生成式AI与预测式AI的主要区别与实际应用
近年来,预测式人工智能(Predictive AI)通过先进的推荐算法、风险评估模型、以及欺诈检测工具,一直在推高着该领域公司的投资回报率。然而,今年初突然杀出的生成式人工智能(Generative AI)突然成为了全球热点话题。
每个人都在热议如何利用大语言模型(Large Language Model,LLM)进行内容的生成;以及利用客户服务或扩散模型(Diffusion Model),进行视觉内容的创建。那么,生成式人工智能将替代预测式人工智能,成为提高生产力的关键驱动因素吗?

为了回答这个问题,本文将和您一起讨论推动这两大类人工智能方法的关键性机器学习技术,与之相关的独特优势和挑战,以及他们各自适用的真实业务应用。
基本定义
不可否认,生成式人工智能和预测式人工智能是两种强大的AI类型,它们在商业和其他领域都有着广泛的应用。虽然都使用机器学习从数据中获取“知识”,但它们的学习方式和目标有所不同:
- 预测式人工智能通常被用于基于历史数据,来预测未来的事件或结果。也就是说,它通过识别历史数据中的模式,并使用这些模式去预测未来的趋势。例如,它可以根据客户购买的历史数据集,通过训练智能模型,以预测次月哪些客户最有可能流失。
- 生成式人工智能通常被用来创建诸如:文本、图像、音乐和代码等新鲜内容。它通过从现有的数据中学习,以生成与训练数据类似的新数据。例如,它可以通过在广告样本的数据集上进行训练,进而用于生成新的、创造性的、且有效的广告。

如上表所示,两者的基本区别在于,预测式人工智能的输出是预测,而生成式人工智能的输出是新的内容。以下是几个典型领域的示例:
- 自然语言处理(NLP):预测式NLP模型可以将文本分类为诸如:垃圾邮件与非垃圾邮件等预定义的类别,而生成式NLP模式可以根据诸如:社交媒体帖子或产品描述等给定的提示,来创建新的文本。
- 图像处理:预测式图像处理模型,如卷积神经网络(CNN),可以将图像分类为预定义的标签,例如:识别杂货店货架上的不同产品。而生成式模型可以利用扩散模型,创建培训数据中没有的新图像,例如:广告活动的虚拟模型。
- 药物发现:预测式药物发现模型可以预测一种新的化合物,是否有毒或有潜力作为一种治疗药物。例如:生殖药物类生成式模型,可以创建新的、更高效、更低毒性的分子结构。
我们有必要了解驱动这两种类型AI的不同机器学习算法的各自优、劣势,以便为业务需求选择正确的实现方式。
预测与生成式人工智能算法的工作原理
预测式人工智能通常基于监督式机器学习,来标记数据。此处的标签数据是指使用正确的输入和输出对或序列,来注释数据。模型通过学习输入与输出数据之间的数学关系,来对新的数据进行预测。
预测式人工智能算法可以基于诸如:线性回归、逻辑回归、决策树、以及随机森林等基本的机器学习模型,来预测包括:连续变量(例如,销售量)和二进制变量(例如,客户是否会流失)等各类信息。在某些情况下,由于能够学习到数据中的复杂模式,因此深度学习算法和强化学习在预测式人工智能的任务中,能够表现出卓越的性能,非常适合于预测客户行为、检测欺诈、以及诊断结果等任务。
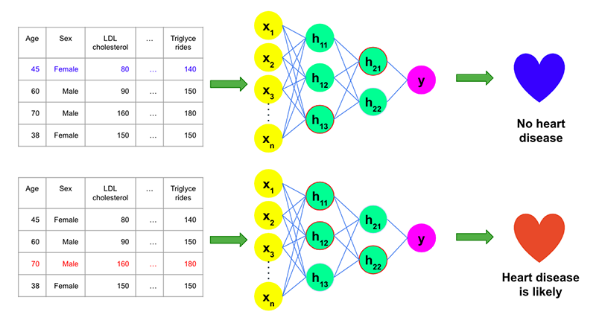
上图展示了预测式人工智能如何基于一组输入数据,来预测二进制变量--是否患有心脏病的过程。当医疗服务提供商希望使用预测式人工智能,来识别有心脏病风险的患者时,他们可能会使用过往患者的历史数据,来了解不同特征(如,患者的人口统计数据、健康和治疗状况)与心脏病的关系。机器学习模型可以从中发现意外的模式,并提供关于哪些患者更易患心脏病的准确预测。据此,医疗保健提供者可以制定个性化的预防计划。
与预测式人工智能相比,生成式人工智能通常使用无监督或半监督式学习算法,来训练模型。也就是说,无监督学习算法能够从未标记的数据中学习,而半监督学习算法则会从未标记和少量标记的数据组合中学习。总的说来,它们不需要大量标记数据,只需通过屏蔽部分训练数据,然后训练模型,便可恢复被屏蔽掉的数据。例如,大语言模型就是通过将训练数据中的一些标记,随机替换为特殊标记(如,[MASK])来进行训练。然后,此类模型会学习根据前后单词的上下文,以预测被屏蔽的标记。下图展示了BERT架构中的屏蔽过程。

