论文笔记:详解NEUPSL DSI
《Using Domain Knowledge to Guide Dialog Structure Induction via Neural Probabilistic 》
名词解释
Dialog Structure Induction(DSI)是推断给定目标导向对话的潜在对话结构(即一组对话状态及其时间转换)的任务。它是现代对话系统设计和话语分析的关键组件。
Probabilistic Soft Logic (概率软逻辑,PSL)是一种在统计关系学习和推理中使用的框架。它结合了逻辑编程的可解释性与概率模型的不确定性处理能力,适用于处理不确定和复杂的关系数据。PSL使用软逻辑(一种近似布尔逻辑的形式)来表达知识,其中逻辑命题的真值不再是简单的真(true)或假(false),而是在[0,1]范围内的实数,表示真实程度的不同。在PSL中,逻辑规则被转化为概率模型的一部分。这使得PSL能够以概率方式处理不确定性,例如,在数据缺失或噪声情况下进行推理。
文章的主要工作
(1) 提出了 NEUPSL DSI,这是一种新颖的平滑PSL(概率软逻辑)约束松弛方法,旨在确保在反向传播过程中提供丰富的梯度信号;
(2) 在合成和现实对话数据集上评估了 NEUPSL DSI,在标准泛化、领域泛化和领域适应三种设置下进行了测试。我们定量地展示了注入领域知识相比于无监督和少量样本方法的优势;
(3) 全面调查了软逻辑增强学习对学习神经模型不同方面的影响,通过检查其在表示学习和结构归纳方面的质量。
前置知识
VRNN
DD-VRNN
Probabilistic Soft Logic(PSL)
这项工作以一种类似于概率软逻辑(Probabilistic Soft Logic,PSL)的声明方式引入了软约束。PSL 是一种声明式统计关系学习(Statistical Relational Learning,SRL)框架,用于定义一种特定的概率图模型,即铰链损失马尔可夫随机场(Hinge-Loss Markov Random Field,HL-MRF)(Bach 等人,2017年)。PSL 使用一阶逻辑规则来模拟关系依赖性和结构约束,这些规则被称为模板,其参数称为原子。例如,“对话中的第一句话很可能属于问候状态”的陈述可以表示为:
FirstUtt ( U ) → STATE ( U , greet ) (5) \text{FirstUtt}(U) \rightarrow \text{STATE}(U,\text{greet})\tag{5} FirstUtt(U)→STATE(U,greet)(5)
在公式(5)中, FirstUtt ( U ) → STATE ( U , greet ) \text{FirstUtt}(U) \rightarrow \text{STATE}(U,\text{greet}) FirstUtt(U)→STATE(U,greet) 的 FirstUtt ( U ) \text{FirstUtt}(U) FirstUtt(U) 和 STATE ( U , greet ) \text{STATE}(U,\text{greet}) STATE(U,greet) 是原子(即原子布尔语句),分别指出一个话语 U U U 是否为对话的第一句话,或者它是否属于问候状态。在PSL规则中的原子通过替换自由变量(例如上文的 U U U)为感兴趣领域的具体实例(例如,具体话语 ‘Hello!’)来实现具体化,我们称这些为具体化原子。概率模型的观测变量和目标/决策变量对应于从领域中构建的具体化原子,例如, FirstUtt ( ′ H e l l o ! ′ ) \text{FirstUtt}('Hello!') FirstUtt(′Hello!′) 可能是一个观测变量,而 STATE ( ′ H e l l o ! ′ , greet ) \text{STATE}('Hello!', \text{greet}) STATE(′Hello!′,greet) 可能是一个目标变量。
观测变量是指在概率模型或统计分析中可以直接测量或记录的变量。它们是数据收集过程中实际观察到的值。在统计和机器学习的上下文中,观测变量通常用于推断或预测那些我们无法直接测量的潜在变量或未知参数。
目标变量,又称为因变量或预测变量,在数据分析、统计建模和机器学习中是指那些模型试图预测或解释的变量。
概率软逻辑(PSL)通过允许原本具有布尔值的原子采用区间 [0, 1] 内的连续真值来执行推理,从而软化了逻辑约束。利用这种放松,PSL用一种称为卢卡西维奇逻辑(Lukasiewicz logic)的软逻辑形式替换了逻辑运算(Klir 和 Yuan, 1995):
A ∧ B = max ( 0.0 , A + B − 1.0 ) A \land B = \max(0.0, A+B - 1.0) A∧B=max(0.0,A+B−1.0)
A ∨ B = min ( 1.0 , A + B ) (6) A \lor B = \min(1.0, A+B) \tag{6} A∨B=min(1.0,A+B)(6)
¬ A = 1.0 − A \lnot A = 1.0 - A ¬A=1.0−A
其中 A A A 和 B B B 代表基础原子或原子上的逻辑表达式,并且取值在 [0, 1] 范围内。例如,PSL将公式 5 中的语句转换为以下形式:
min { 1 , 1 − FirstUtt ( U ) + STATE ( U , greet ) } (7) \min\{1, 1 - \text{FirstUtt}(U) + \text{STATE}(U, \text{greet})\}\tag{7} min{1,1−FirstUtt(U)+STATE(U,greet)}(7)
鉴于 A → B A \rightarrow B A→B 等价于 ¬ A ∨ B \lnot A \lor B ¬A∨B,我们可以创建一系列函数 { ℓ i } i = 1 m \{ \ell_i \}^m_{i=1} {ℓi}i=1m,称为模板,它们将数据映射到 [0, 1] 区间。使用这些模板,PSL定义了一个条件概率密度函数,用于在给定观测数据 x x x 的情况下,对未观测随机变量 y y y 进行推理,这称为铰链损失马尔可夫随机场(HL-MRF):
