入循环。当循环内容与循环次数之乘积大于指定次数则在生成下一个token时将循环内容的第一个token概率设置为0---------------ver: 2023-08-17by: changhongyu"""def __init__(self, tokenizer, threshold: int = 10):self.tokenizer = tokenizerself.threshold = thresholddef __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:current_sequence = self.tokenizer.decode(input_ids[0][current_token_len: ])current_dup_str = longest_dup_substring(current_sequence)if len(current_dup_str):# 如果存在重复子序列,则根据其长度与重复次数判断是否禁止循环if len(current_dup_str) > 1 or (len(current_dup_str) == 1 and current_dup_str * self.threshold in current_sequence):if len(current_dup_str) * current_sequence.count(current_dup_str) >= self.threshold:token_ids = self.tokenizer.encode(current_dup_str)# 获取截止目前的上一个tokenlast_token = input_ids[0][-1].detach().cpu().numpy().tolist()if len(token_ids) and last_token == token_ids[-1]:# 如果截止目前的上一个token,与重复部分的最后一个token一致# 说明即将触发重复, 先把重复部分的第一个token禁掉scores[:, token_ids[0]] = 0# 然后按出现比率判断是否重复部分内还有其他重复for token_id in token_ids:if token_ids.count(token_id) * len(token_ids) > 1.2:scores[:, token_id] = 0return scores
需要注意的是,为了获取当前的序列已经生成的长度,需要在processor的外部,也就是与model.generate同级的结构处,定义一个全局变量current_token_len。
global current_token_len
3.2 防止数字无规则循环的processor
出了上述的情况,还有一种常见的循环,无法利用上面的规则解决,即数字无规则循环的情况。针对这个场景,创建另一个processor,只要连续出现的数字出现次数,大于一定的阈值,则禁止当前step再次生成数字。
class MaxConsecutiveProcessor(LogitsProcessor):"""给定一个集合,集合中的字符最多连续若干次下一次生成时不能再出现该集合中的字符---------------ver: 2023-08-17by: changhongyu---------------修复bugver: 2023-09-11"""def __init__(self, consecutive_token_ids, max_num: int = 10):self.consecutive_token_ids = consecutive_token_idsself.max_num = max_numdef __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:input_ids_list = input_ids.squeeze(0).detach().cpu().numpy().tolist()cur_num = 0for token in input_ids_list[::-1]:if token in self.consecutive_token_ids:cur_num += 1else:breakif cur_num >= self.max_num:# 如果连续次数超过阈值,那集合中的所有token在下一个step都不可以再出现for token_id in self.consecutive_token_ids:scores[..., token_id] = 0return scores
4. 使用
使用方法非常简单,首先创建processor容器。对processor不熟悉的同学,可以去看之前的文章,有非常详细的介绍。
logits_processor = LogitsProcessorList()
然后对于ChatGLM而言,需要先添加其默认的processor:
logits_processor.append(InvalidScoreLogitsProcessor())
接下来,再添加防止陷入循环的两个processor:
number_tokens = [str(i) for i in range(10)] + ['.', '-']
number_token_ids = [tokenizer.convert_tokens_to_ids(tok) for tok in number_tokens]
logits_processor.append(ForbidDuplicationProcessor(tokenizer))
logits_processor.append(MaxConsecutiveProcessor(number_token_ids))
最后在调用generate的时候,把logits_processor作为参数传进去就可以了。
以上便是使用logits_processor来防止大模型在生成过程中陷入循环的方法。经过我的反复调整,基本可以覆盖大多数情景,如果在使用中遇到了bug,也欢迎指出。
相关文章:

NLP实践——LLM生成过程中防止重复循环
NLP实践——LLM生成过程中防止重复 1. 准备工作2. 问题分析3. 创建processor3.1 防止重复生成的processor3.2 防止数字无规则循环的processor 4. 使用 本文介绍如何使用LogitsProcessor避免大模型在生成过程中出现重复的问题。 1. 准备工作 首先实例化一个大模型,…...

