哈希思想的应用
目录
1.位图
位图的实现
题目变形一
题目变形二
题目变形三
总结:
2.布隆过滤器
概念
布隆过滤器的实现
3.哈希切割的思想
1.位图
哈希表和位图是数据结构中常用的两种技术。哈希表是一种数据结构,通过哈希函数把数据和位置进行映射,来实现快速的寻找、插入和删除操作。哈希表适用于海量数据处理,索引,数据压缩等方面有广泛应用123. 位图主要用于海量数据处理,索引,数据压缩等方面有广泛应用。位图的应用场景包括:
1. 给定100亿个整数,设计算法找到只出现一次的整数;
2. 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
3. 位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数。
如下题目:
位图的实现
0.5G我们开不出bit类型的,我们只能开出整形或字符类型的。因此这里直接用vector来映射,因此我们需要计算出映射的位置。
如判断x是否存在,则我们需要计算x在第几个整形的第几个bit位上。

template<size_t N>class bitset
{
public:bitset(){_bit.resize(N/32);}void set(size_t x){size_t i = x / 32;//第几个整形size_t j = x % 32;//第几个位//找到该位置并置1 ,利用位运算计算//注意左移是向高位移,右移是向低位移_bit[i] |= (1 << j);//这里1左移再或上原数据,重新赋值后,该比特位就修改成1}void reset(size_t x){//与set相反,这里是将原来的x有存在变为不存在,不存在变为存在size_t i = x / 32;//第几个整形size_t j = x % 32;//第几个位//找到该位置//1变0 0变1_bit[i] &= ~(1 << j);}//检测是否中存在,即该位置是1还是0bool test(size_t x){size_t i = x / 32;size_t j = x % 32;return _bit[i] & (1 << j);}
private://数据个数足够大,用16进制表示std::vector<int> _bit;size_t size;
};
题目变形一
/用两个数组表示两个bit位
//用两位bit位映射一个数三种状态,存在,不存在,个数
//00 不存在 01存在 10两个以上的个数
template<size_t N>class twobitset
{
public:void set(const size_t x){if (bit1.test(x) == false && bit2.test(x) == false)//0 0 -> 0 1{bit2.set(x);}else if (bit1.test(x) == false && bit2.test(x) == true) //0 1 -> 1 0 {bit1.set(x);bit2.reset(x);}}
private:bitset<N> bit1;bitset<N> bit2;
};题目变形二
题目变形三
template<size_t N>class twobitset
{
public:void set(const size_t x){if (bit1.test(x) == false && bit2.test(x) == false)//0 0 -> 0 1{bit2.set(x);}else if (bit1.test(x) == false && bit2.test(x) == true) //0 1 -> 1 0 {bit1.set(x);bit2.reset(x);}else if (bit1.test(x) == true && bit2.test(x) == false;)// 10 ->11{bit1.set(x);bit2.set(x);}}
private:bitset<N> bit1;bitset<N> bit2;
};总结:
对于搜索:
1.暴力查找,数据量太大,效率太低。
2.排序+二分查找 ,极大的提升了效率。但还是存在不足:要排序。数组不方便增删。
3.引入搜索树,AVL树,红黑树。查找效率已经很可观了,但空间消耗较高。
4.哈希 ,与搜索树效率差不多,但对于大量搜索的整型数据,通过映射bit的思想实现更加高效,且节省空间。(但只能处理整形)
对于其他类型的,引出了布隆过滤器:
2.布隆过滤器
概念
布隆过滤器是一种概率型数据结构,用于判断一个元素是否在一个集合中。它可以节省空间和时间,但有一定的误判率:
1. 布隆过滤器的核心是一个位数组,即一个只包含0和1的数组,以及一组哈希函数,即一组可以将任意元素映射到位数组的索引的函数。
2. 当要添加一个元素时,先用哈希函数计算出它在位数组中的多个索引,然后将这些索引对应的值都设为1. 当要检查一个元素是否存在时,也先用哈希函数计算出它在位数组中的多个索引,然后检查这些索引对应的值是否都为1. 如果都为1,说明元素可能存在,如果有一个为0,说明元素一定不存在。
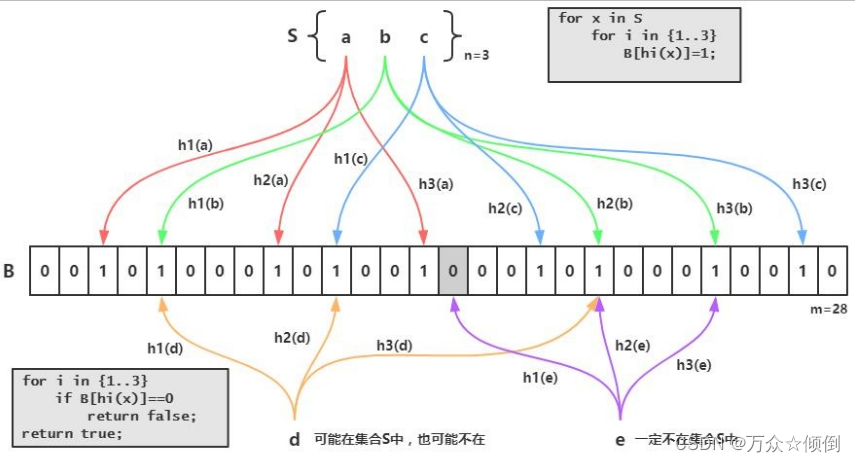