P ( y ∣ x ) ∝ exp ( − ∑ i = 1 m λ i ⋅ ϕ i ( y , x ) ) (8) P(y|x) \propto \exp\left(-\sum_{i=1}^{m} \lambda_i \cdot \phi_i(y, x)\right) \tag{8} P(y∣x)∝exp(−i=1∑mλi⋅ϕi(y,x))(8)
这里 λ i \lambda_i λi 是一个非负权重,而 ϕ i \phi_i ϕi 是基于模板的潜在函数:
ϕ i ( y , x ) = max { 0 , ℓ i ( y , x ) } (9) \phi_i(y, x) = \max\{0, \ell_i(y, x)\} \tag{9} ϕi(y,x)=max{0,ℓi(y,x)}(9)
然后,模型预测 y y y 的推理通过最大后验(MAP)估计继续进行,即通过最大化目标函数 P ( y ∣ x ) P(y|x) P(y∣x)(公式 8)相对于 y y y 的值。
Neural Probabilistic Soft Logic Dialogue Structure Induction(NEUPSL DSI)方法
问题表述
在给定面向目标的对话语料库 D D D 的情况下,我们考虑了学习潜在于该语料库的图 G G G 的对话结构识别(DSI)问题。更正式地说,对话结构被定义为有向图 G = ( S , P ) G = (S, P) G=(S,P),其中 S = { s 1 , … , s m } S = \{s_1, \ldots, s_m\} S={s1,…,sm} 编码了一组对话状态,而 P P P 是概率分布 p ( s t ∣ s < t ) p(s_t|s_{<t}) p(st∣s<t),表示状态之间转移的可能性(见下图作为例子)。给定潜在的对话结构 G G G,对话 d i = { x 1 , … , x T } ∈ D d_i = \{x_1, \ldots, x_T\} \in D di={x1,…,xT}∈D 是按时间顺序排列的话语集合 x t x_t xt。假设 x t x_t xt 根据过去历史条件下的话语分布 p ( x t ∣ s ≤ t , x < t ) p(x_t|s_{\leq t}, x_{<t}) p(xt∣s≤t,x<t) 定义,状态 s t s_t st 根据 p ( s t ∣ s < t ) p(s_t|s_{<t}) p(st∣s<t) 定义。给定对话语料库 D = { d i } i = 1 n D = \{d_i\}_{i=1}^n D={di}i=1n,DSI 的任务是学习一个尽可能接近潜在图的有向图形模型 G = ( S , P ) G = (S, P) G=(S,P)。
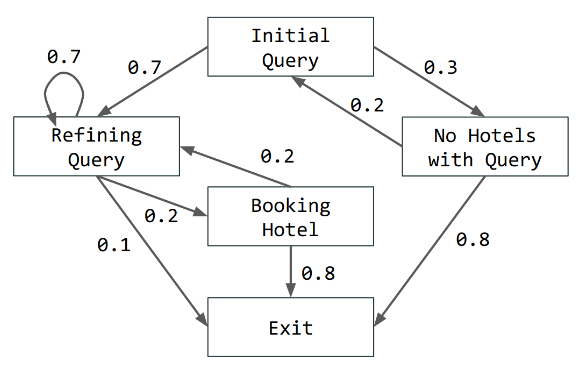
NEUPSL DSI 下整合神经和符号学习
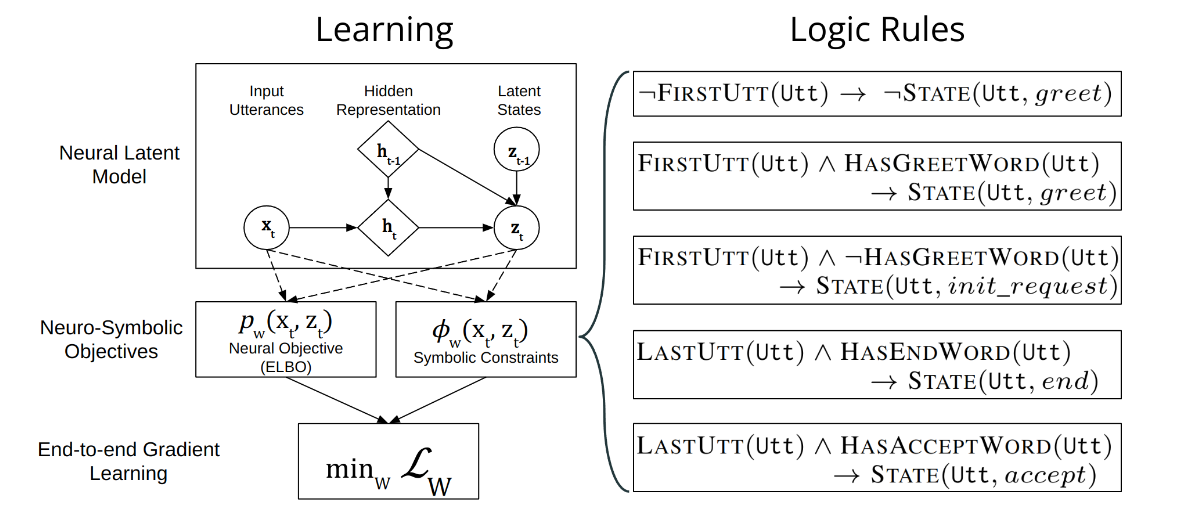
上图提供了 DD-VRNN 和符号约束集成的图形表示。直观上,NEUPSL DSI 可以描述为三个部分:实例化、推理和学习。
实例化 NEUPSL DSI 模型使用一组一阶逻辑模板来创建一组潜力,这些潜力定义了用于学习和评估的损失函数。设 p w p_w pw 为 DD-VRNN 的潜在状态预测函数,其中包含隐藏参数 w w w 和输入话语 x vrnn x_{\text{vrnn}} xvrnn。这个函数的输出,定义为 p w ( x vrnn ) p_w(x_{\text{vrnn}}) pw(xvrnn),将是代表给定话语每个潜在类别可能性的概率分布。给定一个一阶符号规则 ℓ i ( y , x ) \ell_i(y, x) ℓi(y,x),其中 y = p w ( x vrnn ) y = p_w(x_{\text{vrnn}}) y=pw(xvrnn) 是代表来自神经模型的潜在状态预测的决策变量,而 x x x 代表未在神经特征 x vrnn x_{\text{vrnn}} xvrnn 中纳入的符号观察,NEUPSL DSI 实例化一组形式为以下的deep hinge-loss potentials(深度铰链损失潜能):
ϕ w , i ( x vrnn , x ) = max ( 0 , ℓ i ( p w ( x vrnn ) , x ) ) (10) \phi_{w,i}(x_{\text{vrnn}}, x) = \max(0, \ell_i(p_w(x_{\text{vrnn}}), x))\tag{10} ϕw,i(xvrnn,x)=max(0,ℓi(pw(xvrnn),x))(10)
例如,在参考公式7时,决策变量 y = p w ( x vrnn ) y = p_w(x_{\text{vrnn}}) y=pw(xvrnn) 与 STATE(x, greet) 随机变量关联,导致以下情况:
ℓ i ( p w ( x vrnn ) , x ) = min { 1 , 1 − FIRSTUTT ( U ) + p w ( x vrnn ) } (11) \ell_i(p_w(x_{\text{vrnn}}), x) = \min\{1, 1 - \text{FIRSTUTT}(U) + p_w(x_{\text{vrnn}})\} \tag{11} ℓi(pw(xvrnn),x)=min{1,1−FIRSTUTT(U)+pw(xvrnn)}(11)
在上述实例化模型的描述中,NEUPSL DSI 推理目标被拆分为神经推理目标和符号推理目标。神经推理目标通过评估 DD-VRNN 模型预测相对于 DSI 的标准损失函数来计算。鉴于深度铰链损失潜能 { ϕ w , i } i = 1 m \{\phi_{w,i}\}_{i=1}^m {ϕw,i}i=1m,符号推理目标是在决策变量 y = p w ( x vrnn ) y = p_w(x_{\text{vrnn}}) y=pw(xvrnn) 处评估的 HL-MRF 似然(公式8):