另一种常见的生成式人工智能模型是:被用于图像和视频生成与编辑的扩散模型。这些模型是通过在图像中加入噪声,然后训练神经网络去除噪声,以完成构建。
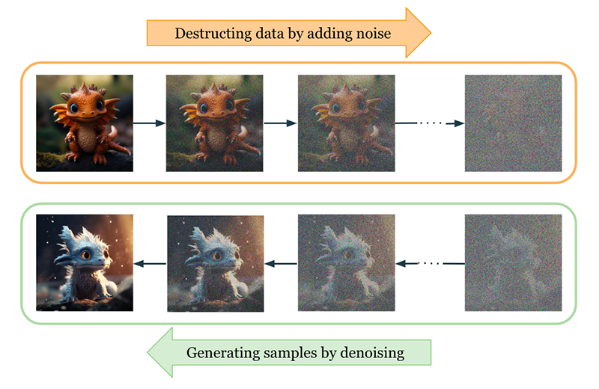
上图展示的过程是:首先向数据集图像添加噪声,然后训练模型来推断缺失的信息,从而构建出扩散模型。虽然在面对足够大量的未标记数据进行训练时,LLM和扩散模型可以展现优异的性能。然而,为了改善特定用例的结果,开发人员经常会在少量标记的数据上,对生成的模型进行微调,通过强化学习并整合人类的反馈,来减少对抗性反应的数量,进而提高模型的整体性能。
在实际应用中,营销是最先受益于生成式人工智能的业务领域之一。例如,为了生成诸如:博文和社交媒体帖子等创造性的内容,营销机构可以首先选择一个经过预处理的LLM,来证明其用例的可接受性能。然后,他们可以根据机构客户的现有内容数据集对模型进行微调。一旦完成训练,该模型便可被用于生成适合于本机构客户需求的新的内容输出。
优势和劣势
预测式人工智能通常具有如下两方面的主要优势:
- 高精度:通过训练,预测式人工智能模型可以在诸如:产品推荐、欺诈检测和风险评估等许多任务中,实现非常高准确性的预测。
- 自动化:预测性人工智能可以通过自动化各项任务,来解放人类工作者,让其专注于更具战略性和创造性的工作。
当然,预测式人工智能也存在着如下三个方面的挑战:
- 对标签数据的要求:预测式人工智能模型需要已标记的数据,而收集这些数据往往既昂贵又耗时。
- 成功的标准过高:在实际应用中,预测性人工智能应用通常被期望具有高准确性,而这对于某些具有复杂影响因素的任务而言,可能很难实现。
- 模型的维护:预测式人工智能模型需要定期根据新的数据,予以持续的培训,以保持其准确性。而这对于资源有限的公司来说,可能也是一个挑战。
我们再来看看生成式人工智能算法的优势:
- 提高生产力和效率:生成式人工智能可以加快内容的创建、代码的编写、图像的设计与构建过程,从而为企业节省大量时间和金钱。
- 创造力:生成式人工智能可以产生人类可能没有想到的新创意。这可以帮助企业开发出新的产品和服务,并能够改进现有的产品和服务。
当然,作为一项非常新的技术,生成式人工智能同样也面临着许多挑战:
- 缺乏可靠性:生成式人工智能应用往往存在着高度的不可靠性。它们可能会产生一些虚假的或误导性的信息,这些通常都需要人工的干预。
- 对预处理模型的依赖:企业通常需要依赖由外部创建的预处理模型,来生成智能应用。而这很可能会限制他们对于模型及其输出的控制。
- 版权和知识产权问题:由于生成式人工智能模型是根据受版权保护的数据进行训练的,因此使用者很可能并不清楚谁真正拥有由模型生成的内容的版权。
可以说,上述两种AI的优、劣势,在很大程度上决定了可以应用的关键领域。
