Stable Diffusion原理详解
Stable Diffusion原理详解
最近AI图像生成异常火爆,听说鹅厂都开始用AI图像生成做前期设定了,小厂更是直接用AI替代了原画师的岗位。这一张张丰富细腻、风格各异、以假乱真的AI生成图像,背后离不开Stable Diffusion算法。
Stable Diffusion是stability.ai开源的图像生成模型,可以说Stable Diffusion的发布将AI图像生成提高到了全新高度,其效果和影响不亚于Open AI发布ChatGPT。今天我们就一起学习一下Stable Diffusion的原理。

文章目录
- 图像生成的发展
- 扩散模型
- Transformer
- Stable Diffusion
- 潜在空间(Lantent Space)
- Latent Diffusion
- 感知压缩
- 感知损失
- 扩散损失
- 条件扩散
- 注意力机制
- 文本-图像合成
- 图像-图像合成
- 整体架构
- 总结
图像生成的发展
在Stable Diffusion诞生之前,计算机视觉和机器学习方面最重要的突破是 GAN(Generative Adversarial Networks 生成对抗网络)。GAN让超越训练数据已有内容成为可能,从而打开了一个全新领域——现在称之为生成建模。
然而,在经历了一段蓬勃发展后,GAN开始暴露出一些瓶颈和弊病,大家倾注了很多心血努力解决对抗性方法所面临的一些瓶颈,但是鲜有突破,GAN由此进入平台期。GAN的主要问题在于:
- 图像生成缺乏多样性
- 模式崩溃
- 多模态分布学习困难
- 训练时间长
- 由于问题表述的对抗性,不容易训练
另外,还有一条基于似然(例如,马尔可夫随机场)的技术路线,尽管已经存在很久,但由于对每个问题的实施和制定都很复杂,因此未能产生重大影响。
近几年,随着算力的增长,一些过去算力无法满足的复杂算法得以实现,其中有一种方法叫“扩散模型”——一种从气体扩散的物理过程中汲取灵感并试图在多个科学领域模拟相同现象的方法。该模型在图像生成领域展现了巨大的潜力,成为今天Stable Diffusion的基础。
扩散模型
扩散模型是一种生成模型,用于生成与训练数据相似的数据。简单的说,扩散模型的工作方式是通过迭代添加高斯噪声来“破坏”训练数据,然后学习如何消除噪声来恢复数据。
一个标准扩散模型有两个主要过程:正向扩散和反向扩散。
在正向扩散阶段,通过逐渐引入噪声来破坏图像,直到图像变成完全随机的噪声。
在反向扩散阶段,使用一系列马尔可夫链逐步去除预测噪声,从高斯噪声中恢复数据1。

对于噪声的估计和去除,最常使用的是 U-Net。该神经网络的架构看起来像字母 U,由此得名。U-Net 是一个全连接卷积神经网络,这使得它对图像处理非常有用。U-Net的特点在于它能够将图像作为入口,并通过减少采样来找到该图像的低维表示,这使得它更适合处理和查找重要属性,然后通过增加采样将图像恢复回来。

具体的说,所谓去除噪声就是从时间帧 ttt 向时间帧 t−1t-1t−1 的变换,其中 ttt 是 t0t_0t0 (没有噪声)到 tmaxt_{max}tmax(完全噪声)之间的任意时间帧。变换规则为:
- 输入时间帧 ttt 的图像,并且在该时间帧上图像存在特定噪声;
- 使用 U-Net 预测总噪声量;
- 然后在时间帧 ttt 的图像中去除总噪声的“一部分”,得到噪声较少的时间帧 t−1t-1t−1 的图像。