用苹果签名免费获取Xcode
使用苹果企业签名免费获取Xcode: 打开Xcode。连接iOS设备到Mac。选择Window→Devices and Simulators。选择该设备。将IPA文件拖到“Installed Apps”的列表框中即可安装。使用Cydia Impactor(可以在网上找到相关下载链接): 打开…...
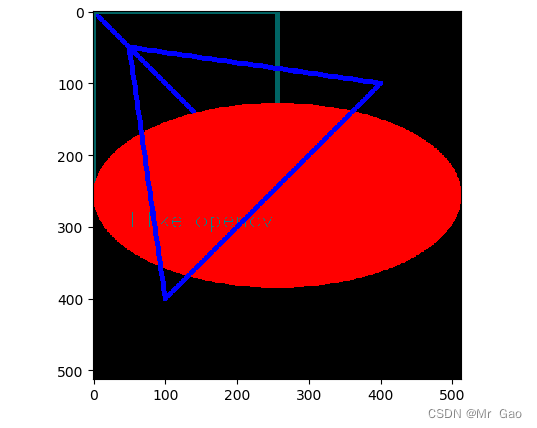
python-opencv在图片中绘制各种图形
python-opencv在图片中绘制各种图形 1.绘制直线 2.绘制矩形 3.绘制圆 4.绘制椭圆 5.绘制多边形 6.嵌入文字 实现代码都在下面了,代码中参数做了简单注释 import copy import math import matplotlib.pyplot as plt import matplotlib as mpl import numpy a…...

