开源大模型框架llama.cpp使用C++ api开发入门
llama.cpp是一个C++编写的轻量级开源类AIGC大模型框架,可以支持在消费级普通设备上本地部署运行大模型,以及作为依赖库集成的到应用程序中提供类GPT的功能。
以下基于llama.cpp的源码利用C++ api来开发实例demo演示加载本地模型文件并提供GPT文本生成。
项目结构
llamacpp_starter- llama.cpp-b1547- src|- main.cpp- CMakeLists.txtCMakeLists.txt
cmake_minimum_required(VERSION 3.15)# this only works for unix, xapian source code not support compile in windows yetproject(llamacpp_starter)set(CMAKE_CXX_STANDARD 14)
set(CMAKE_CXX_STANDARD_REQUIRED ON)add_subdirectory(llama.cpp-b1547)include_directories(${CMAKE_CURRENT_SOURCE_DIR}/llama.cpp-b1547${CMAKE_CURRENT_SOURCE_DIR}/llama.cpp-b1547/common
)file(GLOB SRCsrc/*.hsrc/*.cpp
)add_executable(${PROJECT_NAME} ${SRC})target_link_libraries(${PROJECT_NAME}commonllama
)
main.cpp
#include <iostream>
#include <string>
#include <vector>
#include "common.h"
#include "llama.h"int main(int argc, char** argv)
{bool numa_support = false;const std::string model_file_path = "./llama-ggml.gguf";const std::string prompt = "once upon a time"; // input wordsconst int n_len = 32; // total length of the sequence including the prompt// set gpt paramsgpt_params params;params.model = model_file_path;params.prompt = prompt;// init LLMllama_backend_init(false);// load modelllama_model_params model_params = llama_model_default_params();//model_params.n_gpu_layers = 99; // offload all layers to the GPUllama_model* model = llama_load_model_from_file(model_file_path.c_str(), model_params);if (model == NULL){std::cerr << __func__ << " load model file error" << std::endl;return 1;}// init contextllama_context_params ctx_params = llama_context_default_params();ctx_params.seed = 1234;ctx_params.n_ctx = 2048;ctx_params.n_threads = params.n_threads;ctx_params.n_threads_batch = params.n_threads_batch == -1 ? params.n_threads : params.n_threads_batch;llama_context* ctx = llama_new_context_with_model(model, ctx_params);if (ctx == NULL){std::cerr << __func__ << " failed to create the llama_context" << std::endl;return 1;}// tokenize the promptstd::vector<llama_token> tokens_list = llama_tokenize(ctx, params.prompt, true);const int n_ctx = llama_n_ctx(ctx);const int n_kv_req = tokens_list.size() + (n_len - tokens_list.size());// make sure the KV cache is big enough to hold all the prompt and generated tokensif (n_kv_req > n_ctx){std::cerr << __func__ << " error: n_kv_req > n_ctx, the required KV cache size is not big enough" << std::endl;std::cerr << __func__ << " either reduce n_parallel or increase n_ctx" << std::endl;return 1;}// print the prompt token-by-tokenfor (auto id : tokens_list)std::cout << llama_token_to_piece(ctx, id) << " ";std::cout << std::endl;// create a llama_batch with size 512// we use this object to submit token data for decodingllama_batch batch = llama_batch_init(512, 0, 1);// evaluate the initial promptfor (size_t i = 0; i < tokens_list.size(); i++)llama_batch_add(batch, tokens_list[i], i, { 0 }, false);// llama_decode will output logits only for the last token of the promptbatch.logits[batch.n_tokens - 1] = true;if (llama_decode(ctx, batch) != 0){std::cerr << __func__ << " llama_decode failed" << std::endl;return 1;}// main loop to generate wordsint n_cur = batch.n_tokens;int n_decode = 0;const auto t_main_start = ggml_time_us();while (n_cur <= n_len){// sample the next tokenauto n_vocab = llama_n_vocab(model);auto* logits = llama_get_logits_ith(ctx, batch.n_tokens - 1);std::vector<llama_token_data> candidates;candidates.reserve(n_vocab);for (llama_token token_id = 0; token_id < n_vocab; token_id++){candidates.emplace_back(llama_token_data{ token_id, logits[token_id], 0.0f });}llama_token_data_array candidates_p = { candidates.data(), candidates.size(), false };// sample the most likely tokenconst llama_token new_token_id = llama_sample_token_greedy(ctx, &candidates_p);// is it an end of stream?if (new_token_id == llama_token_eos(model) || n_cur == n_len){std::cout << std::endl;break;}std::cout << llama_token_to_piece(ctx, new_token_id) << " ";// prepare the next batchllama_batch_clear(batch);// push this new token for next evaluationllama_batch_add(batch, new_token_id, n_cur, { 0 }, true);n_decode += 1;n_cur += 1;// evaluate the current batch with the transformer modelif (llama_decode(ctx, batch)){std::cerr << __func__ << " failed to eval" << std::endl;return 1;}}std::cout << std::endl;const auto t_main_end = ggml_time_us();std::cout << __func__ << " decoded " << n_decode << " tokens in " << (t_main_end - t_main_start) / 1000000.0f << " s, speed: " << n_decode / ((t_main_end - t_main_start) / 1000000.0f) << " t / s" << std::endl;llama_print_timings(ctx);llama_batch_free(batch);// free contextllama_free(ctx);llama_free_model(model);// free LLMllama_backend_free();return 0;
}
注:
- llama支持的模型文件需要自己去下载,推荐到huggingface官网下载转换好的gguf格式文件
- llama.cpp编译可以配置多种类型的增强选项,比如支持CPU/GPU加速,数据计算加速库
源码
llamacpp_starter
本文由博客一文多发平台 OpenWrite 发布!
相关文章:

开源大模型框架llama.cpp使用C++ api开发入门
llama.cpp是一个C编写的轻量级开源类AIGC大模型框架,可以支持在消费级普通设备上本地部署运行大模型,以及作为依赖库集成的到应用程序中提供类GPT的功能。 以下基于llama.cpp的源码利用C api来开发实例demo演示加载本地模型文件并提供GPT文本生成。 项…...

Qt 网络通信
获取本机网络信息 (1)在 .pro 文件中加入 QT network(2) #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QDebug> #include <QLabel> #include <QLineEdit> #include <QPu…...
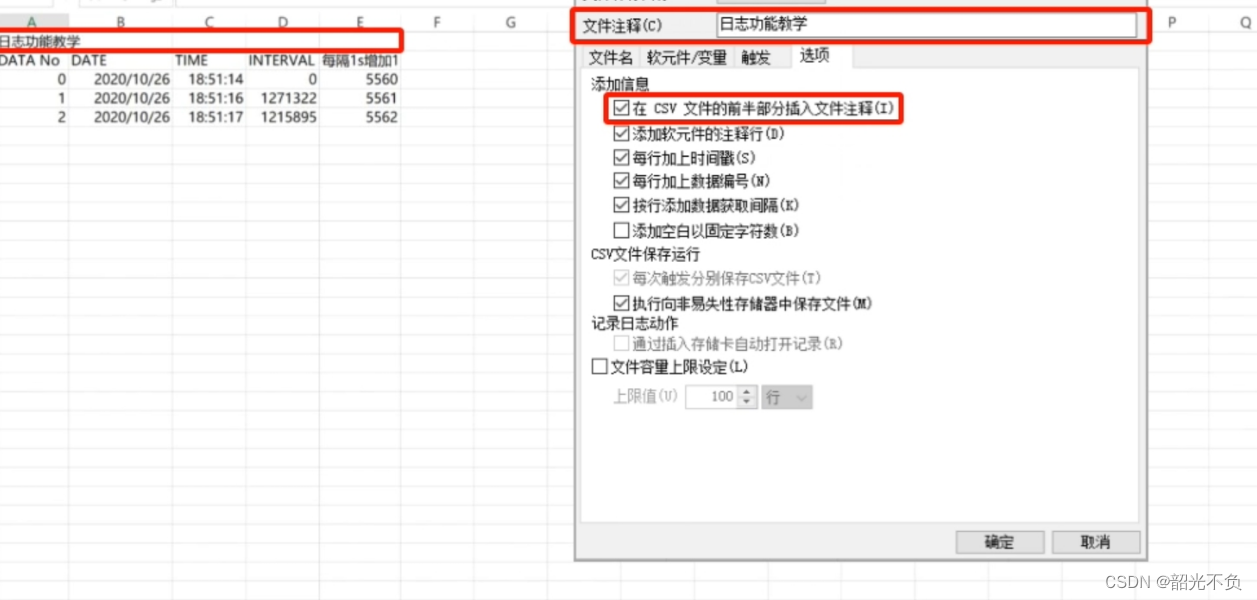
基恩士软件的基本操作(五,日志记录与使用)
目录 基恩士是如何保存日志的? 如何使用日志功能 查看DM10的值1秒加1的记录日志 设定id与储存位置 软元件设定( 日志ID有10个(0~10),每一个ID最多添加512个软元件) 设定触发 执行日志的梯形图程序 触…...

