Doris-Routine Load(二十七)
例行导入(Routine Load)功能为用户提供了一种自动从指定数据源进行数据导入的功能。
适用场景
当前仅支持从 Kafka 系统进行例行导入,使用限制:
(1)支持无认证的 Kafka 访问,以及通过 SSL 方式认证的 Kafka 集群。
(2)支持的消息格式为 csv, json 文本格式。csv 每一个 message 为一行,且行尾不包含换行符。
(3)默认支持 Kafka 0.10.0.0(含)以上版本。如果要使用 Kafka 0.10.0.0 以下版本(0.9.0, 0.8.2, 0.8.1, 0.8.0),需要修改 be 的配置,将 kafka_broker_version_fallback 的值设置为要兼容的旧版本,或者在创建 routine load 的时候直接设置property.broker.version.fallback的值为要兼容的旧版本,使用旧版本的代价是 routine load 的部分新特性可能无法使用,如根据时间设置 kafka 分区的 offset。
基本原理
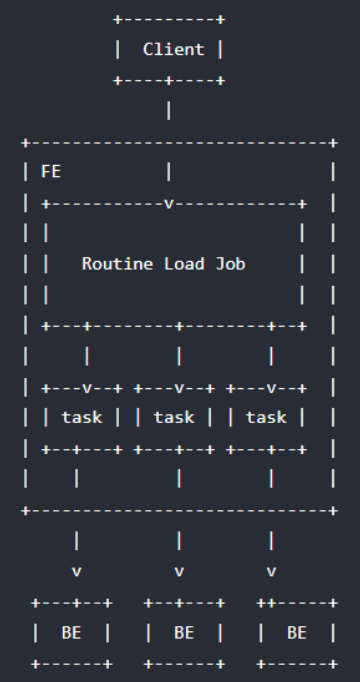
如上图,Client 向 FE 提交一个例行导入作业。
(1)FE 通过 JobScheduler 将一个导入作业拆分成若干个 Task。每个 Task 负责导入指定的一部分数据。Task 被 TaskScheduler 分配到指定的 BE 上执行。
(2)在 BE 上,一个 Task 被视为一个普通的导入任务,通过 Stream Load 的导入机制进行导入。导入完成后,向 FE 汇报。
(3)FE 中的 JobScheduler 根据汇报结果,继续生成后续新的 Task,或者对失败的Task 进行重试。
(4)整个例行导入作业通过不断的产生新的 Task,来完成数据不间断的导入。
基本语法
CREATE ROUTINE LOAD [db.]job_name ON tbl_name
[merge_type]
[load_properties]
[job_properties]
FROM data_source
[data_source_properties]
执行 HELP ROUTINE LOAD 可以查看语法帮助,下面是参数说明
1)[db.]job_name
导入作业的名称,在同一个 database 内,相同名称只能有一个 job 在运行。
2)tbl_name
指定需要导入的表的名称。
3)merge_type
数据的合并类型,一共支持三种类型 APPEND、DELETE、MERGE 其中,APPEND 是默认值,表示这批数据全部需要追加到现有数据中,DELETE 表示删除与这批数据 key 相同的所有行,MERGE 语义 需要与 delete on 条件联合使用,表示满足 delete 条件的数据按照 DELETE 语义处理其余的按照 APPEND 语义处理 , 语法为
[WITHMERGE|APPEND|DELETE]
4)load_properties
用于描述导入数据。语法:
[column_separator], [columns_mapping], [where_predicates], [delete_on_predicates], [source_sequence], [partitions], [preceding_predicates]
(1)column_separator:
指定列分隔符,如: COLUMNS TERMINATED BY "," 这个只在文本数据导入的时候需要指定,JSON 格式的数据导入不需要指定这个参数。
默认为:\t
(2)columns_mapping:
指定源数据中列的映射关系,以及定义衍生列的生成方式。
映射列:
按顺序指定,源数据中各个列,对应目的表中的哪些列。对于希望跳过的列,可以指定一个不存在的列名。假设目的表有三列 k1, k2, v1。源数据有 4 列,其中第 1、2、4 列分别对应 k2, k1, v1。则书写如下:
COLUMNS (k2, k1, xxx, v1)
其中 xxx 为不存在的一列,用于跳过源数据中的第三列。
衍生列:
以 col_name = expr 的形式表示的列,我们称为衍生列。即支持通过 expr 计算得出目的表中对应列的值。 衍生列通常排列在映射列之后,虽然这不是强制的规定,但是 Doris 总是先解析映射列,再解析衍生列。 接上一个示例,假设目的表还有第 4 列 v2,v2 由 k1 和 k2 的和产生。则可以书写如下:
COLUMNS (k2, k1, xxx, v1, v2 = k1 + k2);
再举例,假设用户需要导入只包含 k1 一列的表,列类型为 int。并且需要将源文件中的对应列进行处理:将负数转换为正数,而将正数乘以 100。这个功能可以通过 case when 函数实现,正确写法应如下:
COLUMNS (xx, k1 = case when xx < 0 then cast(-xx as varchar) else cast((xx + '100') as varchar) end)
(3)where_predicates
用于指定过滤条件,以过滤掉不需要的列。过滤列可以是映射列或衍生列。 例如我们只希望导入 k1 大于 100 并且 k2 等于 1000 的列,则书写如下:
WHERE k1 > 100 and k2 = 1000
(4)partitions
指定导入目的表的哪些 partition 中。如果不指定,则会自动导入到对应的 partition 中。
示例:
PARTITION(p1, p2, p3)
(5)delete_on_predicates
表示删除条件,仅在 merge type 为 MERGE 时有意义,语法与 where 相同