P w ( y ∣ x vrnn , x , λ ) = exp ( − ∑ i = 1 m λ i ⋅ ϕ w , i ( x vrnn , x ) ) (12) P_w(y|x_{\text{vrnn}}, x, \lambda) = \exp\left(-\sum_{i=1}^m \lambda_i \cdot \phi_{w,i}(x_{\text{vrnn}}, x)\right) \tag{12} Pw(y∣xvrnn,x,λ)=exp(−i=1∑mλi⋅ϕw,i(xvrnn,x))(12)
在 NEUPSL DSI 下,决策变量 y = p w ( x vrnn ) y = p_w(x_{\text{vrnn}}) y=pw(xvrnn) 是由神经网络权重 w w w 隐含控制的,因此,对决策变量 y ∗ y^* y∗ 进行符号学习的传统 MAP 推理,可以简单地通过神经权重最小化 arg min w P w ( y ∣ x vrnn , x , λ ) \arg\min_w P_w(y|x_{\text{vrnn}}, x, \lambda) argminwPw(y∣xvrnn,x,λ) 来完成。结果,NEUPSL DSI 学习最小化一个受限优化目标:
w ∗ = arg min w [ L DD-VRNN + L constraint ] (13) w^* = \arg\min_w \left[ \mathcal{L}_{\text{DD-VRNN}} + \mathcal{L}_{\text{constraint}} \right] \tag{13} w∗=argwmin[LDD-VRNN+Lconstraint](13)
我们将约束损失定义为 HL-MRF 分布的对数似然:
L Constraint = − log P w ( y ∣ x vrnn , x , λ ) (14) \mathcal{L}_{\text{Constraint}} = -\log P_w (y|x_{\text{vrnn}}, x, \lambda) \tag{14} LConstraint=−logPw(y∣xvrnn,x,λ)(14)
为了改进梯度学习的软逻辑约束,直接使用的线性软约束以及经典的Lukasiewicz松弛无法传递具有幅度的梯度,而是仅传递方向(例如,±1)。正式来说,关于 w w w 的潜能 ϕ w ( x vrnn , x ) = max ( 0 , ℓ ( p w ( x vrnn ) , x ) ) \phi_w(x_{\text{vrnn}}, x) = \max(0, \ell(p_w(x_{\text{vrnn}}), x)) ϕw(xvrnn,x)=max(0,ℓ(pw(xvrnn),x)) 的梯度为:
∂ ϕ w ∂ w = ∂ ℓ ( p w , x ) ∂ w ⋅ 1 ϕ w > 0 \frac{\partial \phi_w}{\partial w} = \frac{\partial \ell(p_w, x)}{\partial w} \cdot 1_{\phi_w>0} ∂w∂ϕw=∂w∂ℓ(pw,x)⋅1ϕw>0
= [ ∂ ∂ p w ℓ ( p w , x ) ] ⋅ ∂ p w ∂ w ⋅ 1 ϕ w > 0 (15) = \left[ \frac{\partial}{\partial p_w} \ell(p_w, x) \right] \cdot \frac{\partial p_w}{\partial w} \cdot 1_{\phi_w>0} \tag{15} =[∂pw∂ℓ(pw,x)]⋅∂w∂pw⋅1ϕw>0(15)
这里 ℓ ( p w , x ) = a ⋅ p w ( x vrnn ) + b \ell(p_w, x) = a \cdot p_w(x_{\text{vrnn}}) + b ℓ(pw,x)=a⋅pw(xvrnn)+b 其中 a , b ∈ R a, b \in \mathbb{R} a,b∈R 和 p w ( x vrnn ) ∈ [ 0 , 1 ] p_w(x_{\text{vrnn}}) \in [0, 1] pw(xvrnn)∈[0,1],这导致梯度 ∂ ∂ p w ℓ ( p w , x ) = a \frac{\partial}{\partial p_w} \ell(p_w, x) = a ∂pw∂ℓ(pw,x)=a。观察在PSL描述的三个Lukasiewicz操作,很明显 a a a 的结果总是 ±1,除非每个约束有多个 p w ( x vrnn ) p_w(x_{\text{vrnn}}) pw(xvrnn)。
因此,这种经典的软逻辑松弛导致了一个幼稚(naive)、不平滑的梯度:
∂ ϕ w ∂ w = [ a 1 ϕ w > 0 ] ⋅ ∂ p w ∂ w (16) \frac{\partial \phi_w}{\partial w} = [a 1_{\phi_w>0}] \cdot \frac{\partial p_w}{\partial w} \tag{16} ∂w∂ϕw=[a1ϕw>0]⋅∂w∂pw(16)
这主要由预测概率的梯度 ∂ ∂ w p w \frac{\partial}{\partial w} p_w ∂w∂pw 组成。它几乎不向模型提供 p w p_w pw 满足符号约束 ϕ w \phi_w ϕw 的程度的信息(除了非平滑的阶跃函数 1 ϕ w > 0 1_{\phi_w>0} 1ϕw>0),从而在基于梯度的学习中产生挑战。
在这项工作中,我们提出了一种新颖的基于对数的松弛方法,它提供了更平滑且更具信息性的梯度信息用于符号约束:
ψ w ( x ) = log ( ϕ w ( x vrnn , x ) ) \psi_w(x) = \log (\phi_w(x_{\text{vrnn}}, x)) ψw(x)=log(ϕw(xvrnn,x))
= log ( max ( 0 , ℓ ( p w ( x vrnn ) , x ) ) ) (17) = \log (\max(0, \ell(p_w(x_{\text{vrnn}}), x))) \tag{17} =log(max(0,ℓ(pw(xvrnn),x)))(17)
这个看似简单的转换给梯度行为带来了非平凡的变化:
$$ \frac{\partial \psi_w}{\partial w} = \frac{1}{\phi_w} \cdot \frac{\partial \phi_w}{\partial w}
= \left[ \frac{a}{\phi_w} 1_{\phi_w>0} \right] \cdot \frac{\partial p_w}{\partial w} \tag{18}$$
如上所示,来自符号约束的梯度现在包含了一个新项 1 ϕ w \frac{1}{\phi_w} ϕw1。它向模型提供了模型预测满足符号约束 ℓ \ell ℓ 的程度信息,使得它不再是相对于 ϕ w \phi_w ϕw 的离散阶跃函数。结果,当一个规则的满足度 ϕ w \phi_w ϕw 是非负但低(即,不确定)时,梯度的大小将会很高,而当规则的满足度很高时,梯度的大小将会低。通过这种方式,符号约束项 ϕ i \phi_i ϕi 的梯度现在引导神经模型更有效地专注于学习那些不遵守现有符号规则的挑战性例子这导致神经和符号组件在模型学习期间更有效的协作,并且从经验上导致了泛化性能的提高。
通过加权词袋模型更强地控制后验坍塌
后验坍塌(Posterior Collapse)是一种在训练变分自编码器(VAEs)时常见的问题,尤其是在自然语言处理(NLP)任务中。这个问题发生在模型的编码器部分学会忽略输入数据,导致模型的隐含变量(latent variables)不再能够捕获数据的有用信息。换句话说,后验分布(即给定观察数据后的潜在变量的条件分布)倾向于与先验分布(潜在变量的分布)相同,因此潜在变量没有为数据的生成过程提供任何有意义的信息。这种情况下,模型的解码器部分将只能基于先验知识来重构数据,而无法利用潜在表示的好处。
在VAEs中,后验坍塌通常表现为隐变量的概率分布趋向于标准正态分布,使得隐变量无法有效地编码任何关于输入数据的信息。因此,解码器学习忽视这些变量,依靠数据中的其他特征来重构输入,这降低了模型的表现力。
避免VRNN解决方案坍塌至关重要,这种坍塌指的是模型将其所有预测仅放在少数几个状态中。这个问题被称为潜在变量消失问题(Zhao等人,2017)。Zhao等人(2017)通过为VRNN引入一个词袋(BOW)损失来解决这个问题,这要求网络预测响应 x x x 中的词袋。他们将 x x x 分成两个变量: x o x_o xo(词序)和 x bow x_{\text{bow}} xbow(无词序),并假设在给定 z z z 和 c c c 的条件下,这两个变量是条件独立的:
p ( x ∣ z , c ) = p ( x o ∣ z , c ) p ( x bow ∣ z , c ) p ( z ∣ c ) . (19) p(x|z,c) = p(x_o|z,c)p(x_{\text{bow}}|z,c)p(z|c). \tag{19} p(x∣z,c)=p(xo∣z,c)p(xbow∣z,c)p(z∣c).(19)
这里, c c c 是对话历史:前面的话语,对话地位(如果话语来自同一个说话者则为1,否则为0),以及元特征(例如,主题)。让 f f f 是一个具有参数 z , x z, x z,x 的多层感知机的输出,其中 f ∈ R V f \in \mathbb{R}^V f∈RV 且 V V V 是词汇量大小。然后词袋概率被定义为 log p ( x bow ∣ z , c ) \log p(x_{\text{bow}}|z,c) logp(xbow∣z,c):
log ∏ t = 1 ∣ x ∣ e f x t ∑ j V e f j \log \prod_{t=1}^{|x|} \frac{e^{f_{x_t}}}{\sum_{j}^V e^{f_j}} logt=1∏∣x∣∑jVefjefxt
其中, ∣ x ∣ |x| ∣x∣ 是 x x x 的长度, x t x_t xt 是 x x x 中第 t t t 个词的索引。
为了对抗后验坍塌施加强有力的正则化,我们使用基于训练语料库计算得到的 tf-idf 权重的 tf-idf 加权方案。直观上,这种重加权方案帮助模型专注于重构每个对话状态中独特的非通用术语,这鼓励模型在其表示空间中“拉开”不同对话状态的句子,以更好地最小化加权 BOW 损失。相比之下,一个在均匀加权 BOW 损失下的模型可能会因重构高频率术语(例如,“what is”,“can I”和“when”)而分心,这些术语是所有对话状态共有的。因此,我们指定 tf-idf 加权 BOW 概率为:
tf-idf 加权 BOW 概率定义为:
log p ( x bow ∣ z , c ) = log ∏ t = 1 ∣ x ∣ w x t e f x t ∑ j V e f j (20) \log p(x_{\text{bow}}|z, c) = \log \prod_{t=1}^{|x|} \frac{w_{x_t} e^{f_{x_t}}}{\sum_{j}^V e^{f_j}} \tag{20} logp(xbow∣z,c)=logt=1∏∣x∣∑jVefjwxtefxt(20)
其中, w x t w_{x_t} wxt 是计算出的 tf-idf 权重,由下式给出:
w x t = ( 1 − α ) N + α w x t ′ w_{x_t} = \frac{(1 - \alpha)}{N} + \alpha w'_{x_t} wxt=N(1−α)+αwxt′
N N N 是语料库大小, w x t ′ w'_{x_t} wxt′ 是 x t x_t xt 索引的 tf-idf 词权重, α \alpha α 是一个超参数。在第5节中,我们探讨这种改变如何影响性能,并观察 PSL 约束是否仍然提供了性能提升。
相关文章:
论文笔记:详解NEUPSL DSI
《Using Domain Knowledge to Guide Dialog Structure Induction via Neural Probabilistic 》 名词解释 Dialog Structure Induction(DSI)是推断给定目标导向对话的潜在对话结构(即一组对话状态及其时间转换)的任务。它是现代对…...