MySQL 8 手动安装后无法启动的问题解决
开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, Oceanbase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,(…...

难怪被人卷了不知道啊!这么学自动化测试,一个星期就搞定了!!!
目前自动化测试并不属于新鲜的事物,或者说自动化测试的各种方法论已经层出不穷,但是,能够明白自动化测试并很好落地实施的团队还不是非常多,我们接来下用通俗的方式来介绍自动化测试…… 首先我们从招聘岗位需求说起。看近期的职…...

每日OJ题_算法_双指针⑦力扣15. 三数之和
目录 力扣15. 三数之和 解析代码 力扣15. 三数之和 难度 中等 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三…...

【计算机网络学习之路】日志和守护进程
文章目录 前言一. 日志介绍二. 简单日志1. 左字符串2. 右字符串 三. 守护进程1. ps -axj命令2. 会话扩展命令 3. 创建守护进程 结束语 前言 本系列文章是计算机网络学习的笔记,欢迎大佬们阅读,纠错,分享相关知识。希望可以与你共同进步。 本…...
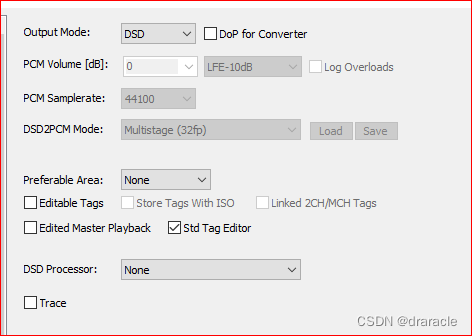
foobar2000 突然无法正常输出DSD信号
之前一直在用foobar2000加外置dac听音乐,有一天突然发现听dsd的时候,dac面板显示输出的是PCM格式信号,而不是DSD信号,这让我觉得很奇怪,反复折腾了几次,卸载安装驱动什么的,依然如此,…...
鸿蒙HarmonyOS 编辑器 下载 安装
好 各位 之前的文章 注册并实名认证华为开发者账号 我们基实名注册了华为的开发者账号 我们可以访问官网 https://developer.harmonyos.com/cn/develop/deveco-studio 在这里 直接就有我们编辑器的下载按钮 我们直接点击立即下载 这里 我们根据自己的系统选择要下载的系统 例…...
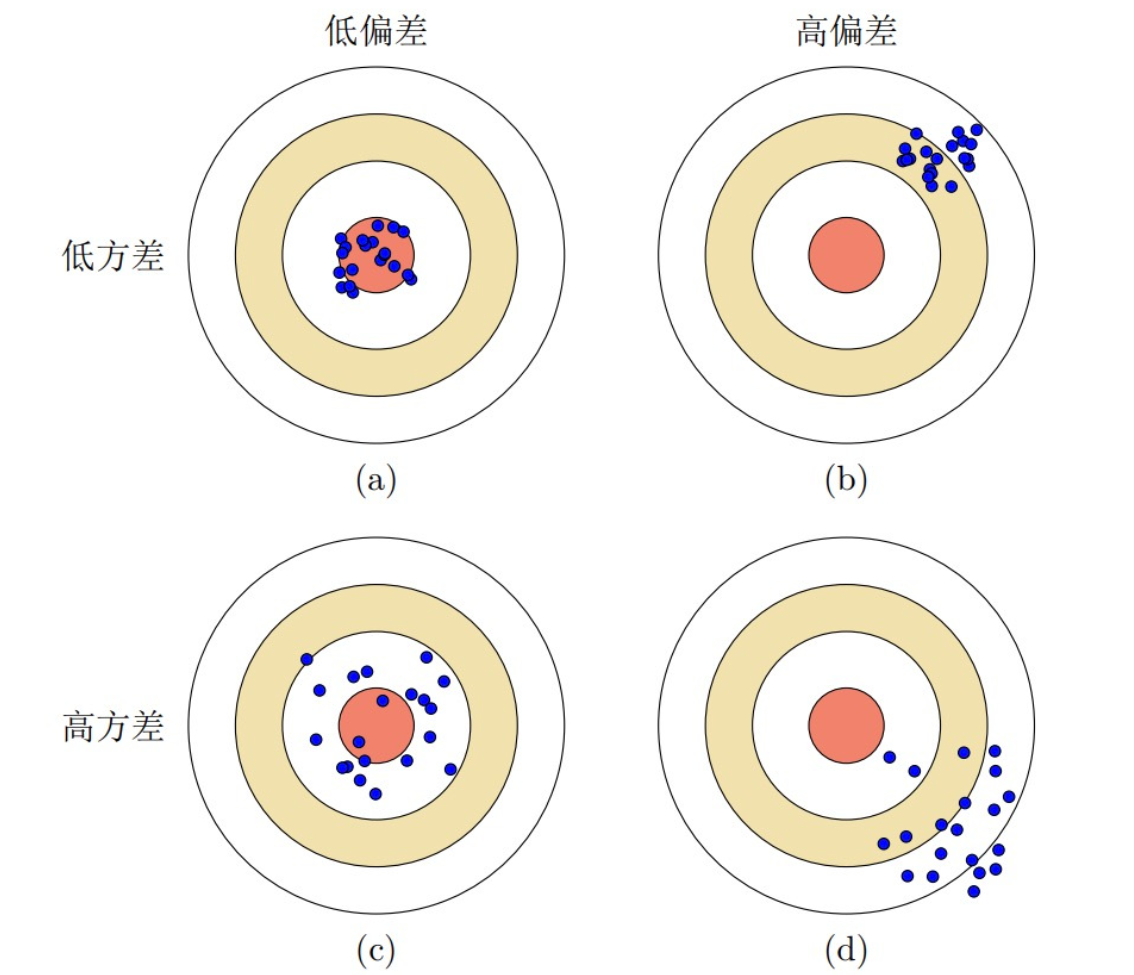
机器学习第13天:模型性能评估指标
☁️主页 Nowl 🔥专栏《机器学习实战》 《机器学习》 📑君子坐而论道,少年起而行之 文章目录 交叉验证 保留交叉验证 k-折交叉验证 留一交叉验证 混淆矩阵 精度与召回率 介绍 精度 召回率 区别 使用代码 偏差与方差 介绍 区…...

