【深度学习笔记】04 概率论基础
04 概率论基础
- 概率论公理
- 联合概率
- 条件概率
- 贝叶斯定理
- 边际化
- 独立性
- 期望和方差
- 模拟投掷骰子的概率随投掷次数增加的变化
概率论公理
概率(probability)可以被认为是将集合映射到真实值的函数。
在给定的样本空间 S \mathcal{S} S中,事件 A \mathcal{A} A的概率,
表示为 P ( A ) P(\mathcal{A}) P(A),满足以下属性:
- 对于任意事件 A \mathcal{A} A,其概率从不会是负数,即 P ( A ) ≥ 0 P(\mathcal{A}) \geq 0 P(A)≥0;
- 整个样本空间的概率为 1 1 1,即 P ( S ) = 1 P(\mathcal{S}) = 1 P(S)=1;
- 对于互斥(mutually exclusive)事件(对于所有 i ≠ j i \neq j i=j都有 A i ∩ A j = ∅ \mathcal{A}_i \cap \mathcal{A}_j = \emptyset Ai∩Aj=∅)的任意一个可数序列 A 1 , A 2 , … \mathcal{A}_1, \mathcal{A}_2, \ldots A1,A2,…,序列中任意一个事件发生的概率等于它们各自发生的概率之和,即 P ( ⋃ i = 1 ∞ A i ) = ∑ i = 1 ∞ P ( A i ) P(\bigcup_{i=1}^{\infty} \mathcal{A}_i) = \sum_{i=1}^{\infty} P(\mathcal{A}_i) P(⋃i=1∞Ai)=∑i=1∞P(Ai)。
联合概率
P ( A = a , B = b ) P(A=a,B=b) P(A=a,B=b)
给定任意值 a a a和 b b b,联合概率可以回答: A = a A=a A=a和 B = b B=b B=b同时满足的概率是多少?
对于任何 a a a和 b b b的取值, P ( A = a , B = b ) ≤ P ( A = a ) P(A = a, B=b) \leq P(A=a) P(A=a,B=b)≤P(A=a)。
条件概率
0 ≤ P ( A = a , B = b ) P ( A = a ) ≤ 1 0 \leq \frac{P(A=a, B=b)}{P(A=a)} \leq 1 0≤P(A=a)P(A=a,B=b)≤1。
我们称这个比率为条件概率(conditional probability),
并用 P ( B = b ∣ A = a ) P(B=b \mid A=a) P(B=b∣A=a)表示它:它是 B = b B=b B=b的概率,前提是 A = a A=a A=a已发生。
贝叶斯定理
根据乘法法则(multiplication rule )可得到 P ( A , B ) = P ( B ∣ A ) P ( A ) P(A, B) = P(B \mid A) P(A) P(A,B)=P(B∣A)P(A)。
根据对称性,可得到 P ( A , B ) = P ( A ∣ B ) P ( B ) P(A, B) = P(A \mid B) P(B) P(A,B)=P(A∣B)P(B)。
假设 P ( B ) > 0 P(B)>0 P(B)>0,求解其中一个条件变量,我们得到
P ( A ∣ B ) = P ( B ∣ A ) P ( A ) P ( B ) . P(A \mid B) = \frac{P(B \mid A) P(A)}{P(B)}. P(A∣B)=P(B)P(B∣A)P(A).
其中 P ( A , B ) P(A, B) P(A,B)是一个联合分布(joint distribution),