shared_ptr子类指针转换成父类指针
假设有如下应用场景: class Base { public:void addChild(std::shared_ptr<Base>& child){...} }class Derived : public Base {}int main() {Base a;std::shared_ptr<Derived> b std::make_shared<Derived>();a.addChild(b); // Error } 该代码中声…...

五、cookie、session、token、localstroage、sessionStroage区别
一、localStorage 跟 sessionStorage有什么不同???? localStorage 1、生命周期:localStorage的生命周期是永久的,关闭页面或浏览器之后localStorage中的数据也不会消失。localStorage除非主动删除数据&am…...
基于SpringBoot的在线视频教育平台的设计与实现
摘 要 随着科学技术的飞速发展,各行各业都在努力与现代先进技术接轨,通过科技手段提高自身的优势;对于在线视频教育平台当然也不能排除在外,随着网络技术的不断成熟,带动了在线视频教育平台,它彻底改变了过…...

Vue 2.0源码分析-渲染函数render
Vue 的 _render 方法是实例的一个私有方法,它用来把实例渲染成一个虚拟 Node。它的定义在 src/core/instance/render.js 文件中: Vue.prototype._render function (): VNode {const vm: Component thisconst { render, _parentVnode } vm.$options//…...
阿里云国际短信业务网络超时排障指南
选取一台或多台线上的应用服务器或选取相同网络环境下的机器,执行以下操作。 获取公网出口IP。 curl ifconfig.me 测试连通性。 (推荐)执行MTR命令(可能需要sudo权限),检测连通性,执行30秒。 m…...