用户增长常用的ChatGPT通用提示词模板
用户画像:请帮助我了解目标用户的特点和需求,包括年龄、性别、职业、兴趣等方面的内容,以便我能够更好地定位和推广。 用户获取渠道:请帮助我了解用户主要从哪些渠道获取我们的产品或服务,以便我能够更好地优化获取渠…...
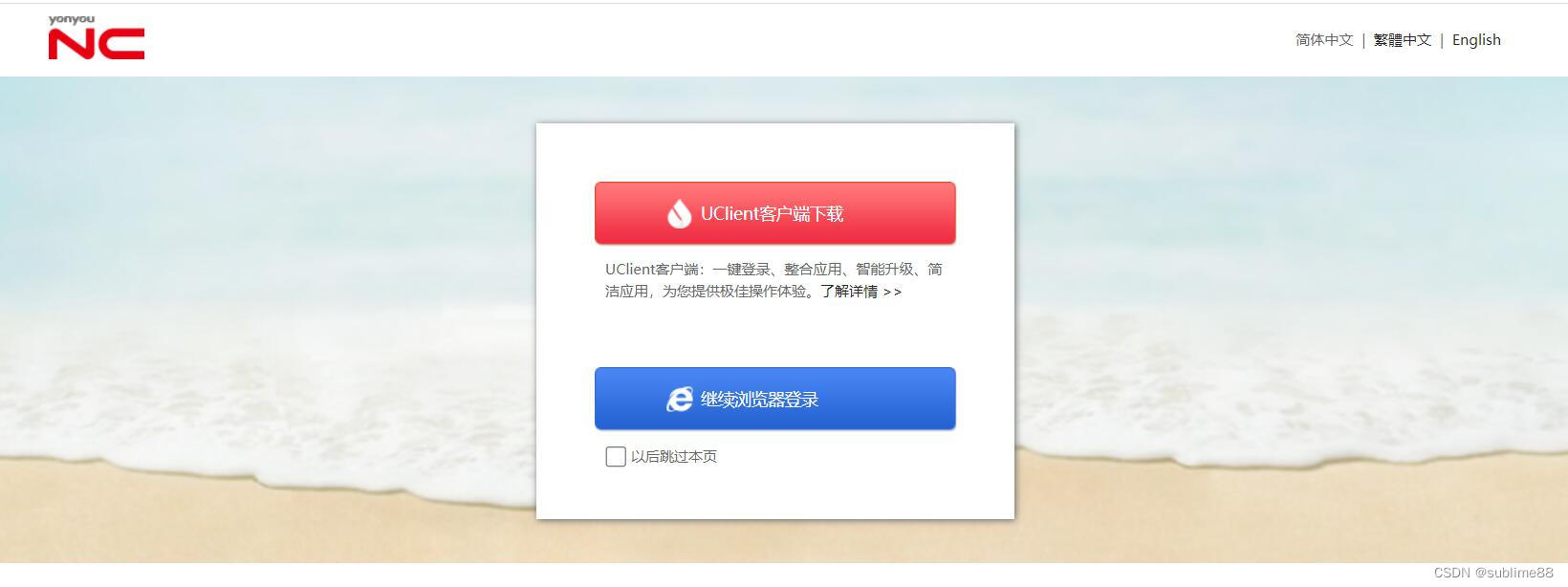
用友NC word.docx接口存在任意文件读取漏洞 附POC
@[toc] 用友NC word.docx接口存在任意文件读取漏洞 附POC 免责声明:请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损失,均由使用者本人负责,所产生的一切不良后果与文章作者无关。该文章仅供学习用途使…...
