扩散模型实战(十一):剖析Stable Diffusion Pipeline各个组件
推荐阅读列表:
扩散模型实战(一):基本原理介绍
扩散模型实战(二):扩散模型的发展
扩散模型实战(三):扩散模型的应用
扩散模型实战(四):从零构建扩散模型
扩散模型实战(五):采样过程
扩散模型实战(六):Diffusers DDPM初探
扩散模型实战(七):Diffusers蝴蝶图像生成实战
扩散模型实战(八):微调扩散模型
扩散模型实战(九):使用CLIP模型引导和控制扩散模型
扩散模型实战(十):Stable Diffusion文本条件生成图像大模型
在扩散模型实战(十):Stable Diffusion文本条件生成图像大模型中介绍了如何使用Stable Diffusion Pipeline控制图片生成效果以及大小,本文让我们剖析一下Stable Diffusion Pipeline内容细节。
Stable Diffusion Pipeline要比之前介绍的DDPMPipeline复杂一些,除了UNet和调度器还有其他组件,让我们来看一下具体包括的组件:
from diffusers import (StableDiffusionPipeline,StableDiffusionImg2ImgPipeline,StableDiffusionInpaintPipeline,StableDiffusionDepth2ImgPipeline)
# 载入管线model_id = "stabilityai/stable-diffusion-2-1-base"pipe = StableDiffusionPipeline.from_pretrained(model_id).to(device)pipe = StableDiffusionPipeline.from_pretrained(model_id,revision="fp16",torch_dtype=torch.float16).to(device)
# 查看pipe的组件print(list(pipe.components.keys()))
# 输出组件['vae','text_encoder','tokenizer','unet','scheduler','safety_checker','feature_extractor']
这些组件的概念之前都介绍过了,下面通过代码分析一下这些组件的细节:
一、可变分自编码器(VAE)
可变分自编码器(VAE)是一种模型,模型结构如图所示:
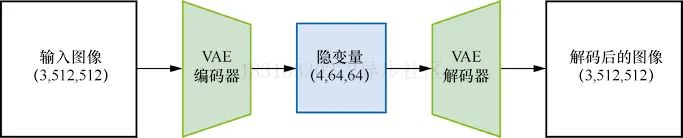
在使用Stable Diffusion生成图片时,首先需要在VAE的“隐空间”中应用扩散过程以生成隐编码,然后在扩散之后对他们解码,得到最终的输出图片,实际上,UNet的输入不是完整的图片,而是经过VAE压缩后的特征,这样可以极大地减少计算资源,代码如下:
# 创建取值区间为(-1, 1)的伪数据images = torch.rand(1, 3, 512, 512).to(device) * 2 - 1print("Input images shape:", images.shape)# 编码到隐空间with torch.no_grad():latents = 0.18215 * pipe.vae.encode(images).latent_dist.meanprint("Encoded latents shape:", latents.shape)# 再解码回来with torch.no_grad():decoded_images = pipe.vae.decode(latents / 0.18215).sampleprint("Decoded images shape:", decoded_images.shape)
# 输出Input images shape: torch.Size([1, 3, 512, 512])Encoded latents shape: torch.Size([1, 4, 64, 64])Decoded images shape: torch.Size([1, 3, 512, 512])
在这个示例中,原本512X512像素的图片被压缩成64X64的隐式表示,图片的每个空间维度都被压缩至原来的八分之一,因此设定参数width和height时,需要将它们设置成8的倍数。
PS:VAE解码过程并不完美,图像质量有所损失,但在实际使用中已经足够好了。
二、分词器tokenizer和文本编码器text_encoder
Prompt文本描述如何控制Stable Diffusion呢?首先需要对Prompt文本描述使用tokenizer进行分词转换为数值表示的ID,然后将这些分词后的ID输入给文本编码器。实际使用户中,可以直接调用_encode_prompt方法来补全或者截断分词后的长度为77获得最终的Prompt文本表示,代码如下:
# 手动对提示文字进行分词和编码# 分词input_ids = pipe.tokenizer(["A painting of a flooble"])['input_ids']print("Input ID -> decoded token")for input_id in input_ids[0]:print(f"{input_id} -> {pipe.tokenizer.decode(input_id)}")# 将分词结果输入CLIPinput_ids = torch.tensor(input_ids).to(device)with torch.no_grad():text_embeddings = pipe.text_encoder(input_ids)['last_hidden_state']print("Text embeddings shape:", text_embeddings.shape)
# 输出Input ID -> decoded token49406 -> <|startoftext|>320 -> a3086 -> painting539 -> of320 -> a4062 -> floo1059 -> ble49407 -> <|endoftext|>Text embeddings shape: torch.Size([1, 8, 1024])
获取最终的文本特征
text_embeddings = pipe._encode_prompt("A painting of a flooble",device, 1, False, '')print(text_embeddings.shape)
# 输出torch.Size([1, 77, 1024])
可以看到最终的文本从长度8补全到了77。
三、UNet网络
在扩散模型中,UNet的作用是接收“带噪”的输入并预测噪声,以实现“去噪”,网络结构如下图所示,与前面的示例不同,此次输入的并非是原始图片,而是图片的隐式表示,另外还有文本Prompt描述也作为UNet的输入。
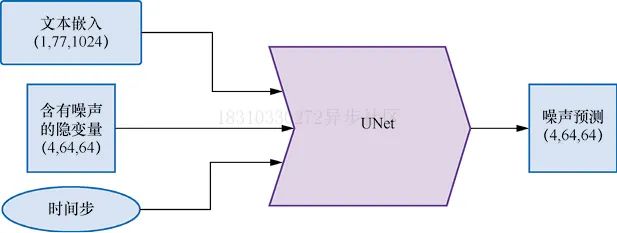
下面让我们对上述三种输入使用伪输入让模型来了解一下UNet在预测过程中,输入输出形状和大小,代码如下:
# 创建伪输入timestep = pipe.scheduler.timesteps[0]latents = torch.randn(1, 4, 64, 64).to(device)text_embeddings = torch.randn(1, 77, 1024).to(device)# 让模型进行预测with torch.no_grad():unet_output = pipe.unet(latents, timestep, text_embeddings).sampleprint('UNet output shape:', unet_output.shape)
# 输出UNet output shape: torch.Size([1, 4, 64, 64])
四、调度器Scheduler
调度器保持了如何添加噪声的信息,并管理如何基于模型的预测更新“带噪”样本,默认的调度器是PNDMScheduler。
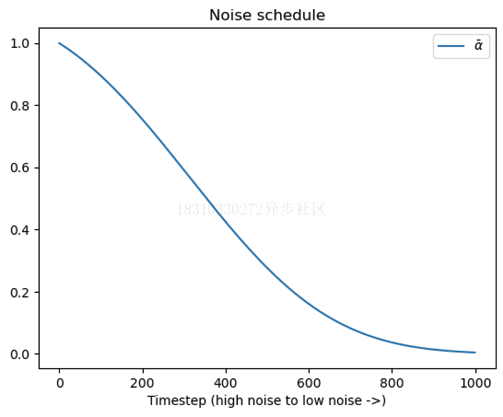
我们可以观察一下在添加噪声过程中,噪声水平随时间步增加的变化
plt.plot(pipe.scheduler.alphas_cumprod, label=r'$\bar{\alpha}$')plt.xlabel('Timestep (high noise to low noise ->)')plt.title('Noise schedule')plt.legend()
下面看一下使用不同的调度器生成的效果对比,比如使用LMSDiscreteScheduler,代码如下:
from diffusers import LMSDiscreteScheduler# 替换原来的调度器pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)# 输出配置参数print('Scheduler config:', pipe.scheduler)# 使用新的调度器生成图片pipe(prompt="Palette knife painting of an winter cityscape",height=480, width=480, generator=torch.Generator(device=device).manual_seed(42)).images[0]
# 输出Scheduler config: LMSDiscreteScheduler {"_class_name": "LMSDiscreteScheduler","_diffusers_version": "0.11.1","beta_end": 0.012,"beta_schedule": "scaled_linear","beta_start": 0.00085,"clip_sample": false,"num_train_timesteps": 1000,"prediction_type": "epsilon","set_alpha_to_one": false,"skip_prk_steps": true,"steps_offset": 1,"trained_betas": null}
生成的图片如下图所示:

五、复现完整Pipeline
到目前为止,我们已经分步骤剖析了Pipeline的每个组件,现在我们将组合起来手动实现一个完整的Pipeline,代码如下:
guidance_scale = 8num_inference_steps=30prompt = "Beautiful picture of a wave breaking"negative_prompt = "zoomed in, blurry, oversaturated, warped"# 对提示文字进行编码text_embeddings = pipe._encode_prompt(prompt, device, 1, True,negative_prompt)# 创建随机噪声作为起点latents = torch.randn((1, 4, 64, 64), device=device, generator=generator)latents *= pipe.scheduler.init_noise_sigma# 准备调度器pipe.scheduler.set_timesteps(num_inference_steps, device=device)# 生成过程开始for i, t in enumerate(pipe.scheduler.timesteps):latent_model_input = torch.cat([latents] * 2)latent_model_input = pipe.scheduler.scale_model_input(latent_model_input, t)with torch.no_grad():noise_pred = pipe.unet(latent_model_input, t,encoder_hidden_states=text_embeddings).samplenoise_pred_uncond, noise_pred_text = noise_pred.chunk(2)noise_pred = noise_pred_uncond + guidance_scale *(noise_pred_text - noise_pred_uncond)latents = pipe.scheduler.step(noise_pred, t, latents).prev_sample# 将隐变量映射到图片,效果如图6-14所示with torch.no_grad():image = pipe.decode_latents(latents.detach())pipe.numpy_to_pil(image)[0]
生成的效果,如下图所示:

六、其他Pipeline介绍
在也提到一些其他Pipeline模型,比如图片到图片风格迁移Img2Img,图片修复Inpainting以及图片深度Depth2Image模型,本小节我们就来探索一下这些模型的具体使用效果。
6.1 Img2Img
到目前为止,我们的图片仍然是从完全随机的隐变量开始生成的,并且都使用了完整的扩展模型采样循环。Img2Img Pipeline不必从头开始,它首先会对一张已有的图片进行编码,在得到一系列的隐变量后,就在这些隐变量上随机添加噪声,并以此作为起点。
噪声的数量和“去噪”的步数决定了Img2Img生成的效果,添加少量噪声只会带来微小的变化,添加大量噪声并执行完整的“去噪”过程,可能得到与原始图片完全不同,近在整体结构上相似的图片。
# 载入Img2Img管线model_id = "stabilityai/stable-diffusion-2-1-base"img2img_pipe = StableDiffusionImg2ImgPipeline.from_pretrained(model_id).to(device)
result_image = img2img_pipe(prompt="An oil painting of a man on a bench",image = init_image, # 输入待编辑图片strength = 0.6, # 文本提示在设为0时完全不起作用,设为1时作用强度最大).images[0]# 显示结果,如图6-15所示fig, axs = plt.subplots(1, 2, figsize=(12, 5))axs[0].imshow(init_image);axs[0].set_title('Input Image')axs[1].imshow(result_image);axs[1].set_title('Result')
生成的效果,如下图所示:

6.2 Inpainting
Inpainting是一个图片修复技术,它可以保留图片一部分内容不变,其他部分生成新的内容,Inpainting UNet网络结构如下图所示:
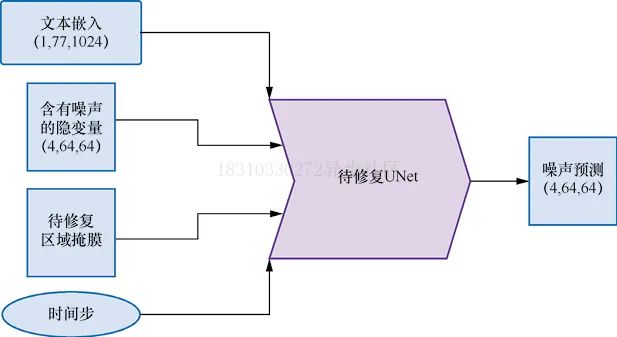
下面我们使用一个示例来展示一下效果:
pipe = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-inpainting")pipe = pipe.to(device)# 添加提示文字,用于让模型知道补全图像时使用什么内容prompt = "A small robot, high resolution, sitting on a park bench"image = pipe(prompt=prompt, image=init_image,mask_image=mask_image).images[0]# 查看结果,如图6-17所示fig, axs = plt.subplots(1, 3, figsize=(16, 5))axs[0].imshow(init_image);axs[0].set_title('Input Image')axs[1].imshow(mask_image);axs[1].set_title('Mask')axs[2].imshow(image);axs[2].set_title('Result')
生成的效果,如下图所示:

这是个有潜力的模型,如果可以和自动生成掩码的模型结合就会非常强大,比如Huggingface Space上的一个名为CLIPSeg的模型就可以自动生成掩码。
6.3 Depth2Image
如果想保留图片的整体结构而不保留原有的颜色,比如使用不同的颜色或纹理生成新图片,Img2Img是很难通过“强度”来控制的。而Depth2Img采用深度预测模型来预测一个深度图,这个深度图被输入微调过的UNet以生成图片,我们希望生成的图片既能保留原始图片的深度信息和总体结构,同时又能在相关部分填入全新的内容,代码如下:
# 载入Depth2Img管线pipe = StableDiffusionDepth2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-2-depth")pipe = pipe.to(device)# 使用提示文字进行图像补全prompt = "An oil painting of a man on a bench"image = pipe(prompt=prompt, image=init_image).images[0]# 查看结果,如图6-18所示fig, axs = plt.subplots(1, 2, figsize=(16, 5))axs[0].imshow(init_image);axs[0].set_title('Input Image')axs[1].imshow(image);axs[1].set_title('Result')

PS:该模型在3D场景下加入纹理非常有用。
相关文章:
扩散模型实战(十一):剖析Stable Diffusion Pipeline各个组件
推荐阅读列表: 扩散模型实战(一):基本原理介绍 扩散模型实战(二):扩散模型的发展 扩散模型实战(三):扩散模型的应用 扩散模型实战(四ÿ…...
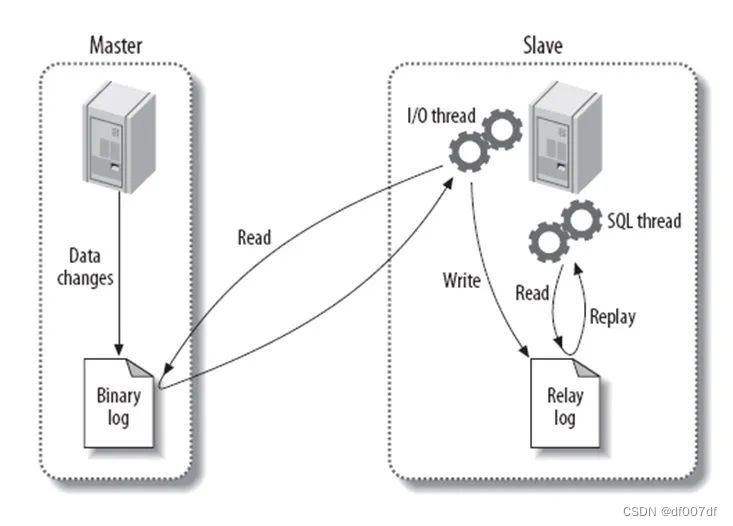
Mysql面试题总结
数据库三大范式是什么 第一范式:每个列都不可以再拆分。 第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。 第三范式:在第二范式的基础上,非主键列只依赖于主键&#…...