浅用tensorflow天气预测
1.开发环境 (1)Python3.8 (2)Anaconda3 (3)Tensorflow (4)Numpy (5)Pandas (6)Sklearn 先依次安装好上面的软件和包…...

基于SpringBoot学生读书笔记共享
摘 要 本论文主要论述了如何使用JAVA语言开发一个读书笔记共享平台 ,本系统将严格按照软件开发流程进行各个阶段的工作,采用B/S架构,面向对象编程思想进行项目开发。在引言中,作者将论述读书笔记共享平台的当前背景以及系统开发的…...
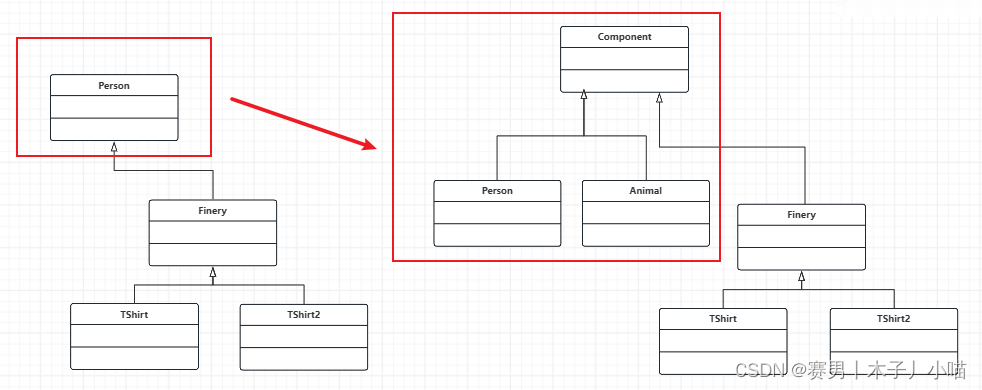
设计模式之装饰模式(2)--有意思的想法
目录 背景概述概念角色 基本代码分析❀❀花样重难点聚合关系认贼作父和认孙做父客户端的优化及好处继承到设计模式的演变过程 总结 背景 这是我第二次写装饰模式,这一次是在上一次的基础上进一步探究装饰模式,这一次有了很多新的感受和想法,也…...
深入了解 Pinia:现代 Vue 应用的状态管理利器
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...

