oracle数据库巡检常见脚本-系列二
简介
作为数据库管理员(DBA),定期进行数据库的日常巡检是非常重要的。以下是一些原因:
保证系统的稳定性:通过定期巡检,DBA可以发现并及时解决可能导致系统不稳定的问题,如性能瓶颈、资源利用率过高或磁盘空间不足等。
提高数据的安全性:巡检可以帮助DBA发现潜在的安全风险,例如未经授权的访问、数据泄露或其他安全漏洞。及时采取措施,可以防止这些风险演变成实际问题。
避免数据丢失:DBA可以通过检查备份和恢复策略来确保数据的完整性,并确保在发生灾难时能够快速恢复业务运营。
确保合规性:许多行业都有特定的数据管理规定和法规要求。通过巡检,DBA可以确保他们的数据库管理系统符合这些规定和要求。
性能优化:巡检可以帮助DBA识别性能瓶颈,从而优化数据库以提高其效率和响应速度。
资源规划:通过巡检,DBA可以了解当前的资源使用情况,预测未来的资源需求,并根据需要调整资源配置。
综上所述,DBA的日常巡检是保持数据库健康运行的关键环节之一,也是确保业务连续性和高效运行的重要步骤。
目录
简介
17、TOP 10 逻辑读排序
18、TOP 10 CPU排序
19、查询等待事件
20、查询当前正在消耗temp空间的sql语句
21、查询需要使用绑定变量的sql,10G以后推荐第二种
一、
二、
22、查看数据文件可用百分比
23、查看表空间可用百分比
24、查看临时表空间使用率
25、查询undo表空间使用情况
26、查看ASM磁盘组使用率
27、统计每个用户使用表空间率
17、TOP 10 逻辑读排序
select *from (select BUFFER_GETS,username,PARSING_USER_ID,sql_id,ELAPSED_TIME / 1000000,sql_textfrom v$sql, dba_userswhere user_id = PARSING_USER_IDorder by BUFFER_GETS desc)where rownum <= 10;
 BUFFER_GETS:这个字段表示SQL语句在数据库中获取了多少次数据,也就是这个SQL被执行了多少次。
BUFFER_GETS:这个字段表示SQL语句在数据库中获取了多少次数据,也就是这个SQL被执行了多少次。
USERNAME:这个字段表示执行SQL语句的用户名。
PARSING_USER_ID:这个字段表示解析SQL的用户ID。
SQL_ID:这个字段表示SQL语句的唯一ID。
ELAPSED_TIME / 1000000:这个字段表示SQL语句执行所花费的时间(单位是秒)。
SQL_TEXT:这个字段表示SQL语句的内容。
"逻辑读排序":是ORACLE中一种用于优化查询性能的技术。当ORACLE执行一个查询时,它需要读取和解析SQL语句。如果一个表有很多行,或者有很多列,那么读取和解析这些数据可能会花费很长时间。因此,ORACLE使用了一种叫做"逻辑读排序"的技术,这种技术可以使得查询优化器能够预测哪些行将会被需要,并提前读取这些行,从而减少了读取和解析的时间。这种技术对于大数据量的表特别有用,因为它可以显著提高查询性能。
注:(不要使用DISK_READS/ EXECUTIONS来排序,因为任何一条语句不管执行几次都会耗逻辑读和cpu,可能不会耗物理读(遇到LRU还会耗物理读,LRU规则是执行最不频繁的且最后一次执行时间距离现在最久远的就会被交互出buffer cache),是因为buffer cache存放的是数据块,去数据块里找行一定会消耗cpu和逻辑读的。Shared pool执行存放sql的解析结果,sql执行的时候只是去share pool中找hash value,如果有匹配的就是软解析。所以物理读逻辑读是在buffer cache中,软解析硬解析是在shared pool)
18、TOP 10 CPU排序
select *from (select CPU_TIME / 1000000,username,PARSING_USER_ID,sql_id,ELAPSED_TIME / 1000000,sql_textfrom v$sql, dba_userswhere user_id = PARSING_USER_IDorder by CPU_TIME / 1000000 desc)where rownum <= 10;
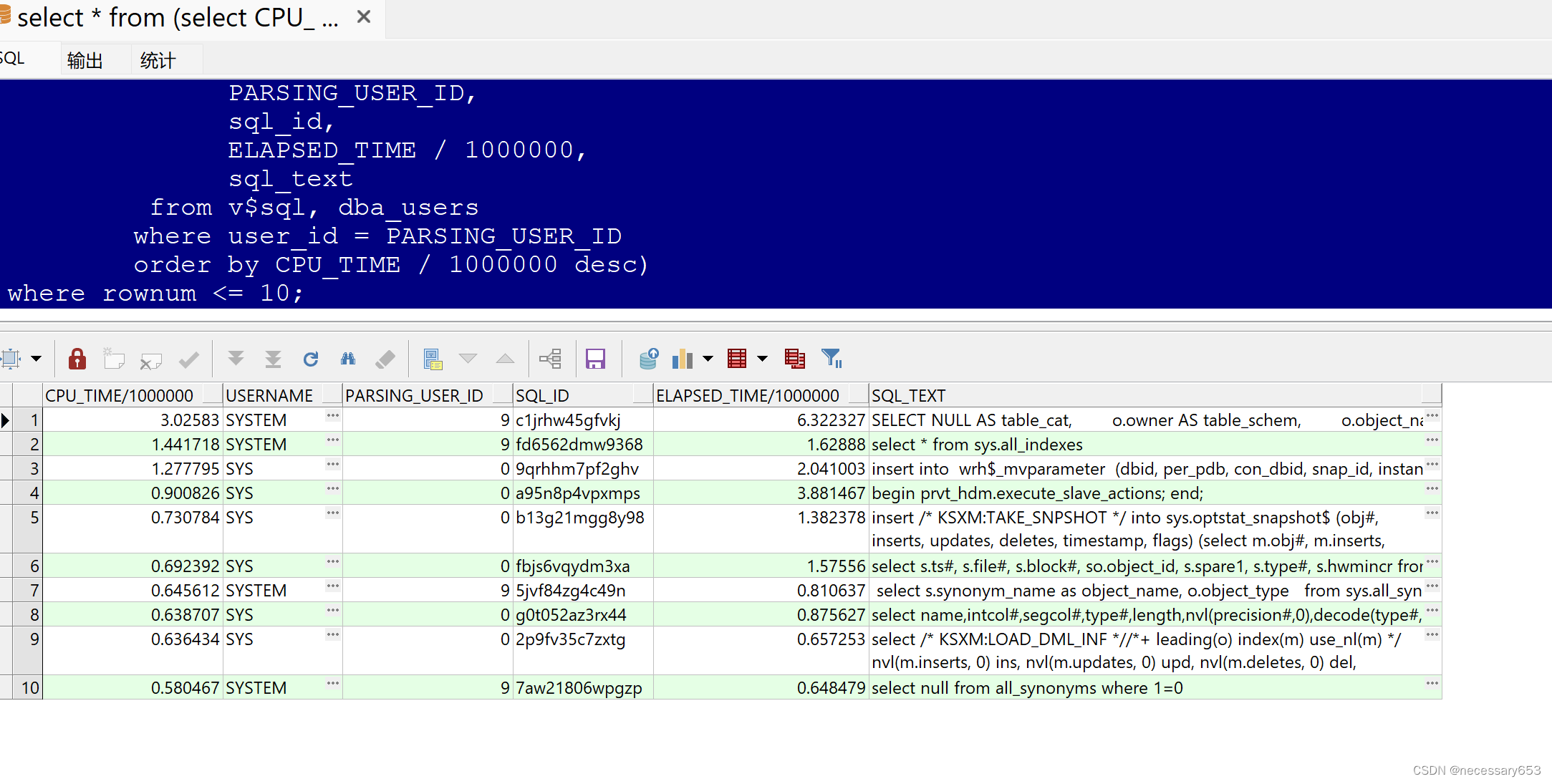 CPU_TIME / 1000000:这个字段表示SQL语句在数据库中执行时所消耗的CPU时间(单位是秒)。
CPU_TIME / 1000000:这个字段表示SQL语句在数据库中执行时所消耗的CPU时间(单位是秒)。
USERNAME:这个字段表示执行SQL语句的用户名。
PARSING_USER_ID:这个字段表示解析SQL的用户ID。
SQL_ID:这个字段表示SQL语句的唯一ID。
ELAPSED_TIME / 1000000:这个字段表示SQL语句执行所花费的总时间(单位是秒)。
SQL_TEXT:这个字段表示SQL语句的内容。
当数据库执行一个SQL语句时,它会在CPU上运行,消耗一定的CPU时间。通过使用CPU排序,我们可以找出最消耗CPU时间的SQL语句,从而优化它们以提高数据库的性能。这种技术特别适用于找出那些需要大量计算和处理的SQL语句,因为这些语句通常会对数据库的性能产生最大的影响。
19、查询等待事件
select event,sum(decode(wait_time, 0, 0, 1)) "之前等待次数",sum(decode(wait_time, 0, 1, 0)) "正在等待次数",count(*)from v$session_waitgroup by eventorder by 4 desc
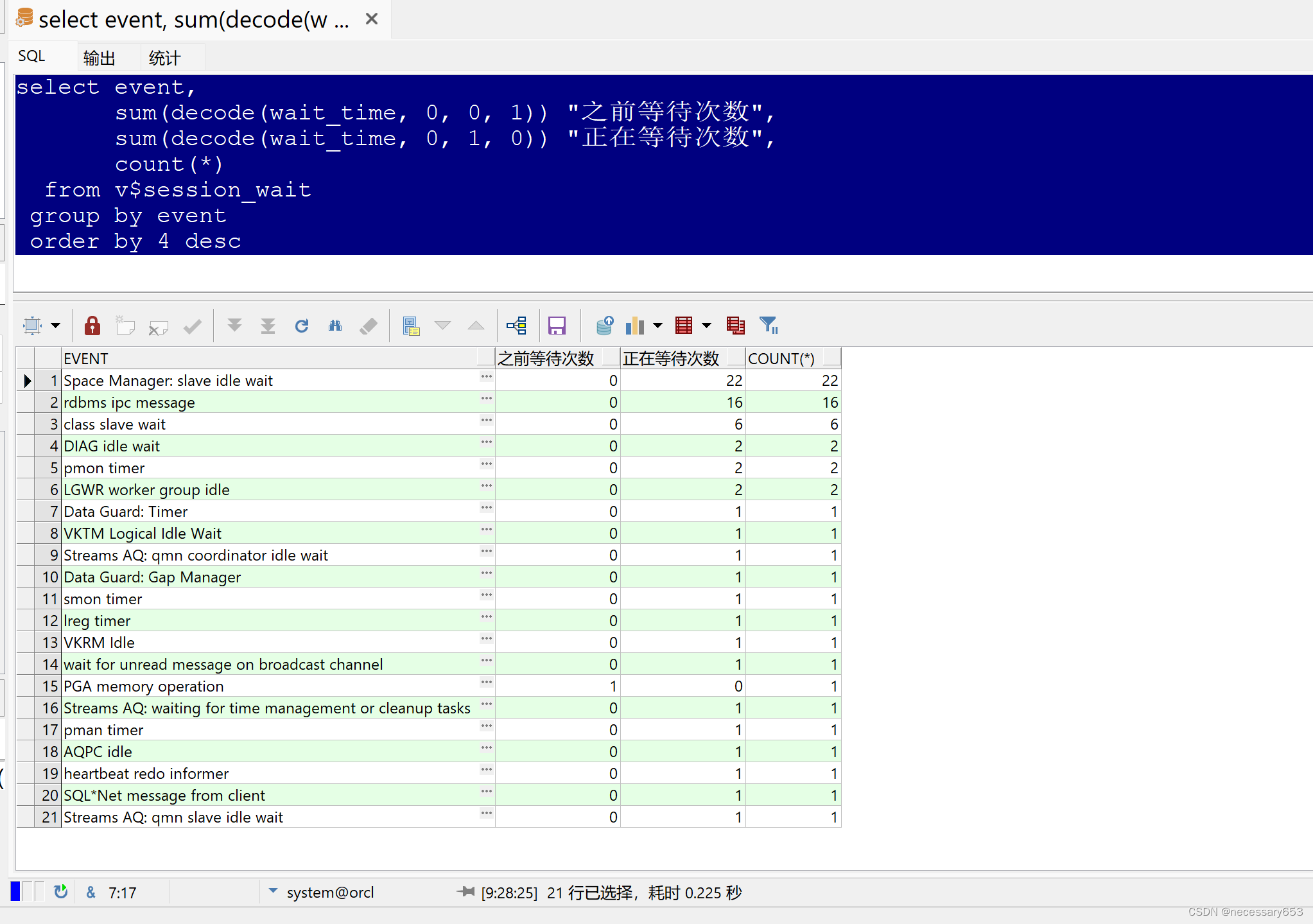
EVENT:这个字段表示等待事件的类型。等待事件是指在数据库操作过程中,用户需要等待资源释放的情况。
SUM(DECODE(WAIT_TIME, 0, 0, 1)) "之前等待次数":这个字段表示在等待时间(WAIT_TIME)为0的情况下,该事件发生的次数。如果等待时间为0,说明该事件没有发生过。
SUM(DECODE(WAIT_TIME, 0, 1, 0)) "正在等待次数":这个字段表示在等待时间不为0的情况下,该事件发生的次数。如果等待时间不为0,说明该事件正在发生。
COUNT(*):这个字段表示该事件发生的总次数。
该查询从V$SESSION_WAIT视图中获取数据,这是一个包含数据库中所有会话的等待事件信息的视图。它会根据等待事件的类型(EVENT)进行分组,并按照等待事件的次数进行降序排序。
在ORACLE数据库中,等待事件是常见的性能问题分析工具。通过分析等待事件,我们可以了解数据库的资源使用情况、会话的活动情况以及可能存在的性能瓶颈。例如,如果"LOG FILE SYNC"事件的等待次数很多,可能意味着磁盘I/O存在问题;如果"ROW LOCK"事件的等待次数很多,可能意味着存在竞争行锁的情况等。
之前的文章有列举出关于等待事件名称对应的数据库事件情况的列表。
20、查询当前正在消耗temp空间的sql语句
Select distinct se.username,se.sid,su.blocks * to_number(rtrim(p.value)) / 1024 / 1024 as space_G,su.tablespace,sql_textfrom V$TEMPSEG_USAGE su, v$parameter p, v$session se, v$sql swhere p.name = 'db_block_size'and su.session_addr = se.saddrand su.sqlhash = s.hash_valueand su.sqladdr = s.address