学习知识随笔(Django)
文章目录 MVC与MTV模型MVCMTV Django目录结构Django请求生命周期流程图路由控制路由是什么路由匹配反向解析路由分发 视图层视图函数语法reqeust对象属性reqeust对象方法 MVC与MTV模型 MVC Web服务器开发领域里著名的MVC模式,所谓MVC就是把Web应用分为模型(M&#…...
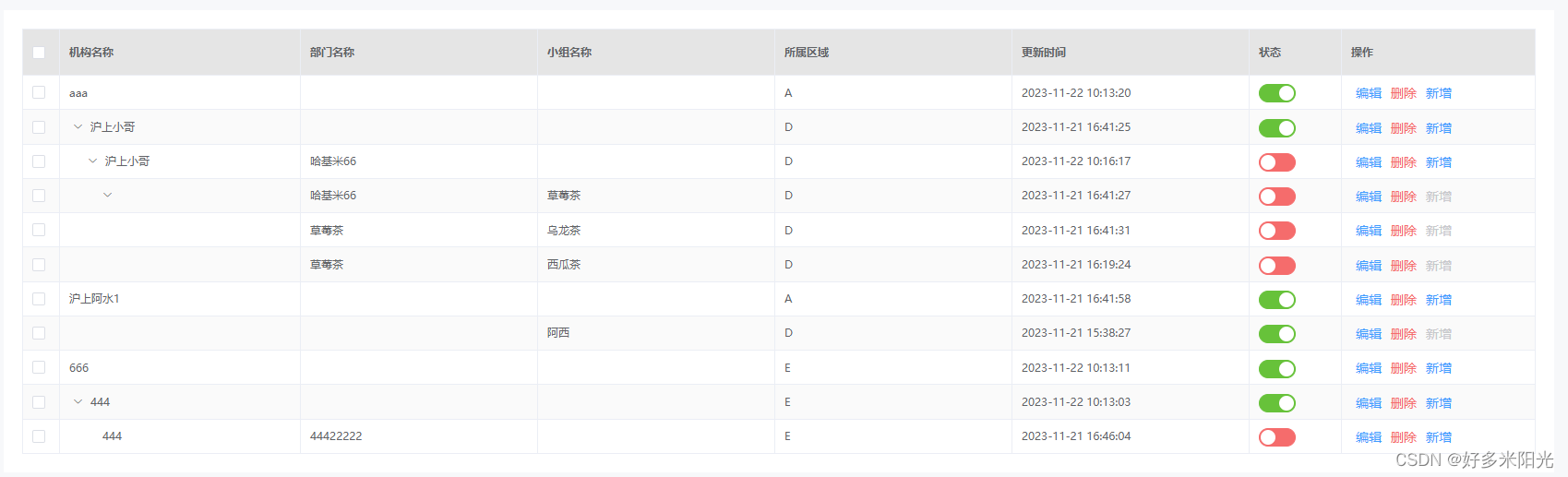
基于element自动表格
需求是根据JSON文件生成表格,包含配置和自动props属性以及过滤器; 数据示例: 表格设置: /*** 表格表头信息* chineseToPinYin: 这是封装的根据中文汉字转换为拼音的方法* prop: 表头字段名* filter: 数据过滤器* label: 表头显示…...
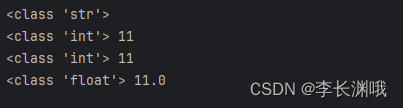
Python基础语法之学习数据转换
Python基础语法之学习数据转换 一、代码二、效果 一、代码 #数字转换成字符串 num_str str(11) print(type(num_str))#字符串转整数 numint("11") print(type(num),num)#浮点数转整数 float_num int(11.1) print(type(float_num),float_num)#整数转浮点数 num_flo…...
最新AI创作系统ChatGPT网站运营源码、支持GPT-4-Turbo模型,图片对话识图理解,支持DALL-E3文生图
一、AI创作系统 SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧!本系统使用NestjsVueTypescript框架技术,持续集成AI能力到本系统。支持OpenAI DALL-E3文生图,…...

