redis作为缓存详解
目录
前言:
为什么说关系型数据库性能不高
如何提高MySQL并发量
缓存更新策略
定期更新
实时更新
内存淘汰策略
Redis内置的淘汰策略
缓存常见问题
缓存预热
缓存穿透
缓存雪崩
缓存击穿
前言:
对于缓存的理解,缓存目的就是为了提供更快速的访问效率。一般会使用访问迅速的为访问较为缓慢的作为缓存。例如使用内存作为硬盘的缓存,硬盘作为网络的缓存。使用缓存可以减轻被缓存服务请求数量,一定程度上提供了系统高可用性能。
为什么说关系型数据库性能不高
1)数据库把数据存储在硬盘上,硬盘IO速度并不快,尤其是随机访问。
2)如果查询不能命中索引,就需要进行表遍历,这会大量增加硬盘IO次数。
3)关系型数据库会对SQL进行一系列的解析,优化,校验等工作。
4)一些复杂查询,联表查询,会进行笛卡尔积操作,效率会降低很多。
注意:
因为mysql等数据库效率比较低,所承担的并发量就有限,一旦请求数量多了,数据库压力就会很大,就很容易宕机。
如何提高MySQL并发量
开源:
引入更多机器,构成MySQL集群。
节流:
引入缓存,把一些频繁读取的热点数据,保存在缓存上。后续查询数据的时候,如果缓存中存在,就不去MySQL中进行查询了。
注意:
数据是存在二八原则的,20%的数据可以满足80%的请求,虽然redis是内存数据库,只能存储少量数据,但基于这个原则,可以大大减少MySQL数据库压力。
缓存更新策略
如何知道redis中应该存储哪些数据,如何知道哪些数据是热点数据呢?
定期更新
会把访问的数据以日志形式记录下来,然后就可以分析这些日志数据,得到一些频繁出现的词,那么这些词所对应的数据就算热点数据了,就可以存储在redis中。
这里redis中的数据可以按照一天一更新,或者一周一更新,定期的进行热点数据统计,更新redis中的数据。
优点:
上述过程实现起来比较简单,过程更加可控(缓存中有什么数据比较固定),方便排查问题。
缺点:
实时性不够,如果出发一些特殊事件,有一些本来不是热词的数据成了热词,新热词查询就可能给后面数据库带来比较大的压力。
实时更新
1)先从redis中查询,如果查到数据直接返回。
2)如果redis中不存在,则去数据库查,然后把数据插入redis中。
3)这样不停的往redis中插入数据,就会使redis的内存占用越来越多,逐渐达到上限。此时如果继续往redis中插入数据,就会触发问题。为了解决此问题,redis引入了内存淘汰策略。
内存淘汰策略
1)FIFO(First In First Out)先进先出
把缓存中存在时间最久的(也就是先来的数据)淘汰掉。
2)LRU (Least Recently Used)淘汰最久未使用的
记录每个key的最近访问时间.把最近访问时间最老的key淘汰掉。
3)LFU(Least Frequently Used)淘汰访问次数最少的
记录每个key最近⼀段时间的访问次数。把访问次数最少的淘汰掉.。
4)Random随机淘汰
从所有的key中抽取幸运儿被随机淘汰掉。
注意:
1)经过一段时间的动态平衡,redis中的数据逐渐就成为了热点数据。
2)具体采用哪种内存淘汰策略,需要根据业务具体问题具体分析。
Redis内置的淘汰策略
volatile-lru 当内存不足以容纳新写⼊数据时,从设置了过期时间的key中使用LRU(最近最少使用)算法进行淘汰。
allkeys-lru 当内存不足以容纳新写⼊数据时,从所有key中使⽤LRU(最近最少使用)算法进 进行淘汰。
volatile-lfu 4.0版本新增,当内存不足以容纳新写⼊数据时,在过期的key中,使用LFU算法 进行删除key。
allkeys-lfu 4.0版本新增,当内存不足以容纳新写⼊数据时,从所有key中使用LFU算法进行淘汰。
volatile-random 当内存不足以容纳新写入数据时,从设置了过期时间的key中,随机淘汰数据。
allkeys-random 当内存不足以容纳新写入数据时,从所有key中随机淘汰数据。
volatile-ttl 在设置了过期时间的key中,根据过期时间进行淘汰,越早过期的优先被淘汰.。(相当于FIFO,只不过是局限于过期的key)
noeviction 默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。
注意:
整体来说redis提供的策略和上述介绍的通用策略是基本⼀致的。只不过redis这里会针对 "过期key" 和 "全部key" 做分别处理。
缓存常见问题
缓存预热
1)定期更新缓存数据,不存在缓存预热情况,首次启动缓存,也会存在一些热点数据,不会给mysql服务造成太大压力。
2)实时更新缓存数据,缓存服务首次启动缓存中是没有数据的,这个时候mysql服务承载的压力就比较大。
解决方案:
通过离线的方式,向缓存服务导入一些热点数据,首次启动mysql服务就不会有太大压力。随着时间推移,缓存中数据逐渐就都成为热点数据了。
缓存穿透
查询某个key,redis中不存在,MySQL中也不存在,那么就不会在redis中进行存储。如果存在大量的这些查询,同样会给MySQL造成太大压力。
问题出现场景:
1)业务设计不合理,不如缺少必要的参数校验,导致非法key也被查询了。
2)开发/运维误操作,不小心把部分数据从MySQL中删除了。
3)黑客恶意攻击。
解决方案:
1)如果发现这个key,在redis和MySQL中都不存在,仍然写入redis中,value可设置一个非法值(比如“”),那么后续这些key的查询,在缓存中就可以查询到,就可以执行非法校验逻辑。
2)引入布隆过滤器,每次查询redis/MySQL时,都先判断一下key是否在布隆过滤器中存在。(把所有key都插入到布隆过滤器中),如果布隆过滤器不存在就不需要查询redis或MySQL,MySQL就不会有太大压力。
3)布隆过滤器:本质是结合了 hash + bitmap 不会存储真实数据,但可以判断是否存在。以比较小的空间开销,比较快的时间速度,实现争对key是否存在的判定。
缓存雪崩
由于在短时间内,redis上大规模的key失效,导致缓存命中率陡然下降,导致MySQL服务压力迅速上升,甚至直接宕机。
问题出现场景:
1)redis直接挂了,redis宕机 / redis集群模式下大量节点宕机。
2)redis没问题,但可能之前短时间内设置很多key到redis中,并且设置的过期时间都是相同的。
解决方案:
1)加强监控报警,保证redis集群的可用性。
2)不给key设置过期时间。
3)key设置过期时间的时候,添加随机因子,避免同一时刻同时失效。
缓存击穿
相当于缓存雪崩的特殊情况,针对热点key,突然过期了,导致大量请求直接访问数据库,甚至引起数据库直接宕机(热点key的访问频率高,请求数就多,影响更大)
解决方案:
1)基于统计的方式发现热点key,并且设置永不过期。
2)进行必要的服务降级,例如访问数据库的时候使用分布式锁,限制同时请求数据库的并发数。客户端响应时间会比较长,但不至于数据库服务直接挂了。
小结:
redis作为缓存场景是非常常见的,需要因地制宜选择适合自己业务的功能。
相关文章:

redis作为缓存详解
目录 前言: 为什么说关系型数据库性能不高 如何提高MySQL并发量 缓存更新策略 定期更新 实时更新 内存淘汰策略 Redis内置的淘汰策略 缓存常见问题 缓存预热 缓存穿透 缓存雪崩 缓存击穿 前言: 对于缓存的理解,缓存目的就是为了…...
231127 刷题日报
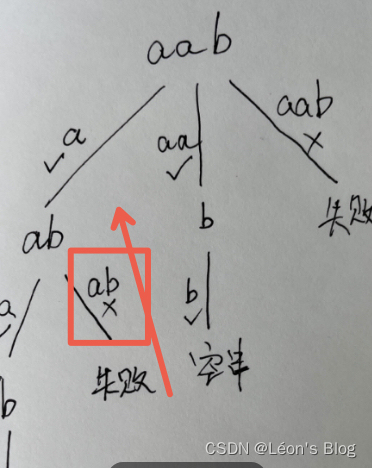
这周值班。。多少写道题吧,保持每天的手感。老婆给买了lubuladong纸质书,加油卷。 1. 131. 分割回文串 写个这个吧,钉在耻辱柱上的题。 为啥没写出来: 1. 递归树没画对 把树枝只看做是1个字母,而且不清楚树枝和节点…...
【Linux】vim-多模式的文本编辑器
本篇文章内容和干货较多,希望对大家有所帮助👍 目录 一、vim的介绍 1.1 vi 与 vim的概念1.2 Vim 和 Vi 的一些对比 二、vim 模式之间的切换 2.1 进入vim2.2 [正常模式]切换到[插入模式]2.3 [插入模式]切换至[正常模式]2.4 [正常模式]切换至[底行模式…...