(6)source_sequence:
只适用于 UNIQUE_KEYS,相同 key 列下,保证 value 列按照 source_sequence 列进行REPLACE, source_sequence 可以是数据源中的列,也可以是表结构中的一列。
(7)preceding_predicates
PRECEDING FILTER predicate用于过滤原始数据。原始数据是未经列映射、转换的数据。用户可以在对转换前的数据前进行一次过滤,选取期望的数据,再进行转换。
5)job_properties
用于指定例行导入作业的通用参数。 语法:
PROPERTIES ("key1" = "val1","key2" = "val2"
)
目前支持以下参数:
(1)desired_concurrent_number
期望的并发度。一个例行导入作业会被分成多个子任务执行。这个参数指定一个作业最多有多少任务可以同时执行。必须大于 0。默认为 3。 这个并发度并不是实际的并发度,实际的并发度,会通过集群的节点数、负载情况,以及数据源的情况综合考虑。
一个作业,最多有多少 task 同时在执行。对于 Kafka 导入而言,当前的实际并发度计算如下:
Min(partition num, desired_concurrent_number, alive_backend_num,
Config.max_routine_load_task_concurrrent_num)
其中 Config.max_routine_load_task_concurrrent_num 是系统的一个默认的最大并发数限制。这是一个 FE 配置,可以通过改配置调整。默认为 5。
其中 partition num 指订阅的 Kafka topic 的 partition 数量。alive_backend_num 是当前正常的 BE 节点数。
(2)max_batch_interval/max_batch_rows/max_batch_size这三个参数分别表示:
-
① 每个子任务最大执行时间,单位是秒。范围为 5 到 60。默认为 10。
-
② 每个子任务最多读取的行数。必须大于等于 200000。默认是 200000。
-
③ 每个子任务最多读取的字节数。单位是字节,范围是 100MB 到 1GB。默认是100MB。
这三个参数,用于控制一个子任务的执行时间和处理量。当任意一个达到阈值,则任务结束。 例如:
"max_batch_interval" = "20",
"max_batch_rows" = "300000",
"max_batch_size" = "209715200"
(3)max_error_number
采样窗口内,允许的最大错误行数。必须大于等于 0。默认是 0,即不允许有错误行。
采样窗口为 max_batch_rows * 10。即如果在采样窗口内,错误行数大于 max_error_number,则会导致例行作业被暂停,需要人工介入检查数据质量问题。 被 where 条件过滤掉的行不算错误行
(4)strict_mode
是否开启严格模式,默认为关闭。如果开启后,非空原始数据的列类型变换如果结果为NULL,则会被过滤。指定方式为 "strict_mode" = "true"
(5)timezone
指定导入作业所使用的时区。默认为使用 Session 的 timezone 参数。该参数会影响所有导入涉及的和时区有关的函数结果
(6)format
指定导入数据格式,默认是 csv,支持 json 格式
(7)jsonpaths
jsonpaths: 导入 json 方式分为:简单模式和匹配模式。如果设置了jsonpath 则为匹配模式导入,否则为简单模式导入,具体可参考示例
(8)strip_outer_array
布尔类型,为 true 表示 json 数据以数组对象开始且将数组对象中进行展平,默认值是false
(9)json_root
json_root 为合法的 jsonpath 字符串,用于指定 json document 的根节点,默认值为""
(10)send_batch_parallelism
整型,用于设置发送批处理数据的并行度,如果并行度的值超过BE配置中的max_send_batch_parallelism_per_job,那么作为协调点的BE将使用max_send_batch_parallelism_per_job 的值
6)data_source_properties
数据源的类型。当前支持:Kafka
("key1" = "val1","key2" = "val2"
)相关文章:
Doris-Routine Load(二十七)
例行导入(Routine Load)功能为用户提供了一种自动从指定数据源进行数据导入的功能。 适用场景 当前仅支持从 Kafka 系统进行例行导入,使用限制: (1)支持无认证的 Kafka 访问,以及通过 SSL 方…...
)
linux驱动.之 网络udp应用层测试工具demon(一)
绑定vlan,网卡的demon,如果有多个网卡,多个vlan,网卡的ip设置成一致,那就不能只简单绑定ip来创建socket, 需要绑定网卡设备 客户端udp_client.c #include <stdio.h> #include <string.h> #inc…...
【Flutter】graphic图表的快速上手
简介 graphic是一个数据可视化语法和Flutter图表库。 官方github示例 网上可用资源很少,只有作者的几篇文章,并且没有特别详细的文档,使用的话还是需要一定的时间去调研,在此简单记录。 示例 以折线图为例(因为我只用到了折线图,但其他的图大差不差) 创建一个两个文…...