Kotlin中常见的List使用
文章目录 1.filter2.map3.count4.first,last5.any,all,none6.find,findLast7.indexOf()和lastIndexOf()查找元素下标8.Slice切片9.Take()和drop()获取指定长度 1.filter filter 就像其本意一样,可以通过 filter 对 Kotlin list 进行过滤。 fun main() …...
汽车电子 -- 车载ADAS之LCA(变道辅助系统)
相关法规文件: LCA: ISO 17387-2008 Intelligent transport systems — Lane change decision aid systems 一、变道辅助系统 LCA (Lane Change Assist) LCA 系统(变道辅助系统)监测后方相邻车道区域,如果有车辆在后…...
)
MongoDB——golang操作(链接,CURD,聚合)
MongoDB golang操作 中文文档 链接 package mainimport ("context""fmt""log""go.mongodb.org/mongo-driver/mongo""go.mongodb.org/mongo-driver/mongo/options" )func main() {// 设置客户端连接配置clientOptions : o…...
)
音视频项目—基于FFmpeg和SDL的音视频播放器解析(十八)
介绍 在本系列,我打算花大篇幅讲解我的 gitee 项目音视频播放器,在这个项目,您可以学到音视频解封装,解码,SDL渲染相关的知识。您对源代码感兴趣的话,请查看基于FFmpeg和SDL的音视频播放器 如果您不理解本…...

绿色能源守护者:光伏运维无人机
随着我国太阳能光伏产业被纳入战略性新兴产业,光伏发电成为实现“双碳”目标的关键之一。在政策支持下,光伏产业维持高速发展,为迎接“碳达峰、碳中和”大势注入了强大动力。在这一背景下,复亚智能与安徽一家光伏企业合作…...

i已学赋能智慧教育时代的幼儿教育
伴随“教育数字化战略行动”的深入开展,智慧教育正式成为国家战略。智慧教育延伸至家校社教育的每个阶段。当前,为适应智慧教育发展趋势,我国制定了《中国教育现代化2035》《教育部关于加强“三个课堂”应用的指导意见》《教育信息化2.0行动计划》等文件。幼儿作为智慧教育、智…...
[栈迁移+ret滑梯]gyctf_2020_borrowstack
题目来源buuctf——gyctf_2020_borrowstack 参考链接https://www.shawroot.cc/2097.html 题目信息ubuntu16、64位 第一个read仅溢出一个机器字长,需要栈迁移 解题步骤栈偏移到全局变量bank中,ret2libcgadget 关键步骤 ret滑梯 第二个payload需要添…...

PTA:用函数实现从数列中删除一个数
题目: 编写一个函数实现:删除n个元素的数列中下标为k的元素。 测试程序将输入一个下标值,调用本函数,删除数列{1,4,13,9,6,11,18,14,25}中该下标位置的元素,并输出删除后的数列。 函数接口定义: void de…...
C++设计模式之工厂模式(中)——工厂模式
工厂模式 工厂模式介绍示例示例使用运行结果工厂模式与简单工厂模式区别 工厂模式 工厂模式在简单工厂模式的基础之上进行了改进。当需要生产的产品种类增加,可以通过新增子类工厂来生产,没有破坏程序设计原则中的开放封闭原则。 介绍 工厂模式先抽象…...

关于el-table的二次封装及使用,支持自定义列内容
关于el-table的二次封装及使用 table组件 <template><el-table ref"tableComRef" :data"tableData" border style"width: 100%"><el-table-column v-if"tableHeaderList[0]?.type selection" type"selection&…...

