HuggingFace学习笔记--Tokenizer的使用
1--AutoTokenizer的使用
官方文档
AutoTokenizer() 常用于分词,其可调用现成的模型来对输入句子进行分词。
1-1--简单Demo
测试代码:
# 分词器测试Demo
from transformers import AutoTokenizerif __name__ == "__main__":checkpoint = "distilbert-base-uncased-finetuned-sst-2-english" # 使用该模型tokenlizer = AutoTokenizer.from_pretrained(checkpoint) # 加载该模型对应的分词器raw_input = ["I love kobe bryant.","Me too."]inputs = tokenlizer(raw_input, padding = True, return_tensors = "pt") # padding并返回pytorch版本的tensorprint("After tokenlizer: \n", inputs) # 打印分词后的结果str1 = tokenlizer.decode(inputs['input_ids'][0]) # 将词ID恢复print("str1: \n", str1)print("All done!")输出结果:
After tokenlizer:
{
'input_ids': tensor([[101, 1045, 2293, 24113, 12471, 1012, 102],[101, 2033, 2205, 1012, 102, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 0, 0]])
}
str1: [CLS] i love kobe bryant. [SEP]分析:
上述代码将输入的句子进行分词,并将每一个词利用一个 ID 进行映射;例如上述代码中,101 对应 [CLS],1045 对应 I,2293 对应 love,24113 对应 kobe,12471 对应 bryant,1012 对应 . 符号,102 对应 [SEP];
input_ids 存储了每一个句子分词后对应的 ID,0 表示 padding 的词;由于上面测试代码设置了padding,因此会将每一个句子自动padding为最长句子的长度,padding的词用 0 来表示。
attention_mask 标记了哪些词是真正有意义的,只有为 1 的词才会参与后续的 attention 等计算。
利用 decode 可以将词 ID 重新解码为句子。
1-2--常用参数
1-2-1--padding
设置 padding 时,可以指定具体的 padding 长度;
from transformers import AutoTokenizerif __name__ == "__main__":checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"tokenlizer = AutoTokenizer.from_pretrained(checkpoint) raw_input = ["I love kobe bryant.","Me too."]input1 = tokenlizer(raw_input, padding = "longest", return_tensors = "pt") # padding长度与输入中的最长句子相同input2 = tokenlizer(raw_input, padding = "max_length", return_tensors = "pt") # padding到最大句子长度,默认是512input3 = tokenlizer(raw_input, padding = "max_length", max_length = 10, return_tensors = "pt") # 指定最大长度是10print("After tokenlizer: \n", input1['input_ids'].shape)print("After tokenlizer: \n", input2['input_ids'].shape)print("After tokenlizer: \n", input3['input_ids'].shape)
输出结果:
After tokenlizer: torch.Size([2, 7])
After tokenlizer: torch.Size([2, 512])
After tokenlizer: torch.Size([2, 10])1-2-2--truncation
设置 truncation 时,用于截断,可以指定截断的长度。
from transformers import AutoTokenizerif __name__ == "__main__":checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"tokenlizer = AutoTokenizer.from_pretrained(checkpoint) raw_input = ["I love kobe bryant.","Me too."]# 长度超过5的部分会被截断input1 = tokenlizer(raw_input, padding = "longest", truncation = True, max_length=5, return_tensors = "pt")print("After tokenlizer: \n", input1)str1 = tokenlizer.decode(input1['input_ids'][0]) # 将词ID恢复print("str1: \n", str1)输出结果:
After tokenlizer:
{
'input_ids': tensor([[ 101, 1045, 2293, 24113, 102],[ 101, 2033, 2205, 1012, 102]]),
'attention_mask': tensor([[1, 1, 1, 1, 1],[1, 1, 1, 1, 1]])
}
str1: [CLS] i love kobe [SEP]2--BertTokenizer的使用
2-1--简单Demo
① 编码两个句子:
from transformers import BertTokenizerif __name__ == "__main__":tokenizer = BertTokenizer.from_pretrained(pretrained_model_name_or_path = 'bert-base-chinese')sents = ['我喜欢科比布莱恩特.', '我也是.', '我喜欢他的后仰跳投', '我喜欢他的曼巴精神']# 编码两个句子 inputs = tokenizer.encode(text = sents[0],text_pair = sents[1],truncation = True, # 截断padding = 'max_length', # padding到最大长度add_special_tokens = True,max_length = 20, # 设置最大长度return_tensors = None # None默认返回list,可取值tf,pt,np)print(inputs)print(tokenizer.decode(inputs))