P ( A ∣ B ) P(A \mid B) P(A∣B)是一个条件分布(conditional distribution)。
这种分布可以在给定值 A = a , B = b A = a, B=b A=a,B=b上进行求值。
边际化
为了能进行事件概率求和,需要求和法则(sum rule),
即 B B B的概率相当于计算 A A A的所有可能选择,并将所有选择的联合概率聚合在一起:
P ( B ) = ∑ A P ( A , B ) , P(B) = \sum_{A} P(A, B), P(B)=A∑P(A,B),
这也称为边际化(marginalization)。
边际化结果的概率或分布称为边际概率(marginal probability)
或边际分布(marginal distribution)。
独立性
如果两个随机变量 A A A和 B B B是独立的,意味着事件 A A A的发生跟 B B B事件的发生无关。
在这种情况下,通常将这一点表述为 A ⊥ B A \perp B A⊥B。
根据贝叶斯定理,马上就能同样得到 P ( A ∣ B ) = P ( A ) P(A \mid B) = P(A) P(A∣B)=P(A)。
在所有其他情况下,我们称 A A A和 B B B依赖。
由于 P ( A ∣ B ) = P ( A , B ) P ( B ) = P ( A ) P(A \mid B) = \frac{P(A, B)}{P(B)} = P(A) P(A∣B)=P(B)P(A,B)=P(A)等价于 P ( A , B ) = P ( A ) P ( B ) P(A, B) = P(A)P(B) P(A,B)=P(A)P(B),
因此两个随机变量是独立的,当且仅当两个随机变量的联合分布是其各自分布的乘积。
同样地,给定另一个随机变量 C C C时,两个随机变量 A A A和 B B B是条件独立的(conditionally independent),
当且仅当 P ( A , B ∣ C ) = P ( A ∣ C ) P ( B ∣ C ) P(A, B \mid C) = P(A \mid C)P(B \mid C) P(A,B∣C)=P(A∣C)P(B∣C)。
这个情况表示为 A ⊥ B ∣ C A \perp B \mid C A⊥B∣C。
期望和方差
一个随机变量 X X X的期望(expectation,或平均值(average))表示为
E [ X ] = ∑ x x P ( X = x ) . E[X] = \sum_{x} x P(X = x). E[X]=x∑xP(X=x).
当函数 f ( x ) f(x) f(x)的输入是从分布 P P P中抽取的随机变量时, f ( x ) f(x) f(x)的期望值为
E x ∼ P [ f ( x ) ] = ∑ x f ( x ) P ( x ) . E_{x \sim P}[f(x)] = \sum_x f(x) P(x). Ex∼P[f(x)]=x∑f(x)P(x).
在许多情况下,我们希望衡量随机变量 X X X与其期望值的偏置。这可以通过方差来量化
V a r [ X ] = E [ ( X − E [ X ] ) 2 ] = E [ X 2 ] − E [ X ] 2 . \mathrm{Var}[X] = E\left[(X - E[X])^2\right] = E[X^2] - E[X]^2. Var[X]=E[(X−E[X])2]=E[X2]−E[X]2.
方差的平方根被称为标准差(standard deviation)。