Elasticsearch基础优化
分片策略 分片和副本得设计为ES提供支付分布式和故障转移得特性,但不意味着分片和副本是可以无限分配, 而且索引得分片完成分配后由于索引得路由机制,不能重新修改分片数(副本数可以动态修改) 一个分片得底层为一个l…...
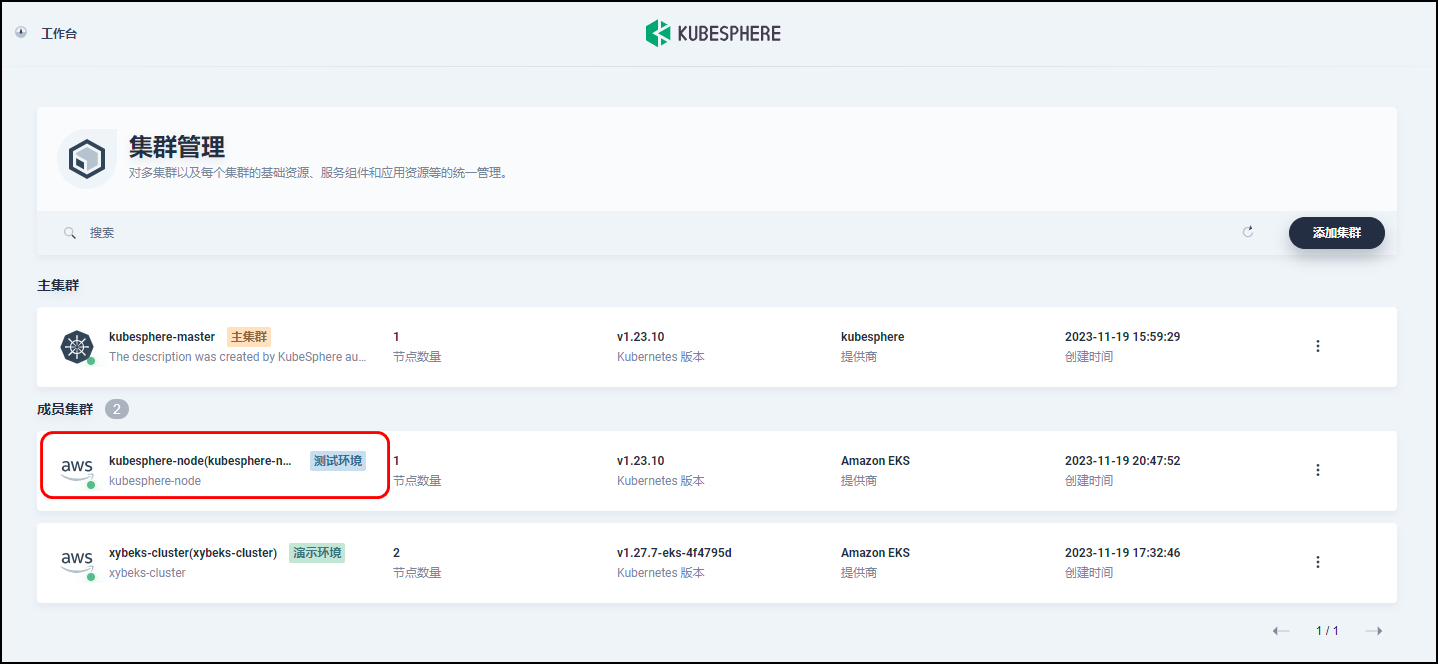
【Amazon】通过直接连接的方式导入 KubeSphere集群至KubeSphere主容器平台
文章目录 一、设置主集群方式一:使用 Web 控制台方式二:使用 Kubectl命令 二、在主集群中设置代理服务地址方式一:使用 Web 控制台方式二:使用 Kubectl命令 三、登录控制台验证四、准备成员集群方式一:使用 Web 控制台…...
三数之和问题
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的三元组。 示例 1&…...