上述说了位图,我们知道位图可以来查找大量整形数据,但是对于其他类型,如字符型,就无法去查找,此时我们就需要有一种方法将他搞成整形。
直接用ascll码肯定不行,再通过哈希字符串算法转化一下,但是仍会有较大的冲突,还是有大概率的值是一样的,为了减少这些冲突,我们让一个字符串对应三个或者更多的哈希字符串算法转化后的整形,只有当这些整型值都存在的时候才存在,大大减少了重复带来的问题。各种字符串Hash函数 - clq - 博客园 (cnblogs.com)
但是还是存在问题:即使我们让一个字符串对应了三个转化后的数,但还是存在别的字符串也会对应这三个转化后的数(将不存在的判断为存在的),我们只能尽可能的减少这种情况,因此是否存在我们还是有不确定因素,但不存在我们一定能够能确定。
一个字符串对应的三个整数的对应比特位设置为1.
总的来说,存在误判率,但概率已经不是很大了。
那么如何选择n(插入元素个数)和k(映射的个数)的值呢?
有人给出了公式计算这里的m是布隆过滤器的长度。我们先以k=3先来实现。
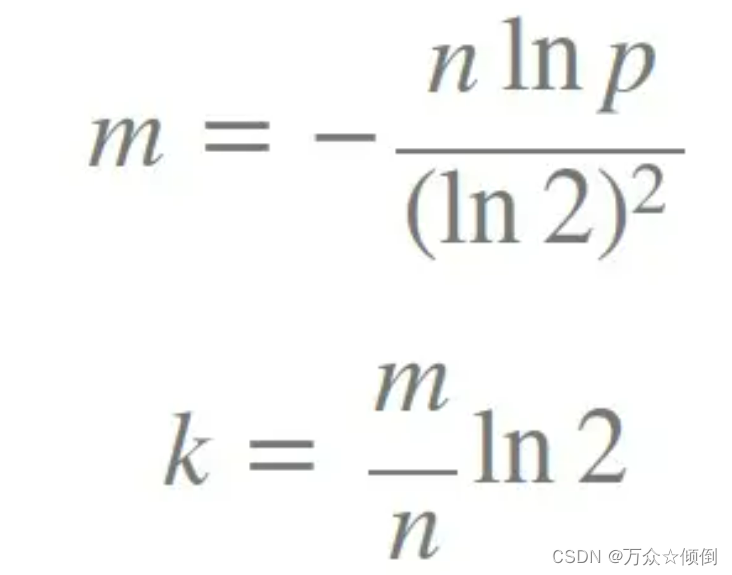
布隆过滤器的实现
#pragma once
#include"bitset.h"
//这里我们就选用3个映射值来对应一个字符串,每一个映射值我们选取一种hash字符串算法
#include<string.h>
struct BKDR
{size_t operator()(const std::string& key){// BKDRsize_t hash = 0;for (auto e : key){hash *= 31;hash += e;}return hash;}
};
struct AP
{size_t operator()(const std::string& str){size_t hash = 0;int i = 0;char ch = str[i];for (auto ch: str){if ((i & 1) == 0){hash ^= ((hash << 7) ^ ch ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));}i++;}return hash;}
};
struct SDB
{size_t operator()(const std::string& str){size_t hash = 0;for(auto ch:str){hash = 65599 * hash + ch;}return hash;}
};
template<size_t N,class K=std::string,class HashFunc1= BKDR,class HashFunc2 = AP,class HashFunc3 = SDB>
class BloomFilter
{
public://这里的类型就用泛型了void set(const K& key){//三个值来映射size_t hash1 = HashFunc1()(key) % N;size_t hash2 = HashFunc2()(key) % N;size_t hash3 = HashFunc3()(key) % N;_bit.set(hash1);_bit.set(hash2);_bit.set(hash3);}bool test(const K& key){size_t hash1 = HashFunc1()(key) % N;size_t hash2 = HashFunc2()(key) % N;size_t hash3 = HashFunc3()(key) % N;//只有当三个映射值都存在是才能表示存在if (_bit.test(hash1) == true&& _bit.test(hash2) == true&& _bit.test(hash3) == true){return true;//存在误判}return false;}/*double wrongrate(){return }*/private://用位图封装bitset<N> _bit;
};
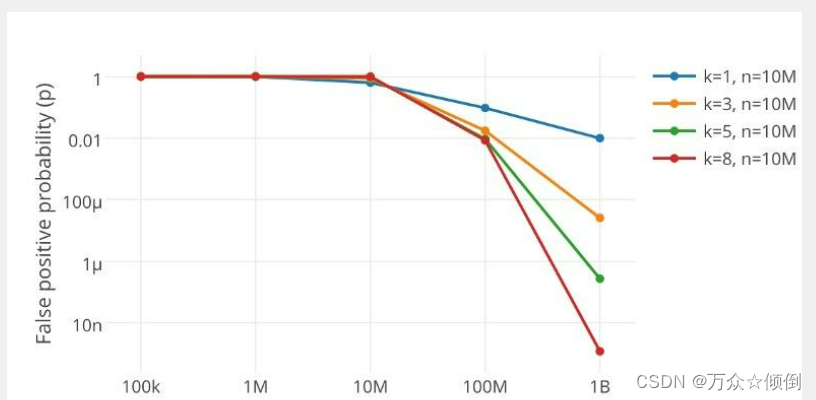
事实上,空间开得越多,选用的映射值越多,都会之误判律极大地降低。
对于布隆过滤器,一般是不支持删除的,我们在删除一个值这会影响以他的字符串成员存在变成不存在,如若像删除,就必须要引用计数,增加计数位(多个比特位),即对应的哈希值在每一次被set之后,对应的计数位++,判断是否存在时,同时添加计数位是否为零,其次删除后,就减减计数位的值,不过还是消耗了空间。
3.哈希切割的思想
哈希切割是一种将大文件分割成若干个小文件的方法,以便于处理海量数据。该方法使用哈希函数将相同的数据分配到同一个文件中。这种方法可以用于处理日志文件等大小超过100GB的文件
例题:
相关文章:
哈希思想的应用
目录 1.位图 位图的实现 题目变形一 题目变形二 题目变形三 总结: 2.布隆过滤器 概念 布隆过滤器的实现 3.哈希切割的思想 1.位图 哈希表和位图是数据结构中常用的两种技术。哈希表是一种数据结构,通过哈希函数把数据和位置进行映射,…...