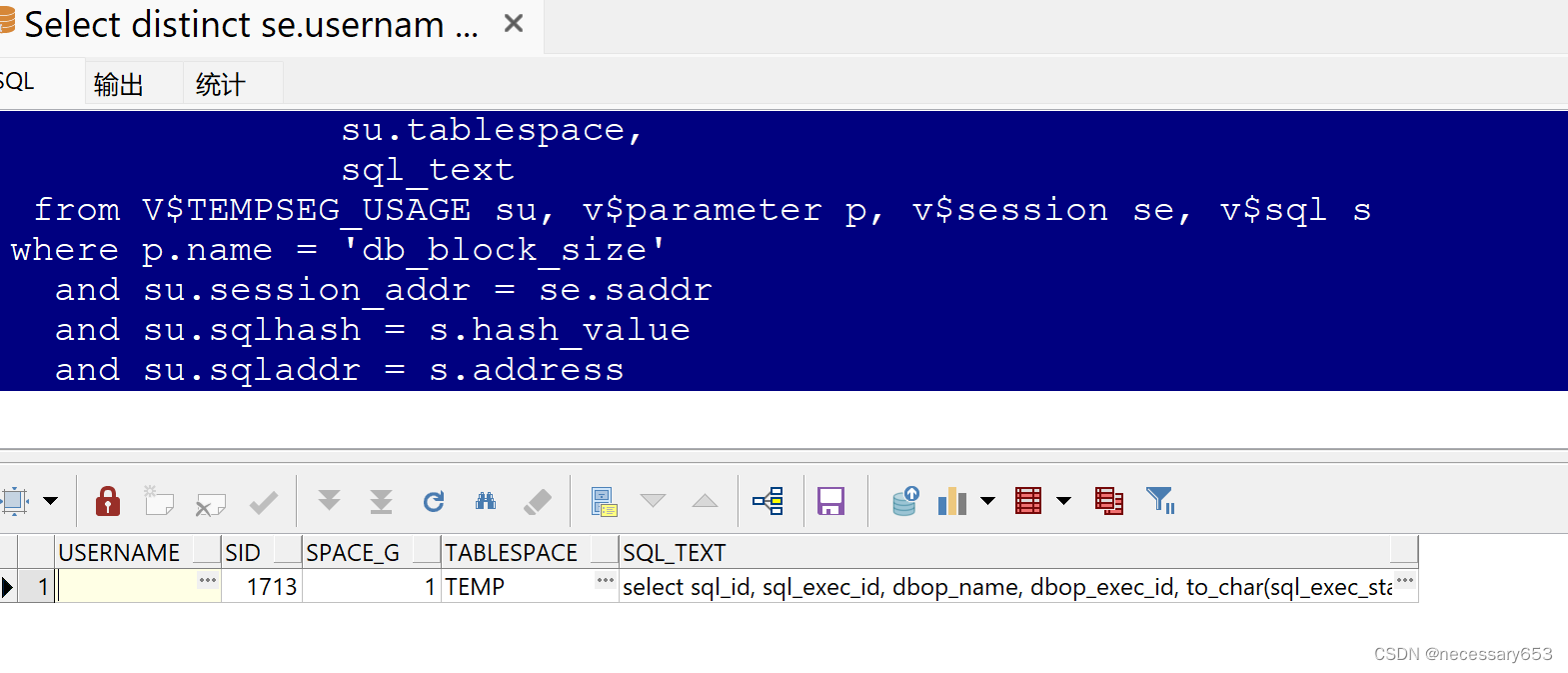
USERNAME: 用户名,表示正在使用临时空间的会话所属的用户。
SID: 会话ID,表示正在使用临时空间的会话的唯一标识符。
BLOCKS * TO_NUMBER(RTRIM(P.VALUE)) / 1024 / 1024 AS SPACE_G: 这部分计算了临时空间使用的空间大小,单位是G字节。其中,SU.BLOCKS表示临时空间使用的块数,TO_NUMBER(RTRIM(P.VALUE))表示数据库块的大小(以字节为单位),然后通过除以1024*1024转换为兆字节(MB),再除以1024转换为G字节。
TABLESPACE: 临时表空间,表示临时空间所在的表空间。
SQL_TEXT: SQL文本,表示正在使用临时空间的SQL语句的文本。
查询当前正在消耗TEMP空间的SQL语句的意义在于:TEMP空间是ORACLE数据库中的临时存储区域,用于存储临时数据和中间结果。当一个SQL语句在执行过程中需要创建临时表、排序数据或执行其他类似操作时,ORACLE会将数据存储在TEMP空间中。通过查询正在消耗TEMP空间的SQL语句,可以了解哪些操作正在使用TEMP空间,以及它们的使用情况,从而帮助数据库管理员进行性能分析和优化。
21、查询需要使用绑定变量的sql,10G以后推荐第二种
一、
select * from (
select count(*),sql_id, substr(sql_text,1,40)
from v$sql
group by sql_id, substr(sql_text,1,40) having count(*) > 10 order by count(*) desc) where rownum<10
从 Oracle 数据库的 v$sql 视图中查询 SQL ID、SQL 语句以及它们的使用次数,需要注意的是,这段代码只返回了 SQL 语句的前 40 个字符,因为这部分足以表明 SQL 语句的大致含义,同时还可减少数据库的 I/O 开销。
二、
select sql_id, FORCE_MATCHING_SIGNATURE, sql_text
from v$SQL
where FORCE_MATCHING_SIGNATURE in
(select /*+ unnest */
FORCE_MATCHING_SIGNATURE
from v$sql
where FORCE_MATCHING_SIGNATURE > 0
and FORCE_MATCHING_SIGNATURE != EXACT_MATCHING_SIGNATURE
group by FORCE_MATCHING_SIGNATURE
having count(1) > 10)从 Oracle 数据库的 v$sql 视图中查询一组具有相同 FORCE_MATCHING_SIGNATURE 的 SQL 语句,同时每个 FORCE_MATCHING_SIGNATURE 的使用次数必须大于 10。其中,FORCE_MATCHING_SIGNATURE 是 Oracle 中的一个哈希值,它用于标识一组具有相同执行计划的 SQL 语句。因此,如果两个 SQL 语句具有相同的 FORCE_MATCHING_SIGNATURE,它们很可能会共享相同的执行计划,并且会相互影响。如果 FORCE_MATCHING_SIGNATURE 不同,即使两个 SQL 语句的文本完全相同,它们也可以拥有不同的执行计划。
结果集反映了在数据库中存在一些具有相同 FORCE_MATCHING_SIGNATURE 的 SQL 语句,并且它们的数量超过了 10。这意味着在数据库中存在一些 SQL 查询语句,它们具有相同的执行计划,却被执行了很多次。这可能是因为它们是经常性的查询,也可能是因为有许多用户同时执行了它们。
22、查看数据文件可用百分比
select b.file_id,b.tablespace_name,b.file_name,b.AUTOEXTENSIBLE,
ROUND(b.bytes/1024/1024/1024,2) ||'G' "文件总容量",
ROUND((b.bytes-sum(nvl(a.bytes,0)))/1024/1024/1024,2)||'G' "文件已用容量",
ROUND(sum(nvl(a.bytes,0))/1024/1024/1024,2)||'G' "文件可用容量",
ROUND(sum(nvl(a.bytes,0))/(b.bytes),2)*100||'%' "文件可用百分比"
from dba_free_space a,dba_data_files b
where a.file_id=b.file_id
group by b.tablespace_name,b.file_name,b.file_id,b.bytes,b.AUTOEXTENSIBLE
order by b.tablespace_name;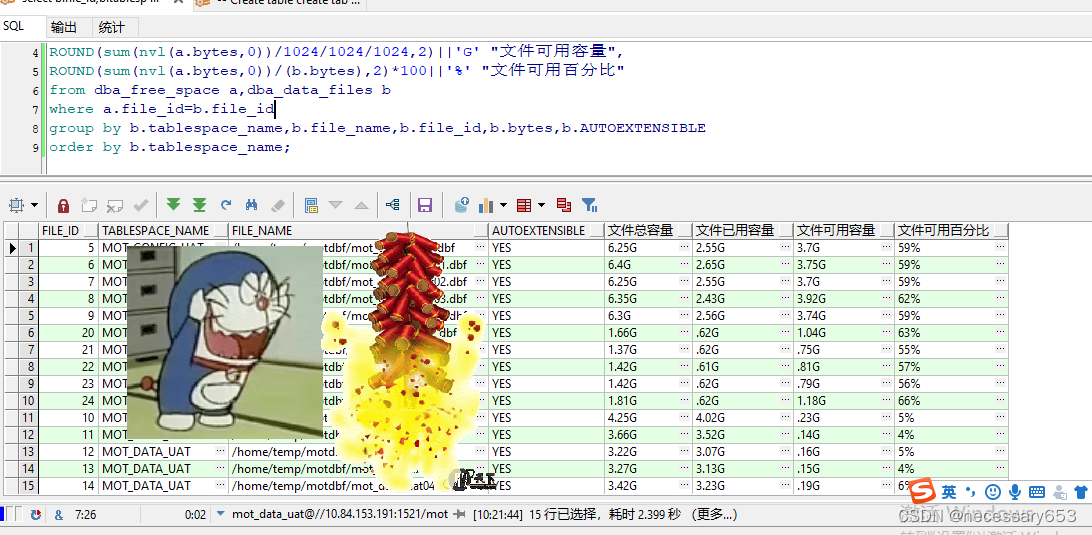
file_id: 文件ID,唯一标识数据库中的文件。
tablespace_name: 表空间名称,表空间是Oracle数据库中的一个逻辑存储单位,它包含了数据库的对象(如表,索引等)。
file_name: 文件的名称,这是在文件系统中的实际文件名。
AUTOEXTENSIBLE: 自动扩展标志,如果此字段为TRUE,表示文件是自动扩展的。
ROUND(b.bytes/1024/1024/1024,2) ||'G' "文件总容量": 这个字段表示文件的总容量,单位是GB。
ROUND((b.bytes-sum(nvl(a.bytes,0)))/1024/1024/1024,2)||'G' "文件已用容量": 这个字段表示文件的已使用容量,单位是GB。如果a.bytes字段为空(即没有记录或者没有数据),则使用0代替。
ROUND(sum(nvl(a.bytes,0))/1024/1024/1024,2)||'G' "文件可用容量": 这个字段表示文件的可用容量,单位是GB。如果a.bytes字段为空(即没有记录或者没有数据),则使用0代替。
ROUND(sum(nvl(a.bytes,0))/(b.bytes),2)*100||'%' "文件可用百分比": 这个字段表示文件的可用百分比。如果a.bytes字段为空(即没有记录或者没有数据),则使用0代替。
查询的结果集将返回每个表空间的文件的信息,包括文件的ID、名称、总容量、已使用容量、可用容量和可用百分比。这个查询有助于管理员了解数据库的存储使用情况,以便于进行存储管理和优化。
23、查看表空间可用百分比
select b.tablespace_name,a.total,b.free,round((b.free / a.total) * 100) "% Free"from (select tablespace_name, sum(bytes / (1024 * 1024)) totalfrom dba_data_filesgroup by tablespace_name) a,(select tablespace_name, round(sum(bytes / (1024 * 1024))) freefrom dba_free_spacegroup by tablespace_name) bWHERE a.tablespace_name = b.tablespace_nameorder by "% Free";