输出结果:
inputs: [101, 2769, 1599, 3614, 4906, 3683, 2357, 5812, 2617, 4294, 119, 102, 2769, 738, 3221, 119, 102, 0, 0, 0]
decode: [CLS] 我 喜 欢 科 比 布 莱 恩 特. [SEP] 我 也 是. [SEP] [PAD] [PAD] [PAD]② 增强编码
from transformers import BertTokenizerif __name__ == "__main__":tokenizer = BertTokenizer.from_pretrained(pretrained_model_name_or_path = 'bert-base-chinese')sents = ['我喜欢科比布莱恩特.', '我也是.', '我喜欢他的后仰跳投', '我喜欢他的曼巴精神']# 增强编码两个句子inputs = tokenizer.encode_plus(text = sents[0],text_pair = sents[1],truncation = True, # 截断padding = 'max_length', # padding到最大长度add_special_tokens = True,max_length = 30, # 设置最大长度return_tensors = None, # None默认返回list,可取值tf,pt,np,return_token_type_ids = True,return_attention_mask = True,return_special_tokens_mask = True,return_length = True)for k, v in inputs.items():print(k, ':', v)print(tokenizer.decode(inputs['input_ids']))输出结果:
input_ids : [101, 2769, 1599, 3614, 4906, 3683, 2357, 5812, 2617, 4294, 119, 102, 2769, 738, 3221, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]token_type_ids : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]special_tokens_mask : [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]attention_mask : [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]length : 30decode: [CLS] 我 喜 欢 科 比 布 莱 恩 特. [SEP] 我 也 是. [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]③ 批量编码:
from transformers import BertTokenizerif __name__ == "__main__":tokenizer = BertTokenizer.from_pretrained(pretrained_model_name_or_path = 'bert-base-chinese')sents = ['我喜欢科比布莱恩特.', '我也是.', '我喜欢他的后仰跳投', '我喜欢他的曼巴精神']# 批量编码句子inputs = tokenizer.batch_encode_plus(batch_text_or_text_pairs = [sents[0], sents[1]],truncation = True, # 截断padding = 'max_length', # padding到最大长度add_special_tokens = True,max_length = 20, # 设置最大长度return_tensors = None, # None默认返回list,可取值tf,pt,np,return_token_type_ids = True,return_attention_mask = True,return_special_tokens_mask = True,return_length = True)for k, v in inputs.items():print(k, ':', v)print("decode: \n", tokenizer.decode(inputs['input_ids'][0]))print("decode: \n", tokenizer.decode(inputs['input_ids'][1]))输出结果:
input_ids : [[101, 2769, 1599, 3614, 4906, 3683, 2357, 5812, 2617, 4294, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0], [101, 2769, 738, 3221, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]token_type_ids : [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]special_tokens_mask : [[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]length : [12, 6]attention_mask : [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]decode: [CLS] 我 喜 欢 科 比 布 莱 恩 特. [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]decode: [CLS] 我 也 是. [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]④ 批量编码成对的句子:
from transformers import BertTokenizerif __name__ == "__main__":tokenizer = BertTokenizer.from_pretrained(pretrained_model_name_or_path = 'bert-base-chinese')sents = ['我喜欢科比布莱恩特.', '我也是.', '我喜欢他的后仰跳投', '我喜欢他的曼巴精神']# 批量编码成对的句子inputs = tokenizer.batch_encode_plus(batch_text_or_text_pairs=[(sents[0], sents[1]), (sents[2], sents[3])],truncation = True, # 截断padding = 'max_length', # padding到最大长度add_special_tokens = True,max_length = 20, # 设置最大长度return_tensors = None, # None默认返回list,可取值tf,pt,np,return_token_type_ids = True,return_attention_mask = True,return_special_tokens_mask = True,return_length = True)for k, v in inputs.items():print(k, ':', v)print("decode: \n", tokenizer.decode(inputs['input_ids'][0]))print("decode: \n", tokenizer.decode(inputs['input_ids'][1]))输出结果:
input_ids : [[101, 2769, 1599, 3614, 4906, 3683, 2357, 5812, 2617, 4294, 119, 102, 2769, 738, 3221, 119, 102, 0, 0, 0], [101, 2769, 1599, 3614, 800, 4638, 1400, 814, 6663, 2832, 102, 2769, 1599, 3614, 800, 4638, 3294, 2349, 5125, 102]]token_type_ids : [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]]special_tokens_mask : [[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1]]length : [17, 20]attention_mask : [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]decode: [CLS] 我 喜 欢 科 比 布 莱 恩 特. [SEP] 我 也 是. [SEP] [PAD] [PAD] [PAD]decode: [CLS] 我 喜 欢 他 的 后 仰 跳 投 [SEP] 我 喜 欢 他 的 曼 巴 精 [SEP]⑤ 获取字典:
from transformers import BertTokenizerif __name__ == "__main__":tokenizer = BertTokenizer.from_pretrained(pretrained_model_name_or_path = 'bert-base-chinese')sents = ['我喜欢科比布莱恩特.', '我也是.', '我喜欢他的后仰跳投', '我喜欢他的曼巴精神']# 批量编码成对的句子inputs = tokenizer.batch_encode_plus(batch_text_or_text_pairs=[(sents[0], sents[1]), (sents[2], sents[3])],truncation = True, # 截断padding = 'max_length', # padding到最大长度add_special_tokens = True,max_length = 20, # 设置最大长度return_tensors = None, # None默认返回list,可取值tf,pt,np,return_token_type_ids = True,return_attention_mask = True,return_special_tokens_mask = True,return_length = True)# 获取字典token_dict = tokenizer.get_vocab()print(type(token_dict))print(len(token_dict))print('喜' in token_dict) # 中文是按字来编码的,因此喜在字典里print('喜欢' in token_dict) # 同理,喜欢不在字典里输出结果:
<class 'dict'>
21128
True
False⑥ 添加新字典:
from transformers import BertTokenizerif __name__ == "__main__":tokenizer = BertTokenizer.from_pretrained(pretrained_model_name_or_path = 'bert-base-chinese')sents = ['我喜欢科比布莱恩特.', '我也是.', '我喜欢他的后仰跳投', '我喜欢他的曼巴精神']# 批量编码成对的句子inputs = tokenizer.batch_encode_plus(batch_text_or_text_pairs=[(sents[0], sents[1]), (sents[2], sents[3])],truncation = True, # 截断padding = 'max_length', # padding到最大长度add_special_tokens = True,max_length = 20, # 设置最大长度return_tensors = None, # None默认返回list,可取值tf,pt,np,return_token_type_ids = True,return_attention_mask = True,return_special_tokens_mask = True,return_length = True)# 添加新词tokenizer.add_tokens(new_tokens=['喜欢', '跳投'])# 添加新符号tokenizer.add_special_tokens({'eos_token': '[EOS]'})# 获取字典token_dict = tokenizer.get_vocab()print('喜欢' in token_dict) # 添加新词后,喜欢在字典里print('喜欢: ', token_dict['喜欢'])print('跳投: ', token_dict['跳投'])print('[EOS]: ', token_dict['[EOS]'])# 编码新句子,测试新词的编码test = tokenizer.encode(text = '我喜欢科比的后仰跳投[EOS]',text_pair = None,truncation = True,padding = 'max_length',add_special_tokens = True,max_length = 15,return_tensors = None)print(test)输出结果:
True
喜欢: 21128
跳投: 21129
[EOS]: 21130
[101, 2769, 21128, 4906, 3683, 4638, 1400, 814, 21129, 21130, 102, 0, 0, 0, 0]# 将喜欢、跳投和[EOS]直接编码,并没有拆开按字来编码相关文章:

HuggingFace学习笔记--Tokenizer的使用
1--AutoTokenizer的使用 官方文档 AutoTokenizer() 常用于分词,其可调用现成的模型来对输入句子进行分词。 1-1--简单Demo 测试代码: # 分词器测试Demo from transformers import AutoTokenizerif __name__ "__main__":checkpoint "…...
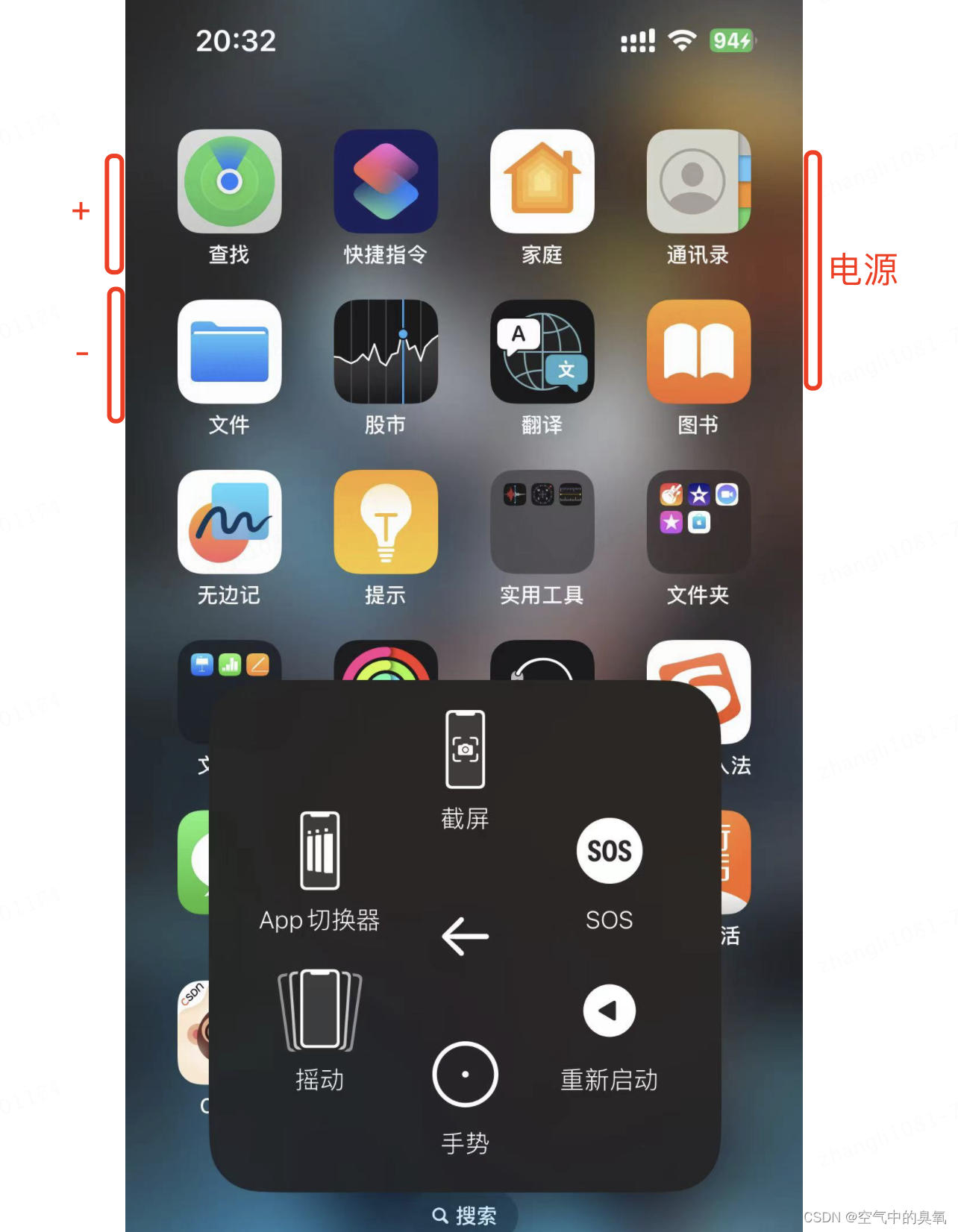
解决苹果手机iphone手机强制重启
强制关机: 方法1.同时按住左侧的,- 键中的一个和右侧的电源键 方法2.点击桌面的悬浮键–设备–更多–重新启动...
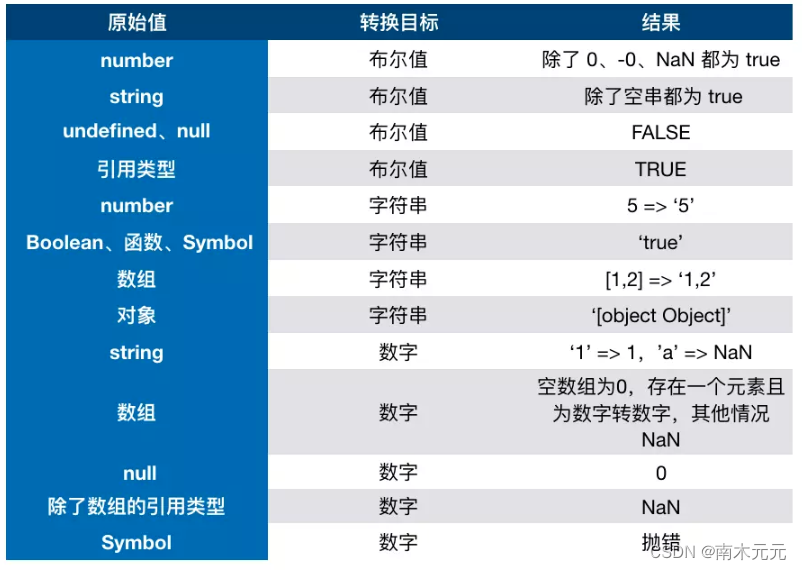
10分钟的时间,带你彻底搞懂JavaScript数据类型转换
前言 📫 大家好,我是南木元元,热衷分享有趣实用的文章,希望大家多多支持,一起进步! 🍅 个人主页:南木元元 目录 JS数据类型 3种转换类型 ToBoolean ToString ToNumber 对象转原…...
好用的chatgpt工具用过这个比较快