随机变量函数的方差衡量的是:当从该随机变量分布中采样不同值 x x x时,
函数值偏离该函数的期望的程度:
V a r [ f ( x ) ] = E [ ( f ( x ) − E [ f ( x ) ] ) 2 ] . \mathrm{Var}[f(x)] = E\left[\left(f(x) - E[f(x)]\right)^2\right]. Var[f(x)]=E[(f(x)−E[f(x)])2].
模拟投掷骰子的概率随投掷次数增加的变化
%matplotlib inline
import torch
from torch.distributions import multinomial
from d2l import torch as d2l
为了抽取像本,即掷骰子,我们只需为了抽取一个样本,
输出是另一个相同长度的向量:它在索引 i i i处的值是采样结果中 i i i出现的次数。
fair_probs = torch.ones([6]) / 6
multinomial.Multinomial(1, fair_probs).sample()
tensor([0., 1., 0., 0., 0., 0.])
使用PyTorch框架的函数同时抽取多个样本,得到我们想要的任意形状的独立样本数组
multinomial.Multinomial(10, fair_probs).sample()
tensor([3., 2., 0., 3., 1., 1.])
模拟1000次投掷,
然后统计1000次投掷后,每个数字被投中了多少次。
# 将结果存储为32位浮点数以进行除法
counts = multinomial.Multinomial(1000, fair_probs).sample()
counts / 1000 # 相对频率作为估计值
tensor([0.1650, 0.1650, 0.1720, 0.1750, 0.1610, 0.1620])
进行500组实验,每组抽取10个样本。
counts = multinomial.Multinomial(10, fair_probs).sample((500,))
cum_counts = counts.cumsum(dim=0)
estimates = cum_counts / cum_counts.sum(dim=1, keepdims=True)d2l.set_figsize((6, 4.5))
for i in range(6):d2l.plt.plot(estimates[:, i].numpy(),label=("P(die=" + str(i + 1) + ")"))
d2l.plt.axhline(y=0.167, color='black', linestyle='dashed')
d2l.plt.gca().set_xlabel('Groups of experiments')
d2l.plt.gca().set_ylabel('Estimated probability')
d2l.plt.legend();
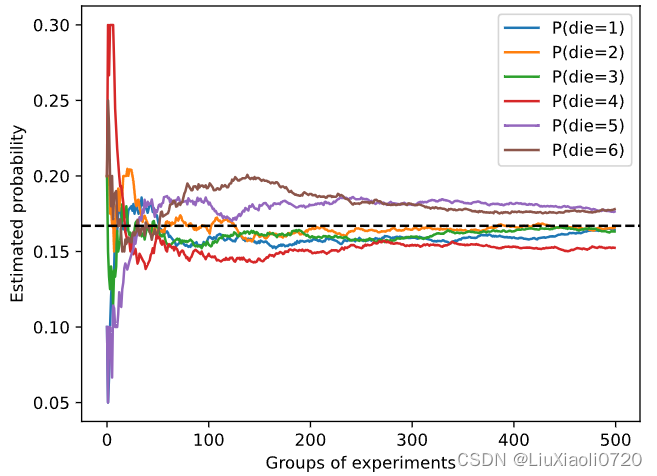
每条实线对应于骰子的6个值中的一个,并给出骰子在每组实验后出现值的估计概率。
当我们通过更多的实验获得更多的数据时,这 6 6 6条实体曲线向真实概率收敛。
相关文章:
【深度学习笔记】04 概率论基础
04 概率论基础 概率论公理联合概率条件概率贝叶斯定理边际化独立性期望和方差模拟投掷骰子的概率随投掷次数增加的变化 概率论公理 概率(probability)可以被认为是将集合映射到真实值的函数。 在给定的样本空间 S \mathcal{S} S中,事件 A \m…...