查询Oracle数据库中各个表空间的存储使用情况。下面是各个字段的解释:
tablespace_name: 表空间名称。
total: a子查询中计算得到的表空间的总容量,单位是MB。
free: b子查询中计算得到的表空间的剩余容量,单位是MB。
round((b.free / a.total) * 100) "% Free": 计算得到的表空间的剩余百分比。
查询的结果集将返回每个表空间的名称、总容量、剩余容量以及剩余空间的百分比。这个查询有助于数据库管理员了解数据库的存储使用情况,以便于进行存储管理和优化。例如,如果发现某些表空间接近其容量限制,那么可能需要增加这些表空间的容量或者优化存储结构。
24、查看临时表空间使用率
SELECT temp_used.tablespace_name,total,used,total - used as "Free",round(nvl(total-used, 0) * 100/total,3) "Free percent"FROM (SELECT tablespace_name, SUM(bytes_used)/1024/1024 usedFROM GV_$TEMP_SPACE_HEADERGROUP BY tablespace_name) temp_used,(SELECT tablespace_name, SUM(bytes)/1024/1024 totalFROM dba_temp_filesGROUP BY tablespace_name) temp_totalWHERE temp_used.tablespace_name = temp_total.tablespace_name获取Oracle数据库中各个表空间的临时空间使用情况。
temp_used.tablespace_name: 这是一个表空间名称,它来自于子查询temp_used。该子查询从GV_$TEMP_SPACE_HEADER视图中获取了临时空间使用的总字节数,并按表空间名称进行了分组。
total: 这是另一个来自子查询temp_total的字段,表示特定表空间的临时文件总字节数。它从dba_temp_files视图中获取数据,并按表空间名称进行了汇总。
used: 这是从GV_$TEMP_SPACE_HEADER视图中获取的已使用的临时空间字节数。它按表空间名称进行了汇总。
total - used as "Free": 这个字段表示表空间的剩余临时空间,计算方法是总临时空间减去已使用的临时空间。
round(nvl(total-used, 0) * 100/total,3) "Free percent": 这个字段表示剩余临时空间占总临时空间的百分比。如果总临时空间或已使用的临时空间中的任何一个为空(即未定义),则使用NVL函数将其替换为0,并计算剩余临时空间所占的百分比。
查询的结果集将显示每个表空间的名称、总临时空间、已使用的临时空间、剩余临时空间以及剩余临时空间所占的百分比。如果发现某个表空间的临时空间使用率很高,那么可能需要增加该表空间的存储容量,或者优化该表空间的存储结构。
25、查询undo表空间使用情况
select tablespace_name, status, sum(bytes) / 1024 / 1024 Mfrom dba_undo_extentsgroup by tablespace_name, status