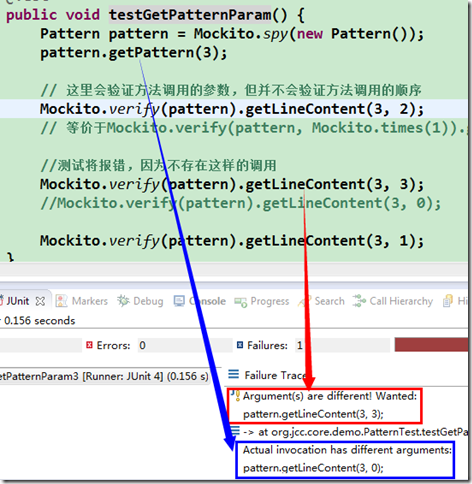
小程序中的大道理之四--单元测试
在讨论领域模型之前, 先继续说下关于测试方面的内容, 前面为了集中讨论相应主题而对此作了推迟, 下面先补上关于测试方面的. 测试覆盖(Coverage) 先回到之前的一些步骤上, 假设我们现在写好了 getPattern 方法, 而 getLineContent 还处于 TODO 状态, 如下: public String ge…...
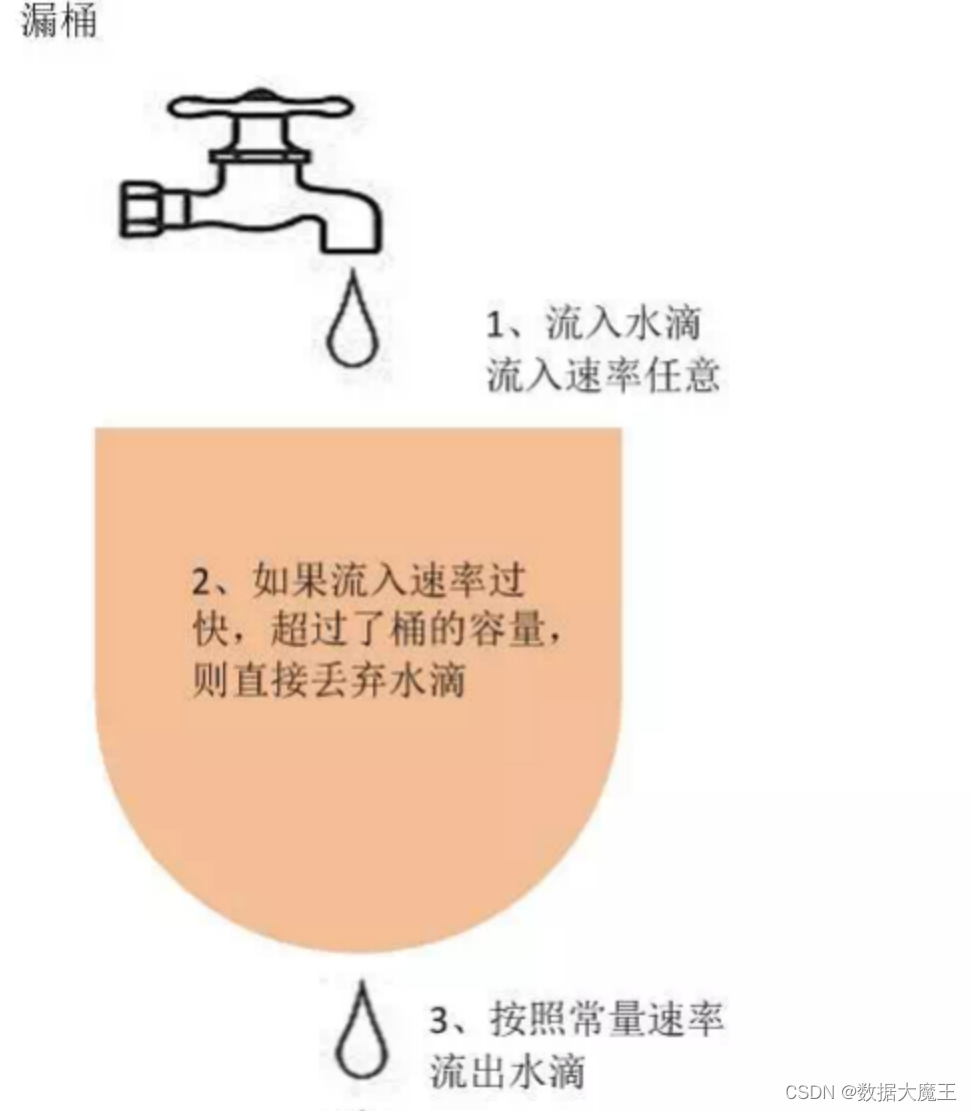
分布式篇---第六篇