DeepMind 推出 OPRO 技术,可用于优化 ChatGPT 提示
本心、输入输出、结果 文章目录 DeepMind 推出 OPRO 技术,可用于优化 ChatGPT 提示前言消息摘要OPRO的工作原理DeepMind的研究相关链接花有重开日,人无再少年实践是检验真理的唯一标准 DeepMind 推出 OPRO 技术,可用于优化 ChatGPT 提示 编辑…...

企业网络中的身份安全
随着近年来数字化转型的快速发展,企业使用的数字身份数量急剧增长。身份不再仅仅局限于用户。它们现在扩展到设备、应用程序、机器人、第三方供应商和组织中员工以外的其他实体。即使在用户之间,也存在不同类型的身份,例如属于IT管理员、远程…...
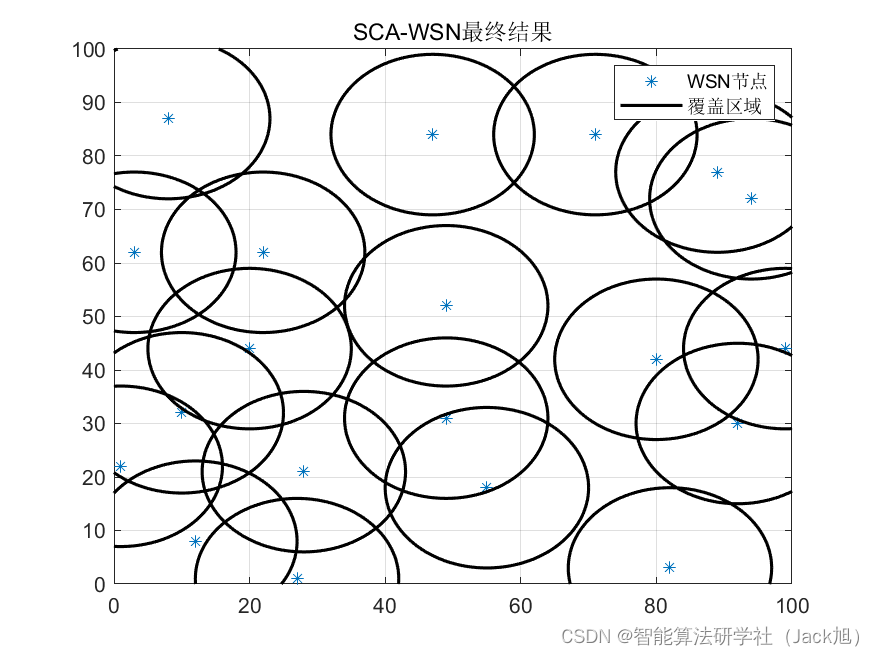
智能优化算法应用:基于正余弦算法无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于正余弦算法无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于正余弦算法无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.正余弦算法4.实验参数设定5.算法结果6.参考文献7.…...