chatgpthttps://www.askchat.ai?r237422 chatGPT能做什么 1. 对话和聊天:我可以与您进行对话和聊天,回答您的问题、提供信息和建议。 2. 问题回答:无论是关于事实、历史、科学、文化、地理还是其他领域的问题,我都可以尽力回答…...
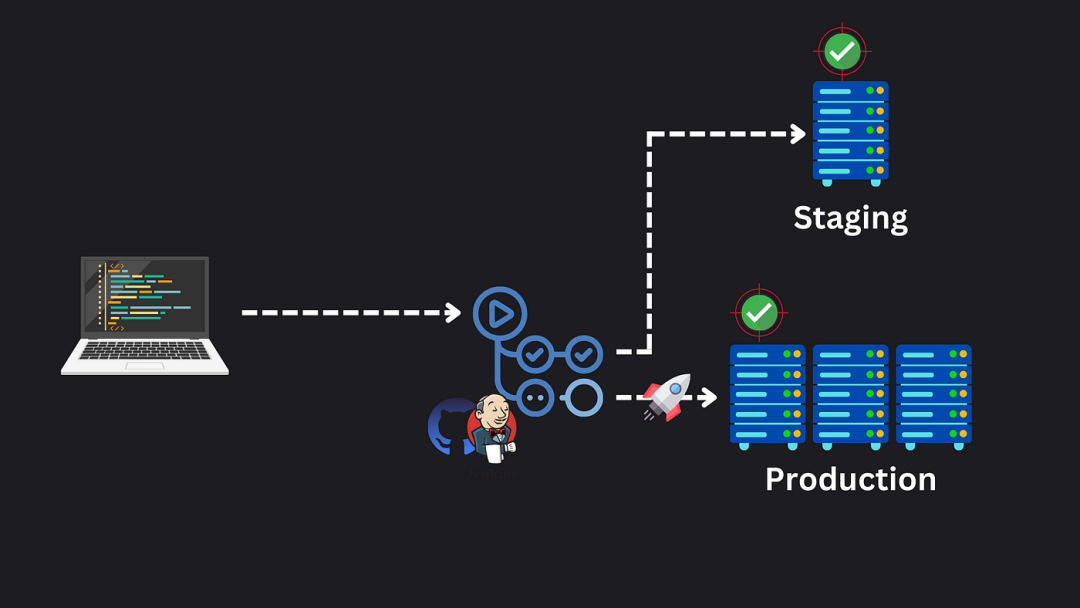
系统设计概念:生产 Web 应用的架构
在你使用的每个完美应用程序背后,都有一整套的架构、测试、监控和安全措施。今天,让我们来看看一个生产就绪应用程序的非常高层次的架构。 CI/CD 管道 我们的第一个关键领域是持续集成和持续部署——CI/CD 管道。 这确保我们的代码从存储库经过一系列测试…...
基于docker的onlyoffice使用--运行JavaSpringExample
背景 我之前看到有开源项目很好地集成了onlyoffice,效果要比kkfilepreview好(应当说应用场景不太一样)。本文是在window10环境,安装完Docker Desktop的基础上运行onlyoffice,并利用官网JavaSpringExample进行了集成。 …...