Ubuntu 启用 root 用户
在启用 root 用户之前,我们先来了解一下, ubuntu 命令的组成。 打开 ubuntu 的终端,现在的命令行是由 topeetubuntu:~$ 这几个字母组成,那么这几个字母都代表 什么意思呢? topeet …...
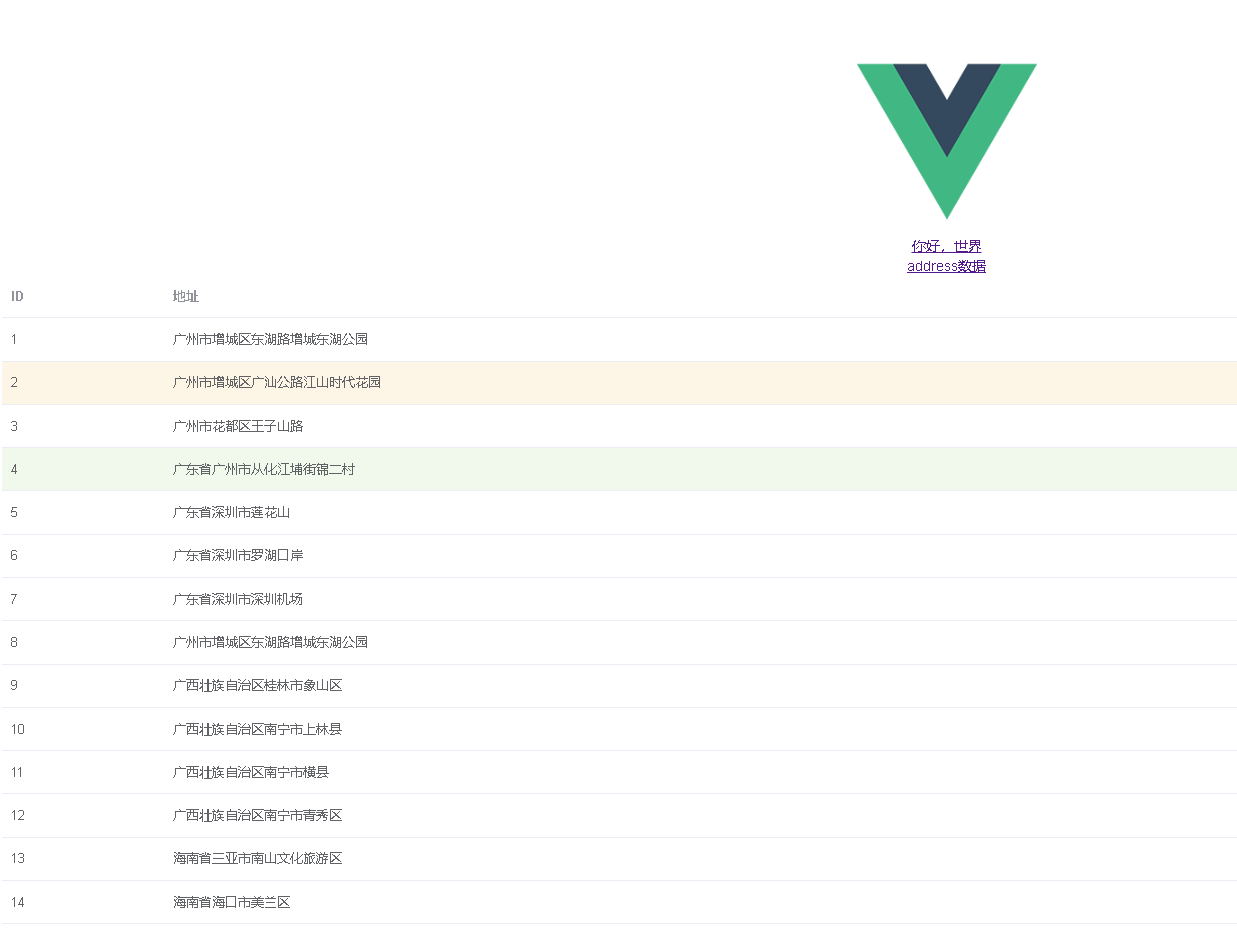
手摸手Element-ui路由VueRoute
后端WebAPI准备 https://router.vuejs.org/zh/guide/ https://v3.router.vuejs.org/zh/installation.html <template><el-table:data"tableData"style"width: 100%":row-class-name"tableRowClassName"><!-- <el-table-colum…...