TTS声音合成:paddlespeech、sherpa-onnx、coqui-ai
1、百度TTS文本合成语音 参考: https://aistudio.baidu.com/aistudio/projectdetail/5237474 https://www.jianshu.com/p/a7522ca6dec4 https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/text_to_speech/README_cn.md 1)过程中需要下载的TTS 声学相关模型…...

Android frameworks 开发总结之十一
1.查看android关机前的log 有时候我们在没有连接电脑的情况下,会在测试的时候突然机器关机. 这个时候如果查看 log信息就看不到了。测试前可以执行下面的命令,之后再进行测试. $ adb shell $ nohup logcat > /sdcard/xxx.log 2.android日期时间同步 关于…...
抑制过拟合——Dropout原理
抑制过拟合——Dropout原理 Dropout的工作原理 实验观察 在机器学习领域,尤其是当我们处理复杂的模型和有限的训练样本时,一个常见的问题是过拟合。简而言之,过拟合发生在模型对训练数据学得太好,以至于它捕捉到了数据中的噪声和…...

开发板启动进入系统以后再挂载 NFS 文件系统, 这里的NFS文件系统是根据正点原子教程制作的ubuntu_rootfs
如果是想开发板启动进入系统以后再挂载 NFS 文件系统,开发板启动进入文件系统,开发板和 ubuntu 能互相 ping 通,在开发板文件系统下新建一个目录 you,然后执行如下指令进行挂载: mkdir mi mount -t nfs -o nolock,nfsv…...

Ubuntu系统执行“docker ps“出现“permission denied“
当我们安装好Ubuntu时,使用鱼香ros一键安装指令 wget http://fishros.com/install -O fishros && . fishros 一键安装Docker后,执行"docker ps"出现"permission denied" seelina:~$ docker ps permission denied while …...

Python与设计模式--桥梁模式
23种计模式之 前言 (5)单例模式、工厂模式、简单工厂模式、抽象工厂模式、建造者模式、原型模式、(7)代理模式、装饰器模式、适配器模式、门面模式、组合模式、享元模式、桥梁模式、(11)策略模式、责任链模式、命令模式、中介者模…...
Linux下查看目录大小
查看目录大小 Linux下查看当前目录大小,可用一下命令: du -h --max-depth1它会从下到大的显示文件的大小。...