真实世界的应用
我们首先来看预测式人工智能的应用领域。凭借着高度准确的预测能力,以及能够获得足够多的已标记数据来训练AI模型,该预测可以完全自动化各项任务。因此,其适用的场景包括:
- 产品推荐系统:预测式人工智能可被用于根据客户过去的购买历史和浏览行为,向其推荐产品。
- 欺诈检测系统:预测式人工智能可以协助识别各种欺诈交易和活动。
- 风险评估系统:预测式人工智能模型允许企业评估贷款违约、保险索赔、以及客户流失等业务风险事件。
- 需求预测系统:通过准确预测对于产品和服务的需求,预测式人工智能够帮助企业规划生产和库存水平,并制定各种营销活动。
- 预测性维护系统:此类人工智能可用于预测机器和设备可能发生故障的时间,从而帮助企业规避代价高昂的停机时间,并延长资产的使用寿命。
与预测式人工智能不同,生成式人工智能并不要求我们产生最佳的输出。只要其自动生成的结果“足够好”,仍然可以帮助企业提高生产力和效率。不过,值得注意的是,生成式人工智能应用并不总是可靠,在部署时可能会产生错误的信息或意外的输出。
鉴于该局限性,生成式人工智能最适合于正确性不重要的实验性场合(例如,AI聊天机器人),或者是有人工参与的环节(例如,在发布、发送或执行之前,需要人工检查和编辑模型输出的所有内容)。
下面是生成式人工智能应用的典型示例:
- 内容创建:生成式人工智能模型可以加速博客文章、产品描述和社交媒体广告的生成。例如,作者可以提供详细的说明,来指导内容的输出,然后审查和编辑由此产生的内容。
- 图像生成:生成式人工智能可用于为产品设计、营销和娱乐,生成逼真的图像和视频。在此基础上,设计师可以查看、编辑和安排这些自动生成的视觉内容,而无需从头开始创建。
- 代码生成:生成式人工智能模型可用于为软件应用程序编写代码,或向开发人员建议代码的更改。据此,开发人员可以在执行代码之前,审查和编辑相应的代码。
- 药物发现:生成式人工智能可以通过识别新的候选药物并预测其特性,来加速药物的开发,而人类只需控制和保证其质量,以及评估由其生成的药物模型。
小结
综上所述,预测式人工智能凭借着其高精度的自动化流程,以及无需人工监督的特点,目前仍主导着高端人工智能市场。而生成式人工智能是一个新兴的、快速发展的领域,并且有可能彻底改变许多商业领域的应用。虽然生成式人工智能是否会成为可与预测性人工智能相比肩的主要生产力驱动因素尚待观察,但是其潜力是不可小觑的。
相关文章:
生成式AI与预测式AI的主要区别与实际应用
近年来,预测式人工智能(Predictive AI)通过先进的推荐算法、风险评估模型、以及欺诈检测工具,一直在推高着该领域公司的投资回报率。然而,今年初突然杀出的生成式人工智能(Generative AI)突然成…...