创建一个带有背景图层和前景图层的渲染窗口
开发环境: Windows 11 家庭中文版Microsoft Visual Studio Community 2019VTK-9.3.0.rc0vtk-example demo解决问题: 创建一个带有背景图层和前景图层的渲染窗口,知识点:1. 画布转image;2. 渲染图层设置;3.…...

Docker 运行 Oracle Autonomous Database Free Container
Docker 运行 Oracle Autonomous Database Free Container Oracle Autonomous Database Free Container Image 介绍通过 Docker 运行 Oracle Autonomous Database Free ContainerWallet 配置可用的 TNS 别名MY_ATP TNS 别名MY_ADW TNS 别名连接到 Oracle Autonomous Databas…...

《2023全球隐私计算报告》正式发布!
2023全球隐私计算报告 1、2023全球隐私计算图谱2、国内外隐私计算相关政策3、隐私计算技术的最新发展4、隐私计算技术的合规挑战5、隐私计算的应用市场动态6、隐私计算开源整体趋势7、隐私计算的未来趋势 11月23日,由浙江省人民政府、商务部共同主办,杭州…...

JAVA sql 查询2
SELECT * FROM employees order by salayr DESC SELECT employee_id,first_name,salary from employees ORDER BY salary,employee_id desc -- 最大值 最小值 总和 平均值 SELECT max(salary),MIN(salary),sum(salary),AVG(salary) FROM employees -- 总共有多少员工 select…...

为第一个原生Spring5应用程序添加上Log4J日志框架!
😉😉 学习交流群: ✅✅1:这是孙哥suns给大家的福利! ✨✨2:我们免费分享Netty、Dubbo、k8s、Mybatis、Spring...应用和源码级别的视频资料 🥭🥭3:QQ群:583783…...
单片机复位电路
有时候我们的代码会跑飞,这个时候基本上是一切推到重来.”推倒重来”在计算机术语上称为复位.复位需要硬件的支持,复位电路就是在单片机的复位管脚上产生一个信号,俗称复位信号.这个信号需要持续一定的时间,单片机收到该信号之后就会复位,从头执行。 复位原理: 那么…...
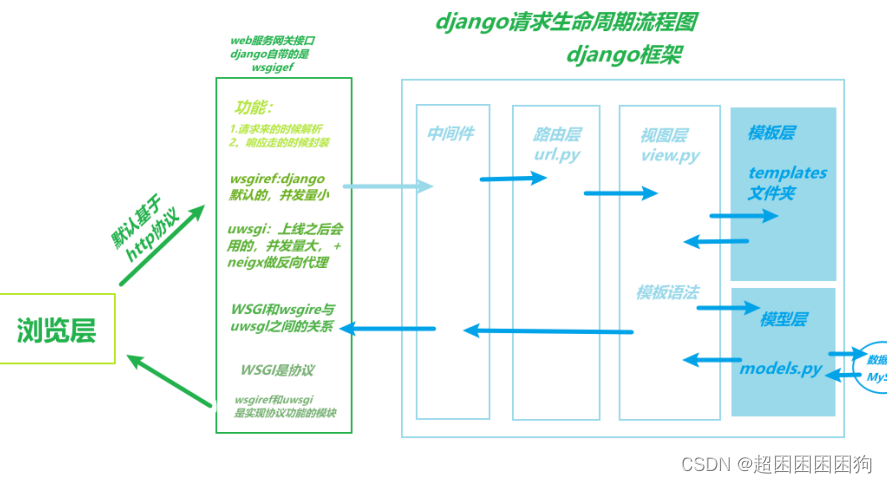
11.28 知识回顾(Web框架、路由控制、视图层)
一、 web 框架 1.1 web框架是什么? 别人帮咱们写了一些基础代码------》我们只需要在固定的位置写固定的代码--》就能实现一个web应用 Web框架(Web framework)是一种开发框架,用来支持动态网站、网络应用和网络服务的开发。这大多…...