从dba_undo_extents视图中获取数据。这个视图存储了数据库中撤销空间的信息。
tablespace_name: 这个字段表示撤销空间所在的表空间的名称。表空间是Oracle数据库中的一个逻辑存储单位,它包含了数据库的对象(如表,索引等)和撤销空间。
status: 这个字段表示撤销空间的当前状态。状态可能包括例如"ACTIVE"、"INACTIVE"等。
sum(bytes) / 1024 / 1024 M: 这是一个计算撤销空间总容量的表达式。bytes字段表示撤销空间的字节大小,通过除以1024*1024将其转换为MB(兆字节)。结果字段标记为M表示结果将以MB为单位显示。
group by tablespace_name, status: 这部分代码将结果按照表空间名称和状态进行分组。这意味着对于每个独特的表空间名称和状态组合,都会有一个对应的行在结果集中。
查询的结果集将显示每个独特的表空间名称和状态组合的撤销空间总容量(以MB为单位)。可以帮助了解数据库中各个表空间的撤销空间的总体使用情况。如果发现某个表空间的撤销空间使用量非常大,那么可能需要增加该表空间的存储容量,或者优化该表空间的存储结构。
26、查看ASM磁盘组使用率
select name,round(total_mb / 1024) "总容量",round(free_mb / 1024) "空闲空间",round((free_mb / total_mb) * 100) "可用空间比例"from gv$asm_diskgroup
在Oracle数据库中查询磁盘组信息
name: 这个字段表示磁盘组的名称。在Oracle磁盘组是用于存储数据的逻辑卷,可以由多个物理磁盘组成。
round(total_mb/1024) "总容量": 这个字段表示磁盘组的总容量。total_mb是磁盘组的总字节数,通过除以1024将其转换为KB(千字节)。使用round函数对结果进行四舍五入,以保留一位小数。
round(free_mb/1024) "空闲空间": 这个字段表示磁盘组的空闲空间大小。free_mb是磁盘组中未使用的字节数,通过除以1024将其转换为KB(千字节)。使用round函数对结果进行四舍五入,以保留一位小数。
round((free_mb/total_mb)*100) "可用空间比例": 这个字段表示磁盘组的可用空间比例。它通过计算未使用的字节数(free_mb)占总字节数(total_mb)的比例,并将其乘以100得到可用空间百分比。
通过查询gv$asm_diskgroup视图,可以得到数据库中所有磁盘组的名称、总容量、空闲空间和可用空间比例的信息。了解数据库存储的总体使用情况,。根据查询结果确定哪些磁盘组已接近满容量,需要增加存储空间,或者哪些磁盘组有大量未使用的空间,可以重新分配给其他需要更多空间的磁盘组。此外,磁盘组的可用空间比例也可以及时发现并处理存储瓶颈问题。
Oracle中的ASM磁盘组是一种分布式存储方案,是Oracle数据库的一种功能模块。它主要用于帮助用户管理磁盘,提高磁盘的调度效率,以及防止数据的丢失
27、统计每个用户使用表空间率
SELECT c.owner "用户",a.tablespace_name "表空间名",total/1024/1024 "表空间大小M",free/1024/1024 "表空间剩余大小M",( total - free )/1024/1024 "表空间使用大小M",Round(( total - free ) / total, 4) * 100 "表空间总计使用率%",c.schemas_use/1024/1024 "用户使用表空间大小M",round((schemas_use)/total,4)*100 "用户使用表空间率%"
FROM (SELECT tablespace_name,Sum(bytes) freeFROM DBA_FREE_SPACEGROUP BY tablespace_name) a,(SELECT tablespace_name,Sum(bytes) totalFROM DBA_DATA_FILESGROUP BY tablespace_name) b,(Select owner ,Tablespace_Name,Sum(bytes) schemas_useFrom Dba_SegmentsGroup By owner,Tablespace_Name) c
WHERE a.tablespace_name = b.tablespace_name
and a.tablespace_name =c.Tablespace_Name
order by c.owner,a.tablespace_name;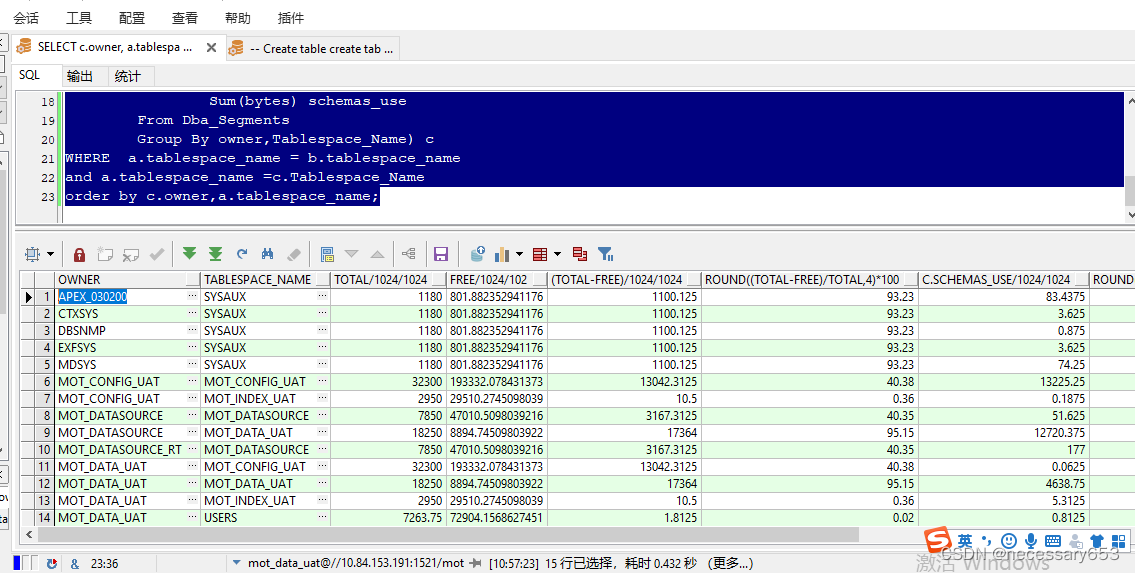
用于获取数据库中表空间的使用情况,包括表空间的总大小、剩余大小、使用大小以及使用率等。
owner :这个字段表示表空间的所有者,即哪个用户拥有这个表空间。
tablespace_name :这个字段表示表空间的名称。
total/1024/1024 :这个字段表示表空间的总大小,单位是MB(兆字节)。它通过将总字节数除以1024*1024得到。
free/1024/1024 :这个字段表示表空间的剩余大小,单位是MB(兆字节)。它通过将剩余字节数除以1024*1024得到。
(total - free)/1024/1024 :这个字段表示表空间的使用大小,单位是MB(兆字节)。它通过将已使用的字节数(总字节数减去剩余字节数)除以1024*1024得到。
Round((total - free) / total, 4) * 100 :这个字段表示表空间的使用率,单位是百分比。它通过计算已使用的字节数占总字节数的比例,并将其乘以100得到,同时使用ROUND函数将其保留到小数点后4位。
schemas_use/1024/1024 :这个字段表示用户在表空间中使用的空间大小,单位是MB(兆字节)。它通过将用户在表空间中使用的字节数除以1024*1024得到。
round((schemas_use)/total,4)*100 :这个字段表示用户在表空间中的使用率,单位是百分比。它通过计算用户在表空间中使用的字节数占总字节数的比例,并将其乘以100得到,
这个查询的结果集提供了数据库中表空间的详细使用情况,包括每个表空间的大小、剩余大小、使用大小和使用率等信息。了解数据库中各个表空间的存储情况,及时发现存储瓶颈并进行优化。
相关文章:
oracle数据库巡检常见脚本-系列二
简介 作为数据库管理员(DBA),定期进行数据库的日常巡检是非常重要的。以下是一些原因: 保证系统的稳定性:通过定期巡检,DBA可以发现并及时解决可能导致系统不稳定的问题,如性能瓶颈、资源利用率…...
JavaScript 表达式
JavaScript 表达式 目录 JavaScript 表达式 一、赋值表达式 二、算术表达式 三、布尔表达式 四、字符串表达式 表达式是一个语句的集合,计算结果是个单一值。 在JavaScript中,常见的表达式有4种: (1)赋值表达式…...
Python之Pygame游戏编程详解
一、介绍 1.1 定义 Pygame是一种流行的Python游戏开发库,它提供了许多功能,使开发人员可以轻松创建2D游戏。它具有良好的跨平台支持,可以在多个操作系统上运行,例如Windows,MacOS和Linux。在本文中,我们将…...
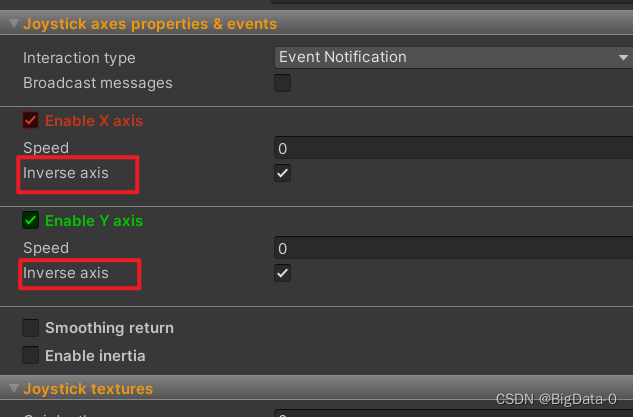
虚拟摇杆easytouch joystick的方向与角色移动方向不一致
更改 勾选 inverse axis 进行校正...