React入门使用 (官方文档向 Part1)
文章目录 React组件:万物皆组件 JSX: 将标签引入 JavaScriptJSX 规则1. 只能返回一个根元素2. 标签必须闭合3. 使用驼峰式命名法给 ~~所有~~ 大部分属性命名!高级提示:使用 JSX 转化器 在 JSX 中通过大括号使用 JavaScript使用引号传递字符串使用大括号&…...
87基于matlab的双卡尔曼滤波算法
基于matlab的双卡尔曼滤波算法。第一步使用了卡尔曼滤波算法,用电池电压来修正SOC,然后将修正后的SOC作为第二个卡尔曼滤波算法的输入,对安时积分法得到的SOC进行修正,最终得到双卡尔曼滤波算法SOC估计值。结合EKF算法和安时积分法…...

Jacobi迭代与SOR迭代求解希尔伯特矩阵
给出线性方程组 Hn*x b,其中系数矩阵Hn为希尔伯特矩阵: 假设 x ∗ (1, 1, . . . , 1)T,b Hnx ∗。若取 n 6,8, 10,分别用 Jacobi 迭代法及 SOR迭代(ω 1, 1:25,1:5)求解,比较计算结果。…...

【云备份】配置加载文件模块
文章目录 配置信息设计配置文件加载cloud.conf配置文件单例模式的使用ReadConfigFile —— 读取配置文件GetInstance —— 创建对象其他函数的实现 具体实现cloud.confconfig.hpp 配置信息设计 使用文件配置加载一些程序运行的关键信息 可以让程序的运行更加灵活 配置信息&am…...

sqlserver写入中文乱码问题
sqlserver写入中文乱码问题解决方案 首先查看sqlserver数据库编码 首先查看sqlserver数据库编码 查询语句:SELECT COLLATIONPROPERTY(Chinese_PRC_Stroke_CI_AI_KS_WS, CodePage); 对应的编码: 936 简体中文GBK 950 繁体中文BIG5 437 美国/加…...

