Flume采集Kafka并把数据sink到OSS
安装环境
- Java环境, 略 (Flume依赖Java)
- Flume下载, 略
- Scala环境, 略 (Kafka依赖Scala)
- Kafak下载, 略
- Hadoop下载, 略 (不需要启动, 写OSS依赖)
配置Hadoop
下载JindoSDK(连接OSS依赖), 下载地址Github
解压后配置环境变量
export JINDOSDK_HOME=/usr/lib/jindosdk-x.x.x
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:${JINDOSDK_HOME}/lib/*
修改Hadoop配置, core-site.xml
<property><name>fs.oss.credentials.provider</name><value>com.aliyun.jindodata.oss.auth.SimpleCredentialsProvider</value></property><property><name>fs.oss.accessKeyId</name><value>xxxx</value></property><property><name>fs.oss.accessKeySecret</name><value>xxxx</value></property><property><name>fs.oss.endpoint</name><value>xxxxx</value></property><property><name>fs.AbstractFileSystem.oss.impl</name><value>com.aliyun.jindodata.oss.JindoOSS</value></property><property><name>fs.oss.impl</name><value>com.aliyun.jindodata.oss.JindoOssFileSystem</value></property>
配置可参考非EMR集群接入OSS-HDFS服务快速入门
配置Flume
此部分全文最关键, 请仔细看
- 基础配置部分, Flume配置
a1.sources = source1
a1.sinks = k1
a1.channels = c1a1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.source1.channels = c1
a1.sources.source1.kafka.bootstrap.servers = xxx
a1.sources.source1.kafka.topics = test
a1.sources.source1.kafka.consumer.group.id = flume-sink-group # 消费者组, 云组件需要先在管理后台创建
a1.sources.source1.kafka.consumer.auto.offset.reset = earliest # 从头消费Kafka里数据a1.sinks.k1.channel = c1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = oss://xxx/test/%Y%m%d # 自动按天分文件夹
a1.sinks.k1.hdfs.fileType=DataStreama1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 1000可参考使用Flume同步EMR Kafka集群的数据至OSS-HDFS服务
2. 进阶配置, 根据自己情况按需配置
a1.sinks.k1.hdfs.rollInterval = 600 # 5分钟切换一个新文件
a1.sinks.k1.hdfs.rollSize = 134217728 # 或者文件大小达到128M则切换新文件
a1.sinks.k1.hdfs.rollCount = 0 # 写入多少条数据切换新文件, 0为不限制
我这里是为了防止sink的文件过于零碎, 但因为使用的memory channel, 缓存时间过长容易丢数据
3. Flume JVM参数
默认启动时-Xmx20m, 过于小了, 加大堆内存可以直接放开flume-env.sh内JAVA_OPTS的注释
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
- Channel问题
如果对数据一致性要求较高, 可以把memory channel改用file channel, 请自行研究
XX启动!
几条测试命令
bin/zookeeper-server-start.sh config/zookeeper.properties # 启动zookeeper
bin/kafka-server-start.sh config/server.properties # 启动kafak服务bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name a1 # 启动flumebin/kafka-console-producer.sh --topic flume-test --bootstrap-server localhost:9092 # 启动一个生产者写测试数据
相关文章:

Flume采集Kafka并把数据sink到OSS
安装环境 Java环境, 略 (Flume依赖Java)Flume下载, 略Scala环境, 略 (Kafka依赖Scala)Kafak下载, 略Hadoop下载, 略 (不需要启动, 写OSS依赖) 配置Hadoop 下载JindoSDK(连接OSS依赖), 下载地址Github 解压后配置环境变量 export JINDOSDK_HOME/usr/lib/jindosdk-x.x.x expo…...
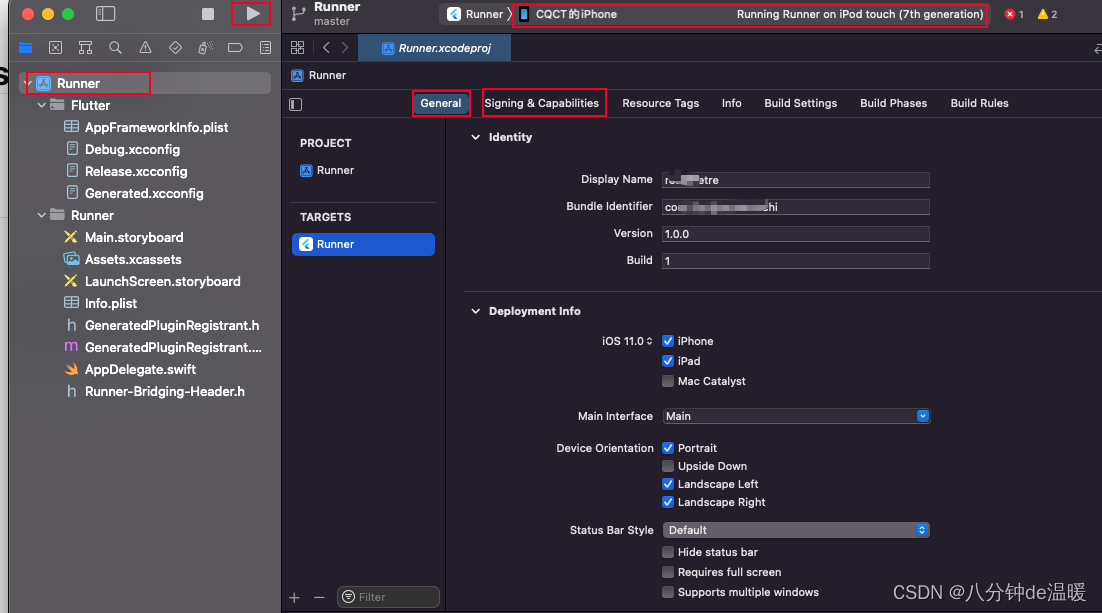
flutter,uni-app开发调试ios
一、申请ios开发者账号 二、ios开发者配置 ios 开发者需要配置的地方 https://developer.apple.com/account/resources/certificates/list Certificates(证书): 作用: 证书用于对应用程序和开发者进行身份验证,确保安全性和可…...

MybatisBatchUtils功能介绍
MybatisBatchUtils 是一个 MyBatis 框架的工具类,主要用于简化 MyBatis 中批量操作的代码编写。该工具类封装了 MyBatis 中的批量操作方法,可以方便地进行批量插入、更新和删除等操作。 一般来说,使用 MyBatis 进行批量操作需要先设置 JDBC 驱…...
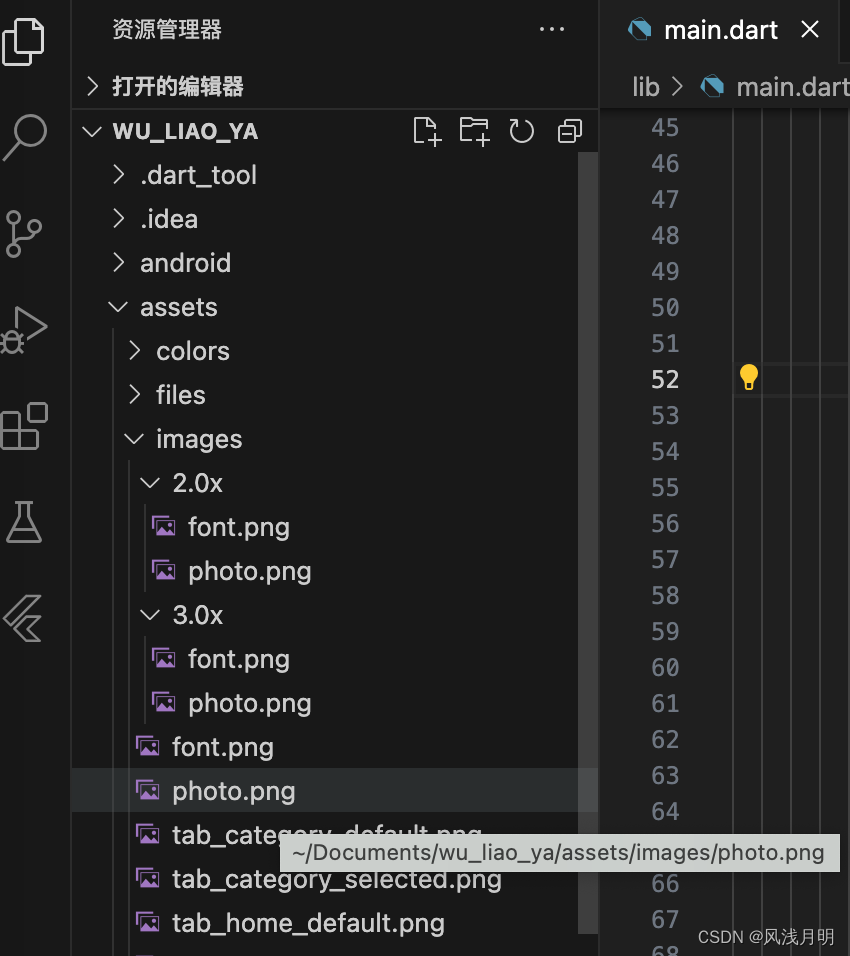
Flutter使用flutter_gen管理资源文件
pub地址: https://pub.dev/packages/flutter_gen 1.添加依赖 在你的pubspec.yaml文件中添加flutter_gen作为开发依赖 dependencies:build_runner:flutter_gen_runner: 2.配置pubspec.yaml 在pubspec.yaml文件中,配置flutter_gen的参数。指定输出路…...
vue3 setup语法糖,常用的几个:defineProps、defineEmits、defineExpose、
vue3和vue2组件之间传参的不同 <script setup> 是在单文件组件 (SFC) 中使用组合式 API 的编译时语法糖。 <script setup> 中的代码会在每次组件实例被创建的时候执行。 任何在 <script setup> 声明的顶层的绑定 (包括变量,函数声明࿰…...

