xorm源码学习
文章目录
- XORM源码浅析及实践
- ORM
- ORM vs. SQL
- XORM
- 软件架构
- ORM 引擎 Engine——DBM
- *core.DB
- Golang:database/sql 源码
- 基本结构
- 连接复用,提高性能。增加数据库连接池
- 数量连接管理
- database/sql
- 主要内容:
- sql.DB
- 创建数据库连接
- sql.Open()
- DB.conn
- 可能需要创建新的连接
- 连接释放
- 清理无效连接
- 数据库操作
- 数据库操作
- Prepare() 和Query()区别
- 接口的实现细节
- Query
- 基本使用
- 源码解析
- Exec
- Prepare
- 基本使用
- Rows
- DB.Stmt,Statements
- 基本使用
- 源码
XORM源码浅析及实践
ORM
应用程序是如何实现的数据的增删改查的?
ORM 是 Object Relational Mapping 的缩写,译为“对象关系映射”框架。
ORM 框架是一种数据持久化技术,是一种为了解决面向对象与关系型数据库中数据类型不匹配的技术,它通过描述对象与数据库表之间的映射关系,自动将应用程序中的对象持久化到关系型数据库的表中。在程序中的对象和关系型数据库之间建立映射关系,这样就可以用面向对象的方式,操作数据。
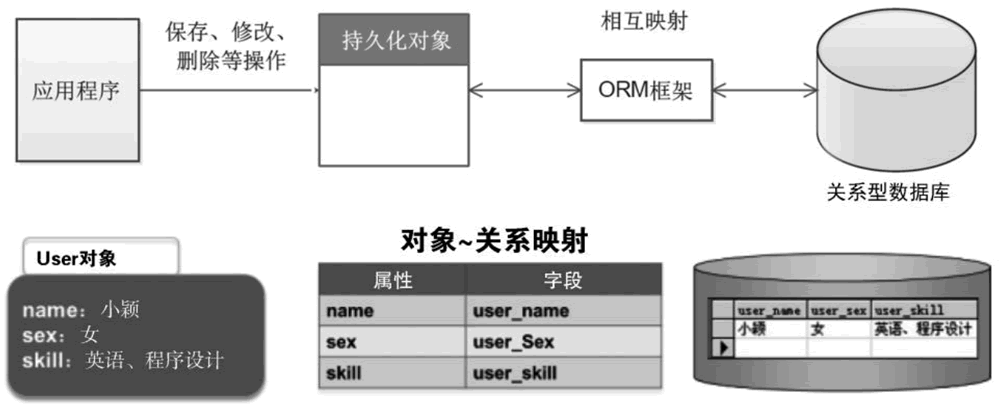

持久化层是作为业务逻辑层和数据库层的桥梁,为业务层提供数据增删改查的接口,接收业务层的指令,与数据库建立连接获取对应的数据
- ORM就是处于持久化层的一个东西
- ORM支撑了数据的增删改查。
- ORM接收业务层指令后最终还是转换成SQL语句,发送给数据库api驱动器