SQL server-excel数据追加到表
参考文章:SQL server 2019 从Excel导入数据_mssql2019 导入excel数据-CSDN博客 将excel数据导入到SQL server数据库的详细过程 注意:第一行数据默认为数据库表中的字段,所以这个必须要有,否则无法映射导入 问题1:ADD…...

深度学习-模型调试经验总结
1、 这句话的意思是:期望张量的后端处理是在cpu上,但是实际是在cuda上。排查代码发现,数据还在cpu上,但是模型已经转到cuda上,所以可以通过把数据转到cuda上解决。 解决代码: tensor.to("cuda")…...
Redis打包事务,分批提交
一、需求背景 接手一个老项目,在项目启动的时候,需要将xxx省整个省的所有区域数据数据、以及系统字典配置逐条保存在Redis缓存里面,这样查询的时候会更快; 区域数据字典数据一共大概20000多条,,前同事直接使用 list.forEach…...
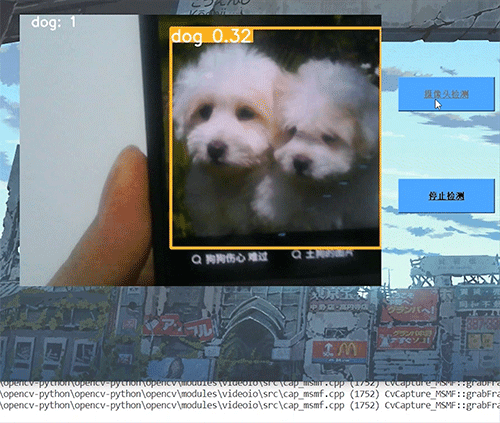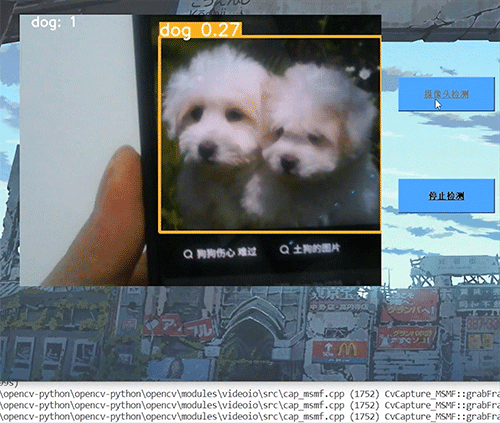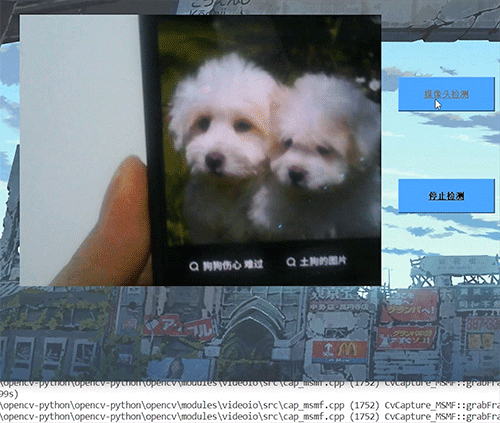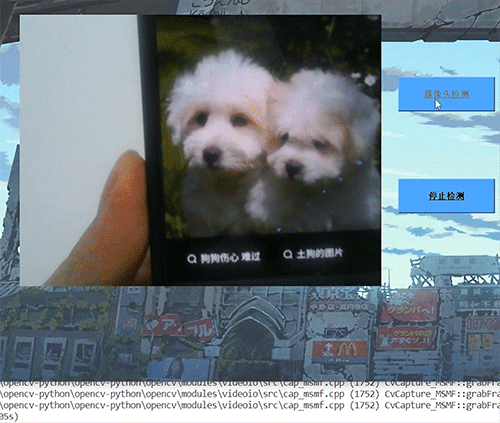
深度学习毕设项目 深度学习 python opencv 动物识别与检测
文章目录 0 前言1 深度学习实现动物识别与检测2 卷积神经网络2.1卷积层2.2 池化层2.3 激活函数2.4 全连接层2.5 使用tensorflow中keras模块实现卷积神经网络 3 YOLOV53.1 网络架构图3.2 输入端3.3 基准网络3.4 Neck网络3.5 Head输出层 4 数据集准备4.1 数据标注简介4.2 数据保存…...