JC/T 2087-2011建筑装饰用仿自然面艺术石检测
建筑装饰用仿自然面艺术石是指以硅酸盐水泥、轻质骨料为主要原料经浇筑成型的饰面装饰材料。 JC/T 2087-2011建筑装饰用仿自然面艺术石测试: 测试项目 测试方法 外观质量 GB/T 18601 尺寸偏差 GB/T 18601 体积密度 GB/T 9966.3 吸水率 GB/T 9966.3 压缩强…...

C语言——写一个简单函数,找两个数中最大者
#include <stdio.h>int max( int a, int b ) { return a>b ? a:b; }int main() { int a, b;printf("输入两个数:\n");scanf("%d %d", &a, &b);printf("max %d\n", max(a, b));return 0; }输出结果:...

机器学习中的混淆矩阵
混淆矩阵是用于评估分类模型性能的表格,它展示了模型在不同类别上的预测情况。对于二分类问题,混淆矩阵的构成如下: 假设有两个类别:正例(Positive)和负例(Negative)。 真正例&…...
QT基础实践之简易计算器
文章目录 简易计算器源码分享演示图第一步 界面设计第二步 设置槽第三步 计算功能实现 简易计算器 源码分享 链接:https://pan.baidu.com/s/1Jn5fJLYOZUq77eNJ916Kig 提取码:qwer 演示图 第一步 界面设计 这里直接用了ui界面,如果想要自己…...
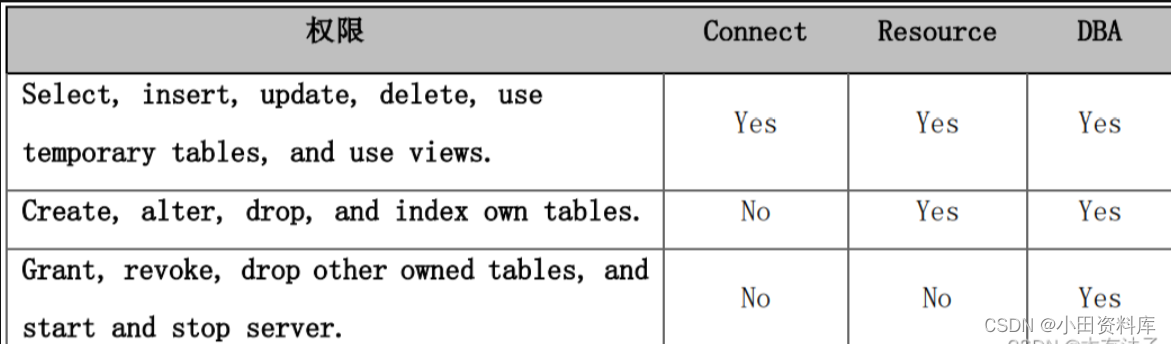
南大通用 GBase 8s数据库级别权限
对于所有有权使用指定数据库的用户都必须赋予其数据库级别的用户权限。在GBase 8s 中,数据库级别的用户权限有三种,按权限从低到高排列依次为:CONNECT、RESOURCE、DBA。 1. CONNECT 这是级别最低的一种数据库级别用户权限。拥有该权限的用户…...
对话式数据需求激增,景联文科技提供高质量多轮对话数据定制采集标注服务
大模型的快速发展使得数据服务需求激增,产品整体处于供不应求状态。对话式数据集成为当下需求热点,人们对于更复杂、更真实的多轮对话数据需求不断增加,定制化服务占据市场需求主流。 通过对多轮对话数据的训练,模型可以更好地理解…...