【亚马逊云】基于EC2以 All-in-One 模式快速部署 KubeSphere 和 Kubernetes
文章目录 1. 云实例配置说明2. SSH连接云实例3. 查看系统版本4. 修改主机名5. 安装依赖项6. 安全组和DNS修改7. 下载KubeKey8. 同时安装Kubesphere和Kubernetes[可选]单独安装Kubernetes[可选]单独安装KubeSphere9. 验证KubeSphere安装结果10. 登录KubeSphere控制台[可选]安装K…...

使用 ChatGPT 创建 Makefile 构建系统:从 Docker 开始
使用 Docker 搭配 ChatGPT 创建 Makefile 构建系统 Makefile 构建系统是嵌入式软件团队实现其开发流程现代化的基础。构建系统不仅允许开发人员选择各种构建目标,还可以将这些构建集成到持续集成/持续部署 (CI/CD) 流程中。使用诸如 ChatGPT 这样的人工智能 (AI) 工…...

嵌入式设备摄像头基础知识
工作原理 摄像头的工作原理是,当光线通过镜头聚焦到图像传感器上时,传感器会将光信号转换为电信号,并将其传输给处理器进行处理。处理器通过算法对图像信号进行增强、去噪、压缩等操作,并将其转换为数字信号输出给计算机或其他设…...

使用Pytorch从零开始构建Normalizing Flow
归一化流 (Normalizing Flow) (Rezende & Mohamed,2015)学习可逆映射 f : X → Z f: X \rightarrow Z f:X→Z, 在这里X是我们的数据分布,Z是选定的潜在分布。 归一化流是生成模型家族的一部分,其中包括变分自动编…...

一个tomcat中部署的多个war,相当于几个jvm
请直接去看原文 原文链接:一个tomcat有几个jvm-CSDN博客 --------------------------------------------------------------------------------------------------------------------------------- 前几天向unmi提问,今天他答复了。我觉得答复很清楚,…...
2023年第十六届中国系统架构师大会(SACC2023)-核心PPT资料下载
一、峰会简介 本届大会以“数字转型 架构演进”为主题, 涵盖多个热门领域,如多云多活、海量分布式存储、容器、云成本、AIGC大数据等,同时还关注系统架构在各个行业中的应用,如金融、制造业、互联网、教育等。 与往届相比&#…...
高校大学校园后勤移动报修系统 微信小程序uniapp+vue
本文主要是针对线下校园后勤移动报修传统管理方式中管理不便与效率低的缺点,将电子商务和计算机技术结合起来,开发出管理便捷,效率高的基于app的大学校园后勤移动报修app。该系统、操作简单、界面友好、易于管理和维护;而且对后勤…...

docker常见问题汇总
docker常见问题 ❓问题1:启动docker容器时,报错Unknown runtime specified nvidia. 当我启动一个容器时,运行以下命令: docker run --runtimenvidia 。。。。 后面一部分命令没写出来,此时报错的信息如下:…...

JMeter 测试脚本编写技巧
JMeter 是一款开源软件,用于进行负载测试、性能测试及功能测试。测试人员可以使用 JMeter 编写测试脚本,模拟多种不同的负载情况,从而评估系统的性能和稳定性。以下是编写 JMeter 测试脚本的步骤。 第 1 步:创建测试计划 在JMet…...
力扣6:N字形变化
代码: class Solution { public:string convert(string s, int numRows){int lens.size();if(numRows1){return s;}int d2*numRows-2;int count0;string ret;//第一行!for(int i0;i<len;id){rets[i];}//第k行!for(int i1;i<numRows-1;…...
【上海大学数字逻辑实验报告】一、基本门电路
一、 实验目的 熟悉TTL中、小规模集成电路的外形、管脚和使用方法;了解和掌握基本逻辑门电路的输入与输出之间的逻辑关系及使用规则。 二、 实验原理 实现基本逻辑运算和常用逻辑运算的单元电路称为逻辑门电路。门电路通常用高电平VH表示逻辑值“1”,…...

基于xml配置的AOP
目录 xml方式AOP快速入门 xml方式AOP配置详解 xml方式AOP快速入门 xml方式配置AOP的步骤 导入AOP相关坐标 <dependency><groupId>org.aspectj</groupId><artifactId>aspectjweaver</artifactId><version>1.8.13</version></de…...

java学习part12多态
99-面向对象(进阶)-面向对象的特征三:多态性_哔哩哔哩_bilibili 1.多态(仅限方法) 父类引用指向子类对象。 调用重写的方法,就会执行子类重写的方法。 编译看引用表面类型,执行看实际变量类型。 2.父子同名属性是否…...