45.113.200.1搜索引擎蜘蛛抓取不到网站内容页面可能的原因
以下是搜索引擎蜘蛛抓取不到网站内容页面的一些主要原因总结: 网站的 robots.txt 文件中禁止了搜索引擎蜘蛛访问网站某些页面或目录,导致搜索引擎无法抓取到相关页面的内容。 网站的页面存在重定向或者跳转,搜索引擎蜘蛛无法直接抓取到需要的…...

VMware 系列:vSphere Client安装配置常见问题及解决方案
vSphere Client安装配置常见问题及解决方案 1.本地通过远程桌面复制文件或者文件夹到windows服务器时出错提示“未指定的错误”问题描述:原因分析:解决方案:方法 1方法 2方法 32.远程桌面连接出现身份验证错误要求的函数不受支持问题描述:原因分析:解决方案:3.Windows se…...
FLASK博客系列5——模板之从天而降
我们啰啰嗦嗦讲了4篇,都是在调接口,啥时候能看到漂亮的页面呢?别急,今天我们就来实现。 来我们先来实现一个简单的页面。不多说,上代码。 app.route(/) def index():user {username: clannadhh}return <html>&…...

6.一维数组——用冒泡法将10个整数由大到小排序
文章目录 前言一、题目描述 二、题目分析 三、解题 程序运行代码 前言 本系列为一维数组编程题,点滴成长,一起逆袭。 一、题目描述 用冒泡法将10个整数由大到小排序 二、题目分析 三、解题 程序运行代码 #include<stdio.h> int main() {int …...
Wireshark的捕获过滤器
Wireshark的过滤器,顾名思义,作用是对数据包进行过滤处理。具体过滤器包括捕获过滤器和显示过滤器。本文对捕获过滤器进行分析。 捕获过滤器:当进行数据包捕获时,只有那些满足给定的包含/排除表达式的数据包会被捕获。 捕获过滤器…...

安陆FPGA调试中遇到的问题总结
参考链接:安陆FPGA踩坑填坑记录(梦里呓语回忆录)_fpga开发是个大坑-CSDN博客 上海安陆FPGA设置重上电启动速度_安路 fpga 加载时间-CSDN博客...

Springboot2+WebSocket
一、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId> </dependency> 二、添加配置 新增配置文件 config/WebSocketConfig.java import org.springframewo…...

希尔伯特和包络变换
一、希尔伯特变换 Hilbert Transform,数学定义:在数学与信号处理的领域中,一个实值函数的希尔伯特变换是将信号x(t)与h(t)1/(πt)做卷积,以得到其希尔伯特变换。因此,希尔伯特变换结果可以理解为输入是x(t)的线性时不…...

国产Ai大模型和chtgpt3.5的比较
下面是针对国产大模型,腾讯混元,百度文心一言,阿里通义千问和chatgpt的比较,最基础的对一篇文章的单词书进行统计,只有文心一言和chatgpt回答差不多,阿里和腾讯差太多了...

机器学习ROC曲线中的阈值thresholds
在ROC(Receiver Operating Characteristic)曲线中,阈值(thresholds)是一个用于分类模型的概率或分数的截断值。ROC曲线的绘制涉及使用不同的阈值来计算真正例率(True Positive Rate,TPR…...

MySOL常见四种连接查询
1、内联接 (典型的联接运算,使用像 或 <> 之类的比较运算符)。包括相等联接和自然联接。 内联接使用比较运算符根据每个表共有的列的值匹配两个表中的行。例如,检索 students和courses表中学生标识号相同的所有行。 2、…...
数智融合 开启金融数据治理新时代
11月24日,由上海罗盘信息科技有限公司(罗盘科技)主办,北京酷克数据科技有限公司(酷克数据)支持协办的“博学近思 切问治理”数据治理分享会在上海成功举行。 本次会议深度聚焦金融行业数智化转型ÿ…...

数据结构——利用堆进行对数组的排序
今天文章的内容是关于我们如何利用堆的特性对我们的数组进行排序,还有就是我们的TopK的问题,这次我们放在的是文件种,我们放入一亿个数字,然后我们取出一亿个数字中最大的十个数,利用上章堆的问题进行解决。 首先就是我…...
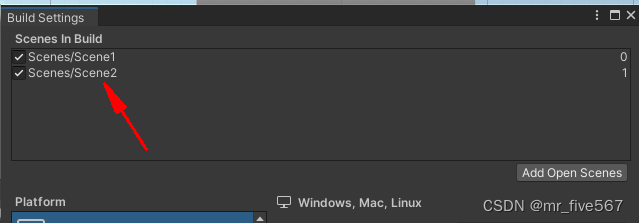
Unity 场景切换
Unity场景切换可使用以下方法: 1、SceneManager.LoadScene()方法: using UnityEngine.SceneManagement;// 切换到Scene2场景 SceneManager.LoadScene("Scene2"); 2、使用SceneManager.LoadSceneAsync()方法异步加载场景,异步加载…...

【PTA题目】7-12 N个数求和 分数 20
7-12 N个数求和 分数 20 全屏浏览题目 切换布局 作者 陈越 单位 浙江大学 本题的要求很简单,就是求N个数字的和。麻烦的是,这些数字是以有理数分子/分母的形式给出的,你输出的和也必须是有理数的形式。 输入格式: 输入第一行…...
智能AIGC写作系统ChatGPT系统源码+Midjourney绘画+支持GPT-4-Turbo模型+支持GPT-4图片对话
一、AI创作系统 SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI…...