从数学上讲,执行此上述方法 TTT 次比尝试消除整个噪声更有意义。通过重复这个过程,噪声会逐渐被去除,我们会得到一个更“干净”的图像。比如对于带有噪声的图,我们通过在初始图像上添加完全噪声,然后再迭代地去除它来生成没有噪声的图像,效果比直接在原图上去除噪声要好。
近几年,扩散模型在图像生成任务中表现出突出的性能,并在图像合成等多个任务中取代了GAN。由于扩散模型能够保持数据的语义结构,因此不会受到模式崩溃的影响。
然而,实现扩散模型存在一些困难。因为所有马尔可夫状态都需要一直在内存中进行预测,这意味着内存中要一直保存多个大型深度网络的实例,从而导致扩散模型非常吃内存。此外,扩散模型可能会陷入图像数据中难以察觉的细粒度复杂性中,导致训练时间变得太长(几天到几个月)。矛盾的是,细粒度图像生成是扩散模型的主要优势之一,我们无法避免这个“甜蜜的烦恼”。由于扩散模型对计算要求非常高,训练需要非常大的内存和电量,这使得早前大多数研究人员无法在现实中实现该模型。
Transformer
Transformer是来自 NLP 领域的非常著名的模型方法。Transformer在语言建模和构建对话式 AI 工具方面取得了巨大成功。 在视觉应用中,Transformer 表现出了泛化和自适应的优势,这使得它们非常适合通用学习。 它们比其他技术能够更好地捕捉文本甚至图像中的语义结构。 然而,Transformers 需要大量数据,并且与其他方法相比,在许多视觉领域的性能方面也面临着平台期。
Transformer可以与扩散模型结合,通过Transformer的“词嵌入”可以将文本插入到模型中。这意味着将词Token化后,然后将这种文本表示添加到U-Net的输入(图像)中,经过每一层U-Net神经网络与图像一起进行变换。从第一次迭代开始到之后的每一次迭代都加入相同的文本,从而让文本“作为指南”生成图像,从有完整噪声的第一次迭代开始,然后进一步向下应用到整个迭代。
Stable Diffusion
扩散模型最大的问题是它的时间成本和经济成本都极其“昂贵”。Stable Diffusion的出现就是为了解决上述问题。如果我们想要生成一张 1024×10241024 \times 10241024×1024 尺寸的图像,U-Net 会使用 1024×10241024 \times 10241024×1024 尺寸的噪声,然后从中生成图像。这里做一步扩散的计算量就很大,更别说要循环迭代多次直到100%。一个解决方法是将大图片拆分为若干小分辨率的图片进行训练,然后再使用一个额外的神经网络来产生更大分辨率的图像(超分辨率扩散)。
2021年发布的Latent Diffusion模型给出了不一样的方法。 Latent Diffusion模型不直接在操作图像,而是在潜在空间中进行操作。通过将原始数据编码到更小的空间中,让U-Net可以在低维表示上添加和删除噪声。
潜在空间(Lantent Space)
潜在空间简单的说是对压缩数据的表示。所谓压缩指的是用比原始表示更小的数位来编码信息的过程。比如我们用一个颜色通道(黑白灰)来表示原来由RGB三原色构成的图片,此时每个像素点的颜色向量由3维变成了1维度。维度降低会丢失一部分信息,然而在某些情况下,降维不是件坏事。通过降维我们可以过滤掉一些不太重要的信息你,只保留最重要的信息。
假设我们像通过全连接的卷积神经网络训练一个图像分类模型。当我们说模型在学习时,我们的意思是它在学习神经网络每一层的特定属性,比如边缘、角度、形状等……每当模型使用数据(已经存在的图像)学习时,都会将图像的尺寸先减小再恢复到原始尺寸。最后,模型使用解码器从压缩数据中重建图像,同时学习之前的所有相关信息。因此,空间变小,以便提取和保留最重要的属性。这就是潜在空间适用于扩散模型的原因。


Latent Diffusion
“潜在扩散模型”(Latent Diffusion Model)将GAN的感知能力、扩散模型的细节保存能力和Transformer的语义能力三者结合,创造出比上述所有模型更稳健和高效的生成模型。与其他方法相比,Latent Diffusion不仅节省了内存,而且生成的图像保持了多样性和高细节度,同时图像还保留了数据的语义结构。
任何生成性学习方法都有两个主要阶段:感知压缩和语义压缩。
感知压缩
在感知压缩学习阶段,学习方法必须去除高频细节将数据封装到抽象表示中。此步骤对构建一个稳定、鲁棒的环境表示是必要的。GAN 擅长感知压缩,通过将高维冗余数据从像素空间投影到潜在空间的超空间来实现这一点。潜在空间中的潜在向量是原始像素图像的压缩形式,可以有效地代替原始图像。
更具体地说,用自动编码器 (Auto Encoder) 结构捕获感知压缩。 自动编码器中的编码器将高维数据投影到潜在空间,解码器从潜在空间恢复图像。