【JavaEE】多线程 (2) --线程安全
目录 1. 观察线程不安全 2. 线程安全的概念 3. 线程不安全的原因 4. 解决之前的线程不安全问题 5. synchronized 关键字 - 监视器锁 monitor lock 5.1 synchronized 的特性 5.2 synchronized 使⽤⽰例 1. 观察线程不安全 package thread; public class ThreadDemo19 {p…...

关于点胶机那些事
总结一下点胶机技术要点: 1:不论多复杂的点胶机,简单点,可以简化为:1:运控 2:点胶,3:检测 运控的目的就是负责把针头移到面板对应的胶路上,点胶即就是排胶&…...
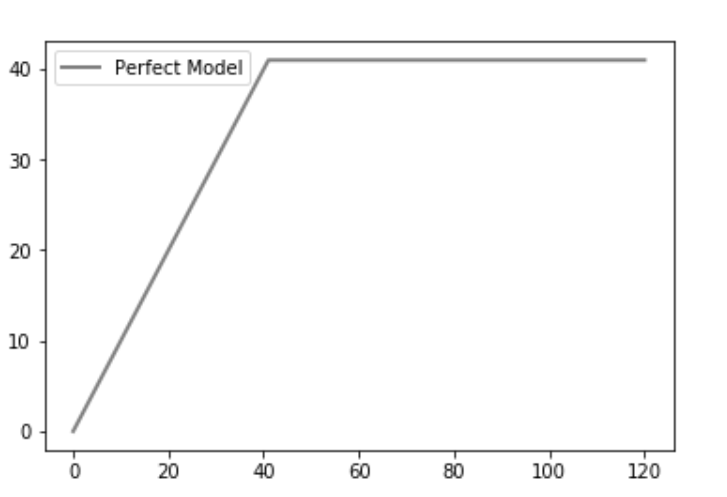
Python | CAP - 累积精度曲线分析案例
CAP通常被称为“累积精度曲线”,用于分类模型的性能评估。它有助于我们理解和总结分类模型的鲁棒性。为了直观地显示这一点,我们在图中绘制了三条不同的曲线: 一个随机的曲线(random)通过使用随机森林分类器获得的曲线…...

ubuntu22.04安装swagboot遇到的问题
一、基本情况 系统:u 22.04 python: 3.10 二、问题描述 swagboot官方提供的安装路径言简意赅:python3 -m pip install --user snagboot 当然安装python3和pip是基本常识,这里就不再赘述。 可是在安装的时候出现如下提示说 Failed buildin…...

python每日一题——8无重复字符的最长子串
题目 给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1: 输入: s “abcabcbb” 输出: 3 解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。 示例 2: 输入: s “bbbbb” 输出: 1 解释: 因为无重复字符的最长子串…...
【数据中台】开源项目(2)-Dbus数据总线
1 背景 企业中大量业务数据保存在各个业务系统数据库中,过去通常的同步数据的方法有很多种,比如: 各个数据使用方在业务低峰期各种抽取所需数据(缺点是存在重复抽取而且数据不一致) 由统一的数仓平台通过sqoop到各个…...