前置任务之安装jdk
已经安装过很多次了,但是每次安装都要搜好几次才能找到正确的,离大谱。 1.打开 oracle官网 https://www.oracle.com 然后切换到Java archive 下载192版本的,页面搜索ctrlF,【Java SE Development Kit】或者【jdk-8u192-windows-…...

oicq 高级技巧:如何构建企业级 QQ 机器人应用架构
oicq 高级技巧:如何构建企业级 QQ 机器人应用架构 【免费下载链接】oicq Tencent QQ Bot Library for Node.js 项目地址: https://gitcode.com/gh_mirrors/oi/oicq oicq 是一个基于 Node.js 的 QQ 协议库,专为构建稳定、高效的 QQ 机器人应用而设…...
)
从NLP到CV:用PyTorch手把手实现ViT的Patch Embedding(附完整代码)
从NLP到CV:用PyTorch手把手实现ViT的Patch Embedding(附完整代码) 当自然语言处理领域的Transformer开始"跨界"重塑计算机视觉的版图时,最精妙的突破点往往藏在最基础的数据表示层。本文将带您亲历从Word Embedding到P…...
)
5分钟快速上手:用Docker一键部署Milvus向量数据库(附常见错误解决)
5分钟极速部署Milvus:Docker实战指南与高频避坑手册 当我们需要快速验证一个AI项目的可行性时,最头疼的往往不是模型本身,而是基础设施的搭建。上周我正准备测试一个图像检索系统,结果在向量数据库部署环节就卡了整整两天——各种…...

PADS Layout VX.1.2设计规则全解析:从安全间距到布线优化的实战技巧
PADS Layout VX.1.2设计规则全解析:从安全间距到布线优化的实战技巧 在高速PCB设计领域,规则约束如同交通信号灯般重要——它们决定了电流的"通行权"和"避让规则"。作为Mentor Graphics旗下的经典工具,PADS Layout VX.1…...

新手福音:通过快马生成的示例项目,轻松上手豆包开放平台第一个AI调用
今天想和大家分享一个特别适合新手入门豆包开放平台的小项目——用快马生成的"天气查询助手"。作为一个刚接触API开发的小白,我发现这种方式真的能快速理解整个调用流程,而且完全不需要从零开始写代码。 项目背景与功能设计 这个天气查询助手…...

实战指南:基于快马平台开发在线教育vc16188视频交互系统
实战指南:基于快马平台开发在线教育vc16188视频交互系统 最近在做一个在线教育项目,需要实现视频课程的智能分段和交互功能。经过一番摸索,发现用InsCode(快马)平台可以快速搭建这样一个系统。下面分享下我的实战经验。 系统架构设计 前端部…...

企业内部培训,适合用教学云桌面吗?
企业内部培训常面临环境部署繁琐、运维压力大、设备资源固化、数据安全难控等问题,教学云桌面凭借集中化管理与弹性资源配置,成为不少企业的选型方向。结合实际应用与技术特性来看,教学云桌面适配企业培训场景,且能系统性解决传统…...

YOLOFuse效果惊艳:红外热成像+可见光,极端环境下的检测利器
YOLOFuse效果惊艳:红外热成像可见光,极端环境下的检测利器 1. 多模态检测的技术突破 在智能安防、自动驾驶和工业检测等关键领域,视觉系统常常面临极端环境的挑战:漆黑的夜晚、弥漫的烟雾、刺眼的强光...传统基于RGB图像的目标检…...

OpenClaw对接Qwen2.5-VL-7B:3步完成模型地址配置
OpenClaw对接Qwen2.5-VL-7B:3步完成模型地址配置 1. 为什么选择Qwen2.5-VL-7B作为OpenClaw的视觉大脑 去年我在尝试用OpenClaw自动化处理图片资料时,发现纯文本模型经常对截图内容"睁眼说瞎话"。直到遇到Qwen2.5-VL-7B这个多模态模型&#x…...

如何让老款RTX显卡免费获得AMD FSR3帧生成技术?5分钟完整解决方案
如何让老款RTX显卡免费获得AMD FSR3帧生成技术?5分钟完整解决方案 【免费下载链接】dlssg-to-fsr3 Adds AMD FSR 3 Frame Generation to games by replacing Nvidia DLSS Frame Generation (nvngx_dlssg). 项目地址: https://gitcode.com/gh_mirrors/dl/dlssg-to-…...