ORM vs. SQL
- ORM为业务层提供了更友好的接口,但其最后还是将业务层的指令转换sql语句。从这大家应该可以猜到,为了实现数据的增删改查,除了使用ORM,我们也可以直接使用sql。
为什么不直接使用sql?使用ORM有什么优势吗?
- ORM将数据表映射为数据模型,屏蔽了底层数据库的细节和差异,并提供易用的接口生成对应的sql语句。
- 直接使用sql势必要了解sql语法,不同的数据库其sql语法也存在差异,相对ORM学习成本更高
- 因为ORM采用面向对象的方式操作数据,可拓展新更强
- 让开发者只需关注具体业务逻辑,具体实现只需调用对应的ORM接口
- 这种模式可以屏蔽底层的数据库的细节,不需要我们与复杂的 SQL 语句打交道,直接采用操作对象的形式操作就可以。且框架会提供一些常用的功能,如字段名别名,查询条件的拼接。
- ORM主要解决的问题是对象关系的映射。这样,我们在具体的操作数据库的时候,就不用再和复杂的SQL语句打交道,只要像平时操作对象一样操作他就行了
- 不用sql直接编码,能够操作对象一样从数据库获取数据.
XORM
Go语言ORM库. 通过它可以使数据库操作非常简便。 通过xorm框架,开发者可以方便的使用各种封装好的方法来代替原生的sql语句。这样就降低了我们开发者使用数据库的门槛。
软件架构
-
builder包下的builder模块拼接SQL语句,它主要是将符合SQL规范的语句,封装成一个个的API,其本身并不能直接操作数据库。 -
dialect包下的IDialect接口,主要处理各类SQL数据库的特性,即: 方言(不属于SQL规范的各类数据库的特性),其本身并不能直接操作数据库。 -
schema包下的schema主要处理的是Model与数据库Table之间的关系,利用反射将模型映射成数据库表结构。 -
core包主要是将sql.DB扩展成core.DB,sql.stmt扩展成core.stmt…就是扩展了database/sql包下的内容。其本身具备了操作数据库的能力。 -
integration包下的statement模块,就是将builder,dialect,core,schema装配起来,生成一个个完整的SQL语句,具备了操作本框架支持的SQL数据库的能力。 -
Session只是对Statement模块的包装和扩展。Session在Statement的基础上增加了一些自定义的逻辑和功能。 -
Engine则又在Session的基础上进一步的封装。扩展了Session的功能。 -
每一个
Engine对象只能持有一个处于连接状态的*core.DB对象。(它只能保持一个数据库连接) -
每一个
Engine对象能打开任意多个*Session对象。(它能维护任意多个会话)
ORM 引擎 Engine——DBM
Engine 是orm的主要结构,表示数据库管理器.通常,一个应用程序只需要一个引擎
// Engine is the major struct of xorm, it means a database manager.
// Commonly, an application only need one engine
type Engine struct {cacherMgr *caches.Manager // 缓存模块defaultContext context.Context // 默认上下文。dialect dialects.Dialect // 主要是为了传给 Session.statementdriver dialects.DriverengineGroup *EngineGrouplogger log.ContextLogger // 上下文日志模块。tagParser *tags.Parser // 主要是为了传给 Session.statementdb *core.DBdriverName string //驱动名称,例如:"mysql","mssql",...dataSourceName string //对应驱动的 dataSourceName 连接信息TZLocation *time.Location // The timezone of the applicationDatabaseTZ *time.Location // The timezone of the databaselogSessionID bool // 默认为false,表示:没有创建 Session对象。初始化一个 Engine 对象时不会自动创建 Session 对象
}
*core.DB
DB 是 *sql.DB 的扩展。
type DB struct {*sql.DBMapper mapper.IMapper //表示结构体的字段名称和表的列名称之间的名称转换cache map[reflect.Type]*cacheStructmu sync.RWMutexLogger log.IContextLoggerhooks ictx.Hooks
}
mapper
IMapper 是实现的多态,任意一个struct实现了接口中的所有方法,那么则认为该struct实现了该接口。
- SnakeMapper 支持struct为驼峰式命名,表结构为下划线命名之间的转换,这个是默认的Maper;
- SameMapper 支持结构体名称和对应的表名称以及结构体field名称与对应的表字段名称相同的命名;
- GonicMapper 和SnakeMapper很类似,但是对于特定词支持更好,比如ID会翻译成id而不是i_d。
// Mapper 表示结构体的字段名称和表的列名称之间的名称转换
type IMapper interface {Obj2Table(string) stringTable2Obj(string) string
}// 1-1,名称map缓存
type CacheMapper struct {oriMapper IMapperobj2tableCache map[string]stringobj2tableMutex sync.RWMutextable2objCache map[string]stringtable2objMutex sync.RWMutex}// SameMapper 实现IMapper并在结构表和数据库表之间提供相同的名称
type SameMapper struct {}
func (m SameMapper) Obj2Table(o string) string {return o
}
func (m SameMapper) Table2Obj(t string) string {return t
}// SnakeMapper 实现IMapper并在结构表和数据库表之间驼峰式名称转化,userId--user_id
type SnakeMapper struct {}// GonicMapper 实现IMapper。映射名称时将考虑初始性。
// id -> ID, user -> User and to table names: UserID -> user_id, MyUID -> my_uid
type GonicMapper map[string]boolGolang:database/sql 源码
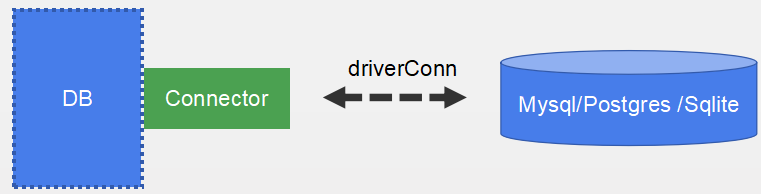
database/sql主要是提供了对数据库的读写操作的接口和数据库连接池功能,需要向其注册相应的数据库驱动才能工作。go-sql-driver/mysql是mysql数据库驱动,mysql客户端的真正实现,负责与mysql服务端进行交互,完成连接、读写操作。github.com/lib/pq常用的第三方 PostgreSQL 驱动程序
Go内置了数据库相关的库 - database/sql,实现数据库操作相关的接口,其中还包含一个很重要的功能 - 连接池,用来实现连接的复用,限制连接的数量,从而提高性能,避免连接数量失控,导致资源消耗不可控。
如何一步步设计包含连接池的数据库组件,包括模型抽象、连接复用,以及如何管理连接数。
基本结构
-
需要一个数据库对象,将数据库对象抽象为一个DB的结构体,一个对象对应的是一个数据库实例,所以DB必须是**单例
-
数据库需要连接,所以可以对连接进行抽象,命名为Conn,这里我们不关心Conn的属性,而是关心行为,所以Conn类型定义成一个interface包含所需两个方法
- 预处理方法Prepare(接收一个sql,返回一个实现Stmt接口的预处对象,接着设置一下参数,最后执行数据库操作)
- 关闭连接方法Close
-
不同的数据库连接的实现方式会有不同,对连接的方式进行抽象,定义一个连接接口 - Connector,用来创建连接(依赖倒置原则,依赖于抽象而不依赖于具体。写代码时用到具体类时,不与具体类交互,而与具体类的上层接口交互),当初始化DB的时候再将具体实现注入到DB对象中(也就是依赖注入)。
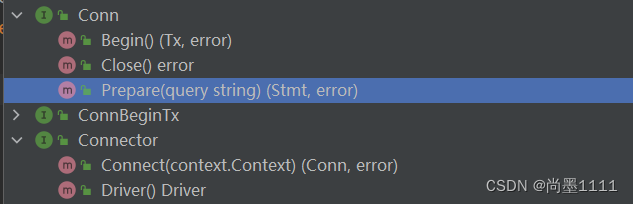
// 数据库对象
type DB struct {connector Connector
}type Conn interface {Prepare(query string) (Stmt, error)Close() error
}// 数据库连接接口
type Connector interface {Connect(context.Context) (Conn, error)
}
给DB对象增加一个获取连接的方法Conn,在不考虑连接池的情况下,调用connector.Connect(ctx)直接获取连接:
// 获取一个连接
func (db *DB) Conn(ctx context.Context) (*Conn, error) {return db.connector.Connect(ctx)
}
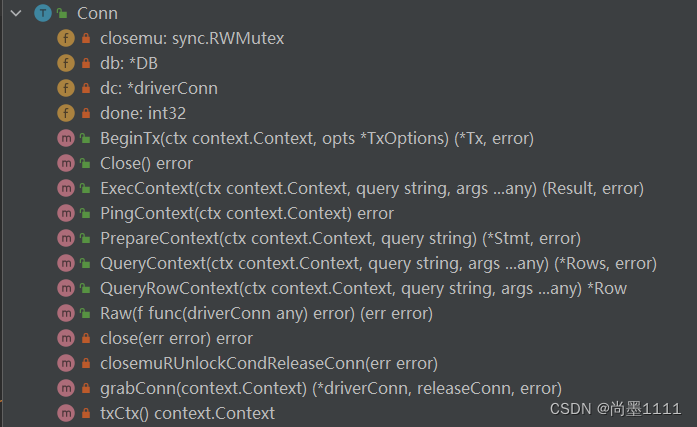
连接复用,提高性能。增加数据库连接池
- 存储空闲连接,切片来存储:freeConn []*Conn
- 并发安全的问题,需要增加一个锁mu sync.Mutex来保护
- 连接要复用,就不能关闭,用完需要放回连接池中,所以DB需要一个将连接放回连接池的方法 - putConn:
- 没有连接池功能的时候,一个Conn用完了就一定会调用Close()释放资源,有连接池功能后,对Conn进行改造,增加一层代理
// 数据库对象
type DB struct {connector Connectormu sync.Mutex // protects following fieldsfreeConn []*Conn
}
数据库连接获取方法Conn就需要修改为:
- 如果没有,创建新连接
- 如果有,返回一个经连接池包装之后的连接
func (db *DB) Conn(ctx context.Context) (*Conn, error) {db.mu.Lock() // 加锁保护freeConnnumFree := len(db.freeConn)if numFree > 0 {conn := db.freeConn[0]// 移除第一个连接copy(db.freeConn, db.freeConn[1:])db.freeConn = db.freeConn[:numFree-1]db.mu.Unlock()return conn, nil}db.mu.Unlock()return db.connector.Connect(ctx) // 没有空闲连接,重新创建
}func (db *DB) putConn(dc Conn) {db.mu.Lock()db.freeConn = append(db.freeConn, dc)db.mu.Unlock()
}
type PConn interface {db *DBci Conn //原来的Conn作为PConn的一个属性,同时实现了Conn接口的两个方法
}
func (pc *PConn) Close() error {dc.db.putConn(pc)
}
func (pc *PConn) Prepare(query string) (Stmt, error) {return pc.ci.Prepare(query)
}// 调整一下Conn的创建方法
func (db *DB) Conn(ctx context.Context) (Conn, error) {...c , err := db.connector.Connect(ctx) // 没有空闲连接,重新创建if err!=nil {return nil, err}return &PConn{ //返回包装过后的连接ci: c,db: db,}
}数量连接管理
限创建连接可能会导致资源耗尽,资源消耗曲线过陡峭
- 限制连接数量。将连接的数量约束在指定的范围内
- 保存当前连接数量
- 最大连接数
- 连接请求队列。当连接数量达到最大值时,连接请求需要需要放到等待队列中,等待有连接释放。
- 没有空闲连接、连接数已达最大连接数怎么操作?
chan 可以理解为一个管道或者先进先出的队列。带缓存的 channel 实际上是一个阻塞队列。队列满时写协程会阻塞,队列空时读协程阻塞。
Database/sql里是采用一个map来存储(注:这个有点奇怪,为什么不用队列?),在DB结构体增加一个属性:connRequests,类型为:map[uint64]chan connRequest,其中key/value:
- key :请求唯一标识。调用nextRequestKeyLocked方法生成,实际上就是一个自增的序列,只是为了保持唯一
- value:等待连接的请求。类型为chan,每个请求封装为一个chan,可以保证并发安全,同时也可以利用其阻塞特性(当chan没有值时阻塞等待),chan接收的数据类型为connRequest格式,当其他协程有释放连接时,会将连接放到一个connRequest对象中发送给该chan,connRequest只包含两个属性:conn和err,用来接收返回连接或是异常。
type DB struct {...numOpen int // number of opened and pending open connectionsmaxOpen int // <= 0 means unlimitednextRequest uint64 // Next key to use in connRequests.connRequests map[uint64]chan connRequest
}func (db *DB) nextRequestKeyLocked() uint64 {next := db.nextRequestdb.nextRequest++return next
}// 连接请求
type connRequest struct {conn *PConnerr error
}
调整获取连接的方法Conn(ctx context.Context) 逻辑:
- 判断freeConn是否有空闲连接,有就返回
- 判断连接数量numOpen是否大于maxOpen,如果还小于maxOpen,说明还可以创建新连接,创建连接后numOpen++,返回连接
- 当numOpen已经是大于等于maxOpen,就不能再创建新连接,这是就把请求放到集合connRequests中,等待连接释放。
func (db *DB) Conn(ctx context.Context) (Conn, error) {db.mu.Lock() // 加锁保护freeConnnumFree := len(db.freeConn)if numFree > 0 { // 有空闲连接conn := db.freeConn[0]copy(db.freeConn, db.freeConn[1:])db.freeConn = db.freeConn[:numFree-1]db.mu.Unlock()return conn, nil}// 连接数已经超出if db.maxOpen > 0 && db.numOpen >= db.maxOpen {req := make(chan connRequest, 1) // 创建一个chan,接收连接reqKey := db.nextRequestKeyLocked() // 生成唯一序号db.connRequests[reqKey] = req // 放到全局属性,让其他方法能访问到db.mu.Unlock()select {case <-ctx.Done(): //超时等// Remove the connection request and ensure no value has been sent// on it after removing.db.mu.Lock()delete(db.connRequests, reqKey) // 移除db.mu.Unlock()}case ret, ok := <-req: // 收到连接释放if !ok {return nil, errDBClosed}return ret.conn, ret.err}}// 连接数没超出,可以创建新连接db.numOpen++ // optimisticallydb.mu.Unlock()c, err := db.connector.Connect(ctx) // 重新创建if err != nil {return nil, err}return &PConn{ci: c,db: db,}, nil
}
接着,我们还需要调整连接释放方法 - putConn:
- 增加一个bool返回值,告诉调用方连接是否释放成功(如果失败,客户端可以决定关闭连接)
- 如果连接数numOpen大于 maxOpen时,当前连接直接丢弃,返回false
- 当len(db.connRequests)大于0时,需要考虑将连接优先给db.connRequests中的请求
- 最后才将连接放入空闲列表中。
func (pc *PConn) Close() error {ok := dc.db.putConn(pc) //释放连接失败,需要把连接关闭if !ok {dc.ci.Close()}
}func (db *DB) putConn(dc Conn) bool{db.mu.Lock()defer db.mu.Unlock()if db.maxOpen > 0 && db.numOpen > db.maxOpen {return false}// 当有等待连接的请求时if c := len(db.connRequests); c > 0 {var req chan connRequestvar reqKey uint64for reqKey, req = range db.connRequests {break}delete(db.connRequests, reqKey) // Remove from pending requests.req <- connRequest{conn: dc,err: err,}return true}// 放入空闲连接池中db.freeConn = append(db.freeConn, dc)return true
}