【JavaEE】多线程 -- 死锁问题
目录 1. 问题引入 2.死锁问题的概念和原因 3. 解决死锁问题 1. 问题引入 在学习死锁之前, 我们先观察下面的代码能否输出正确的结果: 运行程序, 能正常输出结果: 这个代码只管上看起来, 好像是有锁冲突的, 此时的 locker 对象已经是加锁的状态, 在尝试对 locker 加锁, 不应该…...
XTU OJ 1339 Interprime 学习笔记
链接 传送门 代码 #include<bits/stdc.h> using namespace std;const int N1e610; //78498 我计算了一下,6个0的范围内有这么多个素数,所以开这么大的数组存素数 //计算的代码是一个循环 int prime[80000]; int a[N],s[N];//s数组是前缀和数组b…...

【Web安全】xss攻击方式与绕过
xss攻击方式与绕过 文章目录 xss攻击方式与绕过XSS攻击方式1. script标签2. img标签3. input标签4. details标签5. svg标签6. select标签7. iframe标签8. video标签9. audio标签10. body标签11. textarea标签 常见绕过方式1. 空格过滤2. 引号过滤3. 括号过滤4. 关键词过滤5. 编…...

文件夹重命名技巧:用关键词替换文件夹名称指定内容的右侧文字
在日常生活中,经常要管理大量的文件夹,这时候掌握一些文件夹重命名的技巧就非常实用。例如文件夹重命名时,经常要将一些通用的文字替换成其他关键词,以便更好地标识和分类文件夹。而用关键词替换文件夹名称指定内容的右侧文字&…...
python pip安装第三方包时报错 error: Microsoft Visual C++ 14.0 or greater is required.