python第1天之常识及环境安装
前言: 当谈到编程语言的流行度时,Python绝对是其中之一。Python是一种高级编程语言,其语法简单易懂,适用于各种不同的应用领域,包括Web开发、数据分析、人工智能等。在本文中,我们将探讨一些关于Pyth…...
)
中国高纯石英砂行业市场研究与投资前景报告(2024版)
内容简介: 高纯石英砂纯度高、品质好,生产的石英制品具有耐高温、耐腐蚀、低热膨胀性、高度绝缘性和透光性等优异的物理化学属性,被广泛用于光伏、电子、高端电光源、薄膜材料、国防科技等领域,是高端制造行业不可替代的原辅材料…...

遭到美国做空机构“灰熊”做空后,人工智能公司商汤科技股价暴跌
来源:猛兽财经 作者:猛兽财经 猛兽财经获悉,在遭到美国做空机构Grizzly Research(灰熊)指控夸大收入后,商汤科技的股价在周二一度下跌了9.7%。 Grizzly Research在周二发布的一份报告中称,商汤…...
异常检测)
异常数据检测 | Python实现孤立森林(IsolationForest)异常检测
孤立森林(IsolationForest)异常检测 IsolationForest[6]算法它是一种集成算法(类似于随机森林)主要用于挖掘异常(Anomaly)数据,或者说离群点挖掘,总之是在一大堆数据中,找出与其它数据的规律不太符合的数据。该算法不采样任何基于聚类或距离的方法,因此他和那些基于距离的的…...

营销互动类小游戏策划与开发
制定并开发一款营销互动小游戏需要经过一系列策划和实施步骤。以下是一个基本的流程,你可以根据自己的具体情况进行调整: 明确目标:确定小游戏的目标,是提高品牌知名度、增加销售、促进用户互动还是其他目标。 了解目标受众&…...
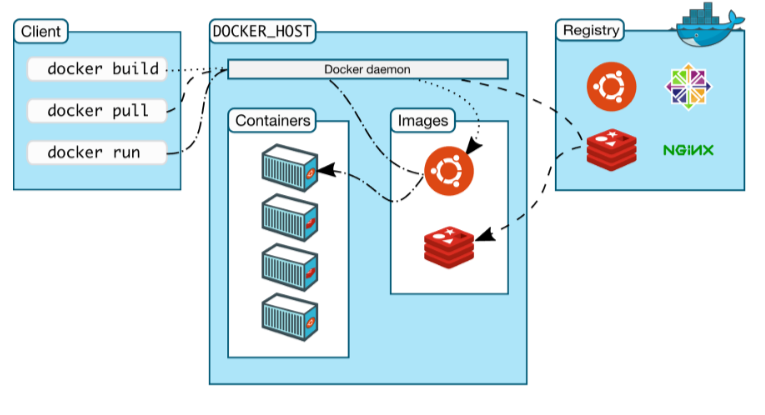
主机的容器化技术介绍
☞ ░ 前往老猿Python博客 ░ https://blog.csdn.net/LaoYuanPython 一、什么是容器 容器是一个标准化的单元,是一种轻量级、可移植的软件打包技术,容器将软件代码及其相关依赖打包,使应用程序可以在任何计算介质运行。例如开发人员在自己的…...