leetcode 611. 有效三角形的个数(优质解法)
代码: class Solution {public int triangleNumber(int[] nums) {Arrays.sort(nums);int lengthnums.length;int n0; //三元组的个数//c 代表三角形最长的那条边for (int clength-1;c>2;c--){int left0;int rightc-1;while (left<right){if(nums[left]nums[r…...

Ubuntu使用Nginx部署前端项目——记录
安装nginx 依次执行以下两条命令进行安装: sudo apt-get update sudo apt-get install nginx通过查看版本号查看是否安装成功: nginx -v补充卸载操作: sudo apt-get remove nginx nginx-common sudo apt-get purge nginx nginx-common su…...

小航助学题库蓝桥杯题库c++选拔赛(22年1月)(含题库教师学生账号)
需要在线模拟训练的题库账号请点击 小航助学编程在线模拟试卷系统(含题库答题软件账号) 需要在线模拟训练的题库账号请点击 小航助学编程在线模拟试卷系统(含题库答题软件账号)...

centos用户相关命令
添加用户命令: adduser tony.wang useradd tony.wang 这两个命令都行,如果已经添加了会提示已经存在。 设置密码: passwd tony.wang 如果需要加入sudo组: usermod -aG sudo tony.wang 这个命令我在CentOS7上是不行的&#x…...

智能优化算法应用:基于哈里斯鹰算法无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于哈里斯鹰算法无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于哈里斯鹰算法无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.哈里斯鹰算法4.实验参数设定5.算法结果6.参考…...
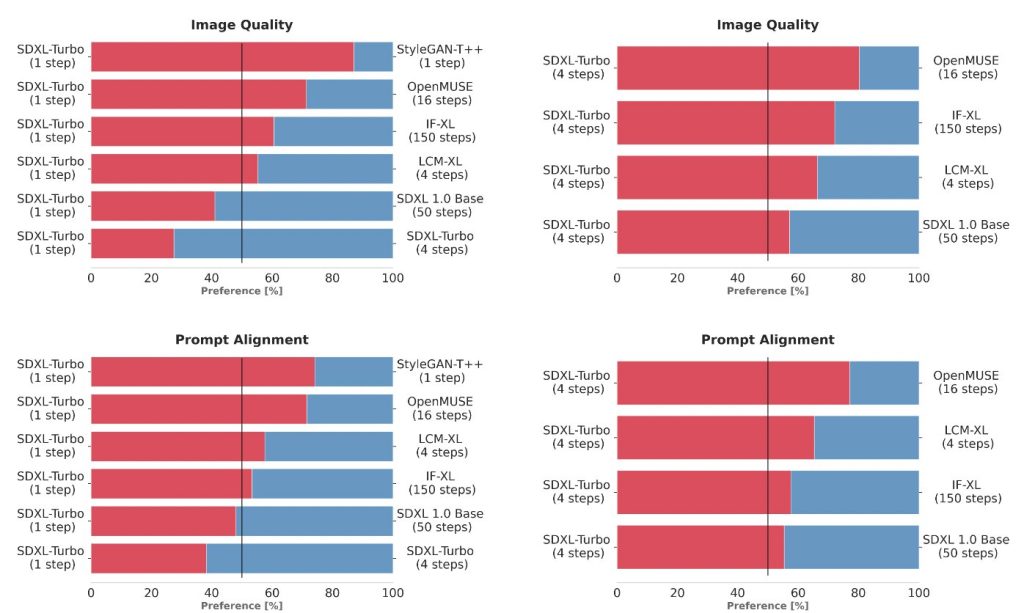
Stability AI 新发布SDXL Turbo:一款实时文本到图像生成模型
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
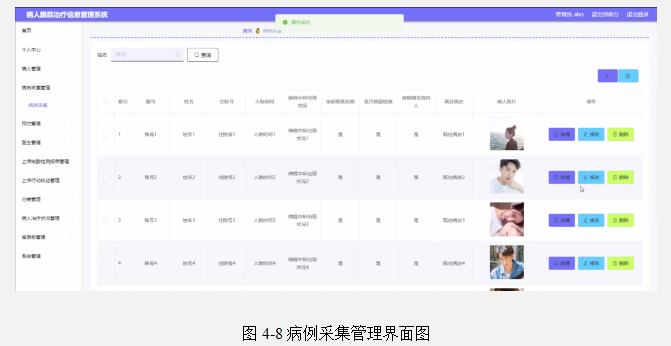
基于Java SSM框架+Vue实现病人跟踪治疗信息系统项目【项目源码+论文说明】
基于java的SSM框架Vue实现病人跟踪治疗信息系统演示 摘要 病人跟踪治疗信息管理系统采用B/S模式,促进了病人跟踪治疗信息管理系统的安全、快捷、高效的发展。传统的管理模式还处于手工处理阶段,管理效率极低,随着病人的不断增多,…...

js一行压缩库
js一行压缩库 压缩 JavaScript 代码通常是为了减小文件大小,提高加载速度。有一些常见的工具和软件可用于这个目的。以下是其中一些: UglifyJS: UglifyJS 是一个流行的 JavaScript 压缩工具,可以通过命令行或作为一个 npm 包来使…...