系列文章目录 文章目录 系列文章目录前言一、说说什么是漏桶算法二、说说什么是令牌桶算法三、数据库如何处理海量数据?前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章男女通用,看懂了就去分享给你的码…...
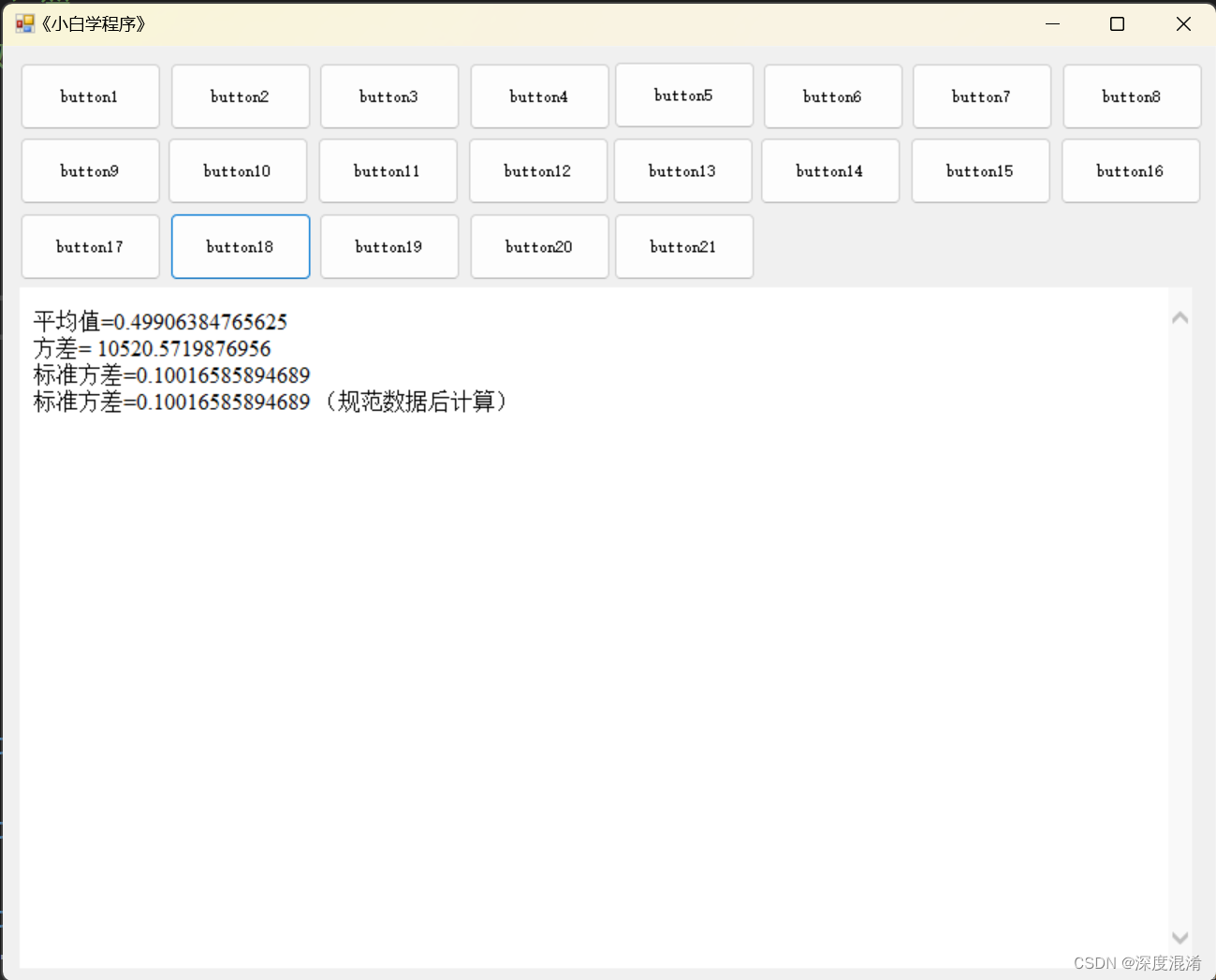
C#,《小白学程序》第十八课:随机数(Random)第五,方差及标准方差(标准差)的计算方法与代码
1 文本格式 /// <summary> /// 《小白学程序》第十八课:随机数(Random)第五,方差及标准方差(标准差)的计算方法与代码 /// 方差 SUM((Xi - X)^2 ) / n i0...n-1 X Average of X[i] ///…...