探究Kafka原理-5.Kafka设计原理和生产者原理解析
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring源码、JUC源码、Kafka原理🔥如果感觉博主的文章还不错的话,请ὄ…...

浅谈C#在unity应用中的工厂模式
文章目录 前言简单工厂模式工厂方法模式抽象工厂模式Unity实战 前言 工厂模式是一种创建型设计模式,它提供了一种将对象的实例化过程封装起来的方法,使得客户端代码不必直接依赖于具体类。这有助于降低代码的耦合度,提高代码的可维护性和可扩…...

卷积神经网络(Inception-ResNet-v2)交通标志识别
文章目录 一、前言二、前期工作1. 设置GPU(如果使用的是CPU可以忽略这步)2. 导入数据3. 查看数据 二、构建一个tf.data.Dataset1.加载数据2. 配置数据集 三、构建Inception-ResNet-v2网络1.自己搭建2.官方模型 五、设置动态学习率六、训练模型七、模型评…...

网易云音频数据如何爬取?
在当今数字化时代,音频数据的获取和处理变得越来越重要。本文将详细介绍如何使用Objective-C语言构建音频爬虫程序,以爬取网易云音乐为案例。我们将从Objective-C的基础知识开始,逐步深入到爬取思路分析、构建爬虫框架、完整爬取代码等方面&a…...

97、Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields
简介 论文地址 使用扩散模型来推断文本相关图像作为内容先验,并使用单目深度估计方法来提供几何先验,并引入了一种渐进的场景绘制和更新策略,保证不同视图之间纹理和几何的一致性 实现流程 简单而言: 文本-图片扩散模型生成一…...
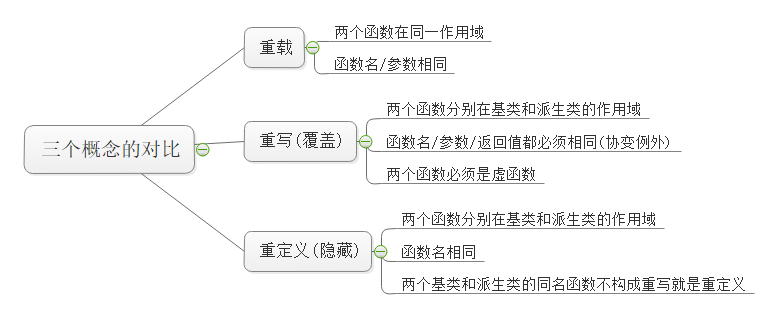
【C++】多态(上) 多态 | 虚函数 | 重写 | final、override | 接口继承与实现继承 | 抽象类
一、多态 概念 多态,就是多种状态,即不同的对象去完成同一个行为时会产生出不同的状态。比如:买票时,成人要原价买,学生和老人就可以享受优惠价便宜一点儿。同样是买票这个行为,不同的对象来做就有不同的…...