database/sql
https://xie.infoq.cn/article/c705a7821cb0d63f8bd381276
https://studygolang.com/articles/35389
sql 包其实是 db 的抽象,实际连接查询是 db 驱动包来完成
主要内容:
- database 包目录结构介绍
- 数据库连接池的定义
- 为什么要连接池
- 主要核心的数据结构及解释
- 重要方法的流程梳理及源码分析
- 初始化数据库
- 获取连接
- 释放连接
- 清理连接
- 复用连接
目录结构:
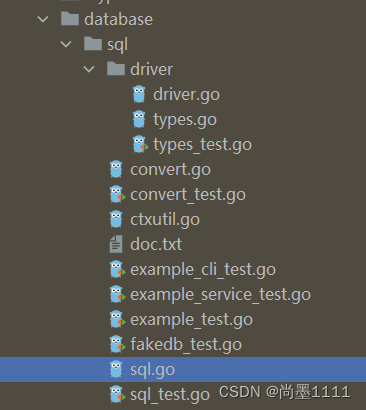
└─database└─sql│ convert.go // 数据类型转换工具│ ctxutil.go // SQL查询接口的一层wrapper,主要处理context close的问题│ sql.go // 数据库驱动和SQL的通用接口和类型,包括连接池、连接、事务、statement等│└─driverdriver.go // driver定义了实现数据库驱动所需的接口,这些接口由sql包和具体的驱动包来实现types.go // 数据类型的别名和转换
sql.DB
DB是数据库句柄,它包含着一个连接池,里面可以有0个或者多个连接。对于多协程的并发调用,它也是安全的。sql包会自动的创建和释放连接池中的连接,也能保持一个空闲连接的连接池。在事务中,一旦DB.Begin被调用,其返回的Tx对象就是绑定到一个单独的连接上,直到事务提交或者回滚,这个连接才会重新被返回空闲连接池。
- sql.DB
- sql.Open
- sql.close
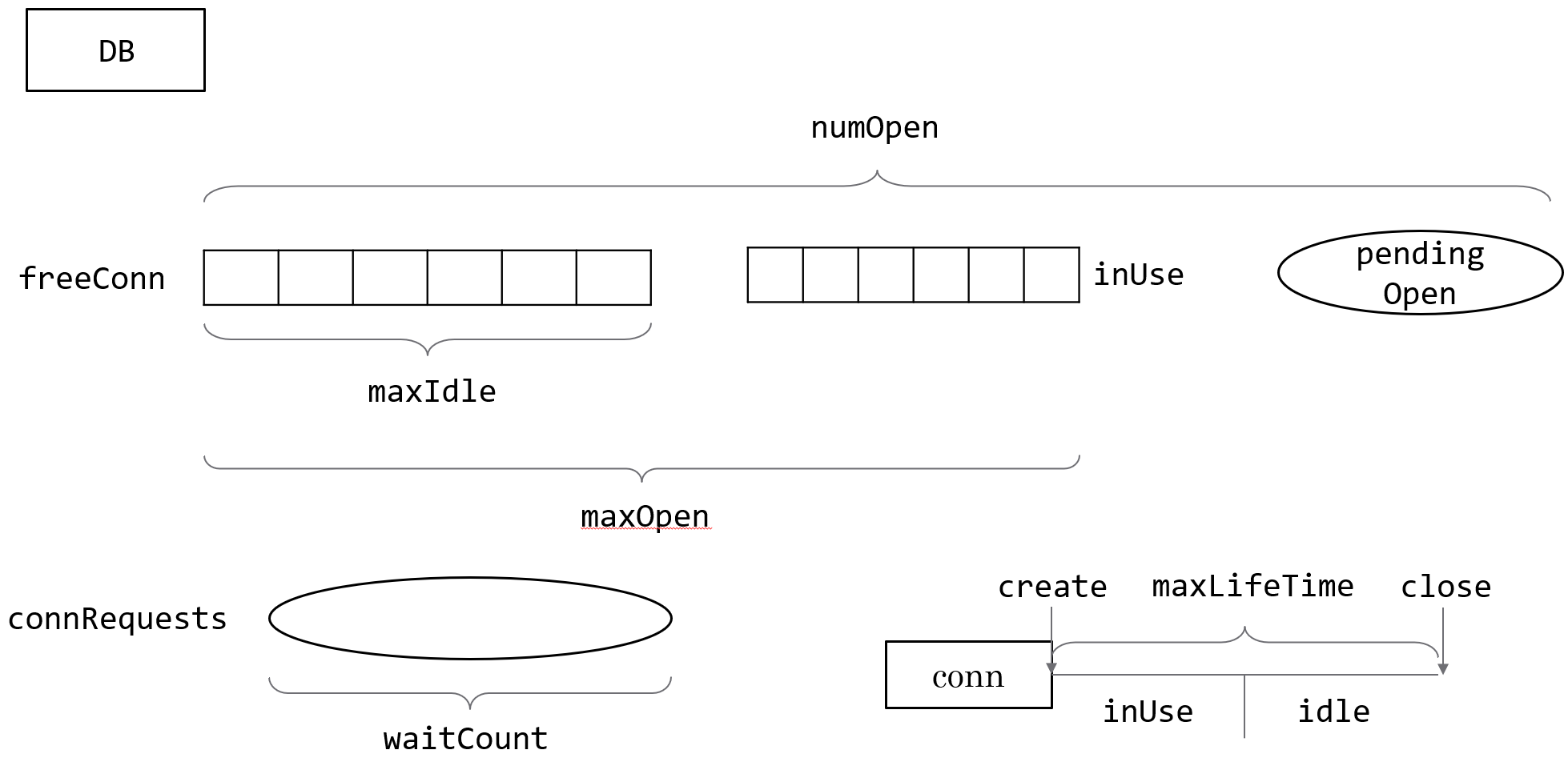
DB结构
type DB struct {waitDuration int64 // 等待新的连接所需要的总时间,原子操作,waitDuration放在第一个是为了避免32位系统使用64位原子操作的坑,https://toutiao.io/posts/jagmqm/previewconnector driver.Connector // 由数据库驱动实现的connectornumClosed uint64 // 关闭的连接数mu sync.Mutex // protects following fieldsfreeConn []*driverConn // 连接池connRequests map[uint64]chan connRequest // 阻塞等待连接的随机队列nextRequest uint64 // 下一个连接的keynumOpen int // 正在用的+在连接池里的+将要打开的// 用来接收创建新连接的信号
// connectionOpener方法会读取该channel的信号,而当需要创建连接的时候,maybeOpenNewConnections就会往该channel发信号。
// 当调用db.Close()的时候,该channel就会被关闭openerCh chan struct{} // channel用于通知建立新连接closed bool // 当前数据库是否关闭dep map[finalCloser]depSet lastPut map[*driverConn]string // debug onlymaxIdleCount int // 最大空闲连接数,也就是连接池的大小,0代表默认连接数2,负数代表0maxOpen int // 最大打开的连接数=已使用+空闲的,小于等于0表示不限制maxLifetime time.Duration // 一个连接在连接池中最长的生存时间maxIdleTime time.Duration // Go1.5添加,一个连接在被关掉前的最大空闲时间cleanerCh chan struct{} // channel用于通知清理连接waitCount int64 // 等待的连接数,如果maxIdelCount为0,waitCount就是一直为0maxIdleClosed int64 // Go1.5添加,释放连接时,因为连接池已满而被关闭的连接数maxLifetimeClosed int64 // 连接超过生存时间后而被关闭的连接数stop func() // stop cancels the connection opener and the session resetter.
}
创建数据库连接
sql.Open()
sql.Open只是创建了数据库对象(简称:db)以及开启了两个协程,并没有连接数据库的操作,
//来在导入go-sql-driver时,该库的init函数就自动注册一个数据库驱动到sql.drivers
var (driversMu sync.RWMutexdrivers = make(map[string]driver.Driver)
)type DB struct {....connector driver.Connector
}type Connector interface {Connect(context.Context) (Conn, error)Driver() Driver
}func Open(driverName, dataSourceName string) (*DB, error) {driversMu.RLock()// 根据driverName获取相应的数据库驱动对象 driveri, ok := drivers[driverName]driversMu.RUnlock()if !ok {return nil, fmt.Errorf("sql: unknown driver %q (forgotten import?)", driverName)}// 如果 Driver 实现了 DriverContext,则 sql.DB 将调用 OpenConnector 来获取 Connector,然后调用该 Connector 的 Connect 方法来获取每个所需的连接,而不是为每个连接调用 Driver 的 Open 方法。if driverCtx, ok := driveri.(driver.DriverContext); ok {connector, err := driverCtx.OpenConnector(dataSourceName)if err != nil {return nil, err}return OpenDB(connector), nil}// 调用 sql.OpenDB返回数据库对象return OpenDB(dsnConnector{dsn: dataSourceName, driver: driveri}), nil
}func OpenDB(c driver.Connector) *DB {ctx, cancel := context.WithCancel(context.Background())// 创建数据库对象db := &DB{connector: c,openerCh: make(chan struct{}, connectionRequestQueueSize),lastPut: make(map[*driverConn]string),connRequests: make(map[uint64]chan connRequest),stop: cancel,}//初始化 db 后,开一个协程来等待,通过 openerCh channel 当做信号来创建新的数据库连接。// 开启协程,负责收到请求后新建连接go db.connectionOpener(ctx)return db
}// Runs in a separate goroutine, opens new connections when requested.
func (db *DB) connectionOpener() {for {select {case <-ctx.Done(): //超时等returncase <-db.openerCh://收到打开一个新的连接信号db.openNewConnection(ctx)}}
}// Open one new connection
func (db *DB) openNewConnection() {ci, err := db.connector.Connect(ctx)// 创建连接的过程加了互斥锁db.mu.Lock()defer db.mu.Unlock()// 如果新连接创建失败,或者已经被关闭,则在返回之前必须减1if db.closed {if err == nil {ci.Close()}db.numOpen--return}if err != nil {db.numOpen--db.putConnDBLocked(nil, err)db.maybeOpenNewConnections()return}dc := &driverConn{db: db,createdAt: nowFunc(),ci: ci,}// 获取到连接之后,会根据 putConnDBLocked 这个方法去决定这个连接是否被复用。如果复用则返回,如果无法复用就会关掉这个连接,不会一直放着不管的。if db.putConnDBLocked(dc, err) {db.addDepLocked(dc, dc)} else {db.numOpen--ci.Close()}
}// 如果有连接请求,并且连接数还没达到上限,就通知connectionOpener创建新的连接
func (db *DB) maybeOpenNewConnections() {numRequests := len(db.connRequests)if db.maxOpen > 0 {numCanOpen := db.maxOpen - db.numOpenif numRequests > numCanOpen {numRequests = numCanOpen}}for numRequests > 0 {db.numOpen++ // optimisticallynumRequests--if db.closed {return}db.openerCh <- struct{}{}}
}putConnDBLocked 如何决定传进来的连接是否可以复用。
func (db *DB) putConnDBLocked(dc *driverConn, err error) bool {// 查看 DB 状态及是否有限制,如果关闭了或者达到限制了,那当然就无法复用了;if db.closed {return false}if db.maxOpen > 0 && db.numOpen > db.maxOpen {return false}// 看一下 connRequests 是否有阻塞等待的请求if c := len(db.connRequests); c > 0 {var req chan connRequestvar reqKey uint64for reqKey, req = range db.connRequests {break}delete(db.connRequests, reqKey) // Remove from pending requests.if err == nil {dc.inUse = true}req <- connRequest{conn: dc,err: err,}return true// 没有的话,就看下连接池是否可用,可以的话就放到连接池里面} else if err == nil && !db.closed {if db.maxIdleConnsLocked() > len(db.freeConn) {db.freeConn = append(db.freeConn, dc)// 会开启清扫连接池里面空闲连接的逻辑db.startCleanerLocked()return true}db.maxIdleClosed++}return false
}
DB.conn
DB.Conn是db内部获取数据库连接的函数,通过 2 个策略来获取连接,cachedOrNewConn,从连接池内或者新建获取连接,alwaysNewConn,总是通过新建来获取连接.
连接池获取连接就是这样的逻辑设计,复用池,阻塞等待,直接获取。