职场快速赢得信任
俗话说的好,有人的地方就有江湖。 国内不管是外企、私企、国企,职场环境都是变换莫测。 这里主要分享下怎么在职场中快速赢取信任。 1、找到让自己全面发展的方法 要知道,职场中话题是与他人交流的纽带,为了找到共同的话题&am…...

FastAPI子应用挂载:别再让root_path坑你一夜稼
Julia(julialang.org)由Stefan Karpinski、Jeff Bezanson等在2009年创建,目标是融合Python的易用性、C的高性能、R的统计能力、Matlab的科学计算生态。 其核心设计哲学是: 高性能:编译型语言(JIT…...

2026年怎么搭建OpenClaw?2分钟新手本地部署OpenClaw及百炼Coding Plan教程
2026年怎么搭建OpenClaw?2分钟新手本地部署OpenClaw及百炼Coding Plan教程。本文面向零基础用户,完整说明在轻量服务器与本地Windows11、macOS、Linux系统中部署OpenClaw(Clawdbot)的流程,包含环境配置、服务启动、Ski…...
)
告别OpenAI API费用!用Ollama+crewAI搭建免费本地AI工作流(保姆级避坑指南)
零成本构建本地AI工作流:Ollama与crewAI深度整合实战指南 在技术迭代日新月异的今天,大型语言模型已成为开发者工具箱中不可或缺的一部分。然而,商业API的高昂成本和网络限制常常让个人开发者和小型团队望而却步。本文将带你探索如何利用Olla…...

BMI088六轴IMU驱动开发:通信配置、同步机制与工程调优
1. BMI088六轴IMU底层驱动技术深度解析1.1 器件特性与工程定位Bosch Sensortec BMI088是一款面向高动态场景的系统级封装(SiP)六轴惯性测量单元,其核心价值不在于参数堆砌,而在于针对无人机、机器人等振动敏感平台的系统级鲁棒性设…...

JAX GPU版安装实战:从cuSPARSE报错到完美运行的完整记录
JAX GPU版深度调优指南:从cuSPARSE报错到高效计算的完整解决方案 在深度学习和高性能计算领域,JAX凭借其自动微分和XLA加速能力已成为研究人员和工程师的重要工具。然而,当我们在GPU环境中部署JAX时,经常会遇到各种库依赖和版本冲…...

备件断供时代:中短波发射机国产化替代的真实进展
本文是工程四部曲之四。此前三篇分别拆解了中波台的运营成本(OPEX篇)、发射机的全生命周期成本、以及天馈系统的数字化适配。本篇文章,我们将把目光转向设备供应链本身——你想买的东西,还买得到吗? 一根导火索 2026年…...

百考通:AI完美贴合答辩PPT,贴合不同场景,助力每一份研究
毕业季、开题季,一份专业出彩的PPT是顺利通过答辩的关键。但从论文中提炼核心观点、规划答辩逻辑、设计美观版式,往往让学生们焦头烂额。百考通(https://www.baikaotongai.com) 凭借AI技术深度赋能,打造出一站式答辩PP…...

模型预测控制:从数学到车轮的暴力破解
mpc模型预测控制从原理到代码实现 mpc模型预测控制详细原理推导 matlab和c两种编程实现 四个实际控制工程案例: 双积分控制系统 倒立摆控制系统 车辆运动学跟踪控制系统 车辆动力学跟踪控制系统 包含上述所有的文档和代码。 模型预测控制(MPC)…...
)
实战指南 | 利用FRP与TOML配置实现高效内网穿透(含反向代理优化)
1. 为什么需要内网穿透? 想象一下这个场景:你家里有一台NAS存储设备,里面存满了家人照片和工作文档;或者你在本地开发了一个网站应用,想临时分享给异地同事测试。这时候你会发现——从外部网络根本无法访问这些服务&am…...

Build Your Own Mint项目架构分析:理解Plaid、Google Sheets和CircleCI的完美结合
Build Your Own Mint项目架构分析:理解Plaid、Google Sheets和CircleCI的完美结合 【免费下载链接】build-your-own-mint Build your own personal finance analytics using Plaid, Google Sheets and CircleCI. 项目地址: https://gitcode.com/gh_mirrors/bu/bui…...