#### 语义压缩
在学习的第二阶段,图像生成方法必须能够捕获数据中存在的语义结构。 这种概念和语义结构提供了图像中各种对象的上下文和相互关系的保存。 Transformer擅长捕捉文本和图像中的语义结构。 Transformer的泛化能力和扩散模型的细节保存能力相结合,提供了两全其美的方法,并提供了一种生成细粒度的高度细节图像的方法,同时保留图像中的语义结构。
感知损失
潜在扩散模型中的自动编码器通过将数据投影到潜在空间来捕获数据的感知结构。论文作者使用一种特殊的损失函数来训练这种称为“感知损失”的自动编码器。该损失函数确保重建限制在图像流形内,并减少使用像素空间损失(例如 L1/L2 损失)时出现的模糊。
扩散损失
扩散模型通过从正态分布变量中逐步去除噪声来学习数据分布。换句话说,扩散模型使用长度为 TTT 的反向马尔可夫链。这也意味着扩散模型可以建模为时间步长为 t=1,…,Tt =1,\dots,Tt=1,…,T 的一系列“T”去噪自动编码器。由下方公式中的 ϵθ\epsilon_\thetaϵθ表示:
LDM=Ex,ϵ∼N(0,1),t[∣∣ϵ−ϵθ(xt,t)∣∣22](1)L_{DM} = \mathbb{E}_{x, \epsilon \sim \mathcal{N}(0, 1), t} \Big\lbrack||\epsilon-\epsilon_\theta(x_t, t)||_2^2\Big\rbrack \tag{1} LDM=Ex,ϵ∼N(0,1),t[∣∣ϵ−ϵθ(xt,t)∣∣22](1)
公式(1)给出了扩散模型的损失函数。在潜在扩散模型中,损失函数取决于潜在向量而不是像素空间。我们将像素空间元素xxx替换成潜在向量ε(x)\varepsilon(x)ε(x),将t时间的状态xtx_txt替换为去噪U-Net在时间t的潜在状态ztz_tzt,即可得到潜在扩散模型的损失函数,见公式(2):
LLDM:=Eε(x),ϵ∼N(0,1),t[∣∣ϵ−ϵθ(zt,t)∣∣22](2)L_{LDM} := \mathbb{E}_{\varepsilon(x), \epsilon\sim \mathcal{N}(0, 1), t} \Big\lbrack||\epsilon-\epsilon_\theta(z_t, t)||_2^2\Big\rbrack \tag{2} LLDM:=Eε(x),ϵ∼N(0,1),t[∣∣ϵ−ϵθ(zt,t)∣∣22](2)
将公式(2)写成条件损失函数,得到公式(3):
LLDM:=Eε(x),y,ϵ∼N(0,1),t[∣∣ϵ−ϵθ(zt,t),τθ(y)∣∣22](3)L_{LDM} := \mathbb{E}_{\varepsilon(x), y, \epsilon\sim \mathcal{N}(0, 1), t} \Big\lbrack||\epsilon-\epsilon_\theta(z_t, t),\tau_\theta(y)||_2^2 \Big\rbrack \tag{3} LLDM:=Eε(x),y,ϵ∼N(0,1),t[∣∣ϵ−ϵθ(zt,t),τθ(y)∣∣22](3)
其中τθ(y)\tau_\theta(y)τθ(y)是条件yyy下的领域专用编码器(比如Transformer)。
条件扩散
扩散模型是依赖于先验的条件模型。在图像生成任务中,先验通常是文本、图像或语义图。为了获得先验的潜在表示,需要使用转换器(例如 CLIP)将文本/图像嵌入到潜在向量τ\tauτ中。因此,最终的损失函数不仅取决于原始图像的潜在空间,还取决于条件的潜在嵌入。
注意力机制
潜在扩散模型的主干是具有稀疏连接的 U-Net 自动编码器,提供交叉注意力机制2。Transformer 网络将条件文本/图像编码为潜在嵌入,后者又通过交叉注意力层映射到 U-Net 的中间层。这个交叉注意力层实现了注意力 (Q,K,V)=softmax(QKT/d)V(Q,K,V) = softmax(QKT/\sqrt{d}) V(Q,K,V)=softmax(QKT/d)V,其中 Q、K 和 V 是可学习的投影矩阵
文本-图像合成
在 Python 实现中,我们可以使用使用 LDM v4 的最新官方实现来生成图像。 在文本到图像的合成中,潜在扩散模型使用预训练的 CLIP 模型3,该模型为文本和图像等多种模态提供基于Transformer的通用嵌入。 然后将Transformer模型的输出输入到称为“diffusers”的潜在扩散模型Python API,同时还可以设置一些参数(例如,扩散步数、随机数种子、图像大小等)。
图像-图像合成
相同的方法同样适用于图像到图像的合成,不同的是需要输入样本图像作为参考图像。生成的图像在语义和视觉上与作为参考给出的图像相似。这个过程在概念上类似于基于样式的 GAN 模型,但它在保留图像的语义结构方面做得更好。
整体架构
上面介绍了潜在扩散模型的各个主要技术部分,下面我们将它们合成一个整理,看一下潜在扩散模型的完整工作流程。

上图中 xxx 表示输入图像,x~\tilde{x}x~ 表示生成的图像;ε\varepsilonε 是编码器,D\cal{D}D 是解码器,二者共同构成了感知压缩;zzz 是潜在向量;zTz_TzT 是增加噪声后的潜在向量;τθ\tau_\thetaτθ 是文本/图像的编码器(比如Transformer或CLIP),实现了语义压缩。
总结
本文向大家介绍了图像生成领域最前沿的Stable Diffusion模型。本质上Stable Diffusion属于潜在扩散模型(Latent Diffusion Model)。潜在扩散模型在生成细节丰富的不同背景的高分辨率图像方面非常稳健,同时还保留了图像的语义结构。 因此,潜在扩散模型是图像生成即深度学习领域的一项重大进步。 Stable Diffusion只是将潜在扩散模型应用于高分辨率图像,同时使用 CLIP 作为文本编码器。
说了这么多理论,想必大家已经迫不及待跃跃欲试了。别着急,后面我会手把手教大家搭建Stable Diffusion本地环境,让大家可以亲手体验Stable Diffusion的威力。