C++二分查找:统计点对的数目
本题其它解法 C双指针算法:统计点对的数目 本周推荐阅读 C二分算法:得到子序列的最少操作次数 本文涉及的基础知识点 二分查找算法合集 题目 给你一个无向图,无向图由整数 n ,表示图中节点的数目,和 edges 组成…...
:了解FFmpeg与SDL常用对象和函数)
播放器开发(二):了解FFmpeg与SDL常用对象和函数
学习课题:逐步构建开发播放器【QT5 FFmpeg6 SDL2】 前言 这一篇内容就是简单的了解一遍一些常用的函数名称和作用,混个眼熟。 能看源码的就去看源码!!! 能看源码的就去看源码!!! …...

【数据库】基于排序算法的去重,集合与包的并,差,交,连接操作实现原理,执行代价以及优化
基于两趟排序的其它操作 专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏…...
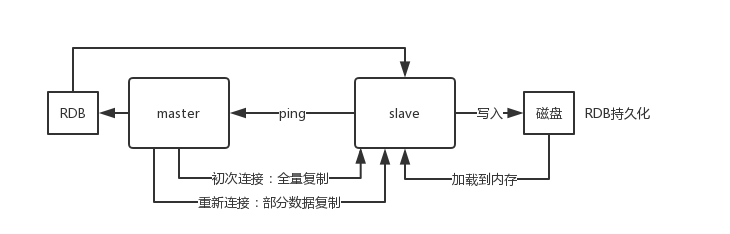
Redis 主从架构,Redis 分区,Redis哈希槽的概念,为什么要做Redis分区
文章目录 Redis 主从架构redis replication 的核心机制redis 主从复制的核心原理过程原理Redis集群的主从复制模型是怎样的?生产环境中的 redis 是怎么部署的?机器是什么配置?你往内存里写的是什么数据?说说Redis哈希槽的概念&…...