国内怎么投资黄金,炒黄金有哪些好方法?
随着我国综合实力的不断强大,投资市场的发展也日臻完善,现已成为了国际黄金市场的重要组成部分,人们想要精准判断金市走向,就离不开对我国经济等信息的仔细分析。而想要有效提升盈利概率,人们还需要掌握国内黄金投资的…...
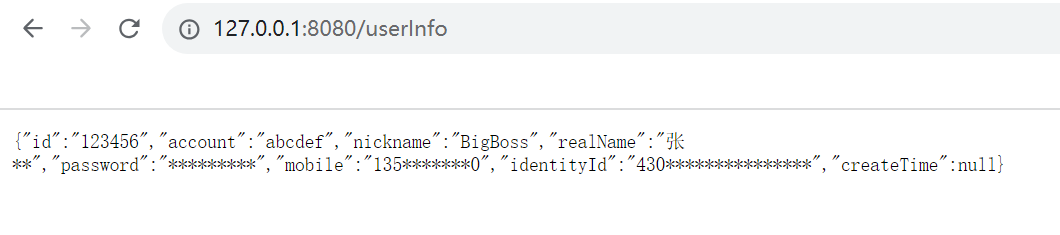
springboot实现数据脱敏
springboot实现数据脱敏 怎么说呢,写着写着发觉 ”这写的什么玩意“ 。 总的来说就是,这篇文章并不能解决数据脱敏问题,但以下链接可以。 SpringBoot中利用自定义注解优雅地实现隐私数据脱敏 然后回到本文,本来是想基于AOP代理&am…...
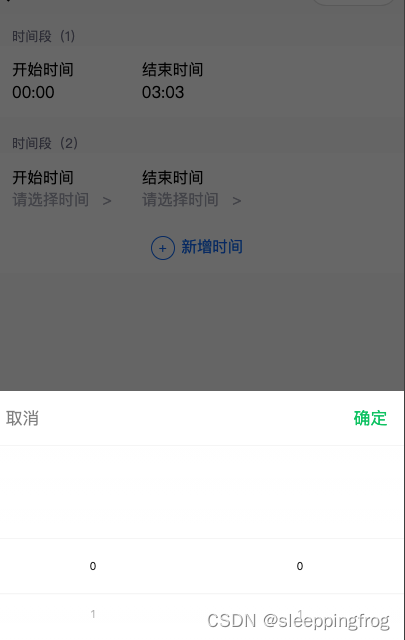
uniapp实现多时间段设置
功能说明: 1 点击新增时间,出现一个默认时间段模板,不能提交 2 点击“新增时间文本”,弹出弹窗,选择时间,不允许开始时间和结束时间同时为00:00, <view class"item_cont"> …...