Jonathan Ho, Ajay Jain, Pieter Abbeel, “Denoising Diffusion Probabilistic Models”, 2020 ↩︎
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, “Attention Is All You Need”, 2017 ↩︎
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever, “Learning Transferable Visual Models From Natural Language Supervision”, 2021 ↩︎
相关文章:
Stable Diffusion原理详解
Stable Diffusion原理详解 最近AI图像生成异常火爆,听说鹅厂都开始用AI图像生成做前期设定了,小厂更是直接用AI替代了原画师的岗位。这一张张丰富细腻、风格各异、以假乱真的AI生成图像,背后离不开Stable Diffusion算法。 Stable Diffusion…...

webpack高级配置
摇树(tree shaking) 我主要是想说摇树失败的原因(tree shaking 失败的原因),先讲下摇树本身效果 什么是摇树? 举个例子 首先 webpack.config.js配置 const webpack require("webpack");/**…...
jQuery 事件
jQuery 事件 Date: February 28, 2023 Sum: jQuery事件注册、处理、对象 目标: 能够说出4种常见的注册事件 能够说出 on 绑定事件的优势 能够说出 jQuery 事件委派的优点以及方式 能够说出绑定事件与解绑事件 jQuery 事件注册 单个时间注册 语法:…...

【批处理脚本】-2.3-解析地址命令arp
"><--点击返回「批处理BAT从入门到精通」总目录--> 共2页精讲(列举了所有arp的用法,图文并茂,通俗易懂) 目录 1 arp命令解析 1.1 询问当前协议数据,显示当前 ARP 项...

改进 YOLO V5 的密集行人检测算法研究(论文研读)——目标检测
改进 YOLO V5 的密集行人检测算法研究(2021.08)摘 要:1 YOLO V52 SENet 通道注意力机制3 改进的 YOLO V5 模型3.1 训练数据处理改进3.2 YOLO V5 网络改进3.3 损失函数改进3.3.1 使用 CIoU3.3.2 非极大值抑制改进4 研究方案与结果分析4.1 实验…...
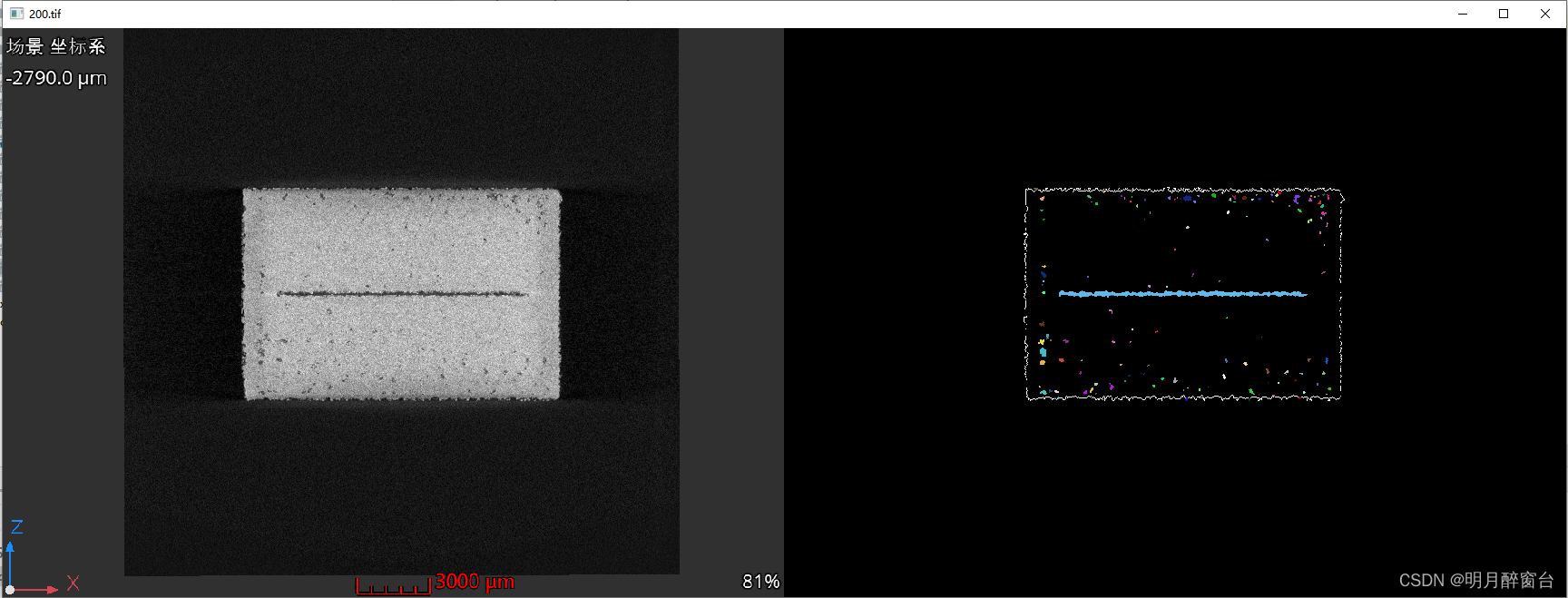
Python - Opencv应用实例之CT图像检测边缘和内部缺陷
Python - Opencv应用实例之CT图像检测边缘和内部缺陷 将传统图像处理处理算法应用于CT图像的边缘检测和缺陷检测,想要实现效果如下: 关于图像处理算法,主要涉及的有:灰度、阈值化、边缘或角点等特征提取、灰度相似度变换,主要偏向于一些2D的几何变换、涉及图像矩阵的一些统…...
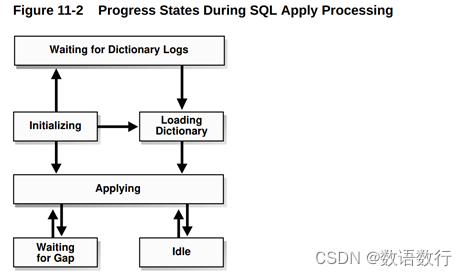
管理逻辑备数据库(Logical Standby Database)
1. SQL Apply架构概述 SQL Apply使用一组后台进程来应用来自主数据库的更改到逻辑备数据库。 在日志挖掘和应用处理中涉及到的不同的进程和它们的功能如下: 在日志挖掘过程中: 1)READER进程从归档redo日志文件或备redo日志文件中读取redo记…...