const (// alwaysNewConn forces a new connection to the database.alwaysNewConn connReuseStrategy = iota// 返回一个缓存连接(如果可用),否则等待一个可用(如果已达到 MaxOpenConns)或创建一个新的数据库连接cachedOrNewConn
)func (db *DB) Conn(ctx context.Context) (*Conn, error) {var dc *driverConnvar err error// 尝试通过缓存或者新建(连接池里面没有可用连接)来获取连接,如果获取不到最大重试次数为2次for i := 0; i < maxBadConnRetries; i++ {dc, err = db.conn(ctx, cachedOrNewConn)if err != driver.ErrBadConn {break}}// 如果在上一步通过缓存或者新建获取不到连接,则再通过新建获取一个连接if err == driver.ErrBadConn {dc, err = db.conn(ctx, alwaysNewConn)}if err != nil {return nil, err}conn := &Conn{db: db,dc: dc,}return conn, nil
}这个方法会分为三种情况返回连接,分别是
- 从连接池获取,复用连接
- 连接池无可用连接或不允许使用连接池,且创建的连接有数量限制的,请求就会阻塞等待创建好的连接
- 直接通过 connector 驱动去从数据库获取连接
从连接池里面直接获取
如果策略是 cachedOrNewConn 的,先检查 freeConn 连接池里面有没有可以复用的连接,如果有取出来判断,没有超时后返回可用的连接。在取的这个逻辑,L4~L6 是获取连接池第一个的连接的写法,这样的做法可以减少切片的容量-1,这样可以减少切片因为伸缩而产生的内存分配问题。
last := len(db.freeConn) - 1
// 如果strategy是cachedOrNewConn,优先从空闲队列中获取
if strategy == cachedOrNewConn && last >= 0 {conn := db.freeConn[last]db.freeConn = db.freeConn[:last]conn.inUse = trueif conn.expired(lifetime) {db.maxLifetimeClosed++db.mu.Unlock()conn.Close()return nil, driver.ErrBadConn}db.mu.Unlock()// Reset the session if required.if err := conn.resetSession(ctx); errors.Is(err, driver.ErrBadConn) {conn.Close()return nil, err}return conn, nil
}
- 如果strategy不是cachedOrNewConn,或者空闲队列为空,则先检查最大打开连接数和正在打开连接数,如果正在打开连接数已经到达了限制,创建一个获取连接请求并等待。
- 如果正在打开连接数还没有到达限制,直接创建一个新连接
// 如果打开的连接数已经到达了限制,创建一个获取连接请求并等待。
if db.maxOpen > 0 && db.numOpen >= db.maxOpen {req := make(chan connRequest, 1)reqKey := db.nextRequestKeyLocked()db.connRequests[reqKey] = reqdb.waitCount++db.mu.Unlock()waitStart := nowFunc()// Timeout the connection request with the context.select {case <-ctx.Done()://等待超时db.mu.Lock()delete(db.connRequests, reqKey)db.mu.Unlock()atomic.AddInt64(&db.waitDuration, int64(time.Since(waitStart)))select {default:case ret, ok := <-req://删除的过程中,再检查了一下会不会刚好超时,刚好 req 收到连接的情况if ok && ret.conn != nil {db.putConn(ret.conn, ret.err, false)//那不会直接 close,相反的会留着用,放到连接池里面使用}}return nil, ctx.Err()case ret, ok := <-req:// req 获取到连接了// 如果策略是cachedOrNewConns,则仅检查连接是否过期。if strategy == cachedOrNewConn && ret.err == nil && ret.conn.expired(lifetime) {db.mu.Lock()db.maxLifetimeClosed++db.mu.Unlock()ret.conn.Close()return nil, driver.ErrBadConn}if ret.conn == nil {return nil, ret.err}// Reset the session if required.if err := ret.conn.resetSession(ctx); errors.Is(err, driver.ErrBadConn) {ret.conn.Close()return nil, err}return ret.conn, ret.err
}//如果strategy不是cachedOrNewConn,或者空闲连接队列为空,需要创建一个新的连接。db.numOpen++ // optimisticallydb.mu.Unlock()ci, err := db.connector.Connect(ctx)if err != nil {db.mu.Lock()db.numOpen-- // correct for earlier optimism//不是失败就失败了,而是会在错误里面再去调一次获取连接的函数。这里的思维就是尽可能的减少 connRequests 里面阻塞的请求,连接池设计不仅仅是要思考如何复用,更多的也要考虑如何减少阻塞的请求db.maybeOpenNewConnections()db.mu.Unlock()return nil, err}db.mu.Lock()dc := &driverConn{db: db,createdAt: nowFunc(),returnedAt: nowFunc(),ci: ci,inUse: true,}db.addDepLocked(dc, dc)db.mu.Unlock()return dc, nil可能需要创建新的连接
maybeOpenNewConnections 。这个方法就是为了获取连接,更多的是给阻塞的请求创建连接的一个方法。里面主要的也就是往前面讲到的 openerCh 发信号,通知它要创建一个新的连接了,有某个请求可能需要了。
- 在这边创建失败后,再次调取 maybeOpenNewConnections,目的还是觉得有需要连接的阻塞的请求
func (db *DB) maybeOpenNewConnections() {numRequests := len(db.connRequests)if db.maxOpen > 0 {numCanOpen := db.maxOpen - db.numOpenif numRequests > numCanOpen {numRequests = numCanOpen}}for numRequests > 0 {db.numOpen++ // optimisticallynumRequests--if db.closed {return}// db.openerCh 收到信号后,其实调取底层的方法就是 openNewConnectiondb.openerCh <- struct{}{}}
}
连接释放
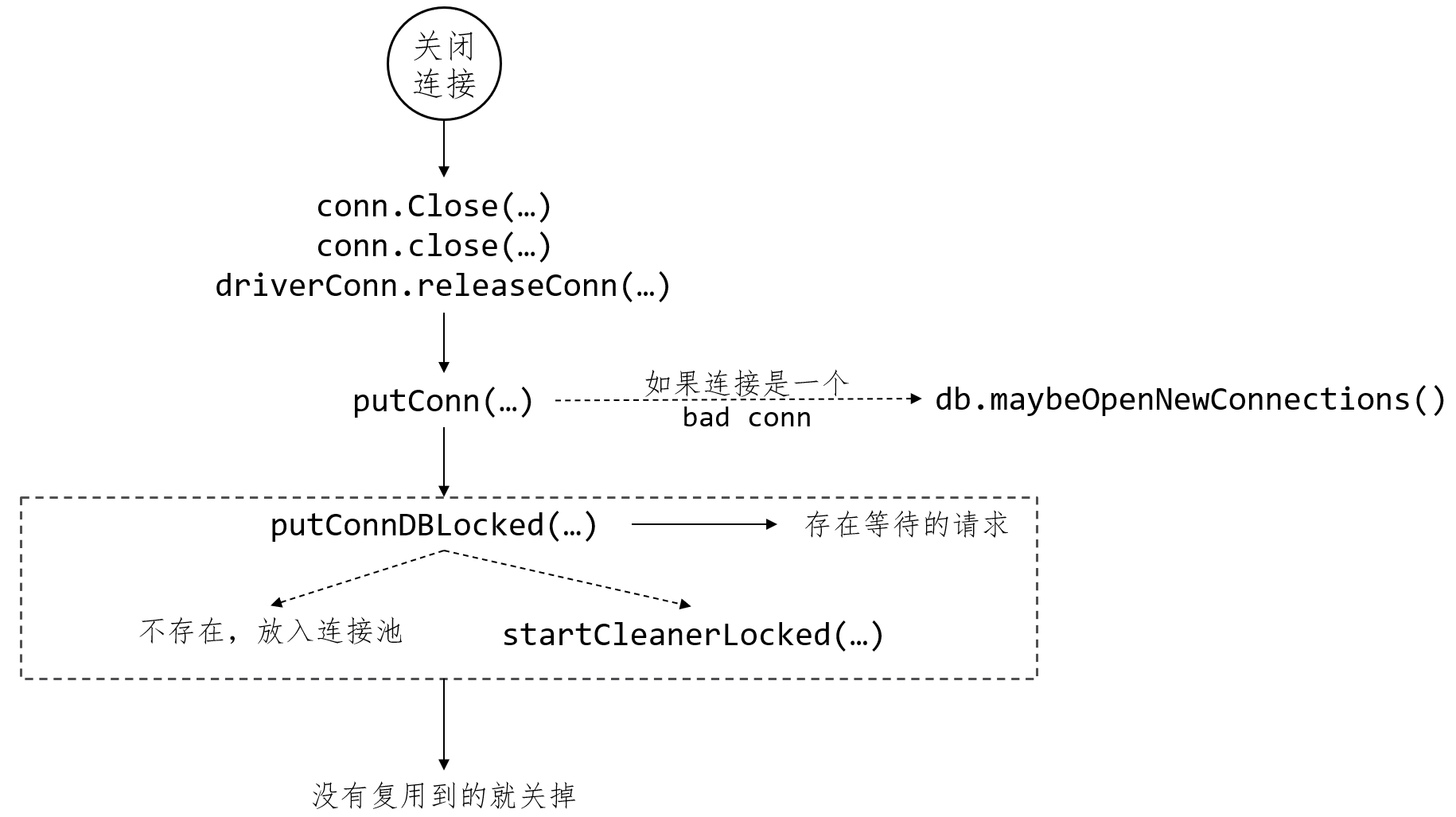
func (c *Conn) Close() error {return c.close(nil)
}closemu sync.RWMutex
func (c *Conn) close(err error) error {if !atomic.CompareAndSwapInt32(&c.done, 0, 1) {return ErrConnDone}// Lock around releasing the driver connection// to ensure all queries have been stopped before doing so.c.closemu.Lock()defer c.closemu.Unlock()c.dc.releaseConn(err)c.dc = nilc.db = nilreturn err
}func (dc *driverConn) releaseConn(err error) {dc.db.putConn(dc, err, true)
}// putConn adds a connection to the db's free pool.
func (db *DB) putConn(dc *driverConn, err error, resetSession bool) {// 判断是否为坏连接,driver.ErrBadConnif errors.Is(err, driver.ErrBadConn) {// Don't reuse bad connections.// Since the conn is considered bad and is being discarded, treat it// as closed. Don't decrement the open count here, finalClose will// take care of that.db.maybeOpenNewConnections()// tell the connectionOpener to open new connections.db.mu.Unlock()dc.Close()return}// 用于测试的后置钩子函数if putConnHook != nil {putConnHook(db, dc)}added := db.putConnDBLocked(dc, nil)db.mu.Unlock()if !added {dc.Close()return}
}func (db *DB) putConnDBLocked(dc *driverConn, err error) bool {if db.closed {return false}if db.maxOpen > 0 && db.numOpen > db.maxOpen {return false}if c := len(db.connRequests); c > 0 {var req chan connRequestvar reqKey uint64for reqKey, req = range db.connRequests {break}delete(db.connRequests, reqKey) // Remove from pending requests.if err == nil {dc.inUse = true}req <- connRequest{conn: dc,err: err,}return true} else if err == nil && !db.closed {if db.maxIdleConnsLocked() > len(db.freeConn) {db.freeConn = append(db.freeConn, dc)db.startCleanerLocked()return true}db.maxIdleClosed++}return false
}
清理无效连接
清理无效连接不是一初始化数据库就开一个协程等超时清理
- 放回连接池就会发起一次清理连接池空闲连接的动作
- 重新设置连接最大生存时间的时候也会触发一次。