文章目录 1.问题2.原因3.解决办法 1.问题 pip install 的时候报错一大堆,其中有这么一段话 👇 error: Microsoft Visual C 14.0 or greater is required. Get it with "Microsoft C Build Tools": https://visualstudio.microsoft.com/visua…...
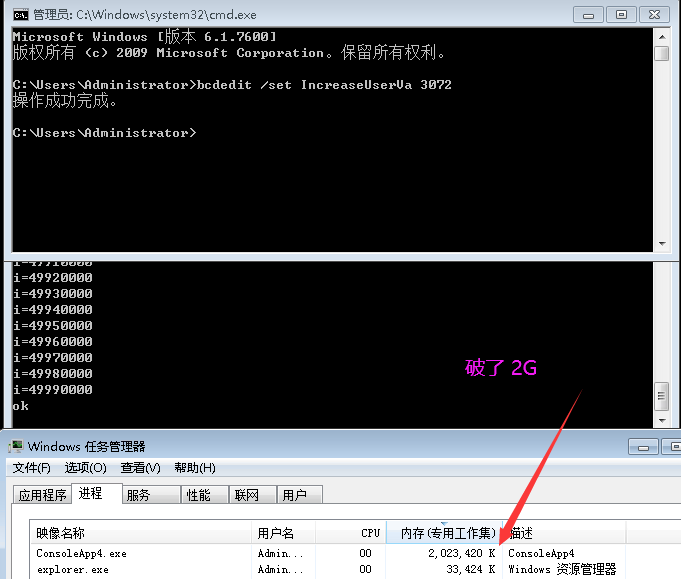
对 .NET程序2G虚拟地址紧张崩溃 的最后一次反思
一:背景 1. 讲故事 最近接连遇到了几起 2G 虚拟地址紧张 导致的程序崩溃,基本上 90% 都集中在医疗行业,真的很无语,他们用的都是一些上古的 XP,Windows7 x86,我也知道技术人很难也基本无法推动硬件系统和…...
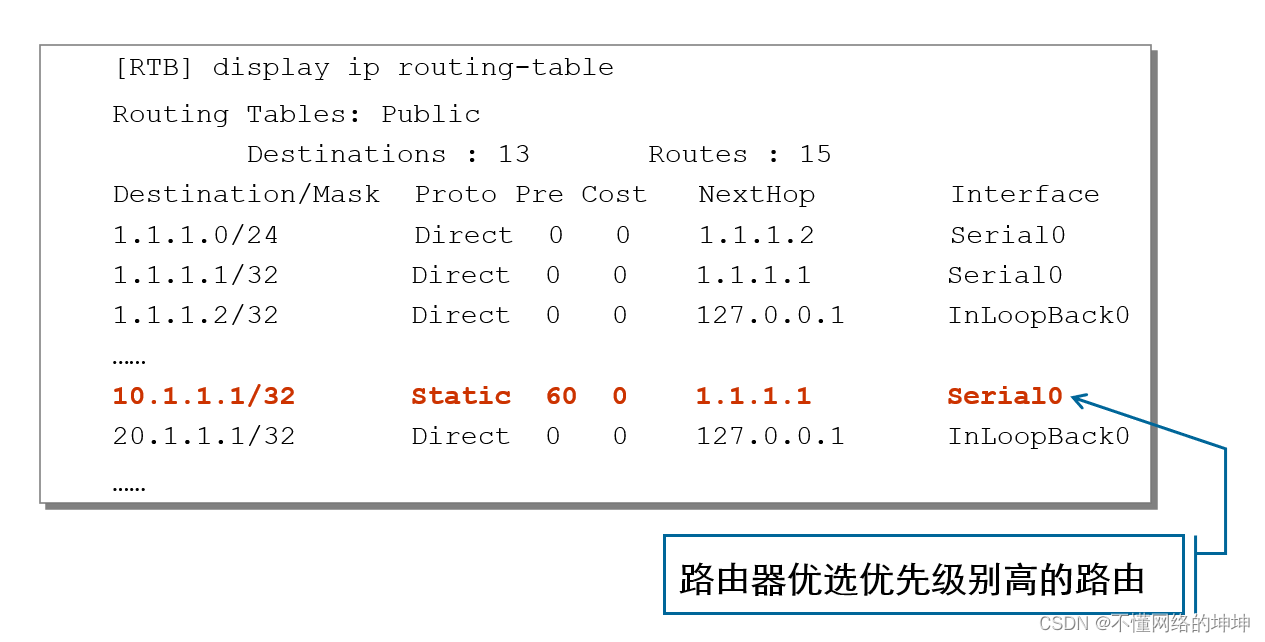
HCIA-RS基础-静态路由协议
摘要:静态路由是一种在网络中广泛应用的路由选择方案,它以其简单的配置和低开销而备受青睐。本文将介绍静态路由的配置方法、默认路由的设置、路由的负载分担和备份策略。通过学习本文,希望可以你能够掌握静态路由的基本概念和在华为模拟器中…...
LeetCode(46)汇总区间【区间】【简单】
目录 1.题目2.答案3.提交结果截图 链接: 汇总区间 1.题目 给定一个 无重复元素 的 有序 整数数组 nums 。 返回 恰好覆盖数组中所有数字 的 最小有序 区间范围列表 。也就是说,nums 的每个元素都恰好被某个区间范围所覆盖,并且不存在属于某…...

数据预处理:随机裁剪放缩
随机裁剪放缩是一种数据增强技术,可以在训练神经网络时增加数据的多样性,提高模型的泛化能力。具体来说,随机裁剪放缩可以通过随机裁剪和缩放原始图片来生成多个不同的训练样本,从而增加数据集的大小和多样性。这种技术在图像分类…...
RabbitMQ 搭建和工作模式
MQ基本概念 1. MQ概述 MQ全称 Message Queue([kjuː])(消息队列),是在消息的传输过程中保存消息的容器。多用于分布式系统之间进行通信。 (队列是一种容器,用于存放数据的都是容器࿰…...