【C++】构造函数(初始化列表)、explicit、 Static成员、友元、内部类、匿名对象
构造函数(初始化列表)前提构造函数体赋值初始化列表explicit关键字static成员概念特性(重要)有元友元函数友元类内部类匿名对象构造函数(初始化列表) 前提 前面 六个默认成员对象中我们已经学过什么是构造…...
再来看看几个最常见和最基本的索引使用规则)
(六十)再来看看几个最常见和最基本的索引使用规则
今天我们来讲一下最常见和最基本的几个索引使用规则,也就是说,当我们建立好一个联合索引之后,我们的SQL语句要怎么写,才能让他的查询使用到我们建立好的索引呢? 下面就一起来看看,还是用之前的例子来说明。…...

机器学习与目标检测作业(数组相加:形状需要满足哪些条件)
机器学习与目标检测(数组相加:形状需要满足哪些条件)机器学习与目标检测(数组相加:形状需要满足哪些条件)一、形状相同1.1、形状相同示例程序二、符合广播机制2.1、符合广播机制的描述2.2、符合广播机制的示例程序机器学习与目标检…...
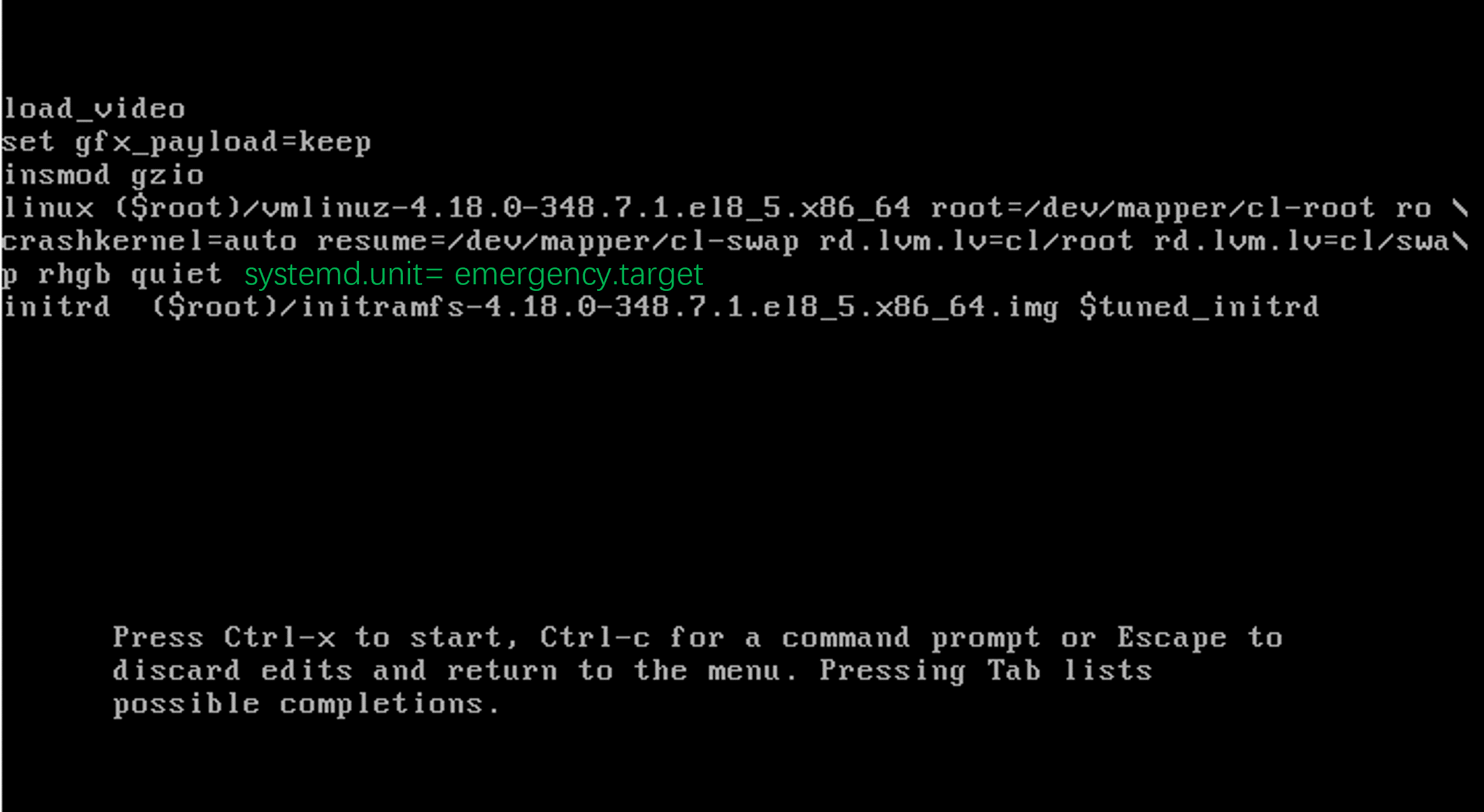
CentOS救援模式(Rescue Mode)及紧急模式(Emergency Mode)
当CentOS操作系统崩溃,无法正常启动时,可以通过救援模式或者紧急模式进行系统登录。启动CentOS, 当出现下面界面时,按e进入编辑界面。在编辑界面里,加入参数:systemd.unitrescue.target ,然后Ctrl-X启动进入…...
从面试官角度告诉你高级性能测试工程师面试必问的十大问题