极客大挑战2023 Web方向题解wp 全
最后排名 9/2049。 玩脱了,以为28结束,囤的一些flag没交上去。我真该死啊QAQ EzHttp 前言:这次极客平台太安全了谷歌不给抓包,抓包用burp自带浏览器。 密码查看源码->robots.txt->o2takuXX’s_username_and_password.txt获…...
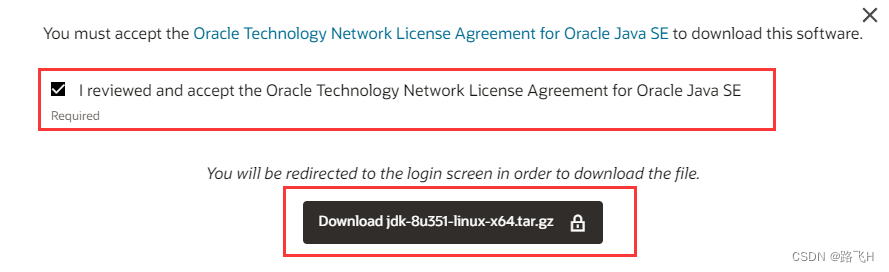
kafka开发环境搭建
文章目录 1 安装java环境1.1 下载linux下的安装包1.2 解压缩安装包1.3 解压后的文件移到/usr/lib目录下1.4 配置java环境变量 2 kafka的安装部署2.1 下载安装kafka2.2 配置和启动zookeeper2.3 启动和停止kafka 1 安装java环境 1.1 下载linux下的安装包 (1…...