网络基础『发展 ‖ 协议 ‖ 传输 ‖ 地址』
🔭个人主页: 北 海 🛜所属专栏: 神奇的网络世界 💻操作环境: CentOS 7.6 阿里云远程服务器 文章目录 🌤️前言🌦️正文1.网络发展1.1.背景1.2.类型 2.网络协议2.1.什么是协议2.2.协议…...

Aapche Dubbo 不安全的 Java 反序列化 (CVE-2019-17564)
漏洞描述 Apache Dubbo 是一个高性能的、基于 Java 的开源 RPC 框架。 Apache Dubbo 支持不同的协议,它的 HTTP 协议处理程序是 Spring Framework 的 .org.springframework.remoting.httpinvoker.HttpInvokerServiceExporter Spring Framework 的安全警告显示&am…...

B/S软件开发架构
1.简述 1. B/S框架,意思是前端(Browser 浏览器, 小程序,APP,自己写)和服务器端(Server)组成的系统的框架结构。 2. B/S架构也可理解为web架构,包含前端、后端、数据库三大组成部分。 2.前端 前端开发技…...

3步高效启用Windows Insider预览计划:免登录离线方案终极指南
3步高效启用Windows Insider预览计划:免登录离线方案终极指南 【免费下载链接】offlineinsiderenroll OfflineInsiderEnroll - A script to enable access to the Windows Insider Program on machines not signed in with Microsoft Account 项目地址: https://g…...
)
Kali Linux 2024.2 环境下,用 Python 脚本复现一次 DDoS 攻击实验(仅供学习防御)
Kali Linux 2024.2环境下Python脚本模拟DDoS攻击实验与防御研究 在网络安全领域,理解攻击原理是构建有效防御体系的基础。本文将带您在Kali Linux 2024.2环境中,通过Python脚本模拟一次DDoS攻击实验,重点分析攻击流量特征,并探讨如…...

终极指南:如何用amdgpu_top实时监控AMD显卡性能
终极指南:如何用amdgpu_top实时监控AMD显卡性能 【免费下载链接】amdgpu_top Tool to display AMDGPU usage 项目地址: https://gitcode.com/gh_mirrors/am/amdgpu_top 还在为AMD显卡性能监控而烦恼吗?想要像NVIDIA用户使用nvidia-smi那样轻松掌握…...

3步上手UI-TARS智能助手:让AI帮你自动化电脑和浏览器任务
3步上手UI-TARS智能助手:让AI帮你自动化电脑和浏览器任务 【免费下载链接】UI-TARS-desktop The Open-Source Multimodal AI Agent Stack: Connecting Cutting-Edge AI Models and Agent Infra 项目地址: https://gitcode.com/GitHub_Trending/ui/UI-TARS-desktop…...

10分钟完成AI智能图像分层:layerdivider完整使用指南
10分钟完成AI智能图像分层:layerdivider完整使用指南 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾经花费数小时手动分离插图中的不…...

Python EXE逆向工程架构解析:多格式可执行文件源码提取技术实现
Python EXE逆向工程架构解析:多格式可执行文件源码提取技术实现 【免费下载链接】python-exe-unpacker A helper script for unpacking and decompiling EXEs compiled from python code. 项目地址: https://gitcode.com/gh_mirrors/py/python-exe-unpacker …...

VideoDownloadHelper:打破网页视频下载壁垒的智能解决方案
VideoDownloadHelper:打破网页视频下载壁垒的智能解决方案 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 你是否曾遇到过这样的困…...

从接入到稳定使用Taotoken服务的整体流程与可靠性观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从接入到稳定使用Taotoken服务的整体流程与可靠性观察 1. 引言 对于需要调用多种大模型能力的开发者而言,找到一个统一…...
)
STM32F103C8T6+TJA1042+UTA0403:一个CAN通讯新手踩过的所有坑(附完整接线图与代码)
STM32F103C8T6与TJA1042的CAN通讯实战:从零到通的完整避坑指南 当蓝色PCB上那颗STM32F103C8T6第一次通过CAN总线发出数据帧时,我的示波器上终于出现了规整的差分信号波形——这距离我首次焊接CAN收发器已经过去了整整三周。作为嵌入式开发的新手…...

HS2-HF_Patch终极指南:如何快速获得完整汉化与去码体验
HS2-HF_Patch终极指南:如何快速获得完整汉化与去码体验 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF_Patch是《Honey Select 2》游戏的全功…...