// startCleanerLocked starts connectionCleaner if needed.
func (db *DB) startCleanerLocked() {if (db.maxLifetime > 0 || db.maxIdleTime > 0) && db.numOpen > 0 && db.cleanerCh == nil {db.cleanerCh = make(chan struct{}, 1)go db.connectionCleaner(db.shortestIdleTimeLocked())}
}func (db *DB) connectionCleaner(d time.Duration) {const minInterval = time.Secondif d < minInterval {d = minInterval}t := time.NewTimer(d)//1秒的定时器for {select {case <-t.C://定时清理case <-db.cleanerCh: // 调用清理,maxLifetime was changed or db was closed.}db.mu.Lock()d = db.shortestIdleTimeLocked()if db.closed || db.numOpen == 0 || d <= 0 {db.cleanerCh = nildb.mu.Unlock()return}
//找到超过max connection lifetime limit、idle time的连接driverConnd, closing := db.connectionCleanerRunLocked(d)db.mu.Unlock()for _, c := range closing {c.Close()}if d < minInterval {d = minInterval}if !t.Stop() {select {case <-t.C:default:}}t.Reset(d)}
}
创建新连接是调用db.connector.Connect进行创建的,先来回顾一下,db.connector是什么,是怎么来的:
在xorm.io/dialects/driver.go中有个注册函数,注册一个pq数据库驱动到sql.drivers
func regDrvsNDialects() bool {providedDrvsNDialects := map[string]struct {dbType schemas.DBTypegetDriver func() DrivergetDialect func() Dialect}{"mssql": {"mssql", func() Driver { return &odbcDriver{} }, func() Dialect { return &mssql{} }},"odbc": {"mssql", func() Driver { return &odbcDriver{} }, func() Dialect { return &mssql{} }}, "mysql": {"mysql", func() Driver { return &mysqlDriver{} }, func() Dialect { return &mysql{} }},"mymysql": {"mysql", func() Driver { return &mymysqlDriver{} }, func() Dialect { return &mysql{}}},"postgres": {"postgres", func() Driver { return &pqDriver{} }, func() Dialect { return &postgres{}}},....}for driverName, v := range providedDrvsNDialects {if driver := QueryDriver(driverName); driver == nil {RegisterDriver(driverName, v.getDriver())RegisterDialect(v.dbType, v.getDialect)}}return true
}
pq
conn.go
func init() {sql.Register("postgres", &Driver{})
}
数据库操作
https://juejin.cn/post/7270900777643622437
关于数据库操作 database/sql 包 功能:提供了 SQL 类数据库的通用接口 前提:
- 必须和数据库驱动配合使用
- 不支持 context 取消的驱动直到查询完成后才会返回结果
- 支持上下文参数 context 指在执行数据库查询或其他操作时,可以使用上下文对象来设置超时时间、传递控制信号以及在需要时进行取消操作。
数据库操作
- 类型定义 Rows,查询结果集
rows.Close()函数释放与*sql.Rows关联的数据库资源rows.Next()函数,遍历rows.Scan()函数将每行记录的值复制到这个例子中定义结构体变量
- 类型 stmt,预编译语句
- Query 执行数据库的Query操作,例如一个Select语句,返回一个
*sql.Rows对象。 - 非查询:
db.Exec()函数用于执行非查询 SQL 语句,例如 INSERT、UPDATE 和 DELETE,返回一个sql.Result对象 - db.Prepare(),准备一个数据库query操作,返回一个 sql 执行模板,*Stmt,用于后续query或执行。这个Stmt可以被多次执行,或者并发执行,预编译,提高效率、防止Sql注入,
- 其中的?为需要输入的参数,之后通过stmt.Exec()添加参数。
- Exec返回的Result可以获取 LastInsertId(),但是并不是所有数据库都支持;
- RowsAffected()能够获取修改数据的条数。
Prepare() 和Query()区别
rows, err := store.DB.Query(SQL, args ...)
defer rows.Close()stmt, err := store.DB.Prepare(SQL)
defer stmt.Close()
// 将参数传递给方法,而不是使用原始SQL字符串(出于安全考虑).
rows, err := stmt.Query(args ...)
defer rows.Close()
接口的实现细节
func (db *DB) Prepare(query string) (*Stmt, error)
func (db *DB) Exec(query string, args ...interface{}) (Result, error)
func (db *DB) Query(query string, args ...interface{}) (*Rows, error)
func (db *DB) QueryRow(query string, args ...interface{}) *Row
这几个接口真正的实现者是:
func (db *DB) PrepareContext(ctx context.Context, query string) (*Stmt, error)
func (db *DB) ExecContext(ctx context.Context, query string, args ...interface{}) (Result, error)
func (db *DB) QueryContext(ctx context.Context, query string, args ...interface{}) (*Rows, error)
核心功能实现者:
func (db *DB) prepare(ctx context.Context, query string, strategy connReuseStrategy) (*Stmt, error)
func (db *DB) exec(ctx context.Context, query string, args []interface{}, strategy connReuseStrategy) (Result, error)
func (db *DB) query(ctx context.Context, query string, args []interface{}, strategy connReuseStrategy) (*Rows, error)
然后最终落实到:
func (db *DB) prepareDC(ctx context.Context, dc *driverConn, release func(error), cg stmtConnGrabber, query string) (*Stmt, error)
func (db *DB) execDC(ctx context.Context, dc *driverConn, release func(error), query string, args []interface{}) (res Result, err error
func (db *DB) queryDC(ctx, txctx context.Context, dc *driverConn, releaseConn func(error), query string, args []interface{}) (*Rows, error)
*DC函数主要是通过调用driverConn实现的函数来执行数据库操作指令,当然driverConn也是继续调用Driver.Conn的实现的函数,这就和具体的驱动实现有关了,这里我们只关心到driverConn。事实上,这里会对应调用Driver.Conn的下列函数:
type ConnPrepareContext interface {// PrepareContext returns a prepared statement, bound to this connection.// context is for the preparation of the statement,// it must not store the context within the statement itself.PrepareContext(ctx context.Context, query string) (Stmt, error)
}type ExecerContext interface {ExecContext(ctx context.Context, query string, args []NamedValue) (Result, error)
}type QueryerContext interface {QueryContext(ctx context.Context, query string, args []NamedValue) (Rows, error)
}
Query
基本使用
func selectData(db *sql.DB) {// 返回查询到的所有行rows, err := db.Query("SELECT * FROM userinfo")checkerr(err)// 一行一行地循环显示// rows.Next() 查看是否还有下一行, 有则返回为真否则假。为后面的rows.Scan()做准备for rows.Next() {var uid intvar username stringvar department stringvar createds string// 由刚才的rows.Next()获得当前行后, 将当前行的各列填入对应参数中// 每次调用Scan方法都必须在前面调用Next方法err = rows.Scan(&uid, &username, &department, &createds)checkerr(err)fmt.Printf("%d,%s,%s,%s\n", uid, username, department, createds)}
}源码解析
func (db *DB) Query(query string, args ...any) (*Rows, error) {// 调用DB.QueryContext,自动传入一个空的context,因此DB.Query无法通过context设置超时或提前取消。return db.QueryContext(context.Background(), query, args...)
}func (db *DB) QueryContext(ctx context.Context, query string, args ...any) (*Rows, error) {var rows *Rowsvar err errorvar isBadConn boolfor i := 0; i < maxBadConnRetries; i++ {rows, err = db.query(ctx, query, args, cachedOrNewConn)isBadConn = errors.Is(err, driver.ErrBadConn)if !isBadConn {break}}if isBadConn {return db.query(ctx, query, args, alwaysNewConn)}return rows, err
}func (db *DB) query(ctx context.Context, query string, args []any, strategy connReuseStrategy) (*Rows, error) {// 调用db.conn来获取连接,获取连接成功后,调用驱动相应的接口进行查询操作:dc, err := db.conn(ctx, strategy)if err != nil {return nil, err}// 调用DB.queryDC时传入了db.releaseConn函数,就是为查询操作结束或者发生异常情况释放连接做准备的return db.queryDC(ctx, nil, dc, dc.releaseConn, query, args)
}func (db *DB) queryDC(ctx, txctx context.Context, dc *driverConn, releaseConn func(error), query string, args []any) (*Rows, error) {// 如果驱动有实现QueryerContext或者Queryer接口,则直接执行驱动的相应接口queryerCtx, ok := dc.ci.(driver.QueryerContext)var queryer driver.Queryerif !ok {queryer, ok = dc.ci.(driver.Queryer)}if ok {var nvdargs []driver.NamedValuevar rowsi driver.Rowsvar err errorwithLock(dc, func() {// 来自 Stmt.Exec 和 Stmt.Query 调用者的参数转换为驱动程序值。nvdargs, err = driverArgsConnLocked(dc.ci, nil, args)if err != nil {return}rowsi, err = ctxDriverQuery(ctx, queryerCtx, queryer, query, nvdargs)})if err != driver.ErrSkip {if err != nil {releaseConn(err)return nil, err}// Note: ownership of dc passes to the *Rows, to be freed// with releaseConn.rows := &Rows{dc: dc,releaseConn: releaseConn,rowsi: rowsi,}// rows.initContextClose函数会开启一个协程,阻塞监听context的Done事件消息// 若发生context超时或cancel事件,调用rows.close,rows.close能调用cancel函数结束awaitDone协程rows.initContextClose(ctx, txctx)return rows, nil}}// 如果如果驱动没有实现QueryerContext或者Queryer接口,又或者返回了driver.ErrSkip错误// 则采取先预编译查询语句再传参进行查询的方法var si driver.Stmtvar err errorwithLock(dc, func() {si, err = ctxDriverPrepare(ctx, dc.ci, query)})if err != nil {releaseConn(err)return nil, err}ds := &driverStmt{Locker: dc, si: si}rowsi, err := rowsiFromStatement(ctx, dc.ci, ds, args...)if err != nil {ds.Close()releaseConn(err)return nil, err}// Note: ownership of ci passes to the *Rows, to be freed// with releaseConn.rows := &Rows{dc: dc,releaseConn: releaseConn,rowsi: rowsi,closeStmt: ds,}// 监听context,超时或cancel时调用rows.closerows.initContextClose(ctx, txctx)return rows, nil
}
Exec
定义:func (*Conn) ExecContext(ctx context.Context,query string,args ...any)(Result,error) 作用:执行不返回任何行结果的查询。 场景:通常用于执行 INSERT、UPDATE 或 DELETE 等修改数据库的操作
参数:
- ctx:上下文对象
- query: sql 查询语句
- args:可选,替换 SQL 查询中的占位符参数(如 ? 或 :name)
import ("context""database/sql""log"
)
var (ctx context.Contextdb *sql.DB // sql.DB 是封装好的一个数据库操作对象,包含了操作数据库的基本方法
)
func main() {conn, err := db.Conn(ctx)if err != nil {log.Fatal(err)}defer conn.Close()id := 41result, err := conn.ExecContext(ctx, `UPDATE balances SET balance = balance + 10 WHERE user_id = ?;`, id)if err != nil {log.Fatal(err)}rows, err := result.RowsAffected()if err != nil {log.Fatal(err)}if rows != 1 {log.Fatalf("expected single row affected, got %d rows affected", rows)}
}Prepare
基本使用
func main() {// 创建数据库连接db, err := sql.Open("mysql", "username:password@tcp(127.0.0.1:3306)/database_name")if err != nil {panic(err.Error())}defer db.Close()// 创建 Prepared Statementstmt, err := db.Prepare("SELECT name, age FROM users WHERE age > ?")if err != nil {panic(err.Error())}defer stmt.Close()// 执行 Prepared Statementrows, err := stmt.Query(18)if err != nil {panic(err.Error())}defer rows.Close()// 遍历查询结果for rows.Next() {var name stringvar age intif err := rows.Scan(&name, &age); err != nil {panic(err.Error())}fmt.Printf("Name: %s, Age: %d\n", name, age)}// 检查是否出错if err := rows.Err(); err != nil {panic(err.Error())}
}
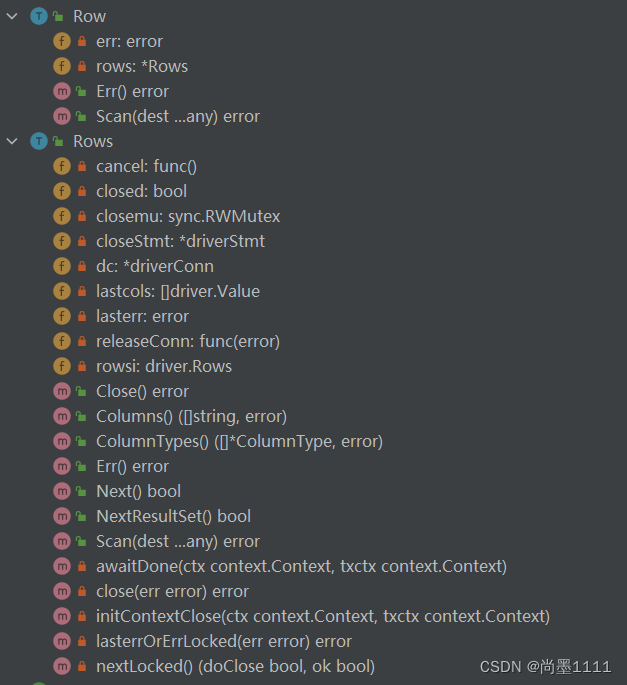
Rows
rows是Query接口的返回,它是一个迭代器抽象,可以通过rows.Next遍历查询操作返回的所有结果行。
- rows依赖于它的子成员rowsi,它是driver.Rows类型。rows的Next函数依赖于rowsi的Next函数来完成:
- Rows.Scan会将数据库的字段转化为Go能识别的字段
rows, _ := db.Query()
defer rows.Close()
for rows.Next() {rows.Scan()
}
// 如果是多结果集查询
for rows.NextResultSet() {for rows.Next() {rows.Scan()}
}func (rs *Rows) Next() bool {var doClose, ok boolwithLock(rs.closemu.RLocker(), func() {// 当nextLocked函数返回EOF或其他类型的错误时,就会自动close调这个rows,而rows.close会release调他所占用的连接doClose, ok = rs.nextLocked()})if doClose {rs.Close()}return ok
}
func (rs *Rows) Scan(dest ...interface{}) error {if rs.isClosed() {return errors.New("sql: Rows are closed")}if rs.lastcols == nil {return errors.New("sql: Scan called without calling Next")}if len(dest) != len(rs.lastcols) {return fmt.Errorf("sql: expected %d destination arguments in Scan, not %d", len(rs.lastcols), len(dest))}for i, sv := range rs.lastcols {err := convertAssign(dest[i], sv)if err != nil {return fmt.Errorf("sql: Scan error on column index %d: %v", i, err)}}return nil
}
DB.Stmt,Statements
基本使用
一般用Prepared Statements和Exec()完成INSERT, UPDATE, DELETE操作。
stmt, err := db.Prepare("INSERT INTO users(name) VALUES(?)")
if err != nil {log.Fatal(err)
}
res, err := stmt.Exec("sommer")
if err != nil {log.Fatal(err)
}
lastId, err := res.LastInsertId()
if err != nil {log.Fatal(err)
}
rowCnt, err := res.RowsAffected()
if err != nil {log.Fatal(err)
}
log.Printf("ID = %d, affected = %d\n", lastId, rowCnt)
源码
在数据库层面,Prepared Statements是和单个数据库连接绑定的。客户端发送一个有占位符的statement到服务端,服务器返回一个statement ID,然后客户端发送ID和参数来执行statement。