目录 1、介绍下最近做过的项目,背景、预期指标、系统架构、场景设计及遇到的性能问题,定位分析及优化; 2、项目处于什么阶段适合性能测试介入,原因是什么? 3、性能测试场景设计要考虑哪些因素? 4、对于一…...
通过知识库深度了解用户的心理
自助服务知识库的价值是毋庸置疑的,如果执行得当,可以帮助减少客户服务团队的工作量,仅仅编写内容和发布是不够的,需要知道知识库对客户来说是否有用,需要了解客户获得的反馈,如果你正确的使用知识库软件&a…...
HiveSQL一天一个小技巧:如何将分组内数据填充完整?
0 需求1 需求分析需求分析:需求中需要求出分组中按成绩排名取倒数第二的值作为新字段,且分组内没有倒数第二条的时候取当前值。如果本题只是求分组内排序后倒数第二,则很简单,使用row_number()函数即可求出,但是本题问…...
【亲测可用】BEV Fusion (MIT) 环境配置
CUDA环境 首先我们需要打上对应版本的显卡驱动: 接下来下载CUDA包和CUDNN包: wget https://developer.download.nvidia.com/compute/cuda/11.6.2/local_installers/cuda_11.6.2_510.47.03_linux.run sudo sh cuda_11.6.2_510.47.03_linux.runwget htt…...
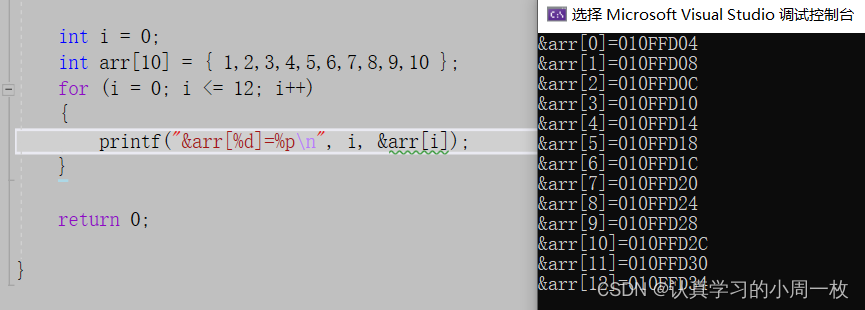
【调试方法】基于vs环境下的实用调试技巧
前言: 对万千程序猿来说,在这个世界上如果有比写程序更痛苦的事情,那一定是亲手找出自己编写的程序中的bug(漏洞)。作为新手在我们日常写代码中,经常会出现报错的情况(好的程序员只是比我们见过…...