uni-app - 去除隐藏页面右侧垂直滚动条
全局配置 "globalStyle": { //全局配置 "scrollIndicator":"none", // 不显示滚动条 "app-plus":{ "scrollIndicator":"none" // 在APP平台都不显示滚动条 } }局部配置 "path": "pages/ind…...
)
一次简单的 Http 请求异常处理 (请求的 url 太长, Nginx 直接返回 400, 导致请求服务异常)
1 结论 按照惯例直接说结论。 后台服务 A 有一个 Http 接口, 代码如下: RequestMapping(value "/user", method RequestMethod.GET) public List<UserInfoVo> getUserInfoByUserIds(RequestParam(value "userIds") List<String> userIds…...
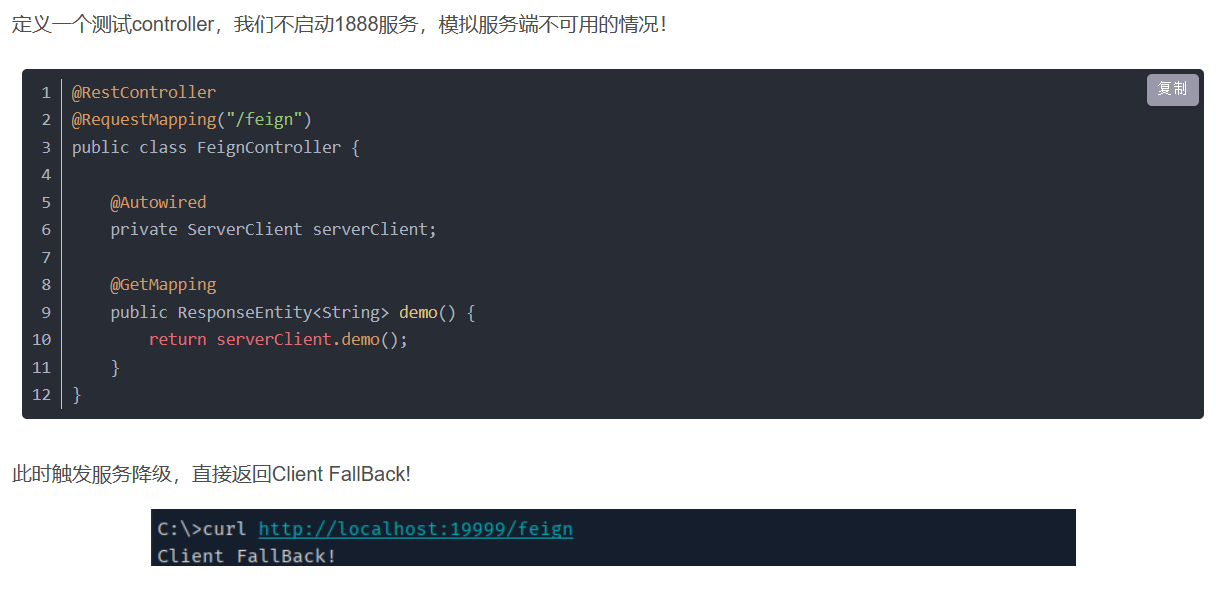
spring Cloud在代码中如何应用,erueka 客户端配置 和 服务端配置,Feign 和 Hystrix做高可用配置
文章目录 Eureka一、erueka 客户端配置二、eureka 服务端配置 三、高可用配置FeignHystrix 通过这篇文章来看看spring Cloud在代码中的具体应用,以及配置和注解; Eureka 一、erueka 客户端配置 1、Eureka 启禁用 eureka.client.enabledtrue 2、Eurek…...

C#8.0中新语法“is {}“的介绍及使用
一、C#7.0及之前is的使用 is操作符检查表达式的结果是否与给定类型兼容,或者(从c# 7.0开始)根据模式测试表达式。有关类型测试is操作符的信息,请参阅类型测试和类型转换操作符文章的is操作符部分。 1、is 模式匹配 从C࿰…...

编译器设计01-入门概述
编译器作用概述 源代码 → 编译器 目标代码 源代码\xrightarrow{\ \ \ 编译器\ \ \ }目标代码 源代码 编译器 目标代码 编译阶段概述 编译处理包括两个阶段:前端处理和后端处理,中间过程生成语法树。 编译处理:源代码 → 语法树 …...

SpringBoot封装Elasticsearch搜索引擎实现全文检索
一、前言 注:本文实现了Java对Elasticseach的分页检索/不分页检索的封装 ES就不用过多介绍了,直接上代码: 二、实现步骤: 创建Store类(与ES字段对应,用于接收ES数据) import com.alibaba.f…...