当生成一个Prepared Statement
- 自动在连接池中绑定到一个空闲连接
- Stmt对象记住绑定了哪个连接
- 执行Stmt时,尝试使用该连接。如果不可用,例如连接被关闭或繁忙中,会自动re-prepare,绑定到另一个连接。
type Stmt struct {...css []connStmt....
}func (db *DB) Prepare(query string) (*Stmt, error) {return db.PrepareContext(context.Background(), query)
}func (db *DB) PrepareContext(ctx context.Context, query string) (*Stmt, error) {var stmt *Stmtvar err errorfor i := 0; i < maxBadConnRetries; i++ {stmt, err = db.prepare(ctx, query, cachedOrNewConn)if err != driver.ErrBadConn {break}}if err == driver.ErrBadConn {return db.prepare(ctx, query, alwaysNewConn)}return stmt, err
}func (db *DB) prepare(ctx context.Context, query string, strategy connReuseStrategy) (*Stmt, error) {dc, err := db.conn(ctx, strategy)if err != nil {return nil, err}var si driver.StmtwithLock(dc, func() {si, err = dc.prepareLocked(ctx, query)})if err != nil {db.putConn(dc, err)return nil, err}stmt := &Stmt{db: db,query: query,css: []connStmt{{dc, si}},lastNumClosed: atomic.LoadUint64(&db.numClosed),}db.addDep(stmt, stmt)db.putConn(dc, nil)return stmt, nil
}
func (s *Stmt) connStmt(ctx context.Context, strategy connReuseStrategy) (dc *driverConn, releaseConn func(error), ds *driverStmt, err error) {if err = s.stickyErr; err != nil {return}s.mu.Lock()if s.closed {s.mu.Unlock()err = errors.New("sql: statement is closed")return}// In a transaction or connection, we always use the connection that the// stmt was created on.if s.cg != nil {s.mu.Unlock()dc, releaseConn, err = s.cg.grabConn(ctx) // blocks, waiting for the connection.if err != nil {return}return dc, releaseConn, s.cgds, nil}s.removeClosedStmtLocked() //这里把所有close的连接从css中删除掉,主要是为了优化遍历s.css的速度s.mu.Unlock()//为什么不直接先在css里面尝试寻找,没有的话,再从全局的空闲连接池中找。(css中的连接无法判断是否是空闲??不是有一个inUse字段的吗.从复杂度方面考虑一下)dc, err = s.db.conn(ctx, strategy)//并不会优先获得执行过prepare语句的connectionif err != nil {return nil, nil, nil, err}s.mu.Lock()for _, v := range s.css { //if v.dc == dc { //检查从空闲连接池获得的是不是该statement执行prepare指令的连接s.mu.Unlock()return dc, dc.releaseConn, v.ds, nil}}s.mu.Unlock()//如果不是,则需要重新在这条新的连接上prepare这个statement// No luck; we need to prepare the statement on this connectionwithLock(dc, func() {ds, err = s.prepareOnConnLocked(ctx, dc)})if err != nil {dc.releaseConn(err)return nil, nil, nil, err}return dc, dc.releaseConn, ds, nil
}相关文章:
xorm源码学习
文章目录 XORM源码浅析及实践ORMORM vs. SQLXORM软件架构 ORM 引擎 Engine——DBM*core.DB Golang:database/sql 源码基本结构连接复用,提高性能。增加数据库连接池数量连接管理 database/sql主要内容:sql.DB创建数据库连接sql.Open()DB.conn…...