单目标应用:蜣螂优化算法DBO优化RBF神经网络实现数据预测(提供MATLAB代码)
一、RBF神经网络 1988年,Broomhead和Lowc根据生物神经元具有局部响应这一特点,将RBF引入神经网络设计中,产生了RBF(Radical Basis Function)。1989年,Jackson论证了RBF神经网络对非线性连续函数的一致逼近性能。 RBF的基本思想是…...
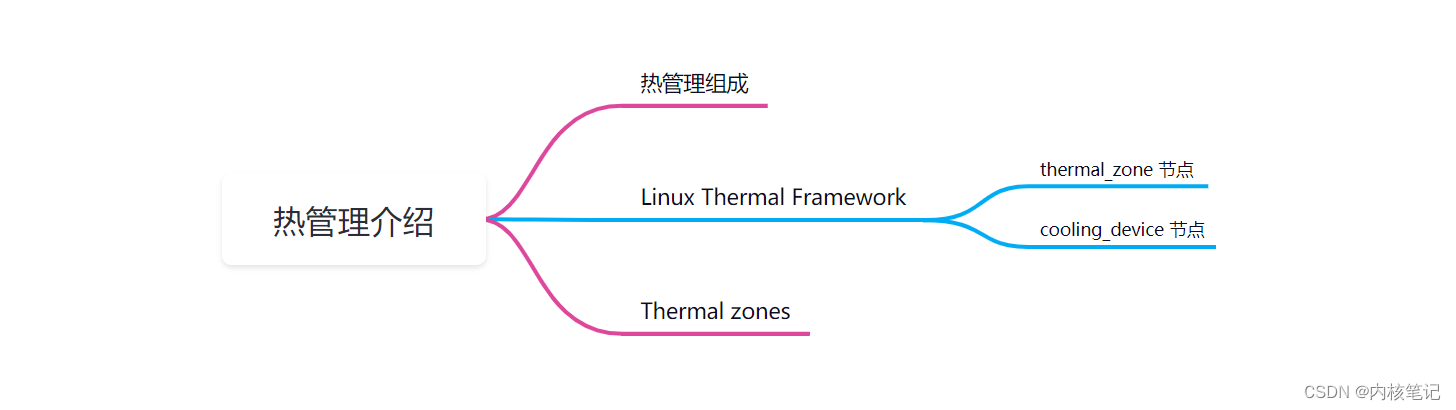
MTK平台开发入门到精通(Thermal篇)热管理介绍
文章目录 一、热管理组成二、Linux Thermal Framework2.1、thermal_zone 节点2.2、cooling_device 节点三、Thermal zones沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇文章将介绍MTK平台的热管理机制,热管理机制是为了防止模组在高温下工作导致硬件损坏而存在的…...
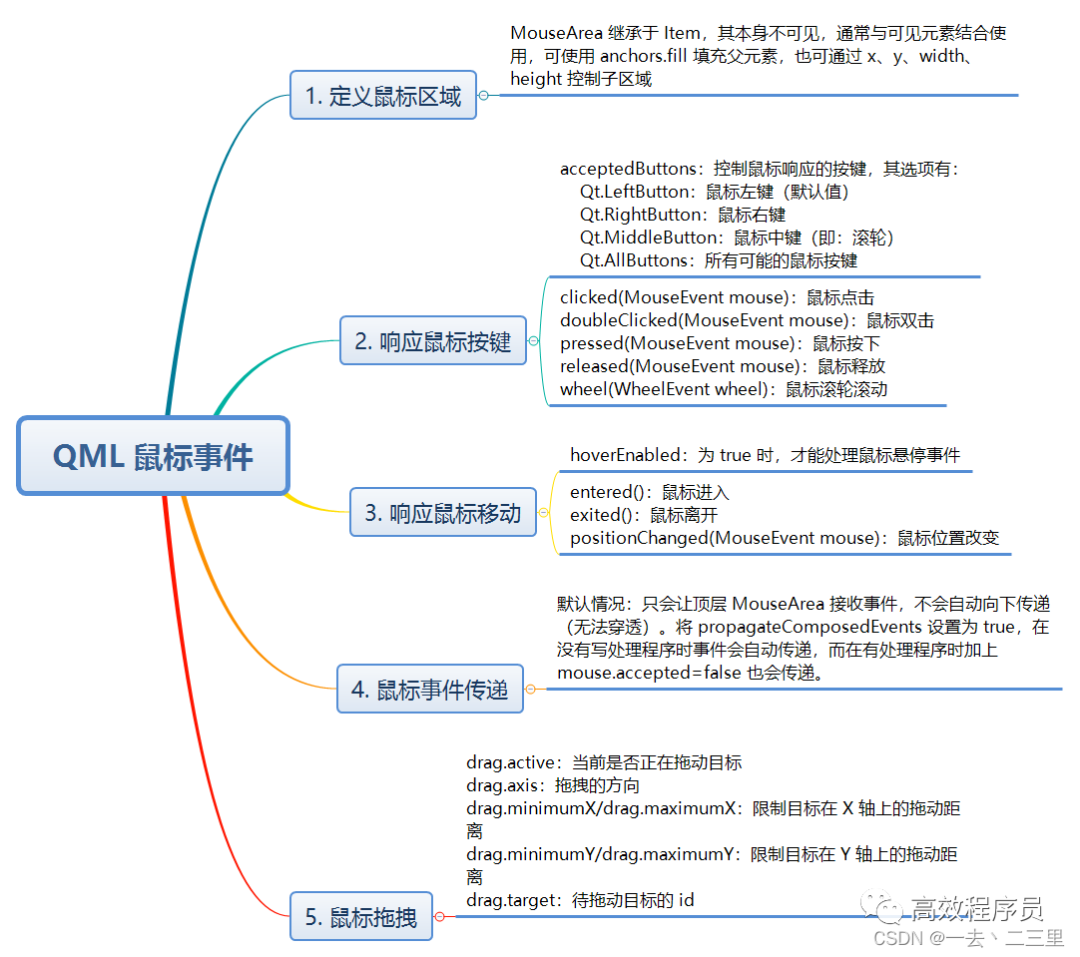
最好的 QML 教程,让你的代码飞起来!
想必大家都知道,亮哥一直深耕于 CSDN,坚持了好很多年,目前为止,原创已经 500 多篇了,一路走来相当不易。当然了,中间有段时间比较忙,没怎么更新。就拿 QML 来说,最早的一篇文章还是 …...
——stack容器的基础理论知识)
笔记(六)——stack容器的基础理论知识
stack是堆栈容器,元素遵循先进后出的顺序。头文件:#include<stack>一、stack容器的对象构造方法stack采用模板类实现默认构造例如stack<T> vecT;#include<iostream> #include<stack> using namespace std; int main(…...