osgFX扩展库-异性光照、贴图、卡通特效(1)
本章将简单介绍 osgFX扩展库及osgSim 扩展库。osgFX库用得比较多,osgSim库不常用,因此,这里只对这个库作简单的说明。 osgFX扩展库 osgFX是一个OpenSceneGraph 的附加库,是一个用于实现一致、完备、可重用的特殊效果的构架工具,其…...
)
SELinux零知识学习三十一、SELinux策略语言之角色和用户(2)
接前一篇文章:SELinux零知识学习三十、SELinux策略语言之角色和用户(1) 三、SELinux策略语言之角色和用户 SELinux提供了一种依赖于类型强制(类型增强,TE)的基于角色的访问控制(Role-Based Access Control),角色用于组域类型和限制域类型与用户之间的关系,SELinux中…...
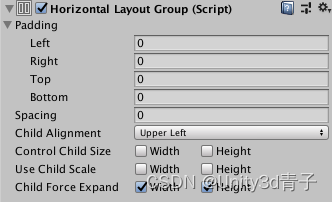
Unity UGUI的自动布局-LayoutGroup(水平布局)组件
Horizontal Layout Group | Unity UI | 1.0.0 1. 什么是HorizontalLayoutGroup组件? HorizontalLayoutGroup是Unity UGUI中的一种布局组件,用于在水平方向上对子物体进行排列和布局。它可以根据一定的规则自动调整子物体的位置和大小,使它们…...

【SpringCloud】设计原则之分层架构与统一通信协议
一、设计原则之分层架构 应用分层看起来很简单,但每个程序员都有自己的一套方法,哪怕是初学者,所以实施起来并非易事 最早接触的分层架构应该是最熟悉的 MVC(Model - View - Controller)架构,其将应用分成…...
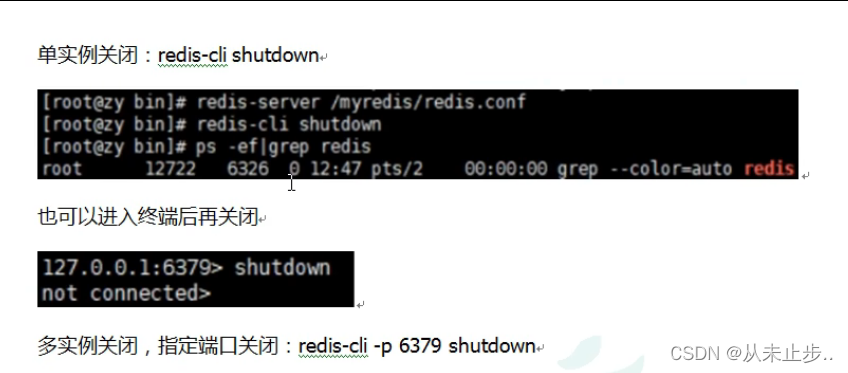
在Linux环境如何启动和redis数据库?
Linux中连接redis数据库: 前台启动: 第一步:redis-server:服务器启动命令 当我们启动改窗口后,出现如下所示: 该窗口就不能关闭,否则会出现redis无法使用的情况,重新打开一个窗口,…...
selenium判断元素是否存在的方法
文章目录 快捷方法完整示例程序 快捷方法 selenium没有exist_xxx相关的方法,无法直接判断元素存在。但是锁定元素时使用的browser.find_elements(By.CSS_SELECTOR, "css元素")会返回一个列表list,如果不存在这个元素就会返回一个空列表。因此…...