Intv_AI_MK11 跨平台开发应用:基于 Qt 框架的桌面智能助手
Intv_AI_MK11 跨平台开发应用:基于 Qt 框架的桌面智能助手 1. 为什么需要跨平台智能助手 在日常工作和学习中,我们经常遇到这样的场景:在Windows上收集的资料,想在Mac上继续编辑;在Linux服务器上开发的代码ÿ…...

【Python并发成本控制终极指南】:GIL移除后3大无锁模型选型公式与ROI量化对比表
第一章:Python无锁GIL环境下的并发成本控制全景图Python 的全局解释器锁(GIL)长期被视为多线程 CPU 密集型任务的性能瓶颈。然而,随着 CPython 3.13 引入实验性无锁 GIL(--without-pymalloc 配合 --with-experimental-…...

如何利用payload-dumper-go构建企业级Android OTA安全验证流水线
如何利用payload-dumper-go构建企业级Android OTA安全验证流水线 【免费下载链接】payload-dumper-go an android OTA payload dumper written in Go 项目地址: https://gitcode.com/gh_mirrors/pa/payload-dumper-go 在Android生态系统的持续交付流程中,OTA…...

利用codex与快马平台,十分钟快速生成待办事项应用原型
最近在尝试快速验证一个待办事项应用的想法,发现用InsCode(快马)平台配合AI模型真的能十分钟就搞出可运行的原型。整个过程特别适合像我这样想快速验证产品概念的人,记录下具体操作和思考过程。 明确核心功能需求 首先梳理出最简功能清单:输入…...

seo网络排名优化如何选择关键词
SEO网络排名优化如何选择关键词 在当今数字化时代,搜索引擎优化(SEO)已经成为了每个网站和网络企业不可忽视的一部分。其中,关键词选择是影响网站排名的核心环节。如何选择最合适的关键词,以优化SEO网络排名呢&#x…...

5分钟部署MGeo:中文地址相似度识别零基础教程
5分钟部署MGeo:中文地址相似度识别零基础教程 你是不是遇到过这样的问题?手里有两份地址数据,一份来自电商订单,一份来自物流系统,明明应该是同一个地方,但写法五花八门——“北京市朝阳区望京街1号”、“…...

黑客马拉松利器:OpenClaw+SecGPT-14B快速构建安全PoC
黑客马拉松利器:OpenClawSecGPT-14B快速构建安全PoC 1. 缘起:当安全专家遇上自动化助手 去年参加某次网络安全竞赛时,我遇到了一个典型痛点:在48小时的黑客马拉松中,团队需要快速验证多个漏洞猜想,但手动…...

像素极光入门指南:像插入游戏卡一样加载模型,快速生成梦幻像素风景
像素极光入门指南:像插入游戏卡一样加载模型,快速生成梦幻像素风景 1. 认识像素极光创意引擎 像素极光(Pixel Aurora Engine)是一款专为像素艺术创作设计的AI绘图工作站。它采用复古游戏机风格界面,让AI绘画变得像玩游戏一样简单有趣。与传…...

OpenClaw异常处理:Qwen3-4B模型的任务失败恢复机制
OpenClaw异常处理:Qwen3-4B模型的任务失败恢复机制 1. 为什么需要关注OpenClaw的异常处理? 上周我让OpenClaw帮我整理一个月的会议录音转文字稿,结果第二天发现它卡在第七个文件就停止了。这种半途而废的情况在使用本地大模型时特别常见——…...

Rails API应用数据一致性终极指南:乐观锁与悲观锁对比详解
Rails API应用数据一致性终极指南:乐观锁与悲观锁对比详解 【免费下载链接】rails-api Rails for API only applications 项目地址: https://gitcode.com/gh_mirrors/ra/rails-api 在现代Web应用开发中,数据一致性是API设计的核心挑战之一。Rails…...