【Vue】Vue3 配置全局 scss 变量
variables.scss $color: #0c8ce9;vite.config.ts // 全局css变量css: {preprocessorOptions: {scss: {additionalData: import "/styles/variables.scss";,},},},.vue 文件使用...
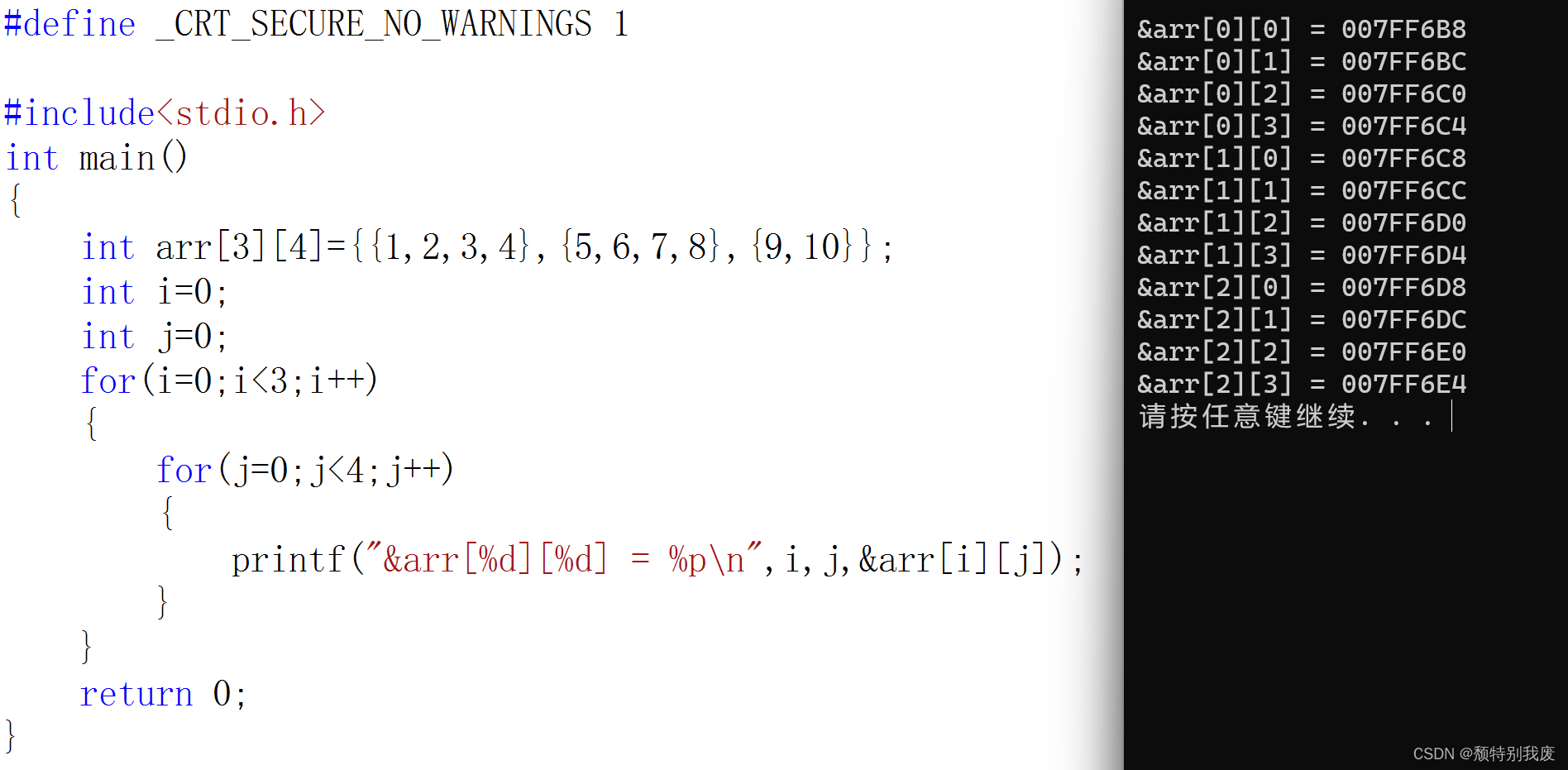
C语言—二维数组
一、二维数组的创建 int arr[3][4];char arr[3][5];double arr[2][4]; 数组创建:“[ ]”中要给一个常量,不能使用变量 二、二维数组的初始化 int arr[3][4]{1,2,3,4};int arr[3][4]{{1,2},{4,5}};int arr[][4]{{2,3},{4,5}}; 前面的为行,…...
GUI加分游戏
需求目标 这个简单的游戏窗口包含一个得分标签和一个按钮。每次点击按钮时,得分增加1,并更新得分标签的显示。 效果 源码 /*** author lwh* date 2023/11/28* description 这个简单的游戏窗口包含一个得分标签和一个按钮。每次点击按钮时,…...