List转string 逗号分隔
List转string 逗号分隔 1、将list转化为逗号分割的字符串 String str String.join(",", list); String str StringUtils.json(list.toArray(), ","); 2、将逗号分隔的字符串转换为List List<String> list Arrays.asList(str.split("…...
手机文件怎么传到电脑?简单方法分享!
将手机文件传输到电脑可以将其备份,以防数据丢失或意外情况发生。并且电脑具有更强大的处理能力,可以将文件进行编辑、修改、转换等操作,大大提高了工作效率。那么,手机文件怎么传到电脑?本文将为大家提供简单易懂的解…...
计算机基础知识59
MySQL的卸载流程 1、先停止MySQL服务:右键“此电脑”,选择“管理”,之后选择“服务和应用程序”--“服务”,在服务中找到“MySQL”,右键选择“停止”。 2、找到“控制面板”--“程序和功能”,找到MySQL&…...

零基础学唱歌全套教程 声乐技巧入门到进阶资源
很多想自学唱歌的朋友,应该都有过这样的困扰:想入门却不知道从哪一步开始,网上找的教程要么太零散,知识点前后接不上;要么内容太晦涩,完全摸不着门道。这段时间我整理了一批适配不同学习阶段的唱歌相关教程…...

Git从入门到精通:原理、实战与企业级协作全攻略
Git从入门到精通:原理、实战与企业级协作全攻略 文章目录Git从入门到精通:原理、实战与企业级协作全攻略Git从入门到精通:原理、实战与企业级协作全攻略前言:为什么每个开发者都必须掌握Git?第一部分:Git初…...

跨境支付风控难?查IP归属地如何识别交易风险与合规隐患
凌晨两点,某跨境支付平台的风控系统突然告警:一笔从东南亚IP发起的交易,试图从一张欧洲信用卡向非洲账户转账。系统立即拦截,事后确认这是一起典型的跨境洗钱行为。这不是偶然,而是查IP归属地技术在交易风控中的日常应…...

BsMax:让3D艺术家无缝切换Blender的专业级工具集
BsMax:让3D艺术家无缝切换Blender的专业级工具集 【免费下载链接】BsMax BsMax Blender Addon (UI simulator/ Modeling/ Rigg & Animation/ Render Tools and ... 项目地址: https://gitcode.com/gh_mirrors/bs/BsMax 你是否曾经因为Blender的操作习惯与…...

2025届学术党必备的降重复率神器实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于人工智能生成内容即AIGC广泛运用的背景状况之下,将AIGC率予以降低成了内容创作…...

数据分析师课程
数据分析是什么定义:运用统计分析方法对收集的数据进行汇总、理解和消化,最大化开发数据功能数据形式:观测值通过实验/测量获得,常以图表或表格呈现分类体系:描述性分析(初级):占日常…...

2025届毕业生推荐的AI科研网站解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在当下这个学术写作的环境当中,论文AI工具已然变成了研究者用来提高效率的极为重…...

终极无损音频压缩指南:FLAC 1.5.0完整教程与实战应用
终极无损音频压缩指南:FLAC 1.5.0完整教程与实战应用 【免费下载链接】flac Free Lossless Audio Codec 项目地址: https://gitcode.com/gh_mirrors/fl/flac 在数字音频的世界中,存储空间与音质质量往往难以兼得,但FLAC(Fr…...

HsMod:55+创新功能重新定义炉石传说体验
HsMod:55创新功能重新定义炉石传说体验 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod 🌟 项目核心价值概述 HsMod作为基于BepInEx框架的炉石传说模改插件…...

Matplotlib横坐标刻度从原点开始的3种实用方法
1. 为什么横坐标刻度从原点开始很重要 做数据可视化时,我们经常需要展示数据从零开始的变化趋势。比如展示销售额增长、用户数量变化或者实验数据对比时,如果横坐标不从零开始,很容易造成视觉上的误导。我见过不少新手做的图表,因…...