嵌入式处理器IP选型指南:从ARM到RISC-V的权衡与实战
1. 从一场早餐会聊起:为什么32位处理器IP依然是嵌入式开发的硬通货最近在整理资料时,翻到一篇十多年前的老新闻,说的是IP供应商CAST要在DesignCon 2012上办一场免费的早餐研讨会,主题是他们新推出的BA22 32位处理器IP核。新闻里笔…...

Remix Icon终极指南:3200+免费矢量图标库的完整使用手册
Remix Icon终极指南:3200免费矢量图标库的完整使用手册 【免费下载链接】RemixIcon Open source neutral style icon system 项目地址: https://gitcode.com/gh_mirrors/re/RemixIcon 还在为项目寻找高质量的免费图标而烦恼吗?🤔 每天…...

SAP ABAP BADI AC_DOCUMENT:跨越VF01/MIRO/AFAB的智能凭证替代实战
1. 为什么需要AC_DOCUMENT BADI? 在SAP标准业务流程中,GGB1提供的凭证替代功能已经能满足大部分常规需求。但实际业务往往更复杂——比如销售开票时,需要根据付款条件动态替换税科目;发票校验时,要根据供应商信息自动填…...

从理论到仿真:深入解读Walker星座设计,用STK验证你的卫星通信作业
从理论到仿真:深入解读Walker星座设计,用STK验证你的卫星通信作业 卫星通信系统的设计从来不是纸上谈兵。当你在教科书上看到那些优美的轨道方程和覆盖计算公式时,是否想过如何将它们转化为真实的系统性能验证?这正是STKÿ…...

终极KMS激活指南:如何永久免费激活Windows和Office系统
终极KMS激活指南:如何永久免费激活Windows和Office系统 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows激活弹窗而烦恼吗?是否遇到过Office突然变成只读模式…...

基于FreeRTOS与LVGL的智能手表开源系统InfiniTime开发指南
1. 项目概述:为你的智能手表注入灵魂 如果你手上有一块PineTime或者类似的低功耗智能手表,并且对官方固件那有限的功能感到意犹未尽,那么“InfiniTime”这个名字你应该不会陌生。它不是一个简单的应用商店,而是一个为这类开源硬件…...

专业右键菜单管理:用ContextMenuManager一键重塑Windows操作效率
专业右键菜单管理:用ContextMenuManager一键重塑Windows操作效率 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 在Windows生态中,右键菜…...

ARM GICv4.1 GICD_TYPER2寄存器详解与虚拟化应用
1. GICD_TYPER2寄存器概述 GICD_TYPER2是ARM GICv4.1架构中引入的关键寄存器,属于中断控制器类型寄存器家族。作为GIC Distributor的一部分,它专门用于增强虚拟化场景下的中断管理能力。这个32位寄存器位于内存映射地址Dist_base 0x000C处,仅…...

MCP协议与n8n集成:构建标准化AI自动化工作流
1. 项目概述:当MCP遇见n8n,一个自动化新范式的诞生最近在折腾自动化工作流,特别是想把不同AI模型的能力串联起来,发现了一个挺有意思的项目:brunopelatieri/mcp-n8n-bruia。这名字乍一看有点复杂,拆开来看&…...

Hperledger Fabric入门课程3 ——软硬件环境
购买专栏前请认真阅读:《Fabric项目学习笔记》专栏介绍 1. 硬件环境 不论是在当前系统上运行、云服务器还是虚拟机,建议内存4G或以上,硬盘空间建议50G以上。 2. 操作系统 Fabric 的操作一般在Linux 或 MacOS上,Mac暂时不支持Apple Silicon芯片即m1以后的芯片。 如果读者…...