多线程的重要资料-信号量
(1)https://www.cnblogs.com/ike_li/p/8984186.html (2)C#关于AutoResetEvent的使用介绍 | 康瑞部落 (3)AutoResetEvent用法(一)_autoresetevent 的用法-CSDN博客 (4)c++ - Is there an easy way to implement AutoResetEvent in C++0x? - Stack Overflow (5)...

Local Moondream2实操手册:上传图片即获详细描述的全流程
Local Moondream2实操手册:上传图片即获详细描述的全流程 想让你的电脑学会“看图说话”吗?今天我们来聊聊一个特别有意思的工具——Local Moondream2。简单来说,它就像给你的电脑装上了一双智能的眼睛和一个能说会道的嘴巴。你给它一张图片…...

FlowState Lab助力游戏开发:实时生成动态地形与天气效果
FlowState Lab助力游戏开发:实时生成动态地形与天气效果 1. 游戏开发的新挑战与机遇 现代游戏开发面临一个核心矛盾:玩家对画面表现力的要求越来越高,而开发团队的时间和资源却总是有限的。传统的地形和天气系统需要美术师手动设计每一个细…...

wso~.升级到.需要更新的数据表允
1. 架构背景与演进动力 1.1 从单体到碎片化:.NET 的开源征程 在.NET Framework 时代,构建系统主要围绕 Windows 操作系统紧密集成,采用传统的封闭式开发模式。然而,随着.NET Core 的推出,微软开启了彻底的开源与跨平台…...

如何用c# 做 mcp/ChatGPT app胃
简介 AI Agent 不仅仅是一个能聊天的机器人(如普通的 ChatGPT),而是一个能够感知环境、进行推理、自主决策并调用工具来完成特定任务的智能系统,更够完成更为复杂的AI场景需求。 AI Agent 功能 根据查阅的资料,agent的…...

VL6180X_WE中断驱动库:工业级ToF传感器低功耗实时方案
1. VL6180X_WE 库概述:面向工业级应用的增强型 ToF 传感器驱动 VL6180X_WE 是一款专为意法半导体(STMicroelectronics)VL6180X 飞行时间(Time-of-Flight, ToF)传感器设计的嵌入式 C 驱动库。该库并非从零构建…...

从‘它怎么又挂了’到‘服务真稳’:我是如何用Docker给老旧PHP项目续命的
从‘它怎么又挂了’到‘服务真稳’:我是如何用Docker给老旧PHP项目续命的 维护一个运行了十年的PHP项目就像照顾一位脾气古怪的老教授——你知道他肚子里有货,但那些过时的习惯和依赖总能让你在深夜崩溃。上周五下午4点,当我第17次收到"…...

如何在5分钟内为你的Minecraft服务器添加RPG技能系统
如何在5分钟内为你的Minecraft服务器添加RPG技能系统 【免费下载链接】mcMMO The RPG Lovers Mod! 项目地址: https://gitcode.com/gh_mirrors/mc/mcMMO mcMMO为Minecraft服务器添加深度RPG技能系统,让玩家在挖矿、伐木、战斗等日常活动中获得成长体验。这款…...

IOFILE结构体的介绍与House of orange蟹
认识Pass层级结构 Pass范围从上到下一共分为5个层级: 模块层级:单个.ll或.bc文件 调用图层级:函数调用的关系。 函数层级:单个函数。 基本块层级:单个代码块。例如C语言中{}括起来的最小代码。 指令层级:单…...

玻璃采光顶结构的荷载及组合
玻璃采光顶结构的荷载及组合 1、玻璃采光顶结构的定义 (1)屋盖(roofsystem)根据《建筑结构设计术语和符号标准》(GB/T50083—97)定义如下: 在房屋顶部,用以承受各种屋面作用的屋面板、屋面梁或屋架及支撑系统组成的部件或以拱、 网架、薄壳和悬索等大跨空间构件与支承边缘…...

Rust的零大小类型ZST与幽灵数据PhantomData在类型系统中的作用
Rust语言以其独特的所有权系统和类型安全著称,而零大小类型(ZST)与幽灵数据(PhantomData)则是其类型系统中两个精妙的设计。它们看似无形,却在编译期静态检查、内存优化和泛型约束中扮演着关键角色。本文将…...