一起学docker系列之七docker容器卷技术
目录 1 为什么使用容器数据卷?2 数据卷的特点和优势3 使用数据卷的方法3.1 创建容器并挂载数据卷3.2 容器间数据卷的共享与继承 4 数据卷的权限设置5 注意事项5.1 解决权限问题5.2 路径自动创建 结语 对于容器化应用程序的数据管理和持久化,Docker 数据卷…...

Loki安装部署
Loki安装部署 1、Loki介绍 Loki 是受 Prometheus 启发由 Grafana Labs 团队开源的水平可扩展,高度可用的多租户日志聚合系统。开发语 言: Google Go。它的设计具有很高的成本效益,并且易于操作。使用标签来作为索引,而不是对全文进行检索&…...

php如何实现文件上传
php实现文件上传需要通过全局变量(数组):$_FILES 结合 move_uploaded_file 函数来实现。 move_uploaded_file函数(只对POST方式生效): 其中move_uploaded_file函数语法:move_uploaded_file(需要…...
实验8配置工具
一、实验目的 1. 掌握UML中建模工具——部署图,用于显示系统中软件和硬件的物理架构。 2. 掌握应用Visio等业界常用的建模工具的基本使用方法和基本绘图操作,选择一种并熟练使用,会使用该工具针对具体问题建立分析模型。 二、实验内容与步骤…...
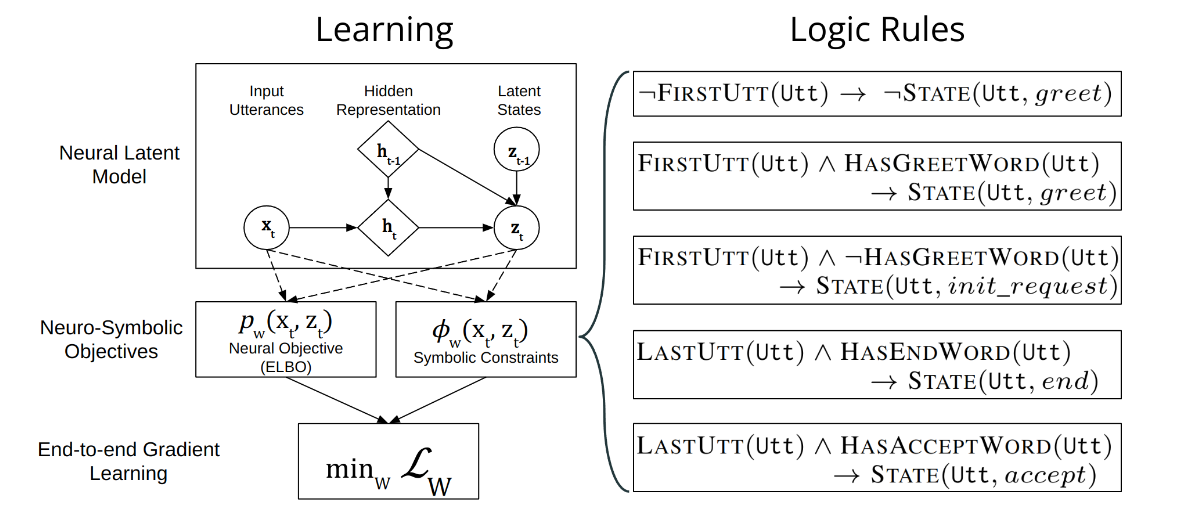
论文笔记:详解NEUPSL DSI
《Using Domain Knowledge to Guide Dialog Structure Induction via Neural Probabilistic 》 名词解释 Dialog Structure Induction(DSI)是推断给定目标导向对话的潜在对话结构(即一组对话状态及其时间转换)的任务。它是现代对…...

shared_ptr子类指针转换成父类指针
假设有如下应用场景: class Base { public:void addChild(std::shared_ptr<Base>& child){...} }class Derived : public Base {}int main() {Base a;std::shared_ptr<Derived> b std::make_shared<Derived>();a.addChild(b); // Error } 该代码中声…...