鸿蒙原生应用/元服务开发-AGC分发如何下载管理Profile
一、收到通知 尊敬的开发者: 您好,为支撑鸿蒙生态发展,HUAWEI AppGallery Connect已于X月XX日完成存量HarmonyOS应用/元服务的Profile文件更新,更新后Profile文件中已扩展App ID信息;后续上架流程会检测API9以上Harm…...

解决warning: #188-D: enumerated type mixed with another type问题
出现问题处如下, 指示在代码的某处将枚举类型与另一种类型混合使用,这种警告通常在将枚举类型与其他类型进行操作或赋值时出现 enum Mode {MODE_IDLE,MODE_1,MODE_2,MODE_3,MODE_4, }; enum Mode currentMode MODE_IDLE;currentMode (currentMode 1)…...

docker的知识点,以及使用
Docker 是一个开源的应用容器引擎,可以让开发者将应用程序及其依赖项打包至一个可移植的容器中,从而实现快速部署、可扩展和依赖项隔离等特性。下面是 Docker 的一些知识点以及使用方法: Docker 的组成部分包括 Docker 引擎、Docker 镜像、Do…...

如何快速掌握游戏逆向工程:FromSoftware资源解析终极指南
如何快速掌握游戏逆向工程:FromSoftware资源解析终极指南 【免费下载链接】BinderTool Dark Souls II / Dark Souls III / Bloodborne / Elden Ring bdt, bhd, bnd, dcx, tpf, fmg and param unpacking tool 项目地址: https://gitcode.com/gh_mirrors/bi/BinderT…...
)
ChatGPT记忆功能深度解析(2024官方API文档未公开的7个底层机制)
更多请点击: https://kaifayun.com 第一章:ChatGPT记忆功能怎么用 ChatGPT 的记忆功能(Memory)允许模型在对话中持续记住用户提供的关键信息,从而实现更连贯、个性化的交互体验。该功能并非默认开启,需用户…...

跨平台资源下载终极指南:轻松获取视频号、抖音、直播流等全网资源
跨平台资源下载终极指南:轻松获取视频号、抖音、直播流等全网资源 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

DLSS Swapper完整指南:免费开源的游戏DLSS智能管理工具终极教程
DLSS Swapper完整指南:免费开源的游戏DLSS智能管理工具终极教程 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否曾经为不同游戏需要管理不同版本的DLSS文件而烦恼?当《赛博朋克2077》需要…...

随机森林在天文大数据中的应用:高红移类星体高效筛选实战
1. 项目概述:用机器学习在星海中“捞针”在广袤的宇宙中寻找高红移类星体,就像是在一片无垠的星海里打捞一根特定的针。高红移类星体,作为宇宙早期最明亮的天体,是研究宇宙再电离时期、超大质量黑洞早期增长以及大尺度结构形成的绝…...

LoRA微调实战2026:从零到生产的完整工程指南
为什么2026年LoRA仍然是最重要的微调方法 大模型微调技术日新月异,但LoRA(Low-Rank Adaptation)自2021年提出以来,不仅没有被淘汰,反而在2026年成为工业界微调的主流方法之一。原因很简单:极致的参数效率。…...

【紧急预警】2024Q3起医保DRG/DIP结算将强制接入AI行为审计日志!医疗机构AI Agent日志治理4级合规改造倒计时
更多请点击: https://kaifayun.com 第一章:AI Agent医疗行业应用 AI Agent正以前所未有的深度融入医疗健康全链条,从辅助诊断、个性化治疗规划到慢病管理与药物研发,展现出强推理、多工具协同与持续学习的核心能力。不同于传统静…...

R3nzSkin Failed to find pattern 根本原因与实战修复指南
1. 这不是“找不到特征码”的报错,而是皮肤加载器在向你发出求救信号“Failed to find pattern”——当你第一次在R3nzSkin控制台里看到这行红色报错时,大概率会本能地以为:“哦,又一个特征码匹配失败”,然后下意识去改…...

非Root安卓设备上使用Frida Gadget实现应用层Hook
1. 为什么非Root设备上Hook安卓App不再是“不可能任务”很多人第一次听说Frida,脑海里自动浮现出的场景是:一台已Root的测试机、adb shell里敲着su、frida-server在后台静静运行、然后用frida-trace监听onCreate——一套行云流水的操作,但前提…...

连续处理效应下的双重差分:从二元到连续的范式演进与DML应用
1. 连续处理效应下的双重差分:从二元到连续的范式演进双重差分(Difference-in-Differences, DiD)是评估政策或干预因果效应的基石方法。它的核心逻辑直观而有力:比较处理组和对照组在干预前后的结果变化,其差值就被认为…...