【版本管理 | Git 】Git最佳实践系列(一) —— LFS .gitignore 最佳实践,确定不来看看?
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…...

【Linux】驱动程序同步和异步通知方式
一、应用程序APP,访问驱动程序/dev/input/enent1流程: 假设用户程序直接访问 /dev/input/event0 设备节点,或者使用 tslib 访问设备节点,数据的流程如下: APP 发起读操作,若无数据则休眠;用户操…...

移动机器人路径规划(七)--- 基于MDP的路径规划MDP-Based Planning
目录 1 什么是MDP-Based Planning 2 worst-case analysis for nondeterministic model 3 Expected Cost Planning 4 Real Time Dynamic Programming(RTDP) 1 什么是MDP-Based Planning 之前我们从起点到终点存在很多可执行路径,我们可以…...

vue--The template root requires exactly one element.的解决办法
[vue/no-multiple-template-root] The template root requires exactly one element.eslint-plugin-vue 在vue中会出现以上问题 这是因为vue的模版中只有能一个根节点,所以在<template>中插入第二个元素就会报错 解决方案: 将<template>…...

嵌入式软件开发学习途径推荐
1、概述 嵌入式系统是当今智能化的重要组成部分,广泛应用于各行业和领域。学习内容多而杂,不同行业学习的内容也有一定差异。学习完一些基础课程后,工作中便是用到或根据就业方向去拓展自己的知识。这里推荐如下途径(后续可能会补充)…...
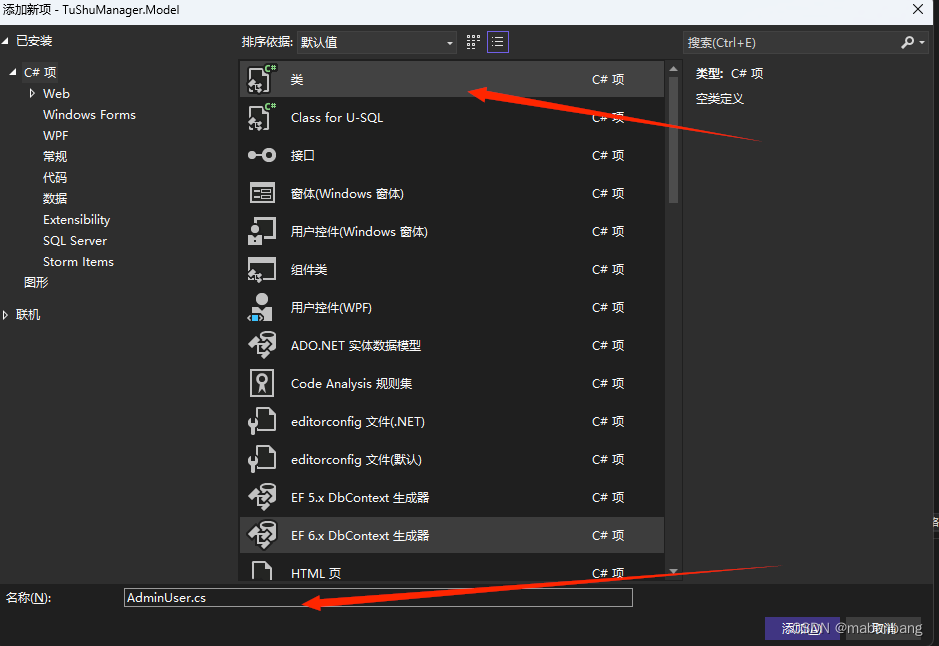
图书管理系统源码,图书管理系统开发,图书借阅系统源码三框架设计原理和说明
TuShuManger项目简介和创建 这里一共设计了6个项目,主要是借助三层架构思想分别设计了主要的三层,包括model实体层,Dal数据库操作层,Bll业务调用层,其他有公共使用项目common层,DButitly提取出来的数据库访问层,下面我们分别创建每个项目和开始搭建整个过程 TuShuManger…...

服务器被入侵了怎么去排查
在当今数字化时代,网络安全问题变得越来越重要。其中,服务器被入侵是一种常见的安全威胁。当服务器被入侵时,我们需要采取一系列措施来排查和解决问题。本文将为您提供服务器被入侵后的排查步骤。 第一步:确认服务器被入侵 当发现…...
、instanceOf和Array.isArray()的区别)
JavaScript中Object.prototype.toString.call()、instanceOf和Array.isArray()的区别
JavaScript是一种非常流行的编程语言,它具有许多强大的功能和特性。在JavaScript中,有一些方法和操作符可以帮助我们更好地处理数据类型和对象。本文将重点讨论Object.prototype.toString.call()、instanceOf和Array.isArray()这三个在JavaScript中常用的…...

Java串口通信入门教程
简介 串口通信是一种用于在计算机和外部设备之间进行数据交换的通信方式。在许多应用场景中,如物联网、自动化控制等领域,串口通信被广泛应用。本教程将带领您入门Java串口通信,介绍串口通信的基本原理和Java中的串口通信库,并提…...
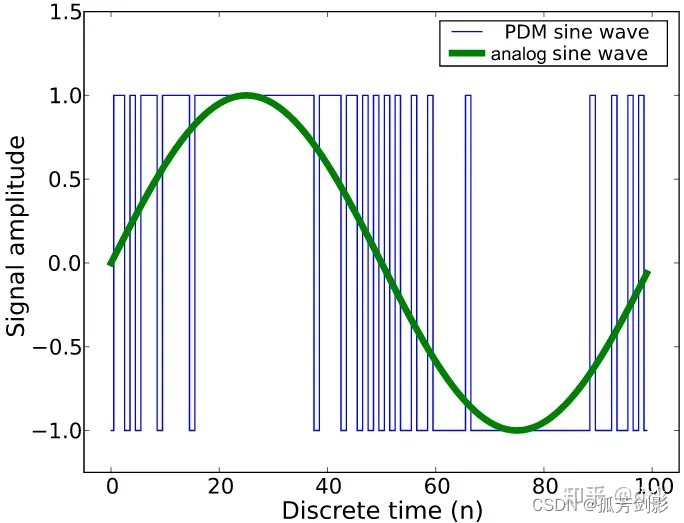
音频采集的相关基础知识
本文引注: https://zhuanlan.zhihu.com/p/652629744 1.麦克风的种类 (1)模拟麦克风 ECM麦克风:驻极体电容麦克风(ECM),典型的汽车ECM麦克风是一种将ECM单元与小型放大器电路整合在单个外壳中的装置。放大器提供一个模拟信号,其电压电平允许…...