后端真批量新增的使用
1,添加真批量新增抽象接口 public interface EasyBaseMapper extends BaseMapper { /** * 批量插入 仅适用于mysql * * return 影响行数 */ Integer insertBatchSomeColumn(Collection entityList); } 2,新增类,添加真批量新增的方法 public class InsertBatchSqlInjector ext…...

200K极致轻量化:勇芳自动校时工具的技术与应用探析
在软件行业普遍追求功能丰富性的今天,勇芳自动校时工具走出了一条截然不同的发展道路。 它以极致的轻量化设计理念,用仅仅200K的体积,实现了精准的网络时间同步功能。 这款由吾爱论坛wyl0205开发的小工具,向我们展示了软件设计的…...

Google 迎来「DeepSeek 时刻」:TurboQuant算法实现bit无损、×加速、×压缩、零预处理矫
从 UI 工程师到 AI 应用架构者 13 年前,我的工作是让按钮在 IE6 上对齐; 13 年后,我用 fetch-event-source 订阅大模型的“思维流”,用 OCR 解锁图片中的文字——前端,正在成为 AI 产品的第一道体验防线。 最近&…...

终极Windows安装指南:如何用MediaCreationTool.bat轻松绕过硬件限制安装Windows 11
终极Windows安装指南:如何用MediaCreationTool.bat轻松绕过硬件限制安装Windows 11 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/Medi…...

clangd配置与优化:从入门到精通
1. 为什么你需要clangd? 如果你经常写C/C代码,肯定遇到过代码跳转卡顿、补全不准的问题。我之前用传统工具时,经常遇到跳转到错误文件、补全列表半天刷不出来的情况,特别是处理大型项目时,一个简单的函数跳转可能要等上…...

OpCore Simplify:黑苹果EFI配置的终极简化工具,30分钟快速搭建macOS系统
OpCore Simplify:黑苹果EFI配置的终极简化工具,30分钟快速搭建macOS系统 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 想要在…...

人工智能提示词场景篇:批判性思维学习
场景篇:批判性思维学习📝 本章学习目标:掌握场景篇:批判性思维学习中高效使用提示词的方法和技巧。一、引言 场景篇:批判性思维学习是提示词应用的重要场景之一。本章将系统讲解如何在该领域高效使用提示词。 ✅ 核心应…...

2026年终极B站资源下载方案:BiliTools跨平台工具箱完整指南
2026年终极B站资源下载方案:BiliTools跨平台工具箱完整指南 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools …...

QQ音乐解码神器qmcdump:5分钟快速解锁加密音乐文件的完整指南
QQ音乐解码神器qmcdump:5分钟快速解锁加密音乐文件的完整指南 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump …...

Qwen3.5-9B-AWQ-4bit效果惊艳分享:手写体混合印刷体截图的高准度识别
Qwen3.5-9B-AWQ-4bit效果惊艳分享:手写体混合印刷体截图的高准度识别 1. 模型能力概述 Qwen3.5-9B-AWQ-4bit是一款支持图像理解的多模态模型,能够结合上传图片与文字提示词,输出中文分析结果。这个模型特别擅长处理图片主体识别、场景描述、…...

Alibaba DASD-4B Thinking 对话工具在时序预测中的应用:结合LSTM模型的分析与报告生成
Alibaba DASD-4B Thinking 对话工具在时序预测中的应用:结合LSTM模型的分析与报告生成 1. 引言 想象一下这个场景:你的团队刚刚用LSTM模型跑完了下个季度的销量预测,屏幕上那条起伏的曲线清晰地告诉你,三月份会有一个销售高峰&a…...