Python大数据考题
Python大数据考题: 2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,oracle,尤其sql要…...

才聚免费为你招聘,用人单位看过来!
才聚团队从1998年开始从事项目管理的推广工作,20多年来培训学员超30万人次,分布全国各地、服务企业超过5000家。拥有大批 PMP (项目管理专业人员资格) NPDP(产品经理国际资格) 软考 (信息系统…...
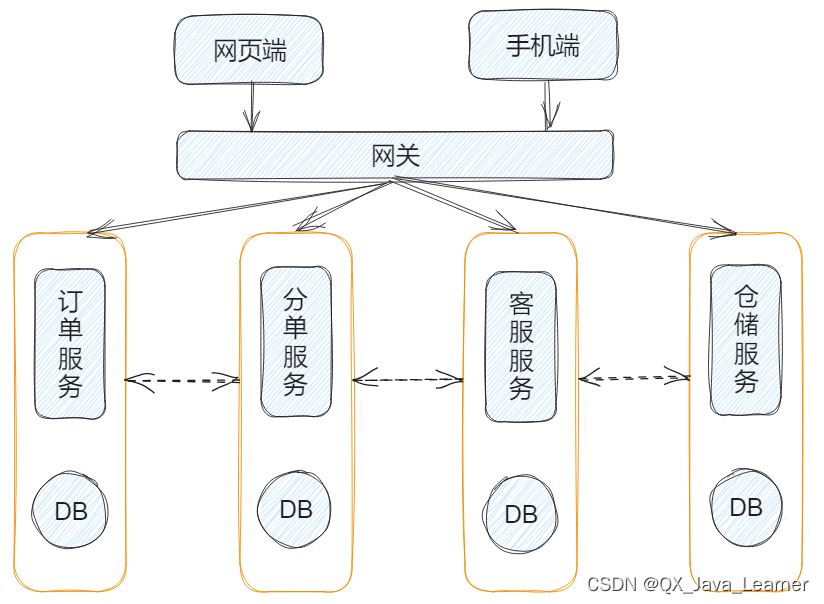
【SpringCloud】微服务的扩展性及其与 SOA 的区别
一、微服务的扩展性 由上一篇文章(没看过的可点击传送阅读)可知, 微服务具有极强的可扩展性,这些扩展性包含以下几个方面: 性能可扩展:性能无法完全实现线性扩展,但要尽量使用具有并发性和异步…...
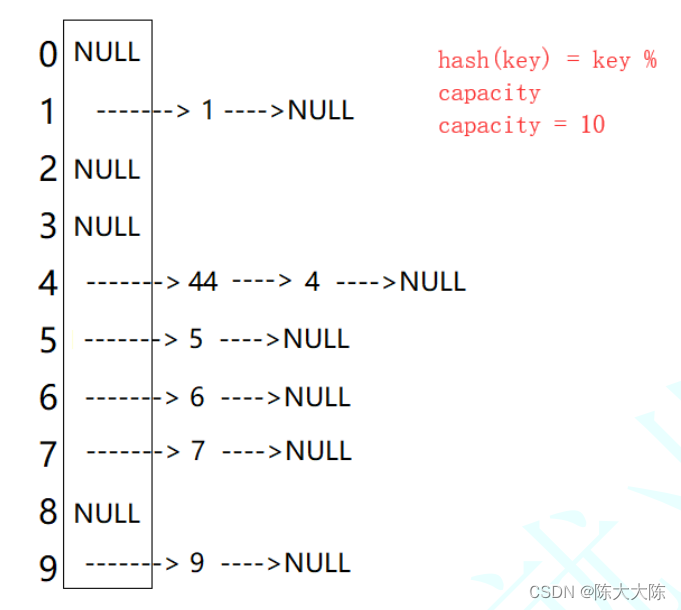
从零带你底层实现unordered_map (2)
💯 博客内容:从零带你实现unordered_map 😀 作 者:陈大大陈 🚀 个人简介:一个正在努力学技术的准C后端工程师,专注基础和实战分享 ,欢迎私信! 💖 欢迎大家…...