vue中 多个请求,如果一个请出错,页面继续执行
vue中 多个请求,如果一个请出错,页面继续执行 在Vue中,可以通过Promise.all()方法来处理多个请求,即使其中一个请求出错,页面也可以继续执行其他的逻辑。 下面是一个示例代码,演示了如何在Vue中处理多个请…...
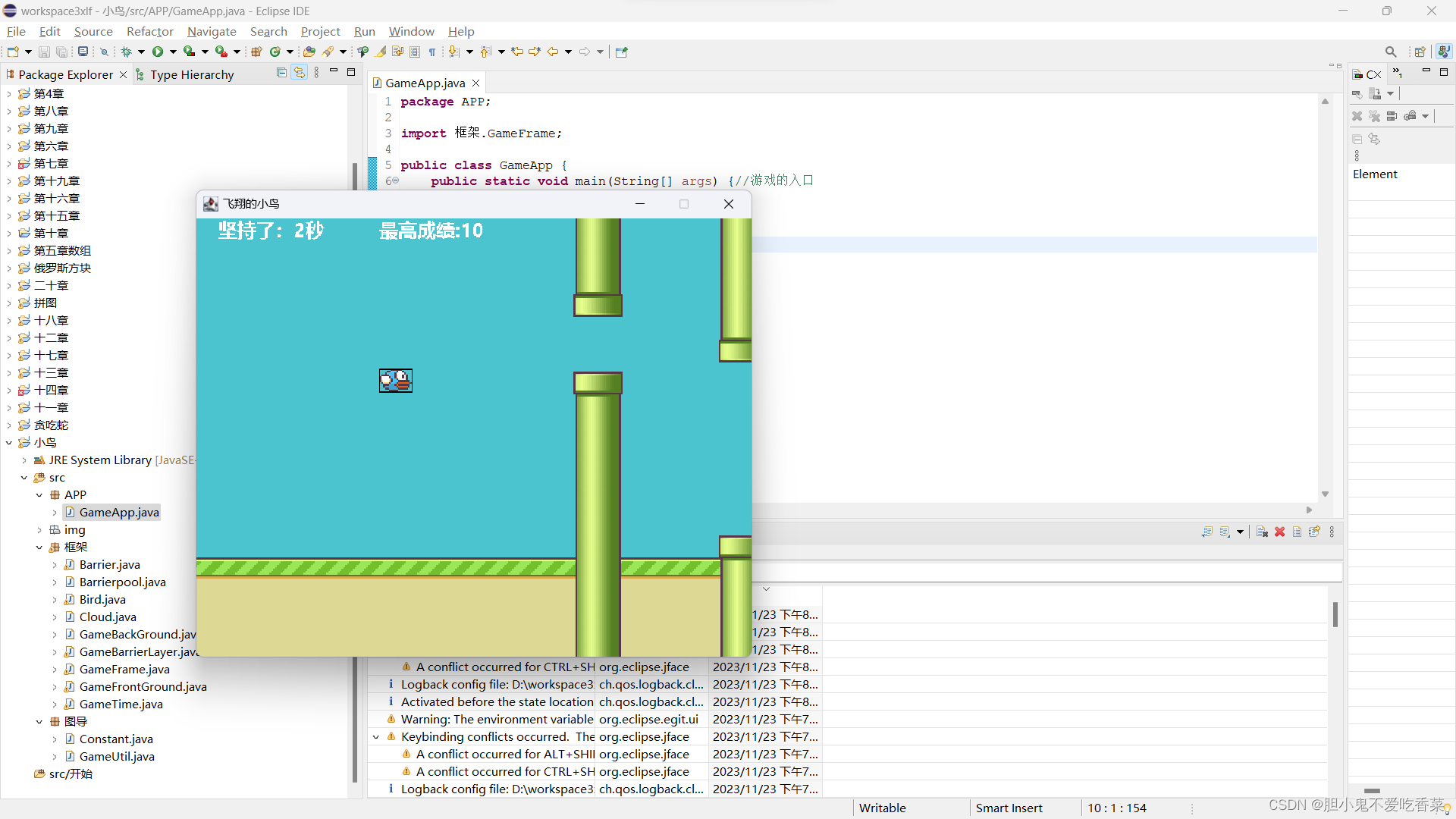
飞翔的小鸟小游戏
主类 package APP;import 框架.GameFrame;public class GameApp {public static void main(String[] args) {//游戏的入口new GameFrame();} }场景实物 package 框架;import 图导.Constant; import 图导.GameUtil;import java.awt.*; import java.awt.image.BufferedImage; …...