管理库存和出货的软件
随着时代的信息化越来越成熟,库存和出货的管理使用专门的软件变得越来越普遍。一款优秀的库存和出货管理软件应具备高效性、实时性、安全性和灵活性,以满足企业的日常运营需求。本文将详细介绍一款管理库存和出货的软件及其功能。 一、软件介绍 &#x…...

保护关键信息基础设施网络安全,SSL证书来助力
近年来,随着信息科技的飞速发展和互联网的普及应用,保护关键信息基础设施网络安全变得越来越迫切和重要。而随着《关键信息基础设施安全保护条例》的发布,保护关键信息基础设施也成为运营者必须履行的义务。SSL证书作为保护传输数据安全的重要…...

网安学习第24天 PHP安全——PHP反序列化
一、序列化与反序列化 1、序列化serialize() 序列化是什么?序列化就是把程序中的对象、数组、结构体等复杂数据,转换成可以存储或传输的格式。 简单说: 把“内存里的对象”变成“字符串/字节流”。 例如 PHP 中有一个对象: $u…...
)
Sora 2 GIF导出速度提升300%?20年多媒体架构师亲授GPU加速转码链路(CUDA 12.4 + cuVID硬编实测)
更多请点击: https://kaifayun.com 第一章:Sora 2 GIF导出方法概览 Sora 2 并非 OpenAI 官方发布的模型,当前(截至2024年)并无名为“Sora 2”的公开产品。因此,所谓“Sora 2 GIF导出”实为社区对视频生成工…...

【C++】零基础入门 · 第 6 节:数组
上一节我们学习了函数,知道了如何把代码封装起来方便复用。但在实际编程中,你很快就会遇到一个问题:如果要存储 100 个学生的成绩,难道要定义 100 个变量吗?这显然不现实。数组就是 C++ 给出的答案——它让我们能用一个变量名管理一组相同类型的数据。 1. 为什么需要数组…...

如何用免费工具解锁QQ音乐、网易云音乐等加密格式:3分钟解决音乐播放限制
如何用免费工具解锁QQ音乐、网易云音乐等加密格式:3分钟解决音乐播放限制 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web…...

如何快速配置虚拟显示器:面向初学者的完整指南
如何快速配置虚拟显示器:面向初学者的完整指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 你是否在为游戏串流画质不佳而烦恼?或者需要为无显示器主机…...

别再只会用spline了!MATLAB csape函数详解:从自然边界到夹持边界的实战选择
MATLAB csape函数深度解析:从自然边界到夹持边界的工程实践 在工程仿真和科学计算领域,数据插值是一个永恒的话题。当我们面对一组离散的实验数据或仿真结果时,如何构建一条光滑的曲线来准确反映数据背后的物理规律?这个问题困扰…...

智慧树自动刷课插件终极指南:3步实现高效学习自动化
智慧树自动刷课插件终极指南:3步实现高效学习自动化 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的重复点击操作而烦恼吗?智…...

SSH 远程连接效率提升:5个你可能不知道的实用技巧
SSH 是后端开发中最常用的远程连接工具之一。但大多数人只用 ssh userhost 连上去就完了,其实 SSH 还有很多隐藏技巧可以大幅提升效率。1. 使用配置文件简化连接每次敲一长串 ssh user192.168.1.100 -p 2222 太麻烦了。只需在 ~/.ssh/config 里加上:Host…...

荣耀出征离线挂机深度攻略:吃透隐性机制,告别无效挂机碾压同级
作为混迹游戏圈二十余年、从街机厅搓摇杆到网吧通宵刷端游,日均稳坐游戏6小时以上的老玩家,实测过无数网游的挂机体系。《荣耀出征》的离线挂机看似门槛极低、操作简单,但全网九成攻略都只停留在“开自动、挂地图”的基础层面,完全…...

淘金币自动化脚本终极指南:5分钟解放双手,轻松获取每日奖励
淘金币自动化脚本终极指南:5分钟解放双手,轻松获取每日奖励 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/ta…...