Vue3中的<script setup>和<script>的区别
相同点 在一个 Vue3 单文件组件 (SFC)中,<script setup> 和 <script> 它们各自最多只能存在一个。 不同点 <script setup> 这个脚本块将被预处理为组件的 setup() 函数,这意味着它将为每一个(也可以说每一次)组件实例都执行。 <…...
)
Docker笔记-Docker搭建最新版zabbix服务端(2023-07-31)
前言 一开始问chartgpt上,搭建的思路是对的,但命令和细节有问题,最后还是依靠StackOverflow解决的。一开始在amd的linux上搭建好docker版的zabbix,但放到arm的机器上就报错了,原因是指令集不匹配,最后跑到…...

QT配合CSS隐藏按钮
第一种方法 在Qt的CSS样式表中,使用 visibility 属性来隐藏按钮。设置 visibility 为 hidden 不可见,而设置为 visible 则可见。 隐藏所有 QPushButton QPushButton {visibility: hidden; }隐藏特定的按钮,用按钮的名称或样式类进行定位就…...

2023亚太地区数学建模C题思路分析+模型+代码+论文
目录 1.2023亚太地区各题思路模型:比赛开始后,第一时间更新,获取见文末名片 3 常见数模问题常见模型分类 3.1 分类问题 3.2 优化问题 详细思路见此名片,开赛第一时间更新 1.亚太地区数学建模ABC题思路模型:9比赛开…...
Linguistic Steganalysis in Few-Shot Scenario论文阅读笔记
TIFS期刊 A类期刊 新知识点 Introduction Linguistic Steganalysis in Few-Shot Scenario模型是个预训练方法。 评估了四种文本加密分析方法,TS-CSW、TS-RNN、Zou、SeSy,用于分析和训练的样本都由VAE-Stego生产(编码方式使用AC编码)。 实验是对比在少样…...
)
详细学习Pyqt5的4种项目部件(Item Widget)
Pyqt5相关文章: 快速掌握Pyqt5的三种主窗口 快速掌握Pyqt5的2种弹簧 快速掌握Pyqt5的5种布局 快速弄懂Pyqt5的5种项目视图(Item View) 快速弄懂Pyqt5的4种项目部件(Item Widget) 快速掌握Pyqt5的6种按钮 快速掌握Pyqt5的10种容器&…...
notepad++ 插件JSONView安装
1,前提 开发过程中经常需要处理json格式语句,需要对json数据格式化处理,因为使用的是虚拟机内开发,所以没法连接外网,只能在本地电脑下载插件后,然后上传到虚拟机中,进行安装使用。 2…...
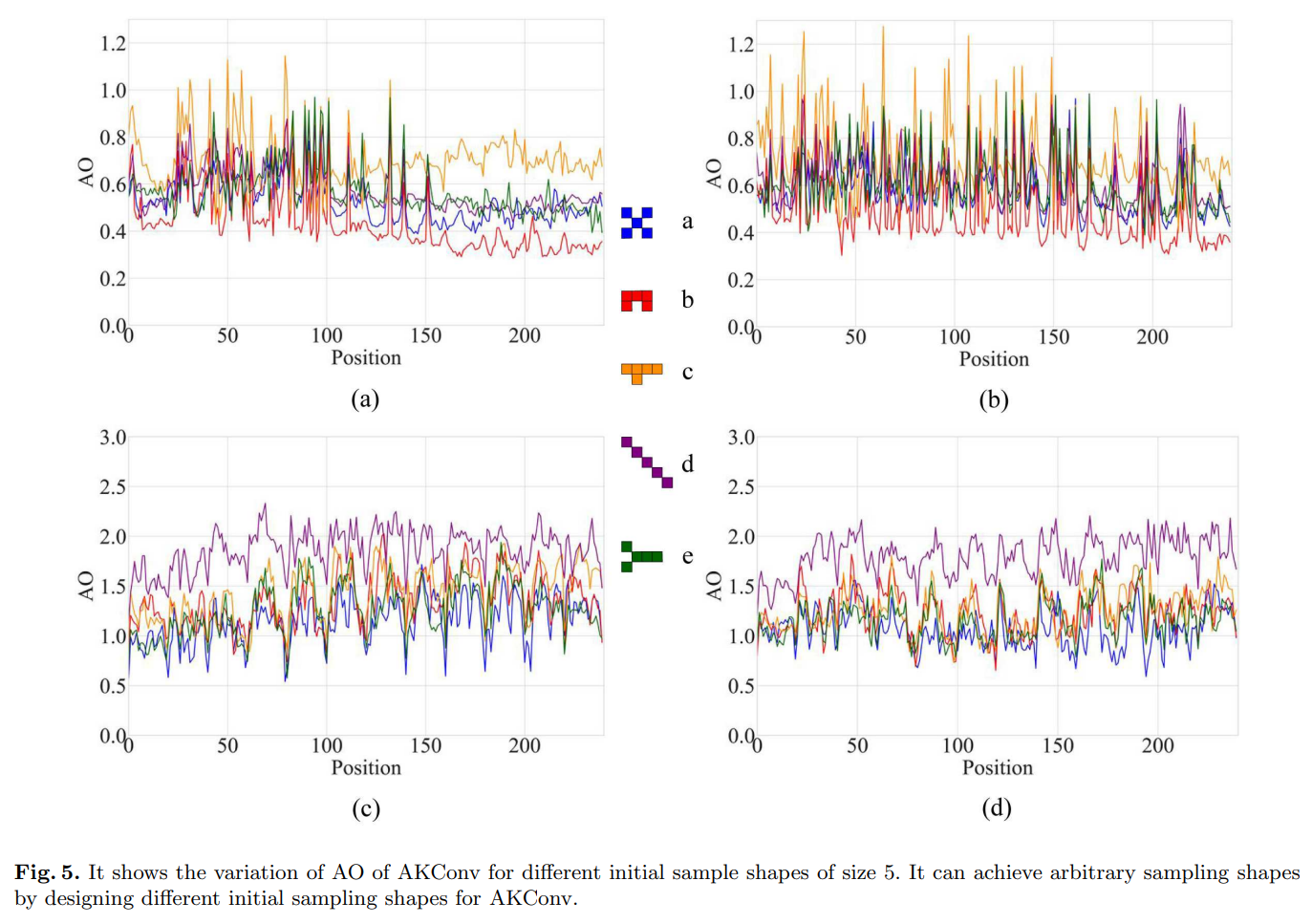
AKConv:具有任意采样形状和任意数目参数的卷积核
文章目录 摘要1、引言2、相关工作3、方法3.1、定义初始采样位置3.2、可变卷积操作3.3、扩展AKConv3.3、扩展AKConv 4、实验4.1、在COCO2017上的目标检测实验4.2、在VOC 712上的目标检测实验4.3、在VisDrone-DET2021上的目标检测实验4.4、比较实验4.5、探索初始采样形状 5、分析…...