Bilibili-Old:重温经典界面,找回最初的B站体验
Bilibili-Old:重温经典界面,找回最初的B站体验 【免费下载链接】Bilibili-Old 恢复旧版Bilibili页面,为了那些念旧的人。 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibili-Old 你是否怀念那个简洁明了的B站界面?是否…...

基于Python的雪具销售系统毕业设计源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在设计并实现一个基于Python的雪具销售系统,以满足现代零售业对高效、便捷、智能化的销售管理需求。具体研究目的如下: 首先&…...

PP-DocLayoutV3快速体验:上传图片即得分析结果,支持合同/论文/书籍
PP-DocLayoutV3快速体验:上传图片即得分析结果,支持合同/论文/书籍 1. 文档版面分析的实用价值 在日常工作中,我们经常需要处理各种文档:合同需要提取关键条款、论文需要分析结构、书籍需要数字化存档。传统的人工处理方式效率低…...

工业肌肉:03 变频器到底改变了什么?为什么它能让电机“听话”
03 变频器到底改变了什么?为什么它能让电机“听话” 变频器不是控制电机,而是控制电机背后的“电磁节奏”。 上次把伺服舞王拆得七零八落,今天终于轮到咱们车间里最亲民的“大管家”——变频器了。工厂里风机、水泵、传送带、搅拌机……哪台大电机旁边没挂个铁箱子?别看它其…...

告别复杂编译!vLLM-v0.17.1镜像一键部署,小白也能快速搭建LLM服务
告别复杂编译!vLLM-v0.17.1镜像一键部署,小白也能快速搭建LLM服务 1. vLLM框架简介 vLLM是一个专为大型语言模型(LLM)设计的高性能推理和服务库,最初由加州大学伯克利分校的天空计算实验室开发,现已发展成为社区驱动的开源项目。…...

FoxMagiskModuleManager:重新定义Magisk模块管理体验
FoxMagiskModuleManager:重新定义Magisk模块管理体验 【免费下载链接】FoxMagiskModuleManager A module manager for Magisk because the official app dropped support for it 项目地址: https://gitcode.com/gh_mirrors/fo/FoxMagiskModuleManager FoxMag…...
 更换国内 YUM 源)
RHEL 7.3 (x86_64) 更换国内 YUM 源
兴趣原因,在本地部署了一台VBox虚拟机,安装了Redhat7.3版本,由于无法正常使用yum源,于是便修改成国内的源,在网上找了搜索了许多的更换教程,略有繁琐,现将我自己的更换方法记录如下,…...

Qwen3-0.6B-FP8部署教程:防火墙/代理环境下离线模型加载解决方案
Qwen3-0.6B-FP8部署教程:防火墙/代理环境下离线模型加载解决方案 你是不是也遇到过这种情况:想在公司内网或者网络受限的环境里部署一个大模型,结果第一步下载模型就卡住了?要么是网络代理设置太复杂,要么是防火墙直接…...

Nginx+ModSecurity 3.0.x WAF实战:从安装到规则配置的完整防护方案
NginxModSecurity 3.0.x WAF实战:从安装到规则配置的完整防护方案 在当今数字化时代,网站安全防护已成为每个技术团队必须面对的核心挑战。Web应用防火墙(WAF)作为抵御SQL注入、XSS攻击等常见威胁的第一道防线,其重要性不言而喻。本文将带您深…...

企微工具对比:第三方SCRM与自动化工作流集成
摘要 🔄将企微私域与公司CRM、工单系统打通,往往需要大量胶水代码。本文通过 AI私域实测 对比5款企微工具的Webhook与触发器能力,展示如何利用脚本实现“客户发关键词→自动创建工单→同步CRM”的全自动化,降本增效。正文一、问题…...