五、cookie、session、token、localstroage、sessionStroage区别
一、localStorage 跟 sessionStorage有什么不同???? localStorage 1、生命周期:localStorage的生命周期是永久的,关闭页面或浏览器之后localStorage中的数据也不会消失。localStorage除非主动删除数据&am…...
基于SpringBoot的在线视频教育平台的设计与实现
摘 要 随着科学技术的飞速发展,各行各业都在努力与现代先进技术接轨,通过科技手段提高自身的优势;对于在线视频教育平台当然也不能排除在外,随着网络技术的不断成熟,带动了在线视频教育平台,它彻底改变了过…...

Vue 2.0源码分析-渲染函数render
Vue 的 _render 方法是实例的一个私有方法,它用来把实例渲染成一个虚拟 Node。它的定义在 src/core/instance/render.js 文件中: Vue.prototype._render function (): VNode {const vm: Component thisconst { render, _parentVnode } vm.$options//…...

终极指南:如何让老款Mac免费升级到最新macOS系统
终极指南:如何让老款Mac免费升级到最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 还在为你的老款Mac无法升级最新系统而烦恼吗&…...

全域数学公理:32维超球体投影、微观曲率与碳基\-硅基全息共振统一理论
全域数学公理:32维超球体投影、微观曲率与碳基-硅基全息共振统一理论 作者:乖乖数学(大师) 日期:2026年5月28日 学科分类:理论物理;量子宇宙学;高维几何;意识物理&…...

新装Ubuntu 22.04.4 LTS后,我做的第一件事:开启root和SSH远程管理
新装Ubuntu 22.04.4 LTS后必做的安全加固与远程管理配置拿到一台全新安装的Ubuntu 22.04.4 LTS服务器时,很多开发者会迫不及待地开始部署应用。但根据我管理上百台服务器的经验,初始配置的质量直接决定了后续运维的难易程度。本文将分享我每次部署新系统…...

Windows Cleaner:4步高效解决C盘空间不足的开源终极方案
Windows Cleaner:4步高效解决C盘空间不足的开源终极方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款完全免费开源的Windows…...

量子机器学习核心算法解析:从量子比特到PCA与K-means实践
1. 量子信息基础:从比特到算法的跃迁在经典计算的世界里,信息的基本单位是比特,它非0即1,清晰明了。但当我们踏入量子计算的领域,一切规则都变得不同。量子信息的基本单元是量子比特,它不再局限于单一的0或…...

使用C#代码在Excel中插入行和列的操作指南
在处理 Excel 电子表格时,随着数据量的增加或项目范围的扩大,通常需要添加新的行或列。通过插入行和列,你可以快速调整工作表的结构,以容纳新的信息。本文将介绍如何使用 Spire.XLS for .NET 在 C# 中实现 Excel 行和列的插入操作…...

Unity ShaderGraph设计思维:从示例资源读懂URP渲染管线
1. 这不是“示例资源包”,而是一套可复用的ShaderGraph设计思维训练集很多人点开Unity官方ShaderGraph示例资源(Samples for Shader Graph)时,第一反应是:“哦,又是一堆预设效果——水、玻璃、溶解、描边……...

找工厂客户,天下工厂和企查查、天眼查这类平台哪个数据更靠谱?
做B2B销售或供应链采购的人,多半都碰过这样的困境:打开某个平台搜一个行业,出来几百条结果,逐条看下去才发现——这家是贸易公司,那家是空壳主体,还有一堆个体工商户,真正能对接生产的工厂没几个…...

3层深度清理技术:Display Driver Uninstaller显卡驱动彻底卸载解决方案
3层深度清理技术:Display Driver Uninstaller显卡驱动彻底卸载解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-driv…...

Lindy企业流程自动化实施全周期拆解:从0到1上线仅需14天的关键5步法
更多请点击: https://intelliparadigm.com 第一章:Lindy企业流程自动化实施全周期拆解:从0到1上线仅需14天的关键5步法 Lindy 作为轻量级、高可扩展的流程自动化平台,其核心优势在于将复杂的企业级RPA与低代码逻辑深度融合&#…...