如何使用C++开发集群服务
开发集群服务需要掌握以下技术: 分布式系统原理:了解集群的概念、工作原理、负载均衡、容错等相关概念。 网络编程:掌握Socket编程和HTTP协议等。 C编程:熟练掌握C语言的基础知识和STL等常用库。 多线程编程:了解线…...
docker安装以及idea访问docker
其他目录: docker 安装环境: https://blog.csdn.net/gd898989/article/details/134570167 docker 打包java包,并运行(有空更新) url “” docker 打包vue (有空更新) url “” docker 多服务 (…...

激光切割头组件中喷嘴的作用是什么
喷嘴是一个不可忽视的部件。尽管喷嘴并不起眼,却有着重要的作用;喷嘴一般是与激光切割头同轴的,且形状多样:圆柱形、锥形、缩放型等。 喷嘴的口径尺寸时不相同的,大口径的喷嘴对聚焦来的激光束没有很严苛的要求;而口径…...

腾讯云双11活动最后一天,错过再等一年!
腾讯云双11活动已经进入尾声,距离活动结束仅剩最后一天,记得抓住这次上云好时机,错过这次,就要等到下一年才能享受到这样的优惠力度了! 活动地址: 点此直达腾讯云双11活动主会场 活动详情: 1…...
Java实现飞翔的鸟小游戏
Java实现飞翔的鸟小游戏 1.准备工作 创建一个新的Java项目命名为“飞翔的鸟”,并在src中创建一个包命名为“com.qiku.bird",在这个包内分别创建4个类命名为**“Bird”、“BirdGame”、“Column”、“Ground”,并向需要的图片**素材导入…...

Python网络请求初级篇:使用Requests库抓取和解析数据
在网络编程中,请求和接收数据是最常见的任务之一。Python的Requests库提供了丰富的功能,使得HTTP请求变得非常简单。在本文中,我们将了解如何使用Requests库发起HTTP请求,并解析返回的数据。 一、安装Requests库 首先࿰…...
详解API开发【电商平台API封装商品详情SKU数据接口开发】
1、电商API开发 RESTful API的设计 RESTful API是一种通过HTTP协议发送和接收数据的API设计风格。它基于一些简单的原则,如使用HTTP动词来操作资源、使用URI来标识资源、使用HTTP状态码来表示操作结果等等。在本文中,我们将探讨如何设计一个符合RESTfu…...

后端项目连接数据库-添加MyBatis依赖并检测是否成功
一.在pom.xml添加Mybatis相关依赖 在Spring Boot项目中,编译时会自动加载项目依赖,然后使用依赖包。 需要在根目录下pom.xml文件中添加Mybatis依赖项 <!-- Mybatis整合Spring Boot的依赖项 --> <dependency><groupId>org.mybatis.s…...

C++ CryptoPP使用RSA加解密
Crypto (CryptoPP) 是一个用于密码学和加密的 C 库。它是一个开源项目,提供了大量的密码学算法和功能,包括对称加密、非对称加密、哈希函数、消息认证码 (MAC)、数字签名等。Crypto 的目标是提供高性能和可靠的密码学工具,以满足软件开发中对…...
从实践角度深入探究数据驱动和关键字驱动测试方法!
数据驱动 数据驱动,指在软件测试领域当中的数据驱动测试(Data-Driven Testing,简称DDT)是⼀种软件测试⽅法,在不同的数据下重复执⾏相同顺序的测试步骤,测试脚本从数据源读取测试数据,⽽不使⽤…...

Unity收费对谁影响最大
Unity的收费政策对以下几类人群影响最大: 游戏开发商:Unity收费政策中最直接的影响对象就是游戏开发商。对于那些使用Unity引擎制作游戏的开发商来说,他们将需要考虑新的许可证费用和服务费用,这可能会对他们的盈利和发展产生影响…...

SillyTavern桌面版终极指南:三步打造你的专属AI聊天桌面应用
SillyTavern桌面版终极指南:三步打造你的专属AI聊天桌面应用 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 还在为复杂的命令行启动和浏览器标签混乱而烦恼吗?Sill…...

亿万富翁不再相信比特币
亿万富翁首次公开称不再相信比特币的「数字黄金」叙事。对比特币而言,或许是一个重要转折点。5月22日,亿万富翁投资者马克库班表示, 在对比特币作为抵御法币疲软和地缘政治不稳定对冲工具的作用失去信心后, 他已经卖掉大部分比特币持仓。净资产约为100亿…...
)
DeepSeek熔断决策延迟超23ms?,基于eBPF实时观测的熔断器内核态性能瓶颈诊断指南(限内部技术圈流通)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek熔断降级方案 DeepSeek大模型服务在高并发、低质量请求或底层依赖异常时,需具备快速响应的熔断与降级能力,以保障系统整体可用性与资源稳定性。该方案基于响应延迟、错误…...

三招识别“纪律高危”学生?K-Means聚类助你构建精准考勤画像
助睿实验3 - 学生用户画像 - 考勤主题扩展标签构建第一部分:实验背景1.1实验目的本实验旨在基于已完成的学生考勤主题标签表,掌握使用K-Means聚类算法对学生考勤行为进行自动分群的核心技能。具体任务包括:通过迟到、早退、请假、校服违规次数…...

Spiderbuf_H05时间戳机制深度解析:锚点偏移与服务端校验
1. 这不是“破解”,是时间戳反爬机制的逆向解构你打开浏览器按F12,切到Network面板,刷新页面,盯着XHR请求发呆——那个带一长串数字的timestamp参数,每次刷新都变,但又不是随机乱跳,而是和当前时…...

Lilishop:基于Spring Boot3的B2B2C开源商城系统全解析
引言在数字化转型浪潮席卷各行各业的今天,电商系统已成为企业拓展线上业务的核心基础设施。然而,从零构建一套功能完备、性能卓越、可扩展的商城系统,不仅需要投入大量研发资源,还面临技术选型、架构设计、安全合规等诸多挑战。开…...
降低 Agent 推理成本?)
成本优化秘籍:如何通过模型路由(Model Routing)降低 Agent 推理成本?
成本优化秘籍:如何通过模型路由(Model Routing)降低 Agent 推理成本? 1. 引入与连接:推理成本的"隐形黑洞"与破解之道 1.1 引人入胜的开场:一个真实的成本困境 让我们从一个真实故事开始。今年早些时候,我与一家知名科技创业公司的CTO进行了一次深入交流。…...

RHEL8 SSH蜜罐实战:生产级威胁感知与行为仿真
1. 为什么在RHEL8上部署SSH蜜罐不是“搞个假登录框”那么简单 很多人第一次听说“SSH蜜罐”,脑子里浮现的是一台开着22端口、用户名密码全设成admin/admin的虚拟机,等着黑客连上来截图发朋友圈。我在金融行业做红蓝对抗支撑的那几年,亲眼见过…...

UE4.26实战:用蒙太奇和根运动实现角色‘钻洞’翻滚,解决碰撞体鬼畜问题
UE4.26实战:蒙太奇与根运动实现角色钻洞翻滚的工程化解决方案在横版过关或潜行类游戏开发中,角色穿越低矮空间的动画实现往往面临两大技术痛点:动画过渡生硬导致的"鬼畜"现象,以及碰撞体未同步调整引发的物理系统冲突。…...

量子机器学习实战:用变分量子电路对泰坦尼克数据集分类
1. 项目概述:当量子计算遇上经典分类难题量子机器学习(QML)听起来像是科幻小说里的概念,但如果你像我一样,在经典机器学习领域摸爬滚打多年,再一头扎进量子计算的海洋,你会发现它更像是一场激动…...