打造企业AI数字人专属IP的重要性
在数字化时代,企业数字人专属IP的打造成为了企业品牌建设的重要组成部分。企业数字人专属IP是指是利用人工智能技术实现与真人直播形象的1:1克隆,即克隆出一个数字化的真人形象,作为独有的企业数字人形象,可以用于产品推广、品牌宣…...
docker容器的生命周期管理常用命令
容器的生命周期管理命令 docker create :创建一个新的容器但不启动它 docker create nginx docker run :创建一个新的容器并运行一个命令 常用选项: 常用选项1. --add-host:容器中hosts文件添加 host:ip 映射记录 2. -a, --attach&#…...

CF 1900B Laura and Operations 学习笔记
原题链接 传送门 题意 输入三个数字a,b,c表示1,2,3的数目,也就是说有a个1,b个2,c个3,每一次可以删除两个不同的数字,增加一个剩下的数字,比如说删除1和3,增加2&#x…...

Linux学习笔记6-串口应用
到现在为止都是在开发板上运行的裸机程序,相当于之前学习STM32单片机时走过的路,还没有真正进入到核心的驱动开发部分,但这都是基础,所以慢慢来不着急。 接下来进入串口通信的学习,和GPIO一样,也是和单片机…...

ubuntu下如何查看.gz压缩包中的内容,以及grep过滤查找文件中的某些内容
1、查看压缩包file.gz中的全部内容 $ zcat file.gz 2、对一个.gz的压缩包解压缩 $ gunzip file.gz 3、过滤查找文件中的某些内容 $ grep "Hello" file.txt 注:我通常先解压,然后再grep 4、过滤查找文件中的内容,并显示其上下3行…...

AI 重构工业制造的故事 我们从大模型开始讲起
在数字化浪潮的推动下,工业制造领域正经历着一场前所未有的变革。人工智能(AI)作为这场变革的关键推动者之一,正以惊人的速度颠覆传统制造业。而大模型作为AI时代最先进的科技工具之一,或将成为引领这场变革的利器&…...

Dhall性能优化与部署指南:构建高效配置管理系统的终极方案
Dhall性能优化与部署指南:构建高效配置管理系统的终极方案 【免费下载链接】dhall-lang Maintainable configuration files 项目地址: https://gitcode.com/gh_mirrors/dh/dhall-lang Dhall是一个强大的配置语言,旨在提供可维护的配置文件解决方案…...

10个Yellowbrick可视化技巧:提升机器学习模型诊断效率
10个Yellowbrick可视化技巧:提升机器学习模型诊断效率 【免费下载链接】yellowbrick Visual analysis and diagnostic tools to facilitate machine learning model selection. 项目地址: https://gitcode.com/gh_mirrors/ye/yellowbrick Yellowbrick是一款强…...

你的SSH密钥可能已经过期了噬
引言 在现代软件开发中,性能始终是衡量应用质量的重要指标之一。无论是企业级应用、云服务还是桌面程序,性能优化都能显著提升用户体验、降低基础设施成本并增强系统的可扩展性。对于使用 C# 开发的应用程序而言,性能优化涉及多个层面&#x…...

SITS2026图谱深度解读:从LlamaFactory到vLLM再到Prometheus-Metrics,谁才是真正可规模化的工程底座?
第一章:SITS2026发布:大模型工程化工具链图谱 2026奇点智能技术大会(https://ml-summit.org) SITS2026(Scalable Intelligent Toolchain Summit 2026)正式发布面向生产级大模型开发的全栈工程化工具链图谱,聚焦模型训…...
)
R语言实战:用GEOquery和AnnoProbe搞定GEO芯片数据下载与ID转换(附避坑指南)
R语言实战:GEO芯片数据探针ID转换的深度解决方案与避坑实践 在生物信息学分析中,GEO数据库是研究者获取基因表达数据的金矿。但这座金矿的"矿石"——原始芯片数据,往往需要经过精细的"冶炼"过程才能转化为可分析的基因表…...
---命令解析和工具映射寡)
【GUI-Agent】阶跃星辰 GUI-MCP 解读---()---命令解析和工具映射寡
先回顾:三次握手(建立连接)核心流程(实际版) 为了让挥手流程衔接更顺畅,咱们先快速回顾三次握手的实际核心,避免上下文脱节: 第一步(客户端→服务器)…...

ESP32实战-打造智能红外遥控中枢
1. ESP32红外遥控中枢的硬件准备 第一次接触ESP32红外遥控功能时,我对着淘宝买来的红外接收头和LED发了半天呆。这些看似简单的小元件,要稳定工作其实有不少门道。先说接收端,市面上最常见的VS1838B红外接收模块,虽然标称工作电压…...

RLC电路仿真对比实验:Simulink原生模块 vs 自定义S函数谁更准?
RLC电路仿真精度对决:Simulink原生模块与S函数建模深度评测 在电力电子和控制系统仿真领域,Simulink作为行业标准工具,提供了两种截然不同的电路建模路径:一种是直接调用现成的RLC模块快速搭建电路,另一种则是通过S函数…...

GB/T28181设备接入WVP平台保姆级教程:从海康到大华的配置避坑指南
GB/T28181设备接入WVP平台实战指南:海康/大华/宇视全品牌配置解析 第一次接触GB/T28181协议时,我盯着设备ID和SIP服务器配置页面发呆了半小时——这些看似简单的字段背后藏着太多细节陷阱。本文将用真实项目经验,带你拆解不同品牌设备在WVP平…...

GitLab数据迁移翻车实录:从备份文件恢复失败到成功找回所有代码的完整复盘
GitLab数据迁移翻车实录:从备份文件恢复失败到成功找回所有代码的完整复盘 那天凌晨三点,当我在新服务器上执行完最后一条恢复命令后,屏幕上跳出的红色错误提示让我的睡意瞬间消散——"Version mismatch between backup and current ins…...